在Mysql中没有表类型这个概念,因为它就只有一种表。
但是Hive中是有多种表类型的,我们可以分为四种,内部表、外部表、分区表、桶表
内部表
内部表是hive默认表类型,也叫管理表(MANAGED TABLE),表数据默认存储在/user/hive/warehouse目录中
在加载数据的过程中,实际数据会被复制到/user/hive/warehouse目录中
删除表时,表的数据和元数据将会被同时删除
外部表(external ★)
建表语句中包含external 的表叫外部表
外部表在加载数据的时候,实际数据并不会移动到warehouse目录中,只是与外部数据建立一个链接(映射关系),数据只是表对hdfs上的某一个目录的引用而已
当删除一个外部表时,数据依然是存在的。仅删除表和数据之间的引用关系,所以这种表是安全的,就算是误删表,数据还是存在的
示例
创建外部表external_table
create external table external_table(key string) location '/data/external';
查看HDFS

- 加载数据
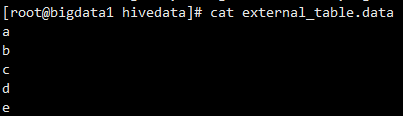
load data local inpath '/data/soft/hivedata/external_table.data' into table external_table;
- 查看external_table表和HDFS


删除表,可以发现文件还在
hive> drop table external_table; OK Time taken: 0.221 seconds hive> show tables; OK stu stu2 stu3 student t1 t2 t3 t3_new Time taken: 0.087 seconds, Fetched: 8 row(s)
-
内部表和外部表的相互转化
```sql — 内部表转外部表 alter table tblName set tblproperties (‘external’=’true’);
— 外部表转内部表 alter table tblName set tblproperties (‘external’=’false’);
<a name="zZQ6j"></a>
## 内部表和外部表的对比
前面使用内部表的过程:将一个文件加载到warehouse目录中,两份的内容其实是一样的。<br />使用外部表就不用复制一份一样的数据。<br /><br />在实际工作中,我们在 hive 中创建的表 95% 以上的都是外部表,先通过 flume 采集数据,把数据上传到 hdfs 中,然后在 hive 中创建外部表和 hdfs 上的数据绑定关系,就可以使用 sql 查询数据了,所以连 load 数据那一步都可以省略了,因为是先有数据,才创建的表<br />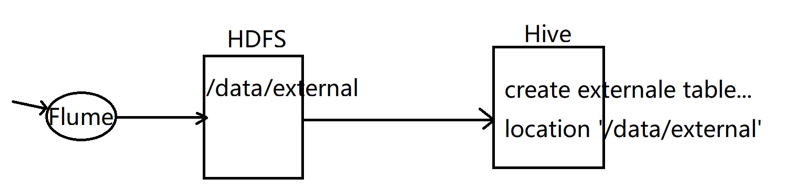
<a name="yns3x"></a>
# 分区表(partitioned by)
> 假设web服务器每天产生一个日志文件,flume会把日志文件采集到HDFS上,每天的数据存储在一个目录里
> 格式类似:
> hdfs:
> /data/logs/20200101
> /data/logs/20200102
> /data/logs/20200103
分区可以理解为分类,通过分区把不同类型的数据放到不同目录中,<br />分区的标准就是指定分区字段,分区字段可以有一个或多个。<br />分区的意义在于优化查询,查询时尽量利用分区字段,如果不使用分区字段,就会全表扫描,最典型的一个场景就是把天作为分区字段,查询的时候指定天。
<a name="JHews"></a>
## 内部分区表
<a name="Q8qGH"></a>
### 示例一:一个分区字段
数据<br />
- 创建表
```sql
create table partition_1
(
id int,
name string
) partitioned by (dt string)
