Xinya Ji et al., “Audio-Driven Emotional Video Portraits,” CVPR, May 19, 2021, http://arxiv.org/abs/2104.07452. code
主页 https://jixinya.github.io/projects/evp/
- 从音频中分别提取出情绪和content,使二者解耦合,并交叉连接作为训练数据。
- 通过缩小推理视频和目标视频的 landmark 来生成高质量的视频。
- 从音频获取landmark,使用3D模型进行姿态对齐。
解决什么问题
此前的 audio-driven talking heads 生成忽略了情绪表达。本文研究了具有生动情绪的高质量视频 audio-driven talking heads 生成。
贡献点
- 提出Emotional Video Portraits (EVP)系统,这是首次尝试在基于视频编辑的说话人脸生成方法中实现情绪控制。
- 提出交叉重构情感解纠缠技术(Cross-Reconstructed Emotion Disentanglement technique),提取与内容无关的情感特征,以实现自由控制。
- 提出目标自适应人脸合成(Target-Adaptive Face Synthesis),使生成的人脸适应目标视频,具有自然的头部姿态和运动,从而合成高质量的人像。
数据集:MEAD(使用LRW预训练了编码器)
具体方法
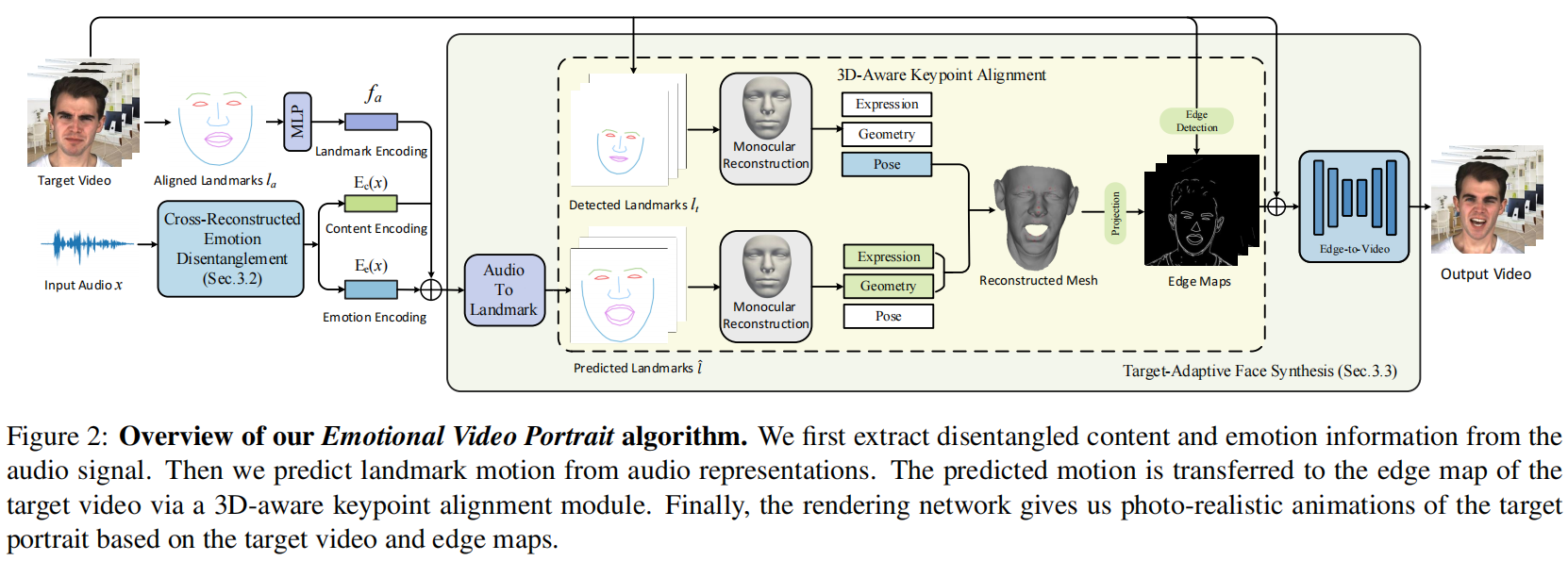
1. Cross-Reconstructed Emotion Disentanglement
从音频信号中提取分离的内容和情感信息。
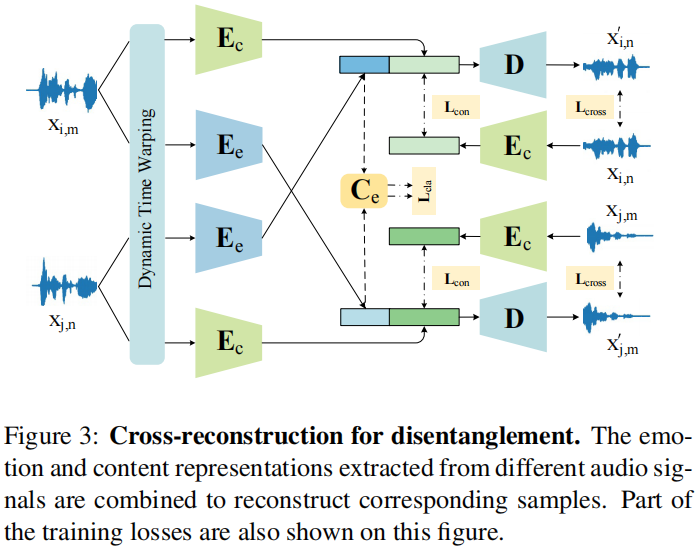
We use a temporal alignment algorithm, Dynamic Time Warping [3] to produce pseudo training pairs, and then design a Cross-Reconstructed Loss for learning the disentanglement.
- temporal alignment 时长对齐:使用MFCC[26]作为音频表示,并使用 Dynamic Timing Warping(DTW)[3] 算法沿时间维度拉伸或收缩MFCC特征向量,生成 pseudo training pairs。
这么做的原因:为了实现交叉重构训练,需要提供相同长度、相同内容、不同情绪的配对句子。内容相同但情感不同的演讲在 speech rate 上存在差异。
