代码地址:https://github.com/Fanziapril/mvfnet
环境配置
conda create -n mvfnet python=2.7- 安装 pytorch
要求安装pytorch 0.4.0,conda install pytorch=0.4.0 cuda92 -c pytorch,在python中import torch,报错ImportError: libcudart.so.9.0: cannot open shared object file: No such file or directory。
改成安装pytorch 1.0.0, conda install pytorch==1.0.0 torchvision==0.2.1 cuda100 -c pytorch。不行,后面运行时会报错cannot import name download_url_to_file,版本太低。要安装 pytorch 1.2.0 之后的版本。
conda install -c 1adrianb face_alignmentModel_shape.matandModel_Expression.matfrom 3DDFA.Model_shape.mat要用代码生成。在3DDFA_Release\Matlab\ModelGeneration路径下,下载BFM模型中的01_MorphableModel.mat,运行ModelGenerate.m。
- download the CNN model from here.
test
python test_img.py --image_path ./data/imgs --save_dir ./result
报错与解决
1. No module named parse
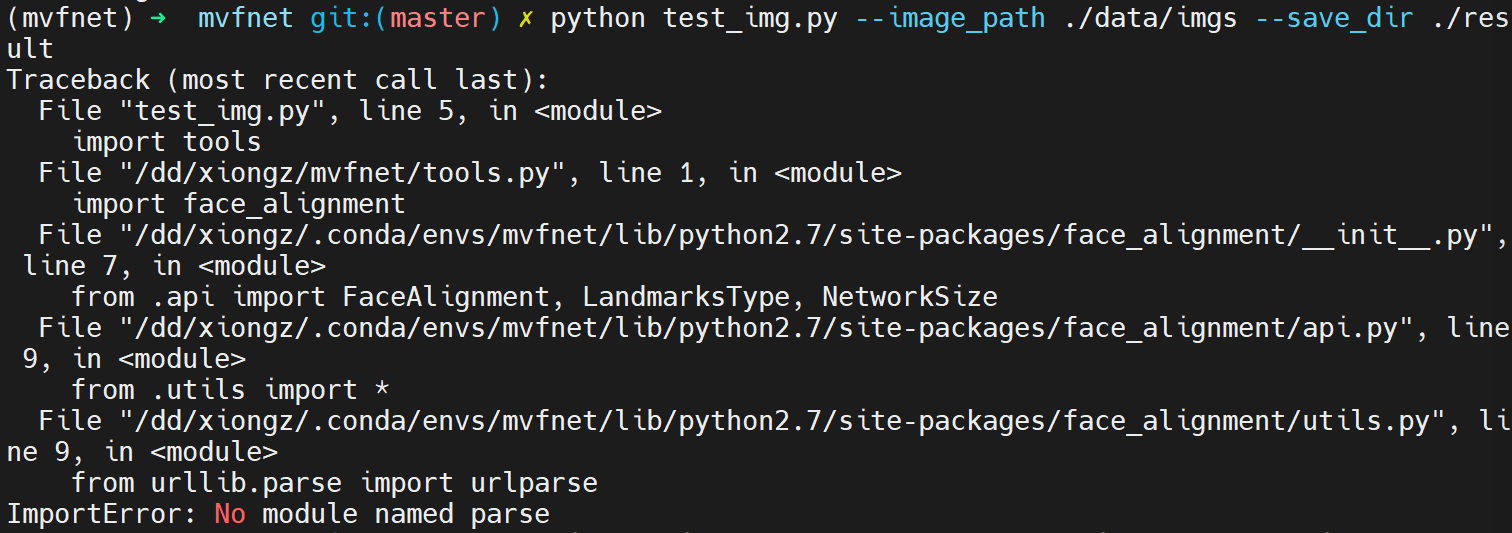
修改报错行代码为:
try:from urllib.parse import urlparseexcept ImportError:from urlparse import urlparse
2. cannot import name download_url_to_file
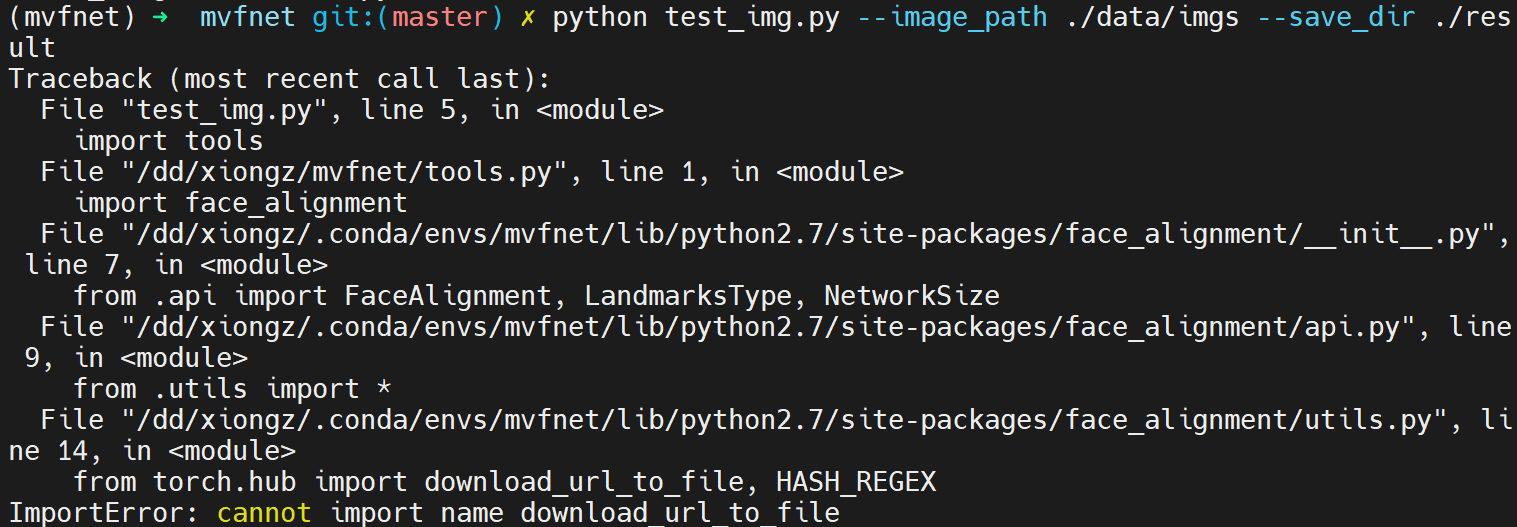
The version of pytorch may be too low. Before 1.2.0 there is no download_url_to_file in torch.hub. Please upgrade pytorch.
输入输出
输入:正视、左、右视角各一张。


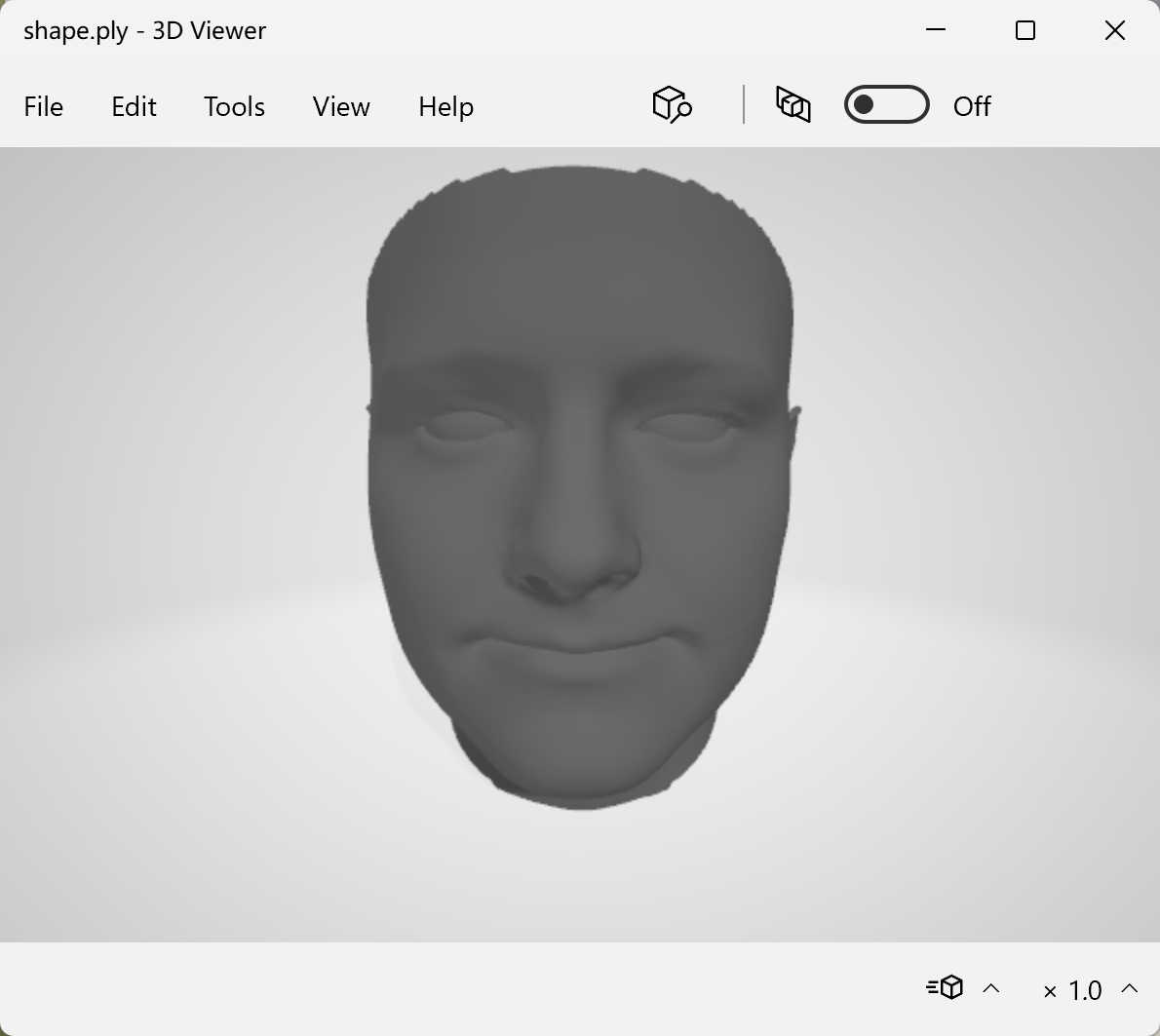
输出:一个shape.ply文件。展示: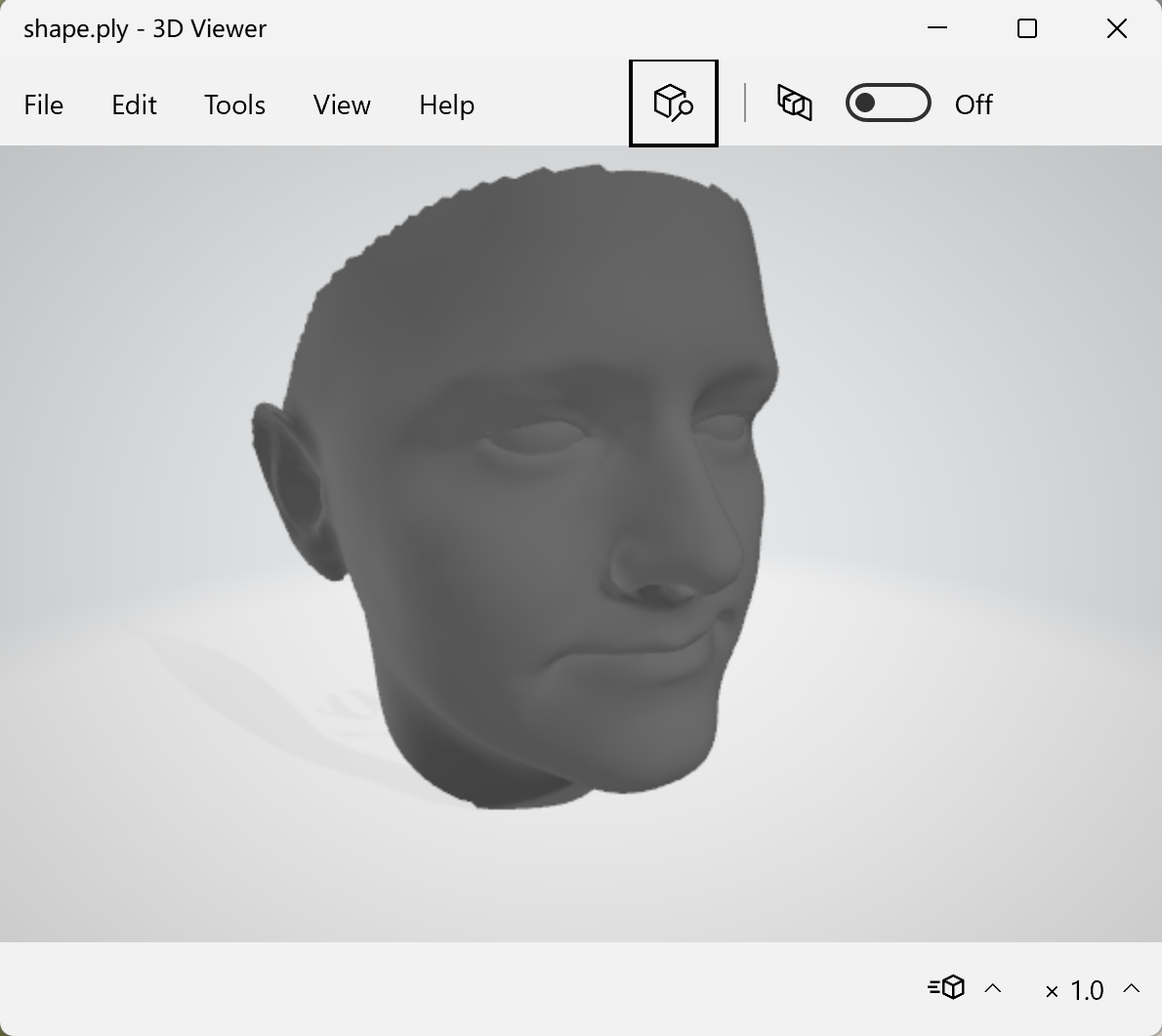
代码解读
读取输入的3张图片,
imgA = Image.open(os.path.join(options.image_path, 'front.jpg')).convert('RGB')imgB = Image.open(os.path.join(options.image_path, 'left.jpg')).convert('RGB')imgC = Image.open(os.path.join(options.image_path, 'right.jpg')).convert('RGB')imgA = transforms.functional.to_tensor(imgA)imgB = transforms.functional.to_tensor(imgB)imgC = transforms.functional.to_tensor(imgC)input_tensor = torch.cat([imgA, imgB, imgC], 0).view(1, 9, 224, 224).cuda()