row format delimited
fields terminated by '\t';
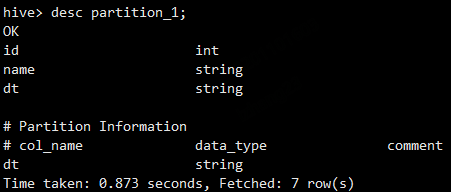
- 查看表信息
加载数据并指定分区
load data local inpath '/data/soft/hivedata/partition_1.data' into table partition_1 partition(dt='20200101');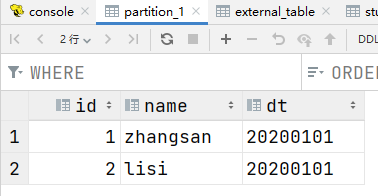
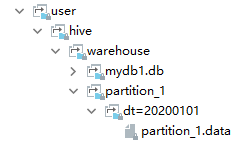
创建分区,不加数据:
alter table partition_1 add partition(dt='20200102');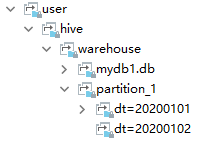
此时,20200102分区可以通过load或者hdfs dfs -put加载数据查看partition_1表的分区
show partitions partition_1;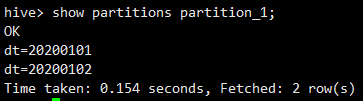
删除表的分区
alter table partition_1 drop partition(dt='20200102');示例二:多个分区字段
数据
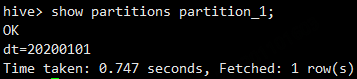
创建表
create table partition_2 ( id int, name string ) partitioned by (year int,school string) row format delimited fields terminated by '\t';查看表信息
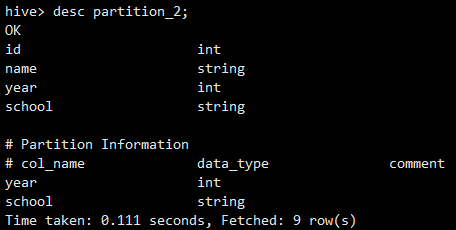
- 加载数据并指定分区 ```sql load data local inpath ‘/data/soft/hivedata/partition_2.data’ into table partition_2 partition(year=2020,school=’jsz’);
load data local inpath ‘/data/soft/hivedata/partition_2.data’ into table partition_2 partition(year=2020,school=’english’);
load data local inpath ‘/data/soft/hivedata/partition_2.data’ into table partition_2 partition(year=2019,school=’jsz’);
load data local inpath ‘/data/soft/hivedata/partition_2.data’ into table partition_2 partition(year=2019,school=’english’);
- 查看partition_2表
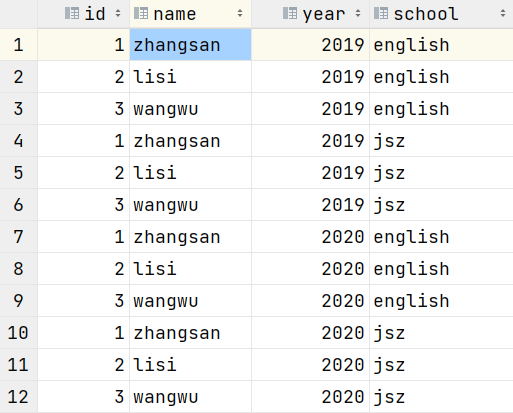
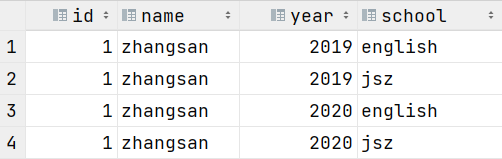
- 查看'zhangsan'的学生信息
```sql
select * from partition_2 where name='zhangsan';
查看2019级,计算机院的学生
select * from partition_2 where year=2019 and school='jsz';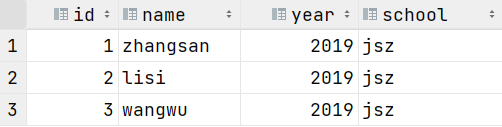
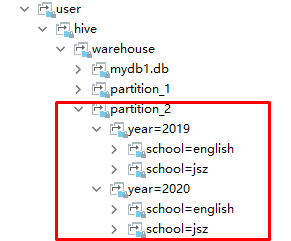
查看HDFS
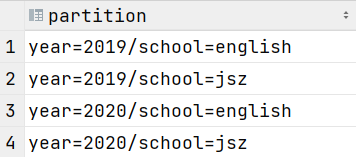
建外部分区表
