Li_2021_Write a speaker
Lincheng Li et al., “Write-a-Speaker: Text-Based Emotional and Rhythmic Talking-Head Generation,” AAAI, May 7, 2021, http://arxiv.org/abs/2104.07995.
我们的框架包括一个独立于说话者的阶段和一个特定于说话者的阶段。
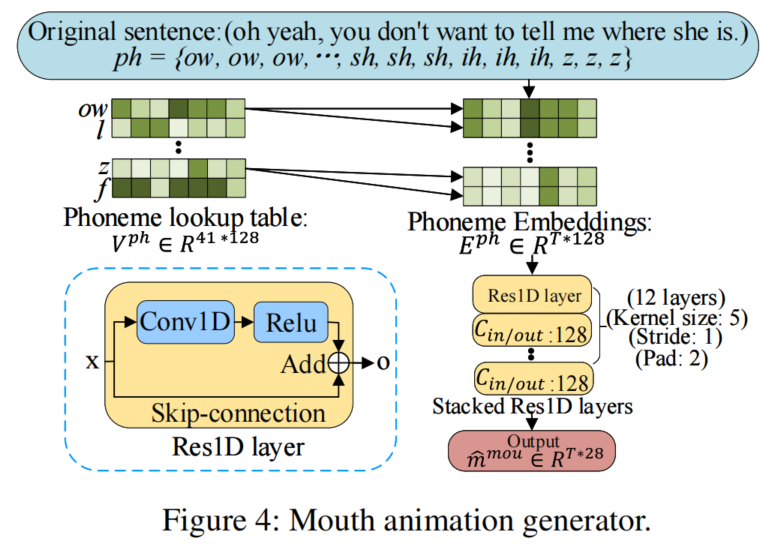
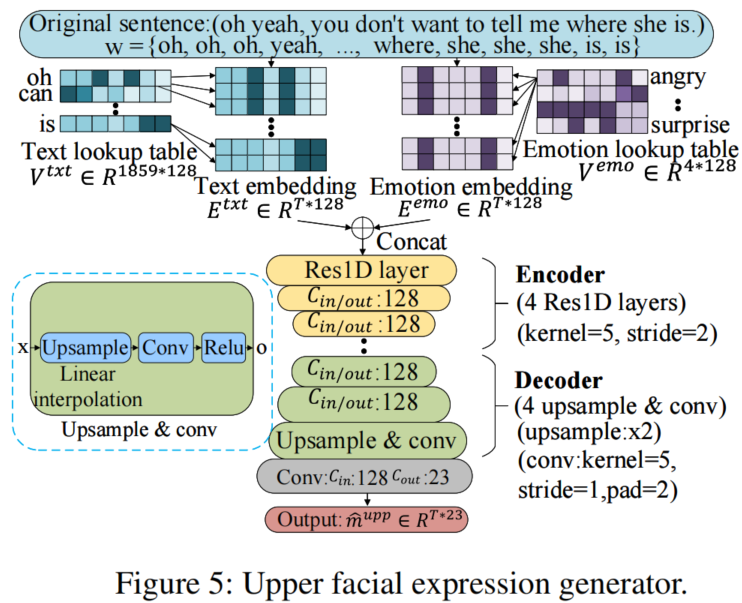
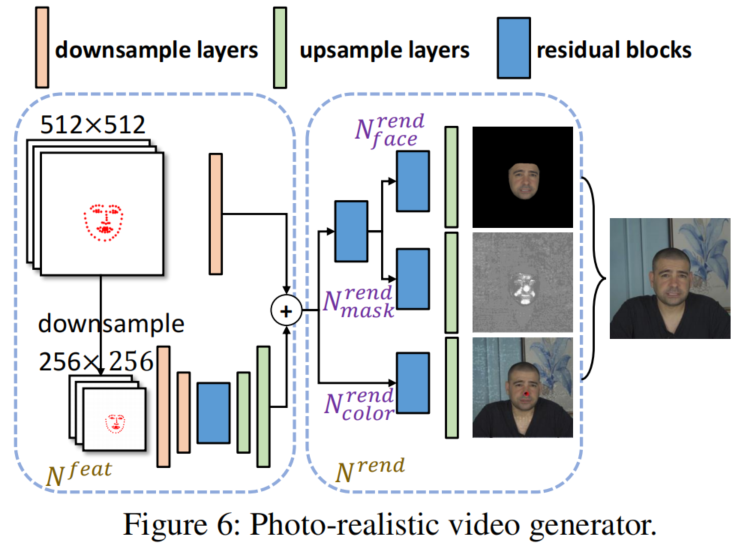
在说话者独立阶段,我们设计了三个并行网络,将输入文本分别映射到口部、上脸和头部的动画参数中。在说话者特定阶段,我们提出了一个三维人脸模型引导的注意网络来合成针对不同个体的视频。它以动画参数作为输入,并利用一个注意力掩模来操纵输入个体的面部表情变化。
