01. 豆瓣影评获取
1.1 获取电影数据
1.1.1 获取电影数据的URL
- 要获取电影数据可以先访问豆瓣电影官网:https://movie.douban.com/,为了减少一点数据量可以点击热门,然后点击更多按钮查看全部热门电影。
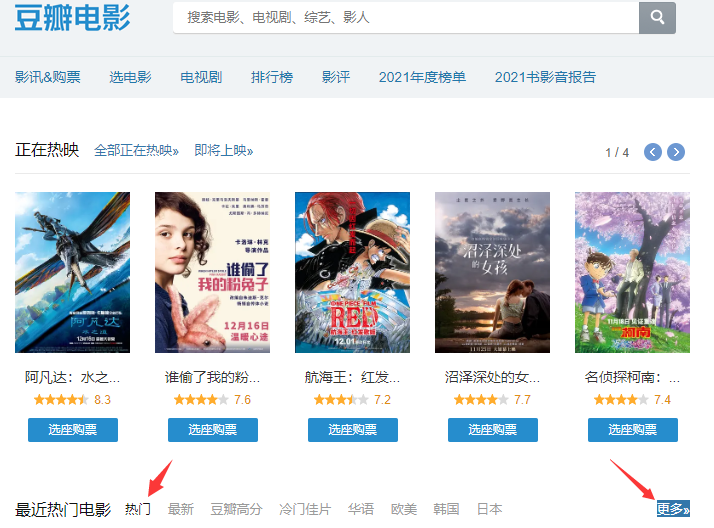
- 在新接口中,默认显示的电影数量有点少,而勾选可播放后就可以获取比较多的数据。
- 由此可以推断出,这些电影数据不是一开始就在页面中的,而是当点击某些按钮时,才从服务器中请求过来的动态数据。
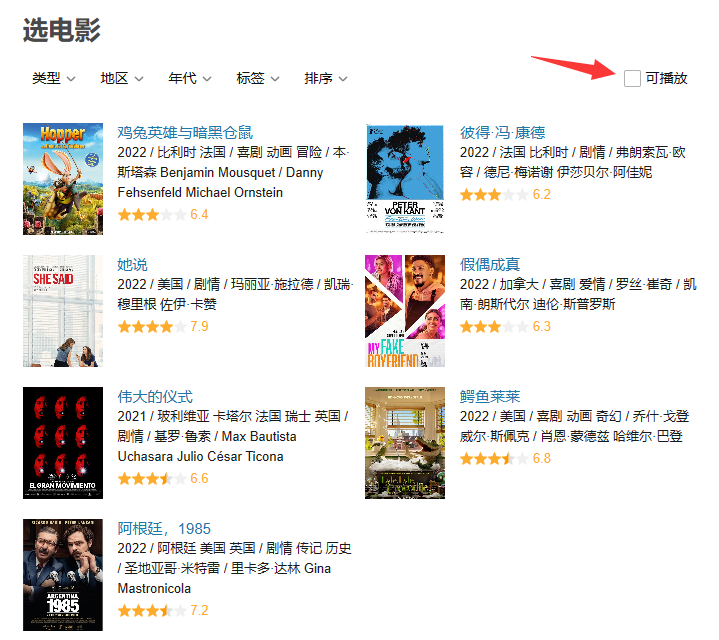
- 此时可以打开Network中的Fetch/XHR,然后可以点击左上角的clear按钮清空一下已经存在的记录。
- 然后将页面下拉到底部,点击“加载更多”按钮去加载更多的电影数据。

- 此时浏览器就会抓到一条动态数据。

- 查看这条数据的HTTP请求头,即可获取到这条请求的URL。
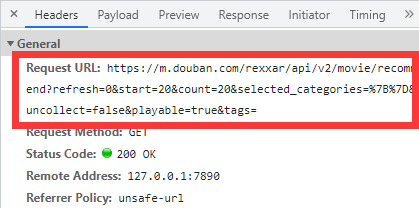
1.1.2 用requests模块请求该URL
直接请求这条URL,发现响应状态码是418,因此这里肯定有反扒机制。
import requestsresp = requests.get("https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=20&count=20&selected_categories=%7B%7D&uncollect=false&playable=true&tags=")print(resp) # <Response [418]>
根据之前学习的经验,这种情况可以优先考虑采用填充请求头的方式来解决。(只填充User-Agent会得到400,再填充Referer即可得到200) ```python import requests
url = “https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=20&count=20&selected_categories=%7B%7D&uncollect=false&playable=true&tags=“ headers={ ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46’, ‘Referer’: ‘https://movie.douban.com/explore‘ }
resp = requests.get(url=url, headers=headers)
print(resp) #
<a name="XyCwh"></a>#### 1.1.3 获取响应体- 可以先用`text`属性查看一下响应体。```python>>> resp.text'{"count": 20, "show_rating_filter": true, "recommend_categories": [{"is_control": true, "type": "\\u7c7b\\u578b", "data": [{"default": true, "text": "\\u5168\\u90e8\\u7c7b\\u578b"}, {"default": false, "text": "\\u559c\\u5267"}, {"default": false, "text": "\\u7231\\u60c5"},
- 可以发现这个是一个JSON数据,因此可以用
json()函数来接收。 通过简单分析,发现所有的电影数据都在items这个Key中;并且这是一个大列表,每一部电影都是这个列表中的一个元素。
>>> type(resp.json().get("items"))<class 'list'>>>> for movie in resp.json().get("items"):... print(movie)...{'comment': {'comment': '这么说吧,光想到人类唯一的幸存者是沈腾就感觉很好笑', 'id': '3438260632', 'user': {'kind': 'user', 'name': '刘初柒', 'url': 'https://www.douban.com/people/65880892/', 'uri': 'douban://douban.com/user/65880892', 'avatar': 'https://img2.douba
可以发现,每条电影数据又是一个字典,而为了后续操作,我们只需要获取每部电影的电影名称(key=title)和电影ID(key=id)即可。
>>> for movie in resp.json().get("items"):... print(movie.get("title"), movie.get("id"))...独行月球 35183042明日战记 26353671流浪地球 26266893少年的你 30166972哈利·波特与魔法石 1295038当幸福来敲门 1849031海上钢琴师 1292001大话西游之大圣娶亲 1292213夏洛特烦恼 25964071功夫 1291543西虹市首富 27605698忠犬八公的故事 3011091飞屋环游记 2129039唐伯虎点秋香 1306249我和我的祖国 32659890触不可及 6786002龙猫 1291560无间道 1307914头号玩家 4920389唐人街探案3 27619748
代码整合: ```python import requests
url = “https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=20&count=20&selected_categories=%7B%7D&uncollect=false&playable=true&tags=“ headers={ ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46’, ‘Referer’: ‘https://movie.douban.com/explore‘ }
resp = requests.get(url=url, headers=headers)
movies_data = resp.json().get(“items”) for movie in movies_data: title = movie.get(“title”) movie_id = movie.get(“id”) print(title, movie_id)
<a name="CUDHi"></a>#### 1.1.4 获取所有电影数据- 从1.1.3中可以清楚地看出,爬虫程序获取到的只有20条数据,这显然不是豆瓣电影中的所有电影数据。- 现在来分析URL:`https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=20&count=20&selected_categories=%7B%7D&uncollect=false&playable=true&tags=`,可以猜测数据条数是由`start=20&count=20`这两个分页参数控制的。- 尝试将`start`的值改为0,将`count`的值尽可能写大,尝试获取足够多的数据。(这里将`count`设置到2000)```python# 导入模块>>> import requests# 定义URL和请求头>>> url = "https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=2000&selected_categories=%7B%7D&uncollect=false&playable=true&tags=">>> headers={... 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46',... 'Referer': 'https://movie.douban.com/explore'... }# 发起请求,获取电影条数。>>> resp = requests.get(url=url, headers=headers)>>> len(resp.json().get("items"))500