create external table ex_par ( id int, name string ) partitioned by (dt string) row format delimited fields terminated by '\t' location '/data/ex_par';加载数据
load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partition(dt='20200101');查看ex_par表和HDFS
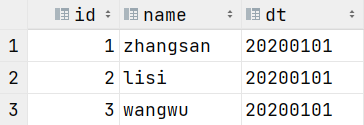
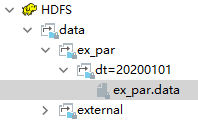
删除分区
20200101alter table ex_par drop partition(dt='20200101');查看数据和分区:都查不到,但是HDFS数据还在(因为是外部表)
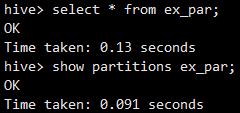
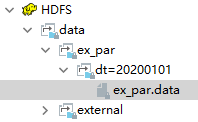
- 再次添加分区并绑定
alter table ex_par add partition(dt='20200101') location '/data/ex_par/dt=20200101';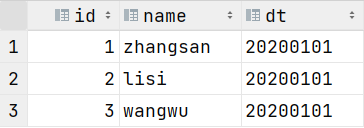
总结

这条命令做了两件事:1、上传数据 2、指定分区load data local inpath '/data/soft/hivedata/ex_par.data' into table ex_par partition(dt='20200101');
等价于: ```shellHDFS创建目录/data/ex_par/dt=20200101
hdfs dfs -mkdir /data/ex_par/dt=20200101
HDFS上传文件ex_par.data到/data/ex_par/dt=20200101目录
hdfs dfs -put /data/soft/hivedata/ex_par.data /data/ex_par/dt=20200101
绑定分区
alter table ex_par add partition(dt=’20200101’) location ‘/data/ex_par/dt=20200101’;
> 实际工作中:
> 先通过 flume 采集数据,把数据上传到 hdfs 中。不需要再load,只要每天定时加分区:`alter table ex_par add partition(dt='20200101') location '/data/ex_par/dt=20200101';`
<a name="xwfcc"></a>
# 桶表(防数据倾斜)
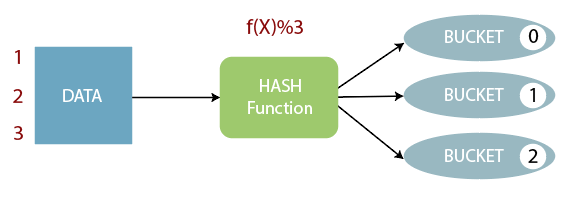<br />桶表是对数据进行哈希取值,然后放到不同文件中存储。物理上每个桶就是表(或分区)里的一个文件。
> 当数据不均衡的时候会用到桶表,比如,针对中国人口主要集中在河南,江苏,山东,广东,四川等地,西藏就三四百万比较少,如果使用分区表,把省份作为分区字段,数据会集中在某几个分区,这样计算的时候会出现数据倾斜的问题,效率会变得较低,这样从源头上解决,就可以采用分桶的概念,相对均匀的存放数据,也就是使用分桶表。
<a name="gNKzc"></a>
## 示例
- 创建桶表
> 这个表的意思是按照id进行分桶,分成4个桶。
```sql
create table bucket_tb
(
id int
) clustered by (id) into 4 buckets;
桶表不能用load data的方式加载数据,而是需要使用其它表中的数据,类似这样的写法:insert into table … select … from …
在插入数据之前需要先设置开启桶操作,不然数据无法分到不同的桶里面,set hive.enforce.bucketing=true;
