源码地址:https://github.com/xinwen-cs/AudioDVP
Pipeline: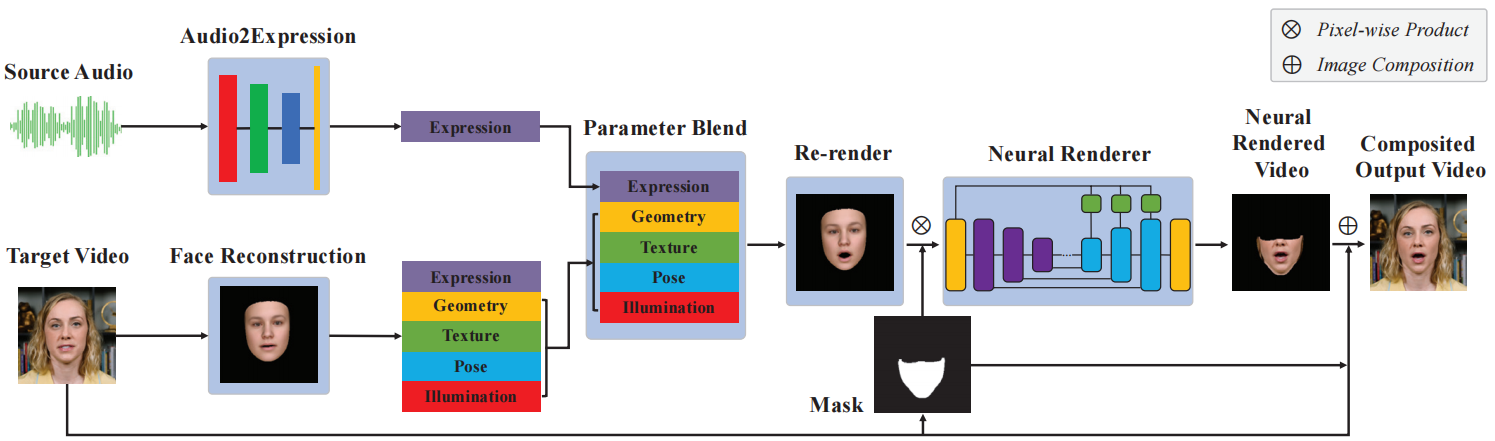
代码流程梳理
将目标人物的3分钟视频放在video_dir,将目标语音放在audio_dir。
- 提取输入视频中的每一帧,以及视频中的音频。
输入:目标人物的视频video_dir
输出:视频中的每一帧$video_dir/full/%05d.png、音频轨$video_dir/audio/audio.aac。
/usr/bin/ffmpeg -hide_banner -y -i $video_dir/*.mp4 -ss $start_time -t $end_time -r 25 $video_dir/full/%05d.png/usr/bin/ffmpeg -hide_banner -y -i $video_dir/*.mp4 -ss $start_time -t $end_time $video_dir/audio/audio.aac
- 分别提取原始音频和目标音频的特征。先用librosa提取音频的MFCC特征,然后送入AT-net[11](conv2d+fc)进行编码并保存。加载了一个预训练模型
atnet_lstm_18.pth。
输入:第一步中从视频里提取出来的原始音频$video_dir/audio/audio.aac,和目标语音$audio_dir/*。
输出:编码后的高级特征分别存于$video_dir/feature/xxx.pt和$audio_dir/feature/xxx.pt。
mkdir -p $video_dir/featurepython vendor/ATVGnet/code/test.py -i $video_dir/mkdir -p $audio_dir/featurepython vendor/ATVGnet/code/test.py -i $audio_dir/
- 裁剪和缩放视频帧。获取每一帧里人脸的bbox坐标,裁剪出人脸区域并resize到256*256,存于
$video_dir/crop。
输入:第一步中提取出的视频帧$video_dir/full/%05d.png。
输出:裁剪缩放后的人脸图片$video_dir/crop/%05d.png。举例:

python utils/crop_portrait.py --data_dir $video_dir \--crop_level 2.0 --vertical_adjust 0.2
- 训练 ResNet-50 网络(含FaceModel),进行3D人脸重建,从输入图像 I 估计人脸模型参数 ‘alpha’, ‘beta’, ‘delta’, ‘gamma’, ‘rotation’, ‘translation。保存重建的人脸图和重建人脸贴回crop帧后的图。
输入:上一步crop的人脸图片$video_dir/crop/%05d.png。
