Fanzi Wu et al., “MVF-Net: Multi-View 3D Face Morphable Model Regression” (arXiv, April 9, 2019), http://arxiv.org/abs/1904.04473.
https://openaccess.thecvf.com/content_CVPR_2019/html/Wu_MVF-Net_Multi-View_3D_Face_Morphable_Model_Regression_CVPR_2019_paper.html
代码:https://github.com/Fanziapril/mvfnet
输入:一个人在 不同视角、同光照、同时 拍摄的多张面部图片。
提出了一种利用端到端可训练的卷积神经网络(CNN)从多视图输入中回归3个DMM参数的新方法。
通过一种新的自监督视图对齐损失,在不同视图之间建立密集的对应关系,将多视图几何约束纳入到网络中。视图对齐损失的主要成分是可微密集光流估计器,它可以通过要推断的三维形状投影到目标视图,反向传播输入视图和另一个输入视图的合成渲染之间的对齐误差。通过最小化视图对齐损失,可以恢复更好的三维形状,这样从一个视图到另一个视图的合成投影可以更好地与观察到的图像对齐。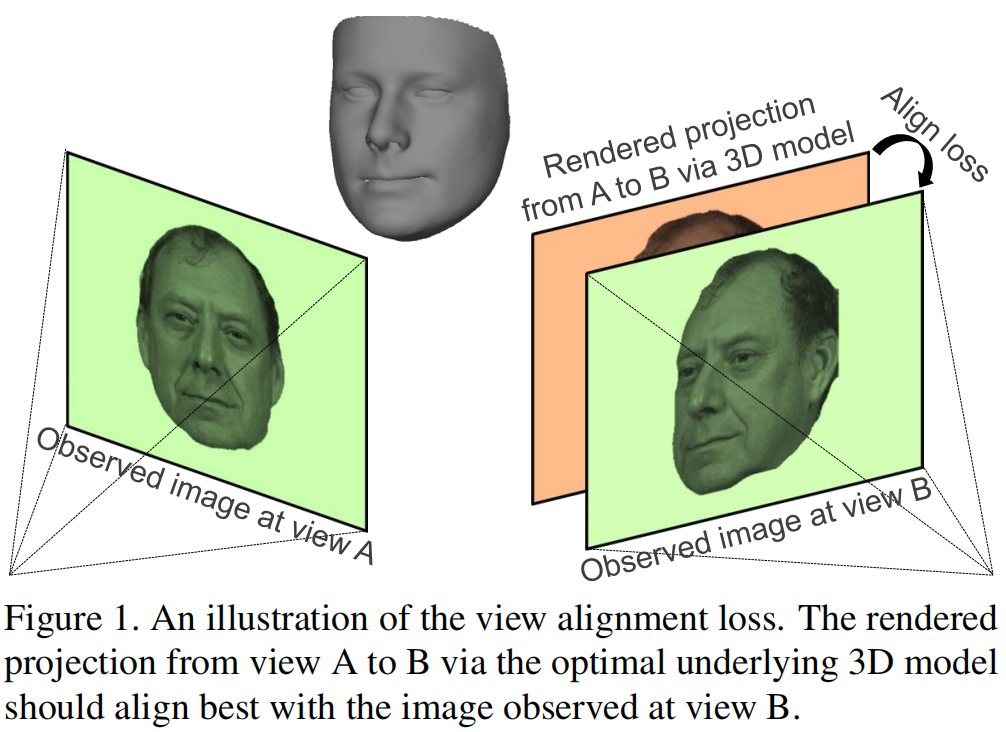
我们的方法基于这样的假设:潜在的最优三维模型应该能最好地解释不同视角下观察到的图像。也就是说,由该视图的底层三维模型引起的每个观测图像和渲染图像之间的光度重投影误差应该被最小化(如图1所示)。为了将这个约束纳入我们的CNN,我们使用预测的3D模型和相机姿态从输入视图中采样纹理,然后将纹理的3D模型渲染到另一个视图,以计算渲染图像和目标视图中观察到的图像之间的损失。
除了两种图像之间的直接光度损失外,我们提出了一种新的视图对齐损失,利用可微密集光流估计器来反向传播对齐误差,以避免在训练过程中捕获到局部最小值。以上所有步骤都是可微的,整个网络都是端到端可训练的。
Pipeline