通过CNN模型,获得预测的人脸参数
model = VggEncoder()model = torch.nn.DataParallel(model).cuda()ckpt = torch.load('data/net.pth')model.load_state_dict(ckpt)preds = model(input_tensor)
模型细节:
class VggEncoder(nn.Module):def __init__(self):super(VggEncoder, self).__init__()self.featChannel = 512self.layer1 = tvmodel.vgg16_bn(pretrained=True).featuresself.layer1 = nn.Sequential(OrderedDict([('conv1', nn.Conv2d(3, 64, (3, 3), (1, 1), (1, 1))),('bn1', nn.BatchNorm2d(64)),('relu1', nn.ReLU(True)),('pool1', nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True)),('conv2', nn.Conv2d(64, 128, (3, 3), (1, 1), (1, 1))),('bn2', nn.BatchNorm2d(128)),('relu2', nn.ReLU(True)),('pool2', nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True)),('conv3', nn.Conv2d(128, 256, (3, 3), (1, 1), (1, 1))),('bn3', nn.BatchNorm2d(256)),('relu3', nn.ReLU(True)),('conv4', nn.Conv2d(256, 256, (3, 3), (1, 1), (1, 1))),('bn4', nn.BatchNorm2d(256)),('relu4', nn.ReLU(True)),('pool3', nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True)),('conv5', nn.Conv2d(256, 512, (3, 3), (1, 1), 1)),('bn5', nn.BatchNorm2d(512)),('relu5', nn.ReLU(True)),('pool4', nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True)),('conv6', nn.Conv2d(512, 512, (3, 3), stride=1, padding=1)),('bn6', nn.BatchNorm2d(512)),('relu6', nn.ReLU(True)),('conv7', nn.Conv2d(512, 512, (3, 3), (1, 1), 1)),('bn7', nn.BatchNorm2d(512)),('relu7', nn.ReLU(True)),('pool5', nn.MaxPool2d((2, 2), (2, 2), (0, 0), ceil_mode=True)),]))self.fc_3dmm = nn.Sequential(OrderedDict([('fc1', nn.Linear(self.featChannel*3, 