Prajwal_2020_A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
代码 https://github.com/Rudrabha/Wav2Lip
Project Page http://cvit.iiit.ac.in/research/projects/cvit-projects/a-lip-sync-expert-is-all-you-need-for-speech-to-lip-generation-in-the-wild/
Pipeline
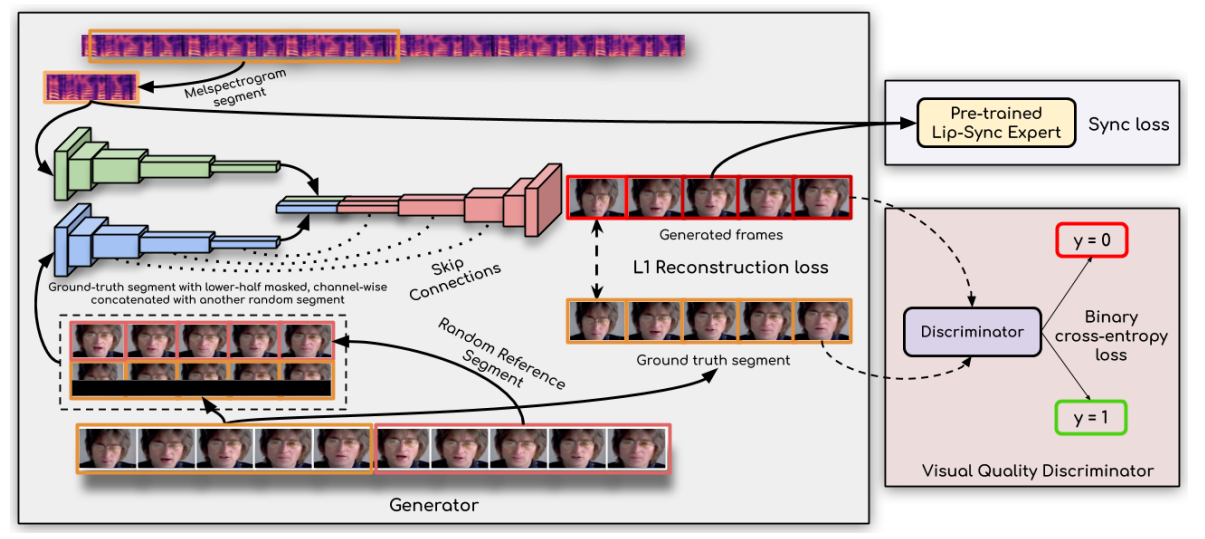
主要通过一种对抗性的方式来训练模型,模型中包含2个网络。一个生成器G,通过条件反射音频输入生成脸,另一个鉴别器D,测试生成的脸和输入音频是否同步。
1. 口型专家鉴别器
基于 SyncNet 做了一点改动。简单介绍 SyncNet:
SyncNet [9]输入连续人脸帧窗口(仅下半部分)和同时长的语音段S。它通过随机采样一个与视频对齐的音频窗口(不同步)或从一个不同的时间步长(不同步)来训练来区分音频和视频之间的同步。它包含一个人脸编码器和一个音频编码器,两者都由一堆二维卷积组成。计算这2个编码器生成的嵌入之间的L2距离,并使用最大边际损失训练模型,以最小化(或最大化)同步(或未同步)对之间的距离。
本文做的改动:
- 我们不像原始模型那样提供按通道连接的灰度图像,而是提供彩色图像。
- 我们的模型明显更深,添加剩余跳跃连接[15]。
- 受这个公共实现的启发,我们使用了一个不同的损失函数:余弦相似性和二值交叉熵损失(原模型使用L2距离)。也就是说,我们计算relu激活的视频和语音嵌入v之间的点积,得到每个样本的[0,1]之间的一个值,表示输入的音频-视频对同步的概率。
训练完成后保存的专家鉴别器模型,在wav2lip的口型生成器训练期间保持冻结。这种纯粹基于从真实视频中学习到的口型同步概念的强烈歧视,迫使生成器也实现现实的口型同步,以最小化口型同步损失。
2. 口型生成器
生成器与作者前一个工作 LipGAN 中的生成器相同,而 LipGAN 是在论文 (You said that?)的基础上进行了修改, 包含3个分支:Face Encoder, Audio Encoder, 还有Face Decoder。
生成器的输入是随机的连续5帧、地面真实的连续5帧(mask掉下半张脸避免正确口型的泄露)以及地面真实帧对应的音频。连续5帧,与前面专家鉴别器的输入窗口大小一致。
在输入时增加地面真实的图片,使得推理过程中模型不需要改变姿态,从而显著地减少了伪影。
- Face Encoder:由带有中间下采样的残差模块组成。输入是随机5帧和 masked 真实5帧的channel concatenate,即 H∗H∗6大小的image。输出的 face embedding 大小为h。
- Audio Encoder:由2D卷积层组成,输入是 MxTx1 的 MFCC heatmap,输出的 audio embedding 大小为 h。
