Yuhan Zhang et al., “Meta Talk: Learning To Data-Efficiently Generate Audio-Driven Lip-Synchronized Talking Face With High Definition,” in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, 4848–52, https://doi.org/10.1109/ICASSP43922.2022.9747284.
- 利用3D重建生成高清图像。
- 模型总结:先使用wav2lip生成pseudo视频,然后对伪视频进行三维重建,获取表达参数。训练本文提出的A2E网络学习音频和3D表达参数的映射。最后训练渲染网络GAN,提高生成图像帧的质量。
解决什么问题
现有的语音驱动人脸研究 需要录制长时间高质量的目标视频,这大大增加了定制成本。目前的方法存在清晰度低、唇动与语音不同步、训练视频要求高等问题。
本文实现了使用3分钟的视频生成高清晰度的唇部同步说话人脸视频,实现了数据高效的训练。该方法减轻了目标视频采集的负担,在高清晰度图像质量方面具有最好的性能,在唇同步方面的性能与现有方法相当。
贡献点
- 本方法中引入了 Wav2Lip 预测的低清晰度伪视频,用来增强 audio driven identity-disentangled ability。
- 训练了一个改进的 audio-to-expression (A2E)网络,以保证任意音频驱动的准确唇形运动,这使得我们的方法具有媲美Wav2Lip[4]的强大的音频驱动能力。
- 引入了修改后的 crop 模块,自动将3DMM合成人脸的大小与原始人脸区域相适应,使我们的框架能够满足4k清晰度的真实感说话人脸视频的要求。
基于三维形态模型(3D morphable model, 3DMM)[2]的方法减少了目标视频采集的负担,但由于其音频驱动性能严重依赖于音频身份,因此lip形状无法与生成的视频中任意一段新音频很好地同步。
具体方法
训练阶段:
- Crop:目标视频裁剪成只有人脸区域的视频;
- resize 后,使用预训练模型 wav2lip 和 LRS2 的音频,生成低清晰度的说话人脸伪视频;
- 提取 3DMM 参数:对生成的伪视频和原始视频同时进行3D人脸重建,从每一帧中提取人脸3DMM参数;
- 用伪视频的 audio-expression pairs 训练 A2E 网络,推理音频特征到3DMM参数的映射关系;
- 利用 3DMM 参数重新渲染合成人脸;
- 训练一个神经渲染网络,输入的是伪视频的 lower face 和 原始视频的 lower face,生成高清逼真的人脸视频。
测试阶段:
- 输入任意音频到 A2E 网络中,预测音频驱动的3DMM参数。
- 用预测的3DMM替换原始3DMM。
- 使用组合的3DMM参数重新渲染人脸,生成的人面的下半部分被转换成一个真实的下半部分面。