256*3)),('relu1', nn.ReLU(True)),('fc2', nn.Linear(256*3, 228))]))self.fc_pose = nn.Sequential(OrderedDict([('fc3', nn.Linear(512, 256)),('relu2', nn.ReLU(True)),('fc4', nn.Linear(256, 7))]))reset_params(self.fc_3dmm)reset_params(self.fc_pose)def forward(self, x):imga = x[:, 0:3, :, :]feata = self.layer1(imga)feata = F.avg_pool2d(feata, feata.size()[2:]).view(feata.size(0), feata.size(1))posea = self.fc_pose(feata)imgb = x[:, 3:6, :, :]featb = self.layer1(imgb)featb = F.avg_pool2d(featb, featb.size()[2:]).view(featb.size(0), featb.size(1))poseb = self.fc_pose(featb)imgc = x[:, 6:9, :, :]featc = self.layer1(imgc)featc = F.avg_pool2d(featc, featc.size()[2:]).view(featc.size(0), featc.size(1))posec = self.fc_pose(featc)para = self.fc_3dmm(torch.cat([feata, featb, featc], dim=1))out = torch.cat([para, posea, poseb, posec], dim=1)return outdef reset_params(net):for m in net.modules():if isinstance(m, nn.Conv2d):nn.init.normal(m.weight, 0.0, 0.02)if m.bias is not None:nn.init.constant(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal(m.weight, 0.0, 0.0001)if m.bias is not None:nn.init.constant(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant(m.weight, 1)nn.init.normal(m.weight, 1.0, 0.02)nn.init.constant(m.bias, 0)
从预测的参数中恢复3D人脸,
faces3d = tools.preds_to_shape(preds[0].detach().cpu().numpy())
提取出人脸参数 alpha, beta, R, t, s,计算 face_shape,以及3个view的 model_shape,
