介绍
HDFS的全称是Hadoop Distributed File System ,Hadoop的分布式文件系统
它是一种允许文件通过网络在多台主机上分享的文件系统,可以让多台机器上的多个用户分享文件和存储空间
其实分布式文件管理系统有很多,HDFS只是其中一种实现而已 还有 GFS(谷歌的)、TFS(淘宝的)、S3(亚马逊的) 为什么会有多种分布式文件系统呢?这样不是重复造轮子吗? 不是的,因为不同的分布式文件系统的特点是不一样的,HDFS是一种适合大文件存储的分布式文件系统,不适合小文件存储,什么叫小文件,例如,几KB,几M的文件都可以认为是小文件
HDFS的Shell介绍
针对HDFS,我们可以在shell命令行下进行操作,就类似于我们操作linux中的文件系统一样,但是具体命令的操作格式是有一些区别的
格式如下: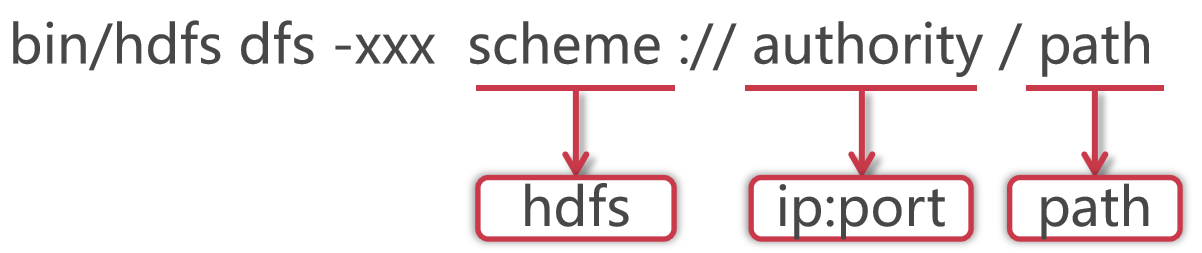
使用hadoop bin目录的hdfs命令,后面指定dfs,表示是操作分布式文件系统的(如果在PATH中配置了hadoop的bin目录,那么这里可以直接使用hdfs就可以了)
xxx是一个占位符,表示对hdfs做什么操作
HDFS的schema是hdfs
authority是集群中namenode所在节点的ip和对应的端口号,把ip换成主机名也是一样的,
path是我们要操作的文件路径信息
其实后面这一长串内容就是core-site.xml配置文件中fs.defaultFS属性的值,这个代表的是HDFS的地址。
HDFS的常见Shell操作
-ls:查询指定路径信息
查看hdfs根目录下的内容,什么都不显示,因为默认情况下hdfs中什么都没有
hdfs dfs -ls hdfs://bigdata1:9000/
其实后面hdfs的url这一串内容在使用时默认是可以省略的,因为hdfs在执行的时候会根据HDOOP_HOME自动识别配置文件中的fs.defaultFS属性
所以这样简写也是可以的
hdfs dfs -ls /
-put:从本地上传文件
接下来我们向hdfs中上传一个文件,使用Hadoop中的README.txt,直接上传到hdfs的根目录即可
hdfs dfs -put README.txt /

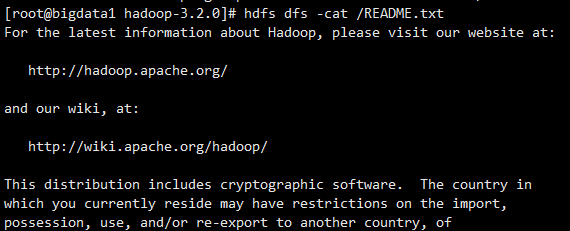
-cat:查看HDFS文件内容
文件上传上去以后,我们还想查看一下HDFS中文件的内容,很简单,使用cat即可
hdfs dfs -cat /README.txt
-get:下载文件到本地
如果我们想把hdfs中的文件下载到本地linux文件系统中需要怎么做呢?使用get即可实现
hdfs dfs -get /README.txt aa.txt
因为本地README.txt已存在,所以命名为aa.txt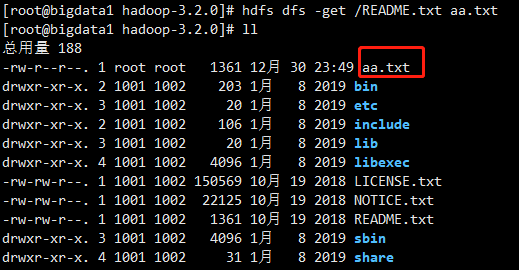
-mkdir [-p]:创建文件夹
创建test文件夹
hdfs dfs -mkdir /test

如果要递归创建多级目录,还需要再指定-p参数
hdfs dfs -mkdir -p /abc/xyz
想要递归显示所有目录的信息,可以在ls后面添加-R参数
hdfs dfs -ls -R /

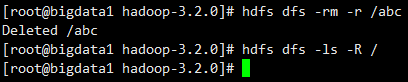
-rm [-r]:删除文件/文件夹
删除文件
hdfs dfs -rm /README.txt
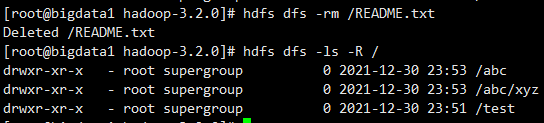
删除目录,注意,删除目录需要指定-r参数
hdfs dfs -rm -r /test

如果是多级目录,可以递归删除吗?可以
hdfs dfs -rm -r /abc
HDFS案例实操
需求:统计HDFS中文件的个数和每个文件的大小
我们先向HDFS中上传几个文件,把hadoop目录中的几个txt文件上传上去
