Chung 和 Zisserman - 2017 - Out of Time Automated Lip Sync in the Wild.pdf
代码 https://github.com/joonson/syncnet_python
粗读
研究问题
确定视频中的嘴唇运动和声音的一致。进一步可用于以下任务:
- 确定视频中的 lip-sync error
- 在多人画面中检测谁是音频对应的说话者
-
研究方法
我们提出了一种双流ConvNet架构,使声音和嘴巴图像之间的联合嵌入,从这些未标记的数据中学习。
研究思路
使用基于计算机视觉的方法。
- 不把声音和嘴型中间分类为元音或音素。
- 直接学习视觉特征。
也有一些论文试图在没有这些标签的情况下找到语音和视觉数据之间的对应关系:许多方法基于典型相关分析(CCA)[3,22]或音频和视觉特征(例如几何参数或2D DCT特征)的共惯性分析(CoIA)[20]。
与我们最相关的工作是Marcharet等人的[17],它使用基于深度神经网络(DNN)的分类器来确定时间偏移,同时也基于预定义的视觉特征(语音类可能性、瓶颈特征等),而我们直接学习视觉特征。
与本文开发的架构相关的是 Siamese 网络[6],在该网络中不需要明确的类别标签,通过学习相似性度量(similarity metrics)来进行人脸分类。[23, 27]也相关,因为它们同时训练输入来自不同领域的多流网络。
[6] Chopra, S., Hadsell, R., LeCun, Y.: Learning a similarity metric discriminatively, with application to face verification. In: Proc. CVPR. vol. 1, pp.539–546. IEEE (2005) [23] Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: NIPS (2014) [27] Zhong, Y., Arandjelovi´c, R., Zisserman, A.: Faces in places: Compound query retrieval. In: British Machine Vision Conference (2016)
研究结论
训练 two-stream ConvNet 可以使音频和嘴唇运动同步。一个有用的应用是纠正假唱。这种方法也可以推广到任何关联数据的联合嵌入学习问题。我们也证明了训练的网络对于视频中说话者的检测和唇读的任务是有效的。
创新点
- conf,Confidence缩写,confidence score即置信度。
