Title: Real-Time Speech Emotion Recognition Using a Pre-trained Image Classification Network: Effects of Bandwidth Reduction and Companding
https://www.frontiersin.org/articles/10.3389/fcomp.2020.00014/full#h7
Speech Emotion Recognition (SER)
有限的训练数据问题在很大程度上可以通过一种称为迁移学习的方法来克服。它使用对大量数据进行预训练的现有网络来解决一般分类问题。然后使用少量可用数据进一步训练(微调)该网络以解决更具体的任务。
鉴于目前最强大的预训练神经网络是用来训练图像分类的,要将这些网络应用于SER问题,需要将语音信号转换成图像格式(Stolar et al., 2017)。本研究描述了语音到图像转换的步骤;它解释了训练和测试程序,以及从连续流语音中实现实时情感识别需要满足的条件。考虑到许多可编程语音通信平台都采用语音扩展,语音带宽被压缩到4khz的窄范围内,本文研究了语音扩展和带宽压缩对实时SER的影响。
Related work
传统SER
早期的 SER 研究寻找情绪和语音声学之间的联系。系统地分析各种低级声学语音参数或参数组,以确定与说话者情绪的相关性。该分析应用了标准分类器,例如支持向量机 (SVM)、高斯混合模型 (GMM) 和浅层神经网络 (NN)。Schröder (2001)、Krothapalli 和 Koolagudi (2013)以及Cowie 等人对 SER 方法进行了全面回顾。(2001 年)。在Schuller 等人中可以找到广泛的基准比较。(2009b)。
大多数低级韵律和频谱声学参数,例如基频、共振峰频率、抖动、微光、语音频谱能量和语速,都与情绪强度和情绪过程相关(Scherer,1986 年,2003 年;Bachorovski 和 Owren, 1995 年;陶和康,2005 年)。