- 发现最终电影的条数是500条,因此猜测用
https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=500&selected_categories=%7B%7D&uncollect=false&playable=true&tags=这条URL就可以获取豆瓣电影中所有的电影数据。 - 代码整合: ```python import requests
url = “https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=500&selected_categories=%7B%7D&uncollect=false&playable=true&tags=“ headers={ ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46’, ‘Referer’: ‘https://movie.douban.com/explore‘ }
resp = requests.get(url=url, headers=headers) movies_data = resp.json().get(“items”)
for index, movie in enumerate(movies_data): title = movie.get(“title”) movie_id = movie.get(“id”) print(index, title, movie_id)
<a name="k0Fnl"></a>### 1.2 影评页面<a name="RZIpW"></a>#### 1.2.1 影评页面地址分析- 以人生大事的前三页评论地址为例:> https://movie.douban.com/subject/35460157/comments?limit=20&status=P&sort=new_score> https://movie.douban.com/subject/35460157/comments?start=20&limit=20&status=P&sort=new_score> https://movie.douban.com/subject/35460157/comments?start=40&limit=20&status=P&sort=new_score- 其中35460157像个ID,因此怀疑是电影的ID。- 参数:start开始位置;limit显示条数;status状态,一般不用去改;sort排序规则。- 尝试将start设置为0,将limit尽可能的取最大值。- 发现一次性可获取的最大评论数量为500,即start=0&limit=500:`https://movie.douban.com/subject/35460157/comments?start=0&limit=500&status=P&sort=new_score`<a name="nKqbf"></a>#### 1.2.2 获取所有电影的评价页面- 既然35460157是一个电影的ID,那么所有电影的评价页面可以总结为:`https://movie.douban.com/subject/{movie_id}/comments?start=0&limit=500&status=P&sort=new_score`- 在1.1.4中我们已经获取到了所有的电影ID,那么由此也可以获取到所有的评价页面:```pythonfor movie in movies_data:title = movie.get("title")movie_id = movie.get("id")movie_comment_url = f"https://movie.douban.com/subject/{movie_id}/comments?start=0&limit=500&status=P&sort=new_score"print(title, movie_comment_url)
1.3 获取评论
1.3.1 获取一部电影的一页评论
- 还是以人生大事为例,获取一页评论只需要将
https://movie.douban.com/subject/35460157/comments?start=0&limit=500&status=P&sort=new_score用Selenium打开,然后获取评论数据即可。 ```python from selenium import webdriver from selenium.webdriver.common.by import By
browser = webdriver.Chrome() browser.get(“https://movie.douban.com/subject/35460157/comments?start=0&limit=500&status=P&sort=new_score“)
comments = [comment.text for comment in browser.find_elements(by=By.CLASS_NAME, value=”short”)] print(comments)
<a name="FihfE"></a>#### 1.3.2 获取一部电影的多页评论- 获取一部电影的多页评论实际上就是两步操作:获取一页评论、翻页。- 对于获取一页评论,可以单独定义一个函数出来。这个函数的功能就只是打开一个评论页面,然后将这个页面中所有评论获取出来,然后返回。- 而翻页操作,我们可能发现豆瓣电影的翻页是有URL中的start参数控制的,当limit为500时,第一页start为0、第二页start为500、第三页start为1500,以此类推。()```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Bydef extract_page_comment(url, driver):"""用于获取每一页的评论。:param url: 每一页的链接地址。:param driver: Selenium的浏览器驱动。:return: 将获取到的评论以列表的形式返回。"""driver.get(url)comments = [comment.text for comment in driver.find_elements(by=By.CLASS_NAME, value="short")]return commentsbrowser = webdriver.Chrome()comments_container = [] # 每一页的评论都会追加到这个容器中。start_index = 0 # 起始索引为0,每次加500表示翻页。while True:# 每页的地址和start_index有关,因此需要重新生成。base_url = f"https://movie.douban.com/subject/35460157/comments?start={start_index}&limit=500&status=P&sort=new_score"# 用extract_page_comment()函数获取该页的评论。comments = extract_page_comment(base_url, browser)# 当前页的评论获取操作结束后。# 若当前页的评论为空,则说明这部电影的评论已经获取结束,可退出循环。# 否则还需要继续获取下一页的内容(将当前页的内容追加到容器中,并让索引向后移动500)。if comments:comments_container.extend(comments)start_index += 500else:breakprint(comments_container)
