MapReduce介绍
MapReduce 是一个分布式运算程序的编程框架,是用户开发 “基于 Hadoop 的数据分析应用” 的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
Map(分)
负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。
Reduce(汇总)
执行过程简介
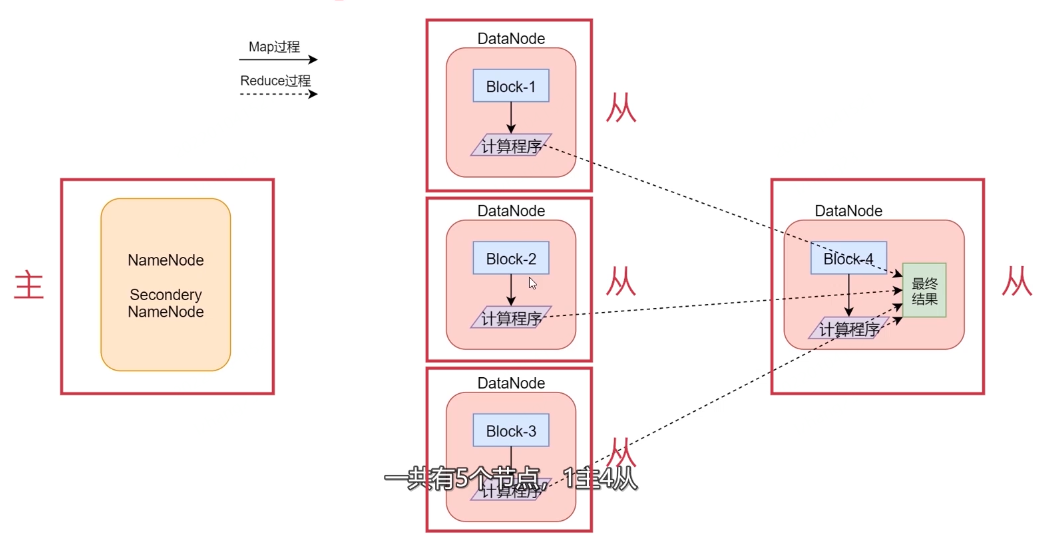
这是一个Hadoop集群,一共5个节点。一个主节点,四个从节点
假设我们有一个512M的文件,这个文件会产生4个block块,假设这4个block块正好分别存储到了集群的 4个节点上,我们的计算程序会被分发到每一个数据所在的节点,然后开始执行计算。
在map阶段,针对每一个block块都会产生一个map任务(这个map任务其实就是执行这个计算程序的),在这里 也就意味着会产生4个map任务并行执行,4个map阶段都执行完毕以后,会执行reduce阶段,
在reduce阶段中会对这4个map任务的输出数据进行汇总统计,得到最终的结果。
MapReduce原理剖析
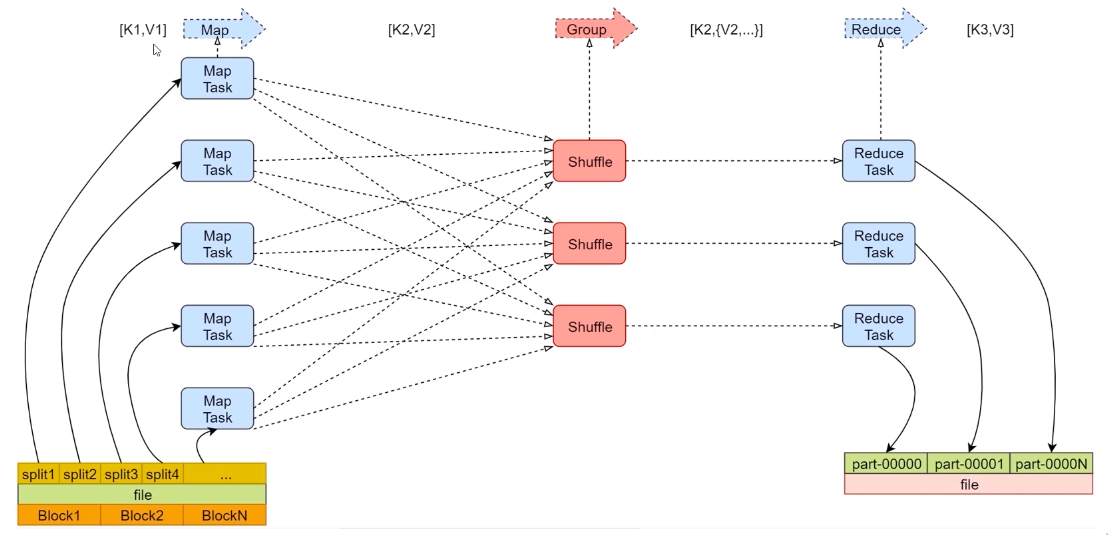
有几个reduce任务就会产生几个文件,这里有三个reduce任务,就产生了3个文件
Split(逻辑切分)
| block块 | 文件的物理切分,在磁盘上是真实存在的。 | 默认128M |
|---|---|---|
| split | 文件的逻辑切分。 | 默认128M |
默认,一个Block对应一个InputSplit。
一个block产生一个map任务,其实这是不严谨的,应该是一个split产生一个Map任务。
对应关系:Block-Split-Map
Partitioner(分区)
分区里放的是同一类的数据。一个分区对应一个Reduce任务。默认只有1个分区
举例:
手机号码文件phone_data.txt1373623051313846544121139564356361396625114618271575951手机号 136、137、138、139 开头都分别放到一个独立的 4 个文件中,其他开头的放到一个文件中。
Shuffle
框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。这个过程称作shuffle
什么情况shuffle? 见spark的宽依赖
WordCount案例
需求
