转载自 https://zhuanlan.zhihu.com/p/42717426 写的太好了
1. Recurrent Neural Networks (RNN)
在使用深度学习处理时序问题时,RNN是最常使用的模型之一。RNN之所以在时序数据上有着优异的表现是因为RNN在  时间片时会将
时间片时会将  时间片的隐节点作为当前时间片的输入,也就是RNN具有图1的结构。这样有效的原因是之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。
时间片的隐节点作为当前时间片的输入,也就是RNN具有图1的结构。这样有效的原因是之前时间片的信息也用于计算当前时间片的内容,而传统模型的隐节点的输出只取决于当前时间片的输入特征。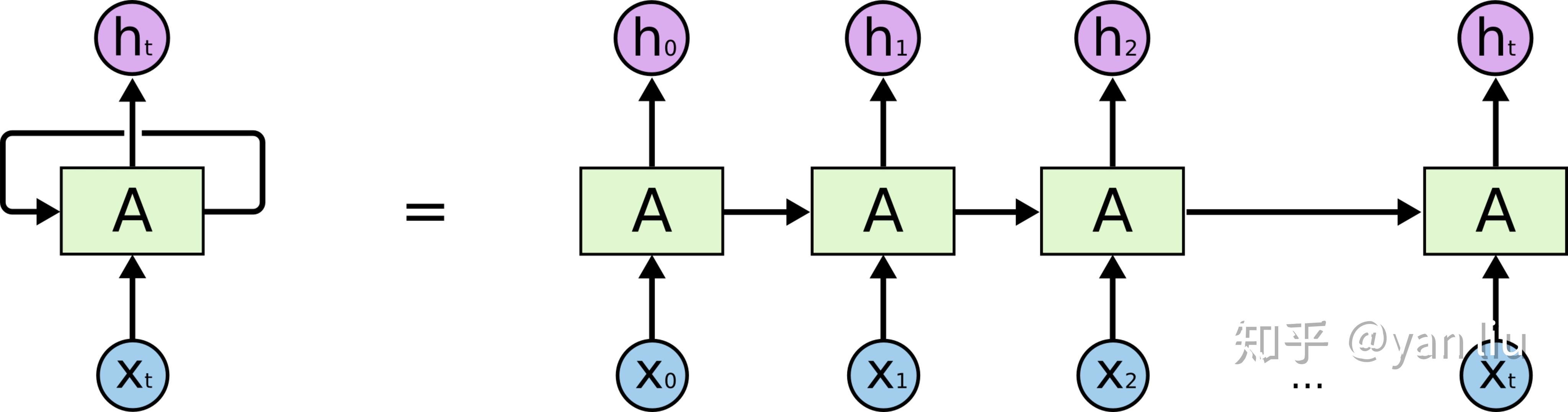 图1:RNN的链式结构
图1:RNN的链式结构
RNN的数学表达式可以表示为
而传统的DNN的隐节点表示为
对比RNN和DNN的隐节点的计算方式,我们发现唯一不同之处在于RNN将上个时间片的隐节点状态  也作为了神经网络单元的输入,这也是RNN擅长处理时序数据最重要的原因。
也作为了神经网络单元的输入,这也是RNN擅长处理时序数据最重要的原因。
所以,RNN的隐节点  有两个作用
有两个作用
- 计算在该时刻的预测值
 :
: 
- 计算下个时间片的隐节点状态

RNN的该特性也使RNN在很多学术和工业前景,例如OCR,语音识别,股票预测等领域上有了十足的进展。
长期依赖(Long Term Dependencies)