- Face Decoder: 由一系列带有中间反卷积的残差块组成,对特征图进行了上采样。输出层是sigmoid激活的1∗1带有3个filter的卷积,所以输出是H∗H∗3。在每个上采样操作后使用跳连接, 总共使用了6个。输入是face embedding 和 audio embedding的连接,大小为 2*h。输出是对于每一帧使用恰当的嘴型补全蒙版区域,生成音频口型同步的5个连续帧。
论文中没有对生成器进行详细介绍,部分细节来自LipGAN。wav2lip 生成器的来源
训练生成器,使生成帧Lg和真实帧LG之间的 L1 重建损失最小化: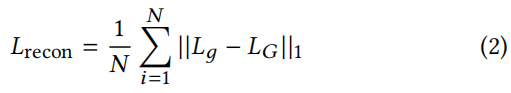
同时最小化来自专家鉴别器的“专家同步损失”Esync: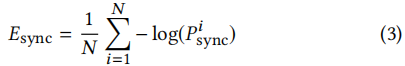
3. 视觉质量鉴别器
通过口型专家鉴别器,能学到基本同步的口型,但变形的区域有模糊和伪影的现象。为了减轻这种质量损失, 于是与生成器共同训练了一个视觉质量鉴别器。鉴别器 D 由一堆卷积块组成。每个块由一个卷积层和紧随其后的 ReLU 激活层组成。
训练鉴别器使目标函数Ldisc最大化: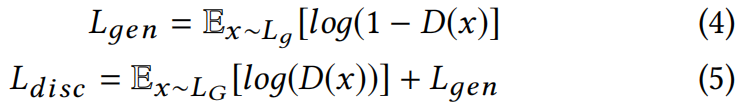
训练
综上,生成器要最小化的损失函数公式总体如下,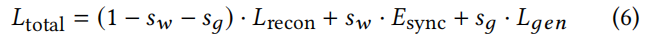
其中,sw是同步惩罚权重,sg是对抗损失权重,根据经验设置为0.03和0.07。
我们在LRS2训练集上训练模型,其批处理大小为80。我们使用Adam优化器[12],生成器和视觉质量鉴别器D的初始学习速率为1e−4,β1=0.5,β2=0.999。注意,口型同步鉴别器没有进一步微调,所以它的权重被冻结。
原文
3 ACCURATE SPEECH-DRIVEN LIP-SYNCING FOR VIDEOS IN THE WILD
我们的核心架构可以总结为“通过从一个训练有素的对口型专家那里学习来生成准确的对口型”。为了理解这种设计选择,我们首先确定了现有架构(第2.2节)在野外视频中产生不准确的对口型的两个关键原因。我们认为,损失的函数,即现有工作[17,18]中使用的 L1重建损失 和LipGAN [18]中使用的 鉴别器损失 都不足以惩罚不准确的唇同步生成。
3.1 Pixel-level Reconstruction loss is a Weak Judge of Lip-sync
计算整个图像的人脸重建损失,以确保正确的姿态生成,保留身份,甚至在人脸周围的背景。唇部区域对应的区域不到总重建损失的4%(基于空间范围),因此在网络开始进行细粒度嘴唇形状校正之前,首先对周围的大量图像重建进行优化。通过训练过程(≈20时代[18]),该网络只在中途(≈第11时代)开始改变嘴唇,这进一步支持了这一点。因此,有一个额外的鉴别器来判断对口型是至关重要的,就像在LipGAN [18]中所做的那样。但是,在LipGAN中使用的鉴别器有多强大呢?
