Zipeng Ye et al., “Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions,” ArXiv:2204.06180 [Cs], April 13, 2022, http://arxiv.org/abs/2204.06180.

基于一个观察:纹理比几何包含更足够的信息来描述对人脸的表示。
同时,低频顶点颜色不能提供足够的表达式信息。
因此,我们设计使用包含高分辨率图像中的精细细节的纹理贴图来控制表达式。
解决什么问题
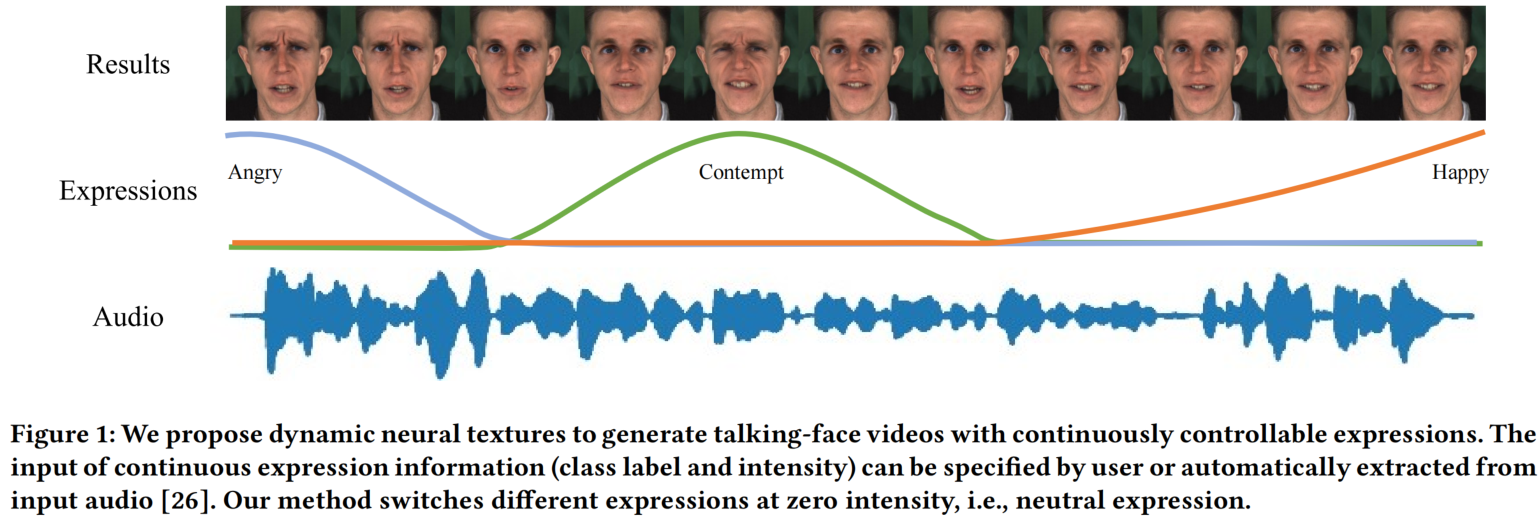
大多数说话人脸视频生成的方法不能控制生成结果,由神经网络或中间表达式隐式决定。我们提出了一种实时生成连续可控表达的说话人脸视频生成的方法。我们的方法是基于一个重要的观察结果:与 moderate 分辨率的面部几何形状相比,大多数表情信息依赖于纹理。
贡献点
- 我们提出了一种新的动态神经纹理来实时生成连续可控表达的说话脸视频,而不使用连续强度值的训练数据,基于输入表达式和连续强度表达式编码(CIEC)生成图像帧(我们称之为动态神经纹理)的神经纹理。
- 我们提出了一种解耦网络来将具有表达式的三维面转移到中性面,使用3DMM作为一个三维模型,对动态神经纹理进行采样。
- 我们提出了一个牙齿子模块来完成牙齿区域缺失的信息,以实现精细的说话脸细节和真实的纹理。
具体方法
输入是一个驱动音频,一系列表达式和一系列背景帧(或一个)。
输出一个具有连续可控表达式的说话人脸视频,其中每个视频帧由输入背景帧、驱动音频段和一个连续强度表达式编码(CIEC)向量生成。
Pipeline包含4个模块,动态神经纹理子模块 和 音频子模块 用来解耦嘴唇运动和表达式。
- 动态神经纹理模块 从CIEC中获得动态神经纹理,用于融合输入表达式的特征。
- 音频模块 从输入音频生成3D面部动画(由3DMM参数表示)。
- 渲染模块,将面部区域融入到背景中,通过使用 CNN 从背景帧中提取特征,并使用来自背景特征和完整面部特征的残差块的 U-Net,同时生成彩色面部图像和 attention mask。
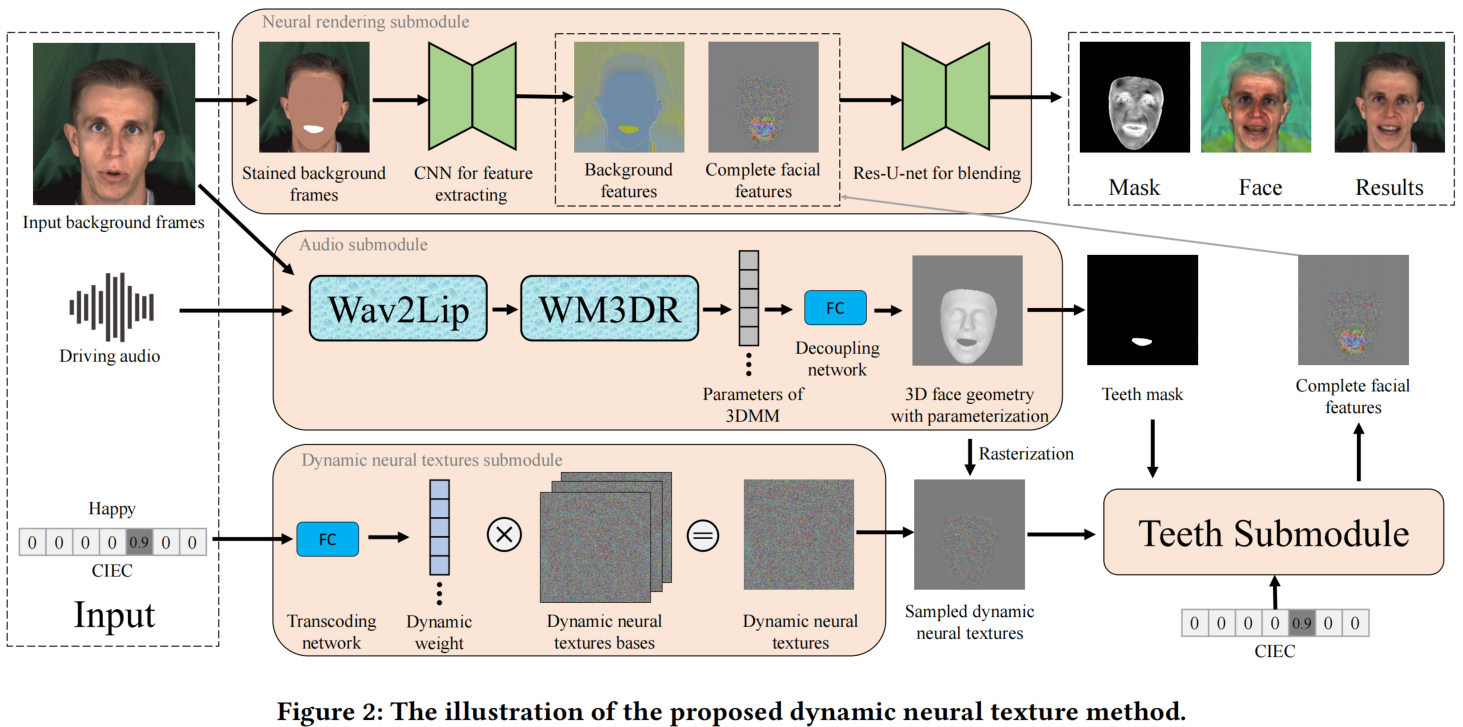