在深度学习领域中(尤其是RNN),“长期依赖“问题是普遍存在的。长期依赖产生的原因是当神经网络的节点经过许多阶段的计算后,之前比较长的时间片的特征已经被覆盖,例如下面例子
eg1: The cat, which already ate a bunch of food, was full.| | | | | | | | | | |t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10eg2: The cats, which already ate a bunch of food, were full.| | | | | | | | | | |t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10
我们想预测’full’之前系动词的单复数情况,显然full是取决于第二个单词’cat‘的单复数情况,而非其前面的单词food。根据图1展示的RNN的结构,随着数据时间片的增加,RNN丧失了学习连接如此远的信息的能力(图2)。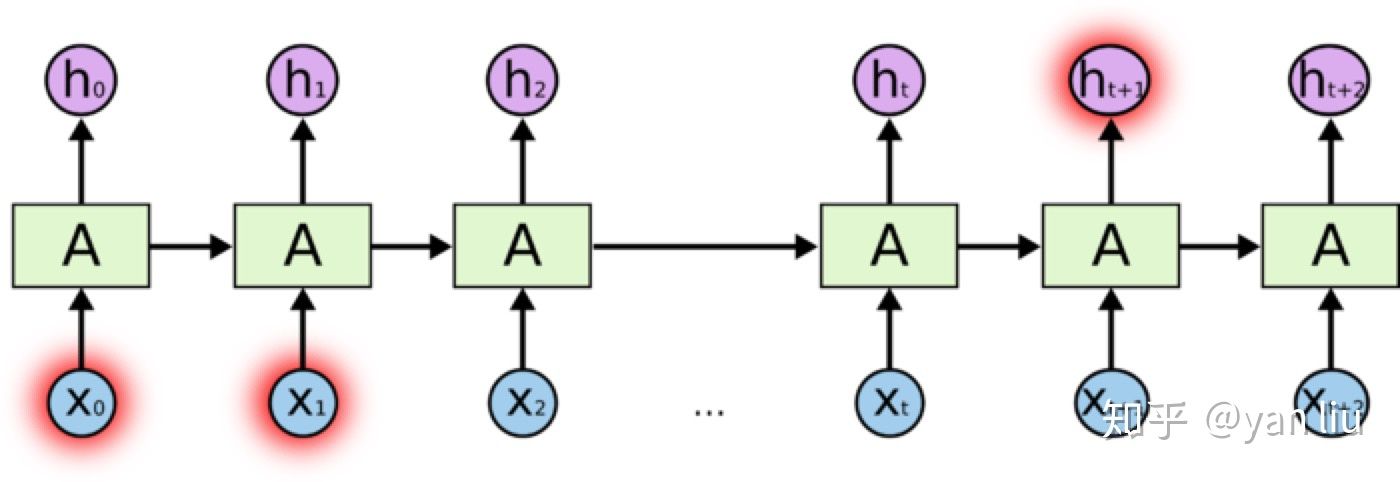 图2:RNN的长期依赖问题
图2:RNN的长期依赖问题
梯度消失/爆炸
梯度消失和梯度爆炸是困扰RNN模型训练的关键原因之一,产生梯度消失和梯度爆炸是由于RNN的权值矩阵循环相乘导致的,相同函数的多次组合会导致极端的非线性行为。梯度消失和梯度爆炸主要存在RNN中,因为RNN中每个时间片使用相同的权值矩阵。对于一个DNN,虽然也涉及多个矩阵的相乘,但是通过精心设计权值的比例可以避免梯度消失和梯度爆炸的问题 [2]。
