AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis (ICCV 2021)
Project Page: https://yudongguo.github.io/ADNeRF/
Code: https://github.com/YudongGuo/AD-NeRF
解决问题:输入音频序列拟合生成高保真语音视频。
解决方法:神经场景表示网络(neural scene representation networks)。
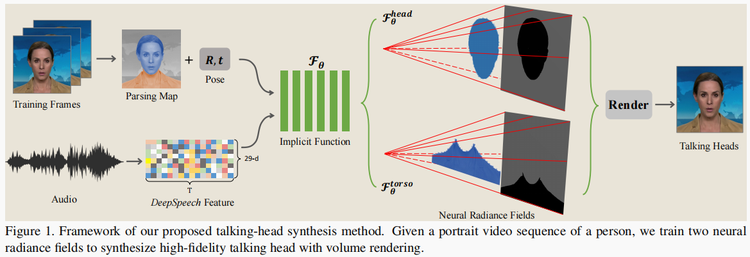
- 我们的方法完全不同于现有的方法,现有方法依赖于中间表示,如二维地标或三维人脸模型,来弥合音频输入和视频输出之间的差距。具体地说,将输入音频信号的特征直接输入条件隐式函数,生成动态神经辐射场,利用音量渲染合成与音频信号对应的高保真说话头视频。
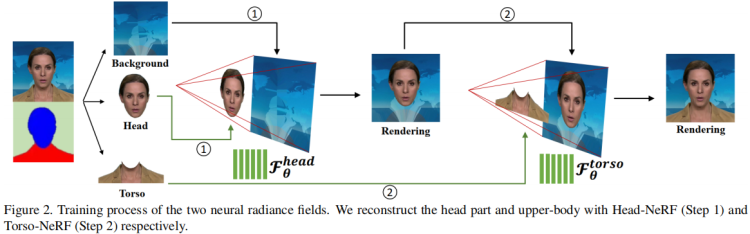
- 我们的框架的另一个优点是,不仅头部(有头发)区域像以前的方法那样被合成,而且头部和上半身是通过两个单独的神经辐射场产生的。
- 实验结果表明,我们的新框架可以(1)产生高保真度和自然的结果,并(2)支持音频信号、观看方向和背景图像的自由调整。
贡献点:
- 我们提出了一种音频驱动的说话头方法,它直接将音频特征映射到动态神经辐射场,用于肖像渲染,而没有任何可能导致信息丢失的中间模式。消融研究表明,这种直接映射能够在短视频的训练数据下产生准确的嘴唇运动结果。
- 我们将人像场景的神经辐射场分解为两个分支,分别建模头部和躯干变形,有助于生成更自然的头部说话的结果。
- 在音频驱动的 NeRF的帮助下,我们的方法实现了语音头部视频编辑,如姿态操纵和背景替换,这对潜在的虚拟现实应用很有价值。
技术要点
- 提取语义音频特征,学习一个条件隐式函数,将音频特征映射到神经辐射场
- 输入: 方向 d、 3D位置 x、 音频 a 的语义特征
- Fθ 通过一个多层感知器(MLP)实现的。对于所有连接的输入向量(a、d、x),网络将估计颜色值 c 以及沿着被发送的光线的密度 σ。
- 隐式函数 Fθ 的表达式:
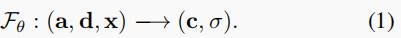
- 利用体积渲染技术从神经辐射场中渲染视觉人脸
- 利用上述隐式模型Fθ预测的颜色 c 和密度 σ,计算图像渲染结果的输出颜色。
- 预期颜色 C 被计算为
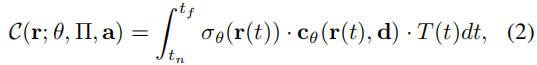
- 相机中心 o、观察方向 d、近界(near bound) tn 和远界(far bound) tf
- cθ(·)和 σθ(·)是上述隐式函数 Fθ 的输出
- T (t)是沿Tn到T的累积透光率:
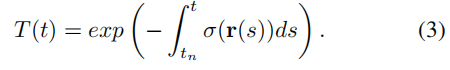
- Π是估计的面的刚性姿态参数,由旋转矩阵R∈R3×3和平移向量t∈R3×1表示。Π用于将采样点转换为规范空间。
- 具体来说,我们首先使用一个粗网络来预测沿着射线的密度,然后在精细网络中的高密度区域采样更多的点。
- 数据处理
- 采用自动解析方法[26]对每一帧分为三个部分:静态背景、头部和躯干;
- 应用多帧光流估计方法[18],在前额、耳朵、头发等近刚性区域的视频帧间的密集对应,然后使用束调整[2]估计姿态参数。注意,估计的姿势只对面部部位有效,不能代表上半身的整个运动;
- 根据所有顺序帧构建一个没有人的干净的背景图像(如图2所示)。
- 这是通过根据解析结果从每一帧中移除人类区域,然后计算所有背景图像的聚合结果来实现的。
- 对于缺失区域,我们使用泊松混合[34]来固定具有邻居信息的像素。
算法优缺点
- 优点
- 背景可编辑替换
- 头部可以调整左右视角,不过可调整的角度不大,且身体是不会一起旋转的