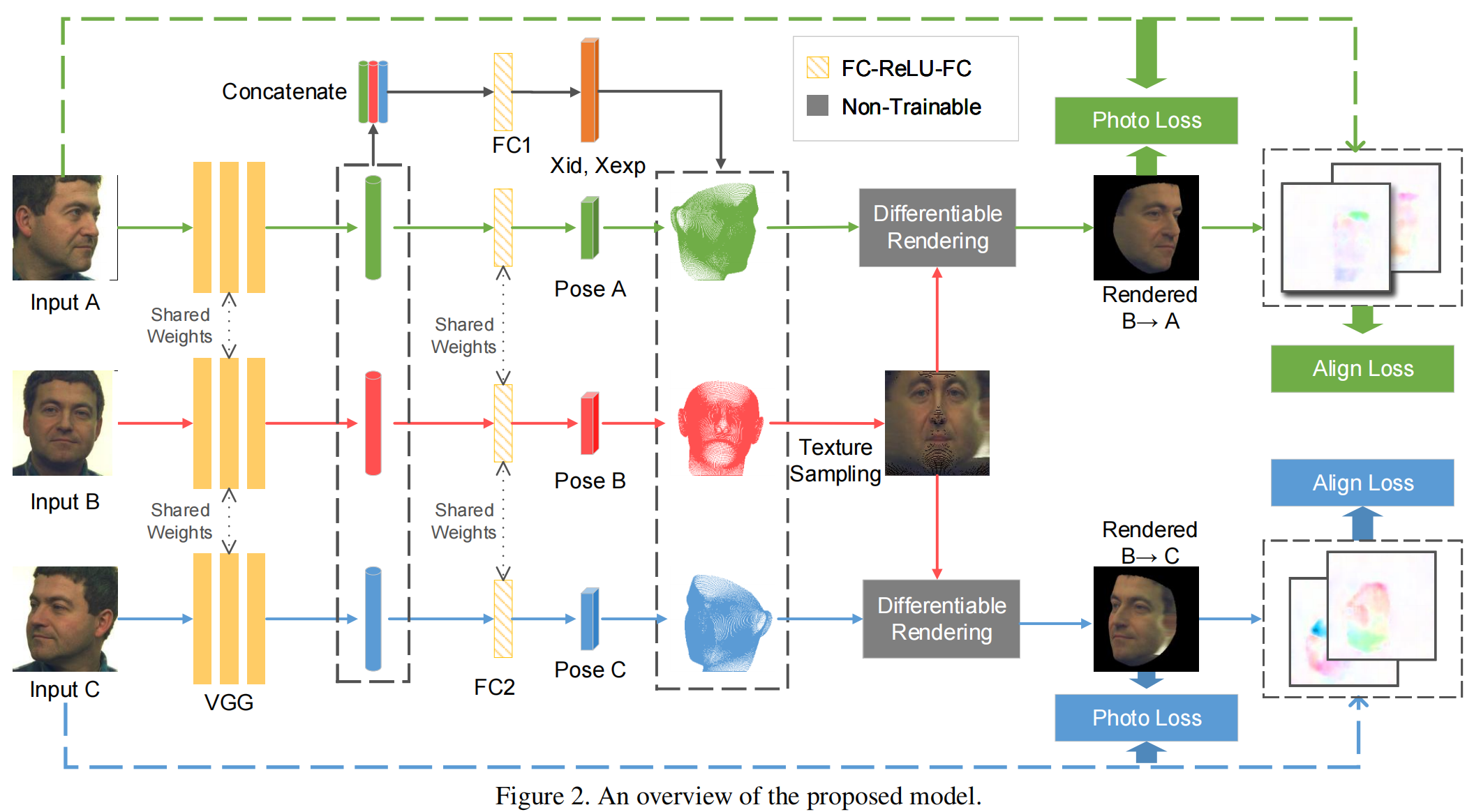
为了简单起见,我们采用三视图设置来描述我们的方法。请注意,它可以很容易地推广到其他数量的输入视图。
- 首先通过一个共享的权重CNN从每个输入图像中学习特征,然后将这些特征连接在一起,为这个人回归一组3DMM参数。不同的是,我们从每个输入视图的姿态参数中回归出它的个人特征(Sec 3.3)。
- 有了姿态参数和3DMM参数,我们就可以通过从图像中采样纹理,从每个输入图像中渲染一个有纹理的三维人脸模型(Sec 3.4)。在三视图中,将会有三个带有纹理的3D人脸模型,它们具有相同的底层3D形状,但具有不同的纹理。
- 在获得不同视图渲染的三维人脸模型后,我们将它们投影到不同的视图中(Sec 3.5)。例如,我们将从视图A采样的纹理的三维模型投影到视图b,然后我们可以计算投影图像与目标视图的输入图像之间的损失。我们将在Sec 3.6 中介绍所采用的损失的细节。请注意,渲染层是非参数的,但却是可微的,就像以前的自监督方法[32,12]一样,因此梯度可以反向传播到可训练层。
简单来说,步骤是:
- 通过CNN获取每个视角的3DMM参数和姿态参数;
- 从每个视图中获取纹理,渲染成3D face。每个3D face的形状相同但纹理不同;
- 将每个3D face 投影到其他视角,计算损失并训练网络使其最小化。
Sec 3.3 Parametric Regression
我们将三视图输入图像表示为IA、IB和IC。我们假设IB是正面视图的图像,IA和IC分别来自左侧和右视图。请注意,我们不需要从精确的已知视角角度拍摄图像。每个输入图像通过几个卷积层(在我们的实现中借用了VGG-Face[30]),并汇集到一个512维的特征向量中。然后对每个视图的一组姿态参数P={f、α、β、tf、β、γ、ty}通过两个全连通层进行回归。三个512维的特征向量被连接在一起,使用另外两个全连接层回归228维的3DMM参数X={xid,xexp}(分别是199维的身份和29维的表达)。注意,对于每一组输入,我们回归一个3DMM参数X和三个姿态参数PA、PB和PC。为三个视图提取特征和回归姿态参数的网络具有共享的权重。