处理梯度爆炸可以采用梯度截断的方法。所谓梯度截断是指将梯度值超过阈值  的梯度手动降到
的梯度手动降到  。虽然梯度截断会一定程度上改变梯度的方向,但梯度截断的方向依旧是朝向损失函数减小的方向。
。虽然梯度截断会一定程度上改变梯度的方向,但梯度截断的方向依旧是朝向损失函数减小的方向。
对比梯度爆炸,梯度消失不能简单的通过类似梯度截断的阈值式方法来解决,因为长期依赖的现象也会产生很小的梯度。在上面例子中,我们希望  时刻能够读到
时刻能够读到  时刻的特征,在这期间内我们自然不希望隐层节点状态发生很大的变化,所以
时刻的特征,在这期间内我们自然不希望隐层节点状态发生很大的变化,所以  时刻的梯度要尽可能的小才能保证梯度变化小。很明显,如果我们刻意提高小梯度的值将会使模型失去捕捉长期依赖的能力。
时刻的梯度要尽可能的小才能保证梯度变化小。很明显,如果我们刻意提高小梯度的值将会使模型失去捕捉长期依赖的能力。
2. LSTM
LSTM的全称是Long Short Term Memory,顾名思义,它具有记忆长短期信息的能力的神经网络。LSTM首先在1997年由Hochreiter & Schmidhuber [1] 提出,由于深度学习在2012年的兴起,LSTM又经过了若干代大牛(Felix Gers, Fred Cummins, Santiago Fernandez, Justin Bayer, Daan Wierstra, Julian Togelius, Faustino Gomez, Matteo Gagliolo, and Alex Gloves)的发展,由此便形成了比较系统且完整的LSTM框架,并且在很多领域得到了广泛的应用。本文着重介绍深度学习时代的LSTM。
