Sefik Emre Eskimez, You Zhang, and Zhiyao Duan, “Speech Driven Talking Face Generation from a Single Image and an Emotion Condition,” ArXiv:2008.03592 [Cs, Eess], July 21, 2021, http://arxiv.org/abs/2008.03592.
code https://github.com/eeskimez/emotalkingface
- 情绪单独设置为一个输入,而不是从语音中提取。
解决什么问题
视觉情绪表达,使图片中人物说话,口型和语音同步,并表达情绪。
贡献点
- 提出了一种新的基于分类情绪条件的说话面孔生成方法。
- 提出了一种情感辨别损失,可以对呈现的视觉情感进行分类。
- 利用视听模式中情绪不匹配的面部语音视频进行了人类情绪感知的初步研究。
数据集: CREAM-D
具体方法
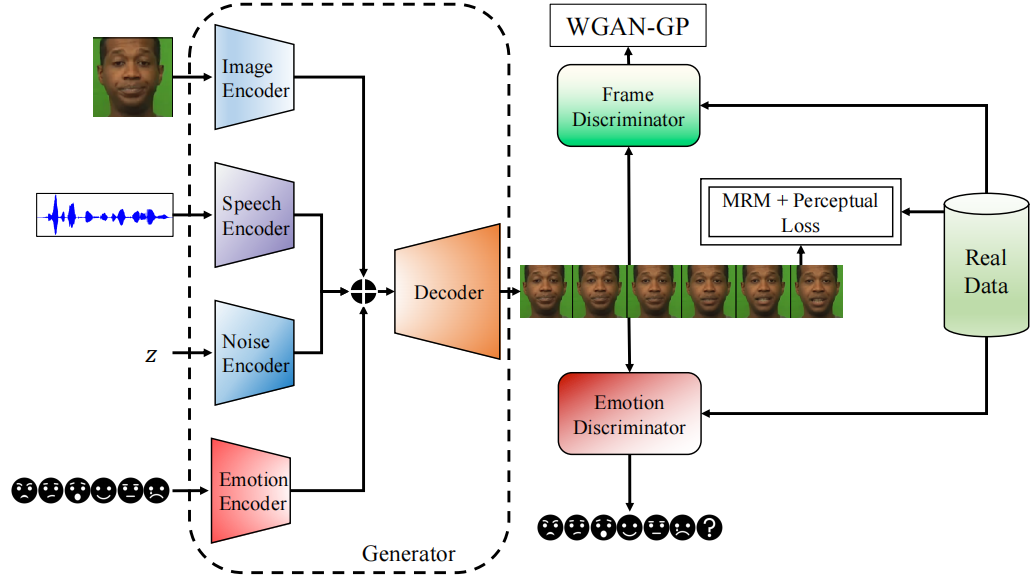
- 情绪不是从语音中提取,而是作为一个单独的条件输入。由此将情绪和语音解耦合。
- 使用GAN结构。
- 生成网络基于作者先前的工作[49],增加了一个情绪条件输入。主要包含:
- speech encoder, contains five convolutional layers with 1-D kernels. 接着是一个 context layer, to concatenate the past and future speech features. 然后进入一个全连接层和两个LSTM层,输出特证序列 speech embedding sequence。
- image encoder,contains six layers of 2-D convolutional layers. 在降采样时不使用 stride,而是用最近邻差值,这样可以消除生成图像中的伪影。使用 U-Net style 的跳跃连接,将最终的图像特征和中间层表示传递给 video decoder。
- emotion encoder,情绪标签转化为 one-hot 向量,输入到2个全连接层,输出情绪特征。每个时间步重复这个情绪特征。
- noise encoder,对视频的每一帧都生成一个标准高斯分布的噪声向量,输入到单层LSTM,输出噪音特征。This module aims to model the head movements that are not correlated with speech, image, and emotion.
- video decoder,将上述4个编码器输出的特征连接,对每个时间步,使用卷积层将该特征投影成 4*4 images(用了2 FC layers 和 reshape 操作)。【These 4 _× _4 images are concatenated channel-wise with the skip connections coming from the image encoder in the U-Net fashion for the next layers, except for the last layer. 】?
- 鉴别网络中有2个鉴别器,一个鉴别人脸表达的情绪,一个区分真实帧和生成帧。
- Frame Discriminator, 提高图像质量,保持人物身份。First, we repeat the target image for the number of frames in the input video and concatenate them together. Then, each frame is processed by five layers of 2-D convolutional layers. 展平后输入2层的全连接网络,它对帧的真假进行判断。
- Emotion Discriminator, 基于视频的情绪分类。第一部分和 Frame Discriminator 相同,是5层2D卷积层 + 2层全连接层。处理视频的每一帧后传给LSTM层,最后一个时间步的输出传递给一个全连接层,输出情绪类别的概率,有6种情绪+1个假类(参考[62])。训练鉴别器时计算真标签和预测标签的交叉熵损失,更新生成器时计算稀疏类别交叉熵损失。
目标函数
- Mouth Region Mask (MRM) Loss([49]中提出的),提高口型和音频的同步。嘴部区域的加权 L1 重建损失。【It uses a 2D Gaussian centered at the mean position of mouth coordinates as the weights. 】?