输出:上述6个人脸模型参数 ,分别存于`video_dir/人脸参数/%05d.pt;重建的人脸图保存为$video_dir/render/%05d.png;重建人脸贴回crop帧后的图,存于$video_dir/overlay/%05d.png`。
python train.py --data_dir $video_dir --num_epoch 20 --batch_size 5--serial_batches False --display_freq 400 --print_freq 400
- 建立 Neural Face Renderer data pair(masked target, masked synthetic)。对整张人脸进行重建看着很不真实,所以只对下半张脸进行重建。获取masked区域,将重建后的masked区域与原脸的masked区域一起保存为图像AB。
输入:上一步估计的人脸参数video_dir/人脸参数*/%05d.pt。
输出:每一张人脸的 Lower face mask$video_dir/mask/%05d.png、原始人脸的 Lower face (A)$video_dir/nfr/A/train/%05d.png、重建人脸的 Lower face (B)$video_dir/nfr/B/train/%05d.png,以及AB pair图像$video_dir/nfr/AB/train/%05d.png
python utils/build_nfr_dataset.py --data_dir $video_dir

pair图像输出举例: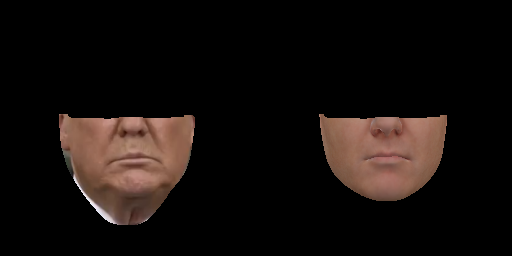
- 训练 audio2expression 网络(AT-net)。网络结构是3个一维卷积加一个全连接层,使用MSE loss。将音频高阶特征映射为表情参数 :’alpha’, ‘beta’, ‘delta’, ‘gamma’, ‘rotation’*, ‘translation’。
输入:原始音频的特征$video_dir/feature//%05d.pt、第四步估计出的人脸参数video_dir/人脸参数*/%05d.pt。
输出:保存模型$video_dir/delta_net.pth。
python train_exp.py --dataset_mode audio_expression --num_epoch 10 \--serial_batches False --display_freq 800 --print_freq 800 \--batch_size 5 --lr 1e-3 --lambda_delta 1.0 --data_dir $video_dir \--net_dir $video_dir
- 训练渲染器 neural face renderer(pix2pix model)。它由基于U-net的生成器G和鉴别器D组成,以对抗性的方式进行优化。neural face renderer 只预测掩模内的内容,并将预测的内容与视频帧进行合成,得到最终的结果。
