Wang_2021_One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
代码 https://github.com/FuxiVirtualHuman/AAAI22-one-shot-talking-face
论文 https://arxiv.org/pdf/2112.02749.pdf
视频 https://www.youtube.com/watch?v=HHj-XCXXePY
技术要点
- 头部运动预测器 Eh
- 从音频中估计头部运动序列(包括3D旋转和3D平移);
- 采用了 [[Wang_2021_Audio2Head]] 的头部运动预测器的网络结构。
- 关键点检测器 Ekd
- 从参考图像中提取初始关键点;采用与在FOMM [[Siarohin_2019]] 中一样的 Ekd 架构。
- 它主要保留了身体、面部和背景的基于姿态的结构信息,削弱了身份相关信息。这种初始结构信息在生成的密集运动场中主导着低频整体布局。
- Audio-visual Correlation Transformer (AVCT) Eavct
- 将音频信号映射到基于关键点的密集运动场(dense motion field);
- 每40ms提取了一个声学特征 ai 和一个音素标签 pi。
- 音素由语音识别工具提取。使用音素标签作为输入,减少不同人音色的影响。
- 声学特征包括梅尔频率倒频系数(MFCC)、梅尔滤波器组能量特征(FBANK)、基频和语音标志。
- 图像渲染器 Er
- 从密集运动场生成输出图像;采用与在FOMM [[Siarohin_2019]] 中一样的Er的架构。
算法优缺点
- 优点
- 学习一个特定人的说话风格,但推理时可以语音驱动任意人。以前学习特定人,驱动也只能驱动那个人。
- 对于语音特征,除了常用的MFCC外,还引入了音素标签。
- 对不同的人进行语音驱动,生成的视频中动作基本统一。
- 缺点
- 为了让视频显得自然而给了身体一些动作,只有头部的时候看着还行,当肩膀也入镜时会觉得肩膀的晃动频率不合理,整体有违和感(视频 1:24~1:34)。
原文
Introduction
我们观察到,从一个特定的说话者那里学习一致的语言风格会容易得多,从而导致真实的嘴部运动。我们的方法探索了来自特定说话人的音频和视觉运动之间的一致的语音风格,然后将基于音频驱动的关键点的运动场转移到参考图像中,用于生成说话的人脸。
为了实现这一目标,我们首先开发了一个独立于说话者的视听相关 Transformer (Audio-Visual Correlation Transformer, AVCT),从音频信号中获得关键点基密集的运动场(Siarohin等人2019)。为了消除不同身份之间的音色效应,我们采用音素来表示音频信号。通过输入的音素和头部姿态,编码器有望建立潜在的姿态纠缠视听映射。
考虑到生动的嘴的运动与音频信号密切相关(例如,嘴的振幅受到激烈的音调的影响),我们使用嵌入的声学特征作为解码器的查询,来调节嘴的形状,以实现更生动的嘴唇运动。采用了一个相对运动转移模块(Siarohin et al. 2019)来减小训练身份和一次性参考之间的运动差距。一旦获得密集的运动场,我们就通过图像渲染器生成谈话的头部视频。
