Zheng Fang et al., “Facial Expression GAN for Voice-Driven Face Generation,” The Visual Computer: International Journal of Computer Graphics 38, no. 3 (2022): 1151–64, https://doi.org/10.1007/s00371-021-02074-w.
- 生成器的输入只有语音特证,没有图像。
- 核心思想是使用辅助分类器来帮助鉴别器更好地识别基于该图像中所表示的身份和情感的人脸图像是生成的,还是真实的。
解决什么问题
表情是重建更清晰、更有分辨力的人脸的关键人脸属性,而很多voice-to-face generation的工作没有考虑表情信息。所以本文提出了FE-GAN,它在面部生成过程中考虑了情绪和表达。
1 Introduction
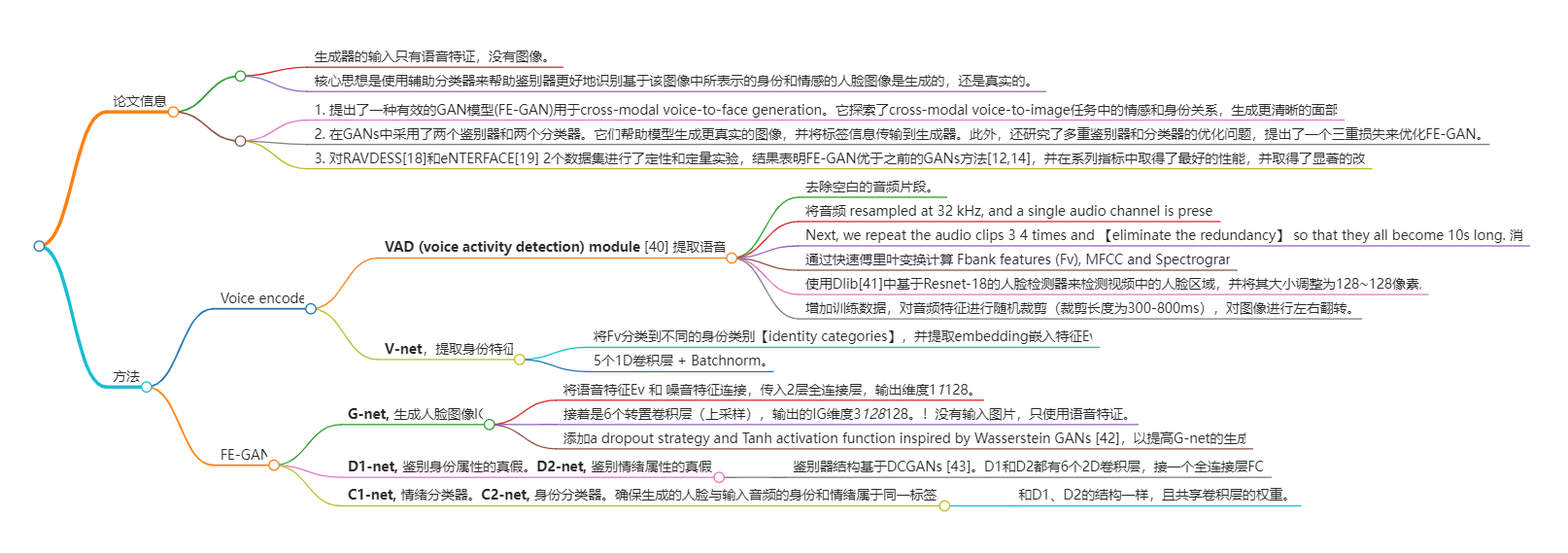
在本文中,我们提出了一种新的模型,面部表情动态变化模型。通过给定的语音信息来生成面孔。简而言之,FE-GAN同时考虑了面部和声音的情感和身份变化。人类声音和面部[16,17]中存在语义一致性,促使我们采用识别标签和情绪标签进行模型训练。具体来说,更多的鉴别者可以考虑到情绪和身份的约束,这样生成者也可以保留更多的情感和身份特征。所提方法的简化管道如图1所示。
FE-GAN的核心由一个生成器网络(G-net)和两个鉴别分类器对组成,例如(C1-net、D1-net)和(C2-net、D2-net)。在生成过程中,语音编码器从语音剪辑V中提取Fbank特征Fv,并通过V-net获得语音嵌入Ev。接下来,以Ev作为输入,生成器G-net生成人脸图像IG。最后,利用两个鉴别器D1-net和D2-网区分人脸图像的真假,同时辅助分类C1-网和C2-网对其身份和情感进行预测。这种 FE-GAN 的设计不仅可以学习人脸和声音之间的一对一映射,还可以捕捉目标人与输入语音相关的各种情绪。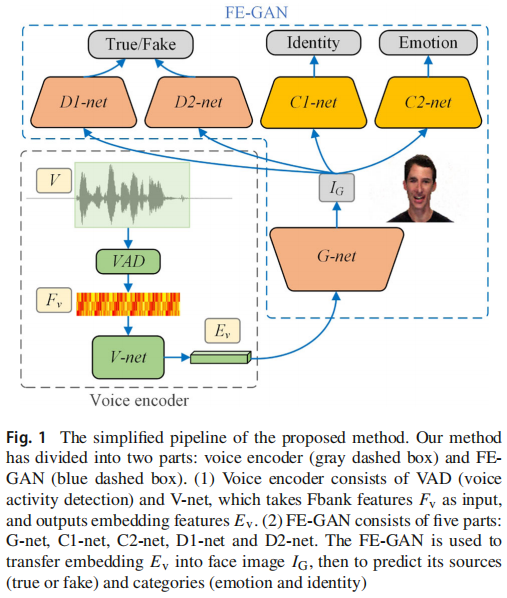
贡献点
- 提出了一种有效的GAN模型(FE-GAN)用于cross-modal voice-to-face generation。它探索了cross-modal voice-to-image任务中的情感和身份关系,生成更清晰的面部图像。
- 在GANs中采用了两个鉴别器和两个分类器。它们帮助模型生成更真实的图像,并将标签信息传输到生成器。此外,还研究了多重鉴别器和分类器的优化问题,提出了一个三重损失来优化FE-GAN。
- 对RAVDESS[18]和eNTERFACE[19] 2个数据集进行了定性和定量实验,结果表明FE-GAN优于之前的GANs方法[12,14],并在系列指标中取得了最好的性能,并取得了显著的改进。
2 Related work
2.1 Generative adversarial networks
FE-GAN模型基于AC-GANs[15]和D2GANs[20]。与这两者的不同在于,使用了两个鉴别器和相应的分类器来指导生成器生成逼真的面部图像。2.2 Audio representations selection and extraction
