Y. Deng, J. Yang, J. Xiang, and X. Tong, GRAM: Generative Radiance Manifolds for 3D-Aware Image Generation, IEEE Computer Vision and Pattern Recognition (CVPR), 2022. (Oral Presentation)
代码 https://github.com/microsoft/GRAM
原文
解决问题:
三维感知图像生成建模的目的是生成具有明确可控的摄像机姿态的三维一致的图像。最近的工作表明,在非结构化二维图像上训练神经辐射场(NeRF)生成器取得了很好的结果,但仍然不能生成具有精细细节的高逼真图像。一个关键的原因是,体积表示学习的高内存和计算成本极大地限制了在训练过程中用于辐射积分的点样本的数量。采样不足不仅限制了生成器处理细节的表达能力,而且由于不稳定的蒙特卡罗采样引起的噪声,阻碍了有效的GAN训练。
解决方法:
我们提出了一种新的方法生成辐射流形( Generative Radiance Manifolds,GRAM),调节在二维流形(2D manifolds)上的点采样和辐射场学习,体现为一组在三维体积上学习的隐式曲面。对于每一条观察射线,我们计算射线-表面的交点,并累积它们由网络产生的亮度。通过训练和渲染这种辐射流形,我们的生成器可以产生高质量的图像,具有真实的细节和很强的视觉三维一致性。
我们的优点
- 通过将采样和辐射学习限制在一个约化空间中,而不是在体积中的任何地方,它极大地促进了细节学习。
- 该网络可以很容易地学习在表面流形上生成薄的结构和纹理细节,保证在GAN训练过程中在图像上有投影并接受监督。
- 此外,我们生成的图像不受蒙特卡罗采样不足引起的噪声模式的影响,因为光线面交叉点是确定性计算的,并且在射线之间平滑变化。即使只有很少的点样本(即学习很少的表面),我们的方法仍然可以学习生成高质量的结果。
- 作为一个意外,在推理时,我们可以通过预先提取具有其亮度的表面来实时渲染生成的实例。
我们的隐式曲面被定义为由轻量级MLP网络预测的标量场中的一组等面。采用另一种用于产生辐射的MLP,我们使用类似于[11]的结构。我们以可微的方式提取射线-表面相交,并使用对抗性学习对整个框架进行端到端训练。正交于我们新的辐射流形设计,我们也探索了网络架构和训练方法的增强。特别是,我们受[29]的启发修改了[11]的网络结构,并删除了其中使用的渐进增长策略。渐进增长不仅引入了额外的超参数来调优,而且可能导致传统2D GAN [29]中显示的图像质量下降。我们的方法通过去除它会产生更好的结果。
我们的方法在多个数据集上进行了评估,包括FFHQ [28],Cats [71]和CARLA [16,58]。
3. Approach
给定一组真实图像,我们学习一个三维感知图像生成器G,它以随机噪声z∈Rd∼pz和相机姿态θ∈R3∼pθ作为输入,并输出姿态θ下合成实例的图像 I: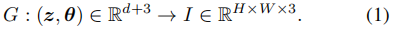
图2显示了G的整体结构,它由一个流形预测器M和一个辐射发生器Φ组成。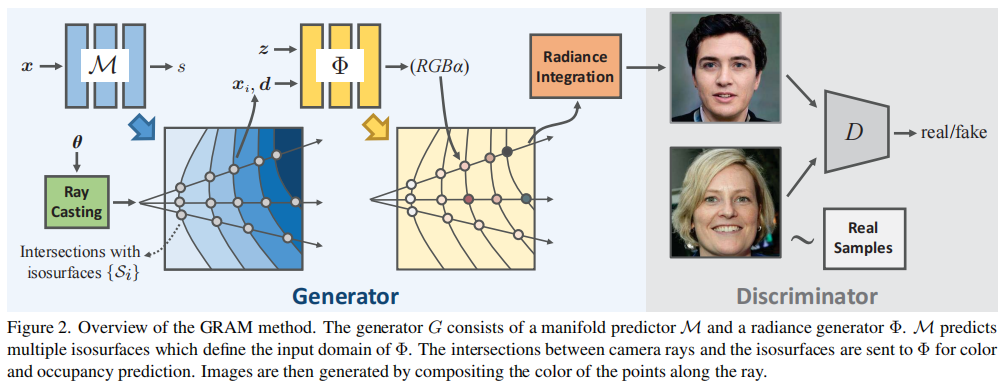
- 流形预测器(manifold predictor)M定义了一个标量场,它推导出一个辐射产生的简化域(a reduced domain for radiance generation),它由多个隐式等值面组成(Sec3.1)。
