Weiguang Zhao et al., “From 2D Images to 3D Model:Weakly Supervised Multi-View Face Reconstruction with Deep Fusion” (arXiv, April 8, 2022), http://arxiv.org/abs/2204.03842.
MVR, Multi-view 3D Face Reconstruction
目前的MVR方法只是简单地连接了多视图的图像特征,而对关键区域(如眼睛、眉毛、鼻子和嘴)的关注较少。为此,我们提出了一种新的 Deep Fusion MVR(DF-MVR) 模型,设计了一种具有跳过连接的单解码编码框架,能够从多视图图像中提取、集成和补偿深度特征。此外,我们开发了一个 multi-view face parse network 来学习、识别和强调关键的共同人脸区域。最后,虽然我们的模型是用少量二维图像进行训练的,但即使输入一个二维图像,它也可以重建一个精确的三维模型。我们提出的模型获得了优越的性能,RMSE指标比现有的最佳弱监督MVRs提高了11.4%。
Introduction
近年来,利用卷积神经网络(CNN)提取二维图像信息来预测3DMM系数已成为人脸重建的主流方法。
弱监督和自监督的方法大多使用地标和可微渲染来进行训练。(Tewari et al.2017)利用原始图像和渲染图像的每个像素之间的差异作为训练损失。(Deng et al.2019)试图结合像素级光度差和皮肤概率掩模来计算训练损失。
上述弱监督方法都只利用一张图像进行构造,通常不能适当地估计人脸深度。比如单视图重建方法不能完全解释面部特征的几何差异,如口腔和眼窝的高度。然而,这种限制可以通过包含在一些不同视图的人脸图像或多视图图像中的几何约束来解决。令人惊讶的是,很少有关于弱监督的多视图三维人脸重建任务的研究。据我们所知,Deep3DFace (Deng等人2019)和 MGCNet (Shang等人2020)是目前唯一可用的利用来自单个受试者的多视图信息进行弱监督重建的方法。具体来说,(Deng et al.2019)使用CNN对每个多视图图像进行评分,然后选择评分最高的图像进行形状参数回归;(Shangetal.2020)基于多视图一致性设计一致性图,并计算一致性图的像素光度差。不幸的是,这两种方法的局限性有限,因为它们只是简单地连接多视图图像特征,没有考虑多视图图像特征的深度融合,也没有注意可能对重建质量影响最大的关键区域(如眼、眉、鼻和嘴)。
为了解决这些缺点,我们提出了一种新的端到端弱监督多视图三维人脸重建网络,该网络可以学习融合深度表示和识别关键区域。首先,由于多视图图像都代表同一张人脸,我们开发了一个编码-解码网络(Tri-Unet),注意提取特征并将其深度融合到一个特征图中。如图3所示,使用多个编码器从多视图图像中提取特征,并使用一个解码器在深度融合这些特征。为了补偿采样可能造成的损失,引入了需要注意的跳跃连接。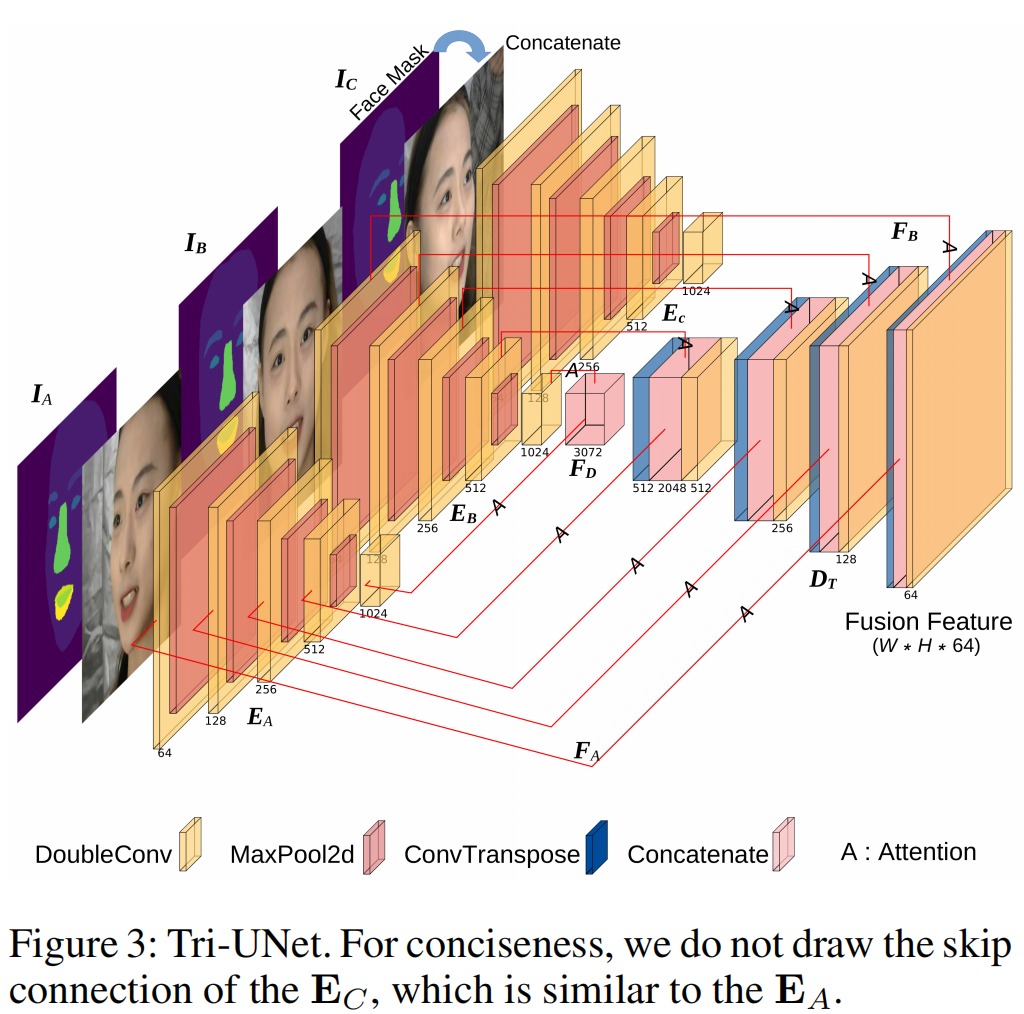