hdfs dfs -put LICENSE.txt /
hdfs dfs -put NOTICE.txt /
hdfs dfs -put README.txt /
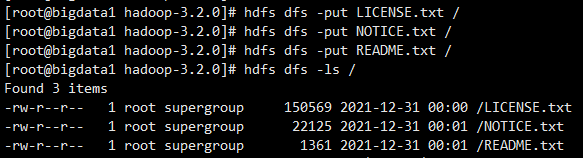
1:统计根目录下文件的个数
hdfs dfs -ls / |grep /| wc -l

2、统计根目录下每个文件的大小,最终把文件名称和大小打印出来
hdfs dfs -ls / |grep / | awk '{print $8,$5}'

Java代码操作HDFS
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
/**
* Java代码操作HDFS
* 文件操作:上传文件,下载文件,删除文件
*/
public class HdfsOp {
public static void main(String[] args) throws Exception {
//创建一个配置对象
Configuration conf = new Configuration();
//指定HDFS的地址
conf.set("fs.defaultFS", "hdfs://192.168.1.21:9000");
//获取操作HDFS的对象
FileSystem fileSystem = FileSystem.get(conf);
//上传文件
//put(fileSystem);
//下载文件
//get(fileSystem);
//删除文件
delete(fileSystem);
}
}
上传文件
/**
* 上传文件
*
* @param fileSystem
* @throws IOException
*/
private static void put(FileSystem fileSystem) throws IOException {
//获取本地文件的输入流
FileInputStream fis = new FileInputStream("D:\\user.txt");
//获取HDFS文件系统的输出流
FSDataOutputStream fos = fileSystem.create(new Path("/user.txt"));
//上传文件:通过工具类把输入流拷贝到输出流里面,实现本地文件上传到HDFS
IOUtils.copyBytes(fis, fos, 1024, true);
}
执行代码,发现报错,提示权限拒绝,说明windows中的这个用户没有权限向HDFS中写入数据
解决办法有两个
第一种:去掉hdfs的用户权限检验机制,通过在hdfs-site.xml中配置dfs.permissions.enabled为false即可
第二种:把代码打包到linux中执行
在这里为了在本地测试方便,我们先使用第一种方式
1:停止Hadoop集群
stop-all.sh
2:修改hdfs-site.xml配置文件
cd etc/hadoop/
vim hdfs-site.xml
伪分布式集群配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
分布式集群配置:
注意:集群内所有节点中的配置文件都需要修改,先在bigdata01节点上修改,然后再同步到另外两个节点上
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
同步到另外两个节点中
scp -rq etc/hadoop/hdfs-site.xml bigdata2:/data/soft/hadoop-3.2.0/etc/hadoop/
scp -rq etc/hadoop/hdfs-site.xml bigdata3:/data/soft/hadoop-3.2.0/etc/hadoop/
