01. 查询基础
1.1 简单查询
1.1.1 查询指定字段的数据
- 可以使用
SELECT 字段1, 字段2, …, 字段n FROM 表名;查询表中指定字段的数据。 示例:查询学生的学号、姓名、性别。
SELECT sno, sname, gender FROM student;
1.1.2 查询所有字段的数据
方式一:使用1.1.1的方法,将所有的字段名都列出来。
优缺点:字段的先后顺序可以自行定制,查询较为灵活;但是当表中字段很多时,书写很麻烦。
SELECT sno, sname, birthday, gender, cnoFROM student;
方式二:使用通配符
*代替所有字段名。优缺点:查询结果中字段的先后顺序与表结构完全一致,查询不灵活;但是不管表中有多少个字段,书写都十分快捷。
SELECT * FROM student;
1.1.3 WHERE筛选数据
可以使用
SELECT 查询字段 FROM 表名 WHERE 筛选条件;将符合条件的行数据筛选出来。示例1:查询11号班级的学生的学号、姓名、性别。
SELECT sno, sname, genderFROM studentWHERE cno=11;
示例2:查询名字是三个字的学生的学号、姓名、性别。 ```sql — 方式一:使用三个下划线匹配三个字符。 SELECT sno, sname, gender, cno FROM student WHERE sname LIKE ‘_‘;
— 方式二:使用正则表达式’^.{3}$’匹配三个字符。 SELECT sno, sname, gender, cno FROM student WHERE sname REGEXP ‘^.{3}$’;
- 示例3:查询名字中包含“鹏”字的学生的所有信息。```sql-- 方式一:使用表达式'%鹏%'匹配带有鹏的字符串。SELECT * FROM studentWHERE sname LIKE '%鹏%';-- 方式二:使用正则表达式'[鹏]'匹配带有鹏的字符串。SELECT * FROM studentWHERE sname REGEXP '[鹏]';
1.1.4 简单查询练习
- 查找李姓同学的学号、姓名。 ```sql — 使用LIKE SELECT sno, sname FROM student WHERE sname LIKE ‘李%’;
— 使用REGEXP SELECT sno, sname FROM student WHERE sname REGEXP ‘^李’;
- 查找2002年出生的学生信息。```sql-- 使用LIKESELECT * FROM student WHERE birthday LIKE '2002%';-- 使用REGEXPSELECT * FROM student WHERE birthday REGEXP '^2002.*?$';
查找2002年出生的女生信息。
SELECT * FROM studentWHERE birthday LIKE '2002%'AND gender = '女';
查找3月份出生的学生信息。 ```sql — 使用LIKE SELECT * FROM student WHERE birthday LIKE ‘%-03-%’;
— 使用REGEXP SELECT * FROM student WHERE birthday REGEXP ‘^.+?-03-.+?$’;
<a name="tET6A"></a>### 1.2 分组查询基础<a name="NHXsl"></a>#### 1.2.1 分组聚合查询概述- 分组查询:指根据某个指标将数据进行分类,然后再显示相关数据的查询。- 分组查询基础语法:```sqlSELECT 分组函数(字段), 其他字段FROM 表GROUP BY 分组的依据字段;
-
1.2.2 COUNT()统计函数
COUNT函数的基本用法:
- 如果查询中不存在分组,则统计的是查询结果的数据行数。
- 如果查询中存在分组,则统计的是对应分类下数据的函数。
COUNT(*)和COUNT(字段名)的区别:COUNT(*):如果某行数据中存在空值null,则该行数据也会被当作一条记录统计在内。COUNT(字段名):若某行数据中该字段的值为null,则该行数据不会被当作一条记录统计在内。
实验准备:将纪涵的生日数据改为null。
UPDATE student SET birthday = NULL WHERE sname = '纪涵';SELECT * FROM student WHERE sname = '纪涵';
示例1:查询学生的总人数。
SELECT COUNT(*) FROM student;
示例2:查询有生日数据的人数。
SELECT COUNT(birthday) FROM student;
示例3:查询女生人数。
SELECT COUNT(*) FROM student WHERE gender = '女';
示例4:查询每个班级的人数。
SELECT cno, COUNT(sno) AS 人数FROM studentGROUP BY cno;
1.2.3 SUM()求和函数
如果查询中不存在分组,则
SUM(字段名)用于统计表中指定字段的所有数据之和。示例1:查询学生表中所有学生的总成绩。
SELECT SUM(score) FROM score_tb;
如果查询中存在分组,则
SUM(字段名)用于统计表中指定分类下某个字段数据的和。示例2:查询每门课中所有学生的分数之和。
SELECT cid, SUM(score) AS 总分FROM score_tbGROUP BY cid;
示例3:查询每个学生的总成绩。
SELECT sno, SUM(score) AS 总成绩FROM score_tbGROUP BY sno;
1.2.4 MAX()求最大值
如果查询中不存在分组,则
MAX(字段名)用于统计表中指定字段的所有数据中的最大值。示例1:查询所有成绩中的最高分。
SELECT MAX(score) FROM score_tb;
如果查询中存在分组,则
MAX(字段名)用于统计表中指定分类下某个字段数据的最大值。示例2:查询每门课的最高分。
SELECT cid, MAX(score) AS 最高分FROM score_tbGROUP BY cid;
1.2.5 MIN()求最小值
如果查询中不存在分组,则
MIN(字段名)用于统计表中指定字段的所有数据中的最小值。示例1:查询所有成绩中的最低分。
SELECT MIN(score) FROM score_tb;
如果查询中存在分组,则
MIN(字段名)用于统计表中指定分类下某个字段数据的最小值。示例2:查询每门课的最低分。
SELECT cid, MIN(score) AS 最低分FROM score_tbGROUP BY cid;
1.2.6 AVG()求平均值
如果查询中不存在分组,则
AVG(字段名)用于计算表中指定字段的所有数据的平均值。示例1:查询所有成绩的平均值。
SELECT AVG(score) FROM score_tb;
如果查询中存在分组,则
AVG(字段名)用于计算表中指定分类下某个字段数据的平均值。示例2:查询每门课的平均成绩。
SELECT cid, AVG(score) AS 平均数FROM score_tbGROUP BY cid;
1.2.7 分组函数基础练习
查询总成绩在200分以上的学生学号。
SELECT sno, SUM(score)FROM score_tbGROUP BY snoHAVING SUM(score) > 200;