- 给定一个潜在的代码z,辐射发生器Φ生成流形上点的占用率和颜色(Sec3.2)。
- 然后,通过沿着每个观察射线的流形点的颜色累积来生成图像(Sec3.3)。
- 整个方法在一个对抗性的学习框架中进行端到端训练(Sec3.4)。
经过训练后,GRAM可以从不同的角度呈现高质量且3d一致的图像。
3.1. Manifold Predictor 流形预测器
流形预测器M 预测了一个简化空间,简化空间用于点采样和辐射场学习,这是在所有生成的实例中共享的。我们将它实现为一个标量场函数,可以确定一组等值面。具体来说,M是一个轻量级的MLP,它以一个点x作为输入,并预测一个标量值s: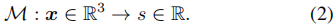
根据预测的标量场,我们得到了具有不同水平{li}的N个等值面{Si}: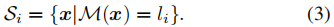
这些级别都是预定义的常数值。请注意,虽然标量场是在要渲染的场景的三维体积中定义的,但标量值本身没有物理意义,级别{li}可以简单地选择。
我们定义辐射发生器的输入域在这些表面上。 Let {xi} be the N intersections between a camera ray r = {o + td, t ∈ [tn, tf ]} and {Si}: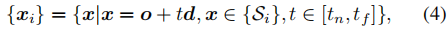
其中,o和d为射线原点和方向,tn和tf为近平面和远平面参数。我们只将{xi}传递给辐射发生器Φ,进行辐射产生和动态渲染,如图2所示。由于没有关于最优等面的先验知识,我们在生成对抗训练过程中共同学习它们。
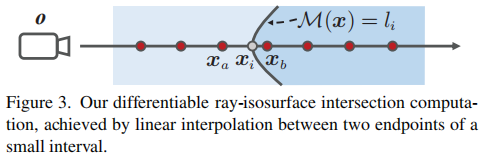
用GAN训练流形预测器M需要一个可微的射线-表面相交计算方案,以反向传播对抗性损失。为此,我们遵循Niemeyer等人的[48]的策略来计算交叉点。如图3所示,我们沿着近平面和远平面之间的光线均匀地采样点,并提供给它们,以得到它们的值s。然后我们搜索某一标量水平li所处的第一个区间,并通过以下区间的两个端点之间的线性插值计算交集: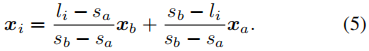
我们将M实现为一个具有3个隐藏层的轻量级MLP,因此可以使用等式对密集点(我们实现中的64个点)进行采样,以获得准确的交点 (5).
M的随机初始化可能会产生高度不规则的等位面,这不利于训练过程。在本工作中,我们采用了Atzmon等人[2]提出的几何初始化策略,即初始等位面接近球面。
3.2. Radiance Generator
给定一个潜在码z,我们的辐射生成器Φ为 位于学习流形上的点 产生辐射。具体来说,Φ由一个MLP参数化,该MLP对方向为 d 的点 x 产生占用率 α 和颜色 c(RGB):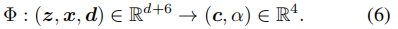
由于在我们的方法中,辐射是定义在表面流形上而不是整个体积上,所以我们在NeRF中生成占用率α而不是体积密度σ,遵循[49,74]。
Φ的网络结构改编自FiLM SIREN[11]的主干,如图I所示。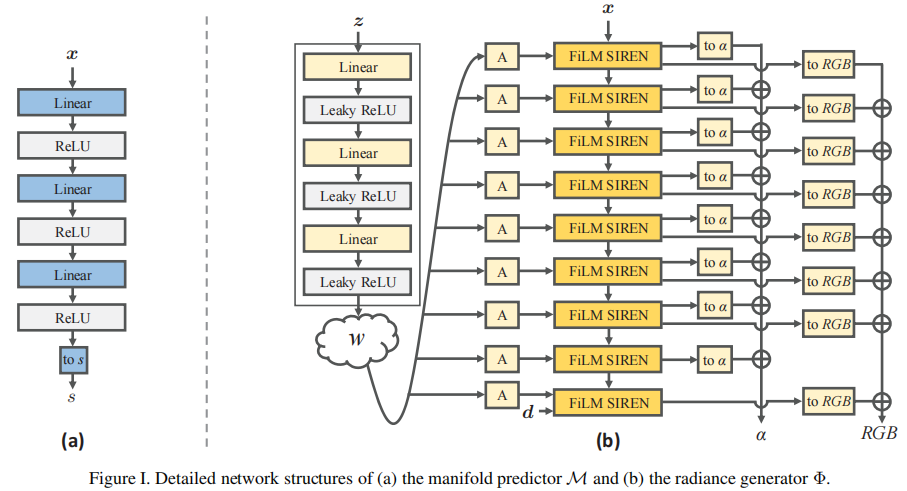