The discriminator employs a PatchGAN [27]. For the full network architecture, please refer to deep video portraits [30] and our source code.
输入:第五步建立的 pair 图像数据集$video_dir/nfr/AB/train/%05d.png。
输出:保存模型$video_dir/checkpoints/nfr/$epoch_net_$name.pth
python vendor/neural-face-renderer/train.py \--dataroot $video_dir/nfr/AB --name nfr --model nfr \--checkpoints_dir $video_dir/checkpoints \--netG unet_256 --direction BtoA --lambda_L1 100 --dataset_mode temporal \--norm batch --pool_size 0 --use_refine \--input_nc 21 --Nw 7 --batch_size 4 --preprocess none \--num_threads 4 --n_epochs 250 --n_epochs_decay 0 --load_size 256
- 从语音特证预测表达参数。
输入:测试音频$audio_dir,加载第6步保存的网络模型$net_dir/delta_net.pth
输出:经过前向传播后的特征参数$data_dir/reenact_delta/%05d.png
python test_exp.py --dataset_mode audio_expression \--data_dir $audio_dir --net_dir $video_dir
- 使用语音预测的表达参数创建人脸。
输入:3DMM人脸模型参数$video_dir/人脸参数*/%05d.pt
输出:masked 部分的重建图,保存于$audio_dir/reenact/%05d.png。如图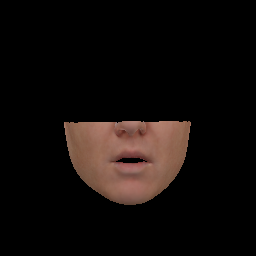
python reenact.py --src_dir $audio_dir --tgt_dir $video_dir
- 使用神经渲染人脸序列(neural rendering the reenact face sequence)。
输入:第7步训练的模型data/video/checkpoints/nfr/50_net_G.pth、第9步重建的masked人脸$audio_dir/reenact/%05d.png
输出:保存image到webpagewebpage.add_images(images, label, image_name, width)【?不是很懂这个输出】
