Standalone
Flink ON YARN
Flink ON YARN模式就是使用客户端的方式,直接向Hadoop集群提交任务即可。不需要单独启动Flink进程。
注意:
1:Flink ON YARN 模式依赖Hadoop 2.4.1及以上版本
2:Flink ON YARN支持两种使用方式
Flink ON YARN两种使用方式
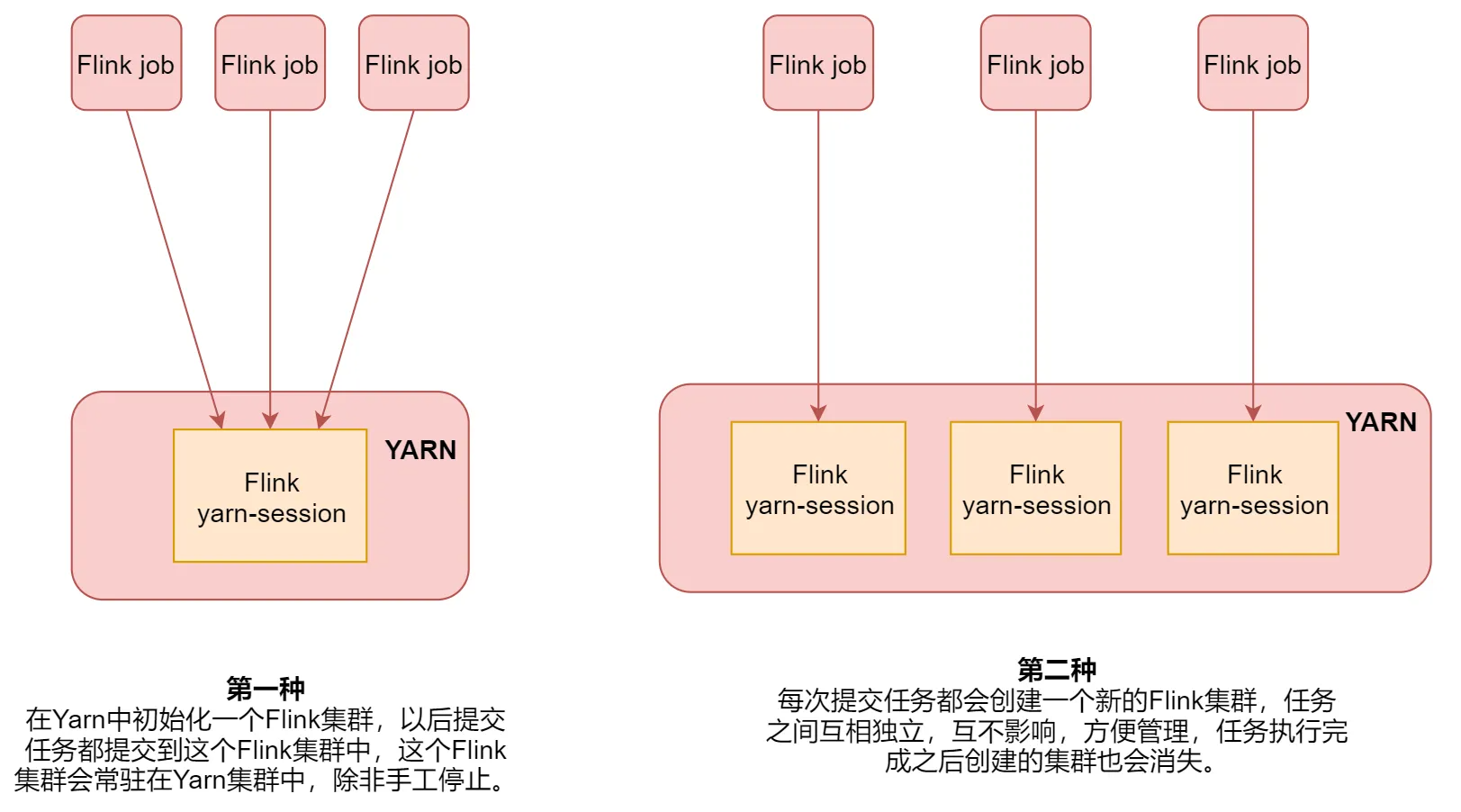
注意: 第一种适合运行规模小,短时间运行的作业。 第二种适合长时间运行的作业。推荐使用
第一种方式(公用集群)
下面来看一下第一种方式
第一步:在集群中初始化一个长时间运行的Flink集群
使用yarn-session.sh脚本
第二步:使用flink run命令向Flink集群中提交任务
注意:使用flink on yarn需要确保hadoop集群已经启动成功
下面来具体演示一下
首先在bigdata04机器上安装一个Flink客户端,其实就是把Flink的安装包上传上去解压即可,不需要启动
cd /data/soft/tar -zxvf flink-1.11.1-bin-scala_2.12.tgz
接下来在执行yarn-session.sh脚本之前我们需要先设置HADOOP_CLASSPATH这个环境变量,否则,执行yarn-session.sh是会报错的,提示找不到hadoop的一些依赖。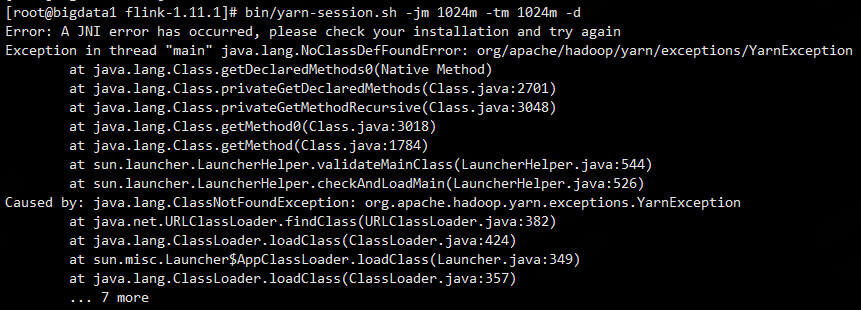
在/etc/profile中配置HADOOP_CLASSPATH
vim /etc/profile...export JAVA_HOME=/data/soft/jdk1.8export HADOOP_HOME=/data/soft/hadoop-3.2.0export HIVE_HOME=/data/soft/apache-hive-3.1.2-binexport SPARK_HOME=/data/soft/spark-2.4.3-bin-hadoop2.7export