3.2 A Weak Lip-sync Discriminator
我们发现,在LRS2测试集上检测非同步时,LipGAN的唇同步唇对的准确率仅为56%左右。为了进行比较,我们将在这项工作中使用的专家鉴别器在同一测试集上的准确率为91%。我们假设了造成这种差异的两个主要原因。首先,LipGAN的鉴别器使用单帧来检查对口型。在表3中,我们展示了一个小的时间上下文在检测唇型同步时是非常有用的。其次,在训练过程中生成的图像由于大尺度和姿态变化而包含大量的伪影。我们认为,在GAN设置中训练鉴别器对这些有噪声生成的图像,就像在LipGAN中所做的那样,导致鉴别器关注视觉伪影,而不是音频-唇对应。这导致了不同步检测精度的大幅下降(表3)。我们论证并表明,从实际的视频帧中捕获的“真实的”、准确的假唱概念可以用来准确地区分和加强生成的图像中的假唱。
3.3 A Lip-sync Expert Is All You Need
基于上述两个发现,我们建议使用一个预先训练好的专家对口型鉴别器,以准确地检测真实视频中的同步。此外,它不应该像在LipGAN中那样对生成的帧进行进一步的微调。SyncNet [9]模型就是一个用于纠正对口型错误的网络就是SyncNet[1,3]。我们建议对一个修改版本的调整和训练SyncNet [9]为我们的任务。
3.3.1 SyncNet概述。SyncNet [9]输入连续人脸帧窗口(仅下半部分)和一个大小为Ta×D的语音段S,其中Tv和Ta分别是视频和音频时间步。它通过随机采样一个与视频对齐的音频窗口(不同步)或从一个不同的时间步长(不同步)来训练来区分音频和视频之间的同步。它包含一个面编码器和一个音频编码器,两者都由一堆二维卷积组成。计算由这些编码器生成的嵌入之间的L2距离,并使用最大边际损失训练模型,以最小化(或最大化)同步(或未同步)对之间的距离。
3.3.2. 我们的专家口型鉴别器。我们对SyncNet [9]进行了以下更改,以训练一个适合我们的唇生成任务的专家唇同步识别器。首先,我们不像原始模型那样提供按通道连接的灰度图像,而是提供彩色图像。其次,我们的模型明显更深,添加剩余跳跃连接[15]。第三,受这个公共实现的启发,我们使用了一个不同的损失函数:余弦相似性和二值交叉熵损失。也就是说,我们计算relu激活的视频和语音嵌入v之间的点积,得到每个样本的[0,1]之间的一个值,表示输入的音频-视频对同步的概率: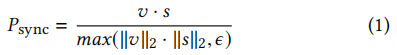
我们在 LRS2 训练集(≈29小时)上训练我们的专家的对口型鉴别器,批量大小为64,使用Adam优化器[12],初始学习速率为1e−3。我们的专家唇同步鉴别器在LRS2测试集上的准确率约为91%,而在LipGAN中使用的鉴别器在同一测试集上的准确率仅为56%。
3.4 Generating Accurate Lip-sync by learning from a Lip-sync Expert
现在我们有了一个精确的对口型鉴别器,我们现在可以使用它来惩罚生成器(图2),因为它在训练期间进行了不准确的生成。我们从描述生成器架构开始。
3.4.1 生成器架构细节。我们使用了与 LipGAN [18]所使用的类似的生成器架构。我们的关键贡献在于用专家鉴别器来训练它。生成器 G 包含三个块:(i)身份编码器,(ii)语音编码器,和(iii)面解码器。身份编码器是一堆残差卷积层,编码一个随机参考系R,与沿通道轴的姿态先验P(下半部分掩蔽的目标面)连接。语音编码器也是一个二维卷积的堆栈,用于对输入的语音段S进行编码,然后与人脸表示相连接。解码器也是一堆卷积层,以及用于上采样的转置卷积。生成器被训练以最小化生成的帧Lд和地面真实帧LG之间的L1重建损失: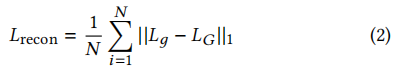
因此,该生成器类似于之前的工作,一个独立生成每一帧的2D-CNN编码-解码器网络。那么我们如何使用预先训练过的专家对口型鉴别器,它需要一个5帧的时间窗口作为输入呢?
