生成器与作者前一个工作 LipGAN 中的生成器相同,而 LipGAN 是在论文 (You said that?)的基础上进行了修改, 包含3个分支:Face Encoder, Audio Encoder, 还有Face Decoder。
You said that? 的生成器结构
输入是0.35秒的音频和目标身份的静止图像。
音频:音频编码器的输入是从原始音频数据中提取的mel频率的反频谱系数(MFCC)值。MFCC值由单个系数组成,每个系数代表非线性mel频率尺度上音频短期功率的特定频带;每个样本计算13个系数,但在我们的案例中只使用最后12个系数。馈入音频编码器的每个样本由0.35秒的输入音频数据组成,采样率为100Hz,从而产生35个时间步长。每个编码的样本可以看作一个12×35热图,每列代表每个时间步长的MFCC特征(见图5)。
身份:身份标识编码器的输入是一个尺寸为112×112×3的单一静止图像。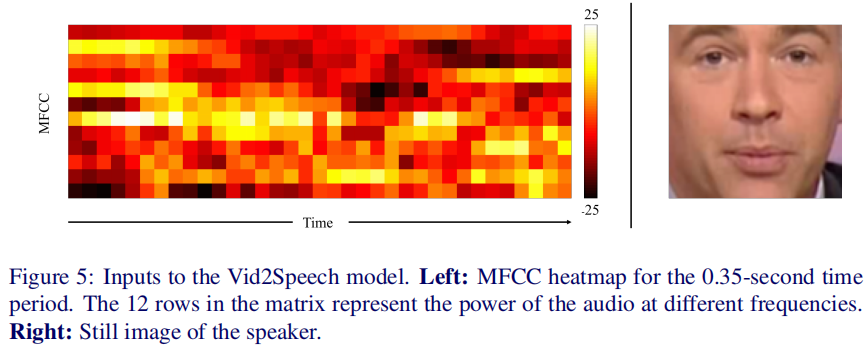
音频到视频的模型结构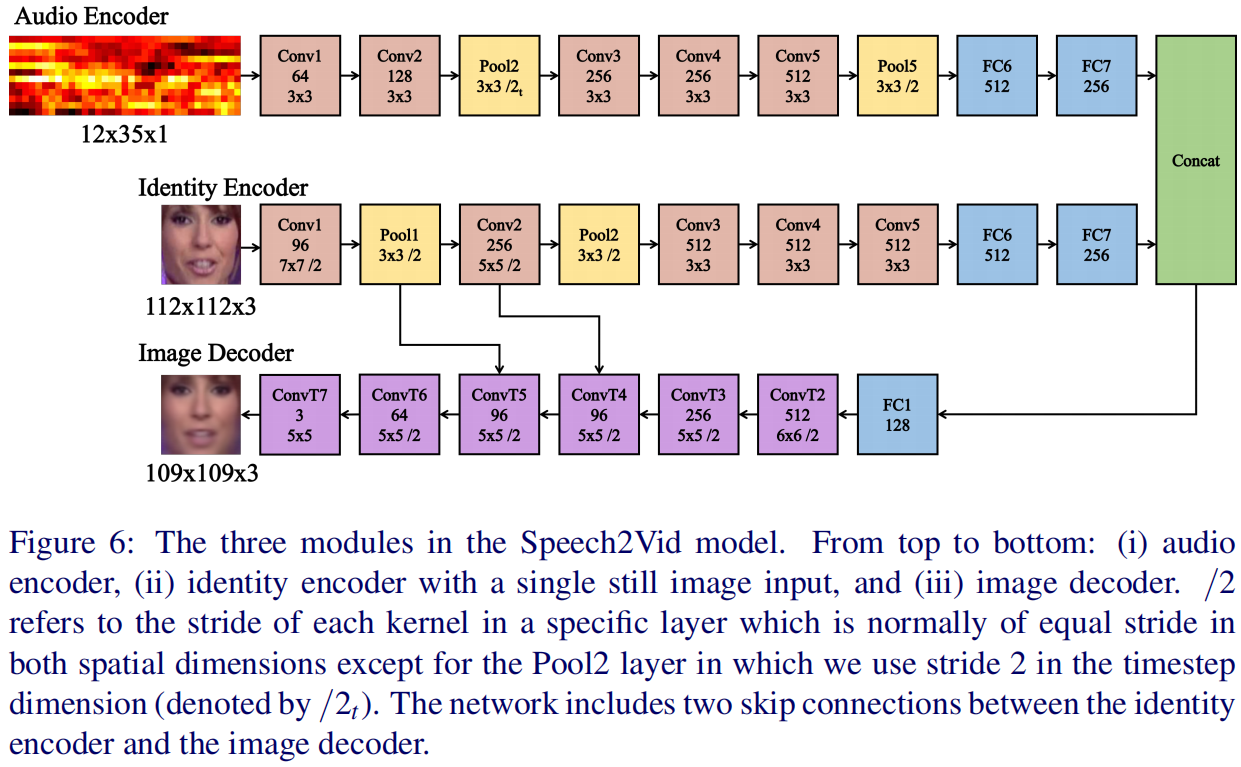
- Audio Encoder:我们使用了一个最初设计用于图像识别的卷积神经网络。层配置基于AlexNet [16]和VGG-M [2],但过滤器的大小适用于不寻常的输入尺寸。这与[5]中学习音频嵌入的配置类似。
- Identity Encoder:我们使用了在VGG Face数据集[22]上预先训练的VGG-M网络。在编码器中只使用卷积层的权值,而全连接层的权值被重新初始化。
- Image Decoder。解码器将音频和身份编码器(均为256维)的FC7层的连接特征向量作为输入。特征向量通过转置卷积逐层逐步上采样。
在训练过程中,使用地面真实输出图像作为监督。说话人输入身份的图像从不同的时间点随机采样,如图7所示。
LipGAN 的生成器结构
LipGAN的输入也是人脸图片和语音。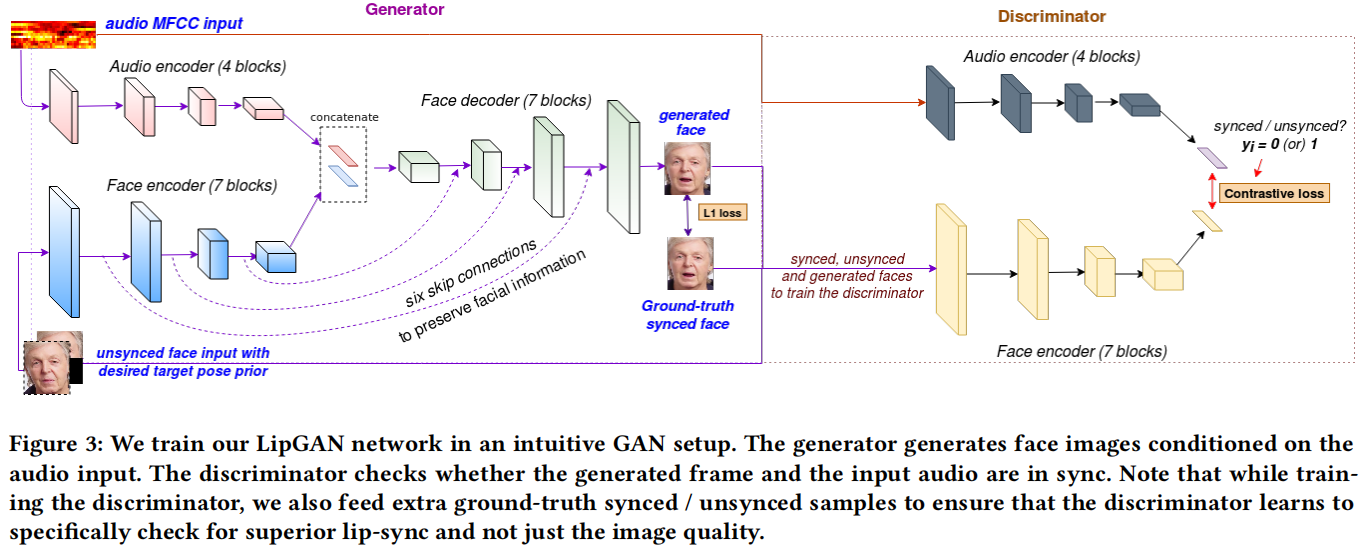
作者提出,训练时提供的的随机姿态的照片与其对应的语音,但随即姿态与地面真实的姿态可能不同,所以需要输入地面真实的人脸,以提供姿态信息。但为了不泄露嘴部的真实口型,于是将地面真实的下半张人脸mask掉。
- Face Encoder:The encoder consists of a series of residual blocks with intermediate down-sampling layers and it embeds the given input image into a face embedding of size h. The input to the face encoder is a HxHx6 image(也就是随机照片和mask后的真实照片的连接).
- Audio Encoder. The audio encoder is a standard CNN that takes a Mel-frequency cepstral coefficient (MFCC) heatmap of size MxTx1 and creates an audio embedding of size h.
- Face Decoder: 在mask的真实照片上重建口型同步的下半张脸。It contains a series of residual blocks with a few intermediate deconvolutional layers that upsample the feature maps. The output layer of the Face decoder is a sigmoid activated 1x1 convolutional layer with 3 filters, resulting in a face image of HxHx3. 每个上采样操作后使用跳连接,确保在生成面部时解码器保留细粒度输入面部特征,总共使用了6个。

若有收获,就点个赞吧
0 人点赞
