Xin Wen et al., “Photorealistic Audio-Driven Video Portraits,” IEEE Transactions on Visualization and Computer Graphics 26, no. 12 (December 2020): 3457–66, https://doi.org/10.1109/TVCG.2020.3023573. code
主页 https://richardt.name/publications/audio-dvp/
看演示视频,视觉效果不错,人脸没有割裂感和伪影,但是口型和音频不是很同步。
解决什么问题
实现由语音驱动的人物肖像视频合成,可应用于视频会议、虚拟教育和培训场景。这项任务的主要挑战是如何从输入的语音音频中幻化出可信的、逼真的面部表达。
为了解决这个挑战,本文采用了一个由几何形状、面部表达、光照等表示的参数化3D人脸模型,并学习从音频特征到模型参数的映射。
贡献点
- 给定输入语音音频,可以生成目标人物的逼真肖像视频。一个三分钟的目标视频足以训练我们的完整pipeline,比现有方法所需的数据少得多。
- 提出了一个音频到面部表达的映射模块,该模块可以将身份无关的语音音频转换为目标人物的面部表示参数,仅通过在单个目标人像视频上训练。
- 通过广泛的用户研究来评估我们方法的有效性。
具体方法
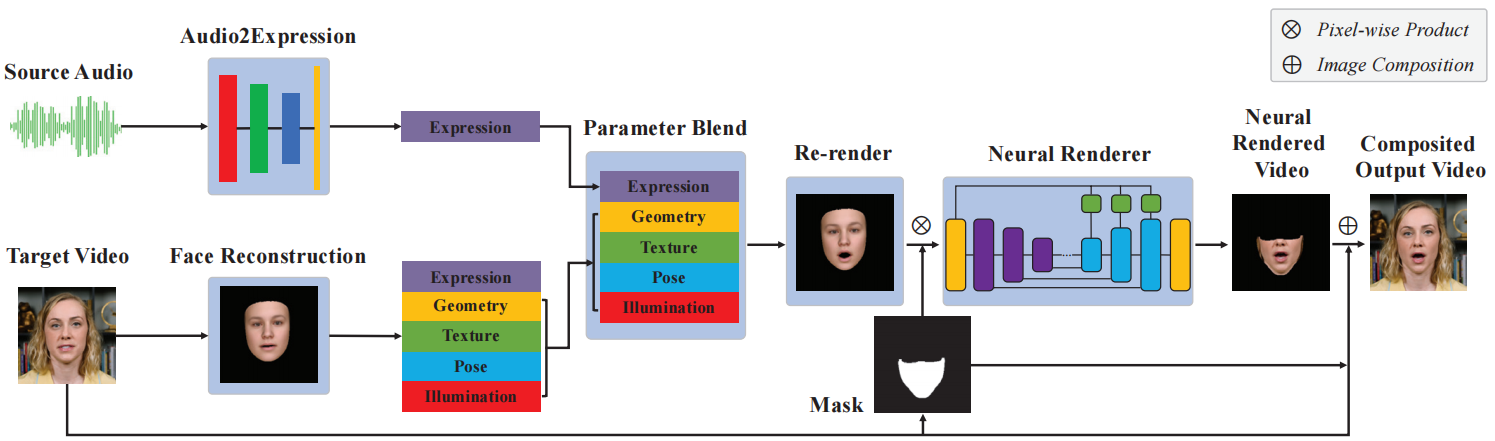
给定一段视频,进行如下步骤
- 重建一个带有每个帧的表情、几何、纹理、姿势和照明参数的参数化的3D人脸模型(章节3.1)。
- 计算从音频特征到同一参数3D人脸模型的面部表情参数的映射(第3.2节),
- 将表情参数与从目标视频重建的人脸模型混合,来创建一个新的面部,并重新渲染新面部模型的合成图像。然而重新渲染的图像并不逼真,所以有了下一步。
- 训练了一个神经人脸渲染器,将渲染的较低的人脸区域转换为逼真的区域,并将其合成为原始目标视频帧的最终结果(第3.3节)。
Monocular 3D Face Reconstruction
遵循Deng等人[16](微软 Deep3DFaceReconstruction 这篇论文)提出的基于单图像的方法,并将其应用于基于视频的三维人脸重建。
本节首先简要介绍我们使用的参数化人脸模型。然后描述图像生成过程,将三维人脸模型转化为二维图像。最后,讨论了用于人脸模型拟合的能量项。
- 人脸参数化
使用3DMM来表示人脸[4,17]。3DMM由一个带有 Nv 个顶点的模板三角形网格和一个仿射模型组成,该模型定义了面几何 v 和堆叠的每个顶点漫反射 r。系数{αk}代表几何,{δk}代表表达式,{βk}代表反射(颜色)。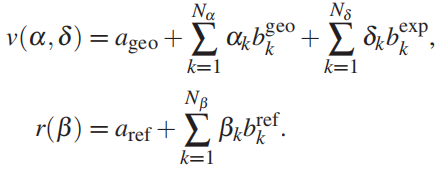
其中,矢量ageo,aref 分别表示平均面形几何和反射率, 为几何基,
为几何基, 为表达式基,
为表达式基, 为反射率基,都由主成分分析(PCA)从面部扫描数据中计算得出。
为反射率基,都由主成分分析(PCA)从面部扫描数据中计算得出。
采用2009巴塞尔人脸模型[39]用于人脸几何(ageo, bgeo)和反射率(aref, bref),并使用来自Guo等人的粗到精学习框架[23]的面部表情bexp来增强它,该框架构建于FaceWarehouse[7]。
设定Nα = 80, Nδ = 64和Nβ = 80。刚性头部姿态由旋转 R ∈ SO(3) 和平移 T ∈ R3表示。
- 图像生成过程
要将3D人脸模型X渲染为合成图像I,还需要对光照和相机建模。建模后即可计算图像空间坐标ui(X)和相应的颜色ci(X),传入栅格化器([20]+cuda)生成渲染的合成图像i(X,Π)