缺点
- 每一个新的人物都得重新训练一次(训练数据得是正方形的头部视频)
原文
3.1. Overview
基于神经渲染的思想,我们通过 neural scene representation 隐式地建模变形的人类头部和上半身,比如 neural radiance fields.
- 每一个新的人物都得重新训练一次(训练数据得是正方形的头部视频)
提取语义音频特征,学习一个条件隐式函数,将音频特征映射到神经辐射场(Sec 3.2)
- 利用体积渲染技术从神经辐射场中渲染视觉面脸(Sec 3.3)
借助自动解析方法[26],对头部和躯干部分进行分割,提取干净的背景。当我们将体积特征转换为一个新的规范空间时,头部和其他身体部位将用它们各自的隐式模型以不同的方式呈现,从而产生非常自然的结果。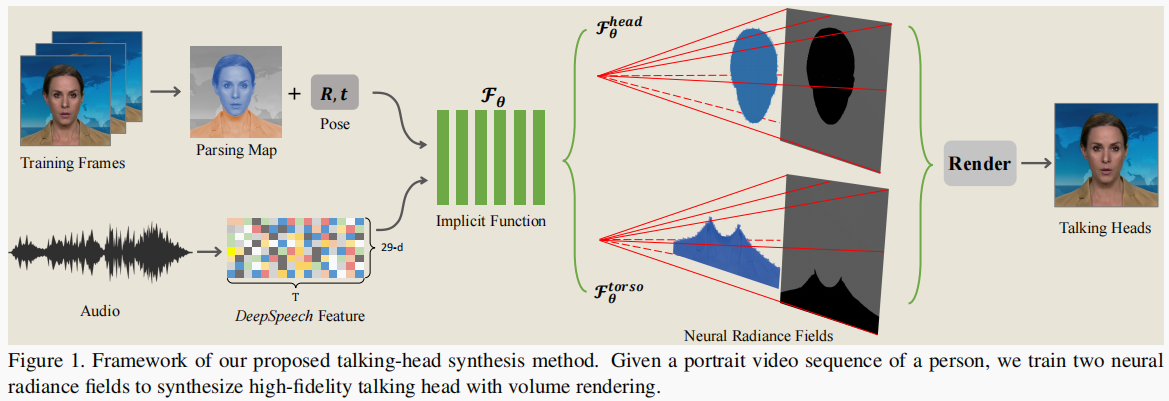
3.2. Neural Radiance Fields for Talking Heads
基于标准的神经辐射场场景表示(Neural Radiance Field scene representation, NeRF)[30],并受Gafni等人[16]介绍的面部动画动态神经辐射场的启发,我们提出了一个条件辐射场的说话头部使用条件隐式函数和一个额外的音频代码作为输入。除了查看 方向 d 和 3D位置x 外,还将添加 音频 a 的语义特征作为 隐式函数 Fθ 的另一个输入。在实践中,Fθ 是通过一个多层感知器(MLP)来实现的。对于所有连接的输入向量(a、d、x),网络将估计颜色值 c 以及沿着被发送的光线的密度 σ。整个隐式函数可以表述如下: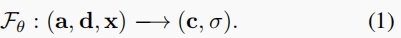
我们使用与NeRF [30]相同的隐式网络结构,包括位置编码。
Semantic Audio Feature
为了从声学信号中提取有语义意义的信息,类似于之前的音频驱动方法[10,43],我们使用流行的 DeepSpeech [1] 模型来预测每个20 ms音频片段的29维特征代码。在我们的实现中,几个连续的音频特征帧被联合发送到一个时间卷积网络中,以消除来自原始输入的噪声信号。具体来说,我们使用来自16个相邻帧的特性 a ∈ _R16×_29 来表示音频模态的当前状态。使用音频特征代替回归表达系数[43]或人脸关键点[49],有利于降低中间翻译网络的训练成本,防止音频和视觉信号之间潜在的语义不匹配问题。
3.3. Volume Rendering with Radiance Fields
利用上述隐式模型Fθ预测的颜色c和密度σ,我们可以利用体渲染过程,通过每个像素的射线累积采样密度和RGB值,计算图像渲染结果的输出颜色。与NeRF [30]一样,一个具有相机中心 o、观察方向 d、近界(near bound) tn 和远界(far bound) tf 的预期颜色 C 被计算为: 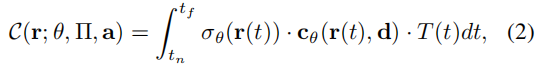
其中,cθ(·)和 σθ(·)是上述隐式函数 Fθ 的输出。
T (t)是沿Tn到T的累积透光率: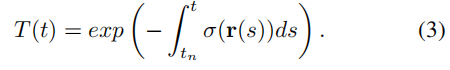
Π是估计的面的刚性姿态参数,由旋转矩阵R∈R3×3和平移向量t∈R3×1表示,即Π = {R,t}。与Gafni等人[16]类似,Π用于将采样点转换为规范空间。请注意,在训练阶段,我们只使用头部姿态信息,而不是任何三维面部形状。我们使用了由Mildenhall等人提出的两阶段集成策略[30]。具体来说,我们首先使用一个粗网络来预测沿着射线的密度,然后在精细网络中的高密度区域采样更多的点。
3.4. Individual NeRFs Representation
