创建RDD的三种方式
RDD是Spark编程的核心,在进行Spark编程时,首要任务是创建一个初始的RDD
这样就相当于设置了Spark应用程序的输入源数据
然后在创建了初始的RDD之后,才可以通过Spark 提供的一些高阶函数,对这个RDD进行操作,来获取其它的RDD
Spark提供三种创建RDD方式:集合、本地文件、HDFS文件
- 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造一些测试数据,来测试后面的spark应用程序的流程。
- 使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件
- 使用HDFS文件创建RDD,是最常用的生产环境的处理方式,主要可以针对HDFS上存储的数据,进行离线批处理操作。
集合(parallelize)
通过SparkContext的parallelize()方法将集合转为RDD
调用parallelize()时,有一个重要的参数可以指定,就是将集合切分成多少个partition。Spark会为每一个partition运行一个task来进行处理。
Spark默认会根据集群的配置来设置partition的数量。可以通过parallelize()方法的二个参数,来设置RDD的partition数量,例如:parallelize(arr, 5)
案例:集合所有元素求和
scala代码
object CreateRddByArrayScala {def main(args: Array[String]): Unit = {//创建SparkContextval conf = new SparkConf()conf.setAppName("CreateRddByArrayScala")conf.setMaster("local")val sc = new SparkContext(conf)//创建集合val arr = Array(1, 2, 3, 4, 5)//基于集合创建RDDval rdd = sc.parallelize(arr)//对集合中的数据求和val sum = rdd.reduce(_ + _)//-->在driver执行println(sum)//停止SparkContextsc.stop()}}
运行结果:
java代码
public class CreateRddByArrayJava {
public static void main(String[] args) {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("CreateRddByArrayJava");
conf.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//创建集合
List<Integer> arr = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(arr);
Integer sum = rdd.reduce((Function2<Integer, Integer, Integer>) (i1, i2) -> i1 + i2);
System.out.println(sum);
sc.stop();
}
}
本地文件和HDFS文件(textFile)
通过SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD,RDD中的每个元素就是文件中的一行文本内容
textFile()方法支持针对目录、压缩文件以及通配符创建RDD
Spark默认会为HDFS文件的每一个Block创建一个partition,也可以通过textFile()的第二个参数手动设置分区数量,只能比Block数量多,不能比Block数量少