查询每门课程的最高分。
SELECT cid, MAX(score)FROM score_tbGROUP BY cid;
统计每个学生的选课数。
SELECT sno, COUNT(cid) AS 选课数FROM score_tbGROUP BY sno;
查询选课数在两门及以上的学生学号。
SELECT sno, COUNT(cid) AS 选课数FROM score_tbGROUP BY snoHAVING COUNT(cid) >= 2;
1.3 高级分组查询
1.3.1 GROUP_CONCAT函数
GROUP_CONCAT函数简介:
- 这个函数区别与1.2中的6个函数,是因为这个函数只能运用在分组查询中。
- 基本的分组函数会将一个组内的多条数据聚合成一条数据,此时就无法查看某个字段的所有数据了。
- 针对于归类的数据要展示其他字段的多个数据,就可以使用GROUP_CONCAT函数。
- 基本语法:
GROUP_CONCAT(要展示的字段) 示例1:查询每个班级中所有学生的姓名。
SELECT cno, GROUP_CONCAT(sname) AS 班级学生FROM studentGROUP BY cno;
此外,还可以使用
GROUP_CONCAT(要展示的字段 ORDER BY 排序基于的字段 [DESC])进行排序。- 默认的排序方式为升序排序。
- 在末尾加上DESC关键字,则排序方式改为降序排序。
示例2:查询每个班级中所有学生的姓名,并根据学生学号进行降序排序。
SELECT cno, GROUP_CONCAT(sname ORDER BY sno DESC) AS 班级学生FROM studentGROUP BY cno;
1.3.2 多字段分组
分组查询可以根据多个字段进行分类:
SELECT 查询列表GROUP BY 分组字段1, 分组字段2, …, 分组字段n;
示例:查询每个班级中男女生的个数。
SELECT cno, gender, COUNT(sno) AS 人数FROM studentGROUP BY cno, gender;
1.3.3 分组函数条件查询
分组函数查询也可以进行条件查询,语法格式如下:
SELECT 分组函数(字段), 其他字段FROM 表[WHERE 分组前的过滤]GROUP BY 分组的依据字段[HAVING 分组后的过滤];
HAVING与WHERE的区别:
- WHERE用于分组前的数据筛选,即先进行数据过滤,然后再进行分组。被WHERE过滤掉的数据不会参与分组。
- HAVING是分组后的数据筛选,即先进行分组,再过滤数据。相当于对分组查询得到的结果表进行一次WHERE。
- HAVING与WHERE的注意事项:
- WHERE后的筛选执行的时机先于HAVING后的筛选。
- WHERE后面不能跟聚合函数,并且筛选字段来源于源数据表。
- HAVING后面筛选的字段必须在SELECT中列出来,否则查询无效。
示例1:查询每个班级中男生的人数。(先筛选出所有男生的数据,再根据班级进行分组)
SELECT cno, COUNT(sno) AS 男生人数FROM studentWHERE gender = '男'GROUP BY cno;
示例2:查询男生人数在2人以上的班级。(先根据示例1查询出每个班级的男生人数,再用HAVING过滤出男生人数大于2的数据)
SELECT cno, COUNT(sno) AS 男生人数FROM studentWHERE gender = '男'GROUP BY cnoHAVING COUNT(sno) > 2;
1.4 子查询
1.4.1 子查询基础
子查询与主查询的概念:
- 出现在其他语句(包括增删改查等大多数SQL语句)内部的SELECT语句,称为子查询或内查询。
- 内部嵌套其他SELECT语句的查询,称为外查询或主查询。
- 示例1:查询比王慧生日小的学生信息。 ```sql — 1. 查询王慧的生日。 SELECT birthday FROM student WHERE sname = ‘王慧’;
— 2. 查询比王慧生日小的学生数据。 SELECT * FROM student WHERE birthday > ( SELECT birthday FROM student WHERE sname = ‘王慧’ );
- 示例2:查询和魏雷同班的其他学生的信息。```sql-- 1. 查询魏雷的班级。SELECT cnoFROM studentWHERE sname = '魏雷';-- 2. 查询和魏雷同班的学生信息。SELECT * FROM studentWHERE cno = (SELECT cnoFROM studentWHERE sname = '魏雷');-- 和魏雷同班的其他学生应该不包含魏雷,需要把数据过滤掉。SELECT * FROM studentWHERE cno = (SELECT cnoFROM studentWHERE sname = '魏雷') AND sname != '魏雷';
- 示例3:查找比耿云鹏总成绩高的学生信息。 ```sql — 1. 查询耿云鹏的学号。 SELECT sno FROM student WHERE sname = ‘耿云鹏’;
— 2. 查询耿云鹏的总成绩。 SELECT SUM(score) FROM score_tb WHERE sno = ( SELECT sno FROM student WHERE sname = ‘耿云鹏’ );
— 3. 查询比耿云鹏总成绩高的学生的学号。 SELECT sno FROM score_tb GROUP BY sno HAVING SUM(score) > ( SELECT SUM(score) FROM score_tb WHERE sno = (SELECT sno FROM student WHERE sname = ‘耿云鹏’) );
— 4. 根据学生的学号,显示学生信息。 SELECT * FROM student WHERE sno IN ( SELECT sno FROM score_tb GROUP BY sno HAVING SUM(score) > ( SELECT SUM(score) FROM score_tb WHERE sno = (SELECT sno FROM student WHERE sname = ‘耿云鹏’) ) );
<a name="moxJ5"></a>#### 1.4.2 子查询应用到修改/修改表数据- 注意:表数据来源于阶段练习一。- 示例1:把肖美的底薪修改成与张丽丽一样的底薪。```sql-- 查询张丽丽的底薪。SELECT ebsalary FROM employee WHERE ename = '张丽丽';-- 修改肖美的底薪。SELECT ebsalary FROM employee WHERE ename = '肖美';UPDATE employee SET ebsalary = (SELECT ebsalary FROM employee WHERE ename = '张丽丽') WHERE ename = '肖美';SELECT ebsalary FROM employee WHERE ename = '肖美';
注意:这条UPDATE语句会报错:
[HY000][1093] You can't specify target table 'employee' for update in FROM clause报错原因:在修改表的同时,对表进行遍历查询操作。这与Python中删除元素的操作类似,会导致数据处理不干净。