受StyleGAN2 [29]的启发,我们在不同级别的输出层之间使用跳过连接。通过这种方式,不同的输出层预测不同层次的细节,并组合在一起形成最终结果。这种变化不仅消除了以前方法中使用的渐进增长策略的必要性,而且在我们的方法中产生了更好的结果,如实验所示。
3.3. Manifold Rendering
对于一个相机射线r,它与表面流形相交于点{xi},从近到远跟随等式(4),渲染方程可以如[49,74]写成: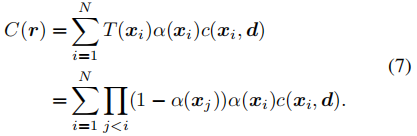
我们的渲染方案明显不同于NeRF中的原始体积渲染,后者采用了分层随机采样策略(NeRF-H)。由于采样的随机性,NeRF-H的采样点可能在相邻射线之间发生显著变化,导致渲染图像上的噪声模式(见图11)。
相比之下,我们只使用相机射线和表面流形之间的交点,这是确定性计算的,并在射线之间平滑变化,而不是以蒙特卡罗的方式选择整个体积空间中的点。这有助于我们消除图像生成中的随机性,并使每条射线用更少的点样本来训练生成器。此外,它极大地促进了精细的细节的学习,因为高频结构和纹理可以很容易地生成在表面流形上(见表2和表3)。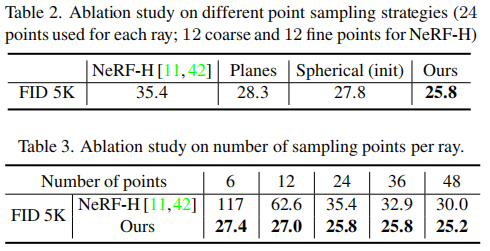
3.4. Training Strategy
在训练阶段,我们从先验分布pz和pθ中随机抽取潜在码z和相机姿态θ。生成器G以相应的潜在代码和姿态为输入,输出合成图像。我们从具有先验分布的训练数据中采样真实图像。在标准的GAN [20]中,鉴别器D接收生成的图像和真实的图像,并判断它们是假的还是真实的,为此我们使用与[11]中相同的CNN结构。我们使用非饱和GAN损失与R1正则化[39] 训练所有网络,包括流形预测器M,辐射发生器Φ和鉴别器D: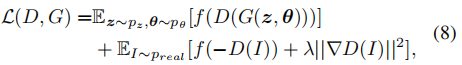
where f(u) = log(1 + exp(u)) is the Softplus function.
此外,我们发现,对于某些对象,只有对抗性损失的训练过程有时对随机初始化很敏感。在一些情况下,学习到的凸物体的三维几何可能会变成凹的(见Sec B.3)。为了解决这个问题,我们可以选择添加一个姿态正则化项来强制生成器在正确的姿态下生成图像: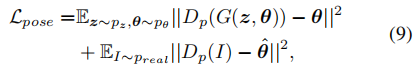
其中,Dp是鉴别器D的一个附加分支,用于预测给定图像的相机姿态,而θˆ是真实图像的姿态标签。我们发现,这种损失也可以略微提高图像的生成质量,没有观察到的凹几何问题。
本文主要引用
[11] Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit generative adversarial networks for 3d-aware image synthesis. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5799–5809, 2021. 1, 2, 3, 4, 6, 7, 8, 12, 13, 19
[29] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In IEEE/CVF Conference on Computer Vision and Pa
关于 NeRF + GAN,可以看看,,介绍了GRAF、GIRAFE、pi-GAN

若有收获,就点个赞吧
0 人点赞
