Chen 等。 - 2020 -What comprises a good talking-head video generation?: A Survey and Benchmark
挑战:
- 视角、头部运动、表情等特征十分复杂,除了对面部区域建模,还需要对头部运动和背景建模;
- 如何明确地利用参考视频中的视觉信息;
- 如何避免合成视频中的伪影和身份变化。
定性评估 qualitative evaluation 常常求助于人工检查 manual inspection生成图像的视觉保真度 visual fidelity。
定量指标 quantitative metrics 可能无法清楚地说明在哪些场景中分数是有意义的,以及在哪些场景中容易产生误解,因为它们可能与人类如何感知和判断生成的视频帧不直接对应。
本文的目的是全面研究现有的关于说话头生成模型定量测量的文献,帮助研究者客观地评估它们。
通过定量评估,我们希望回答以下问题:
- 当前评估指标的优势和局限性是什么?
- 应该选择哪个指标,或者是否可以引入更好的评价指标来评价话头视频生成方法?
- 指标对不同的测试协议是健壮的吗?
一个好的合成说话头视频应该具备的四个特性,以及评估的方法:
- 保持被试的原始身份,select cosine similarity between embedding vectors of ArcFace (Deng et al. 2019) to measure identity mismatch.
- 在语义水平上保持对口型同步,we critically discuss existing lip-sync evaluation methods and introduce a new lip-sync metric—lipreading Similarity Distance(LRSD).
- 保持高视觉质量,We use SSIM and FID to evaluate visual quality at an image-level since they are sensitive to image distortions and transformations. And we use CPBD to judge the sharpness of the synthesized video. 当我们用定量指标(如SSIM、FID)评价一个说话头生成方法时,我们应该考虑测试集的头姿、头部运动的分布;
- 自然的自发动作,包括情绪表达、眨眼和头部运动。we design Emotion Similarity Distance (ESD) to evaluate the facial emotional expression distance between the synthesized video and the ground truth. To quantitatively evaluate the subconscious blinks, we introduce a learning-based metric—Blink Similarity Distance (BSD) to evaluate the quality of the blink motion in the eye region of a synthesized video.