我们将时间偏移(同步误差)的置信度定义为欧氏距离的最小值和中值之差。
- loss函数用的是什么?什么含义?
- 符号fc7代表位于网络第7层的全连接层。
- The 256-dimensional fc7 vectors for each stream are used as features representing the audio and the video.
输入
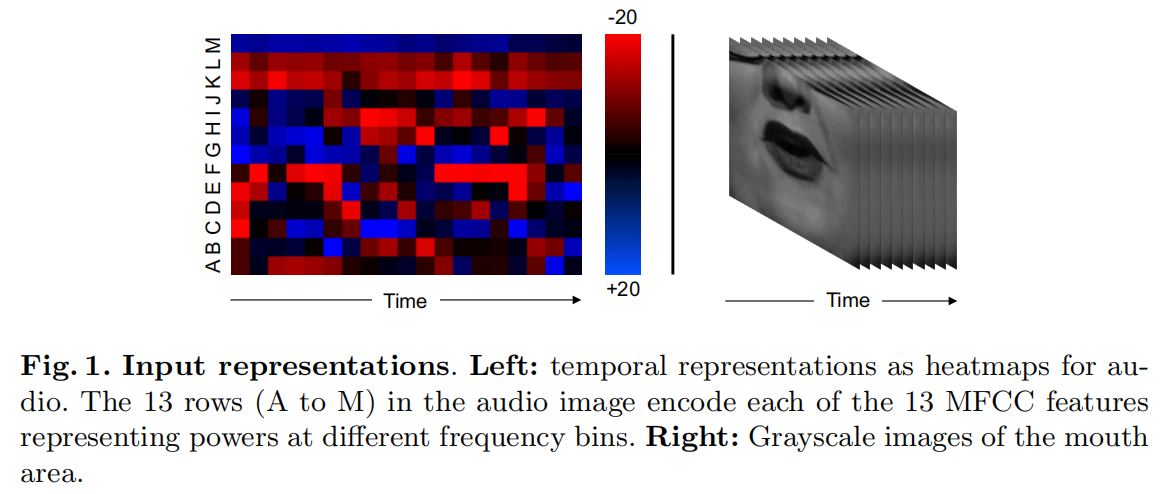
音频流
输入的音频数据为MFCC值。这是一个在非线性梅尔频率尺度上的声音的短期功率谱的表示。每个时间步长使用13 MEL频段。特征以100Hz的采样率计算,0.2秒的输入信号有20个时间步长。
heatmap 为 13*20 pixels(如Fig.1 所示),20是时间步,13是指每个时间步里的13 mel frequency bands。
输入形式和[9]相似。网络结构基于 VGG-M [5],修改了 filter sizes 来提取不寻常尺寸的输入。
[9] Geras, K.J., Mohamed, A.r., Caruana, R., Urban, G., Wang, S., Aslan, O.,Philipose, M., Richardson, M., Sutton, C.: Compressing lstms into cnns. arXiv preprint arXiv:1511.06433 (2015)
视频流
输入一个包含 T_v 个连续人脸帧(只有下半张脸)的window V,和 说话片段 S,大小为T_aD。其中 T_v 和 T_a 是 video audio 各自的 time-step 时间步。获得嘴巴区域的灰度图,1111115(宽高*5帧),对应0.2秒 25 hz的帧速率。
L2距离,最小化同步av pairs的距离,最大化不同步音视频的距离。
网络结构基于[7]。[7]又基于Early Fusion model,紧凑且易于训练。conv1滤波器已被修改以吸收5通道输入。
[7] Chung, J.S., Zisserman, A.: Lip reading in the wild. In: Proc. ACCV (2016)
Lip-sync 对syncnet的改进:
- 输入灰度图改成输入彩色图
- 模型更深,有residual skip connections
- 使用不同的loss function:cosine-similarity with binary cross-entropy loss.
训练