nums = [12, 34, 56, 12, 57, 12, 12, 12]for i in nums:nums.remove(12)print(nums) # [34, 56, 57, 12]# 原因与解决方案在“01. Python语法 -- 03. Python数据结构 -- 02. 列表 -- 2.5.5 移除元素存在的漏洞以及解决方案”中有讲解。
解决方案:备份一遍原表,对原表进行遍历查询操作,然后修改原来的表格。 ```sql — 备份表格(把查询结果当作备份表) SELECT * FROM employee;
— 把一个查询结果当作表使用时,必须给其取别名 SELECT ebsalary FROM employee WHERE ename = ‘肖美’; UPDATE employee SET ebsalary = ( SELECT ebsalary FROM ( SELECT * FROM employee ) AS tmp_emp WHERE ename = ‘张丽丽’ ) WHERE ename = ‘肖美’; SELECT ebsalary FROM employee WHERE ename = ‘肖美’;
- 注意:把子查询应用到删除表数据的思想与修改表数据基本一致,无非就是把`UPDATE`操作改成`DELETE`操作而已。<a name="nFbxQ"></a>### 1.5 阶段练习一- 创建myemployees数据库,并切换使用。```sqlDROP DATABASE IF EXISTS `myemployees`;CREATE DATABASE IF NOT EXISTS `myemployees`;USE `myemployees`;
- 创建部门表dept,包含如下信息:

DROP TABLE IF EXISTS `dept`;CREATE TABLE IF NOT EXISTS `dept` (dno INT PRIMARY KEY COMMENT '部门编号',dname VARCHAR(20) NOT NULL COMMENT '部门名称');
- 创建员工表employee,包含如下信息:

DROP TABLE IF EXISTS `employee`;CREATE TABLE IF NOT EXISTS `employee` (eno INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工编号',ename VARCHAR(20) NOT NULL COMMENT '员工姓名',eage INT COMMENT '员工年龄',esex CHAR(3) COMMENT '员工性别',ejob VARCHAR(20) COMMENT '员工职位',ehiredate DATE COMMENT '入职时间',ebonus INT COMMENT '员工奖金',ebsalary INT COMMENT '员工底薪',deptno INT COMMENT '部门编号',CONSTRAINT fk_employee_dept FOREIGN KEY(deptno) REFERENCES dept(dno));
- 向部门表中添加以下数据:
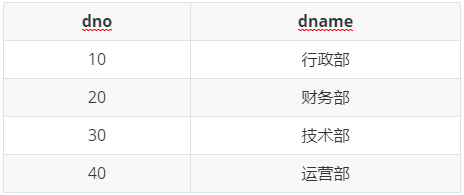
INSERT INTO dept VALUES(10, '行政部'),(20, '财务部'),(30, '技术部'),(40, '运营部');SELECT * FROM dept;
- 向员工表中添加以下数据:
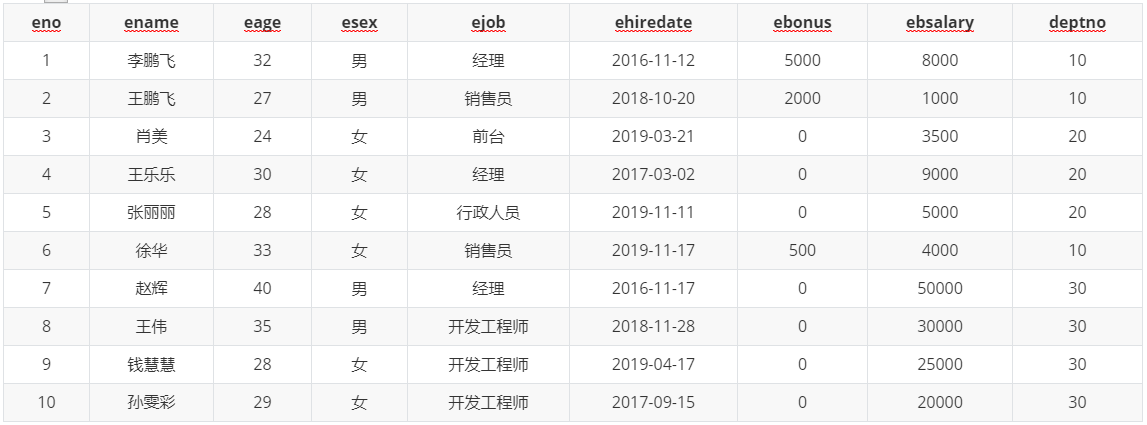
INSERT INTO employee VALUES(1, '李鹏飞', 32, '男', '经理', '2016-11-12', 5000, 8000, 10),(2, '王鹏飞', 27, '男', '销售员', '2018-10-20', 2000, 1000, 10),(3, '肖美', 24, '女', '前台', '2019-03-21', 0, 3500, 20),(4, '王乐乐', 30, '女', '经理', '2017-03-02', 0, 9000, 20),(5, '张丽丽', 28, '女', '行政人员', '2019-11-11', 0, 5000, 20),(6, '徐华', 33, '女', '销售员', '2019-11-17', 500, 4000, 10),(7, '赵辉', 40, '男', '经理', '2016-11-17', 0, 50000, 30),(8, '王伟', 35, '男', '开发工程师', '2018-11-28', 0, 30000, 30),(9, '钱慧慧', 28, '女', '开发工程师', '2019-04-17', 0, 25000, 30),(10, '孙雯彩', 29, '女', '开发工程师', '2017-09-15', 0, 20000, 30);SELECT * FROM employee;
修改肖美的奖金为500。
SELECT * FROM employee WHERE ename = '肖美';UPDATE employee SET ebonus = 500 WHERE ename = '肖美';SELECT * FROM employee WHERE ename = '肖美';
删除名为孙雯彩的员工。
SELECT * FROM employee WHERE ename = '孙雯彩';DELETE FROM employee WHERE ename = '孙雯彩';SELECT * FROM employee WHERE ename = '孙雯彩';
查询出部门编号为30的所有员工。
SELECT * FROM employeeWHERE deptno = 30;
所有销售员的姓名、编号和部门编号。
SELECT ename, eno, deptnoFROM employeeWHERE ejob = '销售员';
找出奖金高于底薪的员工。
SELECT * FROM employeeWHERE ebonus > ebsalary;
找出奖金高于工资60%的员工(工资=底薪+奖金)。
SELECT * FROM employeeWHERE ebonus > (ebonus + ebsalary) * 0.6;
查询有奖金的员工的职位。
SELECT ejob FROM employeeWHERE ebonus > 0;
查询名字由三个字组成的员工。
SELECT * FROM employee WHERE ename LIKE '___';SELECT * FROM employee WHERE ename REGEXP '^.{3}$';
查询2017年入职的员工信息。
SELECT * FROM employee WHERE ehiredate LIKE '2017%';
查询技术部的员工信息。
SELECT * FROM employeeWHERE deptno = (SELECT dno FROM dept WHERE dname = '技术部');
查询工资高于徐华的员工信息。
SELECT * FROM employeeWHERE (ebonus + ebsalary) > (SELECT (ebonus + ebsalary) AS sal FROM employee WHERE ename = '徐华');
查询与赵辉同一部门的员工信息。