良好的 SER 结果由更复杂的参数给出,例如 Mel 频率倒谱系数 (MFCC)、频谱滚降、Teager 能量算子 (TEO) 特征(Ververidis 和 Kotropoulos,2006 年;He 等人,2008 年;Sun 等人) ., 2009 )、声谱图 ( Pribil and Pribilova, 2010 ) 和声门波形特征 (舒勒等人,2009b;他等人,2010;Ooi 等人,2012 年)。
后来通过添加高级导数和低级参数的统计函数来丰富低级特征。慕尼黑多功能快速开源音频特征提取器 (openSMILE) 提供了一个计算平台,允许计算许多低级和高级语音声学描述符 ( Eyben et al., 2018 )。
使用CNN
频谱图提供了一维语音波形的二维图像式时频表示,它保留了信号的完整性。
一些研究调查了卷积神经网络 (CNN) 对整个语音谱图阵列或特定谱图带进行分类以识别语音情感的应用(Han et al., 2014 ; Huang et al., 2014 ; Mao et al., 2014 ; Fayek 等人,2015 年,2017 年;Lim 等人,2016 年;Badshah 等人,2017 年;Stolar 等人,2018 年)。在法耶克等人。(2015), 使用 DNN 研究了来自短帧语音频谱图的 SER。达到了 60.53%(六种情绪 eENTERFACE 数据库)和 59.7%(七种情绪—SAVEE 数据库)的平均准确率。一种类似但改进的方法导致 64.78% 的平均准确率(IEMOCAP 数据有五个类别)(Fayek 等人,2017 年)。 ( Lim et al., 2016 )使用语音频谱图在 EMO-DB 数据上训练了各种结合 CNN 和循环神经网络 (RNN) 的级联结构。对于最佳结构,七种情绪的平均精度为 88.01%,召回率为 86.86%。在韩等人。(2014), CNN 用于学习情感显着特征,然后将其应用于双向循环神经网络,从 IEMOCAP 数据中对四种情绪进行分类。结果表明,这种方法导致了 64.08% 的加权准确率和 56.41% 的未加权准确率。尽管这些方法很有吸引力,但仍有改进的余地。
导致准确性相对较低的原因:
- 语音数据库太小,无法确保对深度网络结构进行充分训练。
- 数据中情感类别和性别表示是不平衡的。