网络包含视频流和音频流,非对称结构。
loss function
contrastive loss 对比损失函数,最初提议于训练Siamese网络[6]。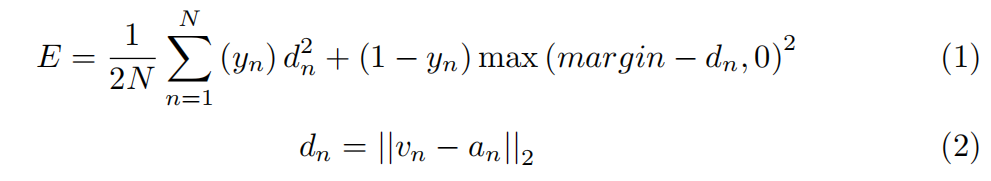
- v and a are fc7 vectors for the video and the audio streams, respectively.
- y ∈ [0, 1] is the binary similarity metric between the audio and the video inputs.
粗略翻了一下[6] Learning a similarity metric discriminatively, with application to face verification. [PDF] 没找到这个等式,但应该就是位于 2.3. Contrastive Loss Function used for Training,提出公式并证明。
training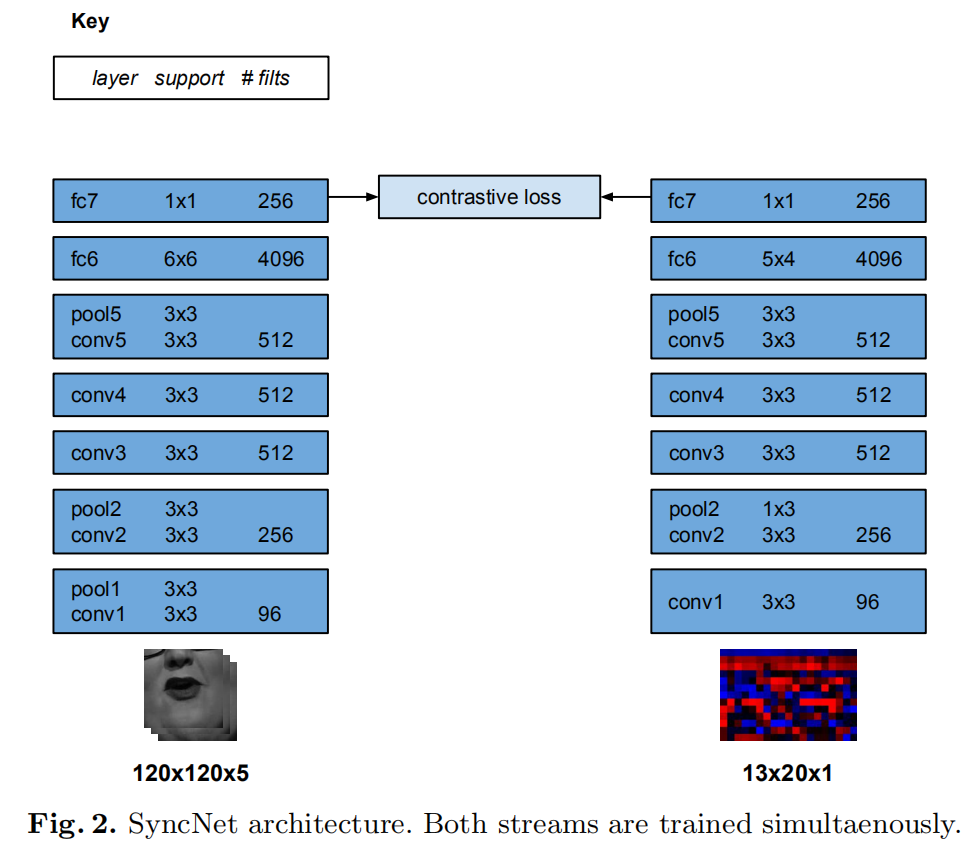
利用带动量的随机梯度下降法学习网络权值。两个网络流的参数是同时学习的。
数据集生成
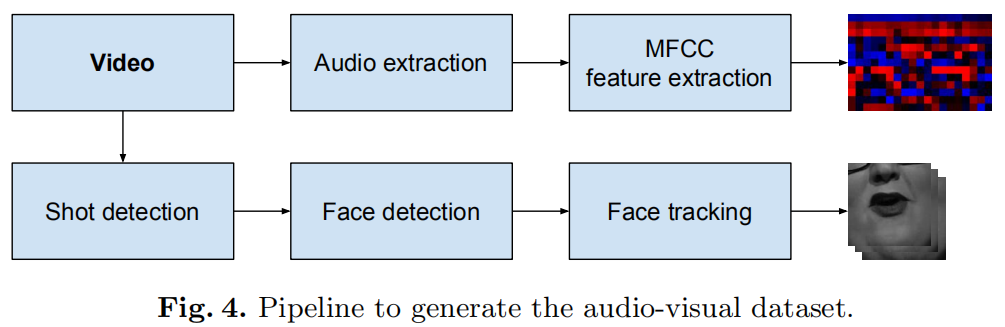
真假pairs的产生:真实的音视频对是同步的5帧,将音频随机移动2秒产生假的音视频对。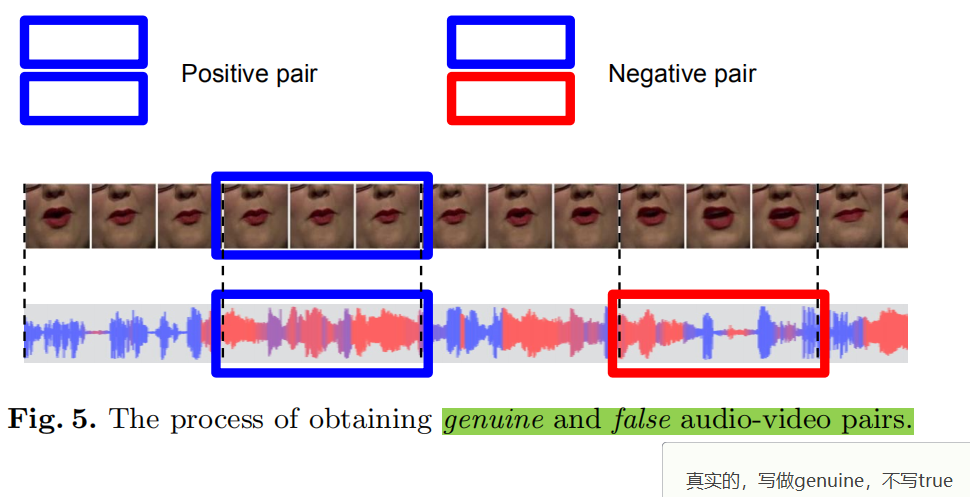
这样产生的数据是有噪声的,先在有噪声的数据上训练一个网络,然后使用训练过的网络通过拒绝 距离超过阈值的 positive pairs 来丢弃训练集中的假阳性。然后根据这些新数据重新训练网络。
这里有个关键的假设:假设我们下载的大部分视频都是近似同步的。尽管有些视频可能有假唱错误。卷积神经网络的损失函数和训练一般都能容忍有一定噪声的数据。
实验
只细看了第4.2节 说话人检测。
我们将时间偏移(同步误差)的置信值定义为欧氏距离的最小值和中值之间的差值(例如,图8中的两个图的这个值都在6到7之间)。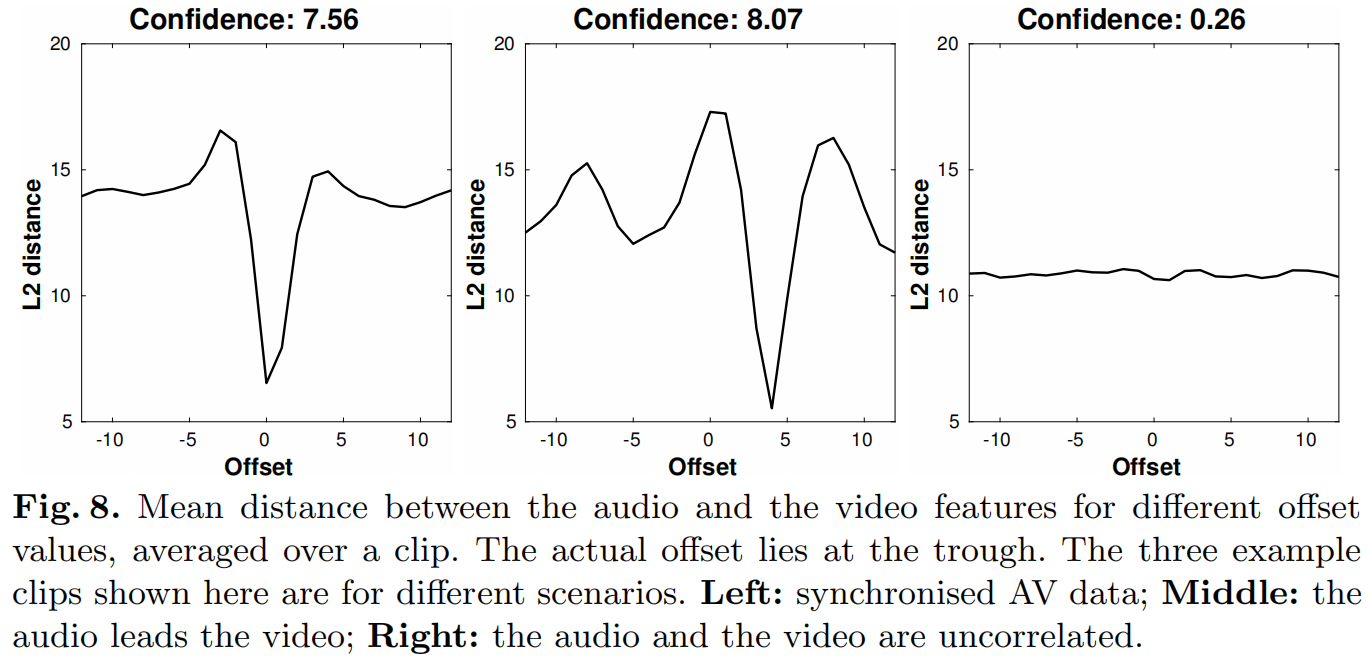
在多人场景中,说话人的置信度应该是最高的,没说话的人应该是0或者非常低的值。
others
可以用到的点:
- 数据增加。在卷积神经网络图像分类任务[14]中,应用数据增强技术可以提高验证性能,减少过拟合。
- 对于音频,音量在10%的范围内随机改变。我们不改变音频播放速度,因为这会影响重要的计时信息。
- 对于错误例子的产生,我们在时间上取随机的片段。