案例:求HDFS文本的总长度 hello you
hello me
scala代码
object CreateRddByFileScala {
def main(args: Array[String]): Unit = {
//创建SparkContext
val conf = new SparkConf()
conf.setAppName("CreateRddByFileScala")
conf.setMaster("local")
val sc = new SparkContext(conf)
//读取文件数据,可以在textFile中指定生成的RDD的分区数量,默认等于block块数量
val path = "hdfs://bigdata1:9000/test/hello.txt"
val rdd = sc.textFile(path)
//获取每一行数据的长度,计算文件内数据的总长度
val length = rdd.map(_.length).reduce(_ + _)
println(length)
sc.stop()
}
}
运行结果
java 代码
public class CreateRddByFileJava {
public static void main(String[] args) {
//创建JavaSparkContext
SparkConf conf = new SparkConf();
conf.setAppName("CreateRddByArrayJava")
.setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
String path = "D:\\test\\hello.txt";
path = "hdfs://bigdata1:9000/test/hello.txt";
JavaRDD<String> rdd = sc.textFile(path, 2);
//获取每一行数据的长度
JavaRDD<Integer> lengthRDD = rdd.map((Function<String, Integer>) line -> line.length());
//计算文件内数据的总长度
Integer length = lengthRDD.reduce((Function2<Integer, Integer, Integer>) (i1, i2) -> i1 + i2);
System.out.println(length);
sc.stop();
}
}
Transformation和Action
Spark对RDD的操作可以整体分为两类:Transformation和Action
不管是Transformation里面的操作还是Action里面的操作,我们一般会把它们称之为算子,例如:map算子、reduce算子
Transformation(转换,lazy)
可以翻译为转换,表示是针对RDD中数据的转换操作,主要会针对已有的RDD创建一个新的RDD:常见的有map、flatMap、filter等等
Transformation的特性:lazy
如果一个spark任务中只定义了transformation算子,那么即使你执行这个任务,任务中的算子也不会执行。
也就是说,transformation是不会触发spark任务的执行,它们只是记录了对RDD所做的操作,不会执行。只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。
Spark通过lazy这种特性,来进行底层的spark任务执行的优化,避免产生过多中间结果。
Action(执行)
可以翻译为执行,表示是触发任务执行的操作,主要对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并且还可以把结果返回给Driver程序