def preds_to_shape(preds):# paras = torch.mul(preds[:228, :], label_std[:199+29, :])alpha = np.reshape(preds[:199], [199,1]) * np.reshape(model_shape['sigma'], [199,1])beta = np.reshape(preds[199:228], [29, 1]) * 1.0/(1000.0 * np.reshape(data['sigma_exp'], [29, 1]))face_shape = np.matmul(model_shape['w'], alpha) + np.matmul(model_exp['w_exp'], beta) + model_shape['mu_shape']face_shape = face_shape.reshape(-1, 3)R, t, s = preds_to_pose(preds[228:228+7])kptA = np.matmul(face_shape[kpt_index], s*R[:2].transpose()) + np.repeat(np.reshape(t,[1,2]), 68, axis=0)kptA[:, 1] = 224 - kptA[:, 1]R, t, s = preds_to_pose(preds[228+7:228+14])kptB = np.matmul(face_shape[kpt_index], s*R[:2].transpose()) + np.repeat(np.reshape(t,[1,2]), 68, axis=0)kptB[:, 1] = 224 - kptB[:, 1]R, t, s = preds_to_pose(preds[228+14:])kptC = np.matmul(face_shape[kpt_index], s*R[:2].transpose()) + np.repeat(np.reshape(t,[1,2]), 68, axis=0)kptC[:, 1] = 224 - kptC[:, 1]return [face_shape, model_shape['tri'].astype(np.int64).transpose() - 1, kptA, kptB, kptC]def preds_to_pose(preds):pose = preds * pose_std + pose_meanR = angle_to_rotation(pose[:3])t2d = pose[3:5]s = pose[6]return R, t2d, s
最后,将人脸写入mesh文件。
tools.write_ply(os.path.join(options.save_dir, 'shape.ply'), faces3d[0], faces3d[1])
def write_ply(filename, points=None, mesh=None, colors=None, as_text=True):points = pd.DataFrame(points, columns=["x", "y", "z"])mesh = pd.DataFrame(mesh, columns=["v1", "v2", "v3"])if colors is not None:colors = pd.DataFrame(colors, columns=["red", "green", "blue"])points = pd.concat([points, colors], axis=1)if not filename.endswith('ply'):filename += '.ply'# open in text mode to write the headerwith open(filename, 'w') as ply:header = ['ply']if as_text:header.append('format ascii 1.0')else:header.append('format binary_' + sys.byteorder + '_endian 1.0')if