本文贡献:
- 提出3个新的评价指标 LRSD, ESD, and BSD.
- 在一系列实验中有一些有趣的发现。
- 构建了一个代码库,包含了我们调查的关于说话头生成的技术,包括图像填充、少量镜头生成器、基于注意力的嵌入和3D图形模块。该代码库提供了统一的结构,使其更容易对不同的话头视频生成进行基准测试,还有利于其他视频动态生成任务,如视频重定向(Chan et al. 2019)、位姿引导的人体图像生成(Siarohin et al. 2019a)和视频预测(Liu et al. 2018;Minderer等人2019年)。
Sec2. talking-head generation的组成
1. 身份保留
- skip connections
- skip connections在合成图像特征和参考图像特征之间提供了一条高速通道,可以减少身份编码和图像解码阶段的身份信息丢失。
- 缺点:这种跳过连接结构对人们应用到它的哪个层很敏感。如果过早或过晚使用跳过连接,可能会降低网络性能。
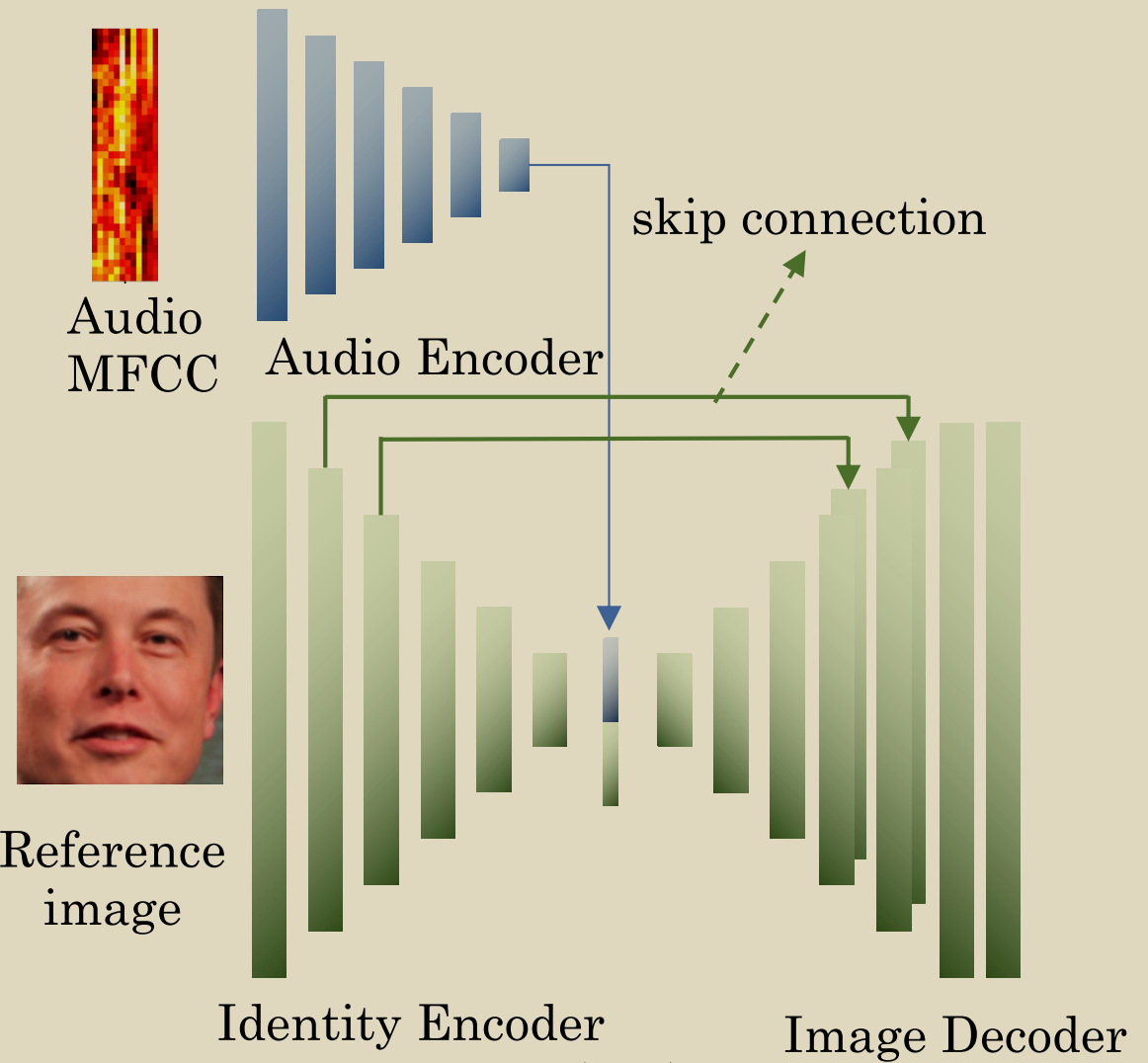
- 多帧参考
- 多幅参考图像增强了整体外观特征,减少了非音频相关运动引起的微小变化。
- 缺点:拼接操作需要将对齐的面部图像作为输入,因为它忽略了头部的运动。
为了生成带有头部运动的talking-head,Wiles等人(2018)提出了一个嵌入网络,用于在不同的参考帧中聚合具有不同姿势和表情的共享表示。然后设计一个驱动网络来从嵌入的公共表示中采样像素以生成一个生成的帧。提出的嵌入网络提供了一种新颖的映射机制和类似记忆网络的结构来提取外观特征。
- few-shot embedding structure
- 与 non-few-shot 方法相比,其生成器的网络参数收敛速度快得多,可以更快地生成真实、个性化的图像。
例如,Zakharov等人(2019)在生成器中嵌入参考图像来预测自适应实例归一化(AdaIN)层的参数。 同样,Wang et al.(2019)预测了生成器的网络参数(Park et al. 2019提出的空间自适应归一化块的比例尺和偏倚图)。
2. 视觉质量
相邻帧过渡要平滑,人眼对像素抖动十分敏感。
对时间依赖进行建模,以实现更平滑的面部跨越时间的过渡。
Song et al.(2018)提出了在生成阶段考虑时间依赖性的循环生成器和在识别阶段在视频级别判断合成视频的时空判别器。 类似地,Vougioukas等人(2019)提出了一种由时空卷积和gru组成的序列判别器,用于提取瞬态特征,判断序列是否真实。
image matting function,也能提升时间相关性。
- 公式
 ,_where I_r, A and C are the input reference image, attention map(obtained by applying Sigmoid activation function) and color mask(obtained by applying Tanh activation function).