Sec 3.4. Texture Sampling
利用预测的3DMM参数X,以及已知的身份基Eid和表达式基Eexp,我们可以使用等式(1)计算三维人脸模型: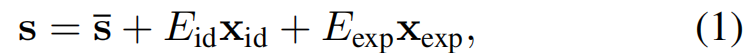
通过使用网络预测的姿态参数从每个图像中分别采样纹理,可以得到三种不同的纹理图。对于三维模型的每个顶点v,我们应用等式(2)将顶点投影到图像平面上,并使用可微采样方案从每个输入图像中获取纹理颜色,如 Spatial Transformer 网络[16]中所述。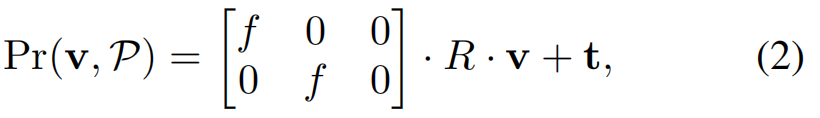
对于网格上三角形内的三维点,我们利用重心插值从周围的顶点获得其纹理颜色。请注意,由于纹理采样方案不处理遮挡,因此在每个图像中为遮挡区域采样的纹理都是错误的。我们使用可见性面具来处理这个问题,这将在Sec 3.5中详细介绍。现在假设我们在这一步中得到了三个不同纹理的三维模型。
Sec 3.5. Rendered Projection and Visibility Masks
通过[12]中介绍的可微渲染层,纹理化的三维模型可以投影到任意视图中来渲染二维图像。例如,给定一个具有从图像 IA 中采样的纹理的三维模型,我们可以使用姿态参数 PB 将其呈现到 IB 的视图中,我们将其表示为 IA→B。在形式上,对于网格表面上的任何三维点v(包括三角形内的点),其在渲染图像中的投影像素的颜色可以计算为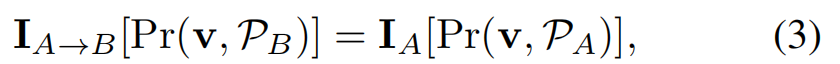
其中,[·]表示图像中的像素选择。在实践中,通过在目标图像平面上的栅格化来实现渲染,即将目标图像中的任意像素表示为 u,然后等式(3)可以被写成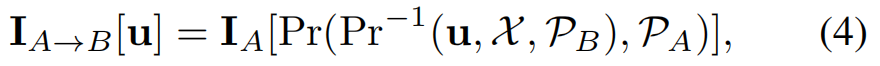
