Yu Deng et al., “Accurate 3D Face Reconstruction With Weakly-Supervised Learning: From Single Image to Image Set,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
论文 https://doi.org/10.1109/CVPRW.2019.00038.
code https://github.com/microsoft/Deep3DFaceReconstruction
- 关键词:弱监督学习
解决什么问题
此前,训练深度神经网络通常需要大量数据,而具有真实3D人脸形状的人脸图像则很少。
本文的目标是利用弱监督学习获得精确的三维人脸重建,其方法快速、准确、对遮挡和 large pose 鲁棒。
- 为弱监督学习提供了一个鲁棒的混合损失函数,它集成了像素级颜色的低级信息和感知损失,考虑到了监督的低层次和感知层次的信息。
- 提出了一种新的基于肤色的光度误差注意策略,通过利用来自不同图像的互补信息进行形状聚合,执行多图像重建,进一步增强了对遮挡和其他外观变化(如胡须和浓妆)的鲁棒性。
贡献点
- 提出了一种基于 CNN 的单图像人脸重建方法,该方法利用混合级图像信息进行弱监督学习。我们的损失包括鲁棒化图像级的损失和感知级的损失。展示了本方法在多个数据集上的最先进的准确性[1,11,56],显著优于以前以完全监督的方式训练的方法[45,14,51]。此外,在低维3DMM子空间中,仍然能够在不受限制的3D表示[45,53,48,14]方面明显优于现有技术。
- 提出了一种新的多图像人脸重建聚合的 shape confidence learning 方案。置信度预测子网也以弱监督的方式进行训练,没有地面真实标签。证明了此方法明显优于单纯的聚合(例如,形状平均)和一些启发式策略[34]。这是首次尝试从一个无约束的图像集进行基于cnn的3D人脸重建和聚合。
预备知识
本文训练了一个现成的深度CNN来预测三维变形模型(3DMM)[5]系数,并在多个数据集上实现精确的重建。训练一个简单的辅助网络生成回归的、带有身份的三维模型系数的“置信度分数”,并通过基于置信度的聚合得到最终的身份系数。
如图1 (a)所示,使用CNN对一个3DMM人脸模型的系数进行回归。在无监督/弱监督训练[49,48]方面,我们回归光照和面部姿势,以实现分析图像重建。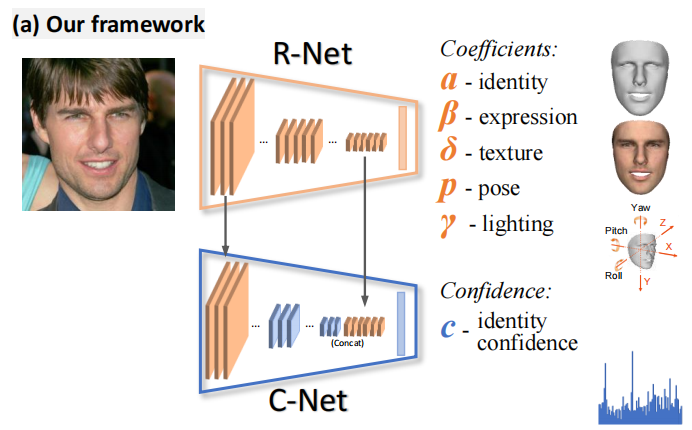
- 3D人脸模型,计算 face shape S 和 texture T
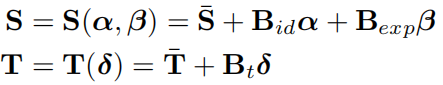
![Deng_2019_Deep3DFaceReconstruction [微软] - 图3](/uploads/projects/xzhao0501@readpapers/89a4a19aede6341dd32919ff6628981b.svg) and
and ![Deng_2019_Deep3DFaceReconstruction [微软] - 图4](/uploads/projects/xzhao0501@readpapers/8cea108da2c5436abb224c127bbc23d5.svg) are the average face shape and texture;