此外,我们使用了一个动作捕捉系统来构建高质量的面部表情以及头部运动和听觉之间的对应关系,作为我们的训练数据。
由于我们的说话者独立网络输出的动画参数是通用的,对于特定的输入说话者需要定制动画参数,以实现逼真的视频生成。在特定的说话者阶段,我们将动画参数作为输入,然后开发了一个适应性注意网络,使被操纵的地标适应特定的人的说话特征。在此过程中,我们只需要更短的参考视频(约5分钟。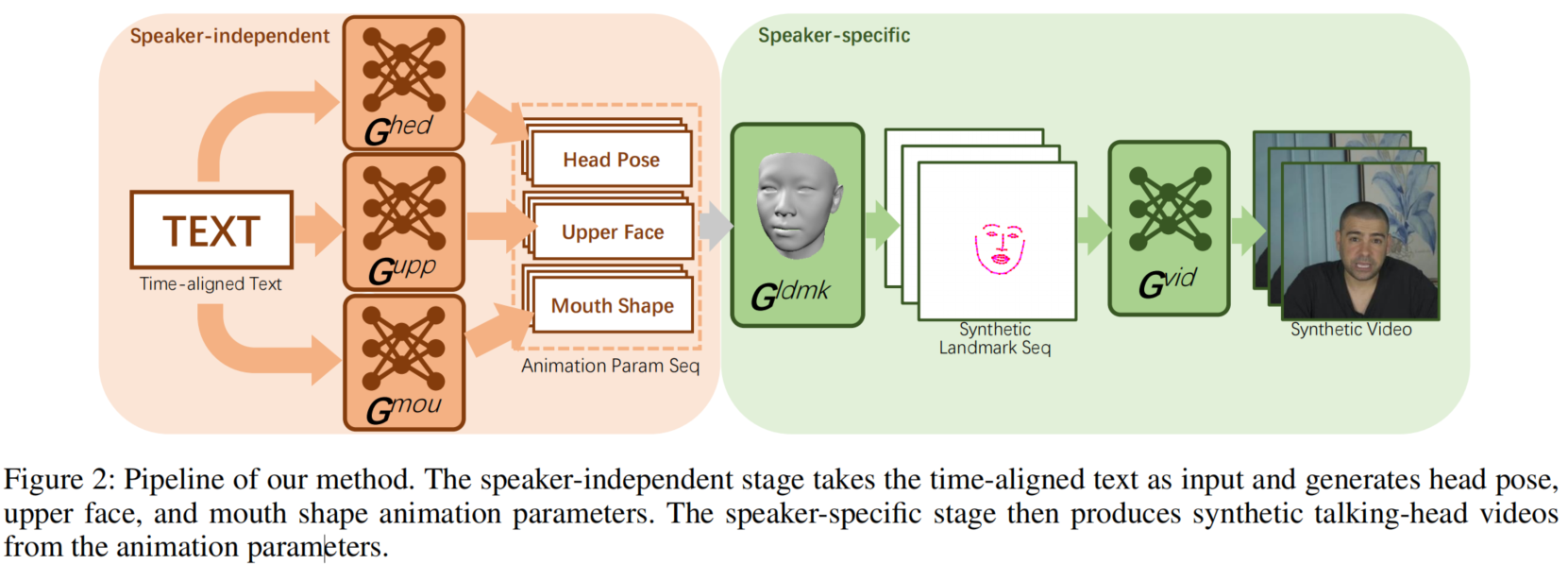

Eskimez_2021_emotalkingface
Sefik Emre Eskimez, You Zhang, and Zhiyao Duan, “Speech Driven Talking Face Generation from a Single Image and an Emotion Condition,” ArXiv:2008.03592 [Cs, Eess], July 21, 2021, http://arxiv.org/abs/2008.03592.