3、启动Hadoop集群
start-all.sh

下载文件
/**
* 下载文件
*
* @param fileSystem
* @throws IOException
*/
private static void get(FileSystem fileSystem) throws IOException {
//获取HDFS文件系统中的输入流
FSDataInputStream fis = fileSystem.open(new Path("/README.txt"));
//获取本地文件的输出流
FileOutputStream fos = new FileOutputStream("D:\\README.txt");
//下载文件
IOUtils.copyBytes(fis, fos, 1024, true);
}

删除文件
/**
* 删除文件或者目录
*
* @param fileSystem
* @throws IOException
*/
private static void delete(FileSystem fileSystem) throws IOException {
//删除文件,目录也可以删除
//如果要递归删除目录,则第二个参数需要设置为true
//如果删除的是文件或者空目录,第二个参数会被忽略
boolean flag = fileSystem.delete(new Path("/user.txt"), true);
if (flag) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
}

使用WEB-UI操作HDFS
web地址:http://192.168.1.21:9870/
解决Couldn’t upload the file XXX.问题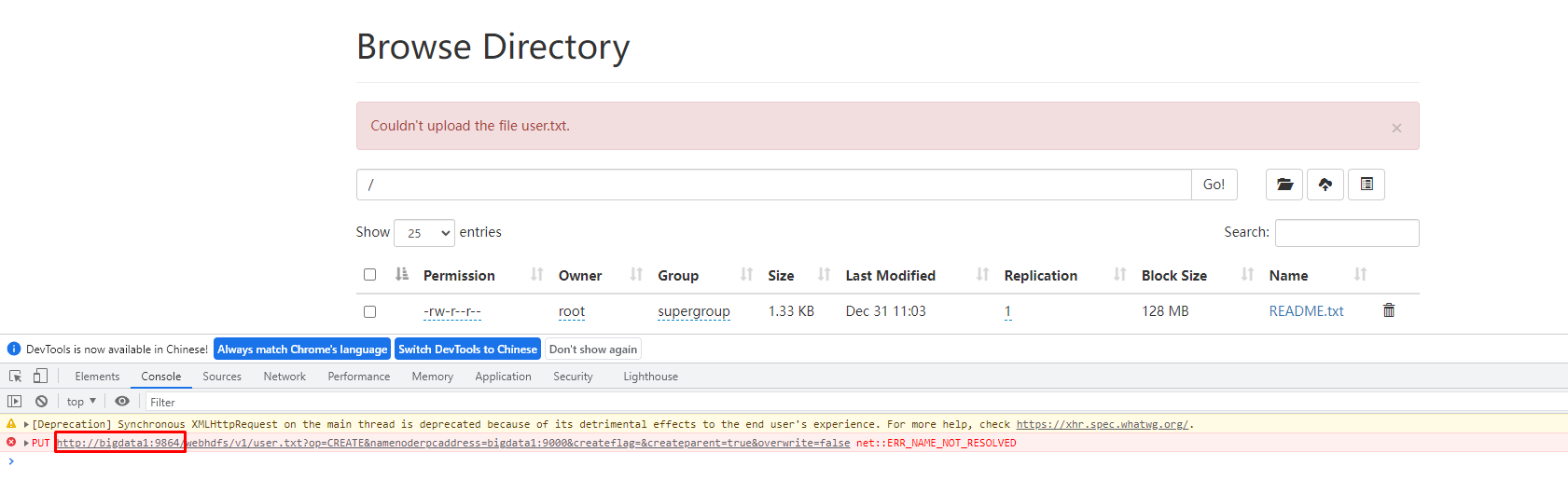
原因 : win10的hosts没有配置ip映射,无法解析域名
在win10上配置ip 域名映射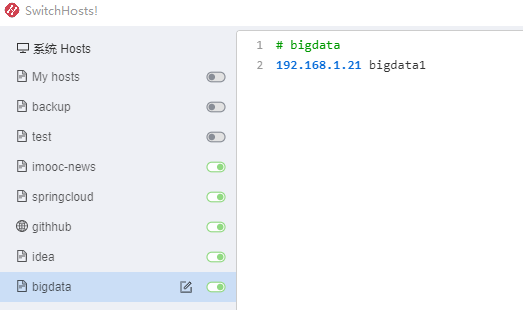
HDFS体系结构
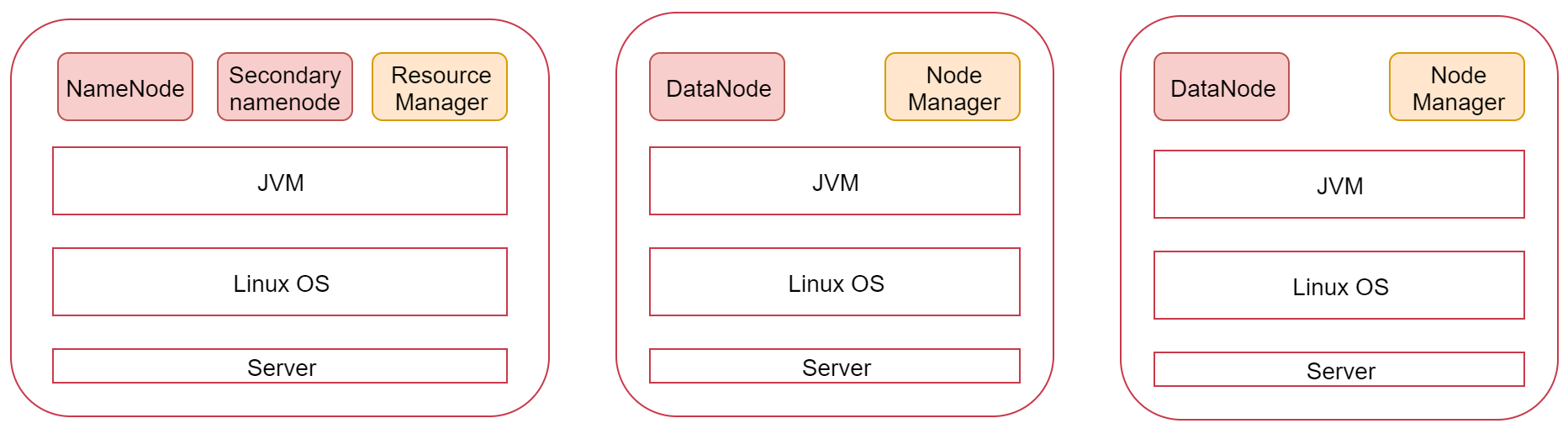
NameNode、SecondaryNameNode、DataNode是HDFS服务的进程,
ResourceManager、NodeManager是YARN服务的进程。
HDFS支持主从结构,主节点称为 NameNode ,NameNode支持多个。
从节点称为 DataNode ,DataNode支持多个。
可以这样理解: 公司BOSS:NameNode 秘书:SecondaryNameNode 员工:DataNode
接着看一下这张图,这就是HDFS的体系结构,这里面的TCP、RPC、HTTP表示是不同的网络通信方式,通过这张图是想加深大家对HDFS体系结构的理解,我们前面配置的集群NameNode和SecondaryNameNode进程在同一台机器上面,在这个图里面是把它们分开到多台机器中了。
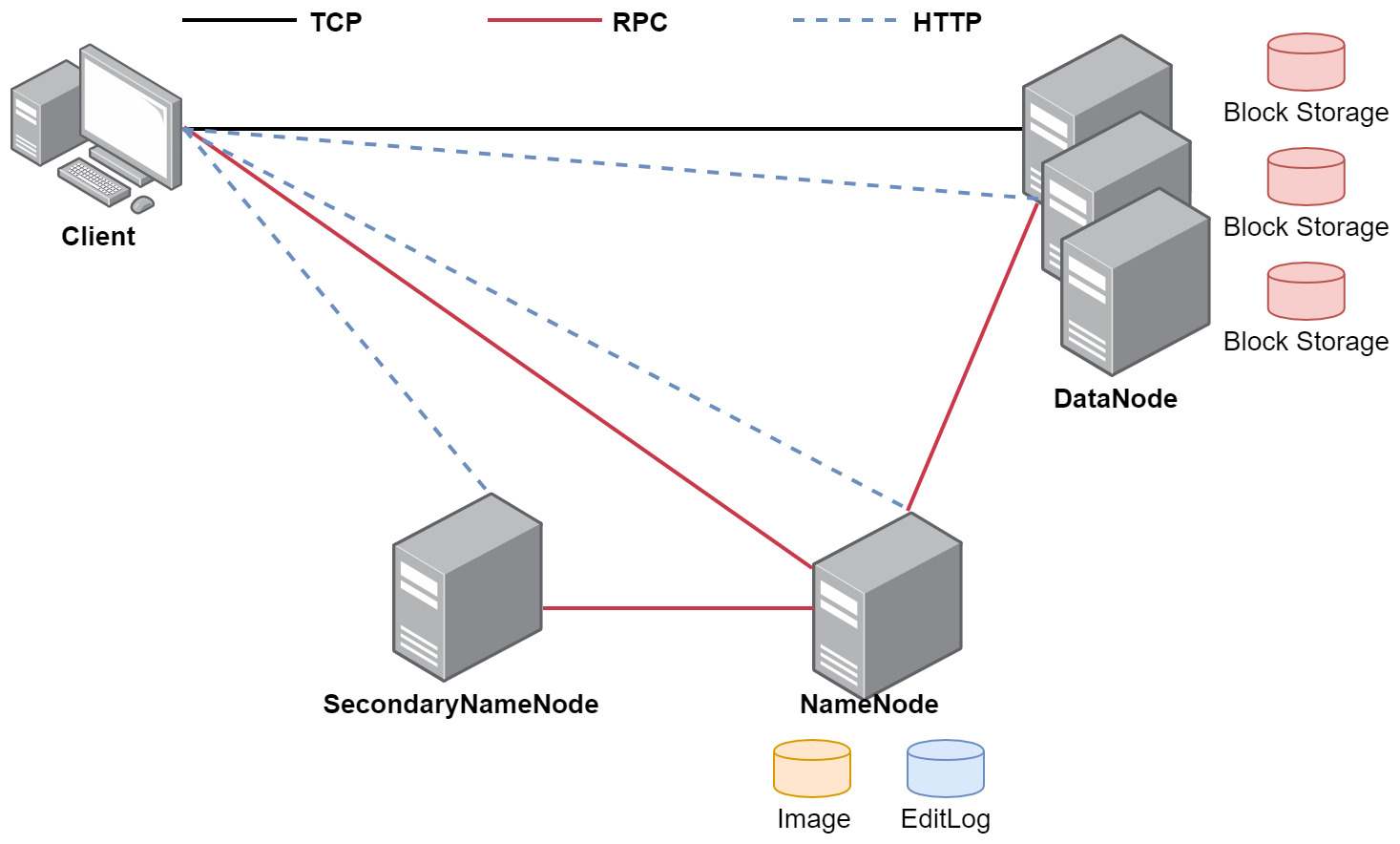
NameNode(管理节点)
NameNode是整个文件系统的管理节点
它主要维护着整个文件系统的文件目录树,文件/目录的信息 和 每个文件对应的数据块列表,并且还负责接收用户的操作请求。
- 目录树:表示目录之间的层级关系,就是我们在hdfs上执行ls命令可以看到的那个目录结构信息。
- 文件/目录的信息:表示文件/目录的的一些基本信息,所有者 属组 修改时间 文件大小等信息
- 每个文件对应的数据块列表:如果一个文件太大,那么在集群中存储的时候会对文件进行切割,这个时候就类似于会给文件分成一块一块的,存储到不同机器上面。所以HDFS还要记录一下一个文件到底被分了多少块,每一块都在什么地方存储着