SQOOP_HOME=/data/soft/sqoop-1.4.7.bin__hadoop-2.6.0export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HOME/bin:$SQOOP_HOME/bin:$PATH...source /etc/profile
接下来,使用yarn-session.sh在YARN中创建一个长时间运行的Flink集群
cd flink-1.11.1bin/yarn-session.sh -jm 1024m -tm 1024m -d
-jm 主节点内存 -tm 从节点内存 -d 后台执行


接下来向这个Flink集群中提交任务,此时使用Flink中的内置案例
[root@bigdata1 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar

注意:这个时候我们使用flink run的时候,它会默认找这个文件,然后根据这个文件找到刚才我们创建的那个永久的Flink集群,这个文件里面保存的就是刚才启动的那个Flink集群在YARN中对应的applicationid。

[root@bigdata1 bin]# more /tmp/.yarn-properties-root#Generated YARN properties file#Thu Feb 24 14:45:10 CST 2022dynamicPropertiesString=applicationID=application_1642475474501_0367
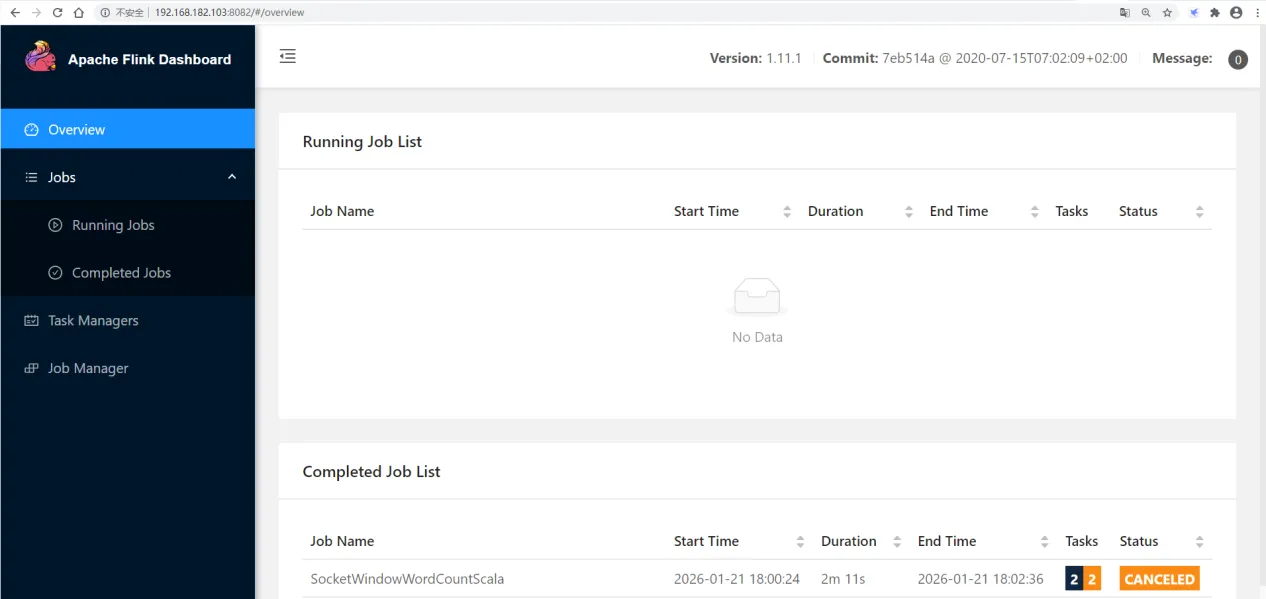
任务提交上去执行完成之后,再来看flink的web界面,发现这里面有一个已经执行结束的任务了。
注意:这个任务在执行的时候,会动态申请一些资源执行任务,任务执行完毕之后,对应的资源会自动释放掉。
最后把这个Flink集群停掉,使用yarn的kill命令
yarn application -kill application_1642475474501_0367