1.3.3 获取多部电影的多部评论
- 获取多部电影的多页评论实际上就是将1.1.4与1.3.2的内容进行一个整合即可。 ```python from selenium import webdriver from selenium.webdriver.common.by import By
import requests
def extract_page_comment(url, driver): “”” 用于获取每一页的评论。 :param url: 每一页的链接地址。 :param driver: Selenium的浏览器驱动。 :return: 将获取到的评论以列表的形式返回。 “”” driver.get(url) comments = [comment.text for comment in driver.find_elements(by=By.CLASS_NAME, value=”short”)] return comments
url = “https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=500&selected_categories=%7B%7D&uncollect=false&playable=true&tags=“ headers={ ‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46’, ‘Referer’: ‘https://movie.douban.com/explore‘ }
resp = requests.get(url=url, headers=headers) movies_data = resp.json().get(“items”) browser = webdriver.Chrome()
for movie in movies_data: title = movie.get(“title”) movie_id = movie.get(“id”) comments_container = [] start_index = 0
while True:# 每页的地址和start_index有关,因此需要重新生成。base_url = f"https://movie.douban.com/subject/{movie_id}/comments?start={start_index}&limit=500&status=P&sort=new_score"# 用extract_page_comment()函数获取该页的评论。comments = extract_page_comment(base_url, browser)# 当前页的评论获取操作结束后。# 若当前页的评论为空,则说明这部电影的评论已经获取结束,可退出循环。# 否则还需要继续获取下一页的内容(将当前页的内容追加到容器中,并让索引向后移动500)。if comments:comments_container.extend(comments)start_index += 500else:breakprint(title, comments_container)
<a name="JAwLh"></a>### 1.4 数据持久化- 由于爬取到的评论都是非关系型的文本数据,因此可以使用最简单的txt文本文档来存储。```pythonimport os# 其他模块try:os.mkdir("豆瓣影评")except Exception as e:pass# 循环外的其他代码for movie in movies_data:# 评论获取部分的代码with open(f"豆瓣影评/{title}.txt", 'w', encoding='utf-8') as file:for comment in comments_container:file.write(f"{comment}\n")print(f"《{title}》影评爬取完成!")
1.5 项目代码整合
import randomimport timeimport requestsimport osfrom selenium import webdriverfrom selenium.webdriver.common.by import Bydef extract_page_comment(url, driver):"""用于获取每一页的评论。:param url: 每一页的链接地址。:param driver: Selenium的浏览器驱动。:return: 将获取到的评论以列表的形式返回。"""driver.get(url)comments = [comment.text for comment in driver.find_elements(by=By.CLASS_NAME, value="short")]return commentsurl = "https://m.douban.com/rexxar/api/v2/movie/recommend?refresh=0&start=0&count=500&selected_categories=%7B%7D&uncollect=false&playable=true&tags="headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46','Referer': 'https://movie.douban.com/explore'}resp = requests.get(url=url, headers=headers)movies_data = resp.json().get("items")browser = webdriver.Chrome()try:os.mkdir("豆瓣影评")except Exception as e:passfor movie in movies_data:title = movie.get("title")movie_id = movie.get("id")comments_container = []start_index = 0while True:# 每次请求前随机休眠2~5秒,避免访问频繁。time.sleep(random.randint(2, 5))# 每页的地址和start_index有关,因此需要重新生成。base_url = f"https://movie.douban.com/subject/{movie_id}/comments?start={start_index}&limit=500&status=P&sort=new_score"# 用extract_page_comment()函数获取该页的评论。comments = extract_page_comment(base_url, browser)# 当前页的评论获取操作结束后。# 若当前页的评论为空,则说明这部电影的评论已经获取结束,可退出循环。# 否则还需要继续获取下一页的内容(将当前页的内容追加到容器中,并让索引向后移动500)。if comments:comments_container.extend(comments)start_index += 500else:breakwith open(f"豆瓣影评/{title}.txt", 'w', encoding='utf-8') as file:for comment in comments_container:file.write(f"{comment}\n")print(f"《{title}》影评爬取完成!")