are the average face shape and texture; - Bid, Bexp, and Bt are the PCA bases of identity, expression, and texture respectively. Bexp 通过 FaceWarehouse [11] 获得,
![Deng_2019_Deep3DFaceReconstruction [微软] - 图5](/uploads/projects/xzhao0501@readpapers/4379d31be991512629e5a7eec3f1196a.svg) ,
, ![Deng_2019_Deep3DFaceReconstruction [微软] - 图6](/uploads/projects/xzhao0501@readpapers/8ce89a77978cc66e102df87316171af0.svg) , Bid, and Bt 通过2009 Basel Face Model [33] 获得。
, Bid, and Bt 通过2009 Basel Face Model [33] 获得。 - α、β、δ为生成三维人脸对应的系数向量,未知。
- 光照模型,计算辐射度 radiosity C
- 假设人脸是一个朗伯表面(Lambertian surface),用球面谐波(Spherical Harmonics, SH)[35,36]近似场景照明。
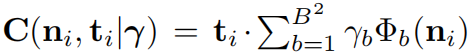
- Φ**b** : R3 → R are SH basis functions 球面谐波基函数
- γ**b** ∈ R9 are the corresponding SH coefficients.
- choose B=3 bands following [49, 48]
- 相机模型,偏移量和旋转。
- We use the perspective camera model with an empirically-selected focal length for the 3D-2D projection geometry.
- The 3D face pose p is represented by rotation R ∈ SO(3) and translation t ∈ R3.
综上,要预测的未知数可以用向量 x = (α, β, δ, γ, p)∈ R**239 ** 表示。(各参数大小分别是80,64,80,9,6)
【注】
刚体在空间中的表示有6个自由度,x, y, z 偏移量以及绕这3个轴的角度,旋转有4种表示方式:
- Eular Angles 欧拉角缺点在于绕一个轴旋转90°后再转一个角,会丢失一个轴的自由度(万向锁)。
- Rotation matrix 旋转矩阵,用9个参数表示3个旋转量。
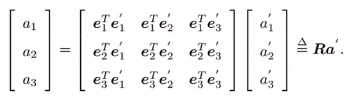
- Quaternions 四元数,加了个虚轴代表旋转值。
Lie algebra 李代数,把乘法转换成加法(矩阵取log)。
具体方法
Hybrid-level Weak-supervision for Single Image Reconstruction
本文使用ResNet-50网络[22],将最后一层全连接层修改为239个神经元来回归这些系数。这个用于单个图像重建的改进ResNet-50网络简称为R-Net,用来回归系数向量 x。
R-Net,单图像三维重建的重建网络,没有任何地面真实标签,通过评估重建图像 I’ 的混合级损失并反向传播它进行训练。它只利用一些薄弱的监督信号,如面部 landmark,皮肤 mask 和预先训练的人脸识别CNN。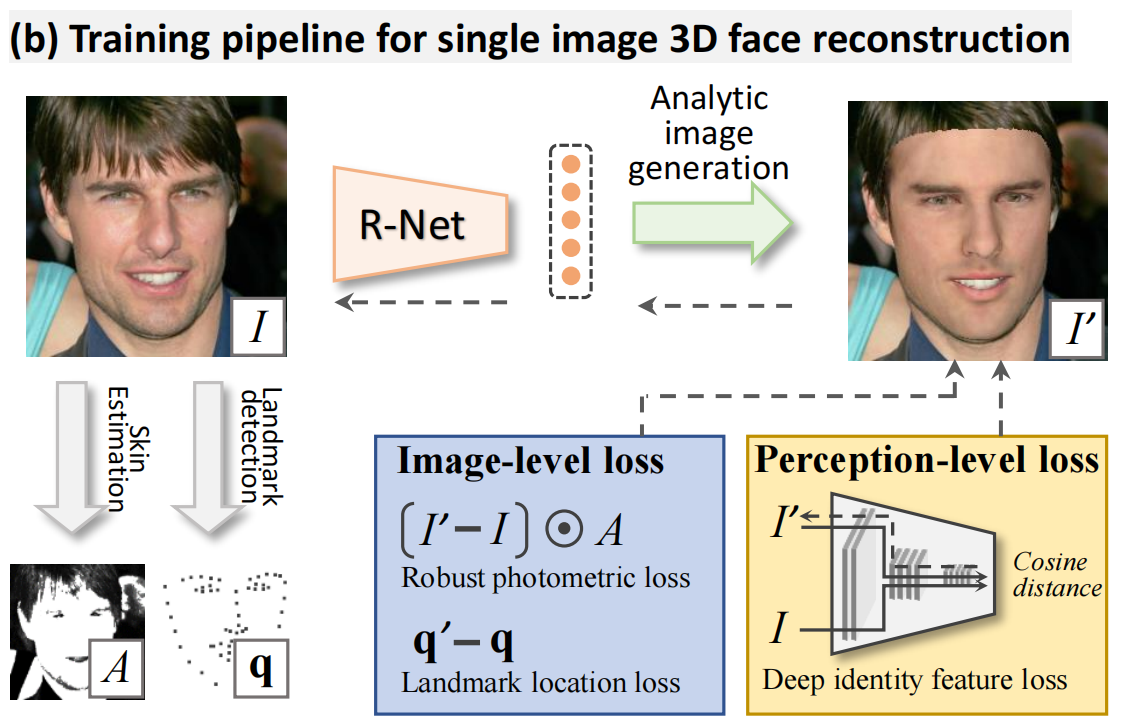