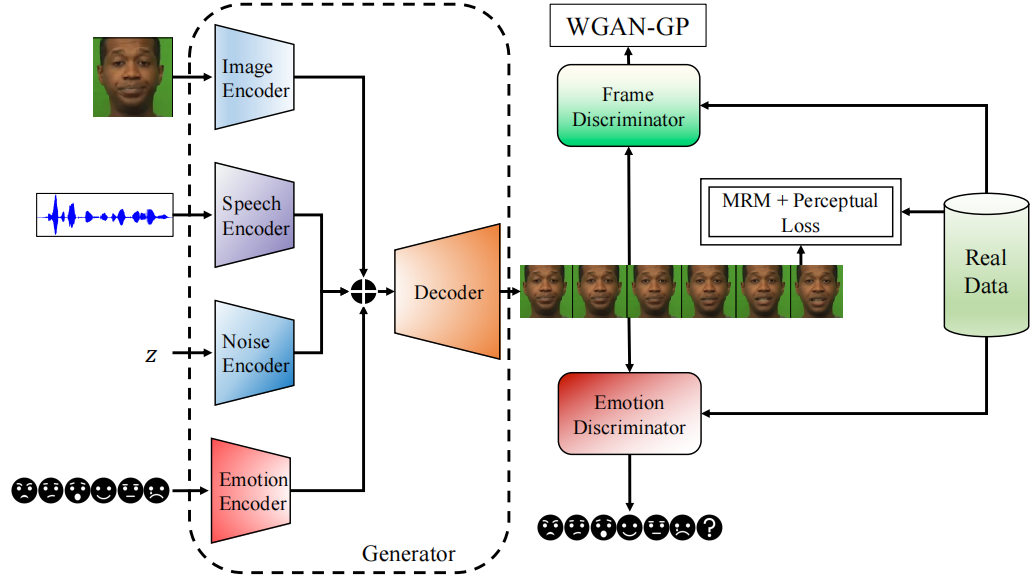
Ji_2021_EVP 情绪解耦并交叉连接
Xinya Ji et al., “Audio-Driven Emotional Video Portraits,” CVPR, May 19, 2021, http://arxiv.org/abs/2104.07452.
- 从音频中分别提取出情绪和content,使二者解耦合,并交叉连接作为训练数据。
- 从音频获取landmark,使用3D模型进行姿态对齐。
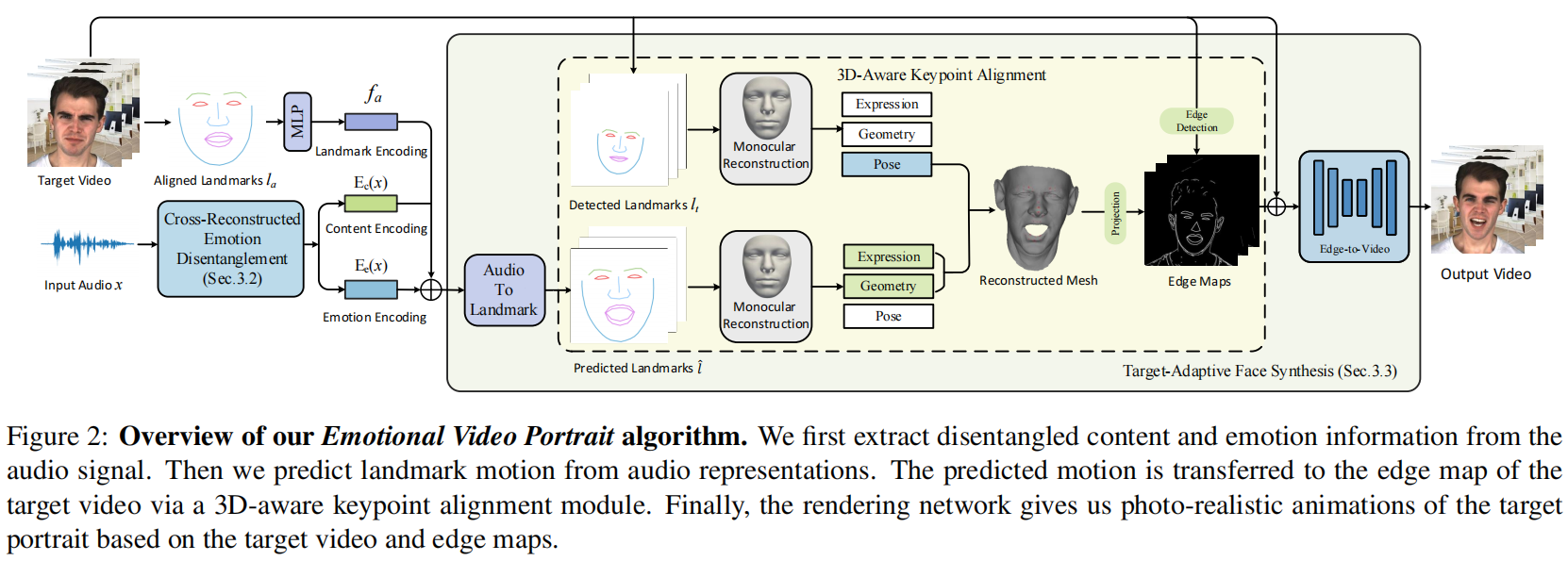
Fang_2022_FE-GAN 只输入语音特征
Zheng Fang et al., “Facial Expression GAN for Voice-Driven Face Generation,” The Visual Computer: International Journal of Computer Graphics 38, no. 3 (2022): 1151–64, https://doi.org/10.1007/s00371-021-02074-w.