LSTM提出的动机是为了解决上面我们提到的长期依赖问题。传统的RNN节点输出仅由权值,偏置以及激活函数决定(图3)。RNN是一个链式结构,每个时间片使用的是相同的参数。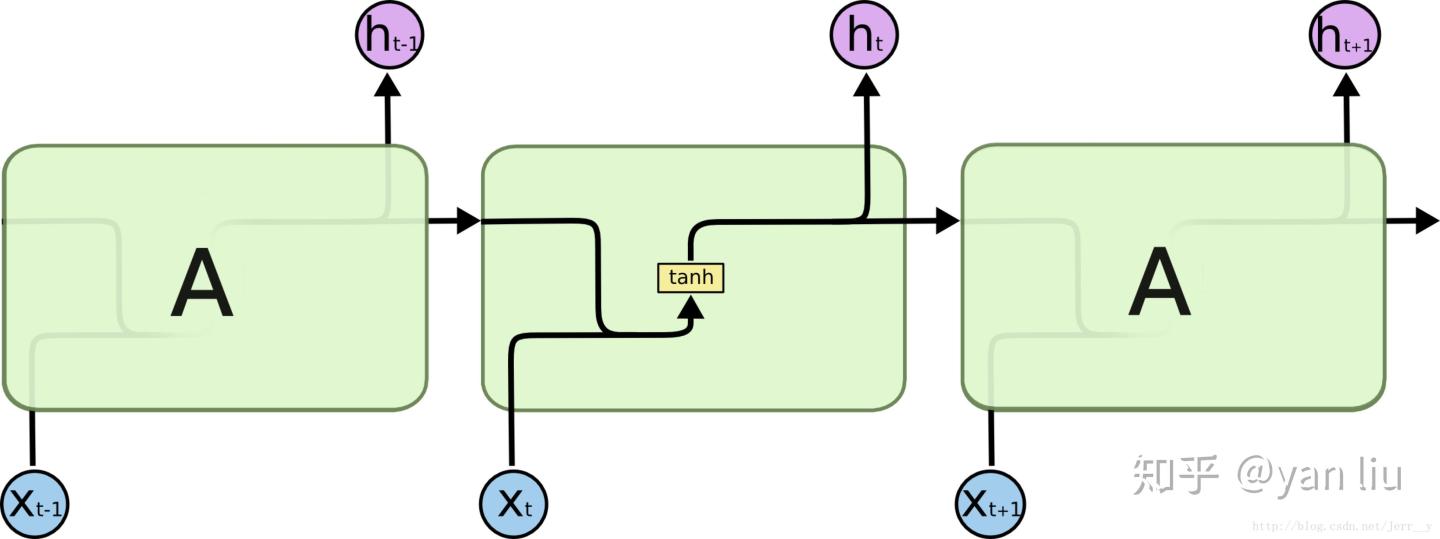 图3:RNN单元
图3:RNN单元
而LSTM之所以能够解决RNN的长期依赖问题,是因为LSTM引入了门(gate)机制用于控制特征的流通和损失。对于上面的例子,LSTM可以做到在t9时刻将t2时刻的特征传过来,这样就可以非常有效的判断  时刻使用单数还是复数了。LSTM是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图。
时刻使用单数还是复数了。LSTM是由一系列LSTM单元(LSTM Unit)组成,其链式结构如下图。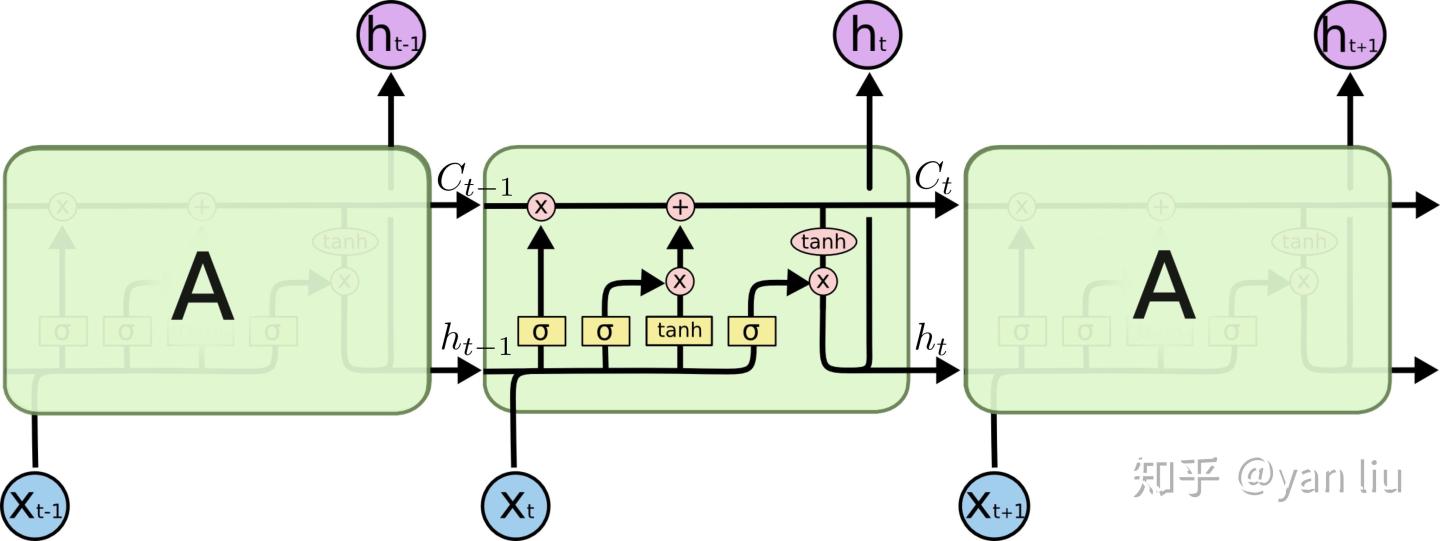 图4:LSTM单元
图4:LSTM单元
在后面的章节中我们再对LSTM的详细结构进行讲解,首先我们先弄明白LSTM单元中的每个符号的含义。每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制。总结如图5. 图5:LSTM的符号含义
图5:LSTM的符号含义
LSTM的核心部分是在图4中最上边类似于传送带的部分(图6),这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中。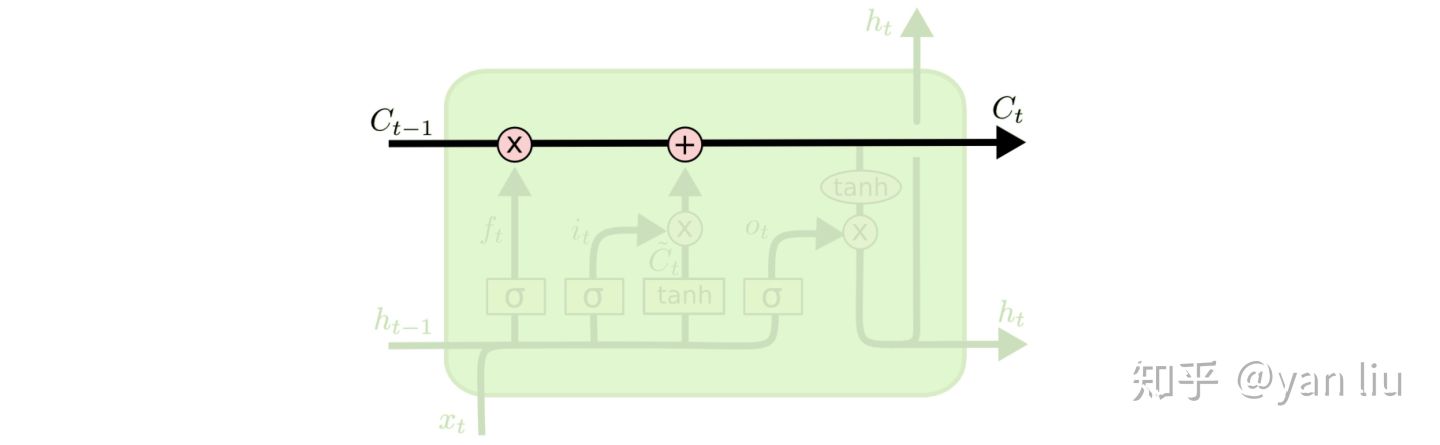 图6:LSTM的单元状态