Image-Level Losses,介绍对于低级信息的损失函数,包括像素颜色和稀疏的 2D landmarks。
- Robust Photometric Loss 皮肤颜色损失
首先,原始图像和重建图像之间的密度光度差异可以直接测量[5,50,49,48]。在本文中,我们提出了一个鲁棒的,皮肤敏感的光度损失: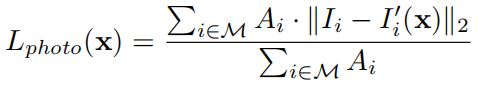
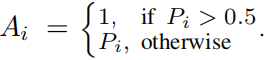
where i denotes pixel index, M is reprojected face region which can be readily obtained, and A is a skin color based attention mask for the training image which is described as follows.
Skin Attention. 为了获得对遮挡和其他具有挑战性的外观变化(如胡须和浓妆)的鲁棒性,我们为每个像素计算 skin-color probabilityPi。在皮肤图像数据集[26]上用高斯混合模型训练一个朴素贝叶斯分类器。图2说明了使用这个 skin attention mask 的好处。
- Landmark Loss 关键点损失
使用3D人脸对齐方法[8],检测68个关键点{qn}。训练期间,将 3D landmark vertices of our reconstructed shape 投影到图像上得到{q’n}的,计算损失为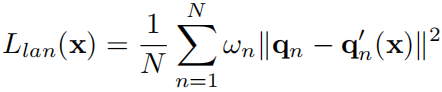
where ωn is the landmark weight which we experimentally set to 20 for inner mouth and nose points and others to 1.
- Perception-Level Loss 深层特征的损失
使用低级信息来测量图像差异会导致基于CNN的3D人脸重建出现局部最小问题。我们使用 Perception-Level Loss 来解决这个问题。具体来说,我们使用一个内部人脸识别数据集训练 FaceNet [44] 作为深度特征提取器,来提取图像的深度特征,然后计算余弦距离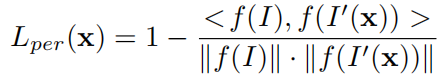
从图3可以看出,随着感知损失的增加,纹理更加清晰,形状更加逼真。
- Regularization 正则化损失
- 防止人脸形状和纹理的退化,在3DMM参数上添加了一个常用的loss
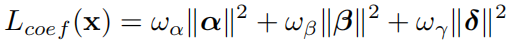
强制向平均人脸靠拢。根据经验,ωα = 1.0, ωβ = 0.8, ωγ = 1.7e−3。
- To favor a constant skin albedo,对纹理变化很大的地方进行方差惩罚(we add a flattening constrain to penalize the texture map variance):
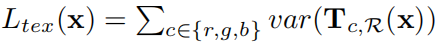
where R is a pre-defined skin region covering cheek, noise, and forehead.