02. 链家房产信息获取
2.1 项目需求
- 访问链家首页:https://bj.lianjia.com/。
- 然后输入一个指定的区域,接着获取这个区域内的房源数据。
获取房源信息中的:城区、小区名称、房屋户型、建筑面积、套内面积、单价、总价、房屋朝向、装修情况、配备电梯、供暖方式等数据信息。
2.2 需求分析与实现
2.2.1 获取房源数据
获取房源数据用浏览器实现:
- 浏览器打开链家首页:https://bj.lianjia.com/。
- 然后在搜索框内输入区域名称,接着点击开始找房按钮。
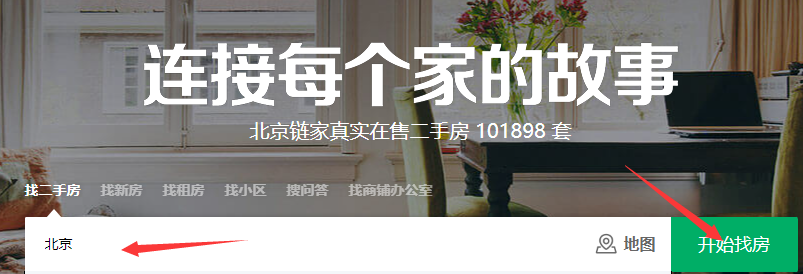
- 此时浏览器就会返回该区域内的各个房源信息。
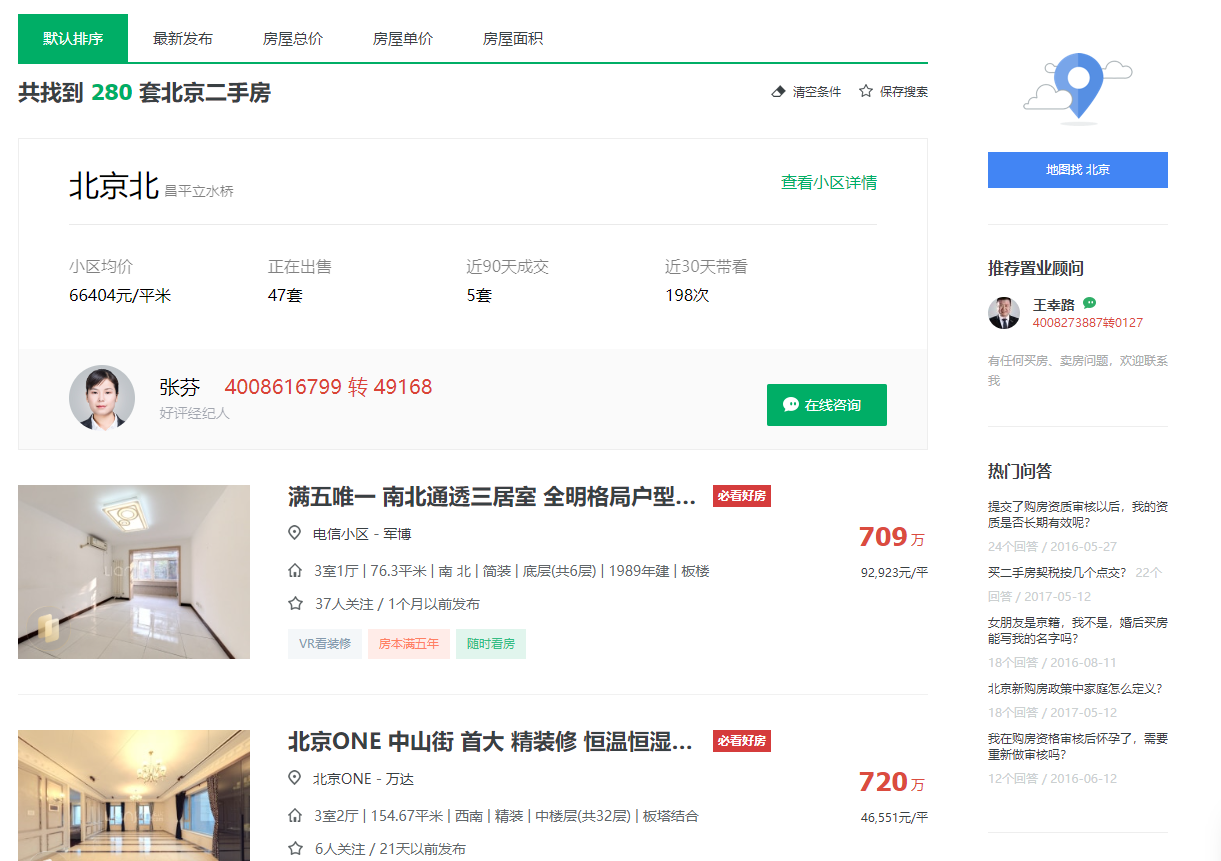
- 这个过程可以用Selenium程序轻松实现: ```sql from selenium import webdriver from selenium.webdriver.common.by import By
import time
打开浏览器,访问链家首页
browser = webdriver.Chrome() browser.get(“https://bj.lianjia.com/“) time.sleep(2)
找到搜索框,输入北京,并点击开始找房。
search_input = browser.find_element(by=By.CSS_SELECTOR, value=”#keyword-box”) search_input.send_keys(“北京”) find_btn = browser.find_element(by=By.CSS_SELECTOR, value=”#findHouse”) find_btn.click() time.sleep(3)
<a name="dPySc"></a>#### 2.2.2 进入房源详情页获取详细信息- 进入详情页获取详细信息用浏览器实现:- 点击每个房源信息的标题(里面含有一个超链接),即可跳转到该房源对应的详情页。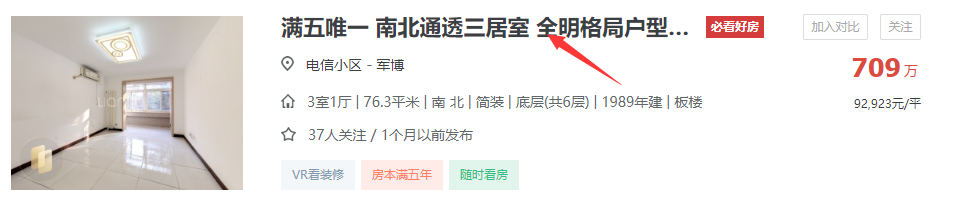- 详情页中有该房源的详细说明信息,值得注意的是该操作浏览器会打开一个新窗口。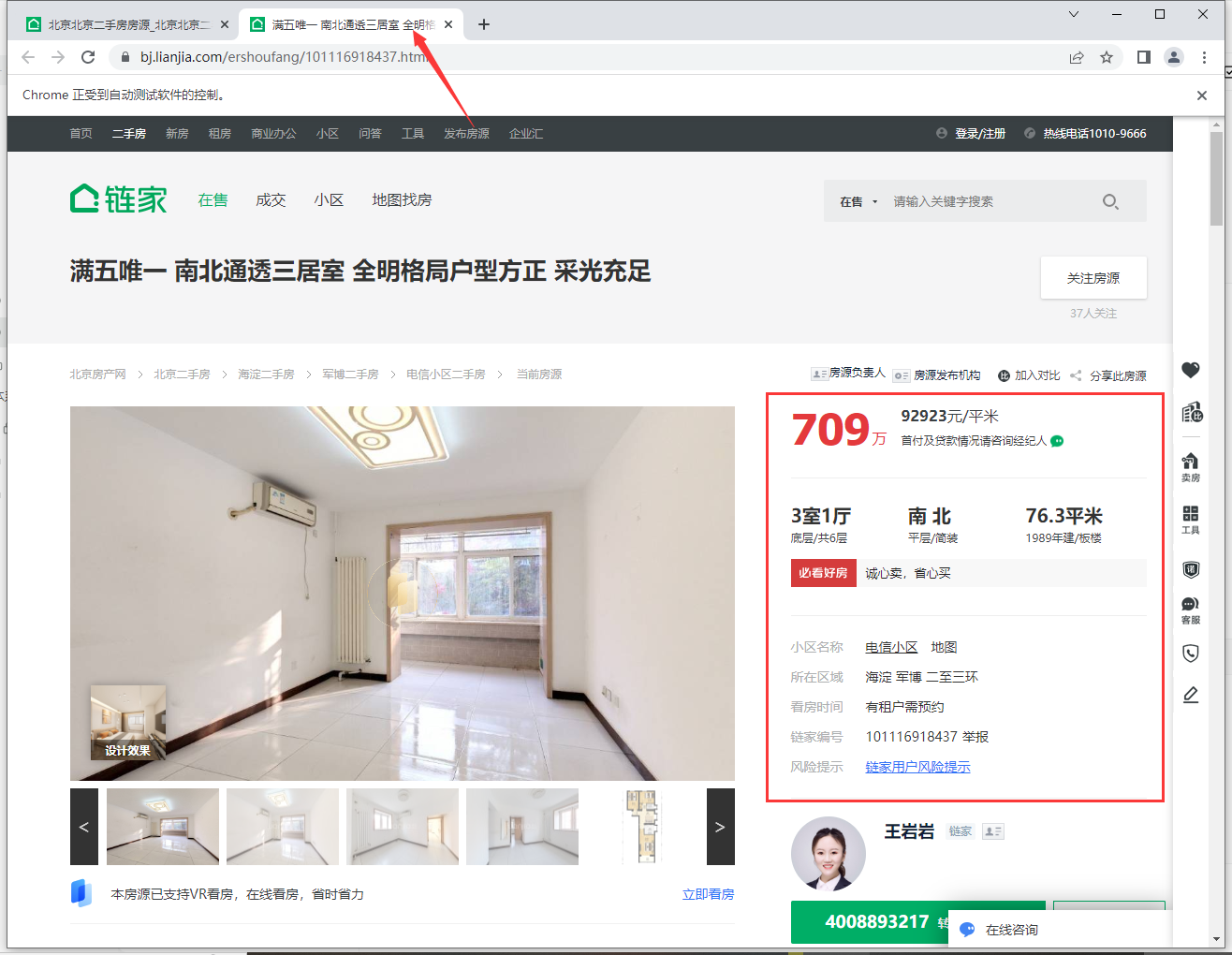- 信息位置: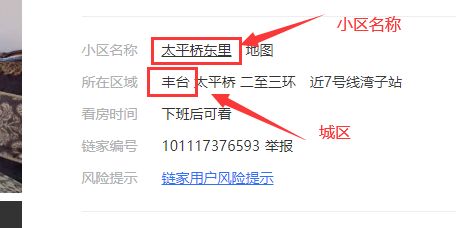<br /><br />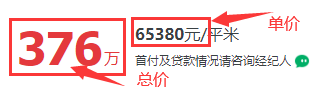- 当这页数据获取完成后,需要关闭当前窗口,并点击下一个页面继续以上操作。- 代码实现:```python# 获取所有房子的详情页连接,并点击进入详情页获取详细信息。house_list = browser.find_elements(by=By.CSS_SELECTOR,value=".sellListContent > li > .info > .title > a")for house_li in house_list:# 点击进入详情页。house_li.click()# 切换窗口browser.switch_to.window(browser.window_handles[-1])time.sleep(3)# 城区。area = browser.find_element(by=By.CSS_SELECTOR, value=".areaName .info a").textprint(area)# 小区名称。community_name = browser.find_element(by=By.CSS_SELECTOR, value=".communityName .info").textprint(community_name)# 获取户型信息。# 通过观察发现,这些信息都在.box-l .introContent .content > ul下的奇数li中。house_intro_lis = browser.find_elements(by=By.CSS_SELECTOR,value=".box-l .introContent .content > ul > li:nth-child(odd)")# get_attribute("innerHTML")获取到的数据是<span class="label">房屋户型</span>"3室1厅1厨1卫"这样的数据。# 因此可以根据</span>将字符串切割成两半,第二部分"3室1厅1厨1卫"就是需要的数据。# 因为需要的只有6个数据,所以可以用切片的方式过滤掉多余的数据。"""innerHTML的作用也是获取标签内的信息,与text类似,但存在以下差别。innerHTML:不会忽略标签内容,因此提取出来的是<span class="label">房屋户型</span>3室1厅1厨1卫这样的数据。text:会忽略标签内容,因此提取出来的是“房屋户型3室1厅1厨1卫”这样的数据。"""house_intro_contents = [li.get_attribute("innerHTML").split("</span>")[-1] for li in house_intro_lis][:6]# 接着,为了方便后续处理,可以将列表中的6个数据分别赋值给6个变量。house_type, house_area, house_true_area, house_direction, house_finish, house_hot = house_intro_contentsprint(house_type, house_area, house_true_area, house_direction, house_finish, house_hot, sep="\n")# 配备电梯。