研究问题
研究背景
声音与人的性别、年龄以及嘴唇开合相关联,脸部最能反应这些特性。挖掘语音与人脸之间的关联性,进而通过给定的语音片段生成对应的人脸图像。
研究方法
- 基于自注意力机制构建语音编码器网络以获得更为准确的听觉特征表达,并将其作为静态生成网络和动态生成网络的输入;
- 静态生成网络利用基于投影层的图像判别器合成出属性一致(年龄、性别)且高质量的静态人脸图像;动态生成网络利用基于注意力思想的嘴唇判别器和图像判别器合成出嘴唇同步的动态人脸序列;
建立涵盖性别和年龄2种属性的数据集Voice-Face,利用属性对齐(性别,年龄)的Voice-Face数据集和公共的LRW数据集分别训练静态人脸生成网络和动态人脸生成网络
研究思路
Zhang等人[12]将自注意力机制与GAN[13]相结合,提出了一种新的图像生成模型SAGAN。本文通过将自注意力机制添加到语音编码器网络中以提取出更准确的听觉特征。同时在动态人脸生成模型中,我们还利用注意力思想捕捉嘴唇区域的特征,进而将身份人脸图像中的身份属性信息与嘴唇运动信息进行分离,以实现在任意身份下生成嘴唇同步的动态人脸序列。