2.3 Audio-to-visual generation
3 Proposed methods
3.1 Overview of V-net and FE-GAN
本节给出了V-net和FEGAN的详细体系结构,如图2所示。
- V-net是一种具有归一化功能的标准CNN,它从语音韵律特征中学习语音嵌入。
- FE-GAN由G-net(从语音嵌入生成人脸图像)、D1-net与C1-net和D2-netC2(两对鉴别器及其分类器分别从身份和情感的角度识别人脸图像是否真实)组成。
从视频中提取说话者的声音和脸,我们可以获得的训练数据元组,_F_v, _IT_, _l_ve, _l_vi, _l_fe, _l_fi,其中Fv是从说话者的声音中提取的Fbank特征,IT是人脸图像,lxy是基于属性x的y的标签,其中x可以是v(声音)或f(人脸),y可以是i(身份)或e(情感)。考虑到身份标签lvi和Fbank特征Fv,我们首先对V-net进行预训练,通过其声音对一个人进行分类。经过V-net的预训练后,可以提取出每个语音的语音嵌入Ev。
随后,给定一个带有高斯噪声Ng的语音嵌入Ev,训练G-net生成目标人脸IG。同时,我们使用真实的face IT与标签(lfi,lfe)和带有标签的假人脸IG(lve,lvi)来训练鉴别器D1-net和D2-net,并使用辅助网络C1-net和C2-net。通过训练D1-net和D2-net分别区分输入人脸图像IT或IG为真或假;分别训练C1-net和C2-net对情绪进行分类,识别输入人脸的标签。此外,还设计了结合来自发生器、鉴别器和分类器的三重损失损失方程,以优化FE-GAN。
3.2 Pre-processing and V-net
我们首先使用语音活动检测(VAD)模块[40]对原始语音去除无声帧(例如,在原始数据集中,原始语音的平均持续时间为3.6 s。在去除无声的部分后,它被缩短为2.4s。)。然后,在32 kHz下重新采样语音剪辑,并保留一个单一的音频通道。接下来,我们重复音频剪辑3 4 次,并消除冗余,使它们都变成10秒长。此外,通过快速傅里叶变换计算bank特征(Fv)、MFCC和谱图,窗口长为33 ms(毫秒),跳长为16 ms。此外,我们使用Dlib [41]中基于Resnet-18的人脸检测器来检测视频中的人脸区域,并将其大小调整为128∼128像素。为了增加训练数据,我们在音频特征中使用随机裁剪,在图像中使用左右翻转,裁剪长度为300-800 ms。
我们的 V-net 旨在将特征Fv分类为不同的身份类别,并提取语音嵌入特征Ev。V-net以64×T(频率×时间)维Fv作为输入,输出1个×128维特征Ev。图2的最上面一行显示了V-net的网络架构,其中有5个一维卷积层1D-Conv1、1D-Conv2、…,和1D-Conv5,内核大小为3、步幅2和填充1,然后以Leaky-ReLU作为激活函数进行批归一化(BN)操作。在第5卷积层之后,Fv的时间通道被减少到256。接下来,我们沿着时间维度应用平均一维池化层。这使得我们能够随着时间的推移有效地聚合信息,并使该模型适用于不同持续时间的输入语音。通过一维池化层,Vnet将特征Ev压缩为1×128维。此外,利用softmax函数的交叉熵损失训练Vnet。