SELECT * FROM employeeWHERE deptno = (SELECT deptno FROM employee WHERE ename = '赵辉') AND ename != '赵辉';
查询每个部门的平均薪资/最高薪资、最低薪资。
SELECTdeptno,AVG(ebonus + ebsalary) AS 平均薪资,MAX(ebonus + ebsalary) AS 最高薪资,MIN(ebonus + ebsalary) AS 最低薪资FROM employeeGROUP BY deptno;
获取平均薪资高于行政部的部门信息。 ```sql — 行政部的平均薪资 SELECT AVG(ebonus + ebsalary) AS avg_sal FROM employee GROUP BY deptno HAVING deptno = ( SELECT dno FROM dept WHERE dname = ‘行政部’ );
— 比行政部平均薪资高的部门编号 SELECT deptno FROM employee GROUP BY deptno HAVING AVG(ebonus + ebsalary) > ( SELECT AVG(ebonus + ebsalary) AS avg_sal FROM employee GROUP BY deptno HAVING deptno = ( SELECT dno FROM dept WHERE dname = ‘行政部’ ) );
— 平均薪资高于行政部的部门信息 SELECT * FROM dept WHERE dno IN ( SELECT deptno FROM employee GROUP BY deptno HAVING AVG(ebonus + ebsalary) > ( SELECT AVG(ebonus + ebsalary) AS avg_sal FROM employee GROUP BY deptno HAVING deptno = ( SELECT dno FROM dept WHERE dname = ‘行政部’ ) ) );
<a name="pv9ss"></a>### 1.6 DISTINCT去重- 引入案例:查询员工表中,有奖金的员工的职位。```sqlmysql> SELECT ejob FROM employee WHERE ebonus > 0;+--------+| ejob |+--------+| 经理 || 销售员 || 前台 || 销售员 |+--------+4 rows in set (0.00 sec)
- 可以发现这个查询结果中是有重复数据的,但是这个场景下其实并不需要这些重复数据。
因此,可以在查询字段前面加上
DISTINCT关键字进行去重。mysql> SELECT DISTINCT ejob FROM employee WHERE ebonus > 0;+--------+| ejob |+--------+| 经理 || 销售员 || 前台 |+--------+3 rows in set (0.00 sec)
除此之外,
DISTINCT关键字还可以用在单个字段上。如查询公司中职位的个数。 ```sql — 查看公司中职位的数据(不去重) SELECT ejob FROM employee;
— 查看公司中职位的数据(去重) SELECT DISTINCT ejob FROM employee;
— 统计职位的个数(去重后统计) SELECT COUNT(DISTINCT ejob) FROM employee;
<a name="Qn9Lw"></a>## 02. 连接查询<a name="UsYcg"></a>### 2.1 多表连接查询基础<a name="b1p21"></a>#### 2.1.1 连接查询概述- 连接查询可以简单理解为将多张表的数据按照一定的规则,整合到一张大表中,然后再进行查询操作。- MySQL中的连接查询有内连接、外连接、自连接、合并连接四种。<a name="ERwKO"></a>#### 2.1.2 最基本的连接(笛卡尔积连接)- MySQL中最基本的多表连接为笛卡尔积连接,其语法为:`SELECT * FROM table1, table2, ..., tableN;`- 这种连接的结果是一种笛卡尔积的形式,所谓的笛卡尔积为:- 假设表1有A、B、C三条数据,表2有1、2、3、4四条数据。- 那边笛卡尔积连接这两张表的语法为:`SELECT * FROM 表1, 表2;`- 结果为:A1、A2、A3、A4、B1、B2、B3、B4、C1、C2、C3、C4这十二条数据。- 笛卡尔积连接的弊端:- 这种连接虽然简单,但是会生成很多错误的冗余数据。- 因为笛卡尔积会对两张表中的每两条数据都进行一次关联,这种关联并不考虑两条数据之间是否真的存在联系。- 如`SELECT * FROM employee, dept;`的结果中,李鹏飞有四条记录,但是按理来说只应该有行政部一条记录,别的三条都是错误的冗余数据。- 笛卡尔积连接弊端的解决方案:设置连接条件,去除冗余数据。- 只有当员工表的deptno和部门表的dno的值相等时,才进行连接。- 因此`SELECT * FROM employee, dept;`应该改写为:```sql-- 这段代码实际上是一种内连接SELECT *FROM employee, deptWHERE employee.deptno = dept.dno;
2.2 内连接
- 内连接的用途:内连接用于查询两个表中均满足条件的数据。
内连接的语法格式一:(INNER JOIN可以省略成JOIN,两者都是内连接)(SQL99标准,推荐使用)
SELECT *FROM table1INNER JOIN table2……INNER JOIN tableNON 连接条件[WHERE 分组前的筛选][GROUP BY 分组字段][HAVING 分组后的筛选];
示例1:查询员工的姓名、职位、部门。
- 虽然dept表中有40运营部,但是employee表中没有deptno=40的员工。
- 因此40运营部不满足employee表,所以查询结果中没有40运营部相关的数据。
SELECT e.ename, e.ejob, d.dnameFROM employee AS eINNER JOIN dept AS dON e.deptno = d.dno;
内连接的语法格式二:(SQL92标准,知道即可,不推荐使用)
SELECT *FROM table1, table2, …, tableNWHERE 连接条件AND 筛选条件;
示例2:用语法格式二查询员工的姓名、职位、部门。
SELECT e.ename, e.ejob, d.dnameFROM employee AS e, dept AS dWHERE e.deptno = d.dno;
示例3:查看有员工的部门信息。 ```sql — 先查询员工名、部门编号、部门名 SELECT e.ename, d.dno, d.dname FROM employee AS e JOIN dept AS d ON d.dno = e.deptno;
— 然后对数据进行字段筛选、去重后即可得到需要的数据 SELECT DISTINCT d.* FROM employee AS e JOIN dept AS d ON d.dno = e.deptno;