我们现在可以到集群的9870界面查看一下,随便找一个文件看一下,点击文件名称,可以看到Block information 但是文件太小,只有一个块 叫Block 0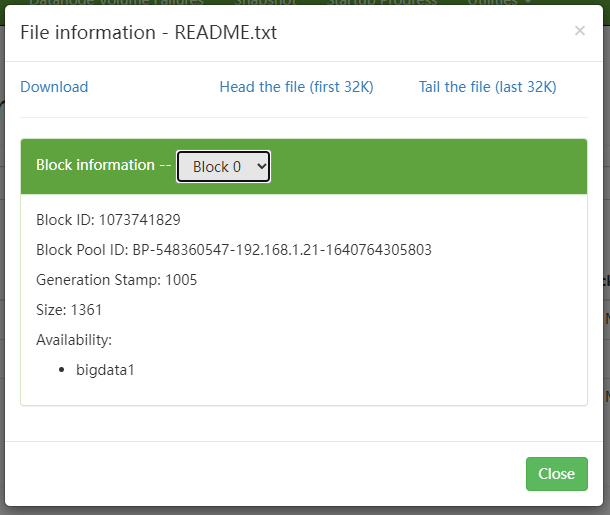
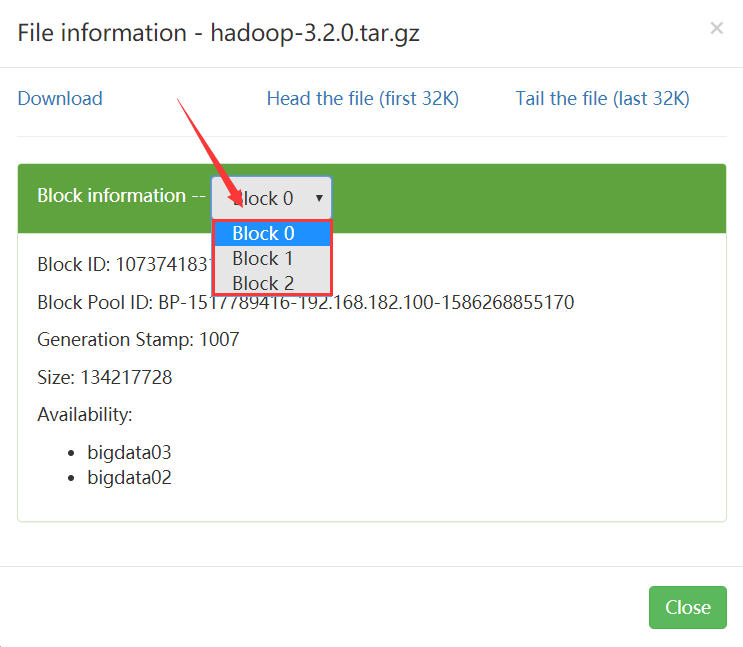
我们试着上传一个大一点的文件,找一个200M左右的文件。
[root@bigdata01 hadoop-3.2.0]# cd /data/soft/
[root@bigdata01 soft]# hdfs dfs -put hadoop-3.2.0.tar.gz /
NameNode主要包括以下文件:
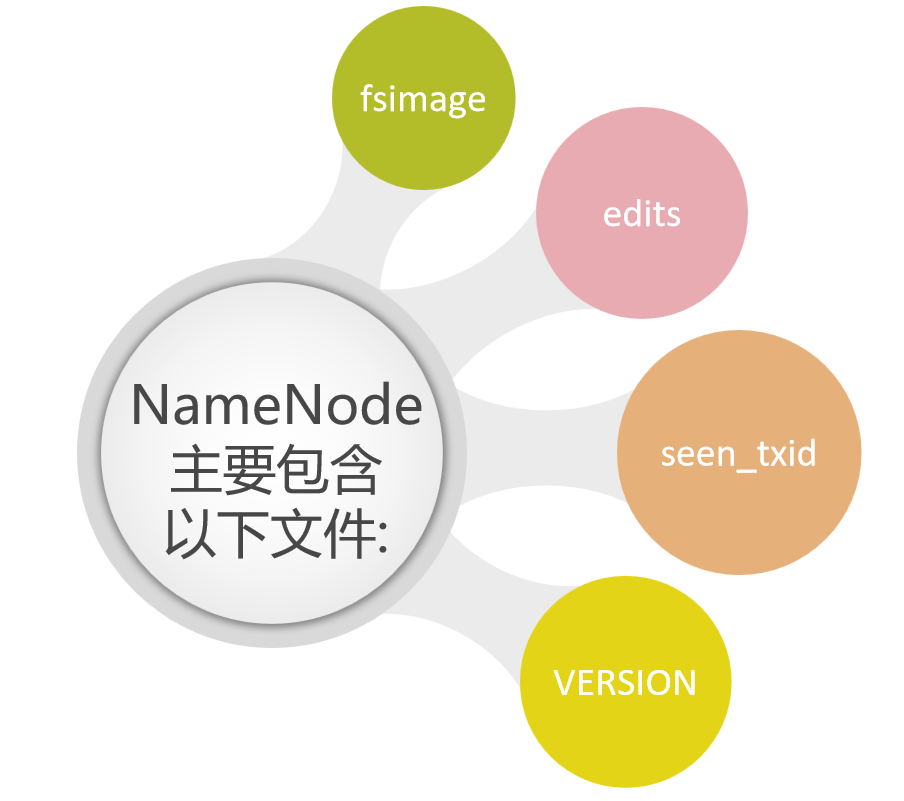
| fsimage | 元数据镜像文件,存储某一时刻NameNode内存中的元数据信息,就类似是定时做了一个快照操作。【这里的元数据信息是指文件目录树、文件/目录的信息、每个文件对应的数据块列表】 |
|---|---|
| edits | 操作日志文件【事务文件】,这里面会实时记录用户的所有操作 |
| seentxid | 是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits*文件的尾数,namenode重启的时候,会按照seen_txid的数字,顺序从头跑edits_0000001~到seen_txid的数字。如果根据对应的seen_txid无法加载到对应的文件,NameNode进程将不会完成启动以保护数据一致性。 |
| VERSION | 保存了集群的版本信息 |
SecondaryNameNode
SecondaryNameNode主要负责定期的把edits文件中的内容合并到fsimage中
这个合并操作称为checkpoint,在合并的时候会对edits中的内容进行转换,生成新的内容保存到fsimage文件中。
注意:在NameNode的HA架构中没有SecondaryNameNode进程,文件合并操作会由standby NameNode负责实现
所以在Hadoop集群中,SecondaryNameNode进程并不是必须的。
DataNode(真实文件存储)
DataNode是提供真实文件数据的存储服务
针对datanode主要掌握两个概念,一个是block,一个是replication
block(128MB)
HDFS会按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block,HDFS默认Block大小是 128MB。
Blokc块是HDFS读写数据的基本单位,不管你的文件是文本文件 还是视频 或者音频文件,针对hdfs而言 都是字节。
我们之前上传的一个user.txt文件,他的block信息可以在fsimage文件中看到,也可以在hdfs webui上面看到, 里面有block的id信息,并且也会显示这个数据在哪个节点上面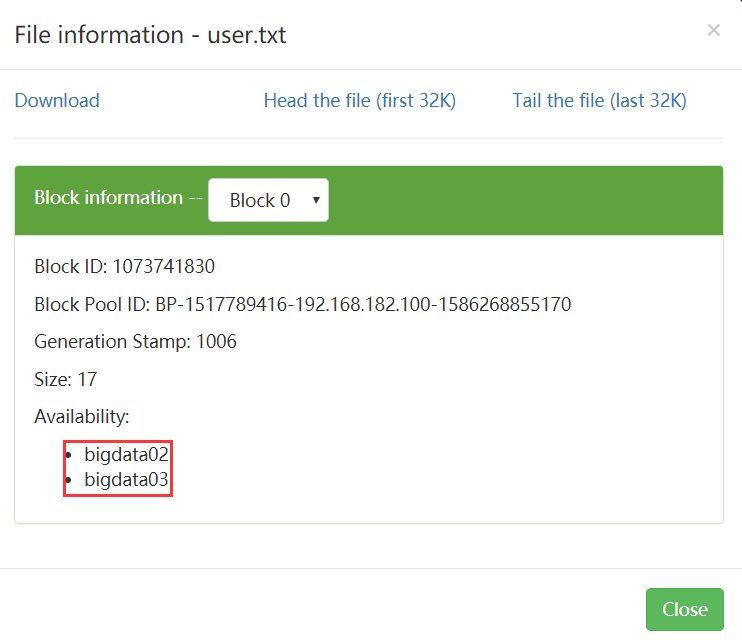
这里显示在bigdata02和bigdata03上面都有,那我们过去看一下,datanode中数据的具体存储位置是由dfs.datanode.data.dir来控制的,通过查询hdfs-default.xml可以知道,具体的位置在这里
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>
....
</description>
</property>
那我们连接到bigdata02这个节点上去看一下
[root@bigdata02 ~]# cd /data/hadoop_repo/dfs/data/
[root@bigdata02 data]# ll
total 4