设定一个朗伯表面(Lambertian surface)和远处场景照明,使用球谐函数 (SH) 来近似环境照明: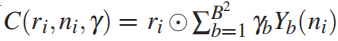
- B is the number of SH bands, We choose B = 3 bands of SH, with B2 = 9 coefficient vectors, resulting in the SH illumination coefficients γ ∈ R27.
- γb ∈ R3 are the RGB SH coefficients,
- Yb : R3 → R are SH basis functions,
- ri and ni are the reflectance and unit normal vectors of vertex i, respectively,
 is the element-wise product. Our complete face model can be represented by a vector
is the element-wise product. Our complete face model can be represented by a vector
综上,人脸模型可由向量 X = (α, δ, β, γ, R, T) ∈ R257 表示。
【注】
输出的257个数,其中80个是形状系数,80个颜色系数,64个表情系数,还有3个角度系数,3个尺寸系数,27个光照系数。角度系数、尺寸系数、光照系数和模型无关,它们的作用是对模型进行一定的旋转、放大或缩小,投上光照,生成一个二维投影。
- 人脸模型拟合
用 VGGFace2[9] 数据集对 ResNet-50网络[25] 进行预训练,从输入图像I估计人脸模型参数X,它比直接优化的结果更连贯。具体来说,我们将网络最后一个全连通层修改为97个维度(不含几何和反射率),并采用一种综合分析(analysis-by-synthesis)的方法,以最小化模型的合成渲染和输入图像之间的差异。重建损失结合了三个:密集光度对齐、稀疏关键点对齐和统计正则化。
- 通过计算面部区域
M中所有像素i的光一致性损失,来测量输入帧I和模型X渲染的合成图像 之间的光度差异:
之间的光度差异:

- 使用稀疏关键点对齐约束,以鼓励3D网格上的关键点投影到输入图像中相应的检测到的2D关键点附近。我们检测 NL = 68个关键点{s1,…,sNL},并计算稀疏关键点对齐损失作为投影关键点 uτi(X) 和检测关键点 si 之间的加权欧氏距离:
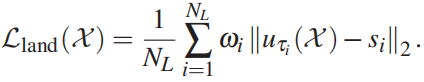
其中,τi为图像空间中关键点i对应的三维人脸模型的顶点指数,ωi为20个嘴关键点和12个眼睛关键点的特定关键点权重,设置为50,其他为1。
- 为了防止面形和反射率的退化,我们进一步在回归的3DMM系数上使用正则化损失Lreg(X),它强制对高斯分布下的平均人脸进行先验[16,49]。
综上,模型拟合的总loss函数为: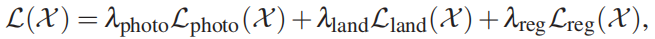
其中,设定 λphoto = 1.9, λland = 0.0016, λreg = 0.0003。关于详细的推导参考Genova[20]。在将模型拟合到完整的目标视频之前,我们随机选取8帧来回归每个actor的几何和反射率参数并保持不变。然后,在批大小为5、学习速率为2*10-5的目标视频上训练我们的人脸重建网络20个epoch。虽然本小节提供了人脸匹配的技术细节以及与之前工作的实现差异,但我们澄清这不是我们的主要贡献之一。
Audio to Facial Expression Mapping