house_lift = browser.find_element(by=By.CSS_SELECTOR,value=".box-l .introContent .content > ul > li:last-child").text.lstrip("配备电梯")print(house_lift)# 单价。house_price = browser.find_element(by=By.CSS_SELECTOR, value=".unitPriceValue").text.rstrip("元/平米")print(house_price)# 总价。house_total_price = browser.find_element(by=By.CSS_SELECTOR, value=".price-container .total").textprint(house_total_price)# 为了区别于其他房源的数据,因此可以打印一行空行。print()# 数据提取完成后,关闭当前窗口browser.close() # 关闭当前窗口。browser.switch_to.window(browser.window_handles[0]) # 切换回起始页面。time.sleep(2)
2.2.3 获取多页数据
- 获取多页数据用浏览器实现:
- 当数据过多时网站一般都会选择分页显示,而当一页信息查看完后,可以点击“下一页”按钮浏览下一页数据。
- 而当浏览到最后一页时,页面中就不会出现“下一页”按钮了,此时就说明所有页面信息已经全部浏览完成。

- 存在问题:
- 问题描述:在使用
next_btn.click()点击“下一页”按钮时,Python程序报错提示无法点击。 - 解决方式:换成JavaScript代码执行点击操作,然后由Selenium程序发送执行。
- 问题描述:在使用
代码实现:
# 在获取当前分页数据的外面套一层循环,用来控制翻页。# 翻页要翻多少次并不知道,只知道当翻页按钮的最后一个不是下一页时,就停止。page = 1 # 用于记录当前页码。while True:print(f"正在获取第{page}页的数据。。。")page += 1# 获取所有房子的详情页连接,并点击进入详情页获取详细信息。house_list = browser.find_elements(by=By.CSS_SELECTOR, value=".sellListContent > li > .info > .title > a")for house_li in house_list:# 点击进入详情页。browser.execute_script('$(arguments[0].click())', house_li) # 这段代码的含义在下面翻页操作中有详细说明。# 切换窗口browser.switch_to.window(browser.window_handles[-1])time.sleep(3)# 城区。area = browser.find_element(by=By.CSS_SELECTOR, value=".areaName .info a").textprint(area)# 小区名称。community_name = browser.find_element(by=By.CSS_SELECTOR, value=".communityName .info").textprint(community_name)# 获取户型信息。# 通过观察发现,这些信息都在.box-l .introContent .content > ul下的奇数li中。house_intro_lis = browser.find_elements(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:nth-child(odd)")# get_attribute("innerHTML")获取到的数据是<span class="label">房屋户型</span>"3室1厅1厨1卫"这样的数据。# 因此可以根据</span>将字符串切割成两半,第二部分"3室1厅1厨1卫"就是需要的数据。# 因为需要的只有6个数据,所以可以用切片的方式过滤掉多余的数据。"""innerHTML的作用也是获取标签内的信息,与text类似,但存在以下差别。innerHTML:不会忽略标签内容,因此提取出来的是<span class="label">房屋户型</span>3室1厅1厨1卫这样的数据。text:会忽略标签内容,因此提取出来的是“房屋户型3室1厅1厨1卫”这样的数据。"""house_intro_contents = [li.get_attribute("innerHTML").split("</span>")[-1] for li in house_intro_lis][:6]# 接着,为了方便后续处理,可以将列表中的6个数据分别赋值给6个变量。house_type, house_area, house_true_area, house_direction, house_finish, house_hot = house_intro_contentsprint(house_type, house_area, house_true_area, house_direction, house_finish, house_hot, sep="\n")# 配备电梯。