值得注意的是,我们的方法也可以处理具有平移和旋转头部运动的说话面孔,而现有技术通常处理旋转头部运动。在广泛使用的VoxCeleb2和HDTF上进行的广泛实验结果证明了该方法的优越性。
总之,我们的贡献有三方面:
- 我们提出了一种新的音频驱动的一次性说话人脸生成框架,该框架建立了从特定的说话人中建立一致的视听相关性,而不是像之前的技术那样从不同的说话人中学习。
- 我们设计了一个视听相关转换器,它将基于音素和基于面部关键点的运动场表示作为输入,从而允许它很容易地扩展到任何其他音频和身份。
- 虽然视听相关性只从特定的说话人中学习,但我们的方法能够生成真实的嘴唇同步、精确的说话面部视频、自然的嘴唇形状和有节奏的头部运动。
Proposed Method
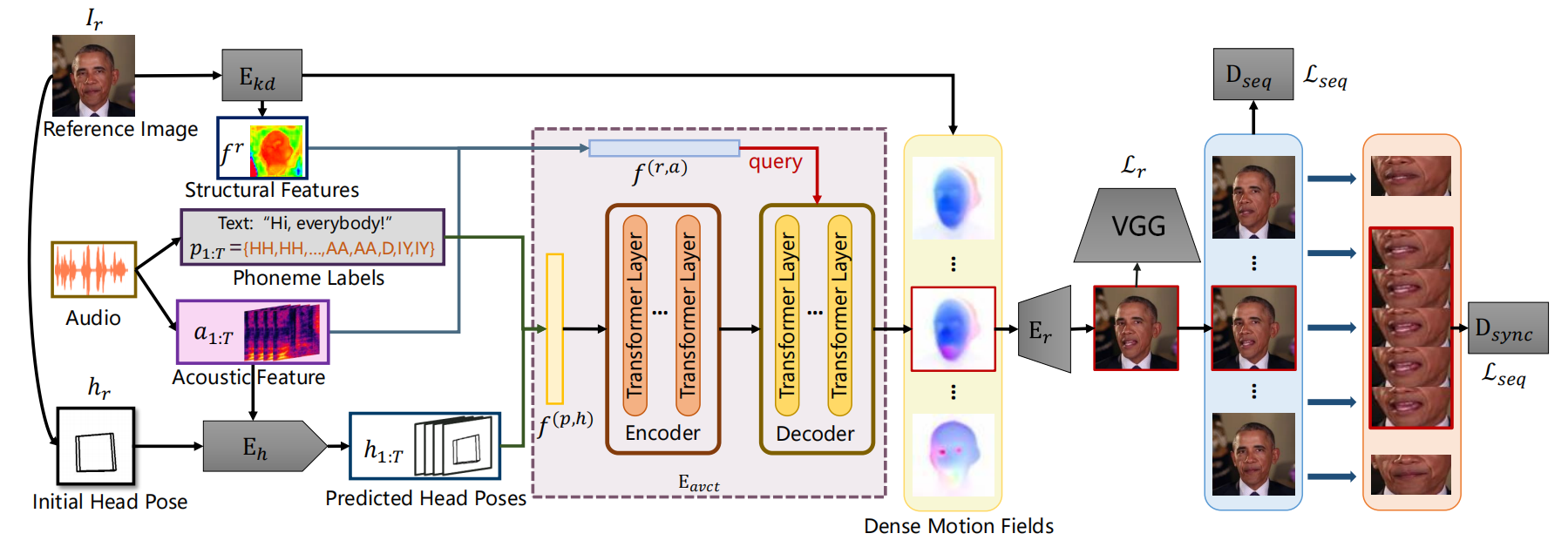
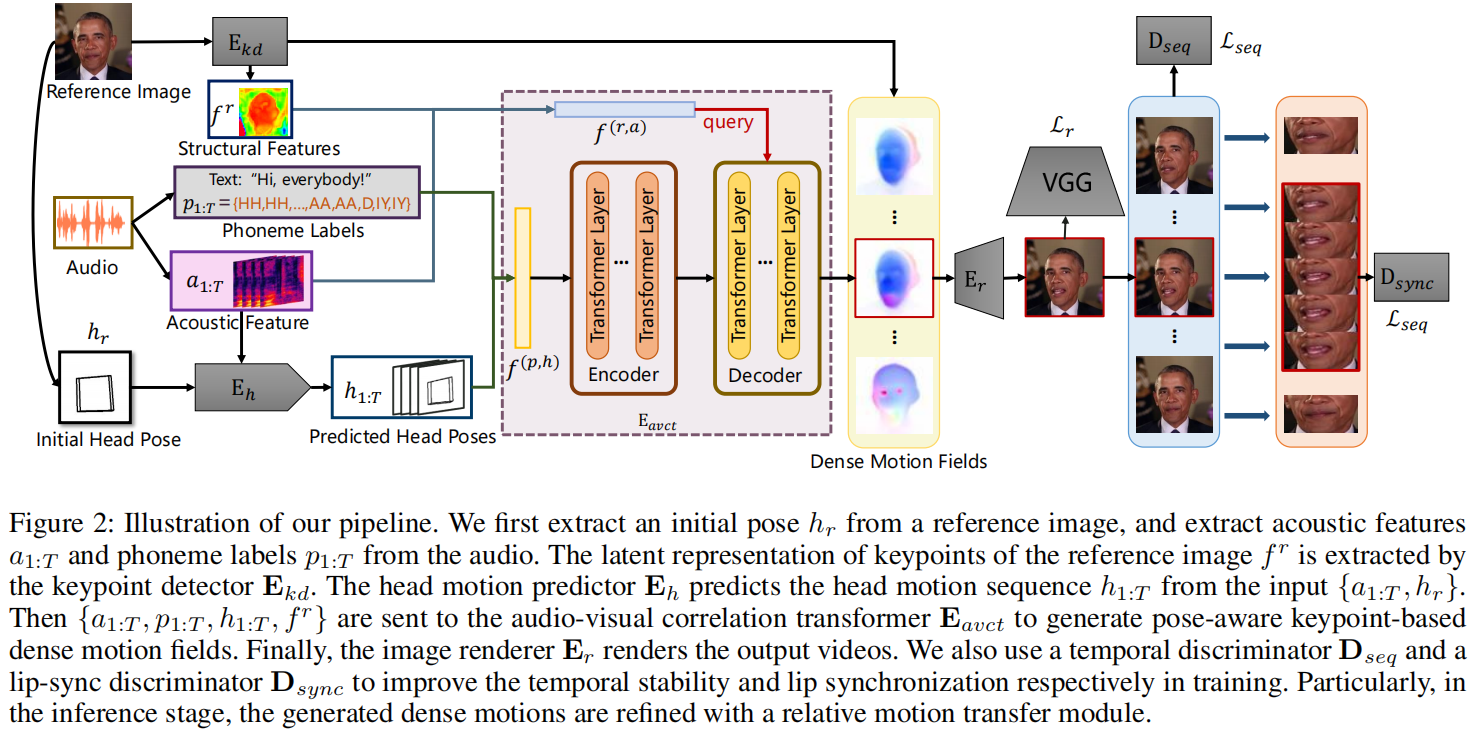
整个管道如图2所示。我们的管道由四个模块组成:
- 头部运动预测器Eh,从音频中估计头部运动序列(包括3D旋转和3D平移);
- 关键点检测器Ekd,从参考图像中提取初始关键点;
- 视听相关 Transformer (AVCT)Eavct,将音频信号映射到基于关键点的密集运动场(dense motion field);
- 图像渲染器Er,从密集运动场生成输出图像。我们采用了与在FOMM(Siarohin 2019)中一样的Ekd和Er的架构。
我们从训练视频中提取音频通道,并将其转换为音频特征和音素作为预处理。为了与25帧每秒的视频保持一致,我们每40ms提取了一个声学特征 ai ∈R4×41 和一个音素标签 pi∈ R。声学特征包括梅尔频率倒频系数(MFCC)、梅尔滤波器组能量特征(FBANK)、基频和语音标志。该音素由语音识别工具提取。
Audio-visual Correlation Transformer (AVCT)
该方法的核心是建立精确的视听相关性,这可以扩展到任何其他的音频和身份。这种相关性是通过一个说话人独立的视听相关性 Transformer 来学习的。考虑到较高的时间相干性,Eavct以滑动窗口中组装好的特征作为输入。
具体地说,对于第 i 帧,Eavct 接受配对条件输入 ci = {fr, ai−n:i+n, hi−n:i+n, pi−n:i+n},并输出关键点ki∈RN×2及其对应的雅可比矩阵 ji∈RN×2×2。fr是参考图像Ir通过关键点检测器 Ekd 对关键点的潜在表示。N表示窗口长度,在我们的实验中被设置为5。N是关键点的个数,并被设置为10。成对的(ki,ji)代表密集的运动场(Siarohin et al. 2019)。头部运动h1:T由OpenFace提取(baltraital.2018)。
AVCT能够在时间窗口内聚集动态的视听信息,从而创建更准确的嘴唇运动。为了模拟不同模式之间的相关性,我们采用 Transformer (Vasvanietal.2017)作为AVCT的主干,因为其强大的注意机制。为了更好地扩展到任何其他音频和身份,我们仔细设计了编码器和Eavct的解码器如下。