最近的研究表明,语音分类任务可以重新表述为图像分类问题,并使用预训练的图像分类网络来解决(Stolar 等人,2017 年;Lech 等人,2018 年)。语音到图像的转换是通过计算语音的幅度谱图并将其转换为RGB图像来实现的,这种方法通常用于可视化频谱图。在这种情况下,目标是创建一组图像来执行预训练的深度卷积神经网络的微调。
实时SER
语音的实时处理需要连续的流式输入信号、快速处理和在有限时间内稳定输出数据,这与生成分析数据样本的时间相差几毫秒。
对于给定的 SER 方法,实时实现的可行性取决于计算特征参数所需的时间长度。
根据最新的研究进展,特征提取和推理过程都可以实时执行。微调的 CNN 已被证明可确保高 SER 精度和短推理时间,适用于实时实现(Stolar 等人,2017 年)。
影响SER的实施因素
- 语音压缩、滤波、频带缩减和噪声的添加会降低 SER 的准确性。(Albahri 和 Lech (2016)、Albahri 等人(2016)和Albahri (2016))
- SER 性能取决于用于生成 SER 训练数据库的情感表达类型(Stolar 等人,2017)。与通过阅读情感丰富的文本诱发情感的 eENTERFACE 数据库相比,在具有由专业演员表演的情感的 EMO-DB 数据库中实现了更高的 SER 性能。Stolar等人(2017)对EMO-DB数据进行了性别依赖和性别无关的SER测试,结果显示两者之间只有很小的差异。
Methods
由于大多数现有的预训练网络都是为图像分类创建的,要将这些网络应用于语音,必须重新定义 SER 问题为图像分类任务。为了实现这一点,标记的语音样本被缓冲到短时间块中(图 1)。对于每个块,计算一个光谱幅度谱图阵列,转换为 RGB 图像格式,并作为输入传递给预训练的 CNN。经过相对较短的训练(微调)后,使用相同的语音到图像转换过程,对未标记(流式传输)语音推断情感标签推断(即识别情感)。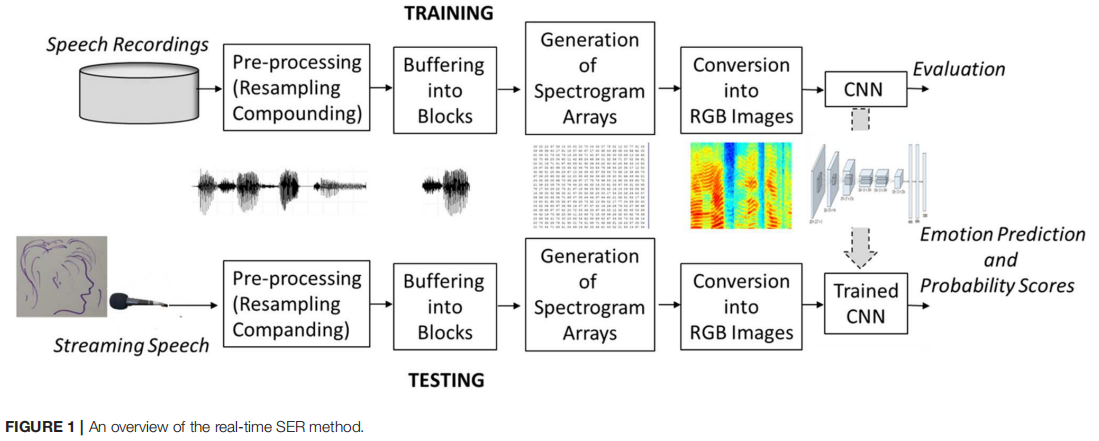
在此处介绍的实验中,使用两种不同的采样频率(16 和 8 kHz)和 μ-low 压扩程序测试了 SER 性能。本文 SER 系统使用 Matlab 2019a 编程软件和配备 Intel Xeon CPU、2.1 GHz、128 GB RAM 的 HP Z440 工作站实现。