主要内容
1. 自建数据集
选择了aidatatang_1505zh数据集中的语音片段和CACD2000数据集[14]中的人脸图像。对于这两个模态的数据,我们对其按年龄段(11-20、21-30、31-40、41-50)和性别(男、女)进行组合。
数据预处理包含2步:语音预处理:原始的语音信号是由16kHz的单声道进行采样而得到,在我们的模型中需要将其转换成声谱图作为系统的原始输入。我们将语音分别转换成短时傅里叶变换(STFT)、梅尔频率倒谱系数(MFCC)和对数振幅梅尔频谱(LMS)这三种声谱图,并对比三者分别作为模型输入时的生成效果,根据模型实际的性能表现,最终选择将语音信号的MFCC特征作为语音编码器网络的输入。
- 人脸图像裁剪:为了去除人脸图像中多余的背景信息,我们采用人脸检测器[15]来检测图像中相应的人脸部分区域,进而从整幅图像中裁剪出人脸区域,最后将裁剪后的人脸图像统一缩放为相同的尺寸大小。
2. 网络架构
包含编码器、生成器、判别器三个部分。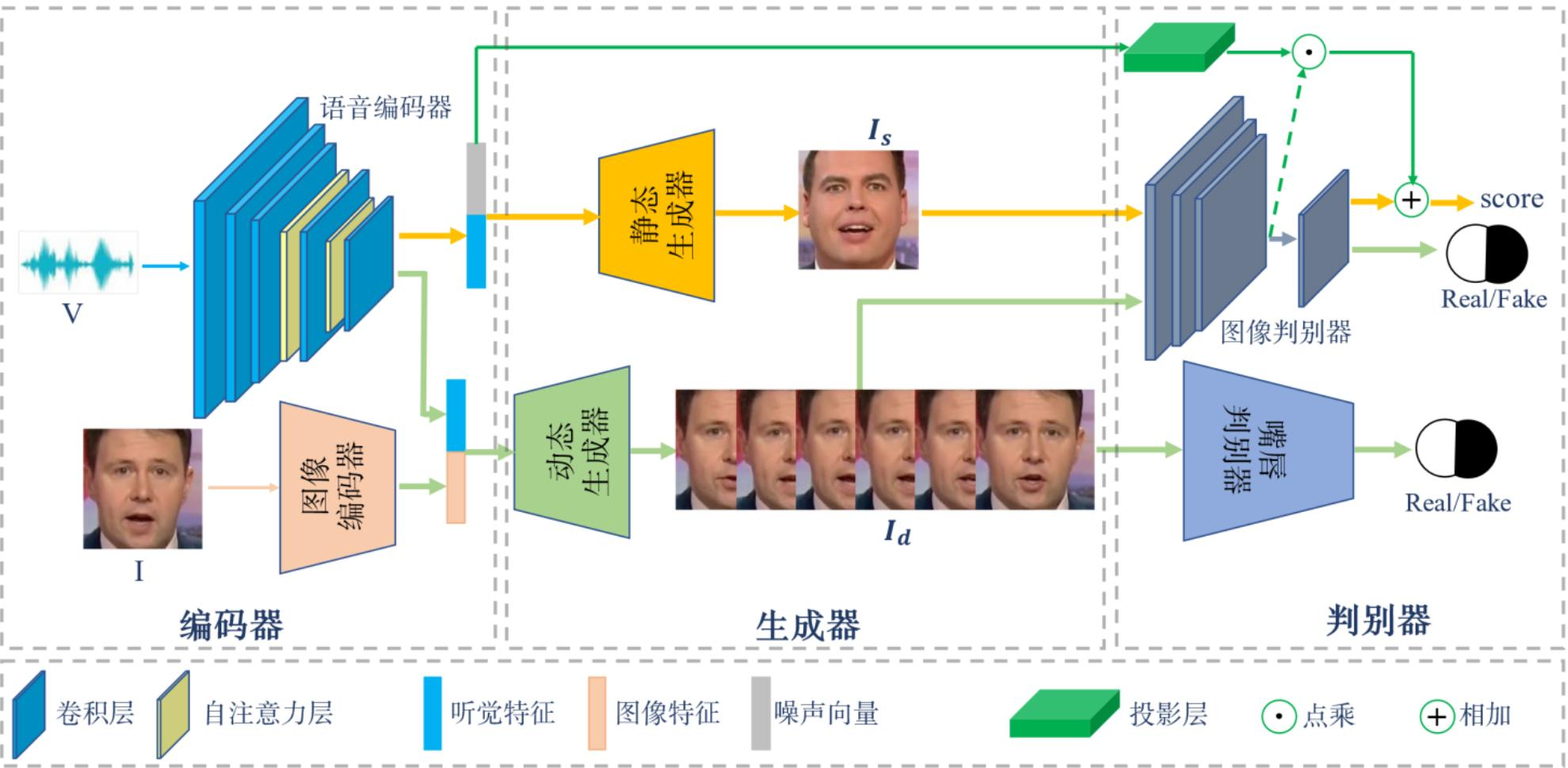