points is not None:header.extend(describe_element('vertex', points))if mesh is not None:mesh = mesh.copy()mesh.insert(loc=0, column="n_points", value=3)mesh["n_points"] = mesh["n_points"].astype("u1")header.extend(describe_element('face', mesh))header.append('end_header')for line in header:ply.write("%s\n" % line)if as_text:if points is not None:points.to_csv(filename, sep=" ", index=False, header=False, mode='a',encoding='ascii')if mesh is not None:mesh.to_csv(filename, sep=" ", index=False, header=False, mode='a',encoding='ascii')else:# open in binary/append to use tofilewith open(filename, 'ab') as ply:if points is not None:points.to_records(index=False).tofile(ply)if mesh is not None:mesh.to_records(index=False).tofile(ply)return True
ply文件预览:
plyformat ascii 1.0element vertex 53215property float xproperty float yproperty float zelement face 105840property list uchar int vertex_indicesend_header-57861.697444928475 41402.07863996125 80754.95994012126-57825.751646592085 41156.33884778988 80756.22177179152-57787.105240666366 40912.49501439184 80753.9681079146-57752.693245361734 40606.47652473882 80702.31823879934-57714.708572422285 40303.915314277816 80648.21141466901-57665.74191753105 39946.24824403958 80564.4580453337-57614.64365355126 39588.81458608739 80479.47785714144-57566.487798421236 39210.266665891104 80364.30959778109-57502.62117264804 38830.57059010113 80246.91493798506-57432.458661227414 38409.00673801282 80117.38173290923-57353.70860100195 37990.52765622997 79981.96981050582-57262.74744467564 37559.03210288704 79831.46206180744-57166.9358116317 37130.19943151452 79677.16034162804...