house_lift = browser.find_element(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:last-child").text.lstrip("配备电梯")print(house_lift)# 单价。house_price = browser.find_element(by=By.CSS_SELECTOR, value=".unitPriceValue").text.rstrip("元/平米")print(house_price)# 总价。house_total_price = browser.find_element(by=By.CSS_SELECTOR, value=".price-container .total").textprint(house_total_price)# 为了区别于其他房源的数据,因此可以打印一行空行。print()# 数据提取完成后,关闭当前窗口browser.close() # 关闭当前窗口。browser.switch_to.window(browser.window_handles[0]) # 切换回起始页面。time.sleep(2)# 当翻页按钮的最后一个是下一页时,点击下一页。# 当翻页按钮的最后一个不是下一页时,停止循环。next_btn = browser.find_element(by=By.CSS_SELECTOR, value=".house-lst-page-box > a:last-child")if next_btn.text == '下一页':# 因为next_btn.click()会报无法点击的异常,因此这里只能用JavaScript的代码来实现点击操作。"""Selenium中通过browser.execute_script(JS代码, 需要传递的参数)来执行JS代码。$(arguments[0].click())是一段JS代码,arguments[0]表示传递的第0个参数,即next_btn。接着对next_btn进行点击操作,故这段代码本质上与next_btn.click()是一样的,只不过换了一个方式去实现这个功能而已。"""browser.execute_script('$(arguments[0].click())', next_btn)time.sleep(5)else:break
2.2.4 数据持久化
数据爬取完成后,可以将爬取的数据存储到Excel文件中。 ```python import openpyxl
save_datas = [ [‘城区’, ‘小区名称’, ‘房屋户型’, ‘建筑面积’, ‘套内面积’, ‘房屋朝向’, ‘装修情况’, ‘供暖方式’, ‘配备电梯’, ‘单价(元/平米)’, ‘总价(万元)’] ]
在获取当前分页数据的外面套一层循环,用来控制翻页。
翻页要翻多少次并不知道,只知道当翻页按钮的最后一个不是下一页时,就停止。
page = 1 # 用于记录当前页码。 while True: print(f”正在获取第{page}页的数据。。。”) page += 1
# 获取当前页所有房子的详情页连接,并点击进入详情页获取详细信息。house_list = browser.find_elements(by=By.CSS_SELECTOR, value=".sellListContent > li > .info > .title > a")for house_li in house_list:# 点击进入详情页。browser.execute_script('$(arguments[0].click())', house_li) # 这段代码的含义在下面翻页操作中有详细说明。# 切换窗口browser.switch_to.window(browser.window_handles[-1])time.sleep(3)area = browser.find_element(by=By.CSS_SELECTOR, value=".areaName .info a").text # 城区。community_name = browser.find_element(by=By.CSS_SELECTOR, value=".communityName .info").text # 小区名称。# 获取户型信息。# 通过观察发现,这些信息都在.box-l .introContent .content > ul下的奇数li中。house_intro_lis = browser.find_elements(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:nth-child(odd)")# get_attribute("innerHTML")获取到的数据是<span class="label">房屋户型</span>"3室1厅1厨1卫"这样的数据。# 因此可以根据</span>将字符串切割成两半,第二部分"3室1厅1厨1卫"就是需要的数据。# 因为需要的只有6个数据,所以可以用切片的方式过滤掉多余的数据。"""innerHTML的作用也是获取标签内的信息,与text类似,但存在以下差别。innerHTML:不会忽略标签内容,因此提取出来的是<span class="label">房屋户型</span>3室1厅1厨1卫这样的数据。text:会忽略标签内容,因此提取出来的是“房屋户型3室1厅1厨1卫”这样的数据。"""house_intro_contents = [li.get_attribute("innerHTML").split("</span>")[-1] for li in house_intro_lis][:6]# 接着,为了方便后续处理,可以将列表中的6个数据分别赋值给6个变量。