综上,R-Net损失函数L(x)由两个图像级损失、一个感知损失和两个正则化损失组成。
Weakly-supervised Neural Aggregation for Multi-Image Reconstruction
给定一个对象的多张面部图像可以构建更好的3D脸型,因为不同条件下拍摄的图像,由于姿态、光线等的变化,会包含相互补充的信息,可以使遮挡和不良光照的图像重建更具鲁棒性。
C-Net,以一种没有标签的弱监督方式来学习向量 c ∈ R80 (confidence),即单张图像重建结果的置信度,并使用它来聚合(aggregate)人物的shapes。计算方法如下。
Let I := {Ij |j = 1, . . . , M} be an image collection of a person, xj = (αj, βj, δj, pj, γj) the output coefficient vector from R-Net for each image j, and cjthe confidence vector for each αj , we obtain the final shape via element-wise shape coefficient aggregation: 
![Deng_2019_Deep3DFaceReconstruction [微软] - 图19](/uploads/projects/xzhao0501@readpapers/d69e40894eb85164976a4edc6fd9d213.svg) 和
和![Deng_2019_Deep3DFaceReconstruction [微软] - 图20](/uploads/projects/xzhao0501@readpapers/a89877447f7d2e68f56b55b57da6e63a.svg) 分别表示Hadamard product 和 Hadamard division(逐元素乘/除)。这里只考虑 the identity-bearing shape coefficients
分别表示Hadamard product 和 Hadamard division(逐元素乘/除)。这里只考虑 the identity-bearing shape coefficients α 的置信度向量c,而不考虑其他系数,如表情、姿势和照明,因为它们在不同的图像和融合是不必要的。也不考虑纹理,因为在野外的图像中受试者的皮肤颜色可以有很大的变化。
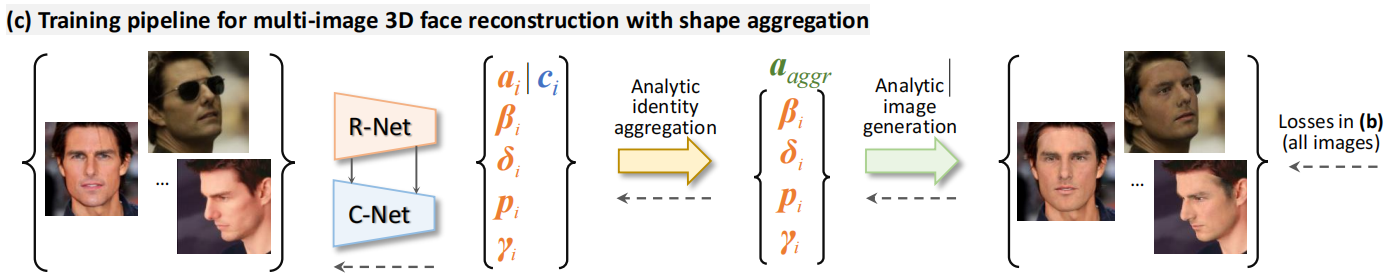
图中虚线箭头表示网络训练的误差反向传播。
- Label-Free Training
To train C-Net on image sets, we generate the reconstructed image set {Ij'} of {Ij} with![Deng_2019_Deep3DFaceReconstruction [微软] - 图22](/uploads/projects/xzhao0501@readpapers/791499b5226483d1aeee8f6d16041e34.svg) , where
, where ![Deng_2019_Deep3DFaceReconstruction [微软] - 图23](/uploads/projects/xzhao0501@readpapers/1372f6364ceccaa8e702d623bb9999a0.svg)
= (αaggr, βj, δj, pj, γj). We define the training loss as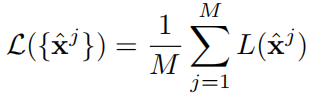
where L(·) is our hybrid-level loss function defined in Section 4 evaluated with {Ij'} of {Ij}.