- 对于视频,我们采用了[14,24]在ImageNet分类任务上使用的标准增强方法(如随机裁剪、翻转、颜色漂移)。一个单一的转换应用于单个剪辑中的所有视频帧。Page 5。
- 数据产生的pipeline。根据代码,crop裁剪出了跟踪的人脸,再根据置信度筛选出和音频对应的说话人视频即可。
- 视频里出现了多人的画面,不要。
- 检测每一帧的conf,记录开始帧,如果连续1s conf 都大于一个值,这个片段可以采用,conf 太小就不要,直到这个视频结束。
code
run_pipeline 输出 *.avi 和 faces.pckl、scene.pckl、tracks.pckl。
$DATA_DIR/pycrop/$REFERENCE/*.avi- 保存连续4秒以上未切换镜头的人脸区域视频。如果一个场景出现多人,将给每个人单独存一个人脸区域视频。faces.pckl-inference_video()- 返回并保存一个字典dets,
{'frame':fidx**, **'bbox':(bbox[:-**1**]).tolist()**, **'conf':bbox[-**1**]} bbox = (pt[**0**]**, **pt[**1**]**, **pt[**2**]**, **pt[**3**]**, **score)
- 返回并保存一个字典dets,
scene.pckl-scene_detect()- 返回并保存scene_list,包含每个场景的 start 和 end。
- for i, scene in enumerate(scene_list):
print(‘ Scene %2d: Start %s / Frame %d, End %s / Frame %d’ % ( i + 1, scene[0].get_timecode(), scene[0].get_frames(), scene[1].get_timecode(), scene[1].get_frames(),))
- 对每个场景,如果它大于 min_track(默认100帧),执行
track_shot()(FACE TRACKING),- 返回一个
tracks,添加到alltracks。tracks.由track({'frame': frame_i**, **'bbox': bboxes_i})组成。 - 大概是每一帧里的人脸位置?如果有多人呢?
- 返回一个