Action的特性:执行Action操作才会触发一个Spark 任务的运行,从而触发这个Action之前所有的Transformation的执行
以我们的WordCount代码为例:
//第一步:创建SparkContext
val conf = new SparkConf()
conf.setAppName("WordCountScala")//设置任务名称
//.setMaster("local")//local表示在本地执行
val sc = new SparkContext(conf)
//第二步:加载数据
var path = "D:\\hello.txt"
if(args.length==1){
path = args(0)
}
//这里通过textFile()方法,针对外部文件创建了一个RDD,linesRDD,实际上,程序执行到这里为止,hello.txt文件的数据是不会被加载到内存中的。linesRDD只是代表了一个指向hello.txt文件的引用
val linesRDD = sc.textFile(path)
//第三步:对数据进行切割,把一行数据切分成一个一个的单词
//这里通过flatMap算子对linesRDD进行了转换操作,把每一行数据中的单词切开,获取了一个转换后的wordsRDD,但是由于linesRDD目前是没有数据的,现在不会做任何操作,只是进行了逻辑上的定义而已,最终生成的wordsRDD也只是一个逻辑上的RDD,此时里面并没有任何数据
val wordsRDD = linesRDD.flatMap(_.split(" "))
//第四步:迭代words,将每个word转化为(word,1)这种形式
//这个操作和前面分析的flatMap的操作是一样的,最终获取了一个逻辑上的pairRDD,此时里面也是没有任何数据的
val pairRDD = wordsRDD.map((_,1))
//第五步:根据key(其实就是word)进行分组聚合统计
//这个操作也是和前面分析的flatMap操作是一样的,最终获取了一个逻辑上的wordCountRDD,此时里面也是没有任何数据的
val wordCountRDD = pairRDD.reduceByKey(_ + _)
//第六步:将结果打印到控制台
//这行代码执行了一个action操作,foreach,此时会触发之前所有transformation算子的执行,Spark会将这些算子拆分成多个task发送到多个机器上并行执行,这个foreach算子是没有返回值的,所以不会向Driver进程返回数据,如果是reduce操作,则会向Driver进程返回最终的结果数据。
//注意:只有当任务执行到这一行代码的时候任务才会真正开始执行计算,如果任务中没有这一行代码,前面的所有算子是不会执行的
wordCountRDD.foreach(wordCount=>println(wordCount._1+"--"+wordCount._2))
//第七步:停止SparkContext
sc.stop()
常用Transformation算子
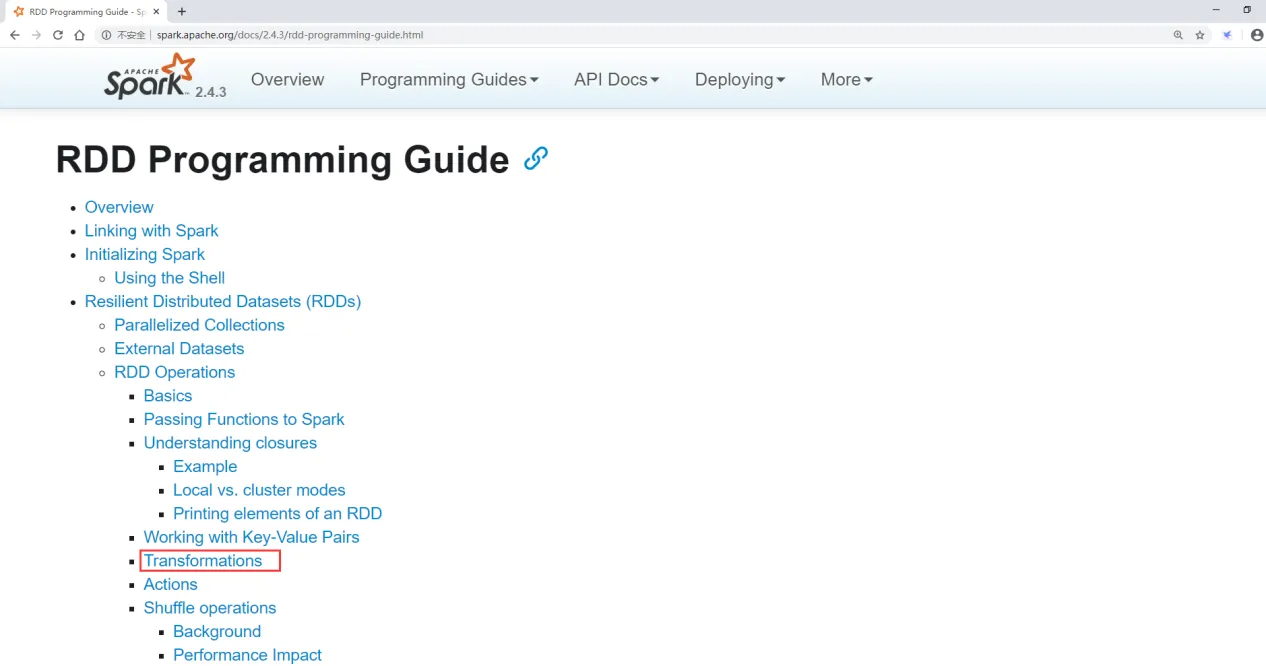
先来看一下官方文档,进入2.4.3的文档界面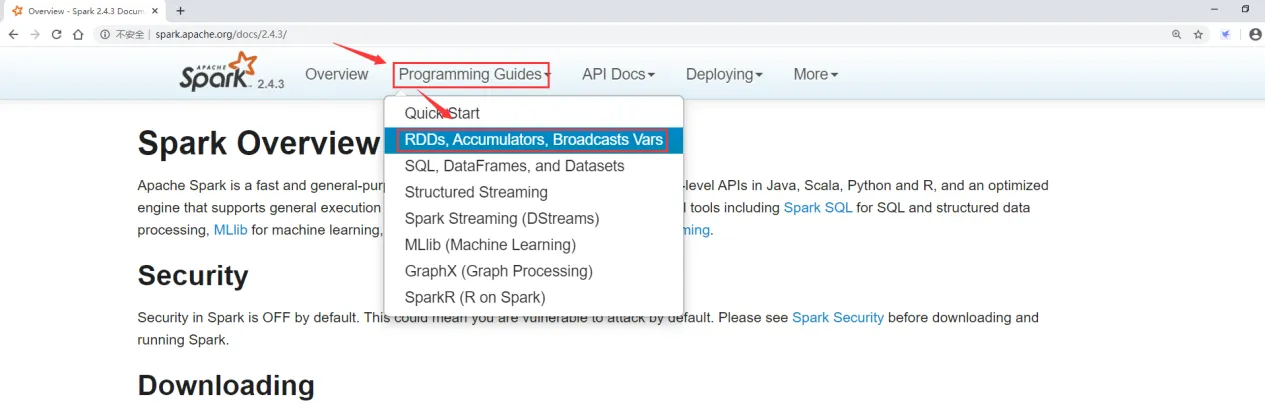
这里面列出了Spark支持的所有的transformation算子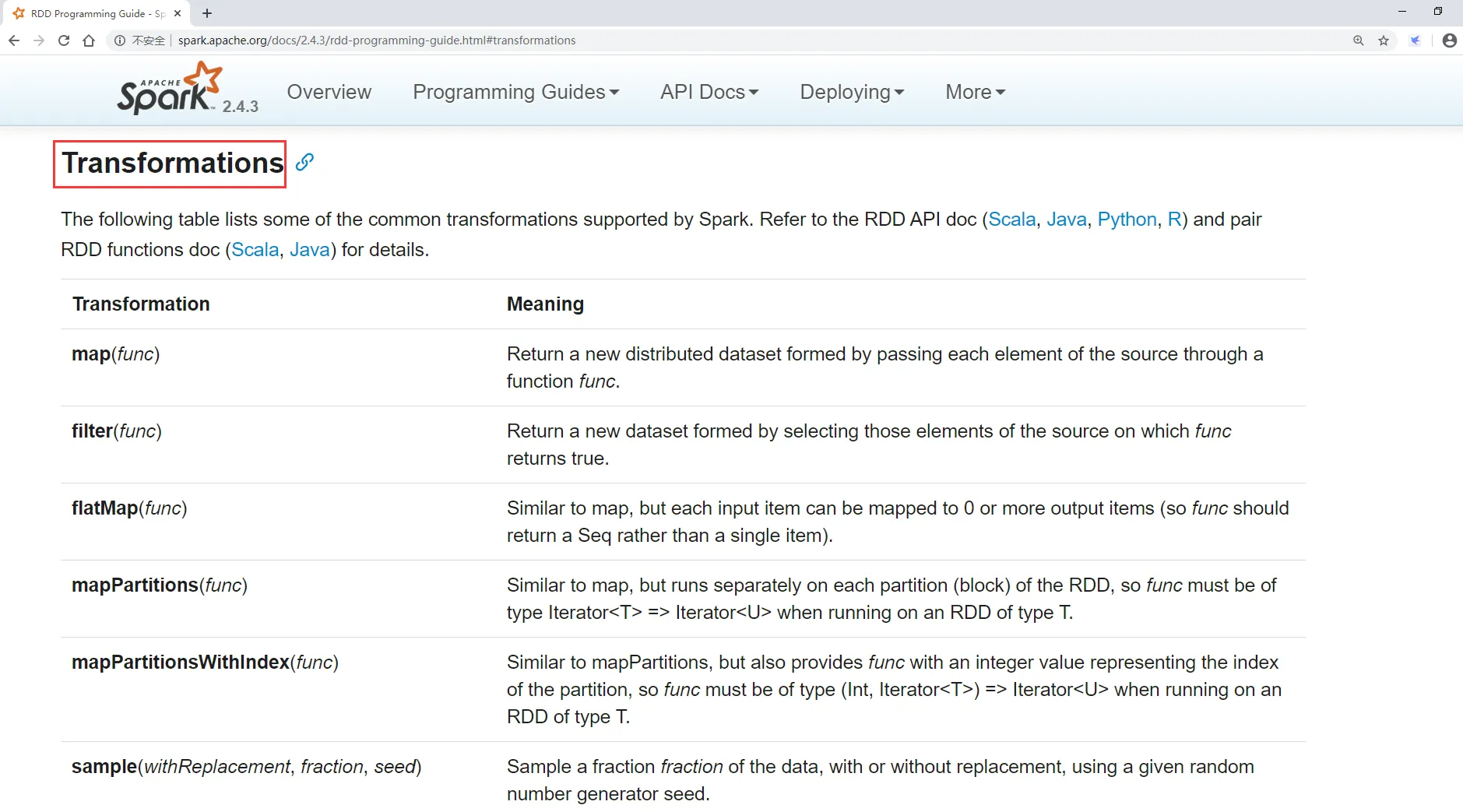
| 算子 | 介绍 |
|---|---|
| map | 将RDD中的每个元素进行处理,一进一出 |
| filter | 对RDD中每个元素进行判断,返回true则保留 |
| flatMap | 与map类似,但是每个元素都可以返回一个或多个新元素 |