读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数。
原始文件hello.txt内容如下:
hello you
hello me
最终需要的结果形式如下:
hello 2
me 1
you 1
执行解析
Map阶段
1、框架会把输入文件(夹)划分为很多InputSplit,默认,一个Block对应一个InputSplit。通过RecordReader类,把每个InputSplit解析成一个个
k1:每行数据起始的偏移量。 v1:行的内容
<0,hello you>
<10,hello me>
2、框架调用Mapper类中的map()函数,map函数的输入是
<hello,1>
<you,1>
<hello,1>
<me,1>
3、框架对map函数输出的
4、框架对每个分区中的数据,按照k2进行排序、分组。分组,指的是相同k2的v2分成一个组
先排序
<hello,1>
<hello,1>
<me,1>
<you,1>
再分组
<hello,{1,1}>
<me,{1}>
<you,{1}>
5、在Map阶段,框架可以执行Combiner操作(提前聚合)。【可选,默认不执行】
Reduce阶段
1、框架对多个Map Task的输出,按照不同的分区,通过网络Copy到不同的Reduce节点,这个过程称作Shuffle
2、框架对Reduce节点接收到的相同分区的<k2,v2>数据进行合并、排序、分组
3、框架调用Reducer类中的reduce方法,输入
<hello,2>
<me,1>
<you,1>
执行流程图

单文件
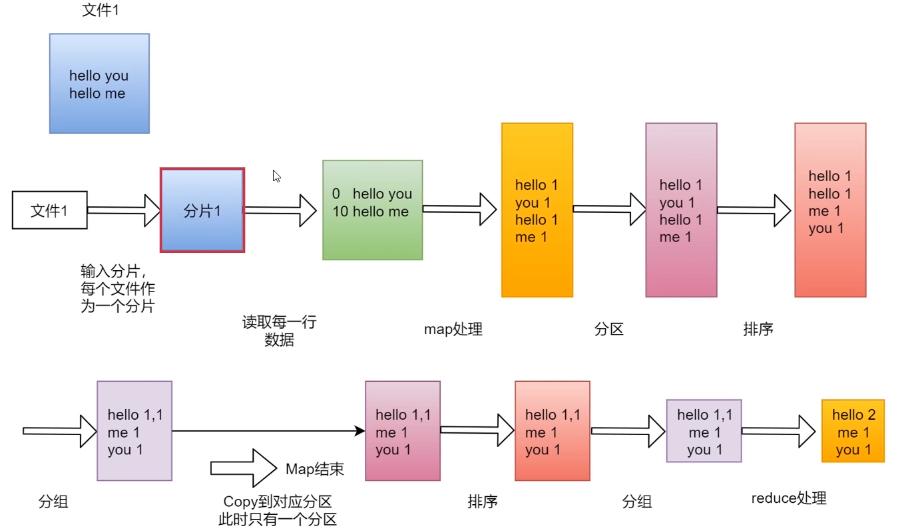
多文件

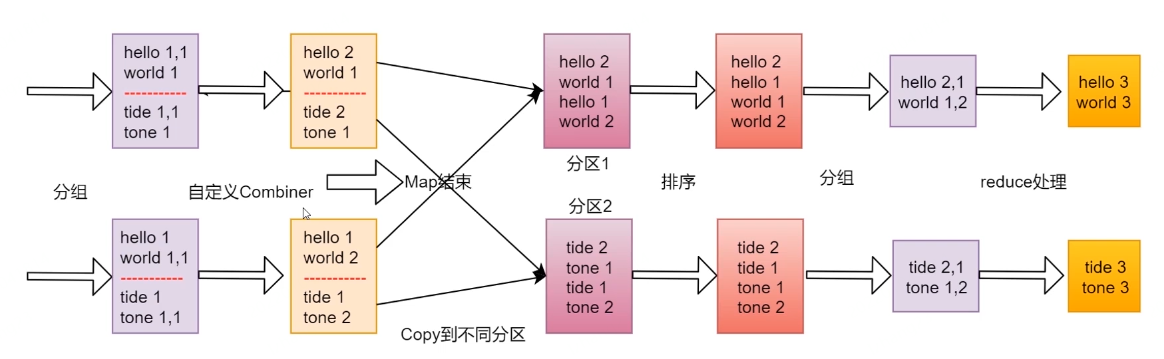
分区里放的是同一类的数据。如分区1只放hello和world,分区2只放tide和tone
代码开发
/**
* 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数
* 原始文件hello.txt内容如下:
* hello you
* hello me
* 最终需要的结果形式如下:
* hello 2
* me 1
* you 1
*/
@Slf4j
public class WordCountJob {
/**
* Map阶段
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 即<k1,v1,k2,v2>
