Xinya Ji et al., “EAMM: One-Shot Emotional Talking Face via Audio-Based Emotion-Aware Motion Model” (arXiv, May 31, 2022), http://arxiv.org/abs/2205.15278.
代码 https://github.com/jixinya/EAMM/
在本文中,我们提出了情绪感知运动模型(EAMM),通过包含一个情绪源视频来生成一次性的情绪说话面孔。具体来说,我们首先提出了Audio2Facial Dynamics module,它从音频驱动的无监督零阶和一阶关键点运动中呈现会说话的人脸。然后通过探索运动模型的特性,我们进一步提出了 Implicit Emotion Displacement Learner,将与情绪相关的面部动力学表示为对先前获得的运动表征的线性加性位移。综合实验表明,通过结合这两个模块的结果,我们的方法可以在具有现实情绪模式的任意主体上产生令人满意的说话人脸结果。
需要四种输入,包括一个中性表达的身份源图像,一个语音源音频,一个预定义的姿势和一个情绪源视频。
我们的贡献总结如下: 1)我们提出了 Audio2Facial 动力学模块,它通过以一种简单的方式预测无监督的运动表征来生成中性的听觉驱动的说话人脸。2)基于两个经验观察,我们提出了隐式情绪位移学习者,它可以从情绪源中提取与面孔相关的表征的位移。3)我们提出的情绪感知运动模型(EAMM)成功地产生了具有情绪控制的一次性会说话的头部动画。据我们所知,这是这一领域最早的尝试之一。
方法
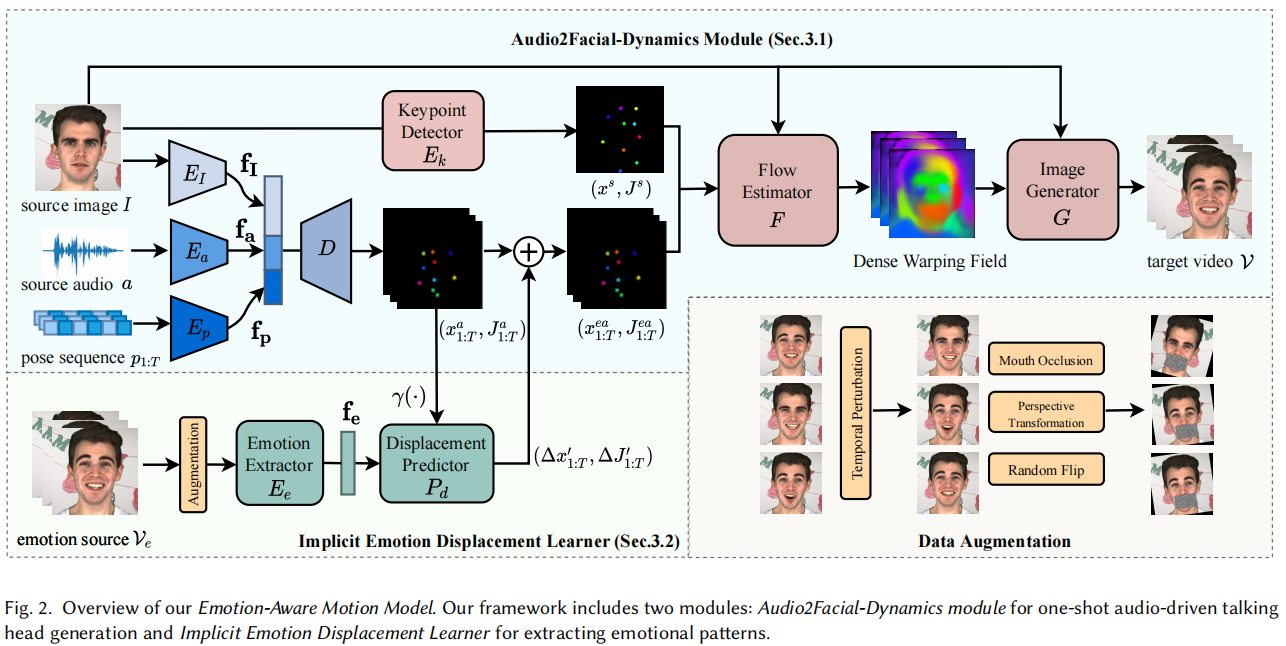
主要由2个模块构成:Audio2Facial-Dynamics module 和 Implicit Emotion Displacement Learner
3.1 Audio2Facial-Dynamics Module
向音频驱动的情绪说话面孔的第一步是建立一个整合表达动态的 one-shot 系统。为此,我们设计了Audio2面部动力学(A2FD)模块,它首先用中性表情来模拟面部运动。该运动被表示为一组无监督的关键点及其一阶动力学,其灵感来自[Siarohin et al. 2019b; Wang et al. 2021a]。基于这种运动表征,可以计算出翘曲场(warping fields)来解释局部的面部运动,从而进一步促进情绪说话面孔的生成。
Training Formulation
由于缺乏配对数据,无法进行直接监督,我们采用了自我监督训练策略[Chen等,2019b;Zhou等,2021]。对于每个训练视频剪辑V={𝑰1,…𝑰𝑡,…𝑰𝑇},我们随机选择一帧𝑰作为身份源图像,并以相应音频𝒂的Mel频率过滤系数(MFCC)𝒔1:𝑇作为语音源音频表示。考虑到头部姿势也是一个关键成分,很难从音频中推断出来,我们将由现成的工具从训练视频中估计的姿势序列 𝒑1:𝑇 作为额外的输入[Guo等人. 2020]。一个6维向量(即,3表示旋转,2表示平移,1表示刻度)被用来表示每一帧 𝒑𝑡 的头部姿态。请注意,在测试阶段,身份图像𝑰、语音源音频剪辑 𝒂 和姿态序列 𝒑1:𝑇 可以来自不同的来源。
Pipeline of A2FD