预处理
Sampling Frequency
降低带宽可能导致说话者传达的情感信息大幅减少。
为了测试这种可能性,对SER系统进行了两种不同采样频率的训练,原始的16khz对应于8khz的宽带语音带宽,而降低的采样频率对应于4khz的窄带带宽。
将采样频率从16 kHz降低到8 kHz的过程包括两个步骤(Weinstein,1979)。首先,应用一个8阶低通切比雪夫 I 型无限脉冲响应滤波器去除超过奈奎斯特频率8 kHz的频率,以防止混叠。其次,通过去除每秒钟的样本,将语音的采样降为原来的2倍。
Speech Companding
本文研究了语音压缩方法(称为 μ-law 算法)对SER的影响。
在发送端,该算法采用对数振幅压缩,对高振幅语音分量进行更高的压缩,对低振幅语音分量进行更低的压缩。压缩后的语音通过通信信道传输,在传输过程中采集噪声。
接收端将语音信号扩展到原来的振幅水平,同时保持高振幅和低振幅分量的信噪比(SNR)相同。
没有companding system 的传输将导致高振幅信号分量的高信噪比值和低振幅信号分量的低信噪比值(Cisco, 2006)。压缩后的膨胀过程称为压扩companding procedure过程(图2)。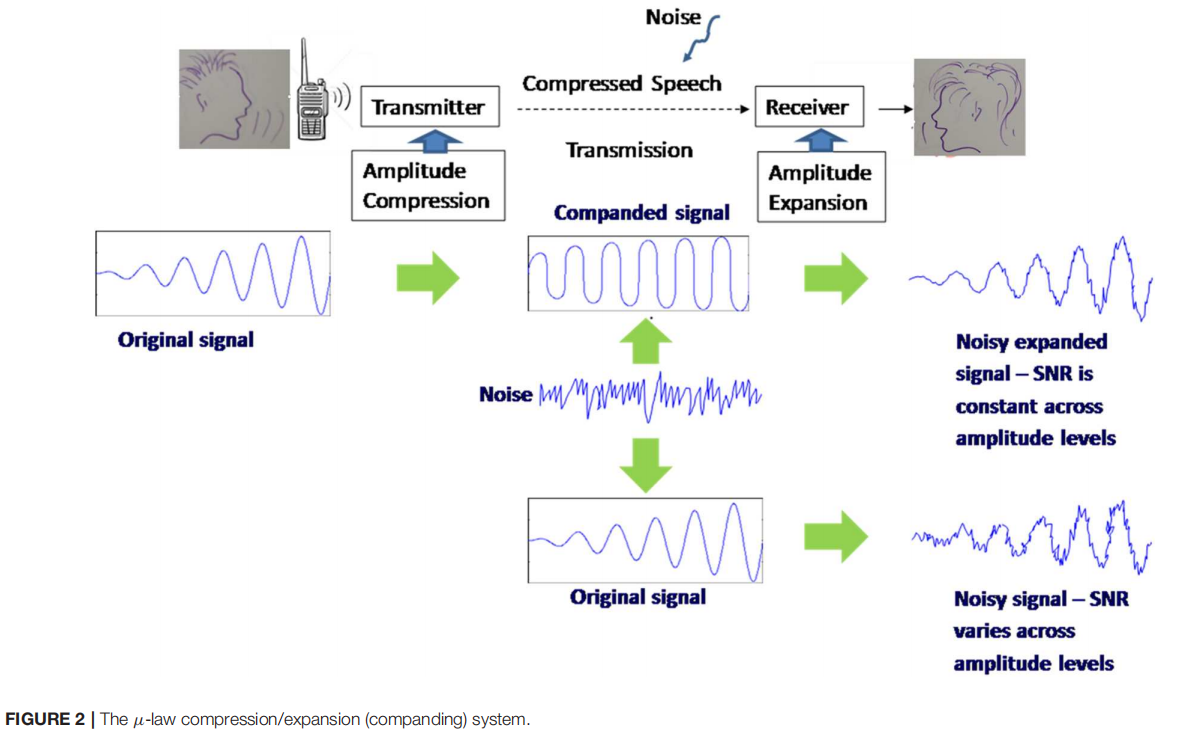
Buffering Speech Waveforms into Blocks
流或录制的语音被缓冲成1秒的块,进行逐块处理(图1)。在随后的块之间应用10ms 的短步幅。振幅水平归一化到 [-1, 1] 的范围。没有使用预强化滤波器。
由于语音记录是逐句标注的,我们假设1秒语音块的情感标签与该语音块(或该语音块中的大多数样本)所属的语音句子的标签相同。
1s 的块持续时间是根据经验确定的,是观察说话者情绪状态之间快速过渡变化的最佳时间(Cabanac,2002;Daniel,2011)。它也被证明可以最大限度地提高SER的准确性。通过后续块间10 ms的非常短的步幅,生成了相对较多的图像(见表2),这反过来提高了训练过程和网络的准确性。