其次,我们开发了一个多视图的人脸解析网络来学习、识别和强调关键的共同人脸区域。人脸解析网络能够学习面具不仅作为输入特性帮助Tri-Unet编码/解码常见的多视图图像更好的深度融合,但也扮演了权重地图的角色计算像素光度损失呈现图像和原始图像。由于像素光度损失更关注RGB的差异,我们还增加了面罩损失,以缩小3D和2D面孔之间的面部特征(如眼睛、眉毛、鼻子和嘴巴)的大小。最后,我们导入RedNet(Li等人2021),而不是ResNet(He等人2016),后者通常用于人脸重建网络。RedNet是一种基于对合的残差网络(Lietal.2021),它比传统的卷积更灵活地提取信道特征。结合像素光度损失、掩模损失和地标损失,我们设计了一种新的弱监督训练框架,该框架能够全面融合深度特征,特别关注关键的人脸特征。
我们的工作贡献如下:
- 我们设计了一种新的弱监督编码解码框架(Tri-Unet)用于多视图特征的深度融合,这在文献中很少被研究。
- 我们开发了一种 mask 机制来识别多视图图像中的常见区域,并鼓励三维人脸重建网络更加关注关键区域(如眼、眉、鼻子和嘴)。
- 与传统的卷积相比,对合(Li et al.2021)具有空间特异性,能够在信道上的特征,这意味着它可以更好地处理深度融合特征。我们是第一个将它应用于面对重建任务的人。
- 在经验方面,我们的新框架获得了优越的性能,RMSE指标比现有的最佳弱监督MVRs提高了11.4%。
Related Work
3D Morphable Model 略
Single-view Methods 略
Multi-view Methods
令人惊讶的是,文献中基于机器学习的多视角三维人脸重建方法很少。(Dou and Kakadiaris 2018)提出使用循环神经网络(RNN)融合从深度卷积神经网络(DCNN)中提取的身份相关特征,以产生更具鉴别性的重构,但他们的方法没有利用多视图几何约束。(Wu 2019年)添加多视图几何约束,引入光流损失,以提高重建精度。在多幅图像的特征提取中,它们只连接了深度特征。这两种方法都需要3DMM的地面真相,这在实际上几乎无法获得。
(Deng 2019)将弱监督学习应用于多图像训练。他们设计了两个CNN模型来预测3个DMM系数,并对每张图像进行评分。采用高置信度的图像对形状系数进行回归,对其余的图像进行表达式、纹理等回归系数。(Shang 2020)采用几何一致性的概念来设计像素和深度一致性损失。他们在多视图输入图像之间建立了密集的像素对应,并引入了共可见映射来解释自遮挡。该方法加强了对多幅图像的公共区域的关注,但对人脸的局部特征和多幅图像的全局特征的关注较少。该方法采用人脸解析网络从多个角度对人脸特征进行标记,不仅可以关注多个视角的共同区域,还可以对共同区域进行更详细的划分。