3.3 G-net
G-net将学习语音嵌入和生成的图像之间的情感和身份映射,从而生成更真实的人脸图像来欺骗识别者。
G-net的体系结构如图2的中间行所示。首先,将语音嵌入Ev与1×128维噪声Ng连接,该连接的嵌入通过两个全连接层(FC1、FC2)操作映射到1×1×128。然后,我们使用6个二维转置卷积层(TrConv1 6)上采样到3×128×128维IG。每一层的内核大小为4,步幅为2和填充量为1,然后是BN和ReLU。除了第一层(内核大小4、步1和填充0)和最后一层(内核大小1、步1和填充0)。转置层中的通道数为10245122561286432。为了提高G-net的生成能力,我们添加了一个受瓦瑟斯坦GANs [42]启发的退出策略和Tanh激活函数
3.4 D-net and C-net
原始的AC-GANs进行反向传播,主要由一个鉴别器和一个分类器决定。一个鉴别器只从一个角度判断图像,而不是从不同的语义角度。同样地,一个分类器也不能解决多标签的一致性问题。本文认为,对应的声音和面孔可以与这两种类型的语义标签相匹配。因此,除了区分说话者与D1-net的真实或虚假的身份属性外,我们还通过D2-net来区分真实或虚假的情感属性。为了进一步控制生成过程中的标签一致性,我们使用两个相应的分类器C1-net和C2-net来确保生成的人脸与输入音频属于同一标签。
设计D1-net和D2-net来区分输入图像是真脸IT还是假IG。这样,假标签和真标签分别与IG和IT耦合,然后将它们输入D1-net和D2-net,得到两个分数。这两种鉴别器的体系结构如图2的下一行所示。它们都有6个二维卷积层。每一层后面只有一个LeakyReLU函数。卷积层中的通道数是G-net的倒数,为32-64-128-256-512-1024,其他参数如核大小、步幅也是倒数。最后,我们应用一个具有1个通道和s型激活函数的FC7,得到一个分数作为输出。此外,我们的鉴别器是基于DCGANs的[43]体系结构。
C1-net是一种情绪分类器,有助于实现说话者的表达重建。C2-net是身份分类器,可以确保说话者的面部身份。也就是说,IG的情绪类别和相应的声音情绪标签Lve应该保持一致,面部情绪标签Lfe与IT的类别保持一致。此外,C1-net和C2-net分别与D1-net和D2-net的卷积层共享权重。这些分类器的结构类似于D1-net和D2-net,如图2的底部一行所示,它们还包括6个二维卷积层,然后是Leaky-ReLU函数、一个FC7和softmax函数。两个分类器的FC7分别有i和m个通道(i表示说话者的数量,m表示语音情绪类别)。
3.5 Triple loss
由以下三部分组成:
- 生成器 loss LG
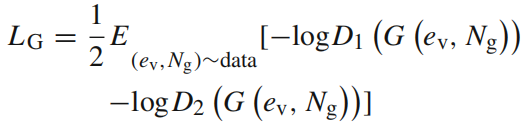
- 2个鉴别器的 loss LD1 and LD2
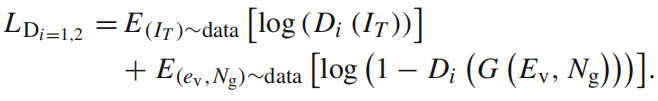
