Wang 等。 - 2021 - AnyoneNet Synchronized Speech and Talking Head Ge.pdf
Demo:AnyoneNet - YouTube
声音合成听起来还挺好,的确和脸对应着看不违和,但视频的人脸效果看着有点假。
主要看看它的创新点吧,毕竟能发论文。
粗读
研究问题
输入:文本和脸部图片。
合成声音和说话视频。合成的声音不是特定人的,而是任意人。
研究背景
研究方法
分为2个阶段:
研究结论
- 由于地标的低维性抑制了细节,可能导致地标与真实感人脸图像语义不匹配。端到端方法在生成更准确的唇动方面有明显的优势。
但是地标在呈现头部姿态方面表现出优势,使得所提方法能够自动预测头部姿态。
创新点
音色和输入图片的人脸对应,当然不是说合成图片中人的真实音色,而是生成的声音与人脸相对和谐自然。对任何人都work。
-
研究局限
预测姿态较小。因为言语和姿态没有明显的关联。
即使是用 ground-truth landmarks,生成的唇形也有些不对。
研究展望
可以考虑使用生成对抗学习策略来预测看似自然的随机头部运动。
使用由地标提供的头姿信息可以考虑在端到端方法中预测头姿,而不是使用参考视频中的头姿。
主要方法
主要看脸部生成。
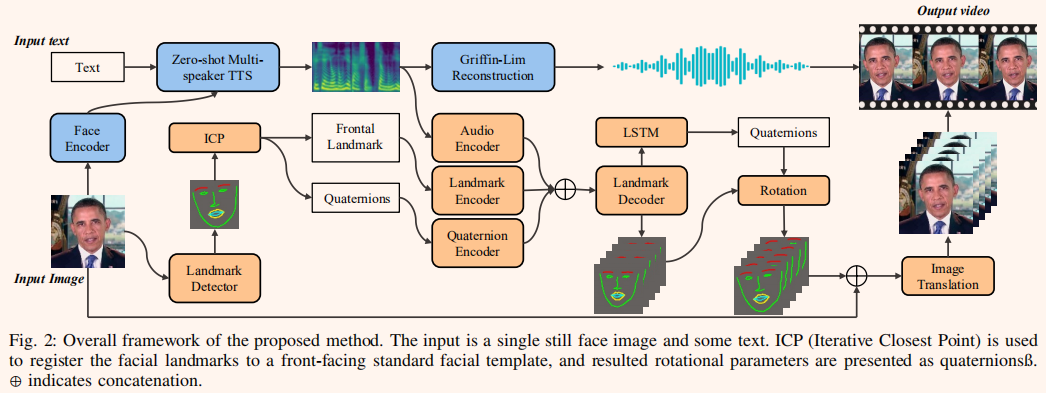
ICP (Iterative nearest Point,迭代最近点),用于将面部地标注册到一个面向前方的标准面部模板上,得到的旋转参数以四元数ß表示。
As shown in Fig. 2, Mel-spectorgrams, the frontal facial landmarks, and quaternions are encoded by the audio encoder, landmark encoder, and quaternion encoder, respectively. Outputs from these three encoders are concatenated to work as input to the landmark decoder that generates the new landmarks.others
The state-of-the-art landmark-based method [9] 是本文的对比模型。
[9] Y. Zhou, X. Han, E. Shechtman, J. Echevarria, E. Kalogerakis, and D. Li, “Makelttalk: speaker-aware talking-head animation,” ACM Transactions on Graphics (TOG), vol. 39, no. 6, pp. 1–15, 2020
[

若有收获,就点个赞吧
0 人点赞