- Cross-Reconstructed Training 交叉训练:结构如下图所示。2个encoder Ee 和 Ec,分别提取 emotion 和 content特征。直觉地,将情绪和内容解耦后,我们可以把2个音频的情绪交换,行成新的音频样本 emotion-content pair。
比如对于样本xi,m, xj,n,i 和 j 表示content,m 和 n 表示 emotion,可以生成新样本xj,m, xi,n。
【Since each sample can only provide one type of information that is beneficial to the cross-reconstruction, the disentanglement can be finally achieved. 】?不理解这个因果关系。
2. Target-Adaptive Face Synthesis
合成目标人脸,即从音频表示中预测 landmark motion 并贴合到视频中的目标人物。
首先使用 multi-layer perceptron (MLP) 从解耦合的音频特征中提取 landmark identity embedding fa。然后 fa和Ee、Ec一起传入audio-to-landmark module。
- Audio-to-Landmark Module. following [34,9],输入
fa,通过 LSTM+2层MLP 预测 landmark displacementsld。
这一步存在2个挑战:1)预测人脸关键点的头部运动可能与目标视频存在严重差异,因为音频中几乎没有提供任何姿势信息。2)在合成高保真度结果时,编辑后的人脸与目标视频的融合比较困难。所以本文提出3D关键点对齐算法如下。
- 3D-Aware Keypoint Alignment,使 landmark 能够适应目标视频中的各种姿态和运动,从而将预测的运动转移到目标视频的边缘检测图像(Edge Map)。
使用[43]的方法对目标视频进行 landmark detection,然后利用模型[5]从2D landmark 获得3D人脸参数。利用这3D参数可以获得姿态参数,包含旋转矩阵R、平移系数 t 和缩放系数s。通过将目标视频的关键点替换为预测人脸关键点的位姿参数(R, t, s),可得到自适应的三维关键点,并将其投影到图像平面上。
注意,使用3D模型只是为了姿态对齐。
- Edge-to-Video Translation Network. ?