其实这里的分桶就是设置reduce任务的数量,因为分了多少桶,最终结果就会产生多少个文件,最终结果中文件的数量就和reduce任务的数量是挂钩的,设置完 set hive.enforce.bucketing=true; 可以自动控制reduce的数量从而适配bucket的个数。
- 初始化一个表,用于向桶表中加载数据
原始数据文件是这样的
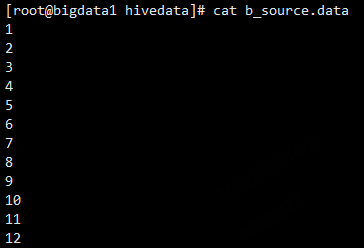
create table b_source(id int);
load data local inpath '/data/soft/hivedata/b_source.data' into table b_source;
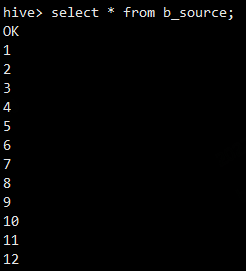
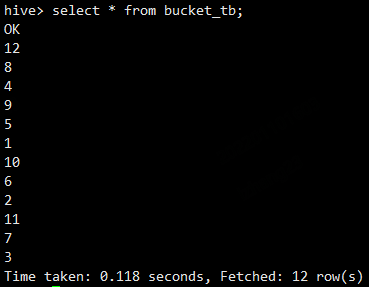
向桶表中加载数据
hive> set hive.enforce.bucketing=true; hive> insert into table bucket_tb select id from b_source;查看分桶后的bucket_tb
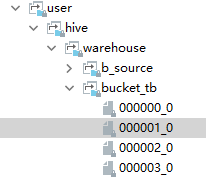
- 查看HDFS:按照我们设置的桶的数量为4,这样在hdfs中会存在4个对应的文件,每个文件的大小是相似的
桶表的作用
1、数据抽样
假如我们使用的是一个大规模的数据集,我们只想去抽取部分数据进行查看.使用bucket表可以变得更加的高效
select * from bucket_tb tablesample(bucket 1 out of 4 on id);
-- tablesample是抽样语句
-- 语法解析:tablesample(bucket x out of y on column)
-- y尽可能是桶表的bucket数的倍数或者因子,而且y必须大于等于x
-- y表示把桶表中的数据随机分为多少桶
-- x表示取出第几桶的数据
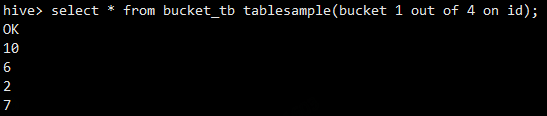
bucket 1 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第1桶的数据
bucket 2 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第2桶的数据
bucket 3 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第3桶的数据
bucket 4 out of 4 on id:根据id对桶表中的数据重新分桶,分成4桶,取出第4桶的数据
2、提高某些查询效率
例如:join 查询,可以避免产生笛卡尔积的操作
select a.id, a.name, b.addr from a join b on a.id=b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id,那么这个操作的时候就不需要再进行全表笛卡尔积了,因为分桶之后相同的规则的id已经在相同的文件里面了,这样a表的每个桶就可以和b表的每个桶直接join,而不用全表join了
视图
hive中,也有视图的概念,视图实际上是一张虚拟表,是对数据的逻辑表示,它的主要作用是为了降低查询的复杂度
使用create view命令来创建一个视图
create view v1 as select t3_new.id,t3_new.stu_name from t3_new;
此时通过show tables也可以查看到这个视图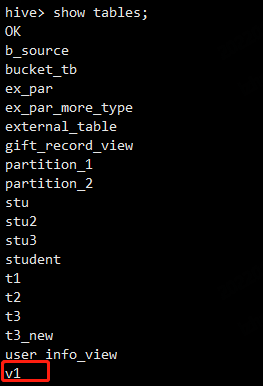
查看视图的结构,显示的内容和表显示的内容是没有区别的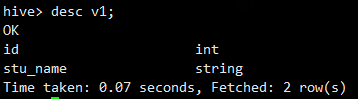
通过视图查询数据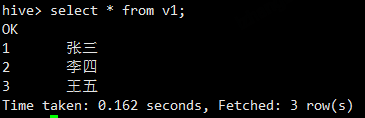
注意:视图在/user/hive/warehouse中是不存在的。因为它只是一个虚拟的表。

若有收获,就点个赞吧
0 人点赞