drwxr-xr-x. 3 root root 72 Apr 7 22:21 current
-rw-r--r--. 1 root root 14 Apr 8 20:30 in_use.lock
然后进入current目录,继续一路往下走
[root@bigdata02 data]# cd current/
[root@bigdata02 current]# ll
total 4
drwx------. 4 root root 54 Apr 8 20:30 BP-1517789416-192.168.182.100-1586268855170
-rw-r--r--. 1 root root 229 Apr 8 20:30 VERSION
[root@bigdata02 current]# cd BP-1517789416-192.168.182.100-1586268855170/
[root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# ll
total 4
drwxr-xr-x. 4 root root 64 Apr 8 20:25 current
-rw-r--r--. 1 root root 166 Apr 7 22:21 scanner.cursor
drwxr-xr-x. 2 root root 6 Apr 8 20:30 tmp
[root@bigdata02 BP-1517789416-192.168.182.100-1586268855170]# cd current/
[root@bigdata02 current]# ll
total 8
-rw-r--r--. 1 root root 20 Apr 8 20:25 dfsUsed
drwxr-xr-x. 3 root root 21 Apr 8 15:34 finalized
drwxr-xr-x. 2 root root 6 Apr 8 22:13 rbw
-rw-r--r--. 1 root root 146 Apr 8 20:30 VERSION
[root@bigdata02 current]# cd finalized/
[root@bigdata02 finalized]# ll
total 0
drwxr-xr-x. 3 root root 21 Apr 8 15:34 subdir0
[root@bigdata02 finalized]# cd subdir0/
[root@bigdata02 subdir0]# ll
total 4
drwxr-xr-x. 2 root root 4096 Apr 8 22:13 subdir0
[root@bigdata02 subdir0]# cd subdir0/
[root@bigdata02 subdir0]# ll
total 340220
-rw-r--r--. 1 root root 22125 Apr 8 15:55 blk_1073741828
-rw-r--r--. 1 root root 183 Apr 8 15:55 blk_1073741828_1004.meta
-rw-r--r--. 1 root root 1361 Apr 8 15:55 blk_1073741829
-rw-r--r--. 1 root root 19 Apr 8 15:55 blk_1073741829_1005.meta
-rw-r--r--. 1 root root 17 Apr 8 20:31 blk_1073741830
-rw-r--r--. 1 root root 11 Apr 8 20:31 blk_1073741830_1006.meta
-rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741831
-rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741831_1007.meta
-rw-r--r--. 1 root root 134217728 Apr 8 22:13 blk_1073741832
-rw-r--r--. 1 root root 1048583 Apr 8 22:13 blk_1073741832_1008.meta
-rw-r--r--. 1 root root 77190019 Apr 8 22:13 blk_1073741833
-rw-r--r--. 1 root root 603055 Apr 8 22:13 blk_1073741833_1009.meta
这里面就有很多的block块了,
注意: 这里面的.meta文件也是做校验用的。
根据前面看到的blockid信息到这对应的找到文件,可以直接查看,发现文件内容就是我们之前上传上去的内容。
[root@bigdata02 subdir0]# cat blk_1073741830
jack
tom
jessic
[root@bigdata02 subdir0]#
注意:这个block中的内容可能只是文件的一部分,如果你的文件较大的话,就会分为多个block存储,默认 hadoop3中一个block的大小为128M。根据字节进行截取,截取到128M就是一个block。如果文件大小没有默认的block块大,那最终就只有一个block。
HDFS中,如果一个文件小于一个数据块的大小,那么并不会占用整个数据块的存储空间
假设我们上传了两个10M的文件 又上传了一个200M的文件
问1:会产生多少个block块? 4个
问2:在hdfs中会显示几个文件?3个
replication
副本表示数据有多少个备份
我们现在的集群有两个从节点,所以最多可以有2个备份,这个是在hdfs-site.xml中进行配置的,dfs.replication
默认这个参数的配置是3。表示会有3个副本。
总结
注意:block块存放在哪些datanode上,只有datanode自己知道,当集群启动的时候,datanode会扫描自己节点上面的所有block块信息,然后把节点和这个节点上的所有block块信息告诉给namenode。这个关系是每次重启集群都会动态加载的【这个其实就是集群为什么数据越多,启动越慢的原因】
namenode维护了两份关系:
第一份关系:file 与block list的关系,对应的关系信息存储在fsimage和edits文件中,当NameNode启动的时候会把文件中的元数据信息加载到内存中
第二份关系:datanode与block的关系,对应的关系主要在集群启动的时候保存在内存中,当DataNode启动时会把当前节点上的Block信息和节点信息上报给NameNode
注意了,刚才我们说了NameNode启动的时候会把文件中的元数据信息加载到内存中,然后每一个文件的元数据信息会占用150字节的内存空间,这个是恒定的,和文件大小没有关系,咱们前面在介绍HDFS的时候说过,HDFS不适合存储小文件,其实主要原因就在这里,不管是大文件还是小文件,一个文件的元数据信息在NameNode中都会占用150字节,NameNode节点的内存是有限的,所以它的存储能力也是有限的,如果我们存储了一堆都是几KB的小文件,最后发现NameNode的内存占满了,确实存储了很多文件,但是文件的总体大小却很小,这样就失去了HDFS存在的价值
HDFS的回收站
我们windows系统里面有一个回收站,当想恢复删除的文件的话就可以到这里面进行恢复,HDFS也有回收站。
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/,每一个被用户在Shell命令行删除的文件/目录,会进入到对应的回收站目录中,在回收站中的数据都有一个生存周期,也就是当回收站中的文件/目录在一段时间之内没有被用户恢复的话,HDFS就会自动的把这个文件/目录彻底删除,之后,用户就永远也找不回这个文件/目录了。