3.4.2 惩罚不准确的嘴唇生成。在训练过程中,由于在第3.3节中训练的专家鉴别器一次处理Tv = 5个连续的帧,我们还需要生成器G来生成所有的Tv = 5个帧。我们为参考系采样一个随机连续窗口,以确保尽可能多的姿态时间一致性等。当我们的生成器独立地处理每一帧时,我们沿着批的维度叠加时间步长,同时输入参考帧,得到(N·Tv、H、W、3)的输入形状,其中N、H、W分别为批的大小、高度和宽度。当将生成的帧提供给专家鉴别器时,时间步长沿着通道维数连接起来,就像在训练鉴别器时所做的那样。向专家识别器得到的输入形状为(N、H/2、W、3·Tv),其中只将生成的人脸的下半部分用于识别。生成器还被训练以最小化来自专家鉴别器的“专家同步损失”Esync: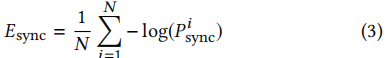
其中,Pi同步是根据公式1计算。请注意,在生成器的训练期间,专家鉴别器的权值将保持冻结。这种纯粹基于从真实视频中学习到的对口型概念的强烈辨别能力迫使生成器也能实现真实的对口型,以最小化对口型损失Esync。
3.5 Generating Photo-realistic Faces
在我们的实验中,我们观察到使用一个强唇型鉴别器迫使发生器产生精确的嘴唇形状。然而,它有时会导致变形的区域稍微模糊或包含轻微的伪影。为了减轻这种质量上的微小损失,我们在GAN设置中训练了一个简单的视觉质量鉴别器。因此,我们有两个鉴别器,一个用于同步精度,另一个用于更好的视觉质量。由于3.2中解释的原因,假型鉴别器没有在GAN设置中进行训练。另一方面,由于视觉质量鉴别器不对唇同步进行任何检查,只惩罚不现实的人脸生成,所以它是在生成的人脸上进行训练的。
鉴别器D由一堆卷积块组成。每个块由一个卷积层和一个泄漏的ReLU激活[20]组成。训练鉴别器以最大化目标函数Ldisc(公式5):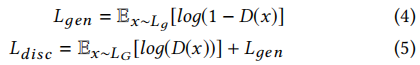
其中,Lд对应生成器G的图像,LG对应真实图像。
生成器使方程6最小,它是重建损失(方程2)、同步损失(方程3)和对抗损失Lдen(方程4)的加权和: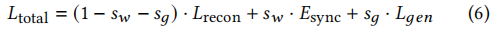
其中,sw是同步惩罚权值,sg是对抗性损失,在我们所有的实验中,经验上分别设置为0.03和0.07。因此,我们的完整的网络是优化为优越的同步精度和质量使用两个不相交的鉴别器。
我们只在LRS2训练集[1]上训练我们的模型,其批处理大小为80。我们使用Adam优化器[12],初始学习速率为1e−4和 betas β1=0.5,β2=0.999的生成器和视觉质量鉴别器d。注意,唇同步鉴别器没有进一步微调,所以它的权重被冻结。我们通过解释在真实视频的推理中是如何工作的来总结我们提出的架构的描述。与LipGAN [18]类似,该模型逐帧生成一个可通话的人脸视频。每个时间步长的视觉输入是当前的面部作物(从源帧),与相同的当前面部作物连接,下半部分掩蔽用作姿态优先。因此,在推理过程中,模型不需要改变姿态,从而显著地减少了伪影。相应的音频段也作为语音子网络的输入,网络生成输入面裁剪,但嘴区域变形。
