谷歌-CVPR2021
LipSync3D: Data-Effificient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization
- LipSync3D:基于姿势和光照归一化的视频个性化3D语音人脸数据高效学习
- 输入音频和视频,预测出唇形同步。
- 个性化模型,数据量要求不高,有更高的视觉保真度,适合个人长演讲。
- 实验数据:three talking head datasets: GRID [10], TCD-TIMIT [16] and CREMA-D [21].
- 数据预处理:消除头部运动和光照变化的影响,并对面部几何和纹理进行归一化处理。训练和推理都在这个标准化空间中进行。
- LipSync3D对这一领域研究工作最显著的贡献可能是其光照归一化算法(lighting normalization algorithm),该算法将训练和推断照明解耦。
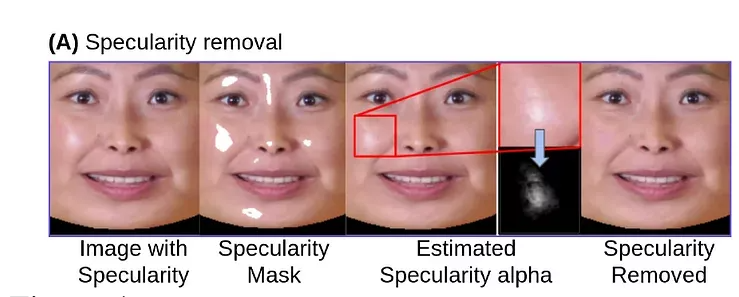
- 研究人员称,LipSync3D在以前的工作中提供了三个主要创新: 将几何、光照、姿态和纹理分离到规范化空间中的离散数据流中; 一个易于训练的自回归纹理预测模型,可以生成时间上一致的视频合成; 以及通过人类评级和客观度量来增加真实感。
- 使用 GeForce GTX 1080,视频的示例训练时间从2-5分钟的视频所需3-5小时不等。
方法
1. 训练数据归一化
姿势归一化:根据输入帧生成网格评估的人脸规范化顶点,然后生成相应的纹理图谱。
? 这里是不是相当于2D转3D然后又转2D?

光照归一化:

2. 联合预测模型和训练pipeline
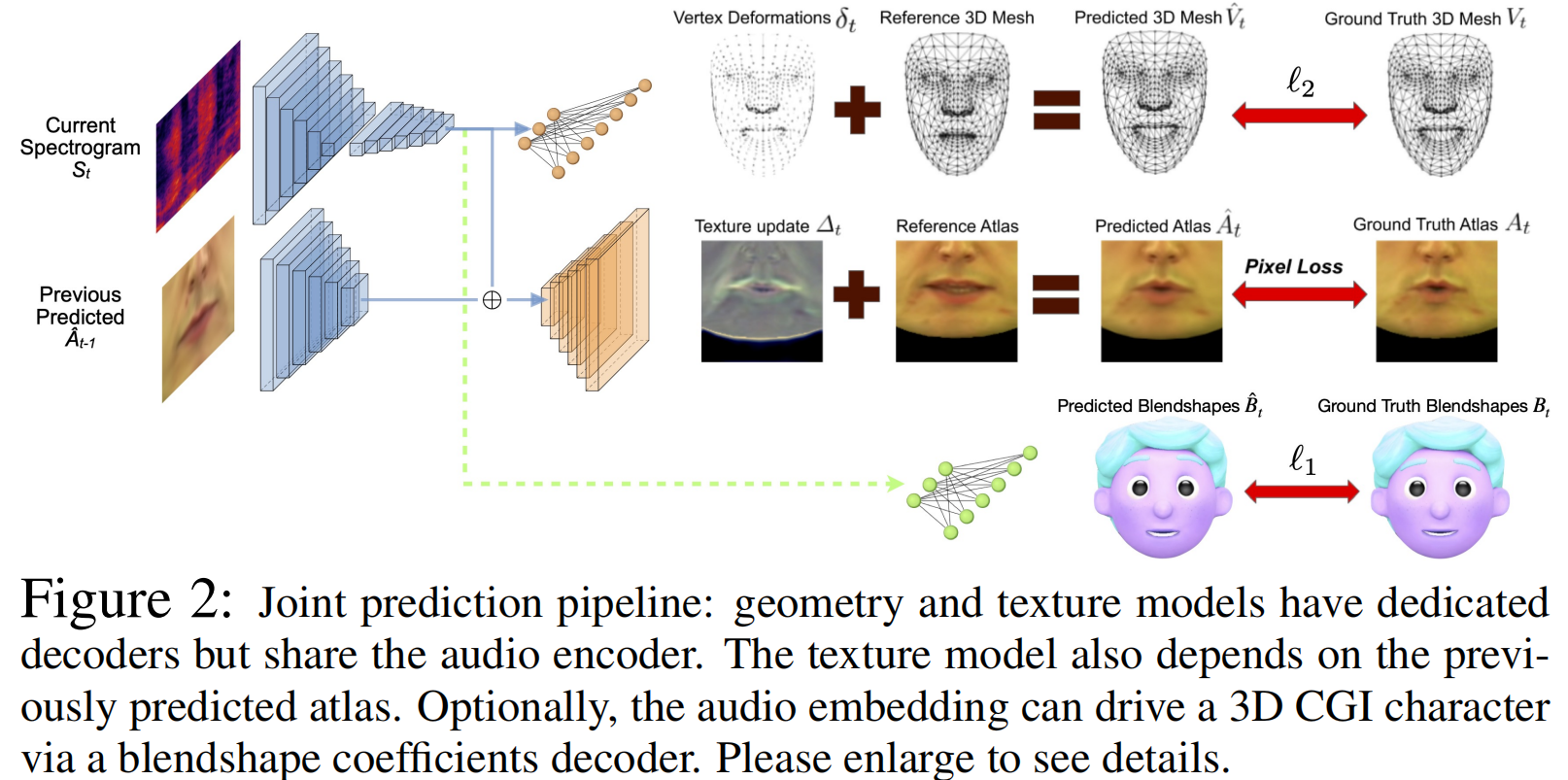
- 在本节中描述了学习函数F的框架,该函数是从音频谱图域S到顶点域V和纹理图集域的联合映射。
1个编码器 + 3个解码器,将几何信息和纹理分离出来,不共用decoder。解耦合。
- audio encoder
- geometry decoder:映射到3D顶点。
- texture decoder:
- blendshapes decoder:To animate CGI characters。
- Auto-regressive (AR) Texture Synthesis