- Confidence-Net Structure
我们从R-Net中同时提取了浅层和深层特征,如图1 (a)所示。浅层特征可以用来测量图像的破坏,如遮挡。由于R-Net能够预测姿势和光线等高级信息,因此很自然地可以将其特征地图用于C-Net。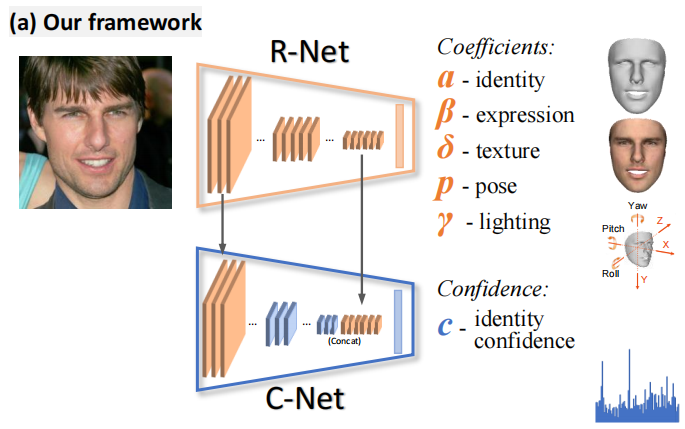
C-Net 直接把 R-Net 浅层和深层的特征图直接抄了过来(we take the features after the first residual block Fb1 ∈R2828256 and after global pooling Fg ∈R2048 of R-Net as the input to C-Net )。
浅层的做一个pooling,使得和深层的特征大小一致,然后将二者concat,过一个2层的FC和一个sigmoid,输出80维的置信度c。
实验
训练 R-Net 使用的数据集:we collected in-the-wild images from multiple sources such as
- CelebA [32]
- CelebFaces Attribute的缩写,名人人脸属性数据集,包含10,177个名人身份的202,599张人脸图片,每张图片都做好了特征标记,包含人脸bbox标注框、5个人脸特征点坐标以及40个属性标记,由香港中文大学开放提供。
- Large-scale CelebFaces Attributes (CelebA) Dataset
- 300W-LP [57]
- 在300W的基础上扩展而来,将多个具有68个关键点的对齐数据库标准化,包括AFW、LFPW、HELEN、IBUG和XM2VTS。与300W相比,300W-LP采用了建议的脸部特征分析,产生了61,225个大姿势的样本(1,786个来自IBUG,5,207个来自AFW,16,556个来自LFPW,37,676个来自HELEN,XM2VTS没有被使用)。
- www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm
- I-JBA [30]
- LFW [24]
- 人脸照片数据库,旨在研究无约束的人脸识别问题。该数据集包含从网络收集的超过 13,000 张人脸图像。每张脸都标有图中人物的名字。照片中的 1680 人在数据集中有两张或更多张不同的照片。
- http://vis-www.cs.umass.edu/lfw/
- LS3D [8]
- 大规模人脸对齐标注数据集,由诺丁汉大学计算机视觉实验室创建。人脸图像来自AFLW, 300VW, 300W和FDDB,人脸对齐采用68点标注法,一共包含了大约 230,000 人脸精准标记图像。
- https://www.adrianbulat.com/face-alignment
We balanced the pose and race distributions and get 260K face images as our training set.
训练 C-Net 使用的数据集:we construct an image corpus using
- 300W-LP [57], Multi-PIE [17]
- choose 5 images with rotation angles evenly distributed for each person.