Generation of Spectrogram Arrays
Spectral Magnitude Calculation
用于生成谱图阵列的过程如图3所示。对每个1秒的语音波形进行短时傅里叶变换,使用 时移汉明窗函数(time-shifting Hamming window function)生成的16ms 帧。随后的帧之间的时移是4毫秒,帧之间有75%的重叠。
短时傅里叶变换的实和虚输出被转换为频谱幅度值,并在属于给定块的所有后续帧之间串联起来,形成大小为257×259的时频频谱幅度数组。式中,257为图像数组中频率值的个数(行),259为图像数组中时间值的个数(列)。
计算是使用Matlab Voicebox spgrambw 程序进行的,频率步长 Δ f 参考自 Voicebox (2018)。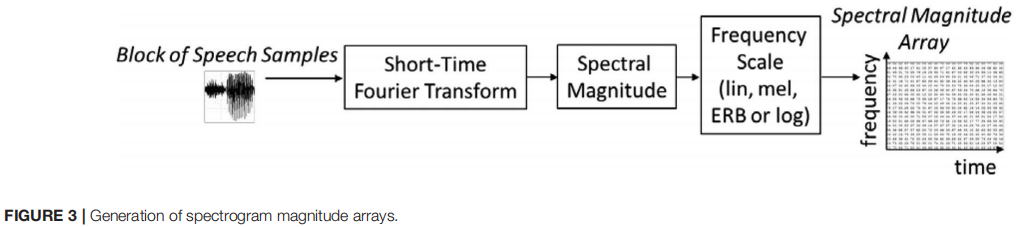
Frequency Scaling 频率尺度
虽然幅度谱图的时间尺度在 0 到 1 s 的时间范围内始终是线性的,但谱图的四种可选频率尺度:线性、旋律 (Mel) ( Stevens and Volkman, 1940 )、等效矩形带宽 (ERB) ( Moore和 Glasberg,1983 年)和对数(log)(Traunmüller 和 Eriksson,1995 年)沿频率轴(从 0 Hz 到 fs /2 Hz)应用。测试了不同的频率尺度以进行比较。计算公式如下,
图5显示了频率标度对谱图图像描述的语音谱分量视觉外观的影响。同样的句子,带有愤怒、悲伤和中性情绪的声谱图被绘制在四种不同的频率尺度上:线性、Mel、ERB和log。可以看出,这种尺度顺序对应着逐渐放大zooming into低频范围特征(约0-2 kHz)的过程,同时缩小zooming out 高频范围特征(约2-8 kHz)的过程。因此,不同频率尺度的应用可以有效地为网络提供更多或更少的频谱上下范围的详细信息。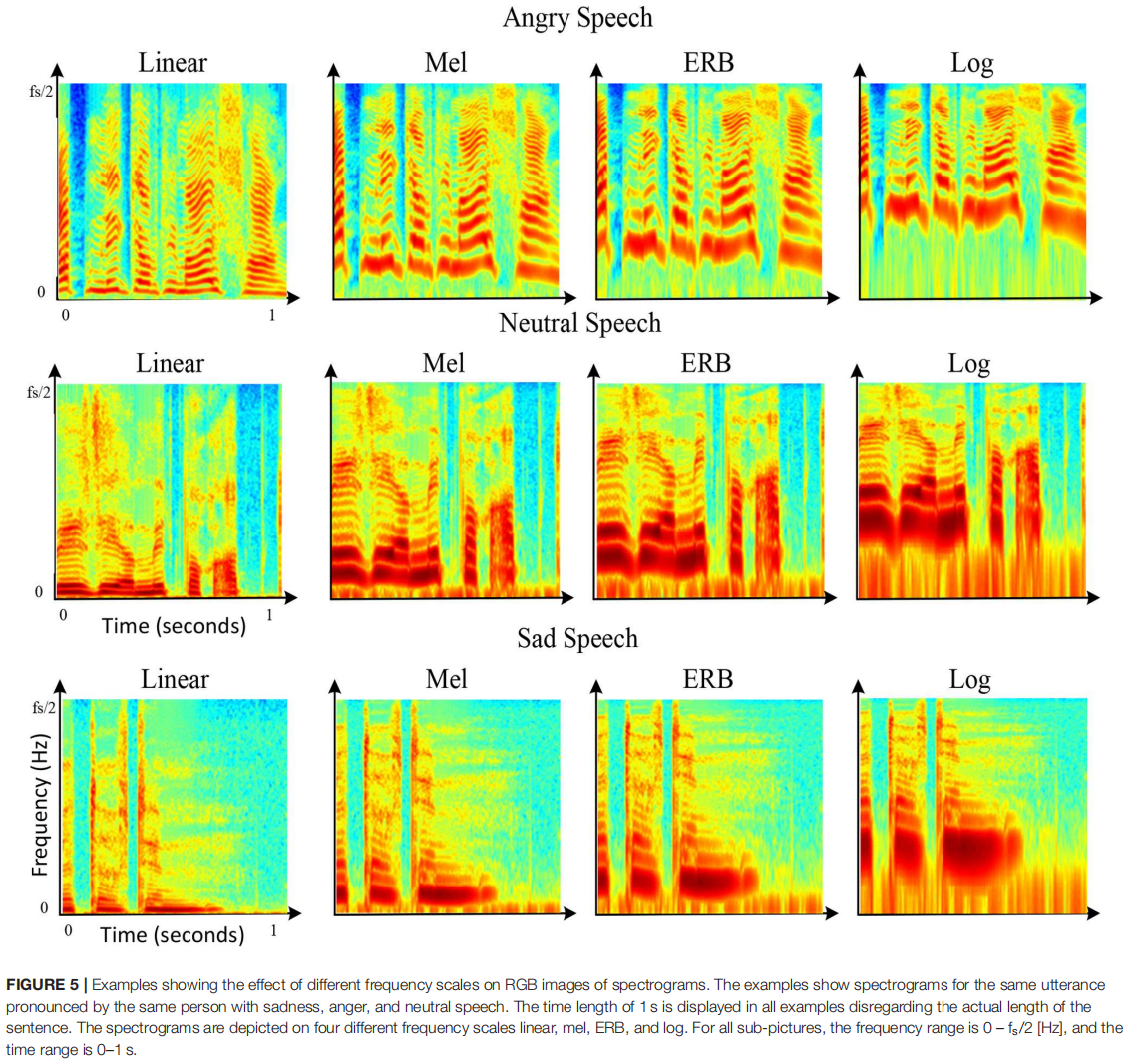
Conversion into RGB Images
Dynamic Range Normalization