针对yarn-session命令,它后面还支持一些其它参数,可以在后面传一个-help参数
[root@bigdata1 flink-1.11.1]# bin/yarn-session.sh -helpUsage:Optional-at,--applicationType <arg> Set a custom application type for the application on YARN-D <property=value> use value for given property-d,--detached If present, runs the job in detached mode-h,--help Help for the Yarn session CLI.-id,--applicationId <arg> Attach to running YARN session-j,--jar <arg> Path to Flink jar file-jm,--jobManagerMemory <arg> Memory for JobManager Container with optional unit (default: MB)-m,--jobmanager <arg> Address of the JobManager to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration.-nl,--nodeLabel <arg> Specify YARN node label for the YARN application-nm,--name <arg> Set a custom name for the application on YARN-q,--query Display available YARN resources (memory, cores)-qu,--queue <arg> Specify YARN queue.-s,--slots <arg> Number of slots per TaskManager-t,--ship <arg> Ship files in the specified directory (t for transfer)-tm,--taskManagerMemory <arg> Memory per TaskManager Container with optional unit (default: MB)-yd,--yarndetached If present, runs the job in detached mode (deprecated; use non-YARN specific option instead)-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-paths for high availability mode
在这我对一些常见的命令进行了整理,添加了中文注释
注意:这里的-j 是指定Flink任务的jar包,此参数可以省略不写也可以
第二种方式(独立集群,推荐)
flink run -m yarn-cluster (创建Flink集群+提交任务)
使用flink run直接创建一个临时的Flink集群,并且提交任务
此时这里面的参数前面加上了一个y参数
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar
提交上去之后,会先创建一个Flink集群,然后在这个Flink集群中执行任务。
针对Flink命令的一些用法汇总
Flink ON YARN的好处
1:提高大数据集群机器的利用率
2:一套集群,可以执行MR任务,Spark任务,Flink任务等
向集群中提交Flink任务
第一步:在pom.xml中添加打包配置
<build><plugins><!-- 编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><!