Bulat 和 Tzimiropoulos - 2017 - How Far are We from Solving the 2D & 3D Face Align.pdf
代码 https://github.com/1adrianb/face-alignment
模型下载
- 2D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-FAN-300W.t7
- 3D-FAN:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN.t7
- 2D-to-3D FAN:https://www.adrianbulat.com/downloads/FaceAlignment/2D-to-3D-FAN.tar.gz
3D-FAN-depth:https://www.adrianbulat.com/downloads/FaceAlignment/3D-FAN-depth
[x] 为什么嘴巴被遮挡了也能识别?
人脸检测器S3FD可以检测到被遮挡的人脸,s3fd训练的数据集里有的人脸就是被遮挡的,标注人脸位置的方框。
FAN这个人脸特征点预测的网络用的训练数据集是标注了特征点的数据集,包含总共~4000张靠近正面的人脸图像。然后用算法生成了从-90到90的姿态,获得合成的数据集,提供了2D和3D标注。
这个算法的目标就是生成人脸特征点,并且专注于各种侧脸、俯仰角等大姿态的预测,能预测到不在画面上的剩余人脸特征点位。它先用s3fd检测人脸,然后去预测并返回人脸特征点。
粗读
研究问题
在现有的2D和3D人脸对齐数据集上,本文研究了一个非常深的神经网络距离接近饱和的性能有多远。
研究背景
研究方法
基于热图回归(heatmap regression)的完全卷积神经网络架构:
For the needs of this work, we built a powerful CNN for 2D and 3D face alignment based on two components: (a) the state-of-the-art Hour Glass (HG) network of [23], and (b) the hierarchical, parallel & multi-scale block recently proposed in [7]. In par ticular, we replaced the bottleneck block [15] used in [23] with the block proposed in [7].