| groupByKey | 根据key进行分组,每个key对应一个Iterable |
| reduceByKey | 对每个相同key对应的value进行reduce操作 |
| sortByKey | 对每个相同key对应的value进行排序操作(全局排序) |
| join | 对两个包含 |
| distinct | 对RDD中的元素进行全局去重 |
map
将RDD中的每个元素进行处理,一进一出
对集合中每个元素乘以2
def mapOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
rdd.map(_ * 2).foreach(println(_))
}

filter
对RDD中每个元素进行判断,返回true则保留
过滤出集合中的偶数
def filterOP(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
rdd.filter(_ % 2 == 0).foreach(println(_))
}
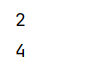
flatMap
与map类似,但是每个元素都可以返回一个或多个新元素
将行拆分为单词
def flatMapOP(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array("hello world", "hello scala"))
rdd.flatMap(_.split(" ")).foreach(println(_))
}

groupByKey
根据key进行分组,每个key对应一个Iterable
对每个大区的主播进行分组
def groupByKeyOp(sc: SparkContext): Unit = {
//使用Tuple类型存放主播的信息,格式:(主播id,地区),在这里可以把这个tuple认为是一个key-value
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN"), (150004, "IN")))
//需要使用map对tuple中的数据进行位置互换,因为我们需要把大区作为key进行分组操作,map算子之后的格式数据格式是("US",150001)
//注意:在使用类似于groupByKey这种基于key的算子的时候,需要提前把RDD中的数据组装成tuple2这种形式
rdd.map(tup => (tup._2, tup._1)).groupByKey().foreach(tup => {
//获取大区信息
val area = tup._1
print(area + ":")
val it = tup._2
//获取同一个大区下面的所有用户id
for (uid <- it) {
print(uid + " ")
}
println()
})
}

如果tuple中的数据列数超过了2列怎么办?比如多了主播性别
def groupByKeyOp2(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, "US", "male"), (150002, "CN", "female"), (150003, "CN", "male"), (150004, "IN", "female")))
//把需要作为key的那一列作为tuple2的第一列,剩下的可以再使用一个tuple2包装一下,格式:("US",(150001,"male"))
rdd.map(tup => (tup._2, (tup._1, tup._3))).groupByKey().foreach(tup => {
val area = tup._1
print(area + ":")