- 示例4:获取平均薪资高于行政部的部门信息以及该部门对应的平均薪资。```sql-- 先获取员工表与部门表的连接表。SELECT * FROM employee AS eJOIN dept AS dON d.dno = e.deptno;-- 在第一步的基础上扩展:按部门进行分组,获取每个部门的平均薪资。SELECT d.*, AVG(e.ebsalary + e.ebonus) AS avg_salFROM employee AS e JOIN dept AS d ON d.dno = e.deptnoGROUP BY d.dno;-- 获取行政部的平均薪资SELECT AVG(e.ebsalary + e.ebonus) AS avg_salFROM employee AS e JOIN dept AS d ON d.dno = e.deptnoWHERE d.dname = '行政部';-- 结合二、三两步,得到最终结果SELECT d.*, AVG(e.ebsalary + e.ebonus) AS avg_salFROM employee AS e JOIN dept AS d ON d.dno = e.deptnoGROUP BY d.dnoHAVING avg_sal > (SELECT AVG(e.ebsalary + e.ebonus) AS avg_salFROM employee AS e JOIN dept AS d ON d.dno = e.deptnoWHERE d.dname = '行政部');
2.3 外连接
2.3.1 外连接概述
- 外连接可以分为左外连接、右外连接、全外连接(MySQL不支持)三种。
- SQL语法可以按年代分SQL92标准和SQL99标准。
- SQL92标准:MySQL对于SQL92语法仅支持内连接。
- SQL99标准(推荐):MySQL对于SQL99语法支持内连接、外连接(左外+右外,不支持全外)、交叉连接。
- 左外连接和右外连接的区别:
- 左外连接:左边的表显示全部信息,右边的表显示满足连接条件的信息;若右边的表数据少于左边的,则右边的表用NULL补齐。
- 右外连接:右边的表显示全部信息,左边的表显示满足连接条件的信息;若左边的表数据少于右边的,则左边的表用NULL补齐。
左、右外连接的选择方式:根据要显示全部信息的表的位置决定,如要显示全部信息的表在左边,那就用左外连接。
2.3.2 左外连接
左外连接语法格式:(
LEFT OUTER JOIN可以简写成LEFT JOIN)SELECT * FROM table1LEFT OUTER JOIN table2 ON 连接条件1LEFT OUTER JOIN table3 ON 连接条件2……LEFT OUTER JOIN tableN ON 连接条件(N-1)[WHERE 分组前筛选][GROUP BY 分组字段][HAVING 分组后筛选];
示例1:连接部门表和员工表。(可以发现,左表数据大于右表,因此右表会用NULL补齐)
mysql> SELECT * FROM dept AS d LEFT OUTER JOIN employee AS e ON d.dno = e.deptno;+-----+--------+------+--------+------+------+------------+------------+--------+----------+--------+| dno | dname | eno | ename | eage | esex | ejob | ehiredate | ebonus | ebsalary | deptno |+-----+--------+------+--------+------+------+------------+------------+--------+----------+--------+| 10 | 行政部 | 1 | 李鹏飞 | 32 | 男 | 经理 | 2016-11-12 | 5000 | 8000 | 10 || 10 | 行政部 | 2 | 王鹏飞 | 27 | 男 | 销售员 | 2018-10-20 | 2000 | 1000 | 10 || 10 | 行政部 | 6 | 徐华 | 33 | 女 | 销售员 | 2019-11-17 | 500 | 4000 | 10 || 20 | 财务部 | 3 | 肖美 | 24 | 女 | 前台 | 2019-03-21 | 500 | 5000 | 20 || 20 | 财务部 | 4 | 王乐乐 | 30 | 女 | 经理 | 2017-03-02 | 0 | 9000 | 20 || 20 | 财务部 | 5 | 张丽丽 | 28 | 女 | 行政人员 | 2019-11-11 | 0 | 5000 | 20 || 30 | 技术部 | 7 | 赵辉 | 40 | 男 | 经理 | 2016-11-17 | 0 | 50000 | 30 || 30 | 技术部 | 8 | 王伟 | 35 | 男 | 开发工程师 | 2018-11-28 | 0 | 30000 | 30 || 30 | 技术部 | 9 | 钱慧慧 | 28 | 女 | 开发工程师 | 2019-04-17 | 0 | 25000 | 30 || 40 | 运营部 | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL |+-----+--------+------+--------+------+------+------------+------------+--------+----------+--------+10 rows in set (0.00 sec)
- 实际上这里应该要显示的是员工表的全部数据,因此员工表适合在左外连接中当左表,部门表适合当右表。
mysql> SELECT * FROM employee AS e LEFT OUTER JOIN dept AS d ON d.dno = e.deptno;+-----+--------+------+------+------------+------------+--------+----------+--------+------+--------+| eno | ename | eage | esex | ejob | ehiredate | ebonus | ebsalary | deptno | dno | dname |+-----+--------+------+------+------------+------------+--------+----------+--------+------+--------+| 1 | 李鹏飞 | 32 | 男 | 经理 | 2016-11-12 | 5000 | 8000 | 10 | 10 | 行政部 || 2 | 王鹏飞 | 27 | 男 | 销售员 | 2018-10-20 | 2000 | 1000 | 10 | 10 | 行政部 || 3 | 肖美 | 24 | 女 | 前台 | 2019-03-21 | 500 | 5000 | 20 | 20 | 财务部 || 4 | 王乐乐 | 30 | 女 | 经理 | 2017-03-02 | 0 | 9000 | 20 | 20 | 财务部 || 5 | 张丽丽 | 28 | 女 | 行政人员 | 2019-11-11 | 0 | 5000 | 20 | 20 | 财务部 || 6 | 徐华 | 33 | 女 | 销售员 | 2019-11-17 | 500 | 4000 | 10 | 10 | 行政部 || 7 | 赵辉 | 40 | 男 | 经理 | 2016-11-17 | 0 | 50000 | 30 | 30 | 技术部 || 8 | 王伟 | 35 | 男 | 开发工程师 | 2018-11-28 | 0 | 30000 | 30 | 30 | 技术部 || 9 | 钱慧慧 | 28 | 女 | 开发工程师 | 2019-04-17 | 0 | 25000 | 30 | 30 | 技术部 |+-----+--------+------+------+------------+------------+--------+----------+--------+------+--------+9 rows in set (0.00 sec)