在渲染过程中考虑头部姿势的原因是,与静态背景相比,人体的各个部位(包括头部和躯干)正在从一个帧动态地移动到另一个帧。因此,将变形点从摄像机空间转换到规范空间是进行辐射场训练的必要条件。Gafni等[16]试图利用基于自动预测密度 解耦前景和背景的方法来处理动态运动,即,对于通过前景像素的调度光线(dispatched rays),人体部分将以高密度预测,而背景图像将被低密度忽略。然而,将躯干区域转化为规范空间还存在一些歧义。由于头部的运动与躯干的运动不一致,姿态参数 Π 仅估计面部形状,在头部和躯干区域同时应用相同的刚性变换,会导致上半身的渲染结果不令人满意。为了解决这个问题,我们用两个单独的神经辐射场来模拟这两个部分:一个是头部部分,另一个是躯干部分。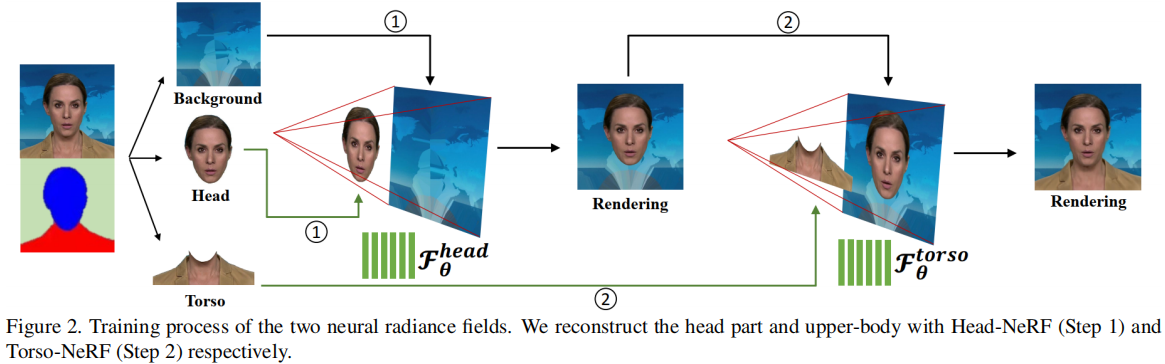
如图2所示,我们首先利用自动人脸解析方法[26]将训练图像分为三个部分:静态背景、头部和躯干。我们首先训练头部的隐式函数Fθhead。在这一步中,我们将 解析映射(parsing map)确定的头部区域 视为前景,其余部分视为背景。头部姿态Π应用于射线穿过的每个像素采样点。假设射线上的最后一个样本位于固定颜色的背景上,即背景图像中与射线对应的像素颜色。然后,我们将Fθhead的渲染图像转换为新的背景,并使躯干部分转换为前景。接下来,我们继续训练第二个隐式模型Fθtorso。在这个阶段,躯干区域没有可用的姿势参数。因此,我们假设所有的点都生活在规范空间中(即,不使用头部姿态Π转换它们),并将面部姿态Π添加为另一个输入条件(结合点位置x、观看方向d 和音频特征a),用于辐射场预测。换句话说,我们隐式地将头部姿态Π作为一个附加的输入,而不是使用Π在Fθ躯干中进行显式转换。
在推理阶段,头部部分模型Fθ头部和躯干部分模型Fθ躯干都接受相同的输入参数,包括音频条件码a和姿态系数Π。体积渲染过程将首先通过头部模型,累积所有像素的采样密度和RGB值。渲染的图像期望覆盖静态背景上的前景头部区域。然后,躯干模型将通过预测躯干区域的前景像素来填充缺失的身体部分。一般来说,这种单独的神经辐射场表示设计有助于模拟不一致的头部和上半身运动,并产生自然的说话头部结果。
3.5. Editing of Talking Head Video
由于神经辐射场都以语义音频特征和姿态系数作为输入来控制语音内容和头部的运动,我们的方法可以通过分别替换音频输入和调整姿态系数来实现音频驱动和姿态操纵的头部视频的生成。此外,类似于Gafni [16],因为我们使用背景图像上相应的像素作为每个射线的最后一个样本,如果射线通过一个背景像素,隐式网络将学习如何预测前景样本的低密度值,以及前景像素的高密度值。通过这种方式,我们的方法解耦了前景-背景区域,并仅通过替换背景图像来实现背景编辑。我们将在 Sec 4.4 中进一步演示了所有这些编辑应用程序。
3.6. Training Details
数据集
对于每个目标人物,我们收集他的一个短视频序列进行训练。平均视频长度为3-5分钟,都是25帧/秒。记录摄像机和背景都被认为是静态的。在测试中,我们的方法允许任意的音频输入,如来自不同身份、性别和语言的语音。
训练数据处理
对训练数据集进行预处理主要有三个步骤:
(1)采用自动解析方法[26]对每一帧的不同语义区域进行标记;
(2)应用多帧光流估计方法[18],在前额、耳朵、头发等近刚性区域的视频帧间的密集对应,然后使用束调整[2]估计姿态参数。值得注意的是,估计的姿势只对面部部位有效,而对颈部、肩部等其他身体部位不有效,即面部姿势不能代表上半身的整个运动;
(3)根据所有顺序帧构建一个没有人的干净的背景图像(如图2所示)。这是通过根据解析结果从每一帧中移除人类区域,然后计算所有背景图像的聚合结果来实现的。对于缺失区域,我们使用泊松混合[34]来固定具有邻居信息的像素。
代码
Train AD-NeRF