输入对齐的 landmark 和目标视频,将 landmark 和目标帧的边缘检测图像 merge into a guidance map for portrait generation。边缘检测算法来自[16]。将目标帧的 landmark 替换为上一步对齐得到的landmark,然后连接相邻的 landmark以create a face sketch。
参考[39], 采用 conditional-GAN 结构作为 Edge-to-Video translation network,输出视频。
目标函数
Cross-Reconstructed Training
训练交叉重构时,使用了4个loss。对于 four audio samples xi,m, xj,n, xj,m, xi,n ,前2个是原始样本,后2个是交叉样本。
- cross reconstruction loss, 对原始和交叉重构的样本
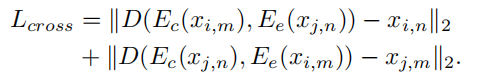
- self reconstruction loss, 对原始样本
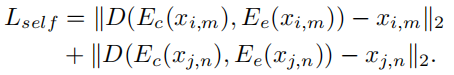
- classification loss, 鼓励 emotion Encoder 将相同情绪的样本映射到潜在空间的同一集群中
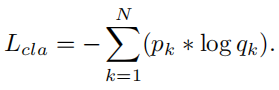
- content loss, 限制具有相同文本的音频具有相似的content embedding
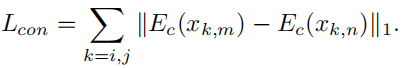
总的损失函数是 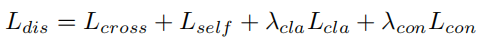
Audio-to-Landmark Module
最小化参考帧的 landmark  和预测的 landmark
和预测的 landmark  之间的距离:
之间的距离: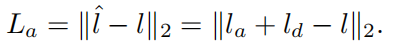
实验
评价指标
评价指标:M-LD ↓ ,_M-LVD ↓ , F-LD ↓ , F-LVD ↓ , SSIM ↑ , PSNR ↑ , FID ↓。_
- 评估面部运动,使用 Landmark Distance(LD) 和 Landmark Velocity Difference(LVD)[9,47]。LD表示生成的和真实的人脸关键点之间的平均欧几里得距离。速度(Velocity)表示连续帧之间的人脸关键点位置差,所以LVD表示两个序列之间人脸关键点运动的平均速度差。我们分别在嘴部和面部区域采用LD和LVD来评估合成视频对嘴唇运动和面部表情的准确表现。
- 评价生成图像的质量,使用SSIM[41]、PSNR和FID[17]。
Experimental Results