用mesh方式打开: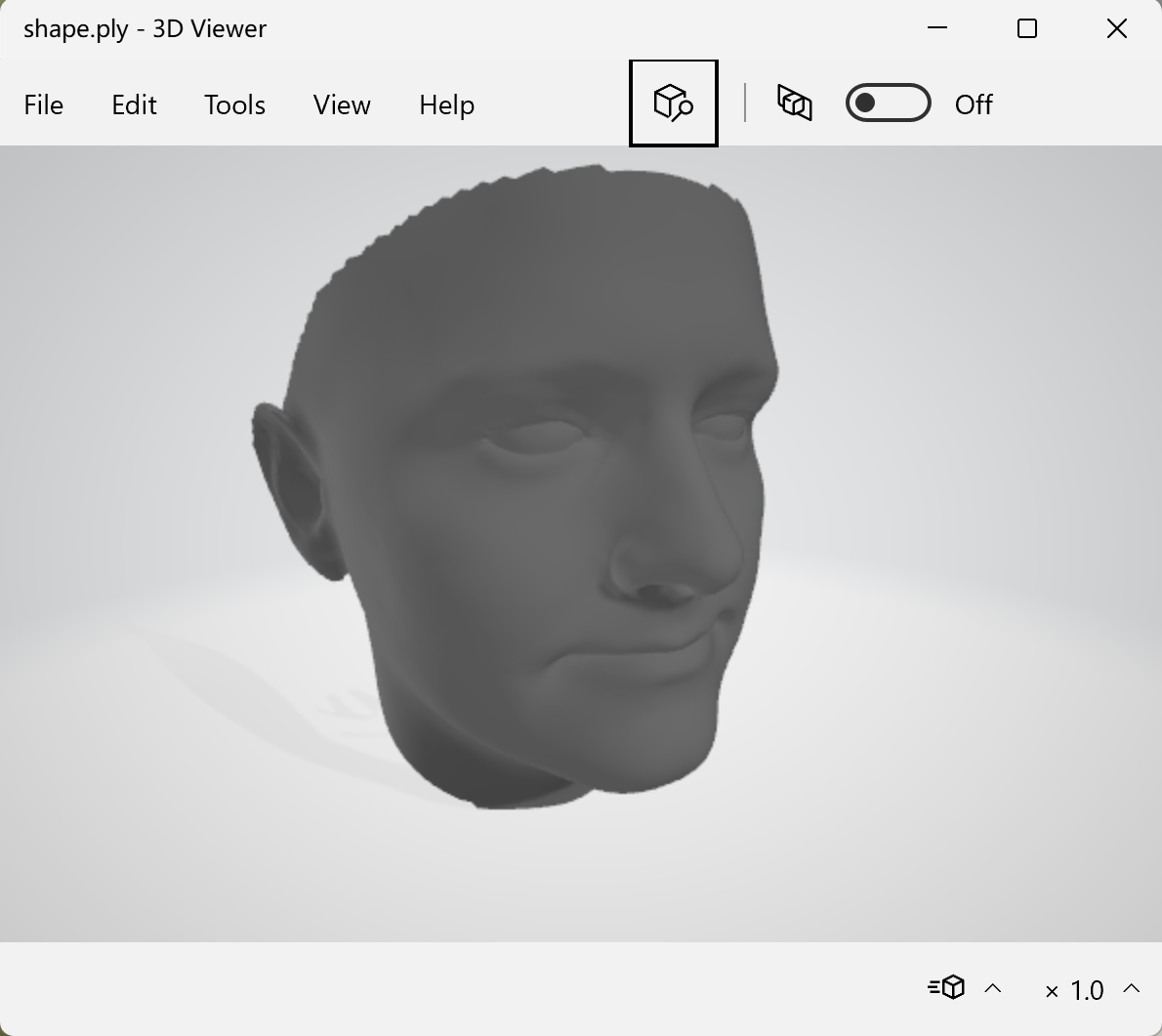
多视角视频人脸重建
模型加载时间:3.69