Data Preprocess ($id Obama for example)
bash process_data.sh Obama
- Input: A portrait video at 25fps containing voice audio. (dataset/vids/$id.mp4)
- Output: folder dataset/$id that contains all files for training
具体过程分为8步:
0 . 使用 ffmpeg 提取音频,使用 deepspeech 提取音频特征
- 提取每一帧图片
- detect landmarks,检测人脸关键点
- face parsing,利用自动人脸解析方法[26]将训练图像分为三个部分:静态背景、头部和躯干
- extract background image
- save training images
- Estimate Head Pose
- Save Transform Param,保存配置,在网络训练完后的rendering时需要。
注:作者给的Obama视频为 450×450 的肩膀以上头部视频(5m20s),背景、视角几乎没有变动。作者有提到数据得是正方形的视频(https://github.com/YudongGuo/AD-NeRF/issues/81)
Train Two NeRFs (Head-NeRF and Torso-NeRF)
Train Head-NeRF with command
python NeRFs/HeadNeRF/run_nerf.py --config dataset/$id/HeadNeRF_config.txt
Copy latest trainied model from dataset/
id_head to dataset/
id_com
Train Torso-NeRF with command
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/$id/TorsoNeRF_config.txt
You may need the pretrained models to avoid bad initialization. #3
Run AD-NeRF for rendering
Reconstruct original video with audio input
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/$id/TorsoNeRFTest_config.txt --aud_file=dataset/$id/aud.npy --test_size=300
Drive the target person with another audio input
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/$id/TorsoNeRFTest_config.txt --aud_file=${deepspeechfile.npy} --test_size=-1
代码运行时的报错与解决
RuntimeError: Not compiled with GPU support