图6:LSTM的单元状态
其中
其中  叫做遗忘门,表示
叫做遗忘门,表示  的哪些特征被用于计算
的哪些特征被用于计算  。
。  是一个向量,向量的每个元素均位于
是一个向量,向量的每个元素均位于  范围内。通常我们使用
范围内。通常我们使用  作为激活函数,
作为激活函数,  的输出是一个介于
的输出是一个介于  区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。其中
区间内的值,但是当你观察一个训练好的LSTM时,你会发现门的值绝大多数都非常接近0或者1,其余的值少之又少。其中  是LSTM最重要的门机制,表示
是LSTM最重要的门机制,表示  和
和  之间的单位乘的关系。
之间的单位乘的关系。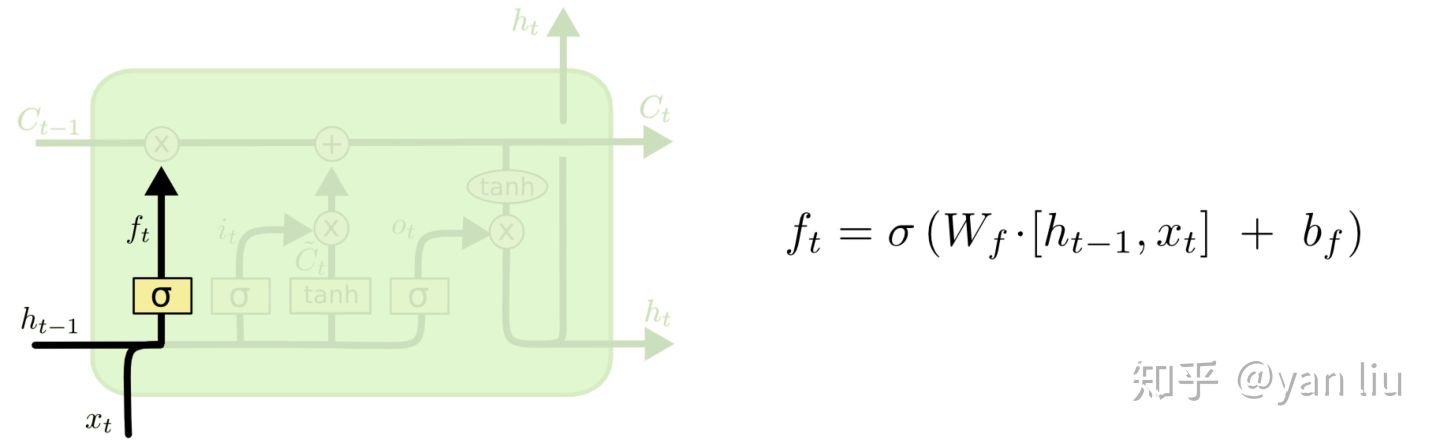 图7:LSTM的遗忘门
图7:LSTM的遗忘门
如图8所示,  表示单元状态更新值,由输入数据
表示单元状态更新值,由输入数据  和隐节点
和隐节点  经由一个神经网络层得到,单元状态更新值的激活函数通常使用
经由一个神经网络层得到,单元状态更新值的激活函数通常使用  。
。  叫做输入门,同
叫做输入门,同  一样也是一个元素介于
一样也是一个元素介于  区间内的向量,同样由
区间内的向量,同样由  和
和  经由
经由  激活函数计算而成。
激活函数计算而成。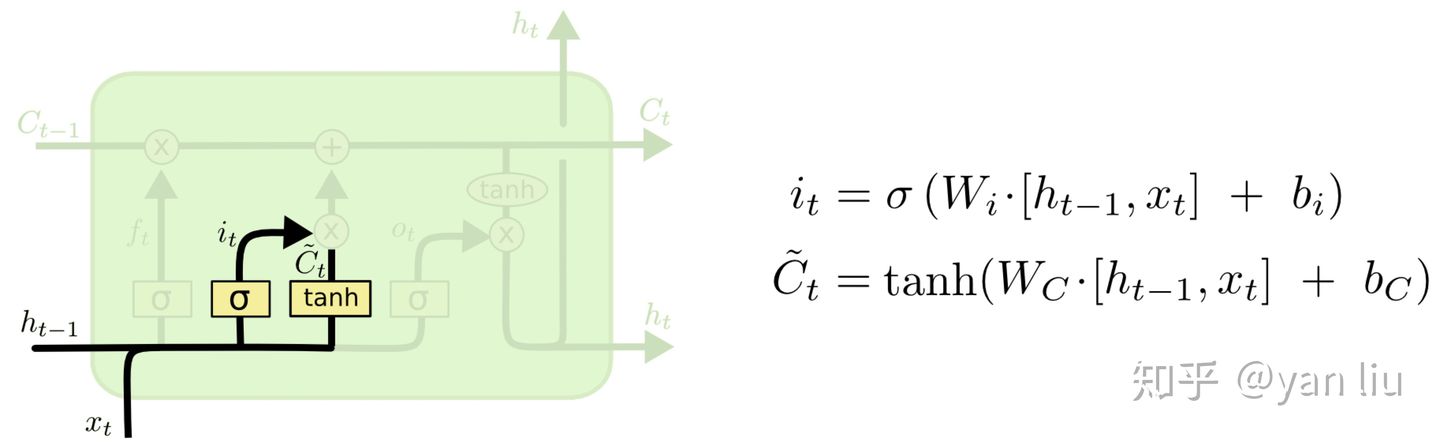 图8:LSTM的输入门和单元状态更新值的计算方式