* k1:每行数据起始的偏移量,Long在MapReduce里是LongWritable
* v1:行的内容
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
* @param k1 代表的是每一行数据的行首偏移量
* @param v1 代表的是每一行内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
//输出k1,v1的值
log.info("<k1,v1>=<{},{}>", k1.get(), v1.toString());
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2, v2);
}
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {
//创建一个sum变量,保存v2s的和
long sum = 0L;
//对v2s中的数据进行累加求和
for (LongWritable v2 : v2s) {
//输出k2,v2的值
log.info("<k2,v2>=<{},{}>", k2.toString(), v2.get());
sum += v2.get();
}
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
log.info("<k3,v3>=<{},{}>", k3.toString(), v3.get());
// 把结果写出去
context.write(k3, v3);
}
}
/**
* 组装Job=Map+Reduce
* 需要传入参数:输入路径和输出路径
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的
job.setJarByClass(WordCountJob.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置maven打包插件
<build>
<plugins>
<!-- compiler插件, 设定JDK版本 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<encoding>UTF-8</encoding>
<source>1.8</source>
<target>1.8</target>
<showWarnings>true</showWarnings>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<!-- 打包成带依赖的jar包 -->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
打包项目
上传jar包到hadoop-3.2.0目录下
上传hello.txt到hdfs的/test目录下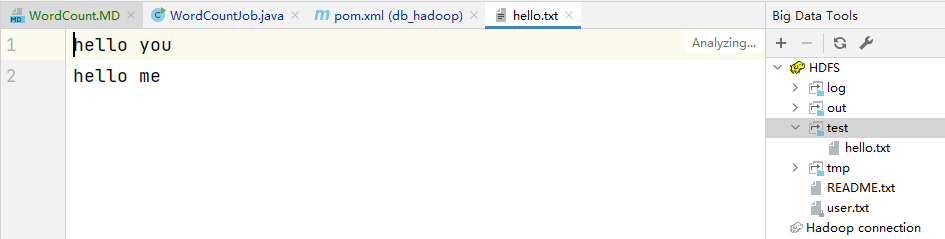
执行WordCountJob,需要传入参数:输入路径和输出路径
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out
Hadoop UI可以看到任务执行情况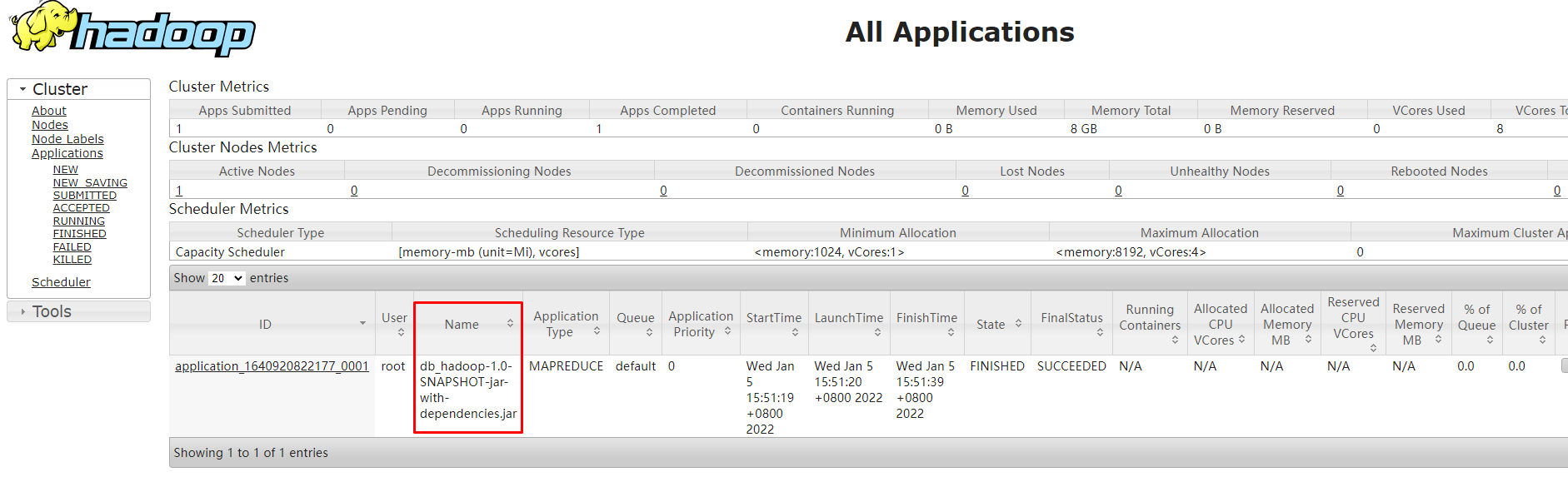
查看任务的执行结果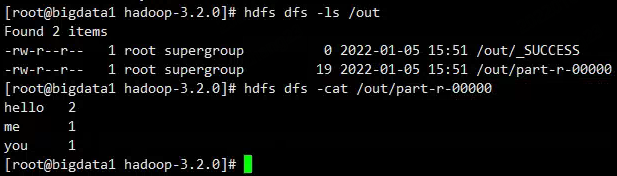
_SUCCESS表示执行成功
part-r-00000表示执行结果,如果reduce任务有多个,会产生对个part文件
MapReduce任务日志查看
使用Hadoop UI查看日志
1、修改yarn-site.xml
cd etc/hadoop/
vim yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs/</value>
</property>
2、重启Hadoop
cd sbin/
stop-all.sh
start-all.sh
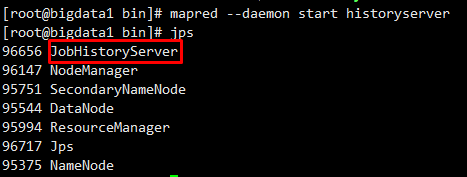
3、开启historyserver
cd bin/
mapred --daemon start historyserver
4、Hadoop UI查看日志:http://192.168.1.21:8088/

分别为Map阶段和Reduce阶段的日志。以Reduce阶段的日志为例:
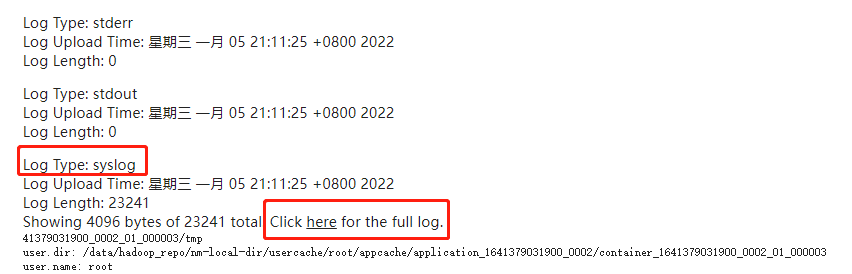
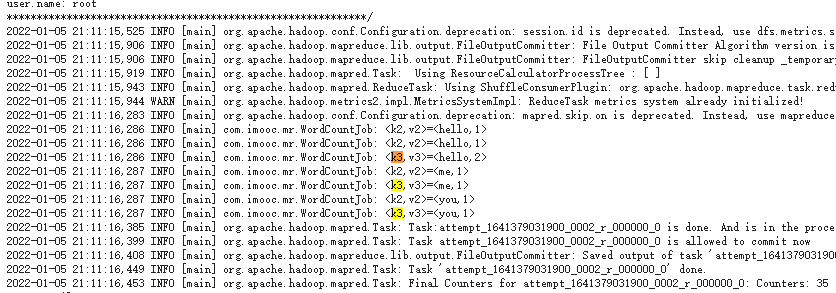
使用YARN命令查看日志
yarn logs -applicationId application_1641379031900_0002
可以重定向到别的日志文件
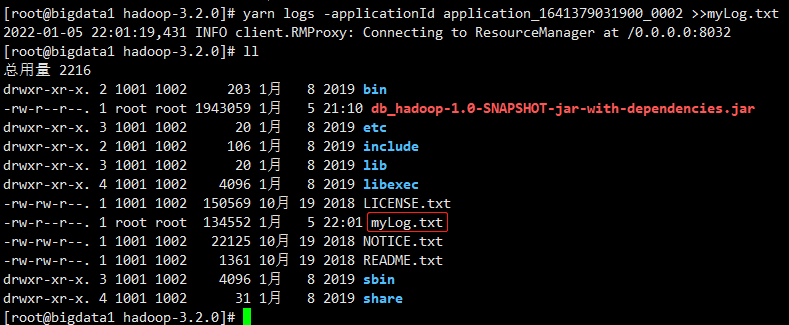
yarn logs -applicationId application_1641379031900_0002 >>myLog.txt
停止Hadoop集群中的任务