默认情况下hdfs的回收站是没有开启的,需要通过一个配置来开启,在core-site.xml中添加如下配置,value的单位是分钟,1440分钟表示是一天的生存周期
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
在修改配置信息之前先验证一下删除操作,显示的是直接删除掉了。
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /NOTICE.txt
Deleted /NOTICE.txt
修改回收站配置,先在bigdata01上操作,然后再同步到其它两个节点,先停止集群
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
[root@bigdata01 hadoop-3.2.0]# vim etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/core-site.xml bigdata02:/data/soft/hadoop-3.2.0/etc/hadoop/
[root@bigdata01 hadoop-3.2.0]# scp -rq etc/hadoop/core-site.xml bigdata03:/data/soft/hadoop-3.2.0/etc/hadoop/
启动集群,再执行删除操作
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /README.txt
2020-04-09 11:43:47,664 INFO fs.TrashPolicyDefault: Moved: 'hdfs://bigdata01:9000/README.txt' to trash at: hdfs://bigdata01:9000/user/root/.Trash/Current/README.txt
此时看到提示信息说把删除的文件移到到了指定目录中,其实就是移动到了当前用户的回收站目录。
回收站的文件也是可以下载到本地的。其实在这回收站只是一个具备了特殊含义的HDFS目录。
注意:如果删除的文件过大,超过回收站大小的话会提示删除失败 需要指定参数 -skipTrash ,指定这个参数表示删除的文件不会进回收站
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r -skipTrash /user.txt
Deleted /user.txt
HDFS的安全模式
大家在平时操作HDFS的时候,有时候可能会遇到这个问题,特别是刚启动集群的时候去上传或者删除文件,会发现报错,提示NameNode处于safe mode。
这个属于HDFS的安全模式,因为在集群每次重新启动的时候,HDFS都会检查集群中文件信息是否完整,例如副本是否缺少之类的信息,所以这个时间段内是不允许对集群有修改操作的,如果遇到了这个情况,可以稍微等一会,等HDFS自检完毕,就会自动退出安全模式。
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /hadoop-3.2.0.tar.gz
2020-04-09 12:00:36,646 WARN fs.TrashPolicyDefault: Can't create trash directory: hdfs://bigdata01:9000/user/root/.Trash/Current
org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/root/.Trash/Current. Name node is in safe mode.