house_type, house_area, house_true_area, house_direction, house_finish, house_hot = house_intro_contentshouse_lift = browser.find_element(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:last-child").text.lstrip("配备电梯") # 配备电梯。house_price = browser.find_element(by=By.CSS_SELECTOR, value=".unitPriceValue").text.rstrip("元/平米") # 单价。house_total_price = browser.find_element(by=By.CSS_SELECTOR, value=".price-container .total").text # 总价。# 将一条数据存储到总数据中,方便后续持久化操作。row_data = [area, community_name, house_type, house_area, house_true_area, house_direction, house_finish, house_hot, house_lift, house_price, house_total_price]save_datas.append(row_data)print(row_data)# 数据提取完成后,关闭当前窗口browser.close() # 关闭当前窗口。browser.switch_to.window(browser.window_handles[0]) # 切换回起始页面。time.sleep(2)# 当翻页按钮的最后一个是下一页时,点击下一页。# 当翻页按钮的最后一个不是下一页时,停止循环。next_btn = browser.find_element(by=By.CSS_SELECTOR, value=".house-lst-page-box > a:last-child")if next_btn.text == '下一页':# 因为next_btn.click()会报无法点击的异常,因此这里只能用JavaScript的代码来实现点击操作。"""Selenium中通过browser.execute_script(JS代码, 需要传递的参数)来执行JS代码。$(arguments[0].click())是一段JS代码,arguments[0]表示传递的第0个参数,即next_btn。接着对next_btn进行点击操作,故这段代码本质上与next_btn.click()是一样的,只不过换了一个方式去实现这个功能而已。"""browser.execute_script('$(arguments[0].click())', next_btn)time.sleep(5)else:break
数据持久化到Excel文件中。
wb = openpyxl.Workbook() ws = wb.worksheets[0] for line, line_data in enumerate(save_datas): for column, data in enumerate(line_data): ws.cell(line + 1, column + 1, data) wb.save(“./excel/链家.xlsx”)
<a name="uOBoi"></a>#### 2.2.5 项目代码整合```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport timeimport openpyxlsave_datas = [['城区', '小区名称', '房屋户型', '建筑面积', '套内面积', '房屋朝向', '装修情况', '供暖方式', '配备电梯', '单价(元/平米)', '总价(万元)']]# 打开浏览器,访问链家首页browser = webdriver.Chrome()browser.get("https://bj.lianjia.com/")time.sleep(2)# 找到搜索框,输入北京,并点击开始找房。search_input = browser.find_element(by=By.CSS_SELECTOR, value="#keyword-box")search_input.send_keys("北京")find_btn = browser.find_element(by=By.CSS_SELECTOR, value="#findHouse")find_btn.click()time.sleep(3)# 在获取当前分页数据的外面套一层循环,用来控制翻页。# 翻页要翻多少次并不知道,只知道当翻页按钮的最后一个不是下一页时,就停止。page = 1 # 用于记录当前页码。while True:print(f"正在获取第{page}页的数据。。。")page += 1# 获取当前页所有房子的详情页连接,并点击进入详情页获取详细信息。house_list = browser.find_elements(by=By.CSS_SELECTOR, value=".sellListContent > li > .info > .title > a")for house_li in house_list:# 点击进入详情页。browser.execute_script('$(arguments[0].click())', house_li) # 这段代码的含义在下面翻页操作中有详细说明。