val it = tup._2
for (elem <- it) {
//elem也是一个tuple,格式 :(150001,"male")
print(elem + " ")
}
println()
})
}
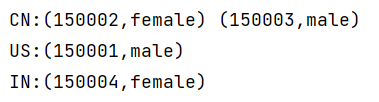
reduceByKey
对每个相同key对应的value进行reduce操作
统计每个大区的主播数量
def reduceByKeyOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN"), (150004, "IN")))
//由于这个需求只需要使用到大区信息,所以在map操作的时候只保留大区信息即可
rdd.map(tup => (tup._2, 1)).reduceByKey(_ + _).foreach(tup => {
println(tup._1 + ":" + tup._2)
})
}

sortByKey和sortBy
对每个相同key对应的value进行排序操作(全局排序)
对主播的音浪收入排序
def sortByKey(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, 400), (150002, 200), (150003, 300), (150004, 100)))
//由于需要对音浪收入进行排序,所以需要把音浪收入作为key,在这里要进行位置和互换
//rdd.map(tup => (tup._2, tup._1)).sortByKey().foreach(println(_))
//sortByKey默认是正序,第一个参数为true,想要倒序需要把这个参数设置为false
//rdd.map(tup => (tup._2, tup._1)).sortByKey(false).foreach(println(_))
//sortBy的使用:可以指定排序字段,比较灵活
rdd.sortBy(_._2, false).foreach(println(_))
}


join
对两个包含
打印每个主播的大区信息和音浪收入
def joinOp(sc: SparkContext): Unit = {
//主播地区信息
val rdd1 = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN"), (150004, "IN")))
//主播收入信息
val rdd2 = sc.parallelize(Array((150001, 400), (150002, 200), (150003, 300), (150004, 100)))
val joinRdd = rdd1.join(rdd2)
//joinRdd.foreach(println(_)) //join后rdd的格式:(150001,(US,400))
joinRdd.foreach(tup => {
val uid = tup._1
val tupleData = tup._2
val area = tupleData._1
val money = tupleData._2
println("uid=" + uid + " area=" + area + " money=" + money)
})
}

distinct
对RDD中的元素进行全局去重
统计当天开播的大区信息
def distinctOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array((150001, "US"), (150002, "CN"), (150003, "CN"), (150004, "IN")))
rdd.map(_._2).distinct().foreach(println(_))