此时访问HDFS的web ui界面,可以看到下面信息,on表示处于安全模式,off表示安全模式已结束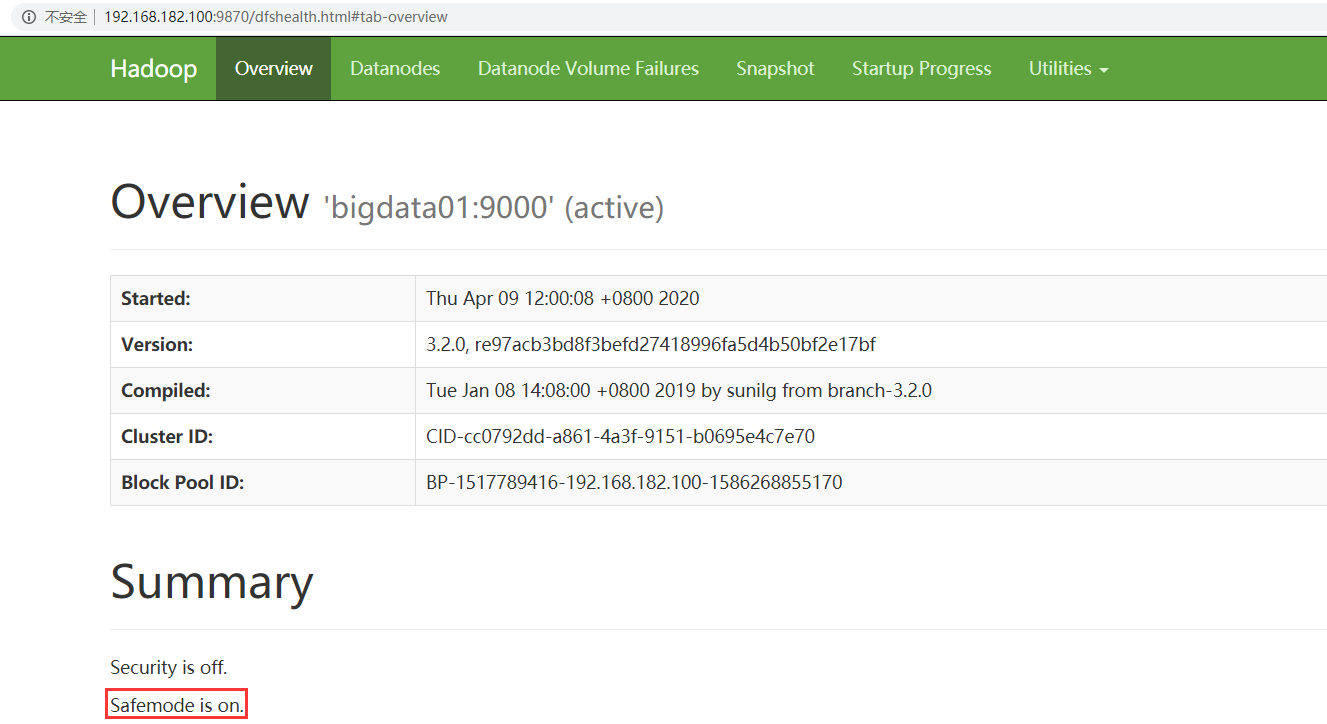
或者通过hdfs命令也可以查看当前的状态
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode get
Safe mode is ON
如果想快速离开安全模式,可以通过命令强制离开,正常情况下建议等HDFS自检完毕,自动退出
[root@bigdata01 hadoop-3.2.0]# hdfs dfsadmin -safemode leave
Safe mode is OFF
此时,再操作HDFS中的文件就可以了。

若有收获,就点个赞吧
0 人点赞