与三个工作[9,32,37]进行比较。[9]基于图像,也利用人脸关键点进行面部动作合成,并采用注意机制来提高生成质量。[32]基于视频,利用3D人脸模型实现视频人像合成。[37]是第一个提出具有情绪的说话人脸生成方法。
Qualitative Comparisons:[9, 32]生成的口型可信,但他们没有考虑情绪。[37]考虑了情绪但有的口型与情绪不符(高兴情绪嘴角向下),且会出现一些奇怪的变化,比如发型的变化。举例3个视频片段。
Quantitative Comparisons:使用上述评价指标,如表1所示,本文提出的方法在音视频同步(M-LD, M-LVD)、面部表情(F-LD, F-LVD)和视频质量(SSIM, PSNR, FID)方面明显优于另外3个方法。
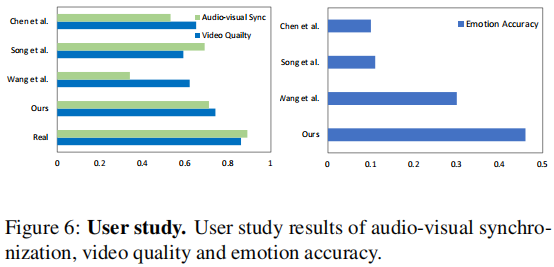
User Study:3个不同的人,8种情绪,每人每个情绪生成3个视频,共生成72个视频片段。评价标准:1) 合成的说话面部视频是否真实,2) 面部运动是否与说话同步,3) 生成的面部表情的准确性。
前2个问题是打分制,从1(最差)到5(最好)打分。第三个问题是选择情感类别。有50名参与者。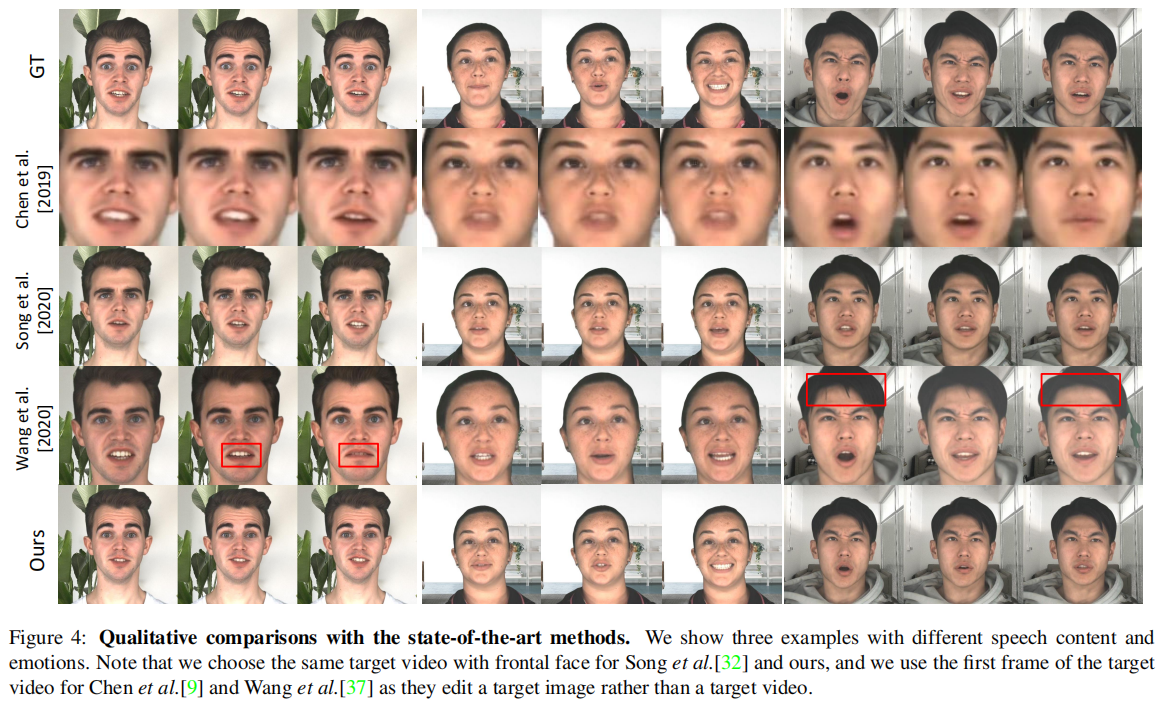

Disentanglement Analysis
- 验证 content 和 emotion 解耦合的有效性:向内容编码器和情感编码器提供不同的音频输入,生成的嘴部运动与输入到内容编码器的音频相一致,而面部表情与情感编码器音频的情感相匹配。
- 验证情绪:使用 MEAD 数据集训练情绪分类网络[28],然后用它计算情绪分类的准确率。首先对数据集进行了情绪识别,准确率90%,本方法生成的视频准确率83%,[37]的准确率76%。可以表明本方法能很好地保持情绪。
- 编辑情绪:通过调整源情绪Es和目标情绪Et之间的权重α,得到以线性插值情感特征为条件的图像序列:αEs+(1-α)Et。我们可以发现帧与帧之间的情感转换是一致且平滑的,这意味着能够通过语音特征连续编辑情感。
Ablation Study
- Cross-Reconstructed Emotion Disentanglement:
- 比较有交叉重构的网络和没有交叉重构的网络所得到的情绪潜在空间,可以看出交叉重构使情绪更聚集,表明交叉重建确实有助于从音频中分离情感信息。
- 比较最终合成的视频片段的情感分类准确率,没有重建模块的准确率为69.79%,低于有重建部分的结果(83.58%)。
- 验证了本模块使用的四个loss函数都有起作用。4个loss都用上,评价指标达到最优。
- Target-Adaptive Face Synthesis:3D人脸关键点对齐能够使头部运动与目标人像视频一致,从而生成流畅、逼真的帧。另一方面,不使用三维对齐,从边缘图和结果帧可以看到轮廓的偏移和伪影。



若有收获,就点个赞吧
0 人点赞