}

常用Action算子
reduce
将RDD中的所有元素进行聚合操作
def reduceOP(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
val sum = rdd.reduce(_ + _)
println(sum)
}
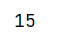
collect
将RDD中所有元素获取到本地客户端(Driver)
注意:如果RDD中数据量过大,不建议使用collect,因为最终的数据会返回给Driver进程所在的节点 如果想要获取几条数据,查看一下数据格式,可以使用take(n)
def collectOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
//collect返回的是一个Array数组
rdd.collect().foreach(println(_))
}
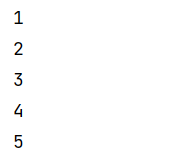
take(n)
获取RDD中前n个元素
def takeOP(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
//从RDD中获取前3个元素
rdd.take(3).foreach(println(_))
}
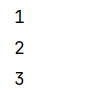
count
获取RDD中元素总数
def countOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
val res = rdd.count()
println(res)
}
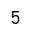
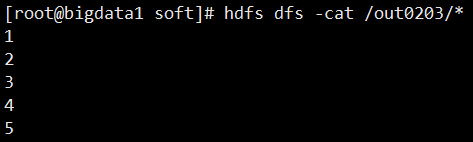
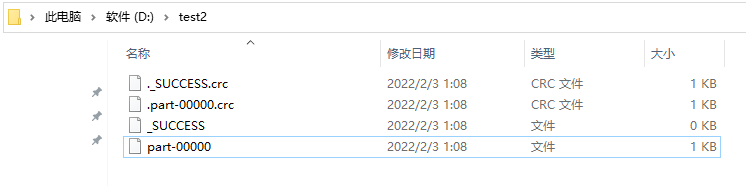
saveAsTextFile
将RDD中元素保存到文件中,对每个元素调用toString
def saveAsTextFileOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
//指定HDFS的路径信息即可,需要指定一个不存在的目录
rdd.saveAsTextFile("hdfs://bigdata1:9000/out0203")
//也可以存到本地文件
//rdd.saveAsTextFile("D:\\test2")
}
countByKey
对每个key对应的值进行count计数
统计相同的key出现多少次
def countByKeyOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(("A", 1001), ("B", 1002), ("A", 1003), ("C", 1004)))
//返回的是一个map类型的数据
val res = rdd.countByKey()
for ((k, v) <- res) {
println(k + "," + v)
}
}

foreach
遍历RDD中的每个元素
注意:foreach不仅限于执行println操作,这个只是在测试的时候使用的 实际工作中如果需要把计算的结果保存到第三方的存储介质中,就需要使用foreach,在里面实现具体向外部输出数据的代码
def foreachOp(sc: SparkContext): Unit = {
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
rdd.foreach(println(_))
}

若有收获,就点个赞吧
0 人点赞