yarn application -kill +任务ID
示例:
yarn application -kill application_1641379031900_0005


注意:在命令行Ctrl+C无法停止程序,因为程序已经提交到Hadoop集群运行了。
MapReduce只有Map的情况
当数据只进行普通过滤、解析的操作,不需要聚合的时候,就不需要使用Reduce阶段
/**
* 只有Map阶段,不包含Reduce阶段
* <p>
* job.setNumReduceTasks(0);
*/
@Slf4j
public class WordCountJobNoReduce {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {
//输出k1,v1的值
log.info("<k1,v1>=<{},{}>", k1.get(), v1.toString());
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for (String word : words) {
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2, v2);
}
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[] args) {
try {
if (args.length != 2) {
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个类的
job.setJarByClass(WordCountJobNoReduce.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//禁用Reduce
job.setNumReduceTasks(0);
//提交job
job.waitForCompletion(true);
} catch (Exception e) {
e.printStackTrace();
}
}
}
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJobNoReduce /test/hello.txt /out6

part -m表示只有map阶段
part -r 表示执行到reduce阶段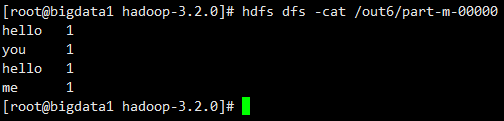
可以看到是

若有收获,就点个赞吧
0 人点赞
