欠拟合
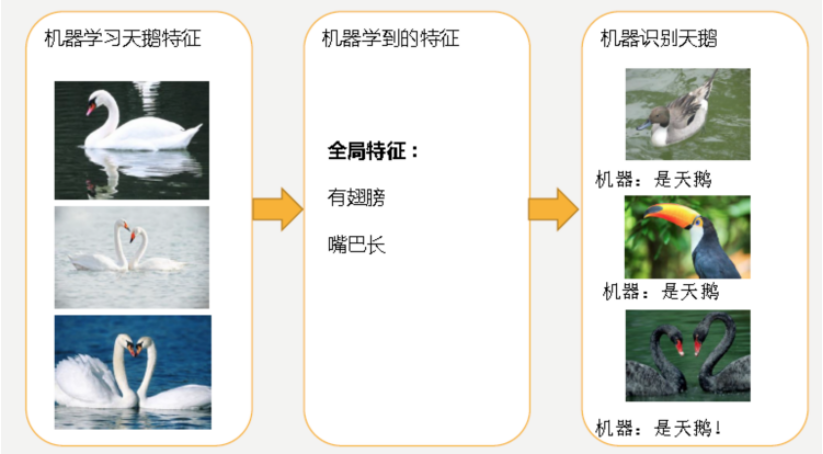
经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的。简单的认为有这些特征的都是天鹅。因为机器学习到的天鹅特征太少了,导致区分标准太粗糙,不能准确识别出天鹅。
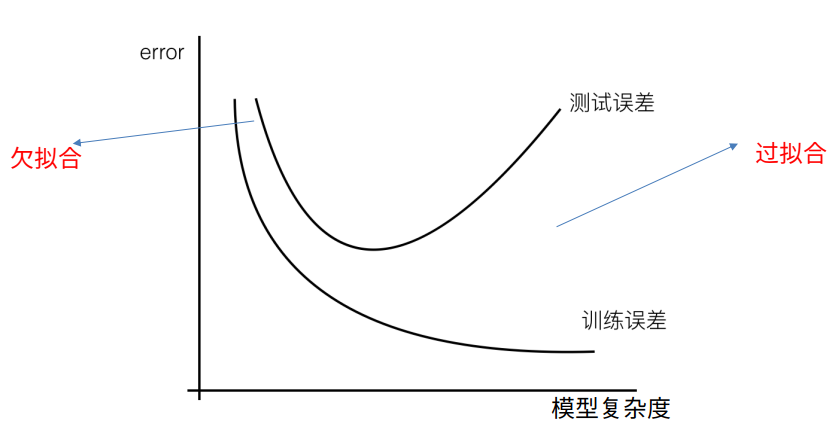
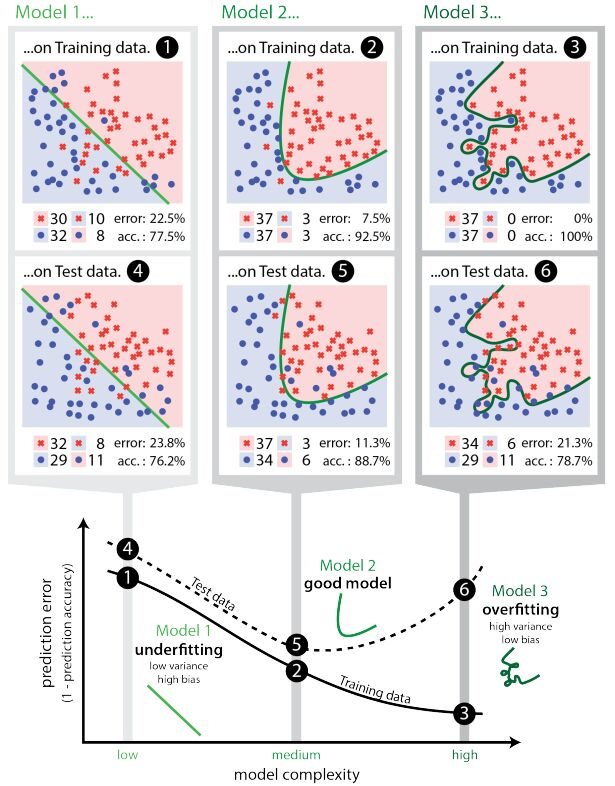
一个假设在训练数据上不能获得更好的拟合, 但是在训练数据外的数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
过拟合
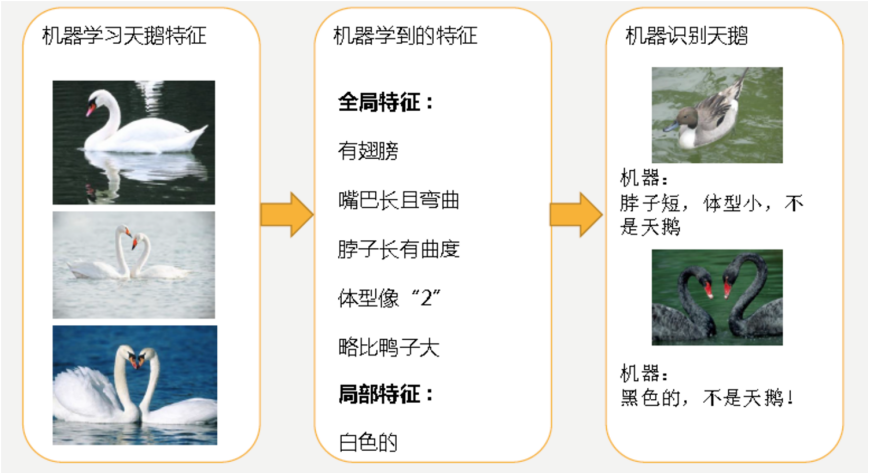
机器通过这些图片来学习天鹅的特征,经过训练后,知道了天鹅是有翅膀的,天鹅的嘴巴是长长的弯曲的,天鹅的脖子是长长的有点曲度,天鹅的整个体型像一个”2”且略大于鸭子。这时候机器已经基本能区别天鹅和其他动物了。然后,很不巧已有的天鹅图片全是白天鹅的,于是机器经过学习后,会认为天鹅的羽毛都是白的,以后看到羽毛是黑的天鹅就会认为那不是天鹅。