示例2:统计每个部门的人数。
-- 这里列出的应该是所有部门,因此部门表适合当左表。-- 注意:这里绝对不能使用`COUNT(*)`,只能使用`COUNT(字段名)`。-- 因为`COUNT(*)`会将NULL也统计在内,会导致数据错误。SELECT d.dno, COUNT(e.eno) FROM dept AS dLEFT OUTER JOIN employee AS e on d.dno = e.deptnoGROUP BY d.dno;
2.3.3 右外连接
右外连接语法格式:(
RIGHT OUTER JOIN可以简写成RIGHT JOIN)SELECT * FROM table1RIGHT OUTER JOIN table2 ON 连接条件1RIGHT OUTER JOIN table3 ON 连接条件2……RIGHT OUTER JOIN tableN ON 连接条件(N-1)[WHERE 分组前筛选][GROUP BY 分组字段][HAVING 分组后筛选];
示例1:连接员工表和部门表。(要显示的是员工表中的所有信息,因此员工表适合做右表)
SELECT * FROM dept AS d RIGHT OUTER JOIN employee AS e ON d.dno = e.deptno;
示例2:统计每个部门的人数。
SELECT d.dno, COUNT(e.eno) FROM employee AS eRIGHT OUTER JOIN dept AS d ON d.dno = e.deptnoGROUP BY d.dno;
2.3.4 外连接练习
查看每个学生的总成绩,展示的信息有学生信息与总成绩。
-- 查询的是每个学生的成绩,那么应该列出所有学生的信息-- 因此若采用左外连接,则学生表适合做左表-- 补充知识点:IFNULL(字段值, 指定数据)表示若字段值为空,则只用指定数据参与运算;否则使用该字段本身的值进行运算。SELECTstu.*,IFNULL(SUM(sco.score), 0) AS 总成绩FROM student AS stuLEFT OUTER JOIN score_tb AS sco on stu.sno = sco.snoGROUP BY stu.sno;
查看每个学生的选课信息,展示的信息有学号、姓名、课程名、成绩。
SELECTstu.sno,stu.sname,IFNULL(c.cname, '无') AS 课程名,IFNULL(sco.score, 0) AS 成绩FROM student AS stuLEFT JOIN score_tb AS sco ON stu.sno = sco.snoLEFT JOIN course AS c on c.cid = sco.cid;
2.4 自连接
自连接概述:
- 多表连接是一张表去连接其他表,而自连接就是一张表自己连接自己。
- 自连接实际上是内连接的一种表现,因此在语法上使用
JOIN关键字连接。
- 示例1:查询出10001课程高于10002课程的学生信息。
```sql
— 将学生的10001课程成绩与10002课程成绩连接在一起
SELECT *
FROM score_tb AS s10001
JOIN score_tb AS s10002
ON s10001.sno = s10002.sno — 将两张score_tb表通过相同的学号连接起来
AND s10001.cid = 10001 -- s10001只取课程号为10001的数据参与连接AND s10002.cid = 10002; -- s10002只取课程号为10002的数据参与连接
— 筛选出10001课程高于10002课程的学生学号。 SELECT s10001.sno FROM score_tb AS s10001 JOIN score_tb AS s10002 ON s10001.sno = s10002.sno AND s10001.cid = 10001 AND s10002.cid = 10002 WHERE s10001.score > s10002.score;
— 用子查询获取步骤二中得到的学号对应的学生信息 SELECT * FROM student WHERE sno IN ( SELECT s10001.sno FROM score_tb AS s10001 JOIN score_tb AS s10002 ON s10001.sno = s10002.sno AND s10001.cid = 10001 AND s10002.cid = 10002 WHERE s10001.score > s10002.score );
- 示例2:查询员工所在部门的部门经理,显示信息有员工编号、员工姓名、部门编号、经理姓名。```sqlSELECTemp.eno,emp.ename,emp.deptno,mana.enameFROM employee AS emp JOIN employee AS manaON emp.deptno = mana.deptno -- 将两张employee表通过相同的部门编号连接起来AND emp.ejob != '经理' -- 员工表只取职位不是经理的数据参与连接AND mana.ejob = '经理'; -- 经理表只取职位是经理的数据参与连接
总结:自连接看似是连接两张表,实则连接的是一张实表定义出的两张虚表。
2.5 合并连接
UNION合并查询可以将多条查询语句的结果合并成一个结果。
UNION合并查询语法格式:
查询语句1UNION查询语句2……UNION查询语句n
联合查询应用场景:要查询的信息来自于多张表,且这些表中间没有之间的关联关系,但查询的信息一致时,就可以考虑使用联合查询。
- 联合查询注意特点:
- 要求所有查询语句的查询字段数量是一致的。(否则语法不通过)
- 每条查询语句中查询列表的顺序要一一对应。(否则数据无意义)
- 如果多条语句间得到的结果集有重复项,UNION联合查询会自动去重。(如果不想去重可以将UNION改写成UNION ALL)
- 示例:查询20号部门和30号部门的员工信息。 ```sql — 查询20号部门的员工信息。 SELECT * FROM employee WHERE deptno = 20;
— 查询30号部门的员工信息。 SELECT * FROM employee WHERE deptno = 30;
— 查询20号部门和30号部门的员工信息。(即将前面两个结果结合起来) SELECT FROM employee WHERE deptno = 20 UNION SELECT FROM employee WHERE deptno = 30;