如图2所示,我们首先使用三个编码器(即𝑬𝐼、𝑬𝑎和𝑬𝑝)从三个输入中提取相应的信息,分别表示为身份特征f𝐼、音频特征f𝑎和姿态特征f𝑝。然后,我们将这三个提取的特征结合起来,并将它们输入一个基于LSTM的解码器𝑫,以递归地预测整个序列的无监督运动表示。运动表示在每个时间步𝑡由𝑁隐式学习关键点𝒙𝑡𝑎∈R𝑁×2及其一阶运动动力学,即雅各比亚𝑱𝑡𝑎∈R𝑁×2×2,其中每个雅各比矩阵表示局部仿射变换的附近区域在每个关键点(零阶表示)位置。我们在整个论文中默认设置了𝑁= 10。
为了推导与局部动力学相关的翘曲场,应该提供初始帧𝑰的标准定位零阶和一阶表示(the standard-positioned zero- and first-order representations)。我们认为,如果我们与预先训练的视频驱动的一阶运动模型共享我们的音频相关的关键点分布,将更容易学习[Siarohin等人2019b]。
因此,我们使用来自[Siarohin 2019b]的预训练的关键点检测器𝑬𝑘来从源图像𝑰中预测初始运动表示𝒙𝑠和𝑱𝑠。然后采用流估计器𝑭生成一个密集的翘曲场,描述从源图像到目标视频帧的非线性变换。具体来说,在每个时间步长𝑡中,我们首先根据预测的关键点𝒙𝑡𝑎,𝒙𝑠和雅各比矩阵𝑱𝑡𝑎,𝑱𝑠计算𝑁扭曲流以及一组掩模M。然后将掩模M与翘曲流进行加权,得到最终的致密翘曲场。最后,我们将密集的翘曲场与源图像𝑰一起输入图像生成器𝑮,以在每个时间步长𝑰^𝑡处产生最终的输出帧。详情请参阅[Siarohin et al. 2019b]。
Training Objectives
如前所述,我们想与基于视觉的模型分享运动表示的分布,我们利用𝑬𝑘作为一个特定的教师网络来进行基于音频的模型学习。其中,将𝑬𝑘从训练视频V中提取的关键点𝒙𝑡𝑣及其雅可比矩阵𝑱𝑡𝑣作为中间监督。然后,我们制定了一个在下面定义的关键点损失项𝐿𝑘𝑝来训练我们的A2FD模块: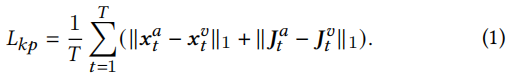
在第二阶段,我们使用感知损失项𝐿𝑝𝑒𝑟,通过最小化重建框架𝑰^𝒕和目标框架𝑰𝑡之间的差异来微调模型: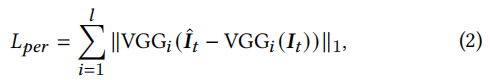
其中,VGG𝑖(·)是一个预先训练过的具有𝑙通道的VGG网络的𝑖𝑡ℎ信道特征[Johnson等人,2016]。总损失函数的定义为: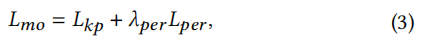
Discussion
在产生带有音频输入的中性谈话面孔之后,一个简单的想法是直接将情感来源融入到这个管道中。然而,情感来源自然包含了所有的面部信息,包括嘴、身份和姿势,导致不良的结果。因此,这就需要在我们的运动表征和扭曲场中分离情感信息。
我们首先探索翘曲场如何基于关键点𝒙变换源图像𝑰。我们可视化了图3中所示的组合掩模M,并观察到面部区域只受到三个关键点的影响。只有三个关键点的表示集被表示为(𝒙’,𝑱’)。
受此观察启发,我们做了一个简单的实验来验证我们是否可以通过编辑三个与面部相关的关键点及其雅可比矩阵,将情绪模式从情绪源视频转移到我们的A2FD模块。一个简单的想法是,找出同一个人的情绪和中性运动表征之间的偏差是否可以线性相加,也就是说,通过在其他人脸的运动表征上添加位移来施加情绪。为了减轻口腔的影响,我们利用了提取完整面部动态的预训练模型和我们产生中性说话面孔的A2FD模型。理想情况下,它们的嘴的形状应该在表示形式中对齐。