Main Methodology
Overview
我们首先提供了我们提出的框架概述,如图1所示。我们决定利用一个主题的三幅多视图图像生成相应的三维人脸,并引入人脸解析网络(a)分别对这三幅图像进行处理,生成统一的标准掩模。设计了一种编解码网络(b),通过与注意机制共享一个解码器,将多视图图像的特征融合到深层。此外,RedNet(Li等人。2021)作为参数回归(c),回归 3DMM 和姿态系数。重建的三维面利用姿态系数重新定向,然后渲染回二维。计算重新渲染的二维图像与目标视图上的输入图像之间的照片损失,同时利用掩模作为权重图来增强面部特征的反向传播。在本节中,我们将提供如下所述的关于每个组件的详细信息。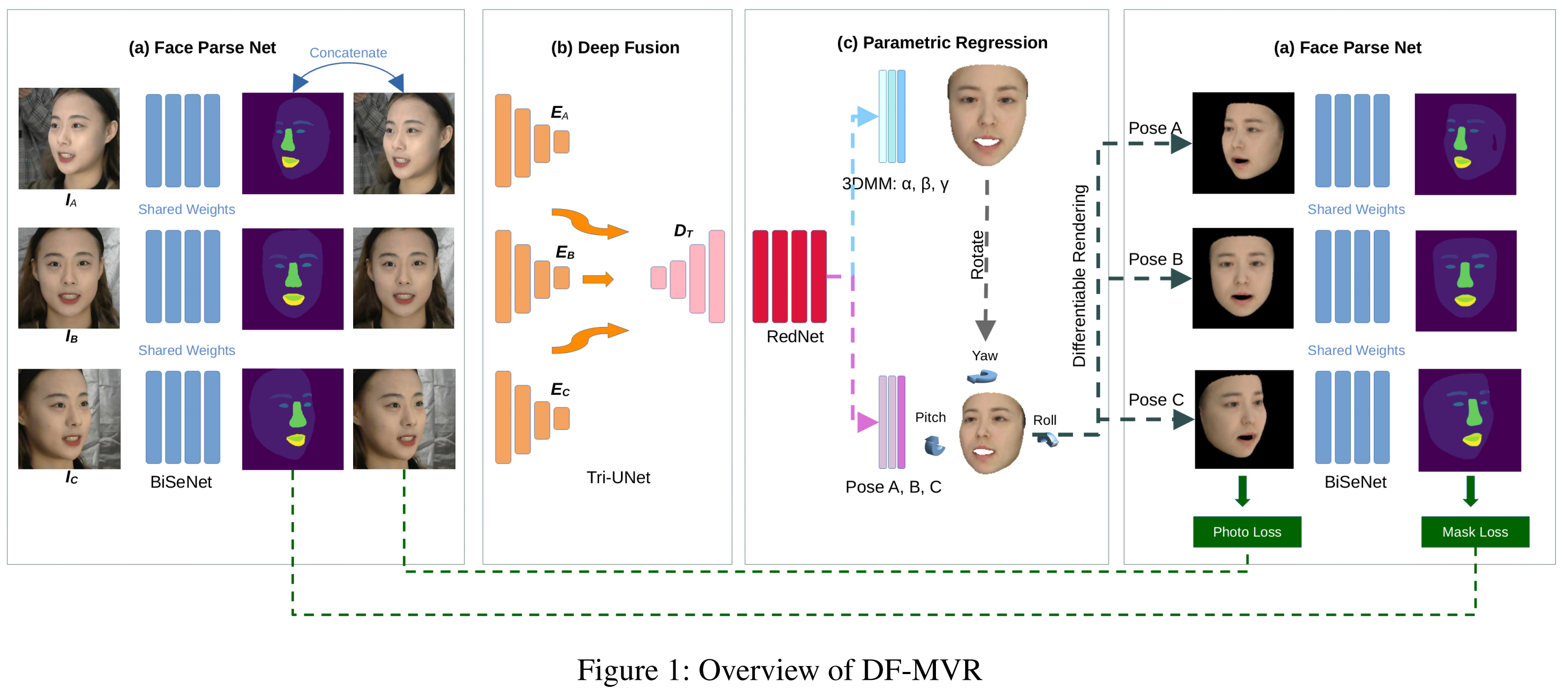
Face Parse Net
我们引入了基于 BiSeNet (Yu et al.2018) 的人脸解析网络,对输入图像进行初步分析,并识别图像的元素。生成的掩模只有一层通道。例如,如果输入图像的大小为2242243,则该掩模的大小将为224224 1。为了更好地突出面部,将去除过多的 mask 元素,如头发和颈部,并保留以下部分:面部、鼻子、下唇、上唇、左眉毛、右眉、左眼、右眼和嘴巴。保留的部分用不同的数字标记,以区分面部特征。一方面,将掩模与原始图像进行连接起来,以帮助网络理解多视图图像的公共区域。另一方面,mask作为weight map,计算训练时的照片损失和面具损失(photo loss and mask loss)。
Deep Fusion
现有的多视图人脸重建网络均部署了CNN或VGG (Simonyan and Zisserman 2014) 作为特征提取器。这些网络将多图特征连接在全连接层中,不能很好地进行特征交互。此外,以往的网络大多采用共享权值或一个骨干网来处理多视图图像,使得网络难以关注每个视图的独特信息。不同的是,受注意力 Unet (Oktay et al. 2018) 启发,我们设计了一种新的特征融合网络 TriUNet,来提取多视图图像的特征。
我们将三视图的输入图像表示为 IA, IB和 IC,代表左、前、右的三个视角。由于每个视图的信息和焦点都是不同的,我们设置了三个编码器,分别从三个视图中提取特征。对应于输入的图像,这三个编码器用EA, EB和EC表示。这三个编码器的权重不共享。编码器主要由双卷积和最大池化组成。在编码器的结尾,深层特征IA, IB, IC将被连接为FD。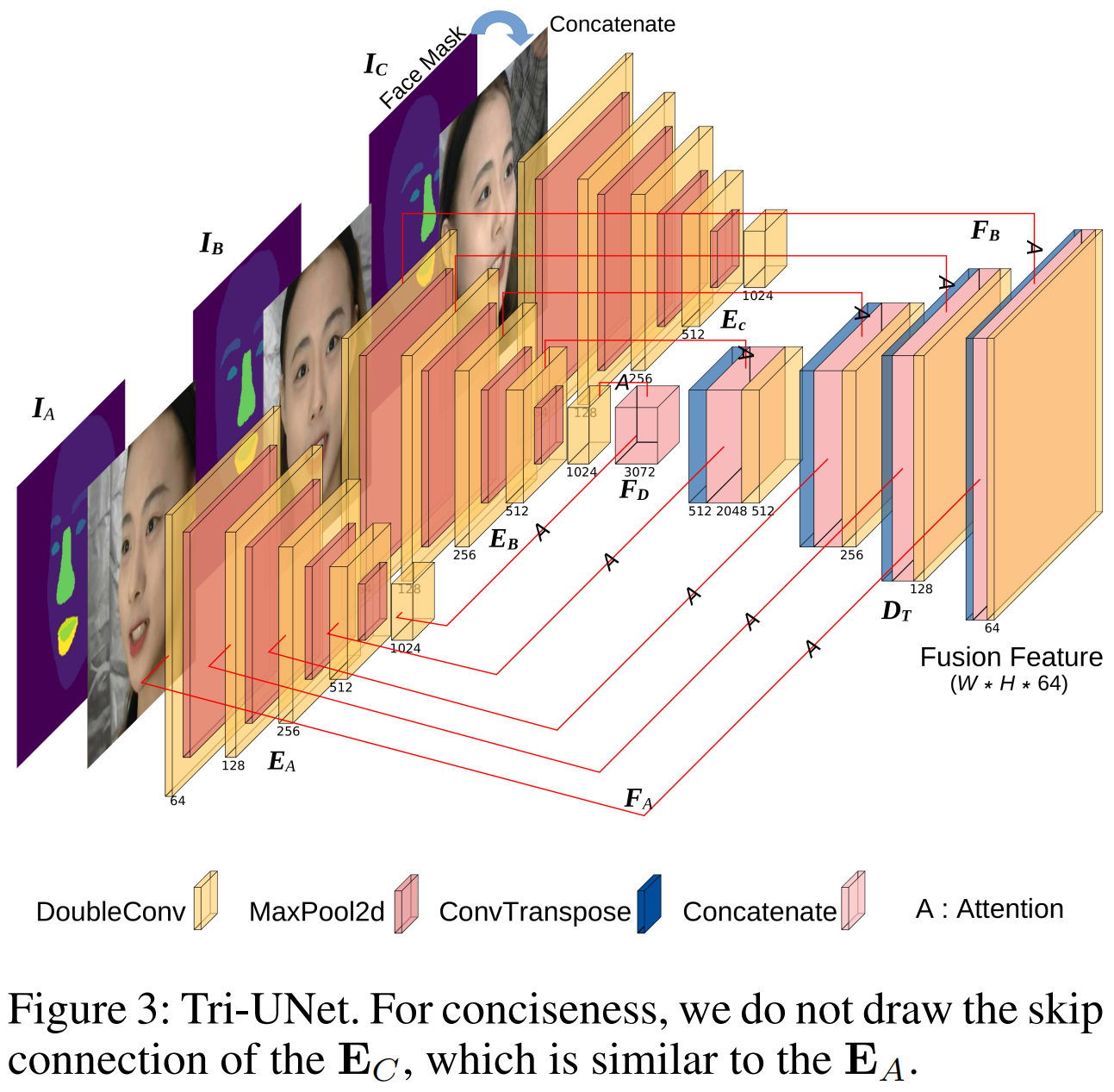
考虑到 IA, IB 和 IC 实际上描述了相同的对象,我们只设置了一个共享解码器,以更好地融合特征,并强调公共特征。该解码器主要由对偶转接、卷积、连接和跳过连接组成。我们采用注意机制从 EA, EB 和 EC 中提取特征 FA, FB 和 FC,来丰富解码 FD 过程中的信息。最后,我们保留的融合特征大小为 224 × 224 × 64,其中的图像大小为224 × 224 × 3。