2.1 编码器
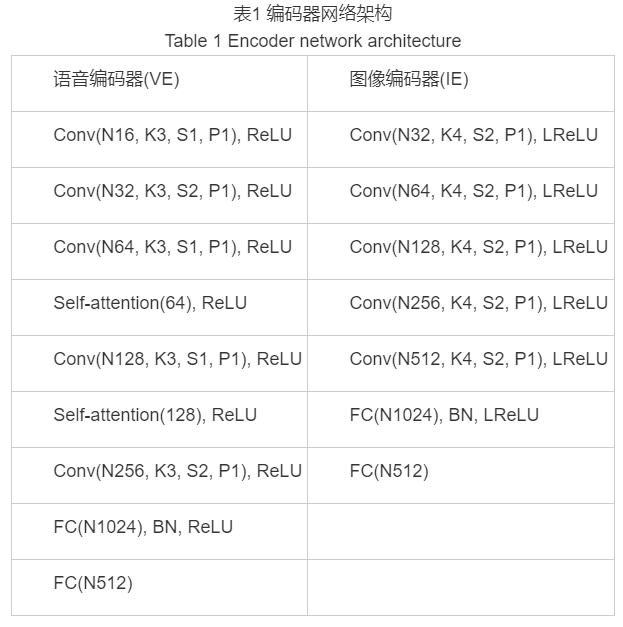
- 使用基于CNN构建的语音编码器VE来提取语音信号的听觉特征向量。
- 自注意力机制[16]可以模拟图像区域中长距离、多级别的依赖关系,进而可以使得远距离依赖特征之间的距离极大的缩短。
- 构建图像编码器IE。将听觉特征和图像特征相串联得到的混合特征作为网络的输入,以确保生成的人脸序列中的多张人脸图像在身份信息上的一致性。
2.2 生成器
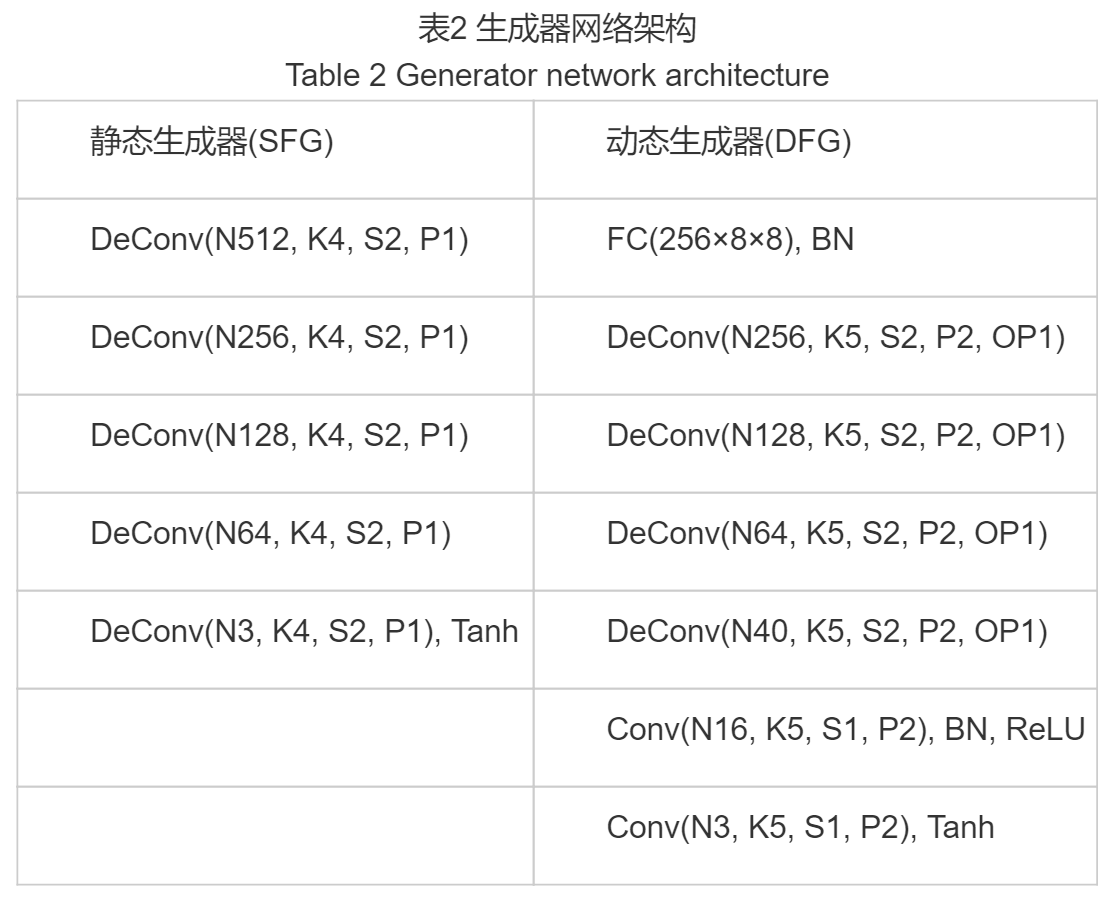
- 基于条件生成对抗网络(CGANs)[17]
- 听觉特征向量与噪声向量相串联,作为静态人脸生成器SFG的输入,进而合成出属性一致(年龄和性别)的静态人脸图像;听觉特征向量与图像特征向量串联,作为动态人脸生成器DFG的输入,通过分别考虑语音相关信息和身份相关信息来生成嘴唇同步的动态人脸序列。
- 噪声向量使用标准正态分布采样zn∼N(0,1)
2.3 判别器
直接截取原文:
对于动态人脸生成,其目的是生成嘴唇同步的人脸序列。由于图像判别器以整个人脸图像为判别标准来更新动态生成器网络的参数,所以仅利用图像判别器不足以在训练时捕获到精准的嘴唇运动。为了能够在人脸图像中捕获嘴唇相关的变化信息,我们基于注意力的思想构建了一个嘴唇判别器Dl,通过仅关注嘴唇区域的变化来去除身份相关信息及面部表情的干扰,并将其与图像判别器相结合,二者共同以对抗训练的方式更新动态人脸生成器,以生成嘴唇同步的高质量的动态人脸序列。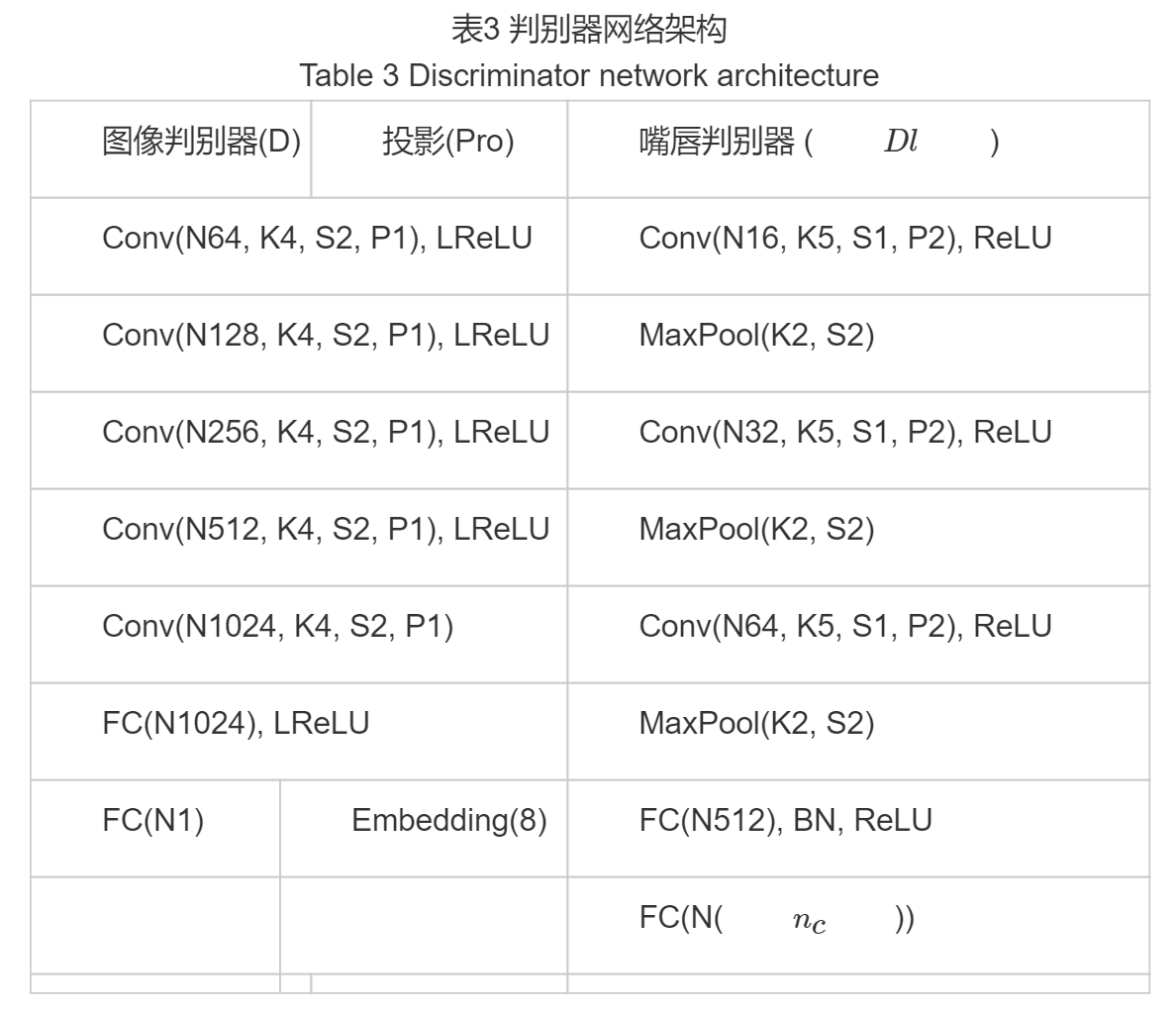
2.4 损失函数
直接截图:
静态人脸生成模型中的计算:
动态人脸生成模型中的计算:
3. 实验设置
- 语音编码器网络的最后两个卷积层之前都添加了一个自注意力层来捕获语音中的长距离依赖信息,并在最后一层卷积层后添加了两个全连接层来得到听觉特征向量。
动态人脸生成器中借鉴了U-Net[20]的思想,其将图像编码器中各卷积层的图像特征分别馈送到生成器网络中,以更好地保持生成的动态人脸序列身份信息的一致性。
4. 评价标准
静态人脸:
跨模态准确率(Cross-Modal Accuracy),定量评估属性组合的跨模态人脸生成是否成功。
- Fréchet Inception Distance (FID),通过计算真实图像和生成图像在特征向量上的距离来定量评估生成的静态人脸图像质量的好坏。FID值越小,表明生成数据与真实数据之间的分布越接近,生成的静态人脸图像质量越高、多样性越丰富。
动态人脸:
- Peak Signal-to-Noise Ratio(PSNR)和Structural SIMilarity (SSIM)[22],评估生成的视频帧质量的好坏,两者的值越大,说明生成人脸序列的质量越好。
Landmarks Distance(LMD)[23],评估生成人脸序列中嘴唇同步的准确性。LMD通过计算真实序列和生成序列之间的关键点距离来度量嘴唇同步准确率,其值越小,表明合成人脸序列的嘴唇运动与输入语音片段的匹配程度越高。
5. 实验结果
静态人脸生成
定性结果
图2显示了8种不同属性组合下的语音片段分别作为静态人脸生成模型的输入时,所生成的相应组合下的静态人脸图像。从中可以观察到,SDVF-GAN能够学习到声音和人脸之间的潜在联系,其生成的人脸图像和真实的人脸图像对应的属性信息(年龄,性别)是一致的。此外,我们还为每个组合选取多个不同的语音片段分别送入静态网络模型中来进行相应的实验,实验结果如图3所示,可以观察到SDVF-GAN在生成属性一致的静态人脸图像的同时还可以保持生成图像的多样性。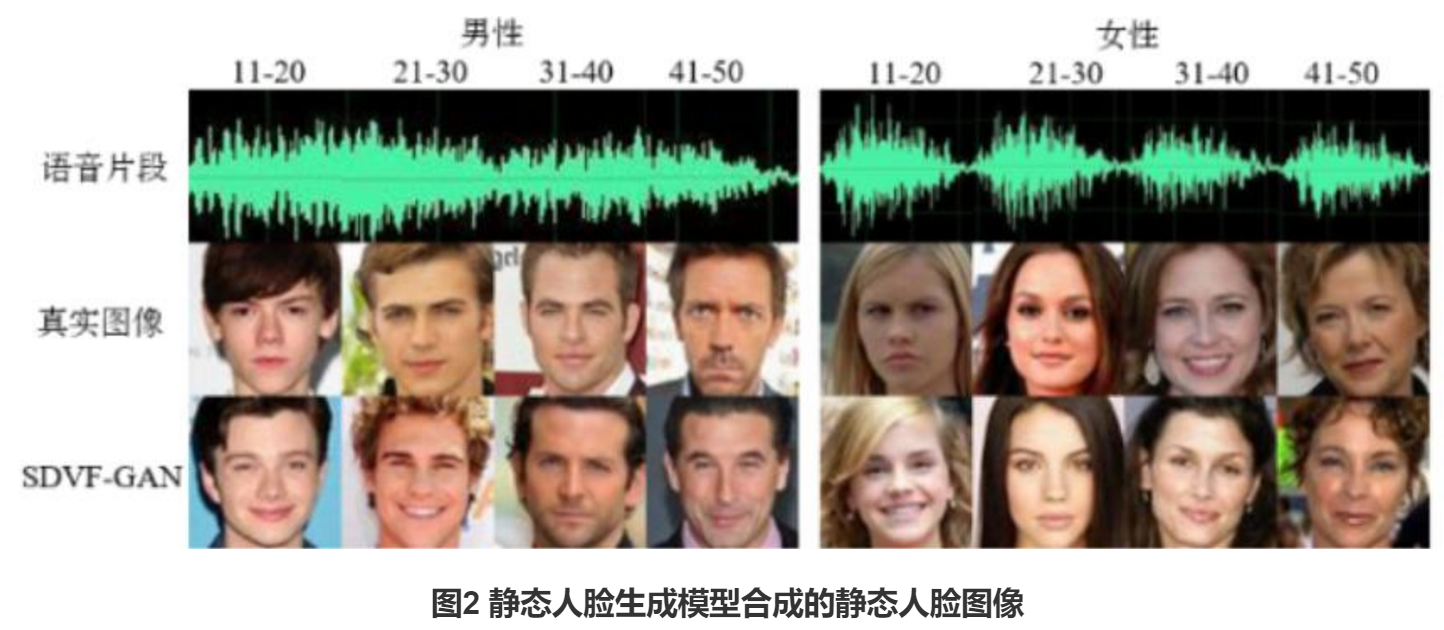

定量结果
我们使用Voice-Face数据集对Wen等人[7]提出的模型进行训练和测试(与别人的模型对比要用自己的数据重新训练),并将其与我们提出的静态人脸生成模型进行定量比较,具体实验结果如表4所示。结果显示SDVF-GAN在两个常用的评价指标下均明显优于Wen等人的方法,表明了SDVF-GAN模型不仅可以生成高质量的静态人脸图像,而且在8种属性组合下的跨模态分类准确率也相对更高。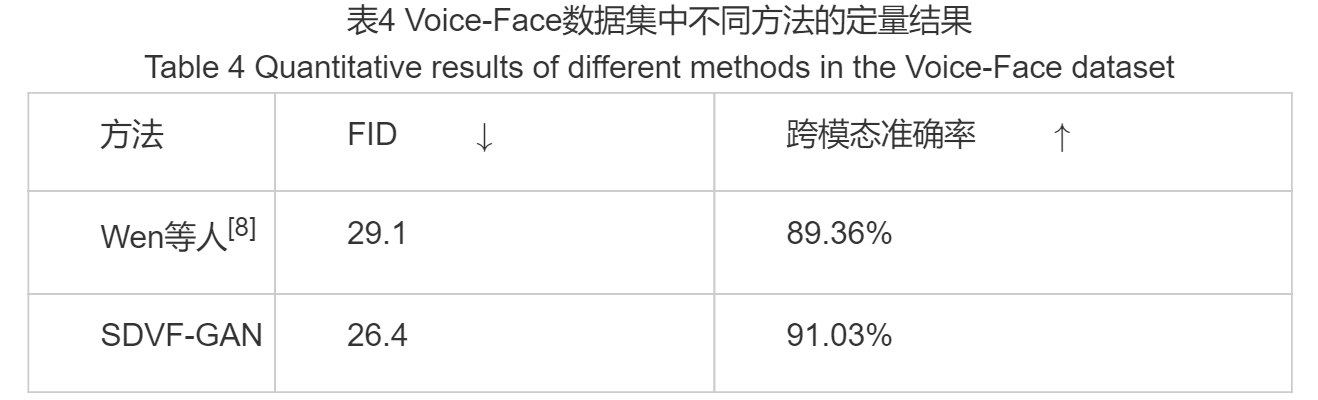
消融研究