<a name="wef3V"></a>## 03. 窗口函数及排序、分页<a name="OZ2pH"></a>### 3.1 窗口函数<a name="MUQWD"></a>#### 3.1.1 窗口函数概述- 窗口函数是MySQL 8.0开始新增的特性。- 窗口函数的应用场景:(常用于数据分析场景)- 第一类:TopN排名问题。(如查询每门课成绩的前三名)(MySQL 5.x的排名问题在06. MySQL高级操作 -- 6.3中介绍)- 第二类:将表中的某一指标与分组后的数学指标进行对比。(如查询低于课程平均分的成绩)- 第三类:累计问题。(如查询某一季度的销售额问题)- 窗口函数的语法格式:- PARTITION BY:用于将数据根据指标进行归纳,类似于GROUP BY分组,但二者存在着差异:- GROUP BY会改变结果显示的行数。(相当于按照指定的字段,把同一组数据折叠在一起)- PARTITION BY不会改变结果显示的行数,原表是几行它就会显示几行。(只不过是把同组中的数据归纳在一起,并纵向连接罢了)- ORDER BY:用于对数据基于指定的字段进行排序,其实ASC代表升序、DESC代表降序;ORDER BY后面可以指定多个字段,用于实现多字段排序。- 注意:一般来说只有TopN排名问题需要排序。- 数学指标问题不需要排序,只需要用`PARTITION BY`归类即可。- 而累计销售额这类问题则只需要排序,没有归纳一说。```sql窗口函数 OVER(PARTITION BY 分组字段1, 分组字段2, .. 分组字段nORDER BY 排序字段 ASC|DESC)
3.1.2 TopN排名窗口函数
- 与TopN排名相关的窗口有以下三个:
- ROW_NUMBER():采用1234的方式进行排序;即没有并列名次。
- RANK():采用1224的方式进行排序;即有并列名次,并且并列名次会占用一个正常的名次。
- DENSE_RANK():采用1223的方式进行排序;即有并列名次,并且并列名次不会占用一个正常的名次。
- 示例1:对每门课的成绩进行降序排名。 ```sql — 用1234排序模型 SELECT cid, sno, ROW_NUMBER() OVER ( PARTITION BY cid ORDER BY score DESC ) AS 排名 FROM score_tb;
— 采用1224排序模型 SELECT cid, sno, RANK() OVER ( PARTITION BY cid ORDER BY score DESC ) AS 排名 FROM score_tb;
— 采用1223排序模型 SELECT cid, sno, DENSE_RANK() OVER ( PARTITION BY cid ORDER BY score DESC ) AS 排名 FROM score_tb;
- 示例2:对班级中的学生按照其总成绩进行1234模式的降序排名。```sql-- 查询每个学生的总成绩SELECTstu.sno,stu.cno,stu.sname,IFNULL(SUM(sco.score), 0) AS totalFROM student AS stuLEFT OUTER JOIN score_tb AS sco on stu.sno = sco.snoGROUP BY stu.sno;-- 根据第一步的结果,按照总成绩进行排名SELECT *, ROW_NUMBER() OVER (PARTITION BY cno -- 显示的是每个班级的排名,所有应该按照班级分组ORDER BY total DESC -- 每个班级中排名的依据是总成绩) AS rankingFROM (SELECT stu.cno, stu.sno, stu.sname, IFNULL(SUM(sco.score), 0) AS totalFROM student AS stu LEFT OUTER JOIN score_tb AS sco on stu.sno = sco.snoGROUP BY stu.sno) AS tmp_table;
示例3:对部门中的员工按照薪资进行排名。
SELECTe.ename,e.deptno,(e.ebonus + e.ebsalary) AS total_sal,ROW_NUMBER() OVER (PARTITION BY deptnoORDER BY (ebonus + ebsalary) DESC) AS rankingFROM employee AS e LEFT OUTER JOIN dept AS d ON d.dno = e.deptno;
示例4:将公司中所有的员工按照薪资进行排名。(这里的排名不涉及分组,因此可以省略
PARTITION BY了)SELECT *, ROW_NUMBER() OVER (ORDER BY (ebonus + employee.ebsalary) DESC) AS ranking FROM employee;
3.1.3 取前N名
使用
SELECT 查询字段 FROM (TopN查询语句) AS topn WHERE 前N的取值范围;可以获取到排名在前N名的数据。示例1:查询每个部门中工资最高的员工名、部门编号及薪资。
SELECT ename, deptno, (ebonus + ebsalary) AS total_sal FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY (ebonus + ebsalary) DESC) AS rankingFROM employee AS e LEFT OUTER JOIN dept AS d ON d.dno = e.deptno) AS topnWHERE ranking = 1;
示例2:查询每门课排名前三的分数的课程编号、学号、分数以及排名。
SELECT * FROM (SELECT cid, sno, score,ROW_NUMBER() OVER (PARTITION BY cid ORDER BY score DESC) AS rankingFROM score_tb) AS topnWHERE ranking <= 3;
3.1.4 聚合窗口函数
SQL中的大部分分组函数都可以用在窗口函数中,如:
SUM()、COUNT()、MAX()、MIN()、AVG()等等。- 示例1:查询低于对应课程平均分的课程分数。
- 不用窗口函数实现: ```sql — 查询每门课程的平均分 SELECT cid, AVG(score) AS avg_sco FROM score_tb GROUP BY cid;
— 将成绩表与第一步的结果连接起来 SELECT * FROM score_tb INNER JOIN ( SELECT cid, AVG(score) AS avg_sco FROM score_tb GROUP BY cid ) AS avg_t ON score_tb.cid = avg_t.cid;
— 过滤出分数低于平均分的成绩 SELECT * FROM score_tb INNER JOIN ( SELECT cid, AVG(score) AS avg_sco FROM score_tb GROUP BY cid ) AS avg_t ON score_tb.cid = avg_t.cid WHERE score_tb.score < avg_t.avg_sco;
- 使用窗口函数实现:```sql-- 用窗口函数查询出课程的平均分SELECT*,-- 此时只需要求出平均数指标,不需要用ORDER BY进行排序AVG(score) OVER(PARTITION BY cid) AS avg_scoFROM score_tb;-- 过滤出分数低于平均分的成绩SELECT * FROM (SELECT *, AVG(score) OVER(PARTITION BY cid) AS avg_sco FROM score_tb) AS tmpWHERE score < avg_sco;