- and part of our in-house face recognition dataset.
- randomly select 5 images for each person.
The whole training set contains 50K images of 10K identities.
单张图片的消融实验
是在2个数据集上进行的验证
- MIGC Florence 3D face[1], 53 subjects. A ground truth scan in neural expression + video sequences.
- 数据集包括来自许多试验者的人脸的高分辨率 3D 扫描,以及每个试验者几个不同分辨率、条件和缩放等级的视频序列。
- https://www.micc.unifi.it/resources/datasets/florence-3d-faces/
- Face Warehouse[11], we use 9 subjects each with 20 expressions for evaluation.
- 3D 面部表情数据库。使用 Kinect RGBD 相机拍摄了 150 名来自不同种族背景的 7-80 岁个体。对于每个人,捕获了19种不同表情的RGBD数据,且每条RGBD数据自动生成一组彩色图像上的面部特征点,如眼角、嘴巴轮廓和鼻尖。
- http://kunzhou.net/zjugaps/facewarehouse/
表1给出了不同损失组合下的重构误差。结果表明,图像信息和感知信息的联合使用比单独使用具有更高的准确率。
Comparison on MICC Florence
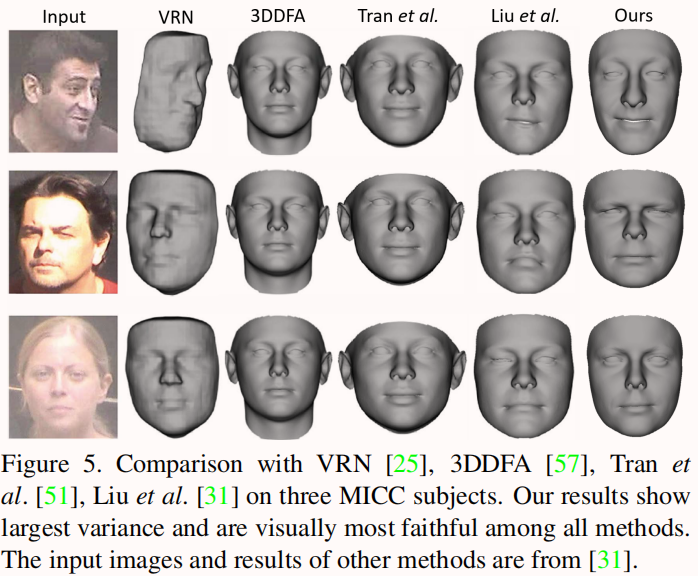
然后与PRN[14]进行比较,PRN[14]是一种最新的CNN方法,带有监督学习,可以预测不受限制的脸型。我们的模型在大姿态的稳定性比PRN好,且模型大小更小。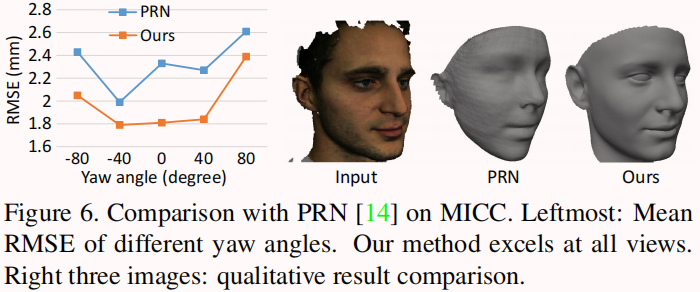
Comparison on Facewarehouse and Comparison with other methods