tracks.pckl-crop_video()# 一个track:{'track': {'frame': array([ 0, 1,... 472], dtype=int64),'bbox': array([[581.19189453, 220.03631592, 795.09796143, 508.57928467],...[575.81396484, 215.0372467 , 790.09545898, 510.09634399]])},'proc_track': {'x': array([688.0317688 , ..., 681.43264771]),'y': array([364.05992126, ..., 359.61843872]),'s': array([143.39903259, ..., 144.09300995])}}# s是矩形长边的一半,x、y是bbox的中心点。
faces
[[{'track': 0, 'conf': 5.057046890258789, 's': 143.39903259277344, 'x': 688.0317687988281, 'y': 364.05992126464844}],...]
我需要做的是:在crop的视频里,裁剪出正在讲话的人。
[x] 根据 conf 判断谁在讲话,conf 写进了 faces.pckl。
- crop裁剪的区域是怎么设定的?
python run_syncnet.py —videofile ./data/30s.mp4 —reference 30s —data_dir xz_output
run_syncnet 输出 activesd.pckl
- $DATA_DIR/pywork/$REFERENCE/offsets.txt - audio-video offset values
run_visualise
- $DATA_DIR/pyavi/$REFERENCE/video_out.avi - output video (as shown below)
报错
Format avi detected only with low score of 1, misdetection possible!
好像是cv2和ffmpeg之间格式的问题。bug出在视频和音频合并这里,视频是cv2将一系列图片写成的。
视频和音频合并,在命令行里用ffmpeg没问题,但代码里就会报上面那行错,发现是最后2帧写不进去,Packet corrupt。
解决:ffmpeg 加一个参数 -fflags +discardcorrupt 表示错误帧丢弃。
颜色
clr = max(min(face[‘conf’] 25, 255), 0)
color = (0, clr*, 255 - clr)









好像代码里颜色的顺序不是rgb而是bgr

若有收获,就点个赞吧
0 人点赞