先使用AT-net[11]算法从音频中提取高级特征。将输入音频流转换为MFCC特征,然后将MFCC特征送入AT-net,并将倒数第二层256-D输出特征作为鲁棒的高阶特征。即,输入音频 As 每 40ms 提取一个256-D的特征向量 F (对应于每秒25帧的一个视频帧)。
(Chen等人[11]首先将音频特征转换为人脸关键点作为中间特征,然后通过注意机制生成以人脸关键点为条件的语音框架。)
我们提出了一个 audio-to-facial-expression 映射网络H,该网络以音频高阶特征为输入,并预测表情参数。为了保持时间一致性,对于每个时间步长t,我们将音频特征作为沿滑动窗口内的时间轴的输入进行叠加,得到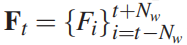 ,其中Nw = 3是滑动窗口的半径。我们将不存在的先验或后继特征F设为零。使用三层1D卷积来整合时空信息,使用64个节点的全连通层来输出预测的表达式系数。网络结构如表1所示。
,其中Nw = 3是滑动窗口的半径。我们将不存在的先验或后继特征F设为零。使用三层1D卷积来整合时空信息,使用64个节点的全连通层来输出预测的表达式系数。网络结构如表1所示。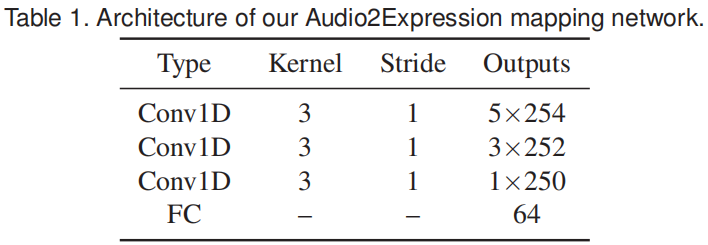
使用mean squared error (MSE) loss 训练本网络: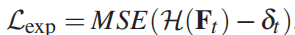
δt为重建目标视频在时间步长t时的表达式参数。
我们的音频到面部表情映射方法只需要在目标视频 Vt 上训练(通常为3分钟长),就能够将任意人的语音音频转换为目标行动者的面部表情参数。
Neural Face Renderer
将表达参数与从目标视频中重建得到的几何、反射率和光照相结合,通过图像生成过程重新渲染人脸模型,可以获得一系列合成的人脸图像。但是这些合成图像看起来并不逼真。所以我们使用了一个 Neural Face Renderer 神经脸部渲染器,用来将渲染的下半张人脸转换为逼真的区域,这些区域被合成到原始的目标视频帧中,作为最终结果。
masking strategy: distill the lower face region with a predefined mask that covers jaw, mouth and part of the nose. 我们使用神经人脸渲染器来预测 mask 的内容,并将预测的内容与目标视频合成以产生最终结果。mask策略使训练的重点在于下半张人脸的嘴部动画,避免了目标视频中任何动态背景的不稳定性。
首先,提取 mask:
- 将人脸的所有顶点标记为小于阈值 ξ = 0 的 y 坐标(假设模型空间坐标归一化为[-1,+1])。
- 栅格化 mask face,获得每一帧的 binary lower face mask。
直接将预测的内容合成到目标视频中会引入双颚,因为预测的表达参数与目标视频中的原始表达参数不一致,如图3所示。
受到 InverseFaceNet[31] 的启发,我们通过减少表达参数的第一个分量的值来完全打开嘴巴,扩展下巴周围的 mask,使下巴覆盖了颈部的一部分。这个过程如图4所示。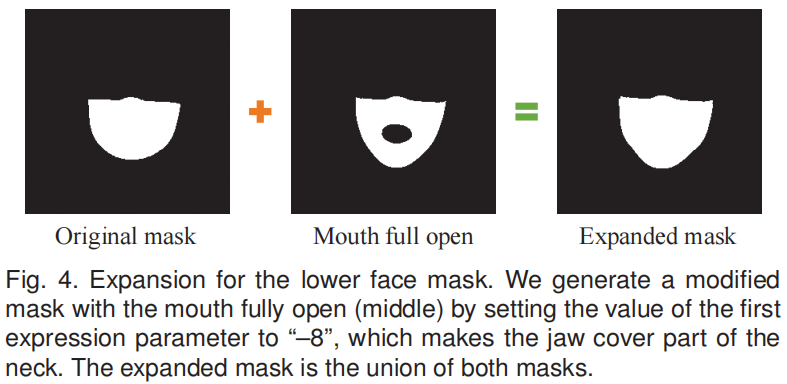
输入帧 和合成图像
和合成图像 的扩展 mask 部分作为成对的训练语料,如图5。
的扩展 mask 部分作为成对的训练语料,如图5。
Following deep video portraits [30],我们训练一个由基于 U-Net 的生成器 G 和鉴别器 D 组成的神经人脸渲染器。The discriminator employs a PatchGAN [27]. For the full network architecture, please refer to deep video portraits [30] and our source code.