其中,Pr−1(·)表示从一个二维点到三维空间的反向投影。注意,由于反向投影本质上是三维空间中的一条射线,我们需要面模型的三维曲面,它可以由3DMM参数X诱导,以便将反向投影射线定位到一个三维点。因此,上述方程中的反投影算子Pr−1(·)除了使用相机姿态PB外,还将X作为输入。理想情况下,使用最佳的底层三维模型和相机姿态,观察到的图像IB应该与非遮挡面部区域的渲染图像IA→B相同,我们将使用这个假设来设计我们的自我监督损失(Sec 3.6.2)。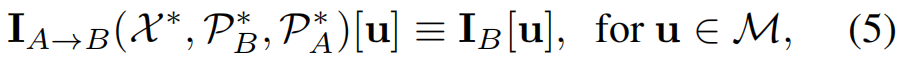
对于面部遮挡:
为了排除遮挡的面部区域,我们使用可见掩模获得 M。注意等式(5)是理想情况,渲染图像和观察图像的可见性掩模是相同的。在实践中,对于不完善的3DMM和姿态参数,我们需要不同的渲染图像和观察图像的面具来加强光度一致性(见Sec 3.6.2的细节)。
对于渲染的图像,我们简单地提取了与二维面部 landmark 对应的三维顶点遮挡的区域(三维顶点与68-points 2D facial landmarks 之间的对应由[40]提供)。图3显示了所有三个视图的可见性 mask 的一个示例。对于观察到的真实图像,我们使用纹理采样区域获得了一个初始掩模。然后以输入的真实图像为引导,对初始掩模进行联合边缘保持滤波[11],使掩模的边缘与输入图像的面部区域良好对齐。最后,使用检测到的 2D landmarks 来排除在其他视图中可能被遮挡的区域,类似于渲染图像的掩模处理(见图4)。注意,对于正面观察的图像,从左右两侧分别有两种不同的能见度罩。我们将对应掩模中的像素集表示为MB(A)和MB(C)。
Sec 3.6. Losses and Training
为了获得一个良好的初始化和避免捕获到局部最小值,使用预训练 CNN 和 300W-LP 数据集[40]的监督标签,通过传统 3DMM 拟合算法得到 ground-truth 3DMM和姿态参数,和多视图图像生成face profiling augmentation。在预训练收敛后,我们在 Multi-PIE 数据集[13]上进行自监督训练,其中在受控的室内环境拍摄多视角面部图像。
3.6.1 Supervised Pretraining