- 生成器的输入只有语音特证,没有图像。
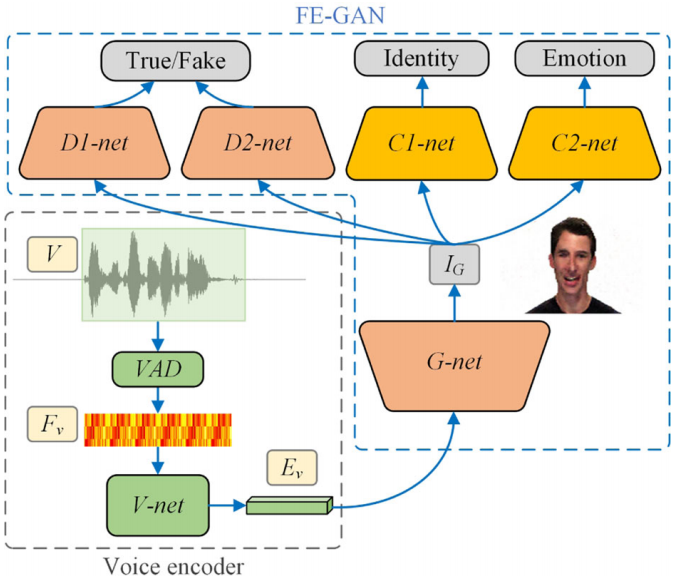
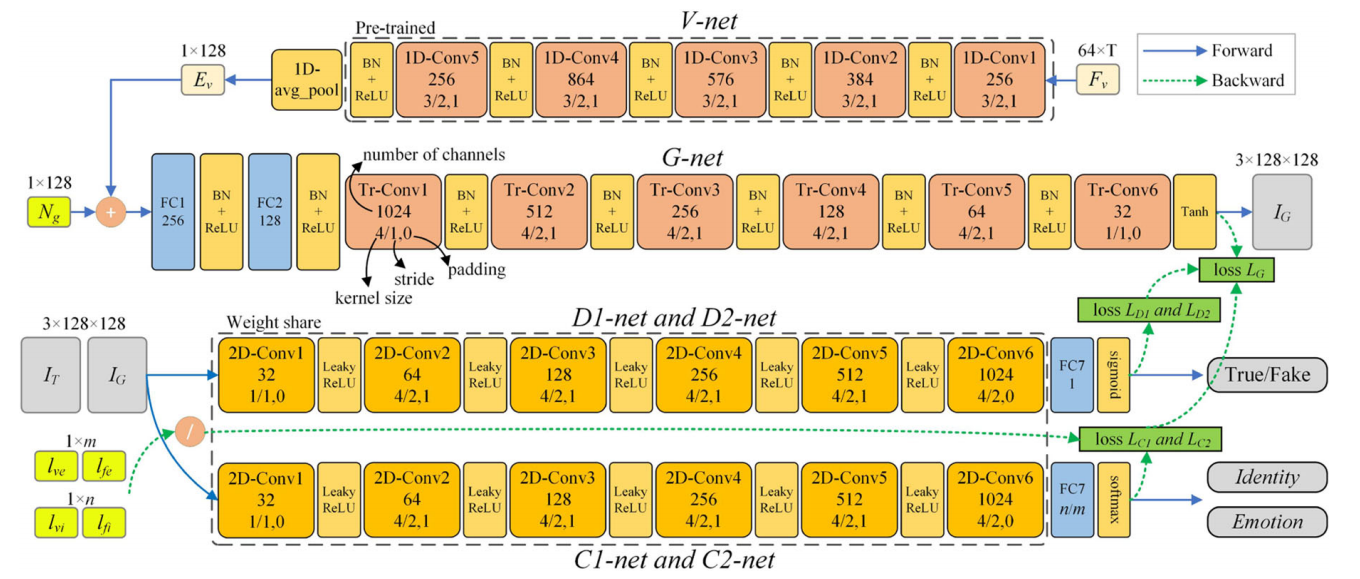
Sinha2022情绪分离
Sanjana Sinha et al., “Emotion-Controllable Generalized Talking Face Generation” (arXiv, May 2, 2022), http://arxiv.org/abs/2205.01155.