图片加载、裁剪等图片处理的时间:8.69
使用模型预测的时间:0.65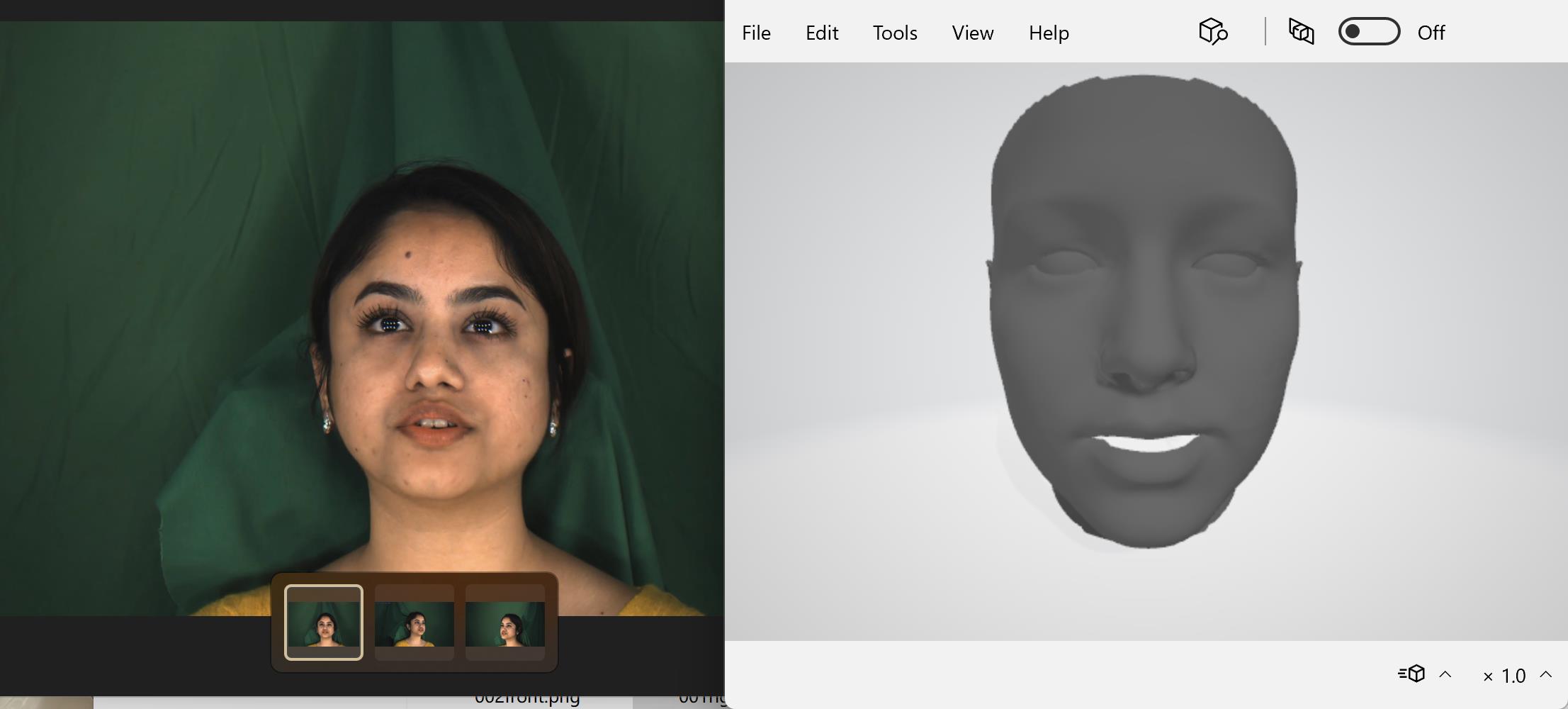