在监督预训练中,提供了 ground-truth landmark 、3DMM和姿态参数。在数据集300W-LP中,对于每个真实的面部图像,将生成几个合成的渲染视图。在训练阶段,我们为每个人脸随机选择一组多视图图像,其中包含左、正面和右视图。我们使用 ground-truth landmark ,3DMM和姿态参数作为监督,以及对3DMM参数的正则化。受监督的训练的损失是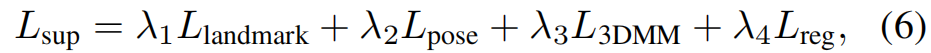
其中, landmark 是类似于[32]的 landmark 对齐损失,Lpose和L3DMM是预测和 ground-truth 之间的L2损失,Lreg是3DMM参数的正则化损失。加权 λ1、2、3、4是控制损失之间权衡的超参数。
3.6.2 Self-supervised Training
在自监督训练阶段,我们加强了观察图像和合成渲染图像之间的光度一致性,以纳入多视图几何约束。从等式网站开始(5),我们推导出了光度损耗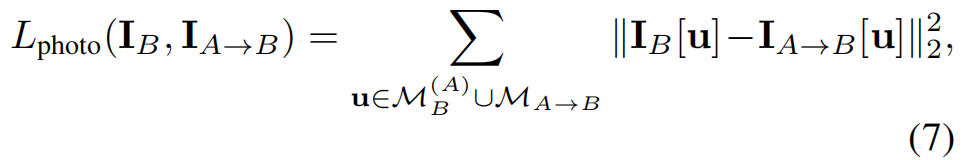
其中,MB(A)和 MA→B 分别是 IB(从左侧查看)和 IA→B 的可见性掩码中的像素集。注意,这里我们使用 M(A)B 和 MA→B 的并集,这样就可以考虑错位错误。不幸的是,我们发现在实践中只使用光度损失可能会导致错误的对准。原因是面部区域内的像素彼此相似,因此很容易发生不匹配。为了提高观测图像和渲染图像之间密集对应的可靠性,我们在训练中引入了一种新的对齐损失。
我们使用可微密集光流估计器来计算观测图像和渲染图像之间的流,然后使用所有像素的流大小的平方和作为对齐损失。由于密集光流估计器倾向于估计平滑的流场,因此可以在很大程度上抑制个体的不匹配。例如,为了加强IB和IA→B之间的光度一致性,我们计算对齐损失为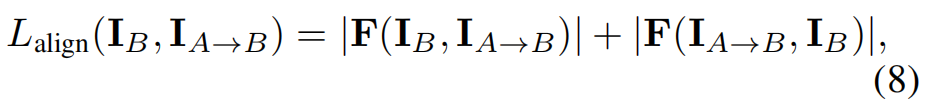
式中,F(·)为光流估计器。请注意,这里采用了双向光流。此外,为了减少不感兴趣区域的光流估计误差的干扰,我们在易于估计的区域用纹理填充可见掩模外的区域(例子见图5)。