1. dynamic neural texture submodule
Interpretation from the perspective of set approximation. 静态神经纹理生成具有固定表情的说话人脸视频。因此,使用不同的静态神经纹理可以表示不同的表达式,而动态神经纹理可以看作是一组静态神经纹理的近似值。受动态卷积内核[34]的启发,我们可以用以下方式来理解动态神经纹理。用E表示所有表达式的空间。对于一个固定的表达式𝑡∈E,我们可以学习一个静态的神经纹理来表示它。对于在E中采样的不同表达式,我们学习不同的静态神经纹理来表示它们,这是一个有限的静态神经纹理集合。另一方面,我们的方法从不同的表达式中推断出动态的神经纹理,而这些纹理在静态的神经纹理的集合中发挥着相同的作用。然而,不同的静态神经纹理集只能表示e中离散采样的表达式。作为比较,动态神经纹理可以表示连续空间中的表达式,从而为连续控制表达式提供了更好的工具。
Continuous Intensity Expression Coding(CIEC):为了连续控制人脸视频中的表达,我们提出了连续强度表达编码(CIEC),which is a continuous version of the one-hot encoding。类似于 one-hot encoding,CIEC最多允许一个非零元素。每个维度表征一个表达式类型,而零向量表示中性表达式。非零元素的值表示相应表达式的强度。在我们的实验中,强度归一化为[0,1],其中0表示中性表达,1表示该表达的最高强度。在MEAD数据集[30]中,每种表达式类型都有三个级别(级别1、2和3)
2. audio submodule
- 使用Wav2lip从输入音频和输入帧中生成说话人脸视频
- 使用WM3DR[36],从生成的人脸视频重建3D人脸,获得3D人脸动画
- 使用解耦网络,转移3D人脸表情到一个中立的脸。
[36] Jialiang Zhang, Lixiang Lin, Jianke Zhu, and Steven CH Hoi. 2021. Weakly Supervised Multi-Face 3D Reconstruction. arXiv preprint arXiv:2101.02000 (2021).