多张图片的消融实验
我们进一步分析了置信度数值的统计数据,看看他们是否会受到面部姿势的影响。我们分别计算了侧面和正面图像的平均相对置信度得分。
如图11(左)所示,对于侧面人脸,置信度一般较低,但在某些维度上较高。
图11(右)进一步表明,对人脸深度(z轴方向)影响较大的系数项,侧面人脸上的置信度比在正面人脸上的置信度更大。
这与我们的直觉是一致的,并表明通过 element-wise 置信度,网络可以利用视图差异进行更好的重建。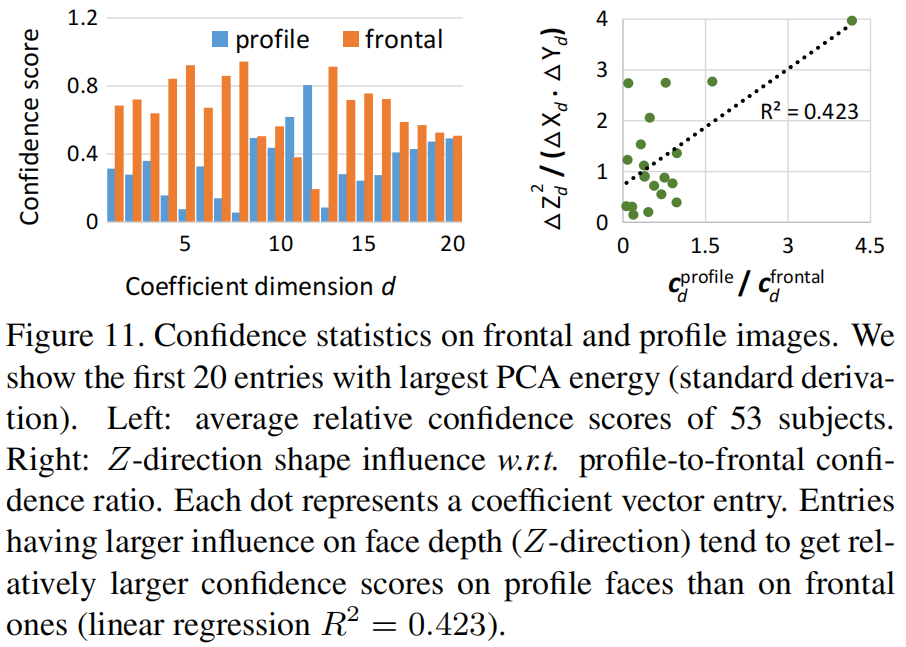
与直觉相同的,正脸、无遮挡、自然光条件下的置信度更高。像太阳镜、帽子和头发这类的遮挡会降低置信度。
读后
- 确认细节:给一个人的多视角图片进行3D重建,是怎么综合这些图片进行重建的。
在训练过程中,综合多视角人脸的3DMM系数,聚合成最终的人脸形状。
- 整个结构中包含2个网络,训练单张图片重建使用R-Net,训练多张图片用R-Net+C-Net。
- R-Net 即 ResNet-50,最后一层全连接层的神经元个数改为239个,其中80个是形状系数,80个颜色系数,64个表情系数,还有9个球面谐波系数,6个3D人脸姿态系数,可以用来重建出3D人脸模型。
- C-net 学习单张图片重建结果的置信度,损失函数是 每张图片重建结果的置信度之和 与 形状系数 做运算。具体来说,对于单个人物的图像集 I := {Ij |j = 1, . . . , M} ,每个图像 j有2个参数,形状系数 αj 从R-Net 得到, cj表示 αj 的置信度,最终这个人的人脸形状通过他所有图片的形状系数聚合而成: 和分别表示Hadamard product 和 Hadamard division(逐元素乘/除)。
- 虽然是弱监督学习,没有给明确的标签,但 C-Net 自动学到给正面、无遮挡的人脸更高的置信度分数。
- 同一个人,用上面这个模型分别进行单张图片重建和多视角图片重建,对比重建结果。
在代码中没有找到同一人多角度图片综合重建的部分。论文标题是从单张图片进行3D人脸重建,可能只在网络训练时使用了多图重建来提升效果,最后只需要单张图就可以有比较好的重建结果。

若有收获,就点个赞吧
0 人点赞