[7] A. Bulat and G. Tzimiropoulos. Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources. In ICCV, 2017. 2, 4 [23] A. Newell, K. Yang, and J. Deng. Stacked hourglass networks for human pose estimation. In ECCV, 2016. 1, 2, 4
研究思路
研究结论
我们构建了一个最先进的用于地标定位的神经网络,对其进行2D和3D面部对齐训练,并在数十万张图像上对其进行评估。我们的结果表明,我们的网络几乎饱和了这些数据集,对姿态、分辨率、初始化,甚至对使用的网络参数的数量也显示出显著的弹性。
- 2D- fan在上述2D数据集上实现了接近饱和的性能。值得注意的是,这个结果主要是通过在合成数据上训练2D-FAN得到的,而且训练和测试地标注释之间存在不匹配。
- 3D-FAN基本上在所有数据集上产生相同的精度,在很大程度上优于3DDFA。此精度与所实现的精度相比略有提高
2D-FAN,尤其是误差曲线的部分误差小于2%这并不奇怪,因为现在训练和测试数据集都是用相同的标记标注的。 - 不同的network size(参数数量)对3D的性能有微小的影响。而 facial pose、resolution、noisy initialization 不是3D-FAN的 major issue。
创新点
本文主要做了5个贡献:
(1)结合最先进的人脸特征点定位(landmark localization)架构和最先进的残差模块(residual block),首次构建了一个非常强大的基准,在一个超大2D人脸特征点数据集(facial landmark dataset)上训练,并在所有其他人脸特征点数据集上进行评估。
(2)我们构建一个将2D特征点标注转换为3D标注,并所有现存数据集进行统一,构建迄今最大、最具有挑战性的3D人脸特征点数据集LS3D-W(约230000张图像)。
(3)然后,训练一个神经网络来进行3D人脸对齐(face alignment),并在新的LS3D-W数据集上进行评估。
(4)本文进一步研究影响人脸对齐性能的所有“传统”因素,例如大姿态( large pose),初始化和分辨率,并引入一个“新的”因素,即网络的大小。
(5)本文的测试结果显示2D和3D人脸对齐网络都实现了非常高的性能,足以证明非常可能接近所使用的数据集的饱和性能。研究局限
研究展望
主要方法
通过堆叠四个HG(HourGlass)构建的人脸对齐网络(Face Alignment Network, FAN),其中所有的 bottleneck blocks(图中矩形块)被替换为新的分层、并行和多尺度block(由其他研究人员提出)。
本质上来说就是一个小卷积网络的4层堆叠来预测人脸。输入2D图片,输出2D图片的Heatmap。
每个heatmap代表着网络预测的每个像素存在对应的特征点的概率,保留概率最大的。
分别训练了3个网络:2D-FAN, 3D-FAN, 2D-to-3D-FAN。