Parametric Regression
我们采用 RedNet50 来处理融合特征和回归参数。RedNet 在 ResNet 架构上用 involution 代替了传统的卷积。卷积滤波器内的通道间冗余在许多深度神经网络中脱颖而出,使卷积核 w.r.t 不同通道的巨大灵活性受到质疑。与传统的卷积相比,involution 具有空间特异性,能够在信道上获得特征。因此,我们选择RedNet进行参数回归,ablation 实验也验证了其有效性。
3DMM参数的回归包括识别、表达和纹理参数。三维面形状S和纹理T可以表示为: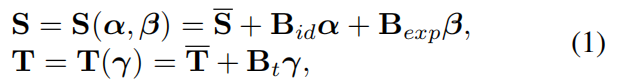
其中, 和
和 是人脸的平均形状和纹理。Bid、Bexp、Bt分别是身份、表达式和纹理的 PCA 基。α、β 和 γ 是网络需要回归的参数向量(α、β ∈ R80, γ ∈ R64)。通过调整这三个向量,可以改变三维面的形状、表达式和纹理。为了与 MGCNet (Shang 2020) 和 Deep3DFac (Deng 2019) 进行比较,我们使用了相同的人脸模型。BFM (Paysan 2009) 采用了
是人脸的平均形状和纹理。Bid、Bexp、Bt分别是身份、表达式和纹理的 PCA 基。α、β 和 γ 是网络需要回归的参数向量(α、β ∈ R80, γ ∈ R64)。通过调整这三个向量,可以改变三维面的形状、表达式和纹理。为了与 MGCNet (Shang 2020) 和 Deep3DFac (Deng 2019) 进行比较,我们使用了相同的人脸模型。BFM (Paysan 2009) 采用了 , Bid,
, Bid,  和Bt。Bexp 由(Guo et al. 2018) 基于Facewarehouse (Cao et al. 2013)获得。
和Bt。Bexp 由(Guo et al. 2018) 基于Facewarehouse (Cao et al. 2013)获得。
姿态参数用于调整摄像机坐标系中三维面的角度和位置。我们利用可微透视渲染 (Ravi et al. 2020) 将三维面渲染回2D。当摄像机坐标固定时,我们可以通过调整三维面在摄像机坐标系中的位置来改变渲染的二维面的大小和角度。通过预测各坐标轴的旋转角度和平移,可以确定三维面在摄像机坐标系中的位置。为了增强多视图重建的几何约束条件,我们分别预测了多视角的三维人脸姿态,而不是只预测一个视角的姿态来渲染二维图像。
Texture Sampling