Deep video portraits [30],将完整的3D头部位置、头部旋转、面部表情、眼睛注视和眨眼从源人物视频转移到目标人物的肖像视频中。Pipeline: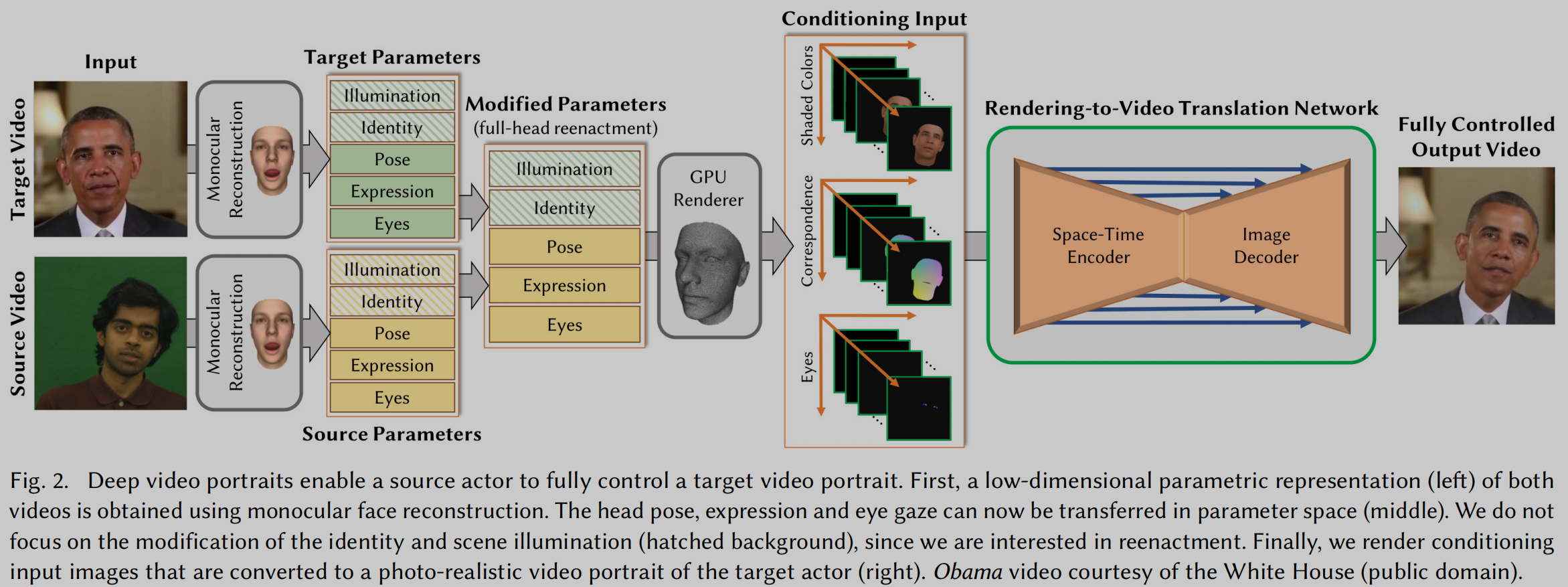
生成器 G 的最优网络参数可通过求解以下问题得到: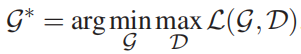
光度重建损失Lrec鼓励了合成输出的锐度,可以用公式表示为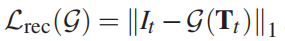
普通GAN的对抗性损失为: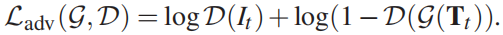
综上,完整的训练目标包括光度重建损失Lr和对抗损失Ladv,加权 λ = 100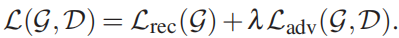
实验
数据集。我们在11个视频上测试我们的方法,这些视频来自 YouTube 和之前的作品[29]。表2提供了这些视频的摘要,包括它们的长度和语言。视频的平均长度为3分钟。
在预处理过程中,我们使用检测到的地标对齐所有视频帧,以确保上半身占据图像的主要空间。对齐的帧被进一步裁剪和调整到256*256像素。
Video Portrait Results
- Self-reenactment:使用视频原始的音频进行重新合成。

- 对儿童的视频和音频也可以很好地合成。
- 可扩展到别的语言。例如德语。
- 对目标人物使用任意人的语音都可以很好地合成。