评估指标
4.1.4 当前的指标并不是特定于对口型的。现有的指标,如SSIM [27]和PSNR,是为了评估整体图像质量,而不是细粒度的唇同步错误。虽然 LMD [4]关注于嘴唇区域,但我们发现嘴唇标记在生成的脸上可能相当不准确。因此,需要一个专门为测量口型误差而设计的度量标准。
4.2.1 测量唇同步错误的度量标准。我们建议使用预先训练的SyncNet [9] 来测量生成的帧和随机选择的语音段之间的对口型误差。SyncNet在一个视频剪辑上的平均准确率超过99%的[9]。因此,我们相信这可以是一个很好的自动评估方法,明确地测试准确的无约束视频。请注意,这不是我们上面训练过的专家对口型鉴别器,而是Chung和齐瑟曼[9]发布的鉴别器,它是在一个不同的非公开数据集上训练的。使用SyncNet解决了现有评估框架的主要问题。我们不再需要采样随机的、时间上不相干的帧,而SyncNet在评估唇同步时也考虑了短期的时间一致性。因此,我们提出了通过使用SyncNet模型自动确定的两个新指标。第一个是根据嘴唇和音频表示之间的距离计算出的平均误差度量,我们将其代号为“LSE-D”(嘴唇同步误差-距离)。较低的ᾯ表示较高的视听匹配,即语音和嘴唇的运动是同步的。第二个指标是平均置信度得分,我们将其代号为“LSE-C”(嘴唇同步错误-置信度)。置信度越高,视听相关性越好。较低的置信度得分表示视频中有几个部分的嘴唇运动完全不同步。更多的细节可以在SyncNet的论文[9]中找到。
4.2.2 评估野外唇同步的一致基准。现在我们有了一个自动的、可靠的度量,可以计算任何视频和音频对,我们可以在每个时间步长采样随机语音样本,而不是随机帧。因此,我们可以创建一个视频对的列表和一个伪随机选择的音频作为一个一致的测试集。我们创建了三个一致的基准测试集,每个测试集分别使用LRS2 [1]、LRW [8]和LRS3 [3]的测试集视频。 对于每个视频Vs,我们从另一个随机采样的视频Vt中获取音频,条件是语音Vt的长度小于Vs。我们使用LRS2创建14K的音频-视频对。使用LRW测试集,我们创建了28K对,这个集合测量了在额/近额视频[2]上的表现。我们还使用LRS3测试集创建了14K对,这也将是轮廓视图中对口型的基准。完整的评估工具包将公开发布,以对野外对口型视频进行一致和可靠的基准测试。
此外,为了测量生成的人脸的质量,我们还报告了FrAlchet起始距离(FrÃľchet Inception Distance, FID)。
主观评估:14个评估者,判断不同的同步视频,基于以下参数: (a)同步精度(b)视觉质量(评估视觉伪影的程度),(c)整体经验(评估视听内容的整体体验),和(d)偏好,观众选择视频的版本是最吸引人的观看。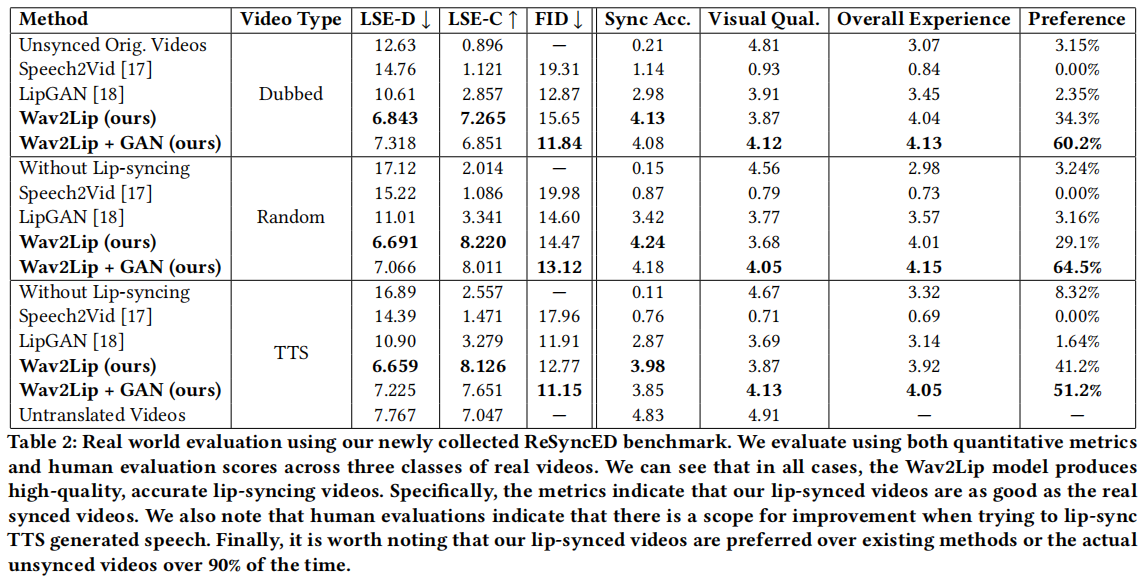

若有收获,就点个赞吧
0 人点赞