三维人脸的纹理也是三维人脸重建的重要组成部分。然而,3DMM模型中包含的纹理基是有限的。如图4所示,3DMM不能代表口红、胡须等的颜色。因此,我们开发了从原始图像中采样的方法来恢复三维面的纹理信息。将预测生成的三维人脸通过摄像机坐标投影到二维图像上。由于三维面是由点云组成的,所以每个点都可以投影到一个二维图像中。投影到二维的点取四个邻域像素值的平均值作为它自己的纹理信息。这样,就可以获得完整的三维面纹理信息。
在此框架下,提出了两种训练方案:弱监督训练和自监控(self-monitored)训练。是否使用三维地标是区分这两种方案的标准。作为一种弱监督的训练方法,我们的模型需要使用少量的3D注释作为标签。另一方面,如果不引入三维地标来计算损失,我们的模型将不需要任何三维标签,只需要多视图图像进行训练。这两种方案都已在下面的章节中进行了验证和比较。
Weakly Supervised Training
为了缓解对标记数据的强烈需求,我们设计了一种弱监督的训练方法。
- 首先,我们将预测的三维人脸模型渲染回二维,并将渲染的图像与原始图像逐像素进行比较。
- 然后,将渲染的二维图像输入人脸解析网络 (face parse net),生成渲染的掩模。根据一致性原则,渲染的 mask 应与原 mask 一致。因此,L2距离被视为一个掩模损失。
- 最后,将地标损失和正则化损失引入三维人脸的形状,抑制畸变脸的产生。
Photo Loss
照片损失经常用于弱监督的人脸重建任务。与传统方法不同的是,我们根据面部特征对每个像素施加一个权重。权重图由原始图像I的掩模M学习。为了增强权值图的鲁棒性,我们将 M 以20像素扩展为 Md,如图5所示。多视图的照片损失可以表示为: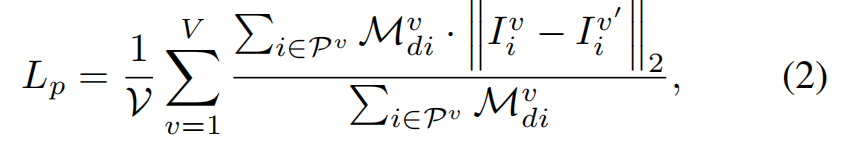
其中,V 是重建的视图的数量。在该模型中 V = 3。Pv 是渲染图像所在的区域 Iv’ 和原始图像 Iv 在当前视图中相交 。i 表示像素索引,| · |2表示 L2 范数。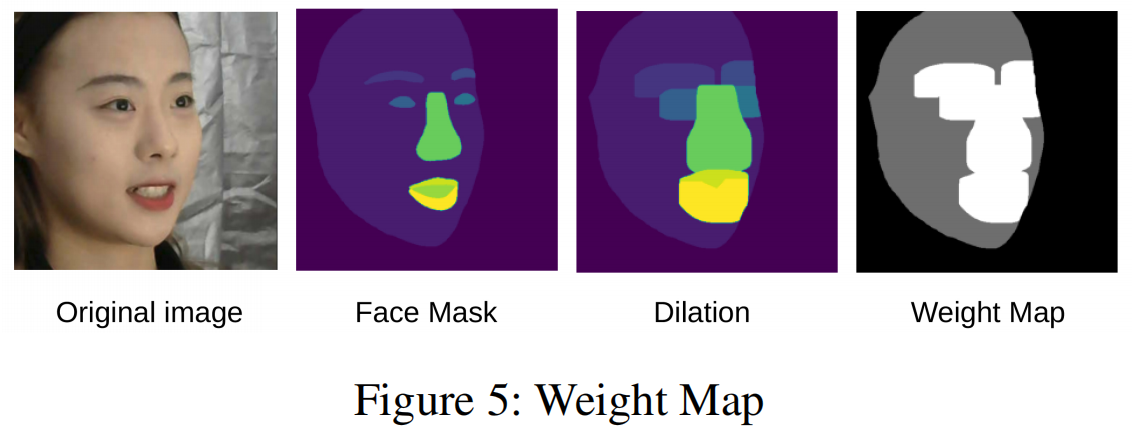
Mask Loss
照片损失主要在两张图片之间的像素差。在这两幅图中,很难限制面部特征区域的大小。例如,鼻子的颜色与脸颊非常相似,因此导致照片丢失很难注意到它们之间的边界线。因此,我们引入掩模损失来缩小输入图像和渲染图像的人脸特征。面部特征的划分和标记如图2所示。我们用20个像素来扩张mask,以增强权重图的鲁棒性。然后将扩张的图像分为三个层次作为权重图。在权重图中,面部特征标记为254,其余的面部区域标记为128,背景标记为32【?】,如图5所示。类似于照片损失,我们可以计算多视图的掩模损失: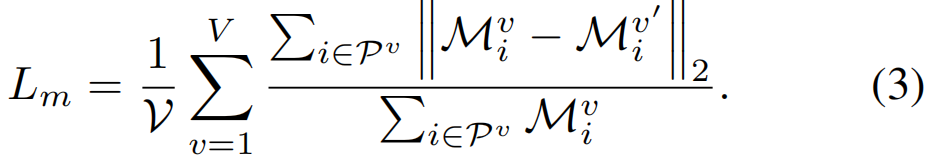
Landmark Loss
我们还采用二维地标和三维地标进行弱监督训练。我们使用三维人脸对齐方法 (Bulat and Tzimiropoulos 2017) 生成 68个地标 {ln} 作为事实。然后将预测的三维面点云中对应的点投影为预测的二维地标 {l}。 然后可以计算出多视图二维地标损失: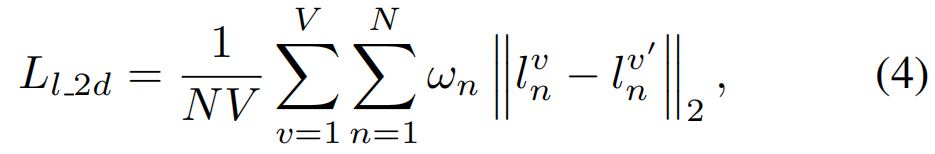