-- scala编译插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.1.6</version><configuration><scalaCompatVersion>2.12</scalaCompatVersion><scalaVersion>2.12.11</scalaVersion><encoding>UTF-8</encoding></configuration><executions><execution><id>compile-scala</id><phase>compile</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>test-compile-scala</id><phase>test-compile</phase><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><!-- 打jar包插件(会包含所有依赖) --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.6</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><!-- 可以设置jar包的入口类(可选) --><mainClass></mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
注意:需要将Flink和Hadoop的相关依赖的score属性设置为provided,这些依赖不需要打进jar包里面。
第二步:生成jar包:mvn clean package -DskipTests
第三步:将flink-study-1.0-SNAPSHOT-jar-with-dependencies.jar上传到/data/soft/flink-1.11.1目录中(上传到哪个目录都可以)
第四步:提交Flink任务
注意:提交任务之前,先开启socket
[root@bigdata1 ~]# nc -l 9002
/data/soft/flink-1.11.1
bin/flink run -m yarn-cluster -c com.example.scala.stream.SocketWindowWordCountScala -yjm 1024 -ytm 1024 flink-study-1.0-SNAPSHOT-jar-with-dependencies.jar
此时到yarn上面可以看到确实新增了一个任务,点击ApplicationMaster进去可以看到flink的web界面
通过socket输入一串内容
[root@bigdata1 ~]# nc -l 9002
hello you let go hello me
然后到flink的web界面查看日志
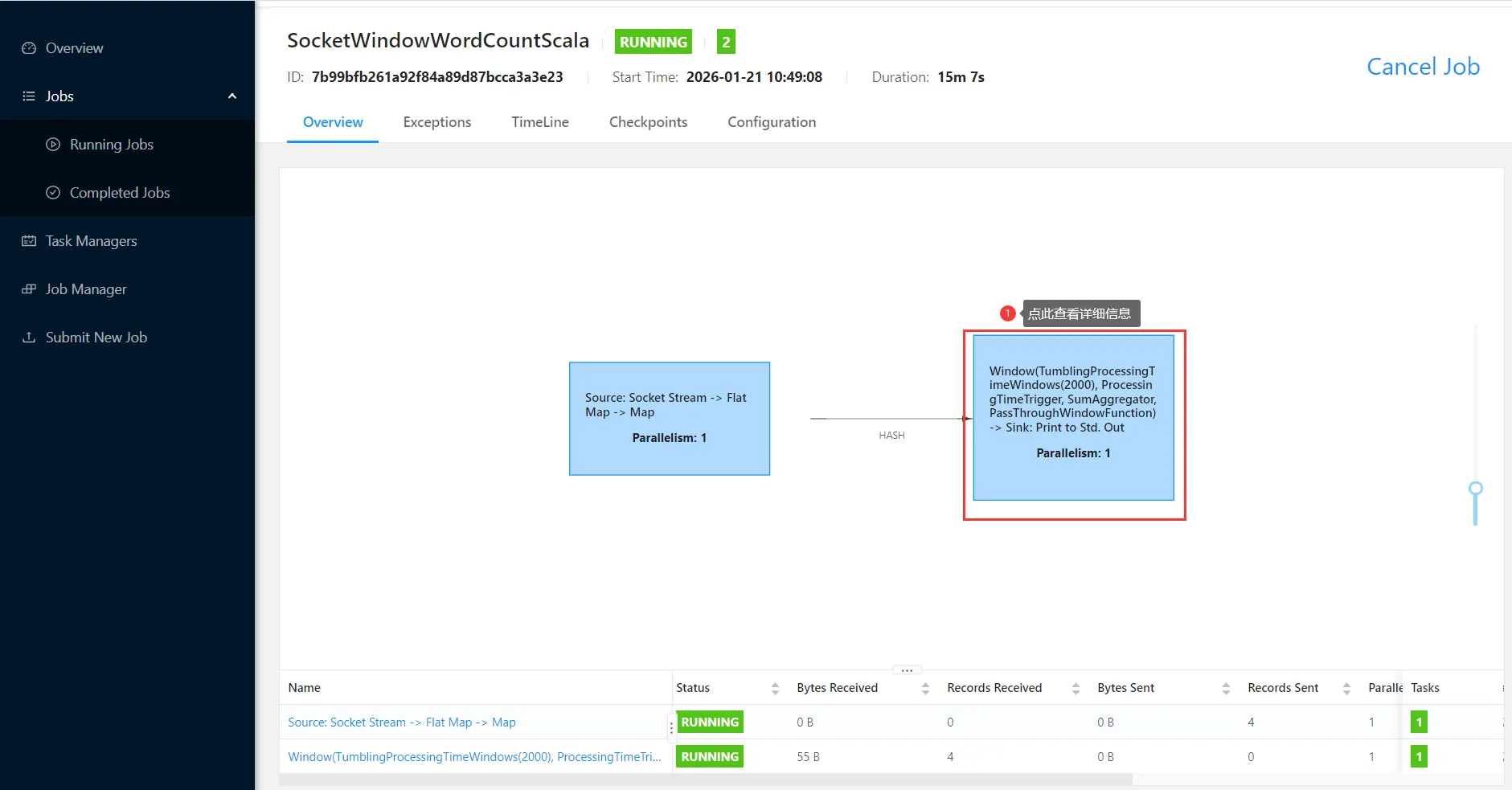
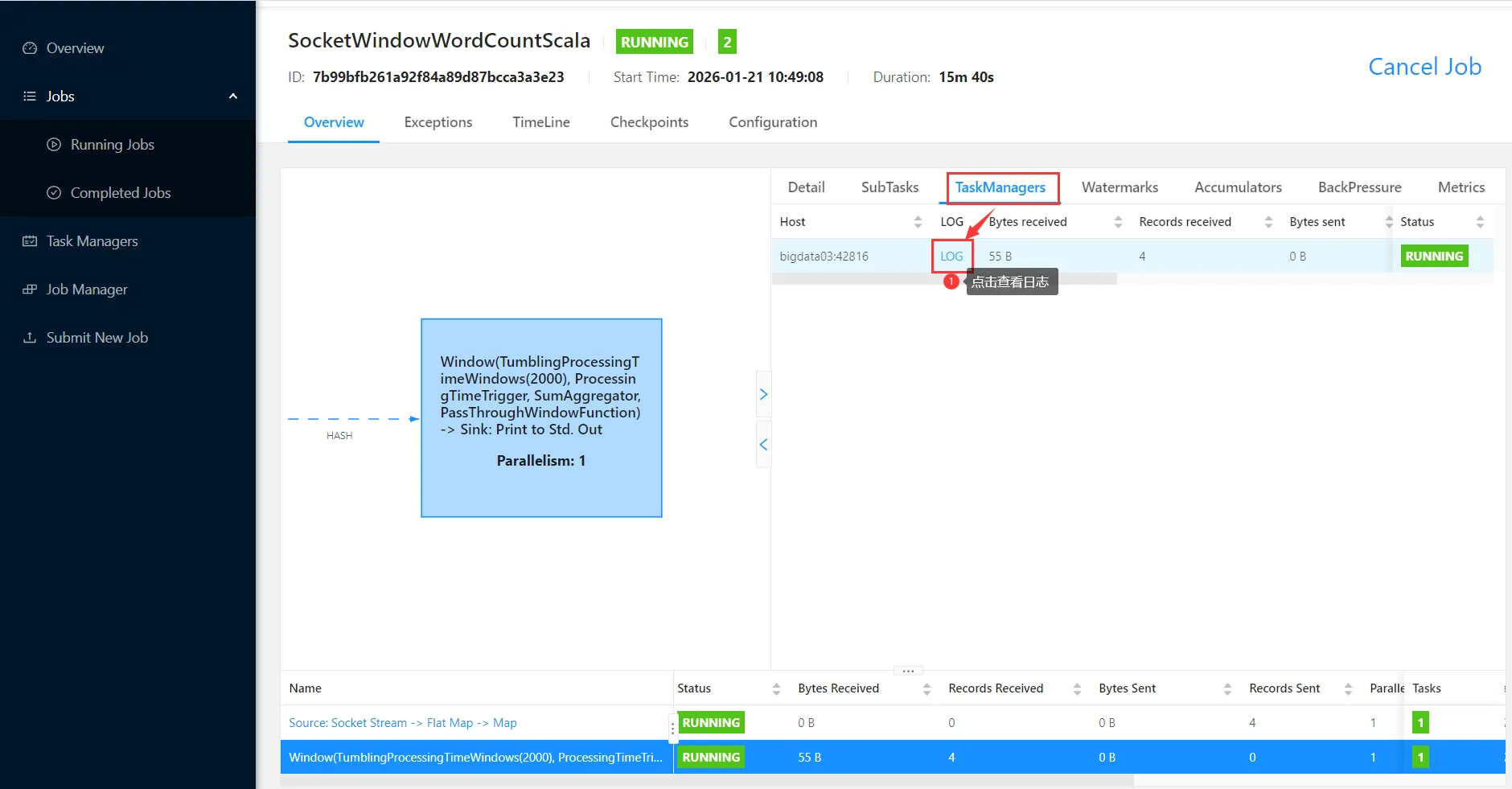
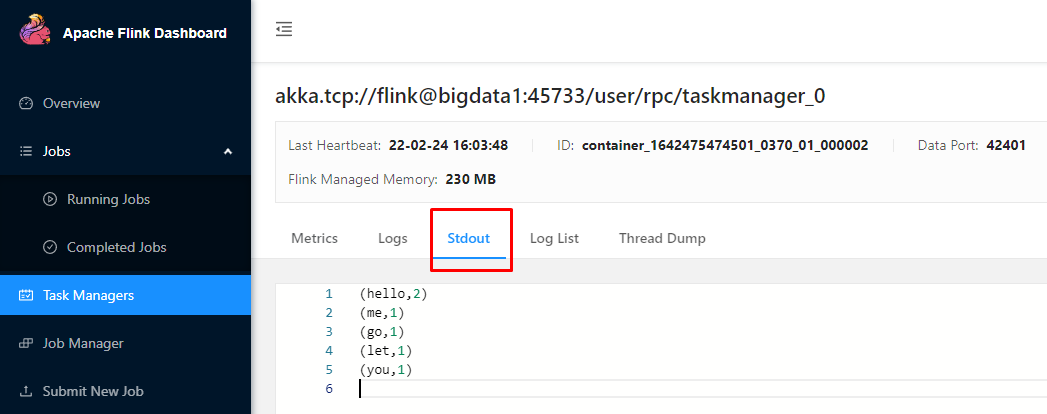
接下来我们希望把这个任务停掉,因为这个任务是一个流处理的任务,提交成功之后,它会一直运行。
注意:此时如果我们使用ctrl+c关掉之前提交任务的那个进程,这里的flink任务是不会有任何影响的,可以一直运行,因为flink任务已经提交到hadoop集群里面了。
此时如果想要停止Flink任务,有两种方式
1:停止yarn中任务
yarn application -kill application_1642475474501_0370
2:停止flink任务
可以在界面上点击这个按钮,或者在命令行中执行flink cancel停止都可以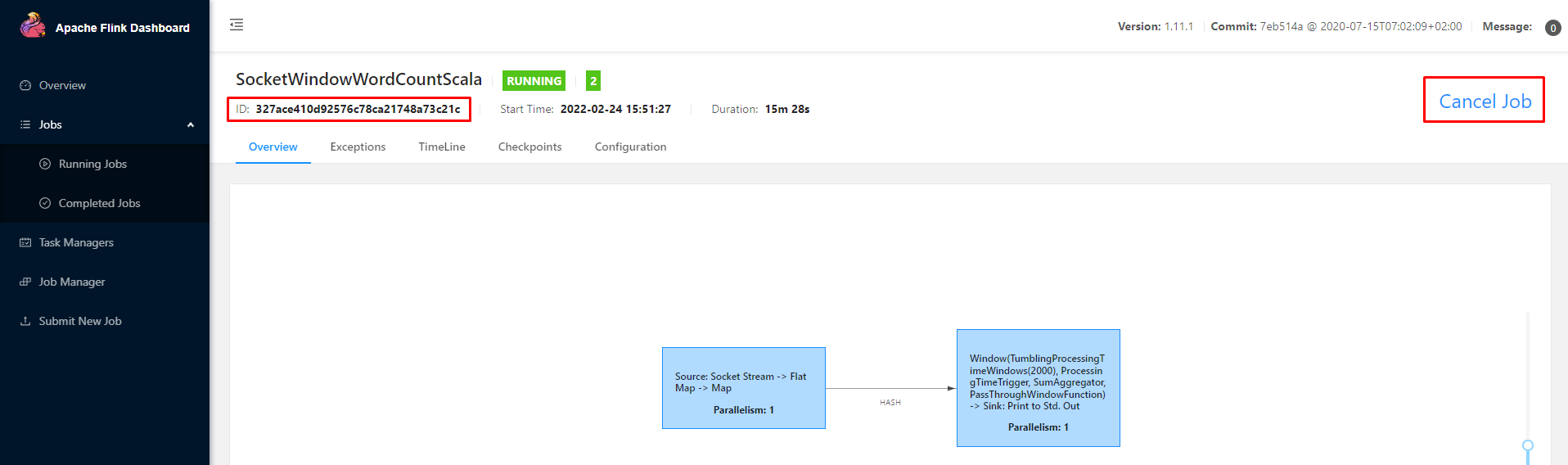
或者
#指定application id和flink id
bin/flink cancel -yid application_1642475474501_0370 327ace410d92576c78ca21748a73c21c
这个flink任务停止之后,对应的那个yarn-session(Flink集群)也就停止了。
Flink HistoryServer
注意:此时flink任务停止之后就无法再查看flink的web界面了,如果想看查看历史任务的执行信息就看不了了,怎么办呢?