对于三视图设置,我们计算了4对图像之间的光度损失和对齐损失:(IB,IA→B)、(IB,IC→B)、(IA,IB→A)和(IC,IB→C)。此外,为了提高训练的稳定性,我们在自监督训练中还采用了 landmark 损失 landmark ,通过[4]中最先进的 landmark 检测器自动检测 landmark 。综上所述,自监督训练损失为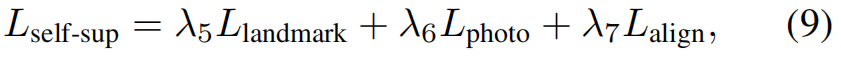
其中,光度损失Lphoto和对齐损失Lalign均由上述4对图像计算得到。超参数λ5,6,7控制了损失之间的权衡。
Experiments
Sec 4.1. Datasets and Metrics
训练数据集
1)我们的监督预训练是在 300W-LP 数据集[40]上进行的,该数据集包含超过60,000张图像,来自3,837张人脸图像,使用人脸轮廓合成方法[40]。 ground-truth landmark 、3DMM和姿态参数由数据集提供。我们使用提供的偏航角,从300个W-LP数据集上采样一个前、左、右视图图像,总共得到140k个训练三元组。
2)我们的自监督训练是在 Multi-PIE 数据集[13]上进行的,该数据集包含了337名受试者使用15台摄像机在不同光照条件下方向记录的超过75万张图像。我们以前视图图像作为锚点,随机选择侧视图图像(左或右),得到 50k 训练三元组和 5k 测试三元组,其中测试分裂的受试者在训练分裂中不出现。注意,图像是正面、左或右视图可以由提供的相机ID来确定。
评估数据集
1)我们主要对 MICC Florence 数据集[1]进行定量和定性评估,该数据集包括53个具有中性表达的人的身份和 ground-truth 的3D扫描。每个人分别包含“室内合作”、“室内”和“室外”三个视频。为了实验本文中提到的多视图设置,我们人为地为每个人选择了一组多视图框架,使他/她的表达在不同的视图中是一致的。由于在“户外”视频中很难选择这样的帧集,我们只对“室内合作”和“室内”视频进行评估。
2)进一步对 Color FERET 数据集[20,21]和 MIT-CBCL 人脸识别数据库[37]进行定性评价,其中有多视图的人脸图像。