- two classifier losses LC1**,** guarantee the semantic consistency, control the generated faces in the specific class domains。
是交叉熵函数 with softmax activation。函数是一样的,只是LC1计算身份标签的loss,LC2计算情绪分类的loss。?这里感觉写反了,C1是情绪分类器,C2是身份分类器。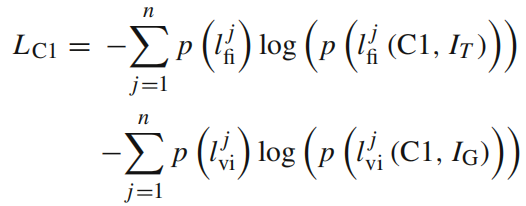

Finally, we implement cross-entropy loss with sigmoid function as loss functions LG, LD1and LD2, and our triple loss Ltriple is a combination of the above four losses: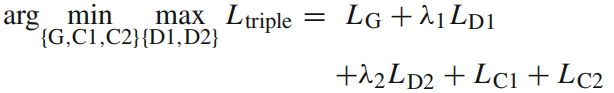
4 Experiments
4.1 Datasets and settings
为了验证FE-GAN在语音面对面生成任务中的性能,我们的实验在两个多模态数据集上运行:RAVDESS [18]和 eNTERFACE [18]。它们被收集在实验室控制的环境中,在那里,说话者被要求阅读具有特定声音情绪和面部表情的给定句子。拉夫迪斯由1440个片段组成,由24个演员表达,有8个情感类别。环境包含1166个片段,由43个说话者表达,有6种情绪类别。表1总结了我们工作中使用的数据集的细节。
我们的模型是在PyTorch中实现的,并在英伟达GeForce RTX 2080ti上进行了训练。V-net和FE-GAN分别进行训练。首先,使用RAVDESS [18]或eNTERFACE [19]数据集,对V-net进行预训练,其中选择了SGD优化器,批处理大小为64,初始学习率为0.03,每100个epoch减少一半。接下来,用Adam优化器进行FE-GAN训练,批处理大小设置为64,学习率为0.0002。此外,三重损失中的超参数λ1和λ2分别为0.7和0.3。
4.2 Evaluation metrics
为了评估生成图像的真实性和变化性,我们选择了初始得分(IS)[46]、弗雷切特初始距离(FID)[47]和分类精度作为定量指标。
- Inception score (IS) [46],
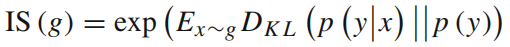
- Fréchet Inception Distance (FID) [47], 评估整个生成图像的质量。FID通过预训练的 Inception-v3 网络计算真实和生成图像在特征空间上的 Wasserstein-2 距离。
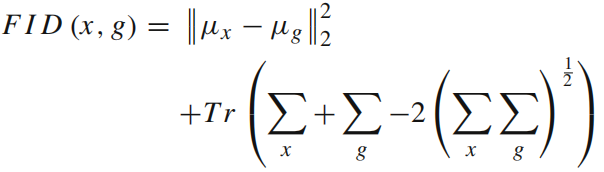
- 身份和情绪的分类准确率,使用 VGG-Face 网络计算。方法是将VGG-Face网络在本文使用的2个数据集上进行预训练,然后对生成的结果进行计算。
4.3 Ablation experiments
4.4 Robustness tests
4.5 Comparison to state-of-the-art