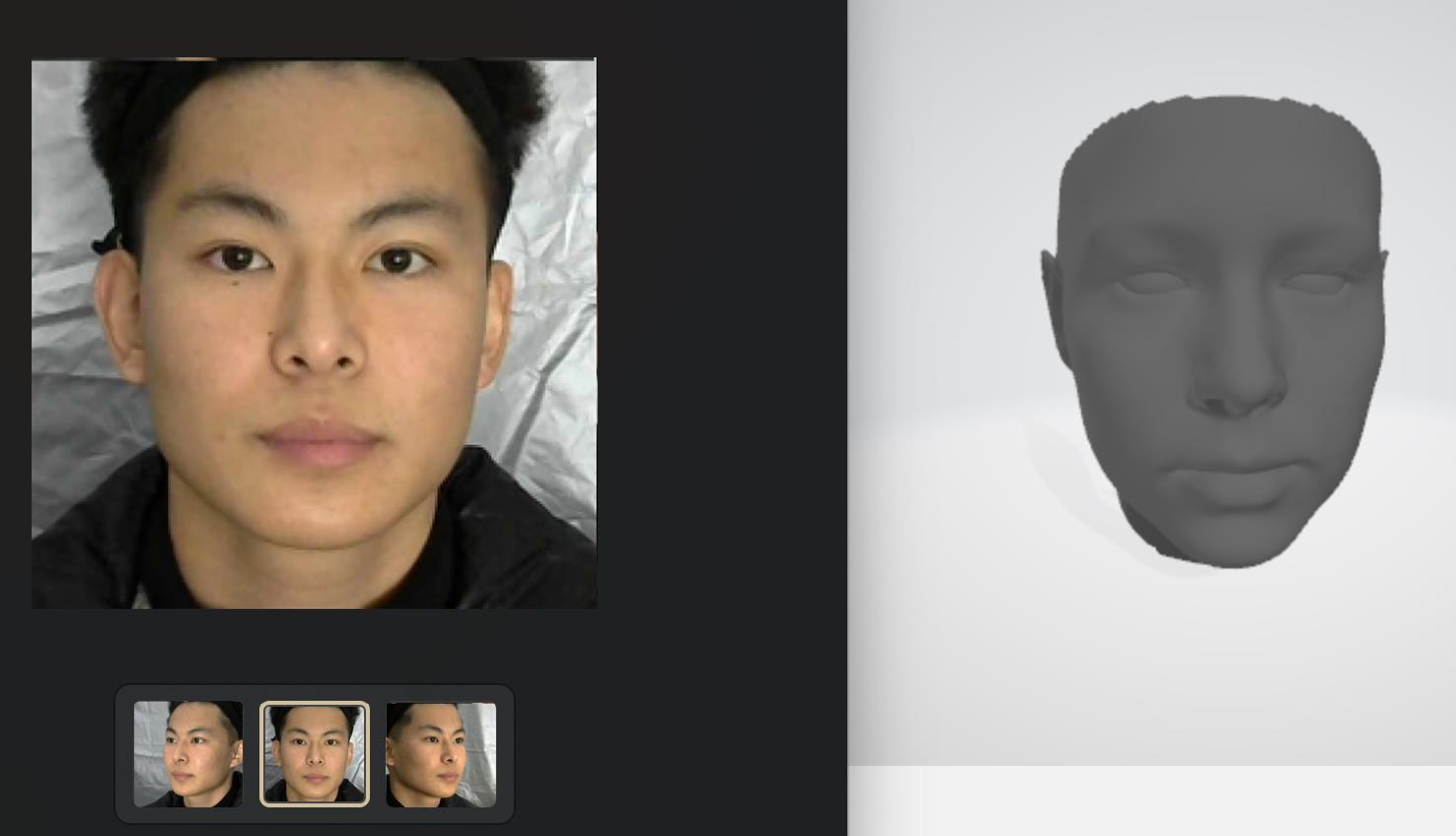
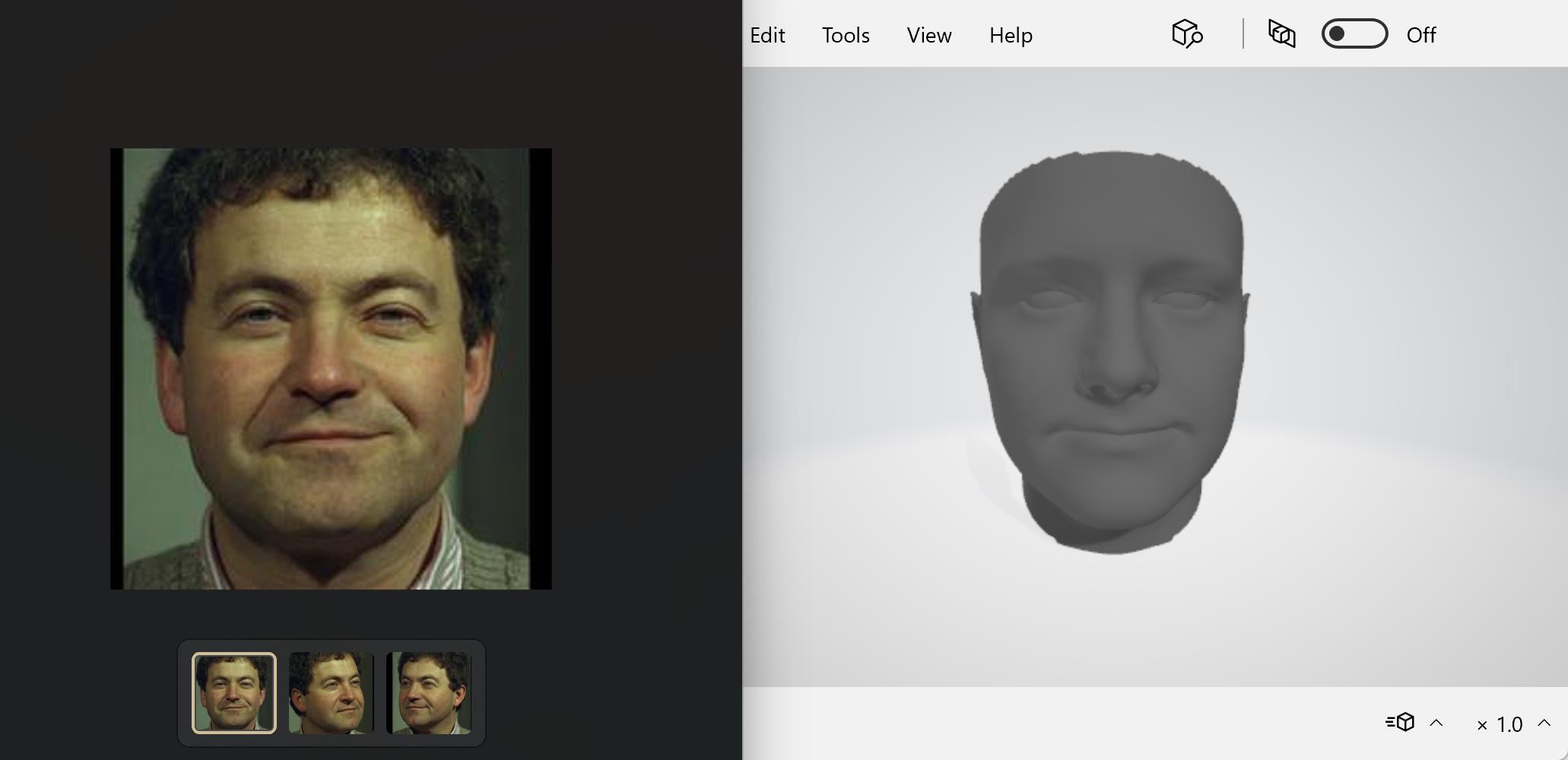

若有收获,就点个赞吧
0 人点赞