基于在整个训练数据集上估计的平均最大值和最小值,将原始光谱幅度阵列的动态范围从 Min [dB] 归一化到 Max [dB]。
对于原始未压缩语音,数据库的动态范围为 -156 dB 至 -27 dB,而对于复合语音,范围为 -123 dB 至 -20 dB。选择这些范围是为了最大化轮廓的可见性,该轮廓概述了基频 (F0) 语音共振峰的时频演变,以及 F0 的谐波分量。
图5显示了Min [dB]和Max [dB]的不同值对可视化结果的影响。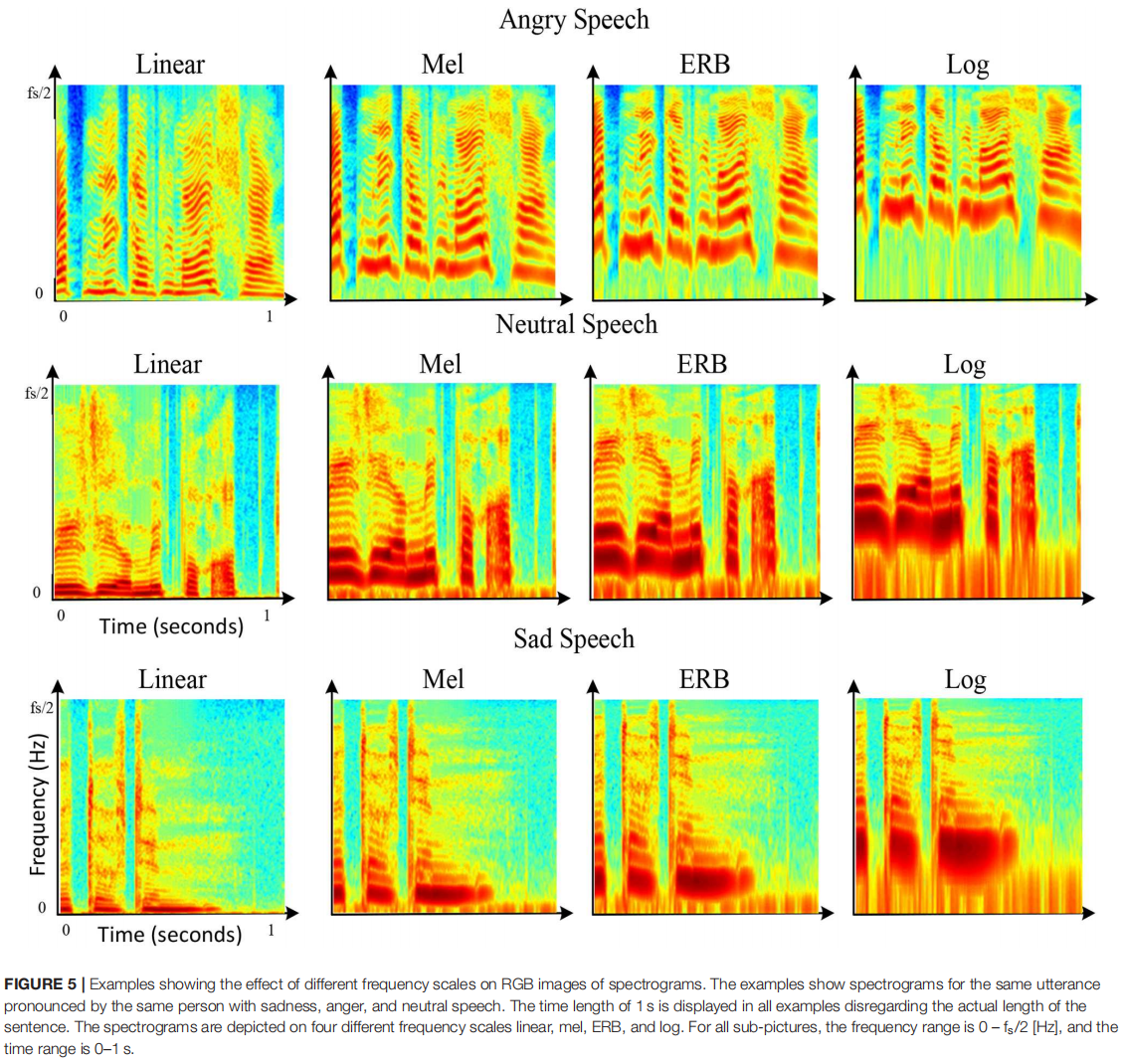
图6说明了谱幅动态范围的不同归一化对谱图细节可视化的影响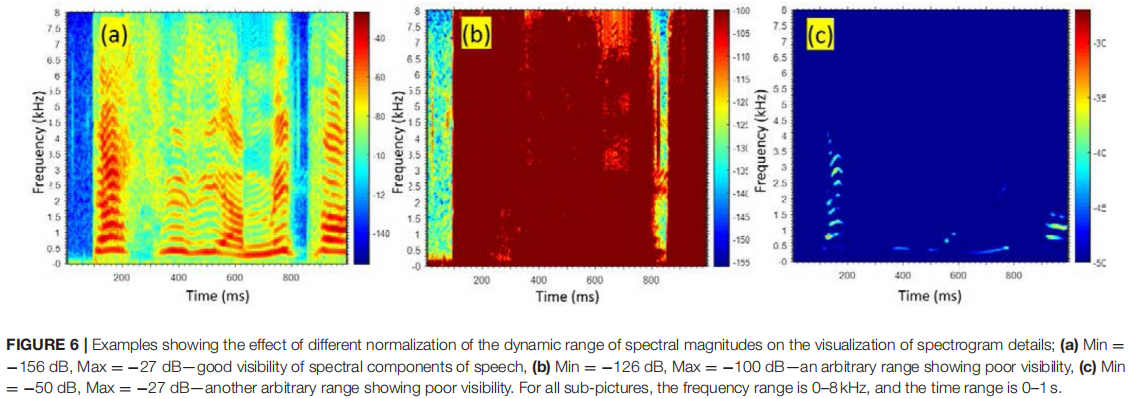
(a) Min = -156 dB, Max = -27 dB——语音频谱分量的良好可见性,
(b) Min = -126 dB,Max = -100 dB——显示较差可见性的任意范围,
(c) Min = −50 dB,Max = −27 dB — 另一个显示较差可见度的任意范围。
对于所有子图,频率范围为 0-8 kHz,时间范围为 0-1 s。
使用R、G和B分量代替谱幅阵列有两个重要的优点。
首先,这三个数组为CNN的三个输入通道提供了不同类型的信息。R 分量对于高光谱振幅级别的语音具有较高的红色强度,因此强调了高振幅语音分量的细节。当振幅较低时,B 组分的蓝色强度较高;因此,强调细节的低振幅谱分量。同样,G 分量强调了中距离光谱振幅分量的细节。
其次,语音以图像的形式表示,我们可以使用现有的预先训练的图像分类网络,用相对较短的时间和低数据的微调过程代替长时间和数据贪心模型的训练过程。
Conversion into R, G, and B Arrays
将 257 × 259 实数值的光谱幅度数组转换为由三个颜色分量数组表示的彩色 RGB 图像格式(图7)。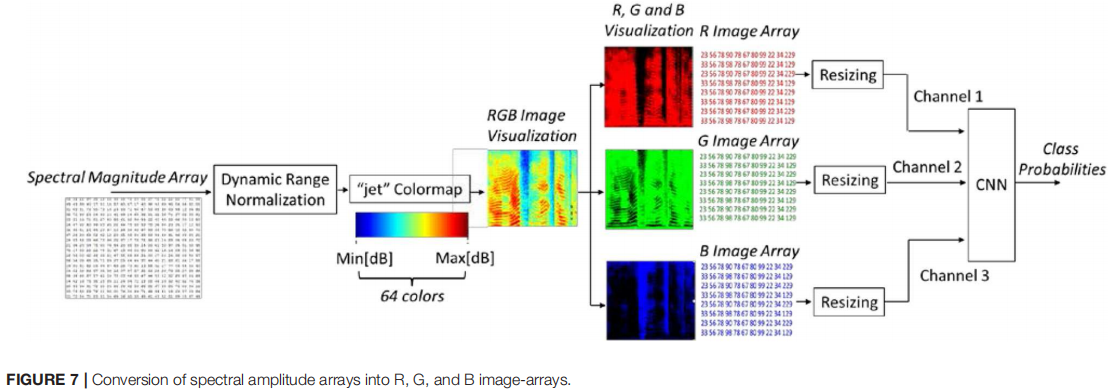
如Lech 等人(2018)所示的,与灰度图像相比,RGB 图像的 SER 性能略高。向 RGB 格式的转换基于 Matlab“ jet ”颜色图。