- Perceptual Loss,提高图像质量。使用预训练的VGG-19网络[63],分别计算真实视频和生成视频的中间特征(4,9,18,27和36层),计算中间特征的均方差损失。
- Frame Discriminator Loss,进一步提升图像质量,特别是锐度。Instead of the vanilla GAN loss, we use Wasserstein GAN for more stable training.
- Emotion Discriminator Loss,a categorical cross-entropy loss。
完整的目标函数是上面4个 loss 的加权和。
评价指标
在图像质量、视听同步和视觉情绪表达的客观评价上,该系统的性能优于最先进的基线系统。 对视觉情感表达和视频真实性的主观评价也证明了该系统的优越性。
客观评价:
- 图像质量方面,使用 Peak SNR (PSNR) 和 Structural Similarity (SSIM)。
- 视听同步性,使用 normalized landmarks distance (NLMD)
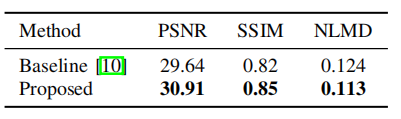
本方法和baseline生成的图像尺寸不同,为了对比的公平性,将真实图像、基线和本方法对齐到一个模板图像中,并使用相似性变换将它们裁剪成相同的大小。
- 情绪表达,训练了一个基于视频的情绪识别网络,结构和情绪鉴别器相同。对生成视频和真实视频进行情绪识别,结果如下。The
6-class emotion classifification accuracy on the ground-truth videos is 62.71%, which is comparable with [67], suggesting the validity of the video-based emotion classififier. 该网络没有用生成的视频进行训练。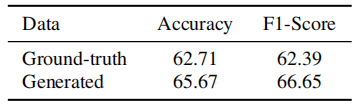
每个类别的分类结果(图1是真实视频,图2是生成视频):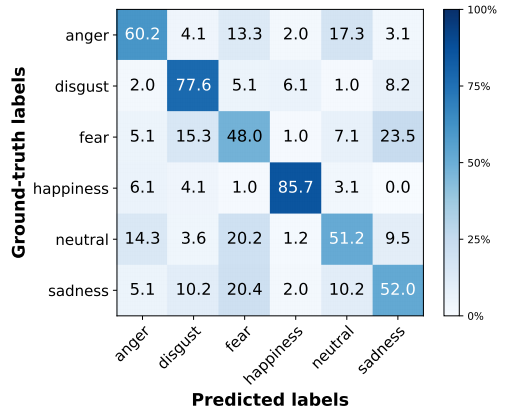
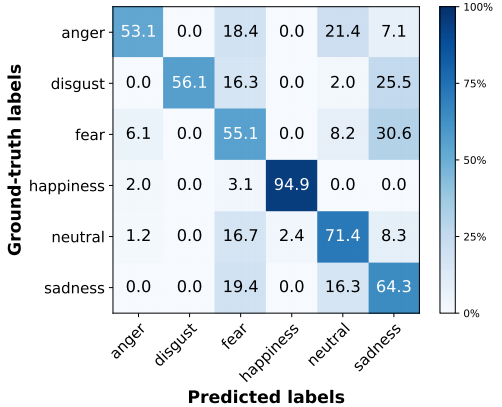
对于情绪分类结果的矩阵,有一些观察:
首先,它们都有一个很强的对角线。特别是,幸福是最容易分类的情感。这可能是因为快乐通常包含着不同于其他面部表情的微笑,这让分类器和我们的一代系统能够清楚地捕捉到它。
第二,有些情绪通常会相互混淆,比如恐惧和悲伤。在地面真实的视频中,恐惧和悲伤经常被错误地归类为厌恶,而在生成的视频中,没有其他情绪被错误地归类为厌恶。总的来说,相似之处大于不同之处,这表明生成的视频中的情感表达与真实的事实相似。
主观评价:【略】
通过主观评价来调查以下研究问题:1)我们的模型在视频渲染中表达情绪是否有效?2)我们的模型生成的视频有多真实?3)人们主要依靠哪种方式来感知情绪?
未来工作
- 提高生成的视频的图像质量。
- 将这项工作扩展到3D动画和渲染。

若有收获,就点个赞吧
0 人点赞
