👍Vougioukas_2020_speech-driven-animation
官方网址 https://sites.google.com/view/facial-animation#h.p_10ig0Cz7wHpx
代码 https://github.com/DinoMan/speech-driven-animation
提出了一个端到端人脸合成模型,能够使用静态图像和语音产生真实的人脸说话序列。生成的序列表现出流畅和自然的表情,比如眨眼和皱眉。
模型
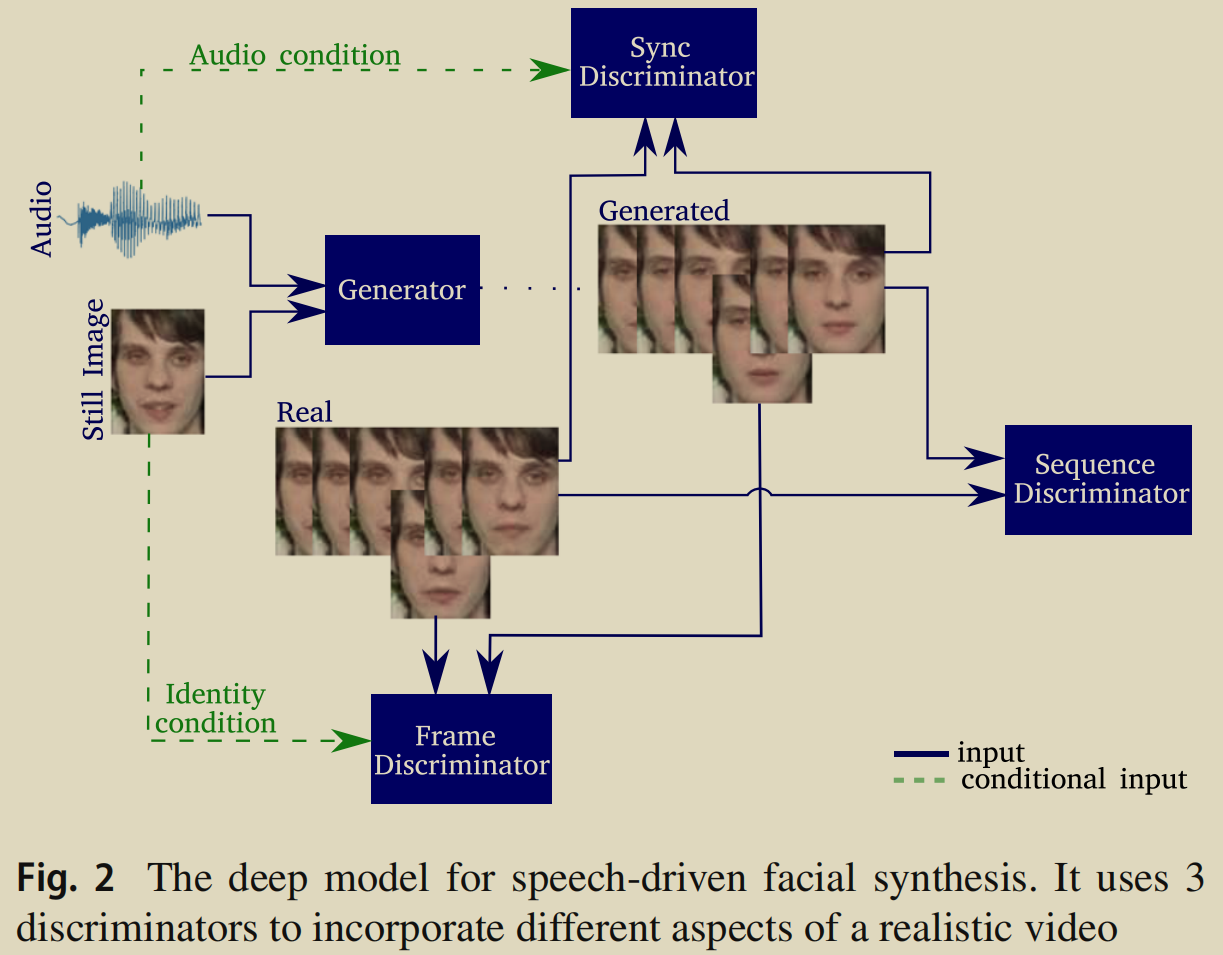
生成器
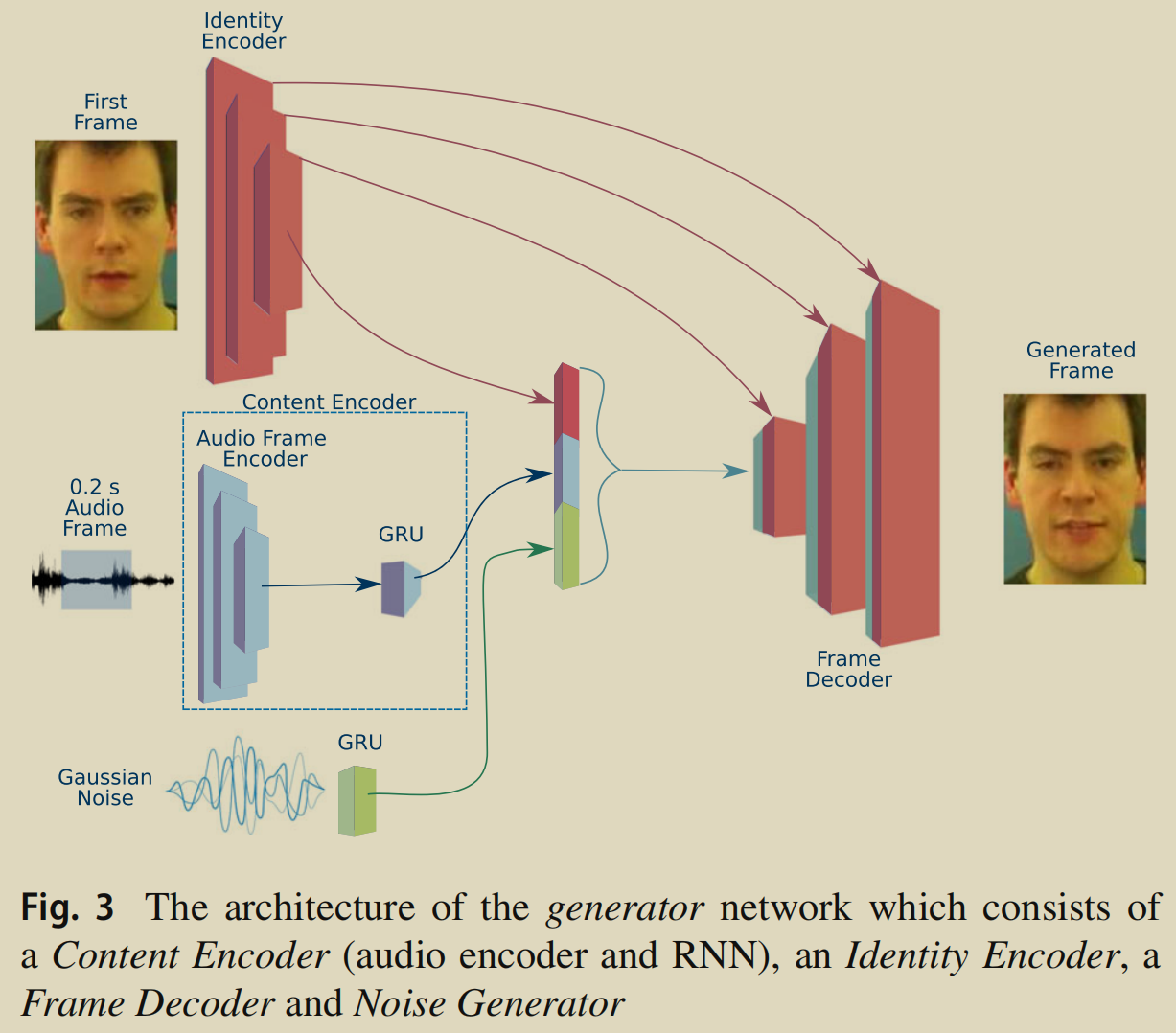
生成器网络的组成:2 encoder + 1 decoder + 1 generator
- 身份 编码器
- 6-layer CNN,每层使用 strided 2D 卷积 + batch norm + ReLU
- 将96*128的输入 reduce 到128维的 encoding 向量。
内容 编码器(音频编码器和RNN)
- 每段音频固定为0.2s。
- 1D 卷积 + batch norm + ReLU
- 编码后输入到 1-layer GRU,生成 256维的 content encoding z**c** 。
The audio frame encoding is input into a 1- layer GRU, which produces a content encoding zc with 256 elements
噪声
- 用来生成自发的面部表示,比如眨眼和眉毛运动。
- 从均值为0、方差为0.6的高斯分布中采样10维向量,并通过单层GRU,以生成噪声序列。
帧 解码器
Frame Discriminator, achieves a high-quality reconstruction of the speakers’ face throughout the video.
- 6-layer CNN,判断帧的真实性。
- 原始的静止帧作为一个条件,以通道方式连接(concatenated channel-wise)到目标帧上,用来保持身份。
- Sequence Discriminator, ensures that the frames form a cohesive video which exhibits natural movements.
- 判别是真实视频还是合成视频。
- 在每一个时间步,鉴别器将使用一个带有时空卷积(spatio-temporal convolutions)的CNN来提取瞬态特征,然后传入 1-layer GRU,最后使用单层分类器确定序列是否为真实序列。
- Synchronization Discriminator, reinforces the requirement for audio-visual synchronization.
- 将帧序列和音频分别 encode 成 256维的 embedding 之后,计算它俩之间的欧式距离,然后传入单层感知机做分类,判断同步还是不同步。
- 为了驱使鉴别器基于同步来判断序列,还训练了从真实视频中获取的不对齐的音视频对。如果只输入真假音频视频对,鉴别器不一定是根据它们的同步程度来判断。
- 由于脸部上半部分的运动不影响视听同步,我们选择只使用脸部下半部分来训练同步鉴别器。


若有收获,就点个赞吧
0 人点赞