Encoder
我们使用音素标签作为输入,而不是声学特征,来弥补特定说话人和任意说话人之间的音色差距。我们通过编码输入音素 pi−n:i+n 和姿态 hi−n:i+n 建立了一个潜在的姿态纠缠视听映射。序列帧2n+1之间的注意允许在帧 i 处获得细化的潜在嘴运动表示。
具体来说,我们使用了一个256维的单词嵌入(Levy 2014)来表示音素标签,然后对其进行重塑和上采样为fi p∈R1×64×64。Hi被转换为投影二值图像2h∈R1×64×64,如(Wang et al. 2021)。然后,将连接的特征{fip,fih}输入到由52个×下采样ResNet块组成的残差卷积网络中(He 2016),以获得组装的特征fi(p,h)∈R1×512。
输入到编码器的输入是顺序特征 f(p,h)∈ R(2n+1)×512,通过连接所有的帧特征沿着时间维度。由于转换器的结构是排列不变的,我们用固定的位置编码来补充 f(p,h)(Vaswanietal.2017)。
Decoder
实际上,除了音素外,口腔的振幅还受到音频的响度和能量的影响。为了创造更微妙的口腔运动,我们在解码阶段使用声学特征来捕捉能量变化。我们使用上采样卷积网络从ai中提取了音频特征 fia∈R32×64×64。为了减少对身份的依赖,我们不能直接将参考图像作为输入,而是使用参考图像Ir的关键点的潜在表示,fr∈R32×64×64。fr从预训练的关键点检测器Ekd中提取。它主要保留了身体、面部和背景的基于姿态的结构信息,削弱了身份相关信息。这种初始结构信息在生成的密集运动场中主导着低频整体布局。
fr重复2n+1次。然后将fir和fia的串联体输入到另一个残差卷积网络中,得到嵌入的fi(r,a)。同样,我们通过连接获得特征f(r,a)∈R(2n+1)×512,并用位置编码补充它。f(r,a)被用作解码器的初始查询,以调节身体、头部和背景的布局,并细化微妙的嘴的形状。按照标准变压器,解码器创建2n+1个嵌入。只将第i个嵌入投影到具有两个不同线性投影的关键点ki和雅可比矩阵 ji 上。
Batched Sequential Training
由于AVCT分别生成每一帧的密集运动场,我们开发了一个批顺序训练策略来提高时间一致性。每批视频上的训练样本由来自同一视频的T个连续图像的T个连续条件输入ci:T组成。然后,我们在每个批处理中并行生成图像序列 Iˆ1:T。这种设计允许我们对每个批处理中的图像序列应用约束,而不是对单个图像应用约束。我们将上述策略称为批量顺序训练(BST)。除了每一帧图像的像素损失外,还通过时间鉴别器Dseq施加顺序约束。此外,由于常见的像素重建损失不足以监督唇型,我们采用了另一种唇型鉴别器Dsync来改善唇型。
Temporal Discriminator
Dseq遵循PatchGAN的结构(Goodfell等2014年;Isola等2017年;Yu和P2017a,b;Yu等2018年)。我们沿着通道维度叠加T个连续的图像帧作为Dseq的输入。Dseq试图区分输入是自然的还是合成的。Dseq和Eavct与生成-对抗性学习共同学习。
Lip-sync Discriminator