其中ωn是每个地标性建筑的权重。我们将鼻子和内口腔的 landmarks 权重设置为20,其他设置为1。
二维地标仍然不足以进行重建三维人脸形状。为了获得更好的重建效果,我们选择了 101 个三维地标{q}来对三维面的形状施加弱约束。 根据 3DMM 指数,有 101 个预测地标{qn}可以找到。然后,我们分别在 {qn’} and {qn} 中 选择7个点 {an’} and {an} 作为对齐点,计算{qn’}和{qn}的对齐参数。对齐参数包括 scale s、旋转 R 和平移 t。这些参数可以通过以下优化方程得到(Tam et al. 2012; Sanyal et al. 2019):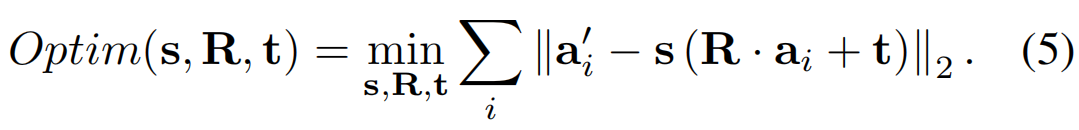
在得到最优的s、R和t后,得到预测的101个地标{qn}可以转换为{qn’}的空间 {qnt}= s (R · qn+ t)。
然后可以计算出多视图三维地标损失: 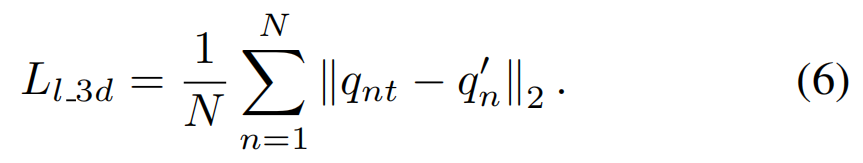
综上所述,Landmark 损失可以表示为: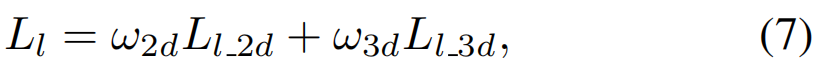
其中ω2d和ω3d分别表示2D地标损失和3D地标损失的权重。在这项工作中,我们根据经验调整了它们为0.02和1。
Regularization Loss
为了抑制扭曲的人脸产生,我们添加了在人脸重建任务 中常用的正则化损失: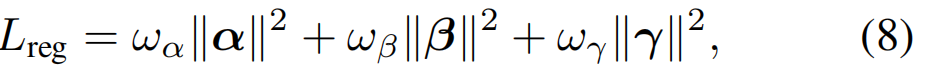
其中,α、、和为网络预测的3个DMM参数向量。ωα, ωβ和ω是3个DMM参数向量的权值。遵循
Deep3DFace(Deng 2019),我们将其设置为1,0.8 和0.017。
Overall Loss
我们的端到端网络对弱监督训练所需的总体损失可以表示为: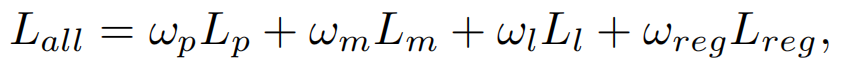
其中,ωp、ωm、ωl、ωreg为照片损失、掩模损失、地标损失和正则化损失的权重。根据Deep3DFace,我们设置了ωreg=3.0×10−4。由于ω2d和ω3d已经被确定,我们只通过敏感性分析来固定ωl=1来调整ωp和ωm。然后,我们将ωp=4和ωm=3作为敏感性分析的经验结果。
Experiment
Setup