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂) 一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
总结
原因分析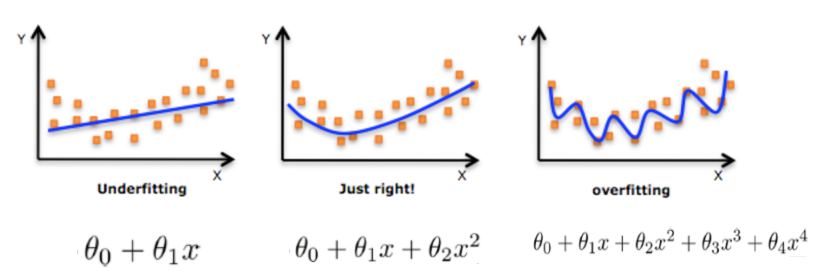
通过交叉验证(计算的方差值)来判断到底是哪种拟合
欠拟合
原因:
学习到数据的特征过少
解决办法:
增加数据的特征数量
过拟合
原因:
原始特征过多,存在一些嘈杂特征,模型过于复杂是因为模型尝试去兼顾
各个测试数据点
解决办法:
进行特征选择,消除关联性大的特征(很难做)
交叉验证(让所有数据都有过训练)
正则化
正则化
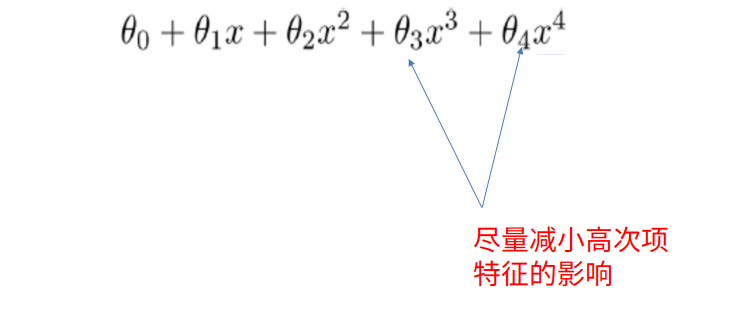 将高次项的系数(权重)接近0。
将高次项的系数(权重)接近0。
作用:可以使得W的每个元素都很小,都接近于0
优点:越小的参数说明模型越简单,越简单的模型则越不
容易产生过拟合现象
api:sklearn.linearmodel.Ridge(alpha=1.0) 具有l2正则化的线性最小二乘法
alpha:正则化力度
coef:回归系数
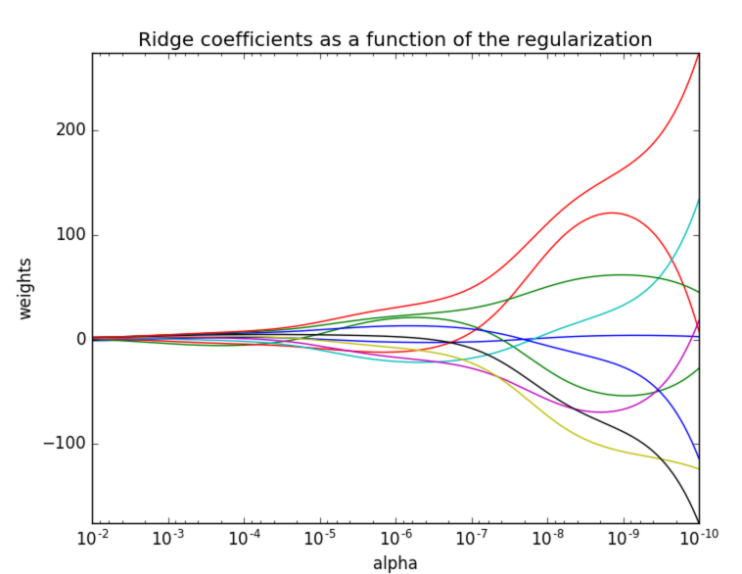
正则化力度越大权重越小,趋近于0。

若有收获,就点个赞吧
0 人点赞