输入:单张图片+音频+情绪向量
语音情绪分离:We use features from a pre-trained automatic speech recognition model DeepSpeech [Hannun et al., 2014] for disentangling emotion from speech content of audio.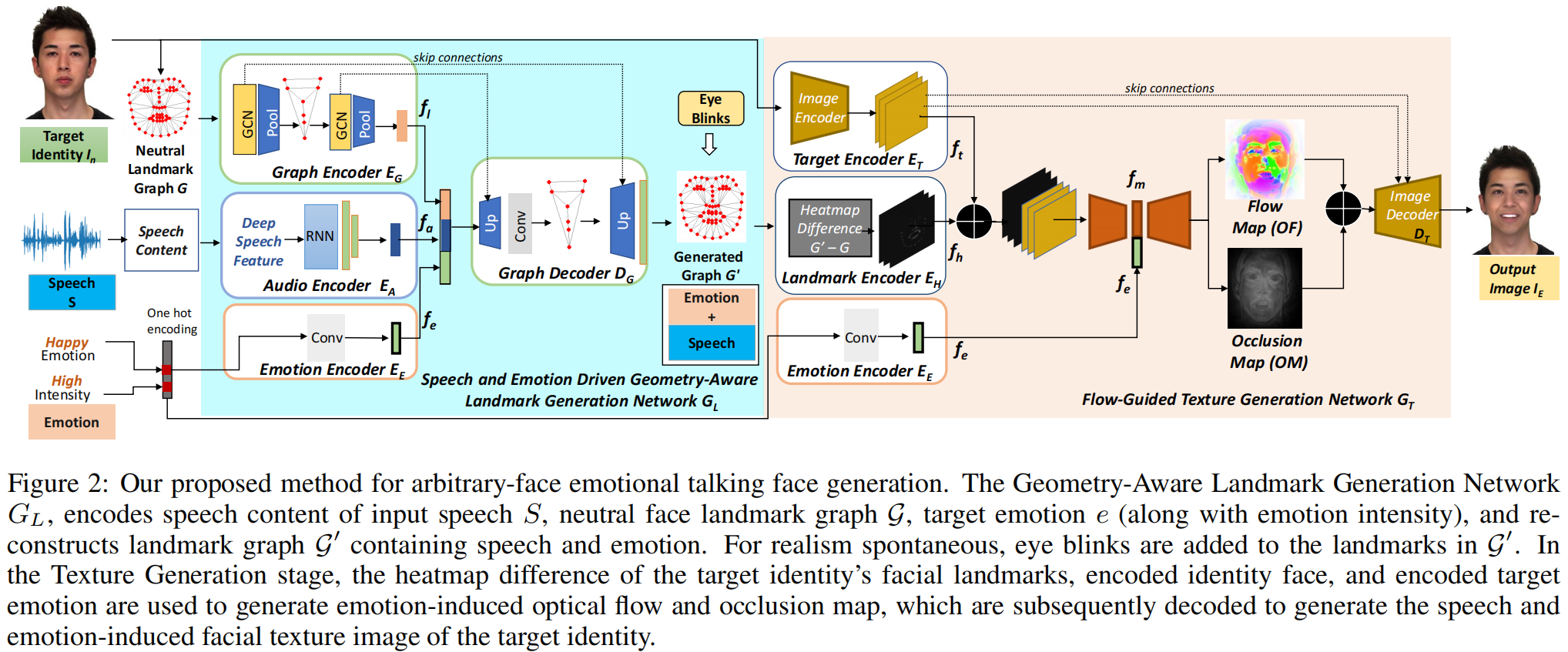
Ye_2022_Dynamic Neural Textures
Zipeng Ye et al., “Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions,” ArXiv:2204.06180 [Cs], April 13, 2022, http://arxiv.org/abs/2204.06180.