数据集。Pixel-Face (Lyu et al. 2020) 是一个大规模的、高分辨率的MVR数据集,其中包含855名年龄在18-80岁之间的受试者。每个受试者有7到23个不同的表达式样本。Pixel-Face 有每个样本的三维网格文件作为基真值,但不是3DMM参数或多视图图像的角度。因此,它适用于MVR的弱监督或无监督训练。在实验中,列车测试分割被设置为0.8。不幸的是,在本文中很少有其他的数据集可供比较。例如,虽然MICC和AFLW2000-3D更常用于三维人脸重建,也不能满足我们的多视图设置:AFLW2000-3d主要采用单个图像测试,和MICC数据集提供数据的视频,这意味着其表达在每个视图可能会改变。为此,我们只在Pixel-Face 数据集上进行测试。
网络。我们的网络如图1所示,并在方法部分中进行了描述。基于预先训练好的BiseNet(Yu 2018)。人脸解析网络位于网络的开始和结束。在MVR的场景中,我们设计了一个由三个不同的编码器组成的融合网络,以强调更多样化的特性。一个轻量级的RedNet50(Li 2021)被设计为参数回归网络,因为融合网络已经提取了足够的信息。
评价指标。根据之前的工作,RMSE(mm) 用于计算预测3D扫描和地面真相3D扫描之间的 point-to-plane L2 distance。具体地说,裁剪正面面积以进行指标计算,而不是使用完整的BFM模型。在计算点到平面的L2距离之前,预测的三维扫描需要与地面真实的三维扫描进行登记。我们使用了与(Dengetal.2019)相同的 ICP 登记方法(Lietal.2019)。
Comparison to SOTAs
我们将我们的方法与现有的弱监督mvr进行了比较。参数化结果如表1所示。据观察,我们提出的模型获得了优越的性能,与现有的最佳弱监督mvr相比,RMSE提高了11.4%。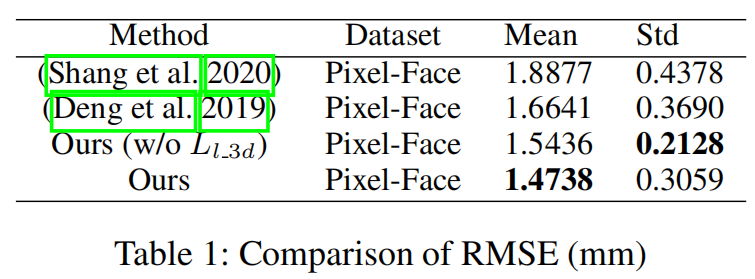
由于(Shang 2020) 和 (Deng 2019)没有使用三维地标,为了公平,我们也提供了没有使用三维地标的模型结果进行比较。根据标准偏差,我们的模型(没有三维地标)与现有方法相比提高了7.2%,具有最高的稳定性。
更具体地说,在有关多视图弱监督三维人脸重建的文献中,只能找到这两种方法。这两者都作为本文的比较方法。(Shang 2020) 使用多个图像进行训练,然后使用单个图像进行测试。我们从三张图像中选择最好的结果进行显示。(Deng 2019)没有发布其评分网络的源代码。我们使用他们的代码来对 PixelFace 进行训练/测试。可视化的比较显示在图6的前 3 行,给定的3视图面。很明显,我们的预测模型更准确,特别是在面部特征的面部深度估计方面。此外,我们的模型可以更好地学习人类的面部表情,比如闭上眼睛和噘起嘴唇。最后,在图6的最后三行表明,即使只输入一个面,我们的模型仍然可以优于其他sota。更多的分析可以在补充资料中看到。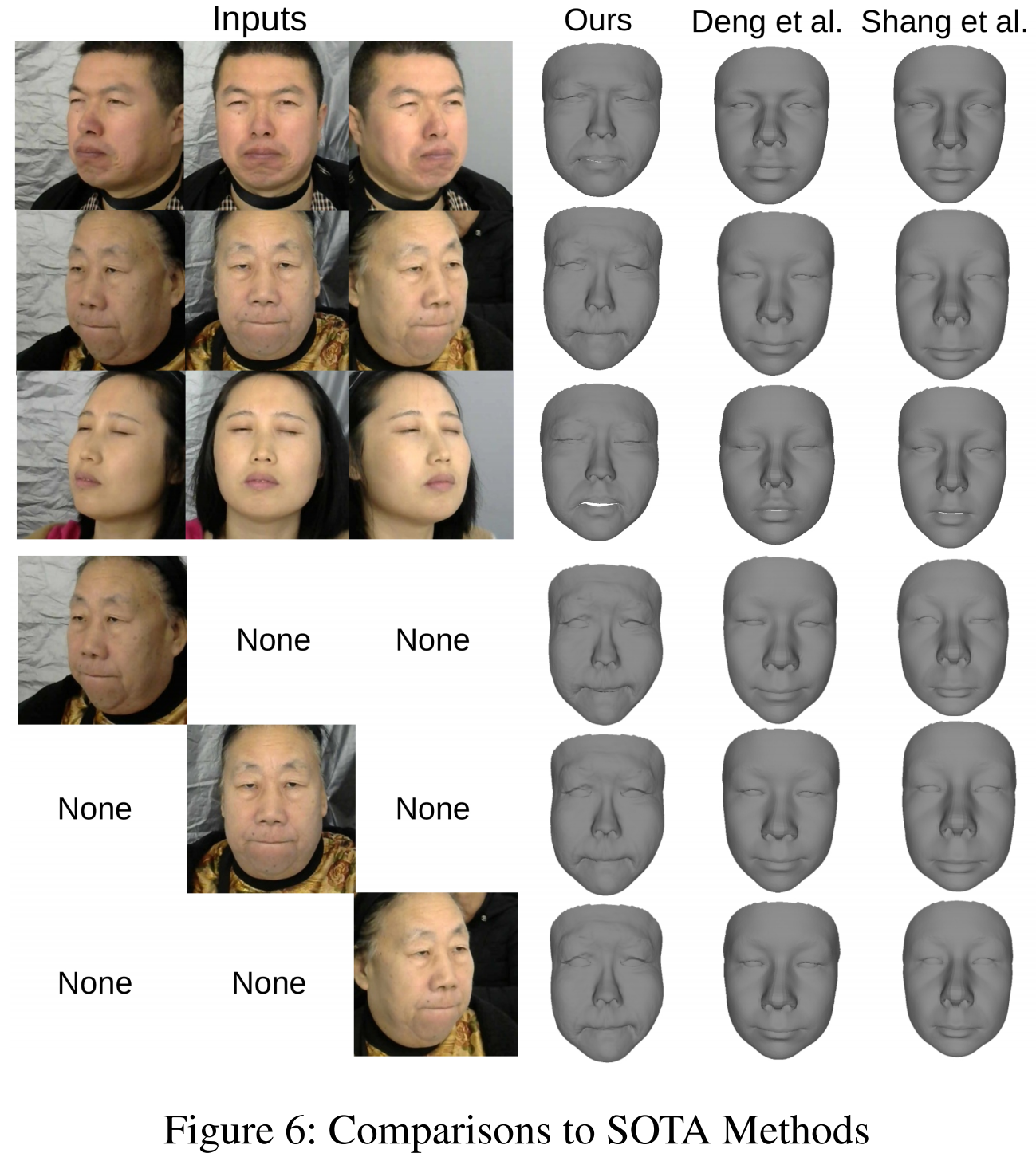
详细的比较。更仔细的比较见图7。由于三维地标将改善面部特征的重建,为了公平起见,我们也报告了结果(没有三维地标)进行比较,可以更好地反映面罩机制对面部特征调整的影响。在第一个样本中,我们的模型可以预测噘起嘴唇的表达。与其他模型相比,我们的模型的上唇几乎是看不见的。在第二个样本中,我们的模型的眉毛和眼睛看起来与原始图像更相似。