为了定量评估静态人脸生成模型中各组成部分(自注意力机制(SA)、投影模块(Pro)以及属性损失LattLatt)对生成效果的影响,我们通过逐一移除模型中的某个组件来进行相应的消融研究实验,实验结果如表5所示。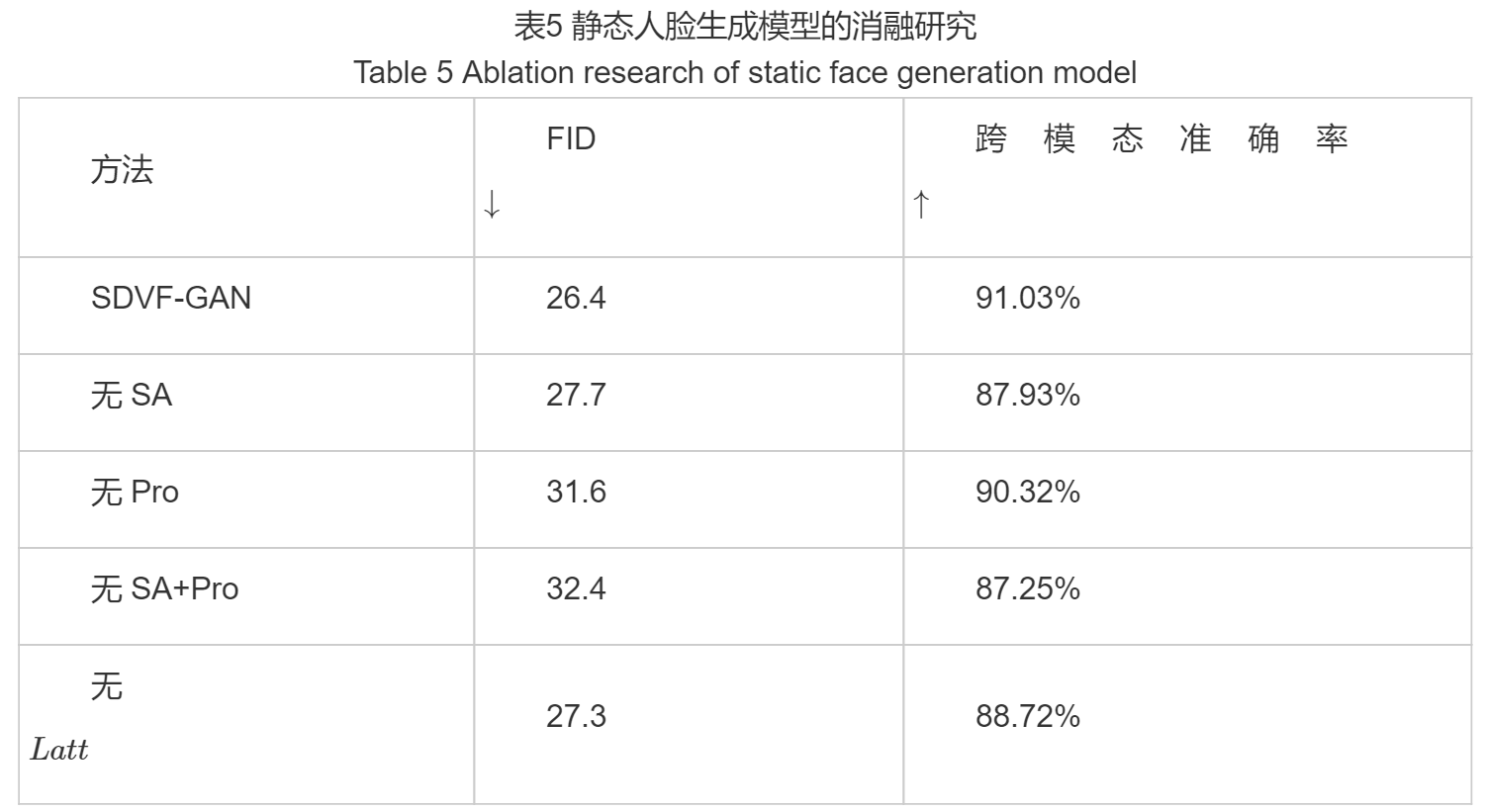
动态人脸生成
定性结果
为了验证本文所提出动态人脸生成模型的先进性,我们在相同的实验设定下,将其与ATVGnet模型进行定性对比,具体实验结果如图4所示。可以直观地看到,相较于ATVGnet模型来说,SDVF-GAN所生成的人脸序列与真实人脸序列在嘴唇运动方面的同步性更好,并且生成的人脸图像更加清晰。
定量结果
结果表明SDVF-GAN模型相比于其他的方法虽然在评价指标PSNR上略低于ATVGnet模型,但其同时取得了最高的SSIM和最低的LMD。这也定量说明了SDVF-GAN可以在保证生成较高质量图像的同时实现嘴唇运动与输入语音片段之间的精准同步。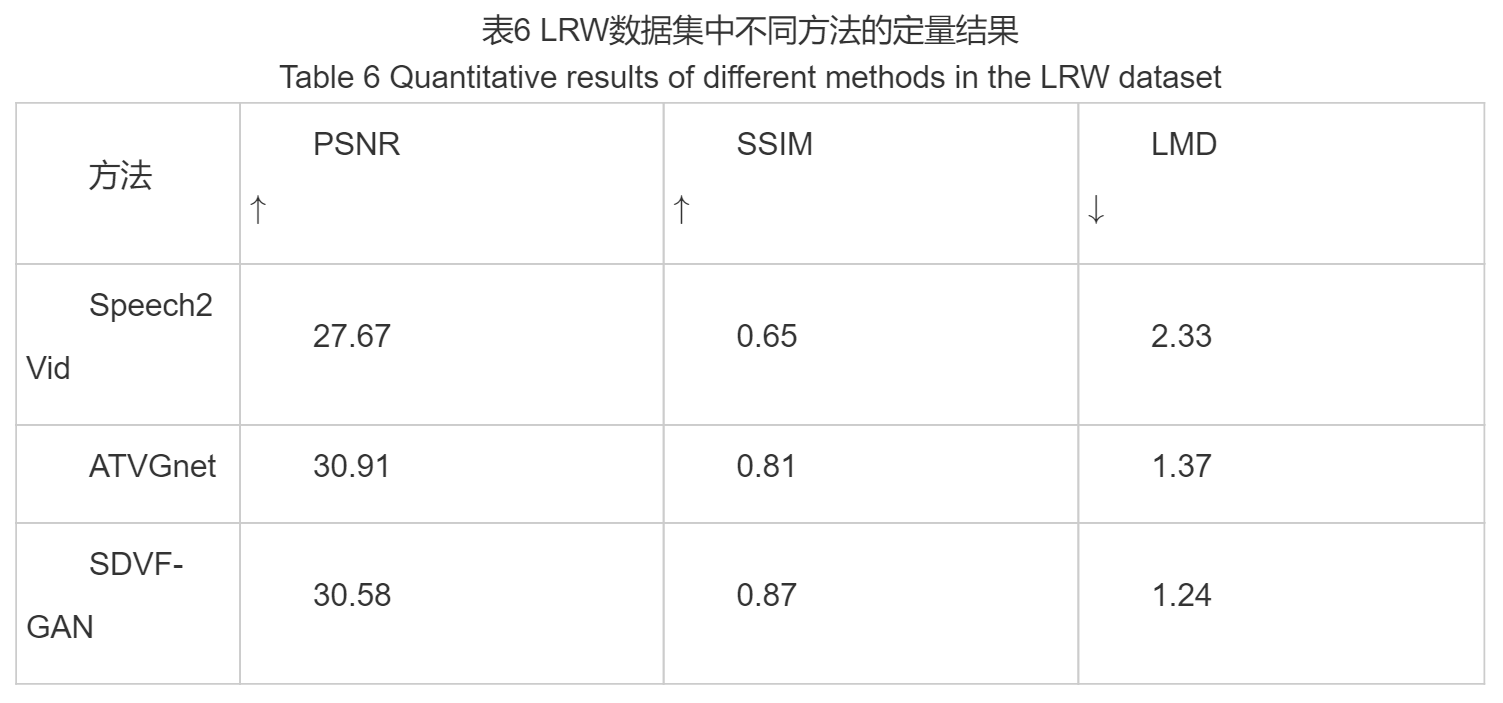
消融研究
验证自注意力机制(SA)和嘴唇判别器Dl对于模型性能提升的重要性,具体实验结果如表7所示。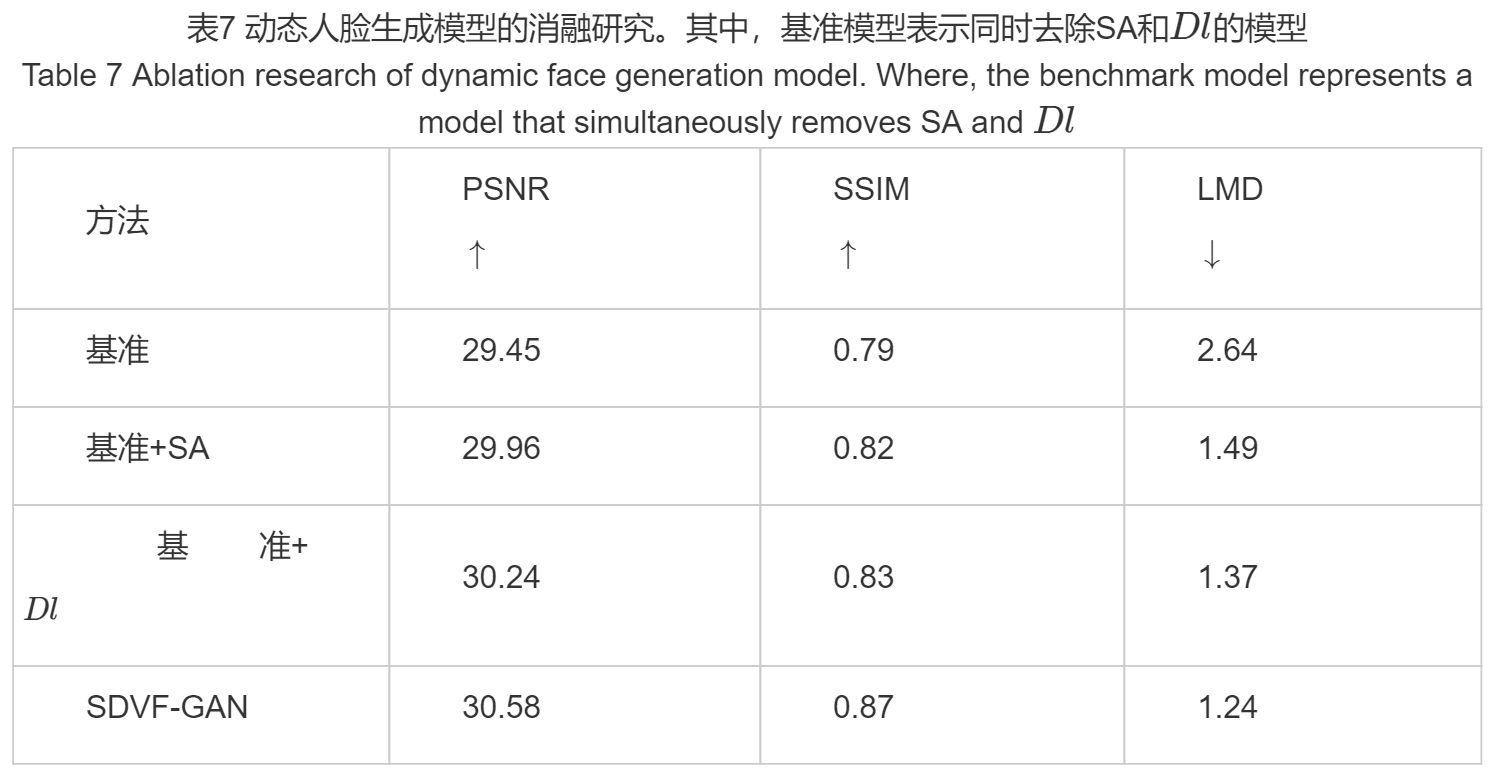
定性实验是什么?和定量实验的区别?
提出了一种可生成静态人脸图像和动态人脸序列的语音驱动人脸生成模型SDVF-GAN。
- 模型的语音编码器在自注意力机制的作用下捕获语音数据的全局听觉特征。
- 在静态人脸生成网络中通过将投影模块加入到图像判别器中以约束静态生成器生成出属性一致(性别,年龄)的静态人脸图像。
- 设计了一种基于自注意力机制(SA)的嘴唇判别器Dl,用于实现嘴唇区域与身份信息的分离。
- 将Voice-Face数据集按照性别和年龄段(11-20、21-30、31-40、41-50)组合成8种属性类别。(这一点应该能算吧,在论文结尾没提)
研究局限
对于训练静态人脸生成网络的Voice-Face数据集,本文只考虑了性别和年龄两种属性,使得属性组合相对较少。研究展望
未来的工作中可进一步添加人的情感属性,更深层次的挖掘语音和人脸的属性关系,提高静态人脸生成网络的应用范围。
未来可在动态人脸生成网络中实现生成的面部序列具有与输入语音同步的表情变化,从而获得更加逼真的视觉效果。

若有收获,就点个赞吧
0 人点赞