在这些步骤中,挑战是如何将嘴唇运动与表情解耦。我们的解决方案是使用动态神经纹理来表示和控制表达式,并使用三维人脸几何图形来表示和控制嘴唇的运动。这样,3D人脸的几何图形就不应该提供表达式信息,这就意味着3D人脸应该是中性的。因此,我们使用解耦网络将具有不同表达式的三维面转移到一个中性人脸,这将在稍后的动态神经纹理子模块中使用。
解耦网络
训练一个解耦网络,将具有不同表达式的3D脸转移到中性脸,同时保留其他属性,包括嘴唇运动和身份。
任务是通过保持其他属性的方向,将一个3D脸投影到中性脸的子空间中。该任务类似于3D人脸的表达式编辑,它只包含一个目标方向。3D脸用3DMM参数表示。
解耦网络可以看作是一个映射函数,我们使用全连接网络实现解耦网络。
纹理映射
在我们的 pipeline 中,使用带有参数化的三维人脸几何图形(作为UV坐标),通过栅格化将来自纹理空间的动态神经纹理采样到屏幕空间。
我们使用延迟渲染来实现纹理映射:(1)对UV坐标进行栅格化以获得屏幕空间中的UV图,(2)使用UV图将纹理空间的动态神经纹理采样到屏幕空间。
3. teeth submodule
用仿射变换来聚焦于牙齿区域,并使用CNN来完成牙齿特征 。为了对齐牙齿区域,仿射变换将牙齿区域的中心转换为图像的中心。我们还使用逆变换来整合牙齿特征与采样的神经纹理。我们用一个CNN来完成牙齿特性,这是一个带有剩余块的U-Net。因为牙齿是与表达式相关,我们也将CIEC输入到CNN。我们通过一个完全连接的网络来重新排列CIEC,并将重新排列的CIEC与图像连接起来 。然后将输出的牙齿特征进行反向变换,并与采样的神经纹理连接起来。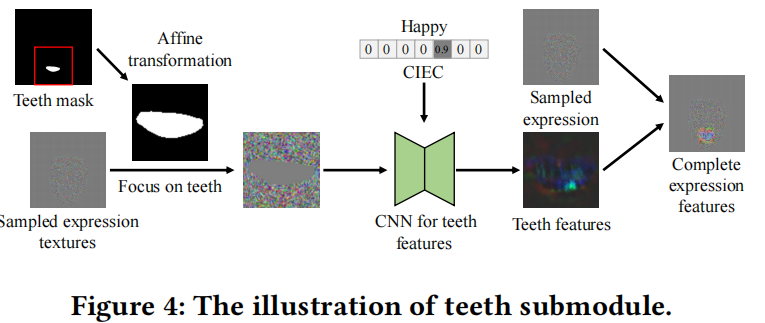
4. neural rendering submodule
由于3DMM不包含头发和背景,所以使用了输入帧中的头发和背景信息。面部区域和牙齿区域是重建的3DMM的投影。
我们使用CNN从 masked 背景帧中提取背景特征,将其与面部特征连接,输入到具有残余块的 U-Net 中进行blending。这一步输出一个彩色的面部图像和attention mask。
blending。使用 attention mask 将彩色面部图像与背景混合。混合公式: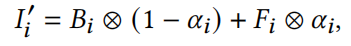
注
dynamic textures have been proposed for dynamic 3D avatar [17], which uses different textures for different expressions.
[17] Koki Nagano, Jaewoo Seo, Jun Xing, Lingyu Wei, Zimo Li, Shunsuke Saito, Aviral Agarwal, Jens Fursund, and Hao Li. 2018. paGAN: real-time avatars using dynamic textures. ACM Transactions on Graphics (TOG) 37, 6 (2018), 1–12.
使用WM3DR[36],从生成的人脸视频重建3D人脸,获得3D人脸动画。
[36] Jialiang Zhang, Lixiang Lin, Jianke Zhu, and Steven CH Hoi. 2021. Weakly Supervised Multi-Face 3D Reconstruction. arXiv preprint arXiv:2101.02000 (2021).

若有收获,就点个赞吧
0 人点赞