图8:LSTM的输入门和单元状态更新值的计算方式 用于控制
用于控制  的哪些特征用于更新
的哪些特征用于更新  ,使用方式和
,使用方式和  相同(图9)。
相同(图9)。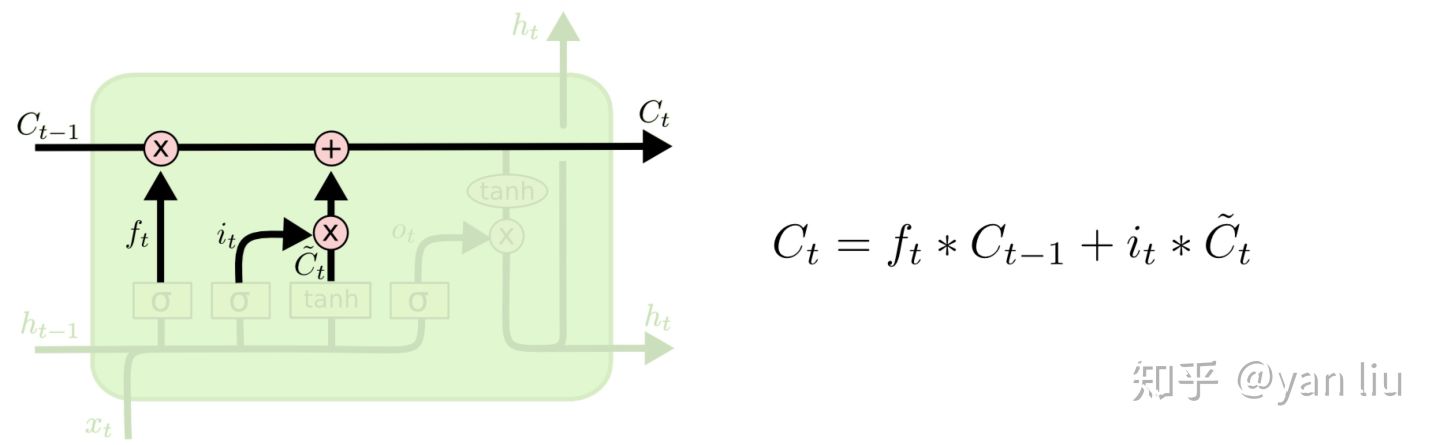 图9:LSTM的输入门的使用方法
图9:LSTM的输入门的使用方法
最后,为了计算预测值  和生成下个时间片完整的输入,我们需要计算隐节点的输出
和生成下个时间片完整的输入,我们需要计算隐节点的输出  (图10)。
(图10)。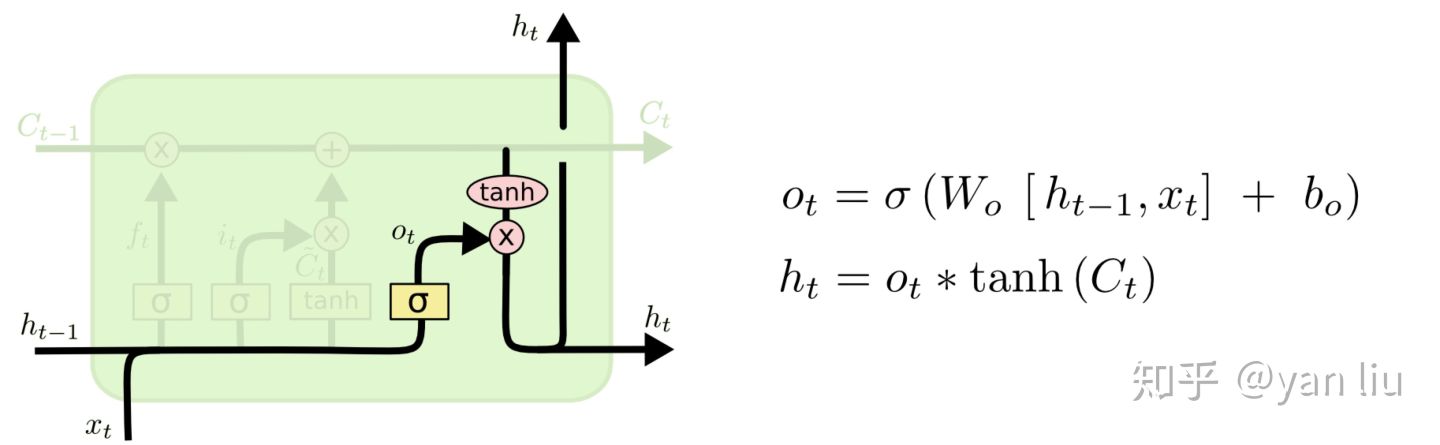 图10:LSTM的输出门
图10:LSTM的输出门 由输出门
由输出门  和单元状态
和单元状态  得到,其中
得到,其中  的计算方式和
的计算方式和  以及
以及  相同。在[3]的论文中指出,通过将
相同。在[3]的论文中指出,通过将  的均值初始化为
的均值初始化为  ,可以使LSTM达到同GRU近似的效果。
,可以使LSTM达到同GRU近似的效果。
3. 其他LSTM
联想之前介绍的GRU [4],LSTM的隐层节点的门的数量和工作方式貌似是非常灵活的,那么是否存在一个最好的结构模型或者比LSTM和GRU性能更好的模型呢?Rafal[5] 等人采集了能采集到的100个最好模型,然后在这100个模型的基础上通过变异的形式产生了10000个新的模型。然后通过在字符串,结构化文档,语言模型,音频4个场景的实验比较了这10000多个模型,得出的重要结论总结如下:
- GRU,LSTM是表现最好的模型;
- GRU的在除了语言模型的场景中表现均超过LSTM;
- LSTM的输出门的偏置的均值初始化为1时,LSTM的性能接近GRU;
- 在LSTM中,门的重要性排序是遗忘门 > 输入门 > 输出门。
reference
[1] Hochreiter, S, and J. Schmidhuber. “Long short-term memory.” Neural Computation 9.8(1997):1735-1780.
[2] Sussillo, D. (2014). Random walks: Training very deep nonlinear feed-forward networks with smart initialization.CoRR,abs/1412.6558. 248, 259, 260, 344
[3] Gers F A, Schmidhuber J, Cummins F. Learning to forget: Continual prediction with LSTM[J]. 1999.
[4] Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014.
[5] Jozefowicz R, Zaremba W, Sutskever I. An empirical exploration of recurrent network architectures[C]//International Conference on Machine Learning. 2015: 2342-2350.

若有收获,就点个赞吧
0 人点赞