,_where I_r, A and C are the input reference image, attention map(obtained by applying Sigmoid activation function) and color mask(obtained by applying Tanh activation function). - 通过在生成器中应用该抠图函数,来自参考图像的重用像素可以部分地稳定视频质量。
- 缺点:如果由于头部运动引起的大变形导致参考帧 Ir 与目标帧 I 之间出现错位,则attention map可能不能很好地发挥作用,甚至会引入伪影。我们将这一问题归因于线性图像抠图函数在解决 Ir 和 I 之间的失调时,其合成能力较差。

- 为了最小化偏差,Wang等人(2018a)提出了一个序列生成模型,不使用 Ir,而使用前一帧生成的同步帧
 。所以公式被改为
。所以公式被改为  ,where ˜w is the estimated optic flow from ˆIt-1 to It
,where ˜w is the estimated optic flow from ˆIt-1 to It - 通过在合成的前一帧上应用mage matting function,可以缓解错位问题。然而,估计的光流可能无法处理面部区域的小偏差,这是导致帧间抖动伪影的主要因素。同时,当光流估计不准确时,翘曲操作可能会引入额外的伪影。
基于gan的方法中引入了3D图形建模,因为3D图形建模有稳定性。三维图形建模的先验纹理信息可以简化生成器的训练,提高时间相干性。
3. 唇同步
列举了3篇论文:
Chen L, (2018) Lip movements generation at a glance.
Chen et al.(2018)提出了 视觉特征(光流)的导数和音频特征的导数之间的 相关损失来解决假唱(lip-sync)问题。但是,这种方法需要固定长度的音频输入,并且只能生成固定长度的图像帧。
- Song Y, (2018) Talking face generation by conditional recurrent adversarial network.