- 最后,将生成的逼真的下半人面贴回原始目标视频的对应位置,生成高清唇同步视频。
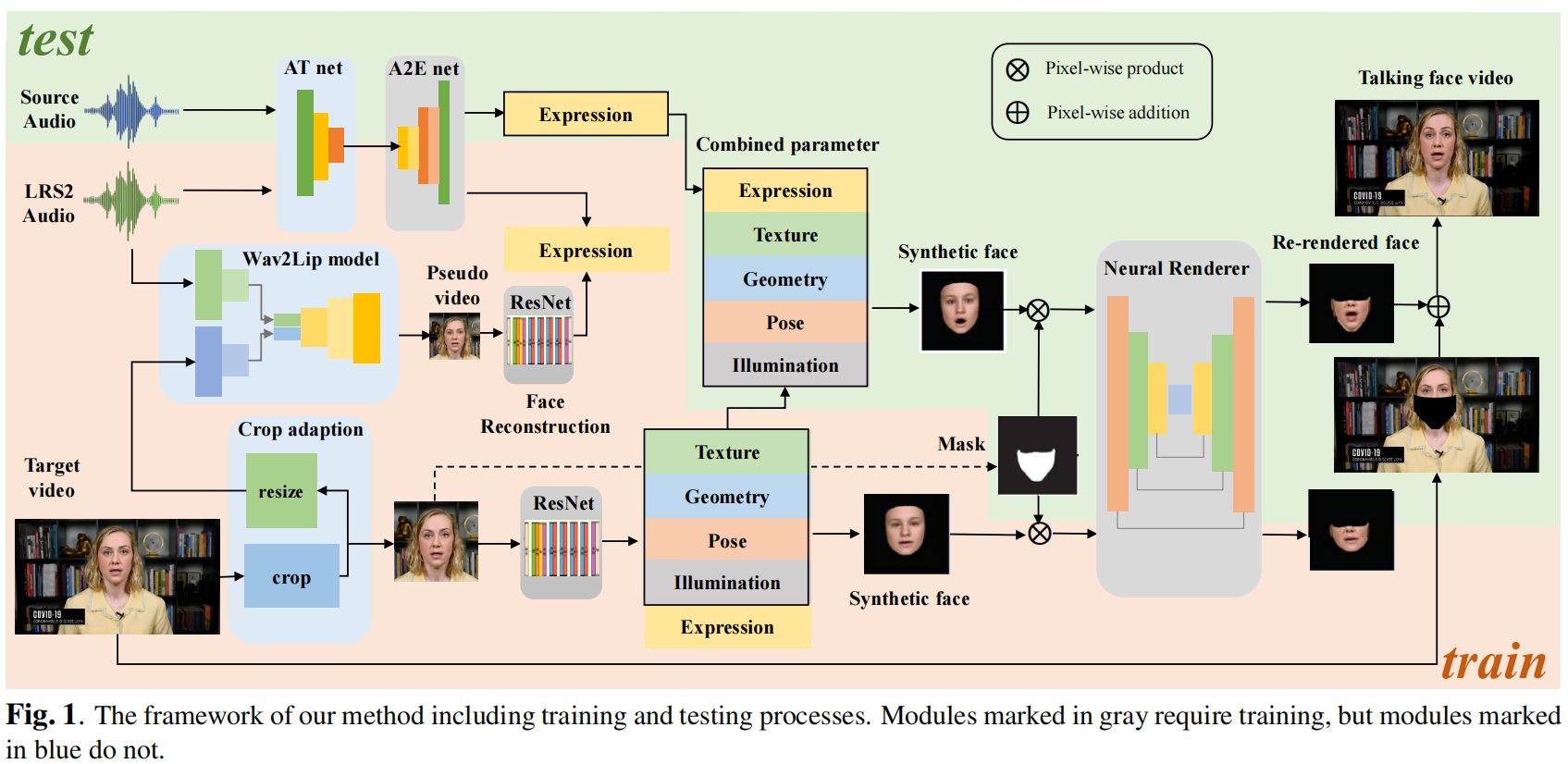
1. Crop adaptation
通过 Wav2Lip 获取伪视频 pseudo video:将目标视频 crop 成只有人脸区域的视频,resize到低分辨率,使用预训练模型 Wav2Lip 和来自LRS2数据集的音频,生成低清晰度的 talking face video。
- 经Wav2Lip预测得到的伪视频清晰度低,但唇同步性好。这一步可以获得wav2lip强大的唇同步性。
resize操作减少了伪视频的大小,但可以显著加快三维重建的速度。本文提出的方法重点是驱动表达参数(三维人脸重建得到的),它不依赖于输入视频的帧大小,所以可以使用低清晰度伪视频来提取表达参数。Due to the priori embbeding of 3DMM,可以在低分辨率和低清晰度下进行3D人脸重建。
2. 3D Face Reconstruction
获取3D人脸参数:分别对伪视频和目标视频进行3D人脸重建,从每帧图像中提取人脸3D形态模型(3DMM)参数,包括表达、几何、纹理、姿态、光照系数。
我们使用基于深度学习的人脸重建模型[10](Deng_2019微软这篇),其中输入的人脸 I 表示为3DMM,这是一个参数化的人脸模型。
- 然后训练一个深度CNN,从输入人脸 I 估计 3DMM的参数ΦI。用3DMM参数和一些公式、规则计算出几何、纹理等。
- 采用了与AudioDVP[2](上面Wen_2020这篇)相同的微调步骤,对伪视频和目标视频的三维重建网络进行微调。
3. Audio to Facial Expression Mapping
训练A2E网络:Audio to Facial Expression Mapping,使用 3DMM(从Wav2Lip预测的伪视频中估计得到 )训练 audio-to-expression transformation network(A2E),将音频特征映射到配对的3D面部表达参数。
- 首先提取输入音频的MFCC特征,输入到AT-net[3]中,得到256-D高阶特征f。
- 然后,建立A2E网络,将该特征映射到配对的3D面部表情参数。由于 audio-expression pairs 的训练数据庞大而丰富,我们在AudioDVP[2]中对A2E网络进行了深化(deepen),以增强网络的建模和拟合能力(见表1)。
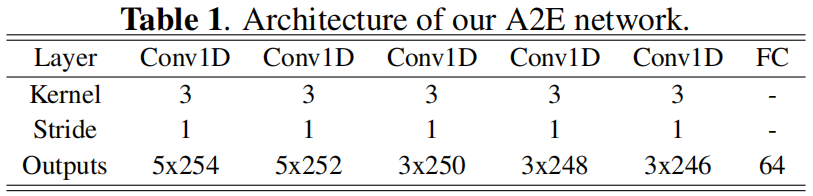
- A2E 网络的损失函数是 mean squared error (MSE) 。
提高人脸图像的质量。用 the lower half of synthetic and real target faces 训练神经渲染网络,利用3DMM参数重新渲染目标视频中合成的人脸图像,生成高清晰度的逼真人脸视频。