限制。虽然我们的模型具有较高的精度,但它也有一些局限性。三个多视图图像作为输入使得模型对一些固定场景的灵活性不那么低。第二,我们的模型是基于具有有限向量基的3DMM (Bid, Bexp和Bt)。为此,我们的模型不能重建皱纹、胡子、眼影等,如图8所示。今后我们将重点解决这两个障碍。
Ablation Study
为了验证Tri-Unet的有效性和我们设计的掩模机制,我们进行了更多的消融实验,如表2所示。RMSE的平均值和标准差再次被用作评价指标。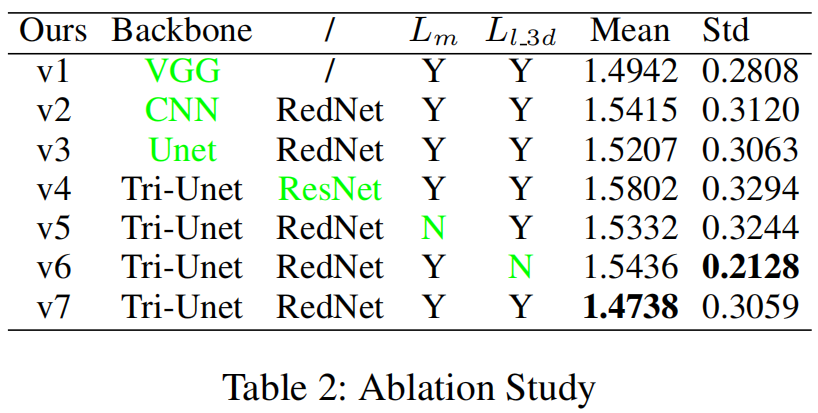
首先,从v1、v2、v7中可以发现,我们设计的多视图特征融合网络在此任务中优于传统的CNN和VGG。然后,v3和v7的结果表明,特征提取阶段的多层特征交互优于最后特征的直接连接。为了公平,我们将RedNet 和 ResNet 的层数设置为50层。通过v4和v7的RMSE,很明显 RedNet 在这个任务中比 ResNet 表现得更好。对于v5,我们不仅去掉了掩模损失,还去掉了与原始图像相连的掩模IA、IB和IC。通过比较v5和v7,我们可以看到掩罩机制促进网络生成更高精度的模型。最后,我们删除了Llan_3d,这意味着我们的模型只能用3张多视图图像进行训练,没有任何3D标签(标记为v6)。结果还表明,该模型是准确、稳定的。
如图9所示,我们从验证集中选择了3个有代表性的样本进行可视化。第一个样本是一个一只眼睛睁着,一只眼睛闭着的老年人。从结果来看,我们的模型可以以较小的误差预测她的肤色和表达方式。由于3DMM形状矢量基的局限性,她的皱纹无法细化。另外两个样本分别是愤怒的年轻女性和平静的中年男子。
Sensitivity Analysis
我们进行敏感性分析,以检验光损失和掩模损失系数是否对模型性能有影响。为了保证模型的准确性,我们对ωp和ωm进行了参数敏感性分析。如图10所示,我们首先固定其他参数,然后只改变ωp。当ωp在4~5之间时,该模型可以获得更高的精度。然后,我们将ωp固定为4,并且只改变ωm。当ωm接近3时,模型可以获得更高的精度。这样,我们将ωp和ωm分别设置为4和3。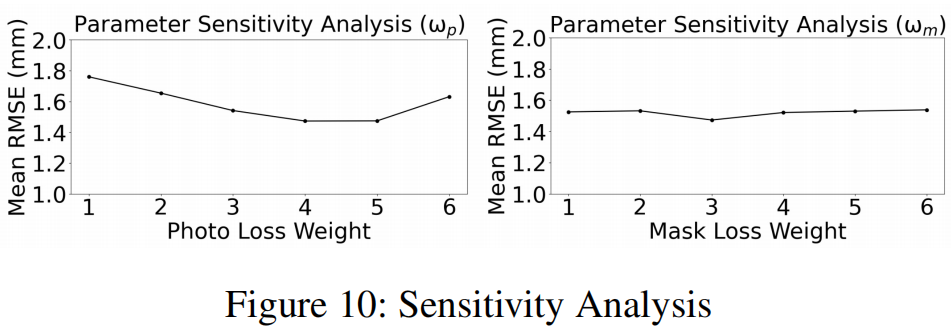
Conclusion
本文设计了一种新的端到端弱监督多视点三维人脸重构网络,该网络利用多视图编码到一个具有跳跃连接的单一解码框架中,能够提取、整合和补偿深度特征。此外,我们开发了一个多视图人脸解析网络来学习、识别和强调关键的共同人脸区域。结合像素级光度损失、掩模损失和地标损失,我们完成了弱监督训练。大量的实验验证了该模型的有效性。我们进一步的研究将集中在部署多视图图像进行训练,并且只使用单一图像来重建三维人脸。

若有收获,就点个赞吧
0 人点赞