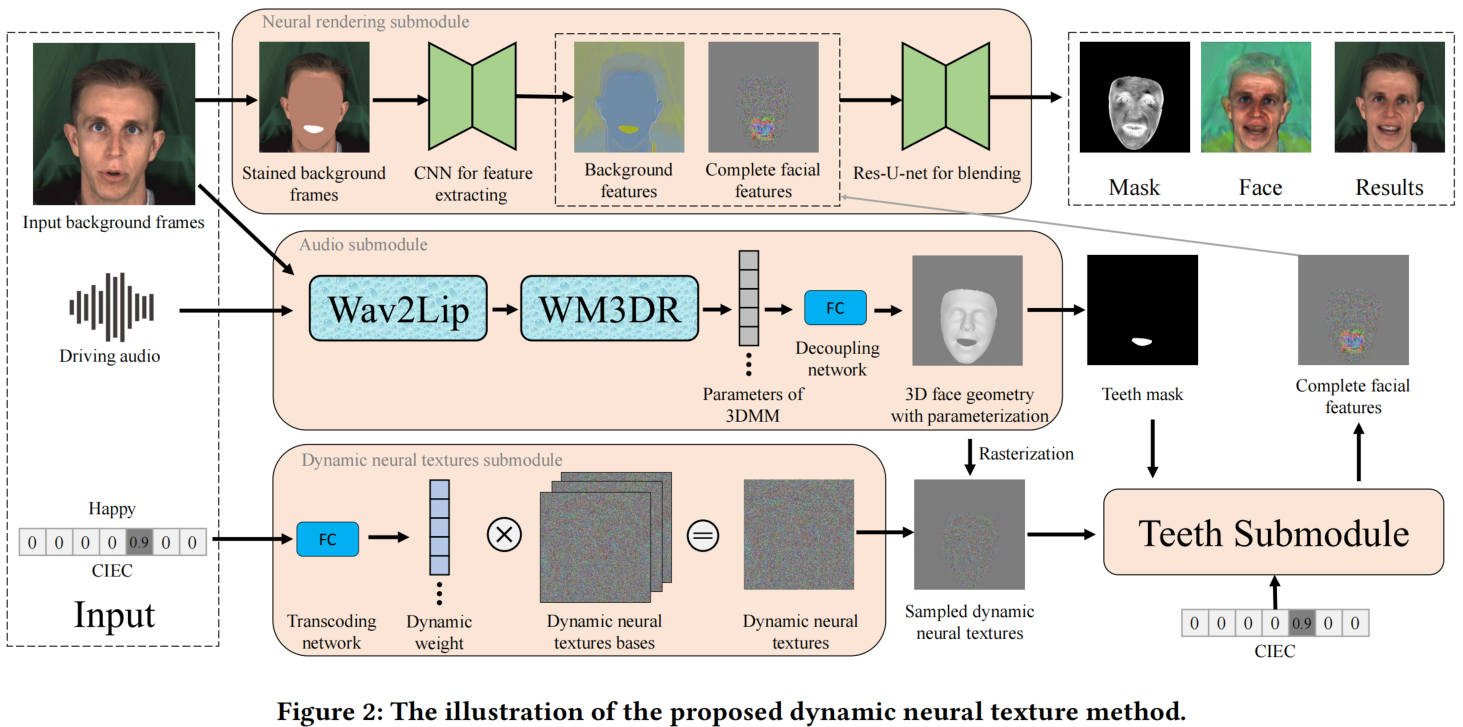
- 我们设计了一种新的神经网络,基于输入表达式和连续强度表达式编码(CIEC)生成图像帧(我们称之为动态神经纹理)的神经纹理。
- 我们的方法使用3DMM作为一个三维模型,对动态神经纹理进行采样。
- 3DMM不覆盖牙齿区域,所以我们提出一个牙齿子模块来完成牙齿的细节。
Ji_2022_EAMM 表情迁移
Xinya Ji et al., “EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model” (arXiv, May 31, 2022), http://arxiv.org/abs/2205.15278.