# 切换窗口browser.switch_to.window(browser.window_handles[-1])time.sleep(3)area = browser.find_element(by=By.CSS_SELECTOR, value=".areaName .info a").text # 城区。community_name = browser.find_element(by=By.CSS_SELECTOR, value=".communityName .info").text # 小区名称。# 获取户型信息。# 通过观察发现,这些信息都在.box-l .introContent .content > ul下的奇数li中。house_intro_lis = browser.find_elements(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:nth-child(odd)")# get_attribute("innerHTML")获取到的数据是<span class="label">房屋户型</span>"3室1厅1厨1卫"这样的数据。# 因此可以根据</span>将字符串切割成两半,第二部分"3室1厅1厨1卫"就是需要的数据。# 因为需要的只有6个数据,所以可以用切片的方式过滤掉多余的数据。"""innerHTML的作用也是获取标签内的信息,与text类似,但存在以下差别。innerHTML:不会忽略标签内容,因此提取出来的是<span class="label">房屋户型</span>3室1厅1厨1卫这样的数据。text:会忽略标签内容,因此提取出来的是“房屋户型3室1厅1厨1卫”这样的数据。"""house_intro_contents = [li.get_attribute("innerHTML").split("</span>")[-1] for li in house_intro_lis][:6]# 接着,为了方便后续处理,可以将列表中的6个数据分别赋值给6个变量。house_type, house_area, house_true_area, house_direction, house_finish, house_hot = house_intro_contentshouse_lift = browser.find_element(by=By.CSS_SELECTOR, value=".box-l .introContent .content > ul > li:last-child").text.lstrip("配备电梯") # 配备电梯。house_price = browser.find_element(by=By.CSS_SELECTOR, value=".unitPriceValue").text.rstrip("元/平米") # 单价。house_total_price = browser.find_element(by=By.CSS_SELECTOR, value=".price-container .total").text # 总价。# 将一条数据存储到总数据中,方便后续持久化操作。row_data = [area, community_name, house_type, house_area, house_true_area, house_direction, house_finish, house_hot, house_lift, house_price, house_total_price]save_datas.append(row_data)print(row_data)# 数据提取完成后,关闭当前窗口browser.close() # 关闭当前窗口。browser.switch_to.window(browser.window_handles[0]) # 切换回起始页面。time.sleep(2)# 当翻页按钮的最后一个是下一页时,点击下一页。# 当翻页按钮的最后一个不是下一页时,停止循环。next_btn = browser.find_element(by=By.CSS_SELECTOR, value=".house-lst-page-box > a:last-child")if next_btn.text == '下一页':# 因为next_btn.click()会报无法点击的异常,因此这里只能用JavaScript的代码来实现点击操作。"""Selenium中通过browser.execute_script(JS代码, 需要传递的参数)来执行JS代码。$(arguments[0].click())是一段JS代码,arguments[0]表示传递的第0个参数,即next_btn。接着对next_btn进行点击操作,故这段代码本质上与next_btn.click()是一样的,只不过换了一个方式去实现这个功能而已。"""browser.execute_script('$(arguments[0].click())', next_btn)time.sleep(5)else:break# 数据持久化到Excel文件中。wb = openpyxl.Workbook()ws = wb.worksheets[0]for line, line_data in enumerate(save_datas):for column, data in enumerate(line_data):ws.cell(line + 1, column + 1, data)wb.save("./excel/链家.xlsx")

若有收获,就点个赞吧
0 人点赞