之前在分享spark的时候其实也遇到过这种问题,当时是通过启动spark的historyserver进程解决的。
flink也有historyserver进程,也是可以解决这个问题的。 historyserver进程可以在任意一台机器上启动,在这我们选择在bigdata04机器上启动
在启动historyserver进程之前,需要先修改bigdata04中的flink-conf.yaml配置文件
vi conf/flink-conf.yaml
...
jobmanager.archive.fs.dir: hdfs://bigdata1:9000/completed-jobs/
historyserver.web.address: 192.168.1.21
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata1:9000/completed-jobs/
historyserver.archive.fs.refresh-interval: 10000
...
然后启动flink的historyserver进程
bin/historyserver.sh start
验证进程
[root@bigdata1 flink-1.11.1]# jps -l
98886 org.apache.flink.runtime.webmonitor.history.HistoryServer
注意:hadoop集群中的JobHistoryServer进程也需要启动
在bigdata01、bigdata02、bigdata03节点上启动hadoop的historyserver进程
[root@bigdata01 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata02 hadoop-3.2.0]# bin/mapred --daemon start historyserver
[root@bigdata03 hadoop-3.2.0]# bin/mapred --daemon start historyserver
此时Flink任务停止之后也是可以访问flink的web界面的。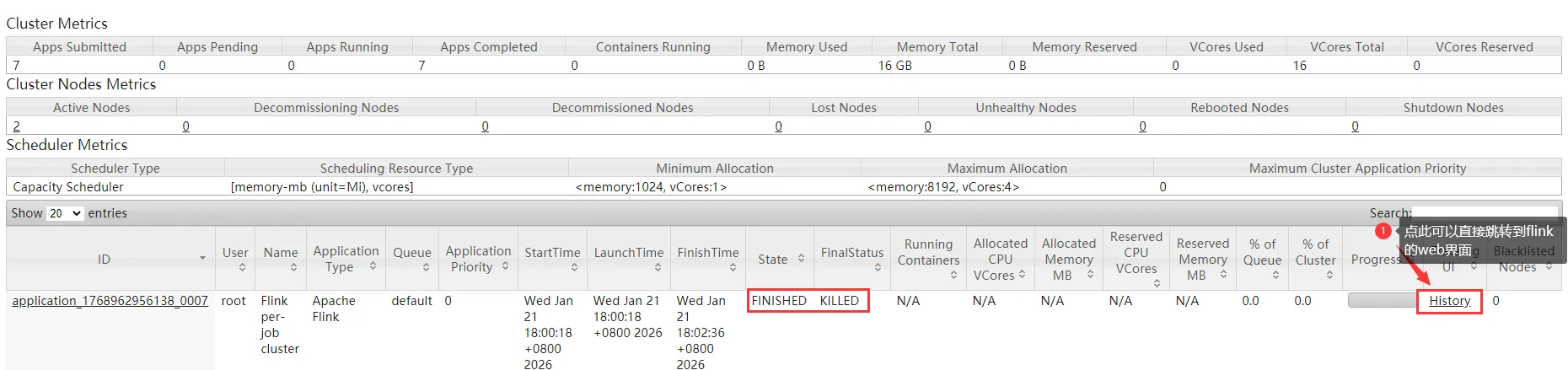

若有收获,就点个赞吧
0 人点赞
