Flink Job开发步骤
在开发Flink程序之前,我们先来梳理一下开发一个Flink程序的步骤
env→source→transformation→sink→execute
1:获得一个执行环境
//流处理val env = StreamExecutionEnvironment.getExecutionEnvironment//批处理val env = ExecutionEnvironment.getExecutionEnvironment
2:加载/创建 初始化数据
//连接socket获取输入数据
val text = env.socketTextStream("bigdata1", 9002)
//读取文件中的数据
val text = env.readTextFile("hdfs://bigdata1:9000/hello.txt")
3:指定操作数据的Transformations算子
val wordCount = text.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
.setParallelism(1)
4:指定数据目的地
wordCount.writeAsCsv("hdfs://bigdata1:9000/flink-out")
5:调用execute()触发执行程序
env.execute("BatchWordCountScala")
注意:Flink程序是延迟计算的,只有最后调用execute()方法的时候才会真正触发执行程序 和Spark类似,Spark中是必须要有action算子才会真正执行。
流处理案例:Streaming WordCount
需求:通过socket实时产生一些单词,使用flink实时接收数据,对指定时间窗口内(例如:2秒)的数据进行聚合统计,并且把时间窗口内计算的结果打印出来
scala代码
object SocketWindowWordCountScala {
def main(args: Array[String]): Unit = {
//获取运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//连接socket获取输入数据
val text = env.socketTextStream("bigdata1", 9002)
//处理数据
//注意:必须要添加这一行隐式转换的代码,否则下面的flatMap方法会报错
import org.apache.flink.api.scala._
val wordCount = text.flatMap(_.split(" ")) //将每一行数据按空格切分
.map((_, 1)) //每一个单词转换成tuple2的形式(单词,1)
//.keyBy(0)//根据tuple2中的第一列进行分组 这个方法过时了
.keyBy(tup => tup._1) //官方推荐使用keySelector选择器选择数据
.timeWindow(Time.seconds(2)) //时间窗口为2秒,表示每隔2秒钟计算一次接收到的数据
.sum(1) //基于tup的第二列聚合,使用sum或者reduce都可以
//.reduce((t1,t2)=>(t1._1,t1._2+t2._2))
//使用一个线程执行打印操作
wordCount.print().setParallelism(1)
//执行程序
env.execute("SocketWindowWordCountScala")
}
}
在bigdata1上面开启socket
yum -y install nc
# nc -l 将处于侦听模式
[root@bigdata1 ~]# nc -l 9002
hello you
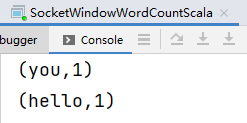
批处理案例:Batch WordCount
需求:统计指定文件中单词出现的总次数
hello.txt
:::tips
hello you
hello me
:::
object BatchWordCountScala {
def main(args: Array[String]): Unit = {
//获取执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
//指定HDFS或者本地文件
//val inputPath = "hdfs://bigdata1:9000/hello.txt"
val inputPath = "D:\\test\\hello.txt"
val outPath = "hdfs://bigdata1:9000/flink-out"
//读取文件中的数据
val text = env.readTextFile(inputPath)
//处理数据
val wordCount = text.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
.setParallelism(1)
wordCount.writeAsCsv(outPath)
env.execute("BatchWordCountScala")
}
}
注意:
setParallelism(1)设置并行度为1是为了将所有数据写到一个文件里面,查看结果比较方便。 默认等于本机的CPU数(逻辑处理器数)
运行程序,查看HDFS
如果注释掉.setParallelism(1),本机是6核12线程(12个逻辑处理器),就会写到12个文件里
并行度
object ParallelismTest {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.readTextFile("D:\\test\\hello.txt")
text.writeAsText("D:\\test\\0225")
.setParallelism(1) //设置并行度为1是为了将所有数据写到一个文件里面,查看结果比较方便。默认等于本机的CPU数(逻辑处理器数)
//如果注释掉.setParallelism(1),本机是6核12线程(12个逻辑处理器),就会写到12个文件里
env.execute()
}
}
setParallelism(1)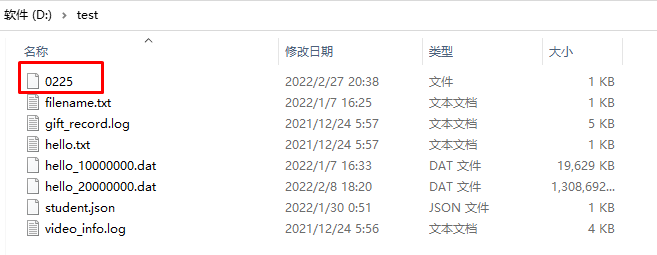
注释掉setParallelism(1)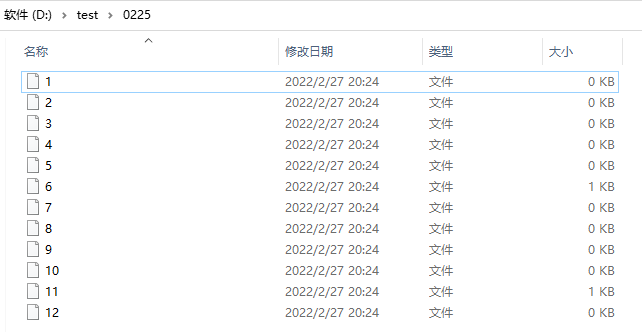
//默认情况下Flink任务中算子的并行度会读取当前机器的CPU个数,但是DataSet API中的fromCollection的并行度为1,可以重新设置
val text = env.fromCollection(Array(1, 2, 3, 4, 5)).setParallelism(2)

若有收获,就点个赞吧
0 人点赞