- 可以使用合成的音频。
Visual Comparisons
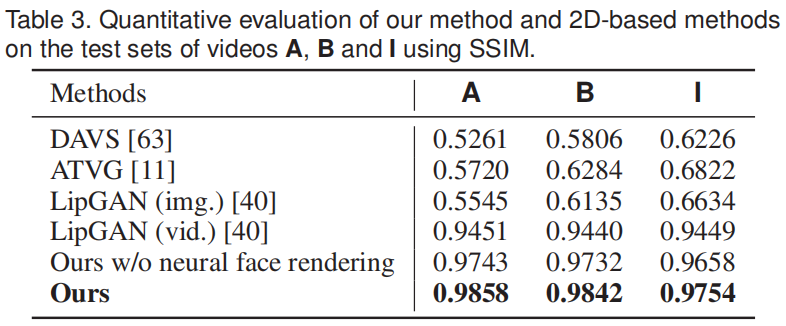
与 2D方法进行对比:DAVS [63], ATVG [11] and LipGAN [40]
与最近的基于GAN的方法 SDA[54] 对比(单张图片作为输入):
与Audio2Obama[46]进行对比(它根据音频特征预测嘴巴形状,并使用重建的3D人脸模型来合成嘴巴纹理):
Quantitative Evaluation
User Study
72名匿名参与者(26名女性,46名男性),平均年龄24.63岁(SD=6.94)。
5段视频,6种方法,共34段视频待评估(奥巴马的少了一个)。
参与者以乱序观看这34个视频并打分,从-2(强烈不同意)到 2(强烈同意)。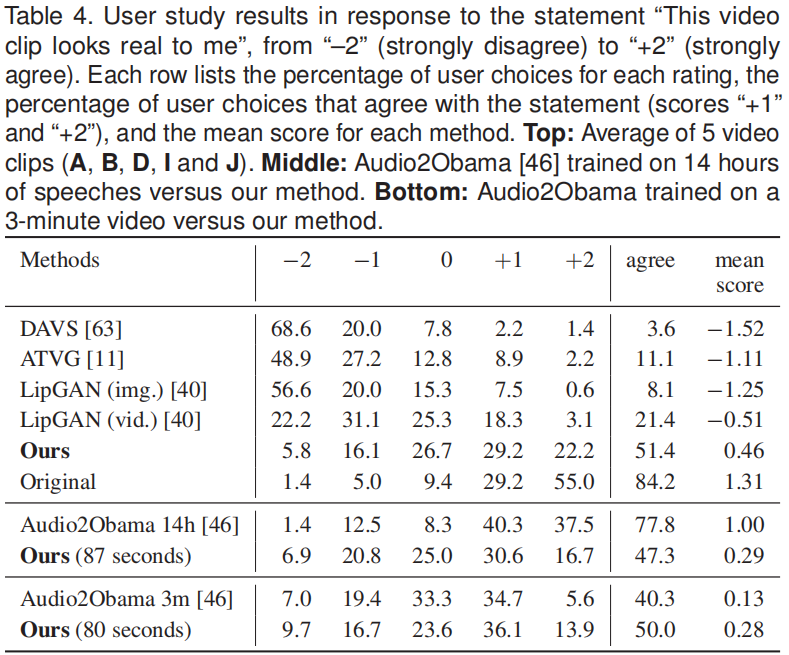
总结
对于目标人物,我们的方法需要一个大约3分钟的肖像视频作为训练数据。这是因为我们的管道包括一个针对个人的神经人脸渲染器,它需要针对每个目标提供足够的训练数据。这大量减少训练渲染器所需的数据,可能使用元学习[56]。
缺点:当原始头部姿势和源音频不兼容时,可能会导致不自然的伪影。例如,图13(a)显示了一幅不自然的头部运动姿势,嘴巴紧闭。这可以通过动态时间规整[46]来改善,它可以从目标视频中检索帧来更好地对齐嘴部运动。此外,当预测的表达参数被夸大时,我们的神经人脸渲染器可能会失败并产生伪像,见图13(b)。

若有收获,就点个赞吧
0 人点赞