In this paper, we propose the Emotion-Aware Motion Model (EAMM) to generate one-shot emotional talking faces by involving an emotion source video. Specifically, we first propose an Audio2Facial Dynamics module, which renders talking faces from audio-driven unsupervised zero- and first-order key-points motion. Then through exploring the motion model’s properties, we further propose an Implicit Emotion Displacement Learner to represent emotion-related facial dynamics as linearly additive displacements to the previously acquired motion representations.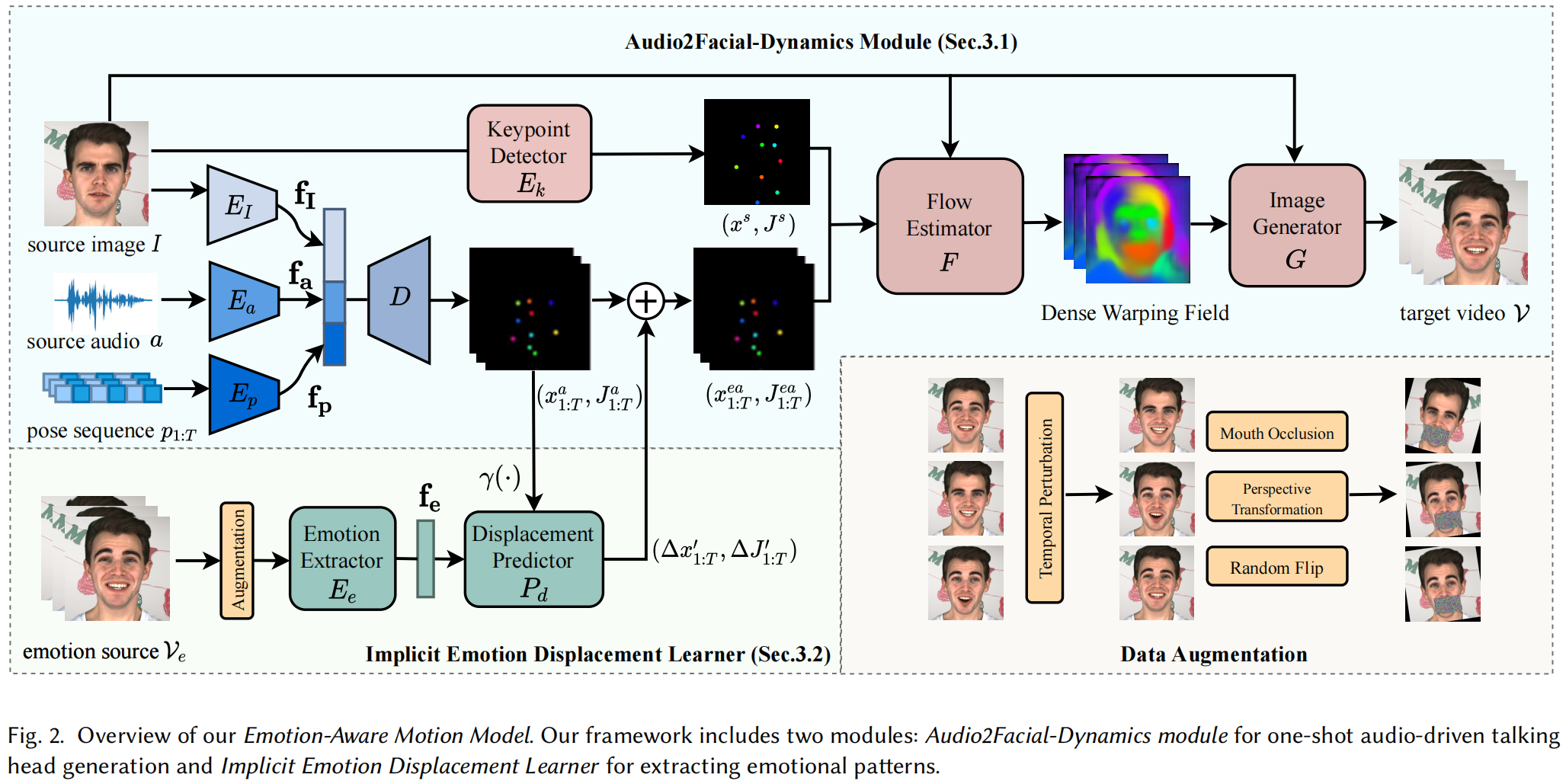


若有收获,就点个赞吧
0 人点赞