Try 自回归预测:增强模型的时间稳定性。没有AR,沉默时唇形有张开,加了AR就没有张开的帧了。
- for temporally smooth video synthesis.
- Training by “Teacher Forcing”[1]:不是使用前面的预测atlas,而是用ground truth。
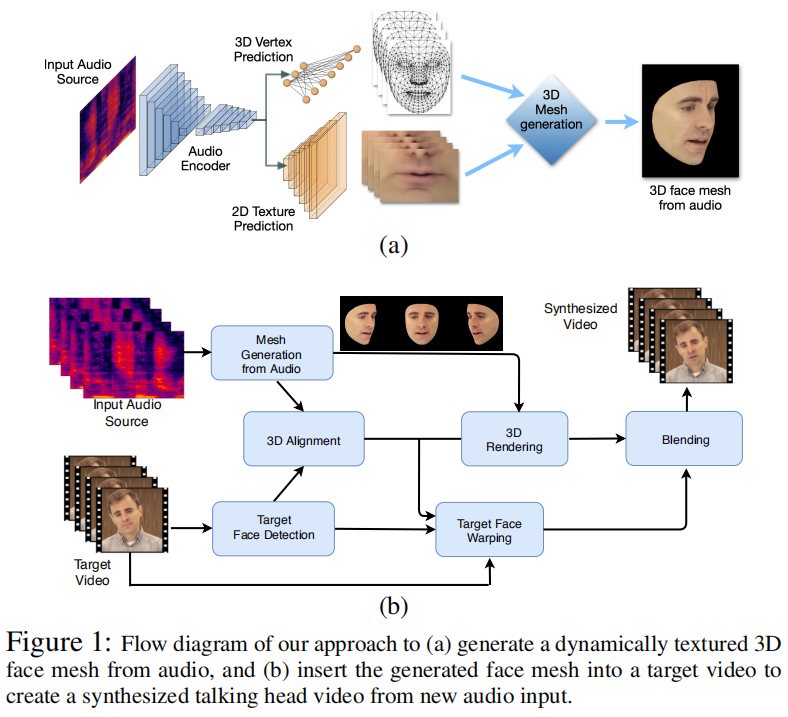
3. 推理和合成
- Textured 3D mesh
- Talking head video synthesis
- Cartoon rendering
- CGI Characters
合成:预测音频对应的3D人脸,与视频帧人脸对齐后进行融合。
结果
在官方演示视频 LipSync3D: Personalized 3D Talking Faces from Video using Pose and Lighting Normalization - YouTube 中可以看到,
如果没有光照归一化,在复杂光照条件下(黑暗、单一光源+人物转向)唇部出现伪影、模糊等不真实现象。
2:52有2个与 wav2lip 进行对比的片段。
除了输入音频的唇形同步,本模型还可以只输入文字text to video、人物CGI头像。应用场景:游戏和VR。


- 4:20展示了视频翻译,有翻译成中文的,看着有些字的唇形不是很对。英文效果挺好的。

若有收获,就点个赞吧
0 人点赞