“jet”colormap 的 64 种颜色提供了权重,允许将原始光谱幅度数组的每个像素值拆分为三个值,分别对应于 R、G 和 B 分量。因此,每个原始的 257 × 259 幅度数组都被转换为三个数组,每个数组的大小为 257 × 259 像素。非正式视觉测试基于 Matlab 提供的其他颜色图。
Classifification Network
AlexNet
考虑到标注情感语音数据的大小非常有限,以及相对较小的计算资源,迁移学习方法被用于微调现有的预训练图像分类网络AlexNet。
AlexNet是Krizhevsky等人(2012)介绍的卷积神经网络(CNN)。它已经对来自斯坦福大学ImageNet数据集的120多万张图像进行了预训练,以区分1000种对象类别。
它由3通道输入层组成,允许输入3个二维数组,每个数组的大小为256256像素。输入层之后是五个卷积层(Conv1-Conv5),每个卷积层都有maxpooling和归一化层(图8)。最后一个卷积层Conv5的二维输出特征被转换为一维向量,并馈送到三个全连接层(fc6-fc8)。卷积层从输入数据中提取特征特征,全连接层学习数据分类模型参数。SoftMax指数函数将fc8输出值映射为一个归一化向量,该向量中实数范围为[0,1]、总和为1。这些值在输出层给出,表示每个类的概率。最终的分类标签是由获得最高概率分数的类给出的。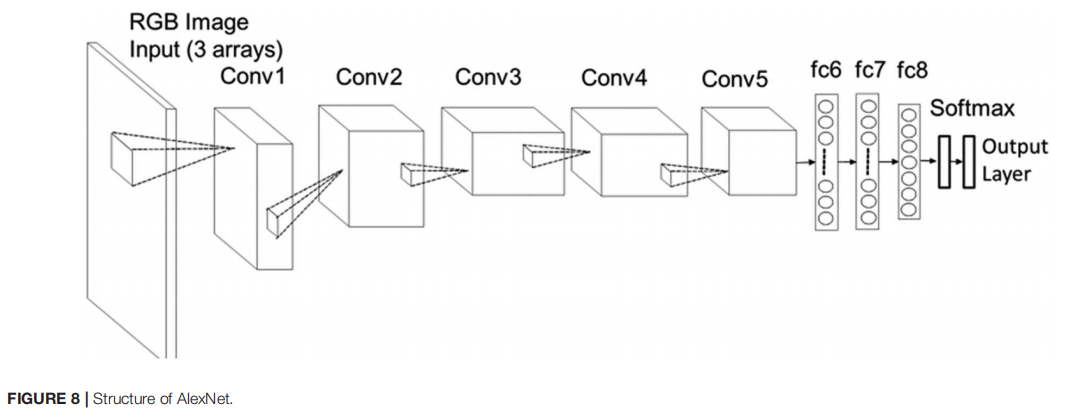
Adapting AlexNet to SER
由于Alexnet所需的输入大小为256×256个像素,因此使用Matlab的 imresize 命令对257×259个像素的原始图像数组进行了非常小的调整。调整大小没有造成任何明显的失真。
RGB光谱图图像的每个颜色分量都作为输入传递到AlexNet的单独通道。
将原来的 fc8 (最后一个全连接层)、Softmax层和输出层修改为7个输出,来学习区分7个情感类。
Fine-Tuning of AlexNet
AlexNet 在标记的情绪语音数据上进行了训练(微调)。
尽管近年来,AlexNet 已经被更复杂的网络结构所匹敌(Szegedy et al., 2015),它仍然具有很大的价值,因为它在数据需求、时间、网络简单性和性能之间提供了很好的折衷。