为了连续生成图像,Song等人(2018)提出了一个有条件的递推对抗网络,将图像和音频合并到递推单元中,以实现生成的视频对面部和嘴唇运动的时间依赖性,并进一步生成对唇同步的视频帧。此外,他们还设计了一个唇读鉴别器来提高唇同步的准确性。
- Vougioukas K, (2019) Realistic speech-driven facial animation with gans.
类似地,Vougioukas等人(2019)提出在原始视频和音频的定长片段上使用同步鉴别器来确定它们是否同步。该鉴别器使用双流结构计算音频和视频的嵌入,然后计算两个嵌入之间的欧氏距离。
4. Natural spontaneous Motions
列举一系列论文:
- 忽视自发运动的模型,导致结果中除了唇部的其他区域都是几乎静止的。
- 为了对情绪表达进行建模,Jia等人(2014)使用神经网络学习从情绪状态(愉悦-不愉快、唤醒-非唤醒和支配-顺从)参数到面部表情的映射。
- Karras et al.(2017)提出了一种通过从音频信号和情绪状态推断信息来合成三维顶点的网络。
- Vougioukas等人(2019)提出了一种能够通过单层GRU产生时间相干噪声的噪声生成器。这种潜在的表征在脸部合成过程中引入了随机性,并有助于眨眼和眉毛运动的产生。
- 一些作品(Yi et al. 2020;Thies等人2016;Kim等人2018;Averbuch et al. 2017;Zhang等人2019b)将包含目标运动的图像帧作为dense mapping来指导视频生成,生成带有卷积头部运动和面部表情的视频帧。
Sec3. 数据集
本节总结了最近发布的与语音相关的视听数据集的属性,从实验室控制数据到野外环境数据(表1和图3),并选择一些有代表性的数据(表2)作为第4节的基准数据集。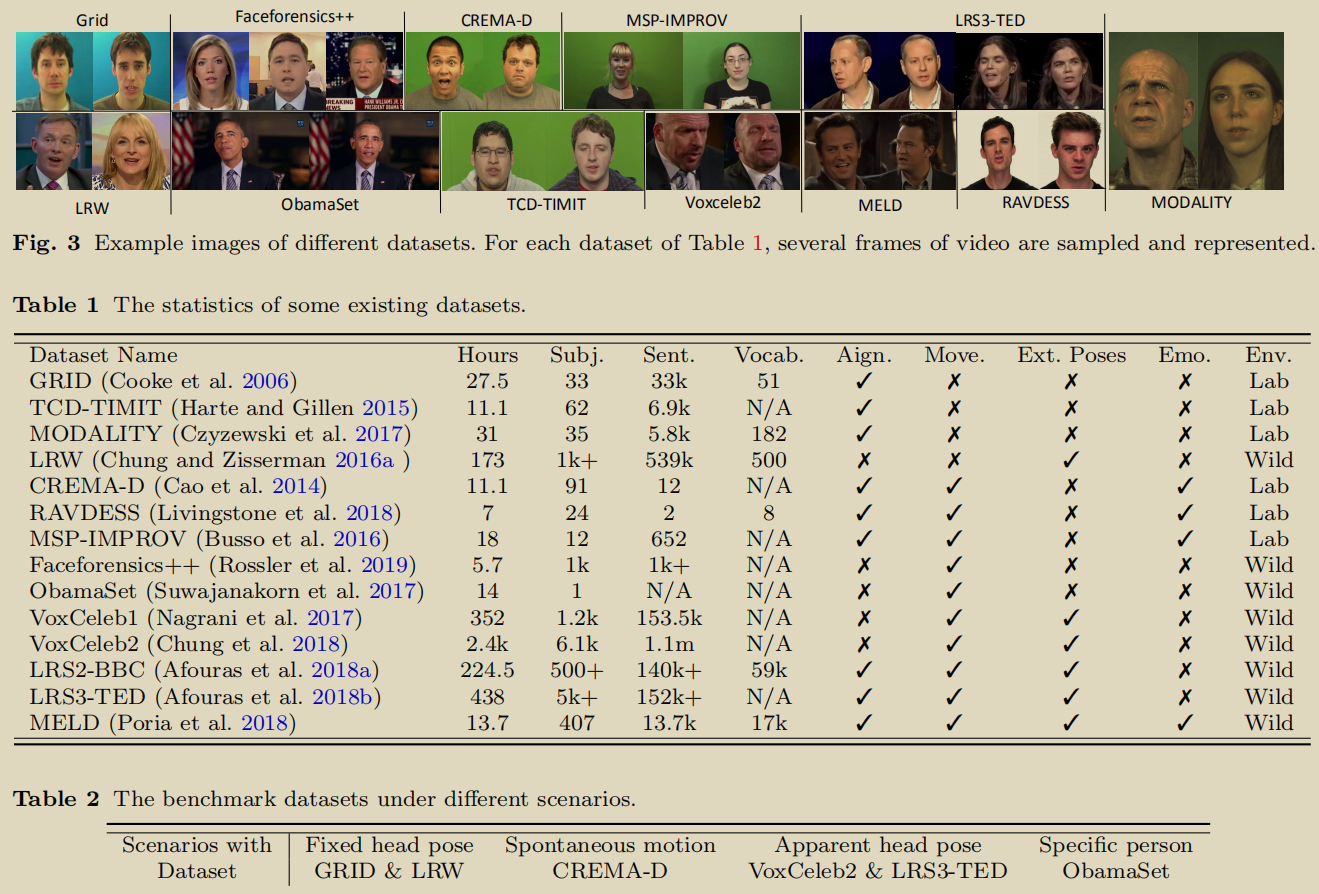
表1列出了许多现有的数据集,我们选择了6个数据集作为我们的基准数据集,这些数据集可以分为4类(表2),但是这些数据集没有经过校准,我们定义了一个统一数据集的pipeline。Sec4. 评价标准
分别介绍了对于4项标准(身份保持,视觉质量,嘴唇同步,自然自发的运动)的现有指标。如果现有指标不能对标准进行评价,作者提出了新的评价方法。Sec5. Results

若有收获,就点个赞吧
0 人点赞
