在实际工作中flume和kafka会深度结合使用
1:flume采集数据,将数据实时写入kafka
2:flume从kafka中消费数据,保存到hdfs,做数据备份
看一个综合案例
使用flume采集日志文件中产生的实时数据,写入到kafka中,然后再使用flume从kafka中将数据消费出来,保存到hdfs上面
那为什么不直接使用flume将采集到的日志数据保存到hdfs上面呢?
因为中间使用kafka进行缓冲之后,后面既可以实现实时计算,又可以实现离线数据备份,最终实现离线计算,所以这一份数据就可以实现两种需求,使用起来很方便,所以在工作中一般都会这样做。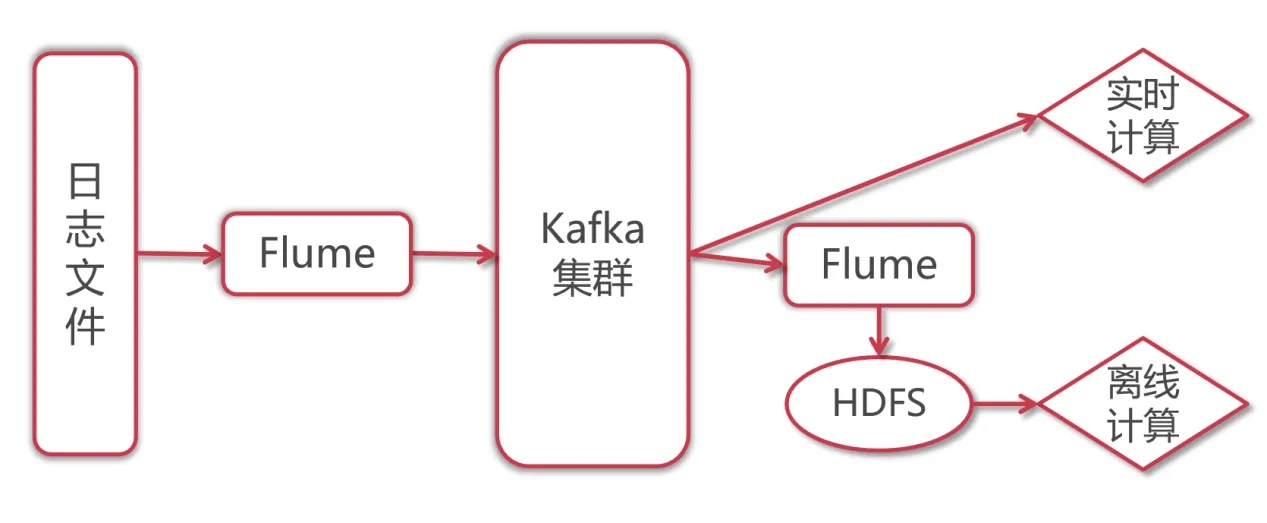
在Flume中,针对Kafka提供的有KafkaSource和KafkaSinkKafkaSource:从kafka中读取数据KafkaSink:向kafka中写入数据
需要配置两个Agent
第一个Agent:负责实时采集日志文件,将采集到的数据写入kafka中,使用KafkaSink
第二个Agent:负责从kafka中读取数据,将数据写入HDFS中进行备份(落盘),使用KafkaSource
Log→Flume→Kafka
第一个Agent负责实时采集日志文件,将采集到的数据写入Kafka中,使用KafkaSink
:::info
source:ExecSource,使用tail -F监控日志文件即可
channel:MemoryChannel
sink:KafkaSink
:::
file-to-kafka.conf
# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# 配置source组件a1.sources.r1.type = execa1.sources.r1.command = tail -F /data/log/test.log# 配置channel组件a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# 配置sink组件a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSinka1.sinks.k1.kafka.topic = test_r1p5a1.sinks.k1.kafka.bootstrap.servers = bigdata1:9092# 一次向kafka中写多少条数据,默认值为100,在这里为了演示方便,改为1。表示采集到1条就写一次# 在实际工作中这个值具体设置多少需要在传输效率和数据延迟上进行取舍# 如果kafak后面的实时计算程序对数据的要求是低延迟,那么这个值小一点比较好# 如果kafka后面的实时计算程序对数据延迟没什么要求,那么就考虑传输性能,一次多传输一些数据,这样吞吐量会有所提升a1.sinks.k1.kafka.flumeBatchSize = 1a1.sinks.k1.kafka.producer.acks = 1# 一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去# linger.ms和flumeBatchSize,哪个先满足先按哪个规则执行,这个值默认是0,在这设置为1表示每隔1毫秒就将这一个Batch中的数据发送出去a1.sinks.k1.kafka.producer.linger.ms = 1# 指定数据传输时的压缩格式,对数据进行压缩,提高传输效率a1.sinks.k1.kafka.producer.compression.type = snappy# 把组件连接起来a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
Kafka→Flume→HDFS
第二个Agent负责从Kafka中读取数据,将数据写入HDFS中进行备份,使用KafkaSource
:::info
Source:KafkaSource
channel:MemoryChannel
sink:HdfsSink
:::
kafka-to-hdfs.conf
# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1# 配置source组件a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource# 一次性向channel中写入的最大数据量,在这为了演示方便,设置为1# 这个参数的值不要大于MemoryChannel中transactionCapacity的值a1.sources.r1.batchSize = 1# 最大多长时间向channel写一次数据a1.sources.r1.batchDurationMillis = 2000# kafka地址a1.sources.r1.kafka.bootstrap.servers = bigdata1:9092# topic名称,可以指定一个或者多个,多个topic之间使用逗号隔开# 也可以使用正则表达式指定一个topic名称规则a1.sources.r1.kafka.topics = test_r1p5# 指定消费者组a1.sources.r1.kafka.consumer.group.id = flume-con1# 配置channel组件a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# 配置sink组件a1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://192.168.1.21:9000/kafkaouta1.sinks.k1.hdfs.filePrefix = data-a1.sinks.k1.hdfs.fileType = DataStreama1.sinks.k1.hdfs.writeFormat = Texta1.sinks.k1.hdfs.rollInterval = 3600a1.sinks.k1.hdfs.rollSize = 134217728a1.sinks.k1.hdfs.rollCount = 0# 把组件连接起来a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
在flume目录下复制两个conf目录,便于区分两个agent的日志
cd /data/soft/apache-flume-1.9.0-bincp -r conf conf-file-to-kafkacp -r conf conf-kafka-to-hdfs
修改 conf_file_to_kafka和conf_kafka_to_hdfs中log4j的配置
cd conf-file-to-kafkavi log4j.properties...flume.root.logger=ERROR,LOGFILEflume.log.file=flume-file-to-kafka.log...
cd conf-kafka-to-hdfsvi log4j.properties...flume.root.logger=ERROR,LOGFILEflume.log.file=flume-kafka-to-hdfs.log...
把刚才配置的两个Agent的配置文件复制到这两个目录下
cd conf-file-to-kafkavi file-to-kafka.conf.....把file-to-kafka.conf文件中的内容复制进来即可
cd conf-kafka-to-hdfs/vi kafka-to-hdfs.conf.....把kafka-to-hdfs.conf文件中的内容复制进来即可
启动这两个Flume Agent
确保zookeeper集群、kafka集群和Hadoop集群是正常运行的
以及Kafka中的topic需要提前创建好
创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 5 --replication-factor 2 --topic test_r2p5
测试的时候忘记创建topic,默认生成了一个r1p1的test_r2p5
先启动第二个Agent,再启动第一个Agent
bin/flume-ng agent --name a1 --conf conf-kafka-to-hdfs --conf-file conf-kafka-to-hdfs/kafka-to-hdfs.confbin/flume-ng agent --name a1 --conf conf-file-to-kafka --conf-file conf-file-to-kafka/file-to-kafka.conf
模拟产生日志数据,
cd /data/log/echo hello world >> /data/log/test.log
标准输出重定向,会覆盖掉之前的内容
标准输出重定向,追加

到HDFS上查看数据,验证结果:
此时Flume可以通过tail -F命令实时监控文件中的新增数据,发现有新数据就写入kafka,然后kafka后面的flume落盘程序,以及kafka后面的实时计算程序就可以使用这份数据了。

若有收获,就点个赞吧
0 人点赞