评估指标
在对 MICC 数据集的定量评估中,我们遵循[12]的评估指标,该指标计算预测三维模型和 ground-truth 三维扫描之间的点到平面L2误差。在这里,我们放弃了ID 2和27的受试者,因为他们的 ground-truth 3D扫描是有缺陷的,也被排除在其他工作[32,12]中。
Sec 4.2. Implementation Details
- 在自监督训练步骤中,我们使用 PWCNet [31]作为可微光流估计器。请注意,在我们的训练过程中,PWCNet的权重是固定的。
- 我们根据面部 landmark 的边界框( ground-truth 或用[4]检测到)裁剪输入图像,并将其大小调整为224×224。
- 为了增加训练数据,我们在边界框中添加了输入大小为0∼0.05的随机移位。
- 我们采用 Adam [18]作为优化器。
- 批处理大小设置为12。
- 在300W-LP上对10个学习率为1e-5的周期进行监督预训练,以1e-6的10个周期进行自我监督训练。
- 平衡损失的默认权值被设置为λ1=0.1、λ2=10、λ3=1、λ4=1、λ5=1、λ6=10和λ7=0.1。我们为不同的损失项设置了不同的权重,使它们的数字在一个相似的规模上。权重λ1和λ7被设置为相对较小的值,因为它们代表像素距离。λ2和λ6的权值设置为较大的值,输入图像的像素值归一化为[0,1]。
Sec 4.3. Ablation Study
我们在MICC数据集上进行了一系列的实验,以证明在我们的方法中每个组件的有效性。表1显示了不同版本的模型的平均误差。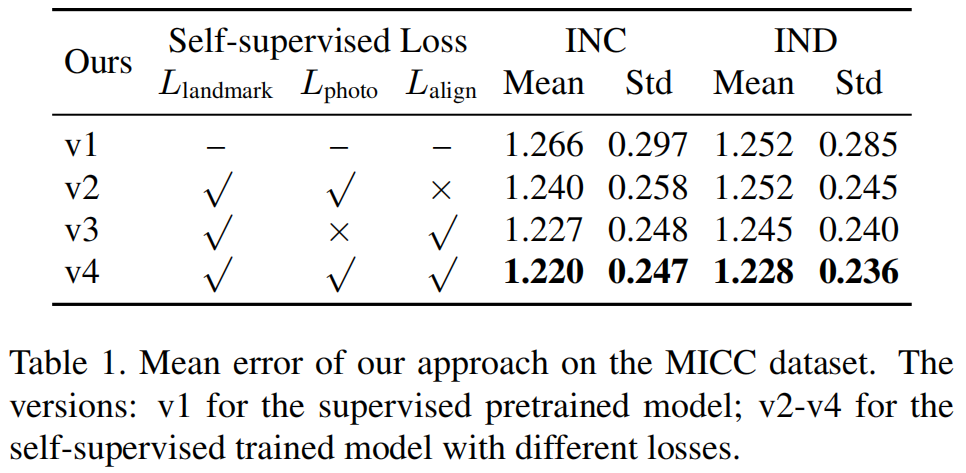
图6显示了消融研究的两个可视化例子。从特写镜头中,我们可以清楚地观察到从v1到v4的性能改进。我们可以观察到,输入面的面部轮廓是平的,而在v1的结果中,它看起来有点丰满,并且在v4的结果中变得更加平坦。通过检查三维模型的面部轮廓,在其他的例子中也可以找到同样的趋势。