我们基于最先进的人体姿态估计架构之一,即[23]的沙漏(HG)网络来构建FAN。特别地,我们使用了四个HG网络的堆栈(见图1)。虽然[23]使用[14]的瓶颈块作为HG的主要构建块,但我们更进一步,用最近引入的[7]的分层、并行和多尺度块替换瓶颈块。正如在[7]中显示的那样,当使用相同数量的网络参数时,该块的性能优于[14]的原始瓶颈。最后,我们使用300W-LP-2D和300W-LP-3D 数据集分别训练2D-FAN和3DFAN。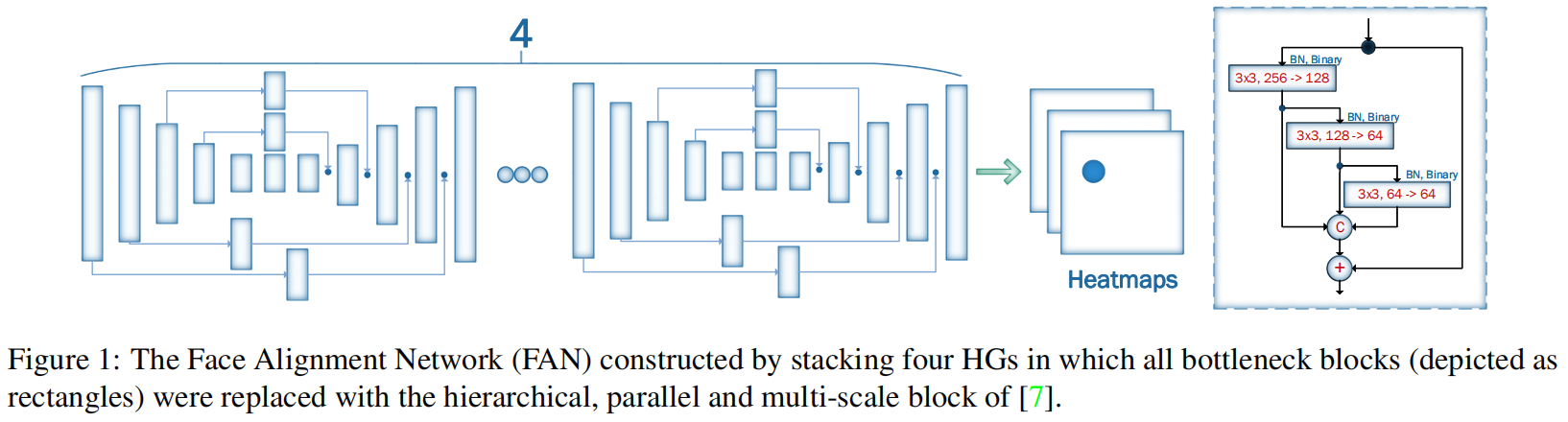
2D-to-3D-FAN: 基于人体姿态估计架构HourGlass,输入是RGB图像和2D面部地标,输出是对应的3D面部地标。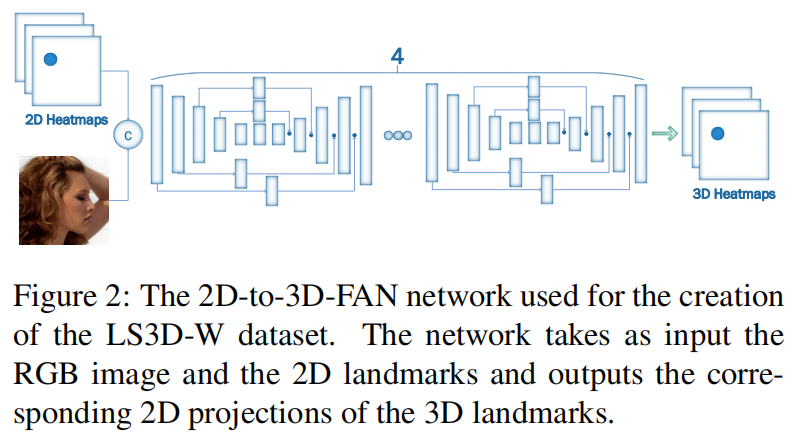
2D-FAN对超过22万张图像进行了评估。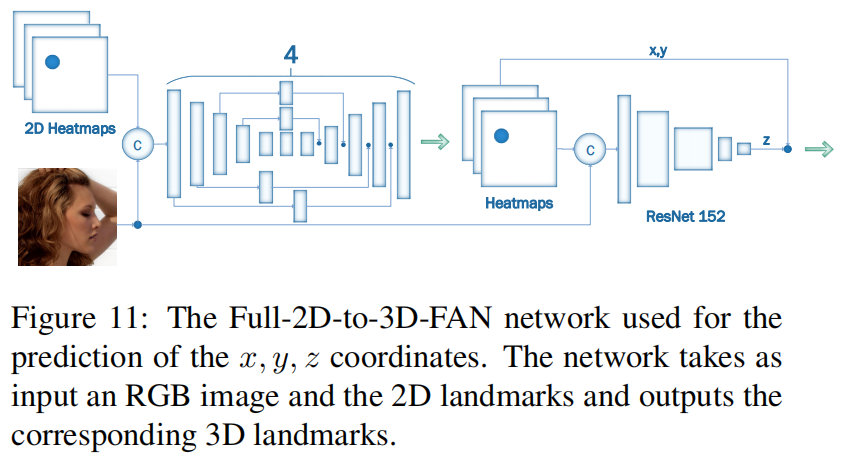 预测z坐标。
预测z坐标。
3D-FAN在大约23万张图像上进行了评估。与2D实验相比,我们使用了更多的大姿态图像来训练3D-FAN,因为我们的3D实验还包括AFLW2000-3D和Menpo的侧面图像(总共多2000张图像)。
数据集
1)训练数据
300-W是目前使用最广泛的用于二维人脸对齐的数据集。数据集本身是一系列较小数据集的连接:LFPW、HELEN、AFW和iBUG,其中使用Multi-PIE的68个2D地标配置以一致的方式重新注释每个图像。该数据集包含总共~4000张靠近正面的人脸图像。
300-W-LP是通过使用[50]的profiling方法将300-W的面部渲染成范围从-90到90的更大的姿态,而获得的合成生成的数据集。数据集包含61225幅图像,提供2D(300W-LP-2D)和3D注释(300W-LP-3D)。
(2)测试数据
300-W测试集由用于300-W挑战的评估目的的600幅图像组成。图像分为两类:室内和室外。所有图像都标注了与在300-W数据集中使用的相同的68个2D标志。
300-VW[33]是一个大规模的人脸跟踪数据集,包含114个视频以及总共218595帧。在114个视频中,64个用于测试,50个用于训练。测试视频进一步分为三类(A、B和C),最后一类是最具挑战性的。值得注意的是,一些视频(尤其是C类视频)包含非常低的分辨率/低质量的脸。由于半自动注释方法(更多细节参见[33]),在某些情况下,这些视频的注释不那么准确。注释错误的另一个来源是面部姿势造成的,即大姿态也未被精确注释。
AFLW2000-3D是通过以与300W-LP-3D一致的方式使用68个3D标志,对AFLW[21]的前2000个图像重新注释而构建的数据集。然而一些注释,特别是对于较大的姿态或遮挡的面孔,并不那么精确。

若有收获,就点个赞吧
0 人点赞