Traceback (most recent call last):File "data_util/face_tracking/face_tracker.py", line 218, in <module>sel_light.to(device_render))File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_implresult = self.forward(*input, **kwargs)File "/base/code/AD-NeRF/data_util/face_tracking/render_3dmm.py", line 189, in forwardrendered_img = self.renderer(mesh)File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_implresult = self.forward(*input, **kwargs)File "/base/code/AD-NeRF/pytorch3d/pytorch3d/renderer/mesh/renderer.py", line 61, in forwardfragments = self.rasterizer(meshes_world, **kwargs)File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/nn/modules/module.py", line 889, in _call_implresult = self.forward(*input, **kwargs)File "/base/code/AD-NeRF/pytorch3d/pytorch3d/renderer/mesh/rasterizer.py", line 266, in forwardcull_to_frustum=raster_settings.cull_to_frustum,File "/base/code/AD-NeRF/pytorch3d/pytorch3d/renderer/mesh/rasterize_meshes.py", line 236, in rasterize_meshescull_backfaces,File "/base/code/AD-NeRF/pytorch3d/pytorch3d/renderer/mesh/rasterize_meshes.py", line 310, in forwardcull_backfaces,RuntimeError: Not compiled with GPU support
出现在 数据处理 step 6,导致在 step 7 时报错
Traceback (most recent call last):File "data_util/process_data.py", line 193, in <module>params_dict = torch.load(os.path.join(id_dir, 'track_params.pt'))File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/serialization.py", line 579, in loadwith _open_file_like(f, 'rb') as opened_file:File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/serialization.py", line 230, in _open_file_likereturn _open_file(name_or_buffer, mode)File "/base/anaconda3/envs/adnerf/lib/python3.7/site-packages/torch/serialization.py", line 211, in __init__super(_open_file, self).__init__(open(name, mode))FileNotFoundError: [Errno 2] No such file or directory: 'dataset/Obama/track_params.pt'

若有收获,就点个赞吧
0 人点赞