- 采用AudioDVP[2]的 masking 策略获取合成人脸的下半部分和目标人脸。
- neural rendering network 由基于U-Net 的生成器G和鉴别器D组成。
- Generator 由 face encoder 和 face decoder 组成。修改了生成器的输入大小,以调整目标人脸的分辨率。Rendering face encoder 是一组下采样卷积层,它对合成人脸的下半部分进行编码,获得其高级特征表示。然后通过转置卷积叠加解码器对特征进行上采样,合成高质量输出。
- Discriminator 使用PatchGAN[15],训练生成器最小化生成的渲染人脸和ground-truth人脸I的L1重建损失。
测试阶段
- 根据音频预测人脸:输入任意音频到训练好的 audio-to-expression transformation 网络中,以预测表达参数。
- 获取3D参数重新渲染人脸:用预测的表达式参数替换三维重建得到的3DMM参数的原始表达式参数。使用组合的3DMM参数重新渲染合成的人脸。Then the lower half of the generated synthetic face is translated to a realistic lower half face.
- 下半张人脸贴合:最后,将生成的逼真的下半边脸缝合到原始目标视频背景中,生成高清晰度的唇同步视频。
目标函数
- A2E网络(音频到脸部表达),均方误差 MSE loss:

- 人脸渲染网络,由生成器的 L1 重建损失和 GAN 的损失组成:

评价指标
使用 LSE-D、LSE-C、FID、SSIM 四个指标。前两者评估 lip-sync 质量,后两者评估图像质量。(LSE-D和FID越低越好,LSE-C和SSIM越高越好)
- Quantitative evaluation,和 ATVG[3], Wav2lip[4], AudioDVP[2] and MakeIttalk[5] 这4 个模型进行了对比,比较上述四个指标。
- Ablation study,证明对生成talking face有改进。AudioDVP [2] 作为baseline,对比A2E网络、modification for high definition 和 本文提出的完整的模型 在上面四个指标上的分数。
- User study,生成了35个长15s的视频,随机展示给20个匿名参与者,从2个角度来评价视频:说话人脸的真实性和清晰度、是否与音频同步(得分不是很高,但是和另外4个方法对比的话得分最高)。
未来工作
In the future work, we will focus on talking face generation based on target identity disentanglement.

若有收获,就点个赞吧
0 人点赞