具体地说,我们首先从一个使用𝑬𝑘的情感源视频中检测到关键点𝒙𝑒‘和雅各比亚人𝑱𝑒’。然后,我们将它的音频和这个人的中性状态图像输入我们的A2FD模块,以生成𝒙𝑛‘和𝑱𝑛’。我们计算了偏差(𝒙𝑒‘−𝒙𝑛’,𝑱𝑒‘−𝑱𝑛’),假设该偏差包含情绪信息。通过简单地将这种偏差作为位移添加到任意一个人的运动表示上,我们观察到运动动力学可以在生成的结果上成功传输。因此,我们可以将这些表示法看作是大致线性相加的。
然而,虽然情绪信息可以被保存下来,但我们观察到在面部边界和口腔周围有许多不可取的人工制品。一种可能的解释是,计算出的位移不仅包括情绪信息,还包括其他因素,如身份、姿势和言语内容等,这导致对下一代的指导不准确。
3.2 Implicit Emotion Displacement Learner
根据以上观察,我们基本上可以将情绪模式表示为与面部相关的关键点和雅可比亚语的互补位移。因此,我们设计了一个隐式情绪置换学习者,从情绪视频V𝑒={𝑸1,…𝑸𝑡,…𝑸𝑇}中提取情绪信息,然后将其编码为A2FD模块的位移(Δ𝒙’,Δ𝑱’)到三个与面孔相关的关键点和雅各比语(𝒙’,𝑱’)。
Data Processing
为了将情绪从其他因素中分离出来,我们设计了一种特殊的数据增强策略。具体来说,为了屏蔽语音内容信息,我们使用一个充满随机噪声的面具来遮挡嘴唇和下巴的运动。此外,为了消除姿势和眨眼等自然运动的影响,我们引入了一种时间扰动技术。对于每个时间步长𝑡,我们不是使用帧𝑸𝑡来提取情绪,而是从不同时间步长的帧中选择一个帧。此外,为了进一步减轻人脸结构信息的影响,我们应用了视角变换和随机水平翻转[Zhou et al. 2021]。在图2中还展示了这种数据增强策略。
Learning Emotion Displacements
为了将情绪模式纳入我们的A2FD模块,我们首先使用情绪提取器𝑬𝑒从处理后的视频帧中提取情绪特征f𝑒。为了生成与输入音频同步的情绪动态,我们将A2FD模块预测的关键点𝒙1:𝑎𝑇及其雅各比矩阵𝑱𝑎1:𝑇和fe作为我们的位移预测器𝑷𝑑的输入。它使用4层多层感知器(MLP)来预测位移,称为Δ𝒙𝑎‘1:𝑇和Δ𝑱𝑎’1:𝑇。请注意,一个位置编码操作[Mildenhall et al. 2020]是将关键点投影到高维空间,使模型能够捕获更高的频率细节。最后,我们通过线性地将Δ𝒙𝑎‘1:𝑇和Δ𝑱𝑎’1:𝑇线性地添加到音频学习表示𝒙𝑎‘1:𝑇,𝑱𝑎’1:𝑇上,来生成𝑁情感音频学习关键点𝒙𝑒𝑎1:𝑇和雅各比亚语𝑱1:𝑒𝑎𝑇。
Training Objectives
在训练过程中,我们遵循Sec 3.1 中的自我监督训练策略。具体来说,对于每个情绪源视频V𝑒,我们使用预先训练的检测器𝑬𝑘提取𝑁关键点𝒙𝑒1:𝑇和雅各比亚𝑱𝑒1:𝑇地面真相,然后我们最小化的区别情感音频学习关键点𝒙𝑒𝑎1:𝑇,雅各比亚𝑱1:𝑒𝑎𝑇和地面真相通过重新制定损失项𝐿𝑘𝑝: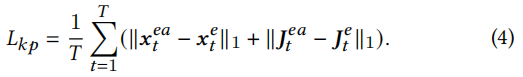
读后
关于翘曲场、零阶一阶表示,去看 这篇论文,关于表情迁移的。
Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019b. First order motion model for image animation. _Advances in Neural Information Processing Systems _32 (2019), 7137–7147
主页 https://aliaksandrsiarohin.github.io/first-order-model-website/

若有收获,就点个赞吧
0 人点赞