我们进一步在不同的光照条件下进行研究,以证明提出的对准损失处理照明变化的有效性。图8显示了一个例子。在这个例子中,当三个视图的照明一致时(左),只使用光度损失训练的模型的表现几乎与使用光度损失和对准损失训练的模型的表现一样好。但是当视图不一致时,仅从光度损失得到的结果比从两种损失得到的结果要差得多。对齐损失对照明变化具有鲁棒的原因是光流估计器,它已经被训练来处理输入图像的照明变化。
Sec 4.4. Comparisons to State-of-the-art Methods
我们首先将我们在MICC数据集上的结果与最先进的单视图3DMM重建方法进行了比较。为了评估每个人的三视图评价三元组上的单视图方法,我们首先使用他们的模型来预测每个输入图像的三维模型和三维模型。然后采用三种不同的评价设置来确保公平的比较。第一个方法是计算每个三维模型的点到平面误差,然后对误差进行平均。第二种方法是将三个预测的三维模型平均为一个三重组,然后用 ground-truth 模型计算合并的三维模型之间的点对点误差(如表2中的“+pool”条目所示)。第三种是计算三个预测的三维模型的加权平均值为[22],然后计算点对点平面的误差(如表2所示的“+[22]”条目)。
表2显示了比较的平均误差。该方法在两种情况下都优于所有单视方法。图10显示了数据集中每个受试者的详细数值比较。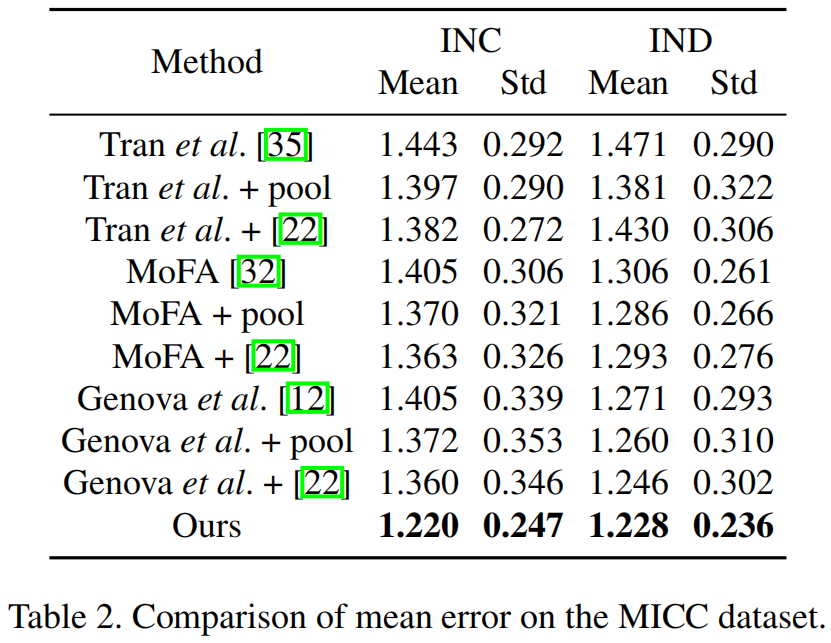
图7中给出了几个详细误差图的比较例子。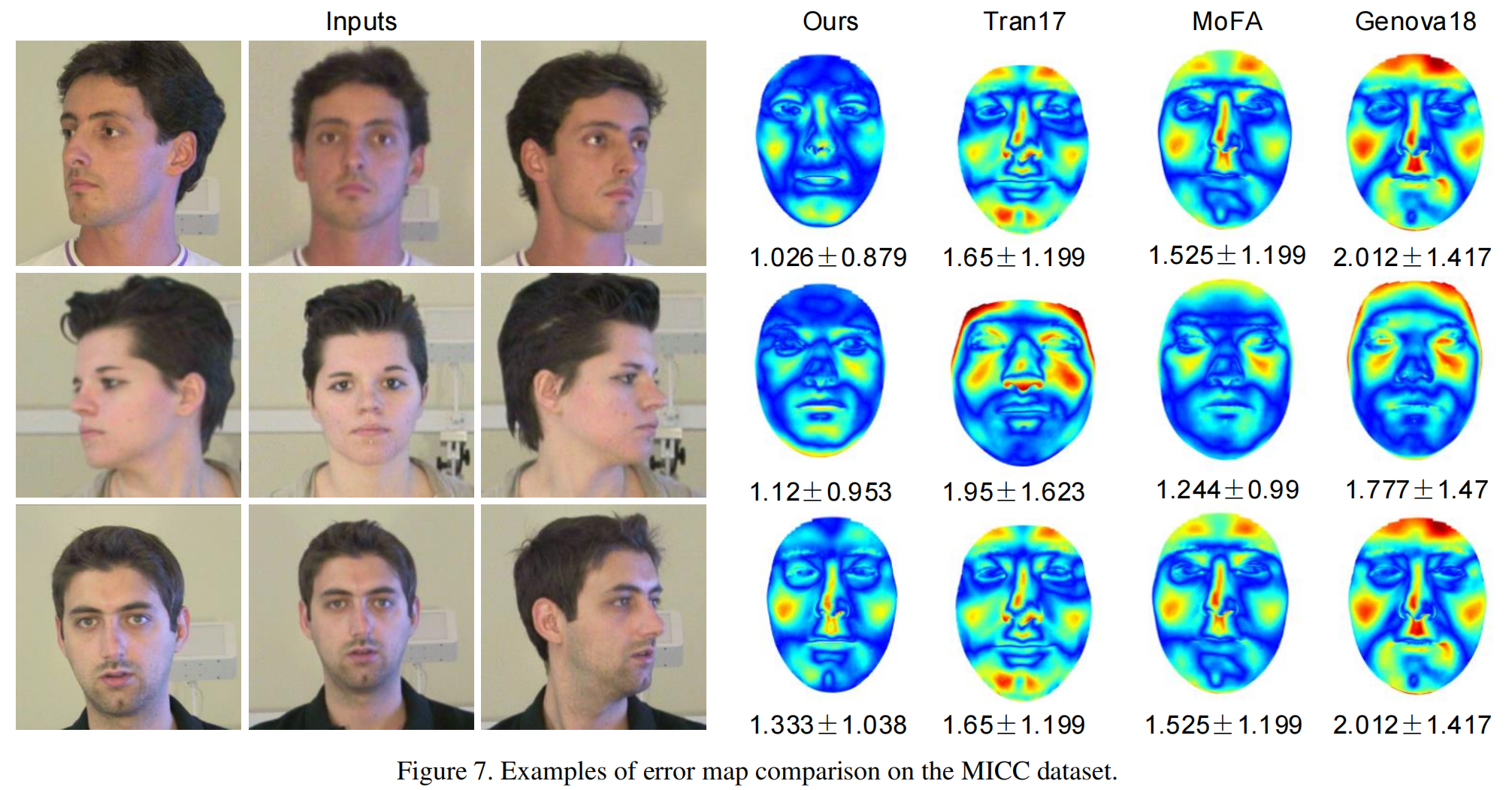
我们进一步使用来自其他数据集的图像进行了一些视觉比较,如Color FERET数据集[20,21]和MIT-CBCL人脸识别数据库[37],其中有多视图的人脸图像。
图9显示了在中性表达式中与单视图方法的视觉比较的几个例子。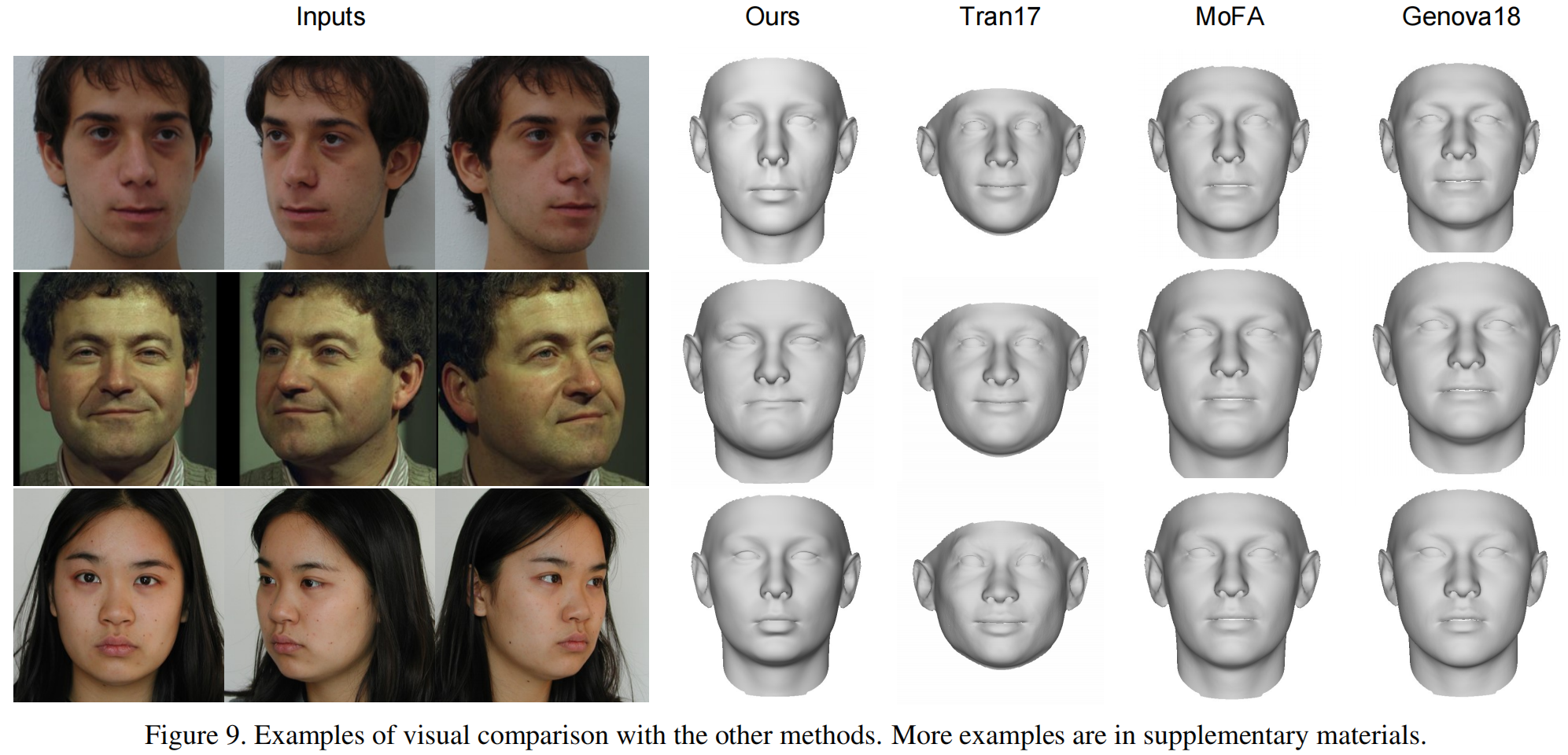
图11显示了在不同面部表情中与 MoFA [32]的视觉比较的几个例子。
在这些比较中可以观察到我们的方法相对于单视点方法的优越性。

若有收获,就点个赞吧
0 人点赞