在迁移学习中,微调过程旨在对网络的最终全连接(数据相关)层产生最大的学习影响,同时保持较早的(数据独立)层几乎完好无损。为了在新的修改层中实现更快的学习,在旧的迁移层中更慢,将初始学习率设置为较小的值,并且仅对全连接的“权重学习率”和“偏差学习率”值增加层。
本文使用 Matlab(2019a 版)进行微调。该网络使用动量随机梯度下降 (SGDM) 和 L2 正则化因子进行优化,以最小化交叉熵损失函数。表 1提供了网络调整参数的值。
Speech database
Berlin Emotional Speech Database (EMO-DB) ( Burkhardt et al., 2005)EMO-DB 数据的原始采样频率为 16 kHz,对应 8 kHz 语音带宽。
该数据库包含了10名专业演员(5名女性和5名男性)用流利的德语说出的7种分类情绪(愤怒、快乐、悲伤、恐惧、厌恶、无聊和中性语言)的语音样本。每个说话者对10个不同的话语(5个短的和5个长的)表现了7种情绪,这些话语都带有情绪中性的语言内容。在一些录音中,说话者会提供同一话语的多个版本。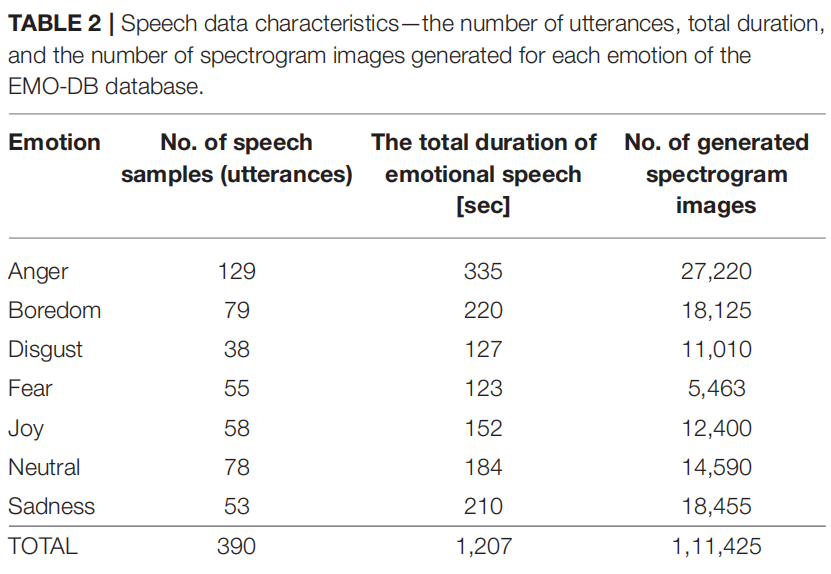
EMO-DB 的优势在于它很好地表示了性别和情感类别,而它的主要劣势在于情感的表现方式过于强烈,这在某些情况下可能会被认为是不自然的。
Conclusion
实验证明,reduction of the speech bandwidth 和 speech companding µ-low procedure 这两个因素都对SER结果有不利的影响。图9显示了实验1-4使用光谱图的不同频率尺度的平均精度。
通过将采样频率从16 kHz降低到8 kHz(即,将带宽从8 kHz降低到4 kHz),观察到平均SER精度略有降低(约3.3%)。压缩程序减少了类似的数量(约3.8%)。两种因素的联合作用导致了约7%的减少。
频谱图的ERB频率尺度导致了两种结果,相对较高的基线结果(79.7%的平均加权精度)和对带宽减少和低扩压程序应用的不利影响的高鲁棒性。
在所有实验情况下,SER都是实时执行的,每1.033-1.026s 生成一个情绪标签。

若有收获,就点个赞吧
0 人点赞