Dsync采用了Wav2Lip中SyncNet的结构(Prajwal等人2020)。Dsync被训练为通过随机采样一个与视频窗口同步或异步的音频窗口来区分音频和视频之间的同步。区分帧位于窗口的中间,窗口大小设置为5。Dsync从图像编码器计算视觉嵌入ev和从音频编码器计算音频嵌入ea。我们采用余弦相似度来表示ev和ea是否同步的概率。
Loss Function
基于批序列训练,将每个批图像序列的损失函数定义为: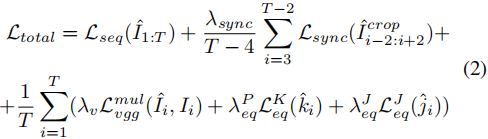
其中Lseq是Dseq的GAN损失。Lsync是从预先训练过的Dsync中得到的lipsync损失。注意,Iˆcrop指的是裁剪的嘴区域,我们忽略了边界帧,以适应Dsync的时间输入。在每次训练迭代中,我们根据真实视频的检测到边界框动态裁剪口腔区域。Lmulvgg是一种依赖于预先训练好的vgg网络的多层感知损失。LKeq和 LJeq是等方差约束损失(Siarohin et al. 2019),以确保估计的关键点和雅各比矩阵的一致性。在我们的实验中,T被设置为24(在RTX 3090上),λsync、λv、λPeq和λ J eq分别被设置为10、1、10、10。
Head Motion Predictor
头部运动预测器Eh,用来在推理阶段产生h1:T,也在特定的说话者上进行训练。Eh采用了Audio2Head的头部运动预测器的网络结构(Wang et al. 2021),但有两个差异。首先,Eh不是接受大量身份的训练,而是接受特定说话者的训练。因此,为了避免对特定说话人的外观进行过拟合,我们将Audio2头的输入参考图像替换为投影的二进制姿态图像。其次,为了方便相对运动传递(见下文),预测的头部姿态序列的起点应与参考图像的头部姿态相同。因此,当训练Eh时,我们将第一预测帧的头部姿态和参考图像之间的L1损失项添加到原始损失函数中。
Relative Motion Transfer
由于生成的运动场不可避免地与特定的说话人纠缠在一起,我们在推理阶段采用了相对运动转移(Siarohin et al. 2019),以减少训练身份与一次性参考图像之间的运动差距。我们将(kˆ1,ˆj1)和(kˆ1:T,ˆj1:T)之间的相对运动转移到(kr,jr)。(kr,jr)从参考图像中检测到。此操作的定义为: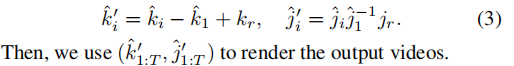
本文重点参考的2篇论文
- Siarohin, A.; Lathuili`ere, S.; Tulyakov, S.; Ricci, E.; and Sebe, N. 2019. First order motion model for image animation. Advances in Neural Information Processing Systems, 32: 7137–7147.
- Wang, S.; Li, L.; Ding, Y.; Fan, C.; and Yu, X. 2021. Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion. IJCAI.

若有收获,就点个赞吧
0 人点赞