python vendor/neural-face-renderer/test.py --model test \--netG unet_256 \--direction BtoA \--dataset_mode temporal_single \--norm batch \--input_nc 21 \--Nw 7 \--preprocess none \--eval \--use_refine \--name nfr \--checkpoints_dir $video_dir/checkpoints \--dataroot $audio_dir/reenact \--results_dir $audio_dir \--epoch $epoch
- composite lower face back to original video。
输入:$audio_dir/images/%05d_fake.png、$video_dir/crop、$video_dir/mask
输出:$audio_dir/comp/%05d.png
python comp.py --src_dir $audio_dir --tgt_dir $video_dir
- 输出最后结果视频。
/usr/bin/ffmpeg -y -loglevel warning \-thread_queue_size 8192 -i $audio_dir/audio/audio.aac \-thread_queue_size 8192 -i $audio_dir/comp/%05d.png \-vcodec libx264 -preset slower -profile:v high -crf 18 \-pix_fmt yuv420p -shortest $audio_dir/result.mp4
运行时报错与解决
OSError: could not read bytes
运行build_data.py时报的错。
解决:
导入from scipy.io import loadmat
把mat_data=sio.loadmat('data/01_MorphableModel.mat')
改成mat_data=loadmat('data/01_MorphableModel.mat')
Package pytorch conflicts
报了非常长的conflicts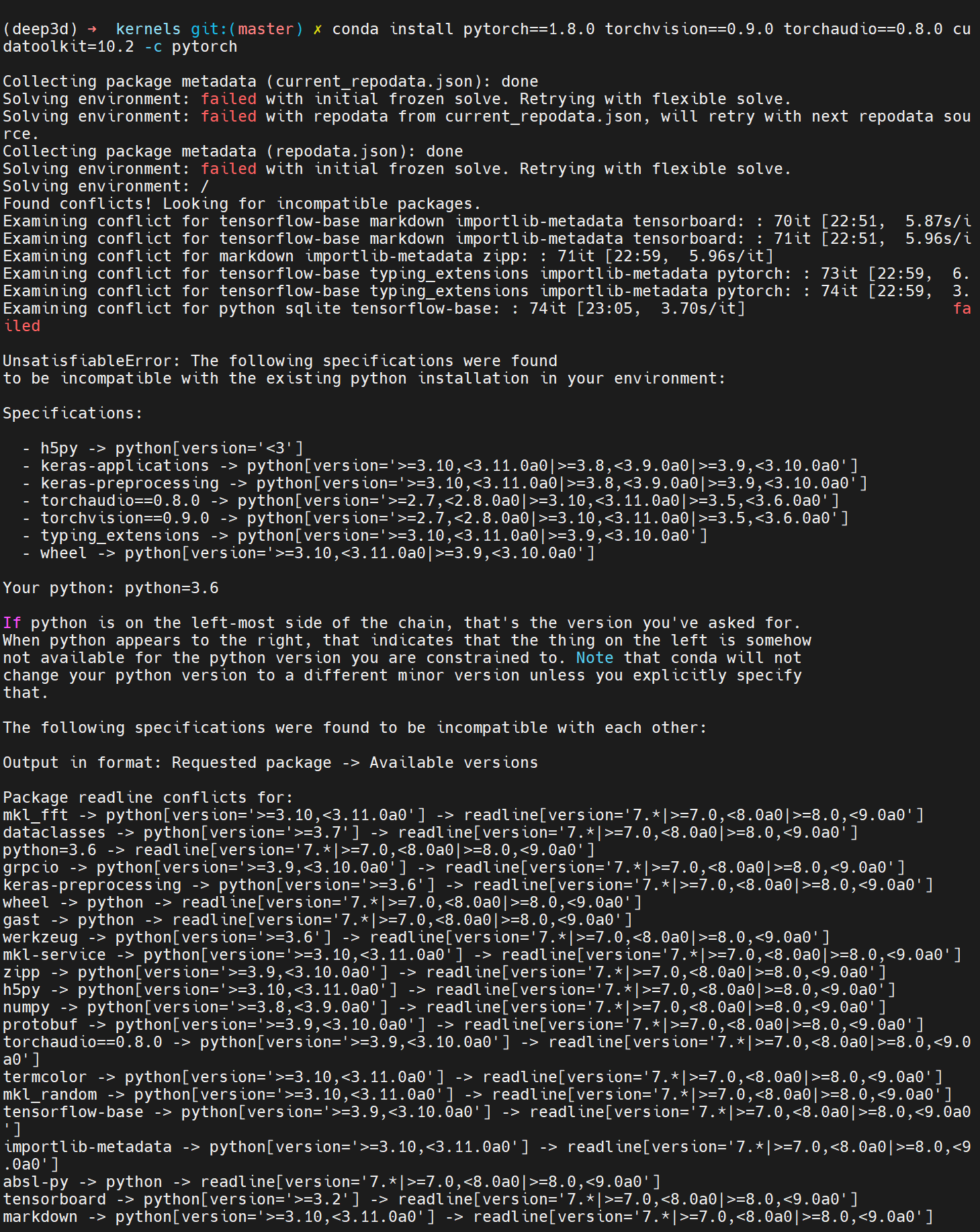
有方案说指令加上-c conda-forge,还是一样。
也试了降低一点版本,安装pytorch==1.5.0,还是conflicts。
直接conda install pytorch,发现它安装的版本是pytorch-1.4.0-cuda92py36h488537e_0。所以是我安装的版本太高了,和其他库有冲突…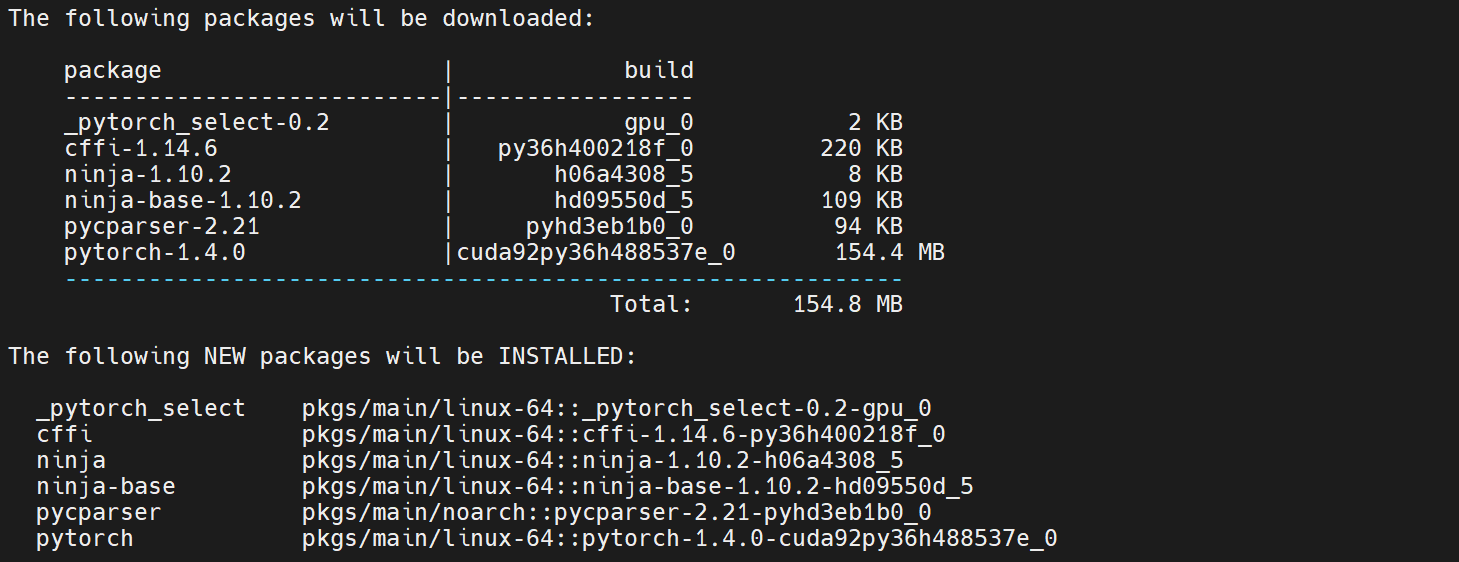

若有收获,就点个赞吧
0 人点赞