4.6 Limitation of FE-GAN
在我们的实验中,我们发现有一些生成的图像有可见的失败,如图所示。3、4和7。主要的问题包括适度的伪影(例如,面部的纹理和颜色似乎不自然),面部轮廓和细节的丧失(例如,牙齿、头发和眉毛区域是模糊的或缺失的),以及轻微的语义不一致(例如,与GT图像相比)。
造成这些问题的原因主要有两个原因: (1)数据集中情绪的内部和人际差异较大,使得FE-GAN难以有效地学习这些面孔和声音情绪特征。(2)输入嵌入特征仅来自单一模式(语音),而不是多个模式(语音和面部)。也就是说,面部属性的一部分与说话者的声音无关,因此生成器不能在声音和人脸之间建立这些映射。因此,仅使用单一模态特征就无法产生高质量的牙齿、头发、眉毛和头部姿态。
本模型的一些问题:
- moderate artifacts (e.g., the texture and color of face seem unnatural),
- loss of facial contours and details (e.g., tooth, hair and eyebrow region are obscure or missing),
- minor semantic inconsistency (e.g., compared with ground truth images).
主要原因:
- The intra-personal and interpersonal variances of emotion are large in datasets, which make FE-GAN hard to learn these face and voice emotion features effectively.
- The input embedding features are only from the single modality (voice) instead of multiple modalities (voice and face).
5 Conclusion
面部表情在高质量的面部生成中起着重要的作用。人类的感知能力对微妙的面部表情非常敏感。因此,如果不考虑对这张脸和声音的情感,就很难产生塑造者和正确的人脸图像。在本文中,我们提出了一种新的FE-GAN来考虑语音生成问题中的情绪。具体来说,音频情感和身份被用来直接生成带有表情的人脸图像。我们提出了包含一个生成器和两个鉴别器及其辅助分类器。其核心思想是使用辅助分类器来帮助鉴别器更好地识别基于该图像中所表示的身份和情感的人脸图像是生成的还是真实的。因此,可以训练生成器来生成更真实的人脸图像。最后,所提出的三重损失有利于模型的泛化和优化能力。实验结果表明,我们提出的方法在定量和定性方面都优于最先进的方法。
FE-GAN也有它自己的局限性。首先,基于单台发电机的输出存在模型崩溃和过拟合问题。例如,一些面部身份特征和情绪特征相互掩盖,导致图像中出现大量的模糊和像素抖动,而一些情绪样本不足,会影响人脸图像的生成。另一方面,该模型在训练中很难实现两种鉴别器之间的最佳平衡。此外,还应考虑表达式的强度,以进一步提高生成图像的质量。

若有收获,就点个赞吧
0 人点赞