- 示例2:查询低于部门平均薪资的员工信息。 ```sql — 用分组函数获取部门的平均薪资。 SELECT *, AVG(ebsalary + ebonus) OVER ( PARTITION BY deptno ) AS dept_avg_sal FROM employee;
— 过滤出薪资低于部门平均薪资的员工信息。 SELECT FROM ( SELECT , AVG(ebsalary + ebonus) OVER ( PARTITION BY deptno ) AS dept_avg_sal FROM employee ) AS tmp WHERE (ebsalary + ebonus) < dept_avg_sal;
- 总结:`GROUP BY`会将同一组数据聚合,若在查询过程中不想减少行数据,就需要用窗口函数。<a name="lgcqP"></a>#### 3.1.5 LAG/LEAD取前后N行的数据- LAG/LEAD也是两个窗口函数,由于获取其他行的数据。具体语法格式:- `LAG(col, N, value) OVER(PARTITION BY 分区字段 ORDER BY 排序字段 ASC|DESC)`:用于获取当前行向前偏移N行的col字段的数据,若前N行不存在,则返回默认值value。- `LEAD(col, N, value) OVER(PARTITION BY 分区字段 ORDER BY 排序字段 ASC|DESC)`:用于获取当前行向后偏移N行的col字段的数据,若后N行不存在,则返回默认值value。- 示例1:现有1~6六行数字数据,获取每个数字的前一个数字和后一个数字。```sqlDROP TABLE IF EXISTS number;CREATE TABLE IF NOT EXISTS number (num INT);INSERT INTO number VALUES (1), (2), (3), (4), (5), (6);SELECT *,LAG(num, 1, NULL) OVER() AS head_line,LEAD(num, 1, NULL) OVER() AS next_lineFROM number;
- 示例2:查看用户在某天刷题后第二天还会再来刷题的平均概率。
``sql -- 数据准备。 DROP TABLE IF EXISTSquestion_practice_detail; CREATE TABLE IF NOT EXISTSquestion_practice_detail(idint NOT NULL,device_idint NOT NULL,question_idint NOT NULL,resultvarchar(32) NOT NULL,date` date NOT NULL ); INSERT INTO question_practice_detail VALUES (1, 2138, 111, ‘wrong’, ‘2021-05-03’), (2, 3214, 112, ‘wrong’, ‘2021-05-09’), (3, 3214, 113, ‘wrong’, ‘2021-06-15’), (4, 6543, 111, ‘right’, ‘2021-08-13’), (5, 2315, 115, ‘right’, ‘2021-08-13’), (6, 2315, 116, ‘right’, ‘2021-08-14’), (7, 2315, 117, ‘wrong’, ‘2021-08-15’), (8, 3214, 112, ‘wrong’, ‘2021-05-09’), (9, 3214, 113, ‘wrong’, ‘2021-08-15’), (10, 6543, 111, ‘right’, ‘2021-08-13’), (11, 2315, 115, ‘right’, ‘2021-08-13’), (12, 2315, 116, ‘right’, ‘2021-08-14’), (13, 2315, 117, ‘wrong’, ‘2021-08-15’), (14, 3214, 112, ‘wrong’, ‘2021-08-16’), (15, 3214, 113, ‘wrong’, ‘2021-08-18’), (16, 6543, 111, ‘right’, ‘2021-08-13’);
— 查询出用户设备ID和日期(要去重) SELECT DISTINCT device_id, date FROM question_practice_detail;
— 从去重的设备日期表中,按照设备分区,按照日期排序,查询出每一条记录的下一条记录的日期。 SELECT device_id, date AS date1, LEAD(date, 1, NULL) OVER (PARTITION BY device_id ORDER BY date) AS date2 FROM ( SELECT DISTINCT device_id, date FROM question_practice_detail ) AS uniq_id_date;
— 若当前行的日期与下一行的日期相差1天,则认为是符合要求的数据,否则就不是。 — 将符合要求的数据标为1,不符合的数据标为0。 — 求标记的平均值。 SELECT AVG(IF(DATEDIFF(date2, date1) = 1, 1, 0)) AS avg_ret FROM ( SELECT device_id, date AS date1, LEAD(date, 1, NULL) OVER (PARTITION BY device_id ORDER BY date) AS date2 FROM ( SELECT DISTINCT device_id, date FROM question_practice_detail ) AS uniq_id_date ) AS id_date1_date2;
<a name="uuSRx"></a>### 3.2 排序查询- 排序查询实际上并不是一种查询,它只是对查询完的结果按照一些指标进行升序或者降序排序的操作。- 排序语法:ASC代表升序,可以省略;DESC是降序,不可以省略。```sqlSELECT 查询字段FROM 表 [连接][WHERE 分组前过滤][GROUP BY 分组字段][HAVING 分组后过滤]ORDER BY 排序字段 ASC|DESC, [排序字段2, ASC|DESC …];
示例1:将学生信息按照生日从大到小排序。
- 注意:对于日期数据而言,日期越大,值越小。
- 比如2000-01-13的生日要比2002-08-11的生日要大,但是从值上来看2000-01-13是小的值。
SELECT * FROM studentORDER BY birthday ASC;
示例2:将员工数据按照底薪进行升序排序,若底薪一样的,则按照员工编号进行降序排序。
SELECT * FROM employeeORDER BY ebsalary ASC,eno DESC;
3.3 分页查询
分页查询常用于数据量较大的场景中,可将大量数据分批显示。
- 分页查询的语法格式:
- 形式一:
SELECT查询语句 LIMIT 行数;,表示从第一行开始,显示指定行数的数据。 - 形式二:
SELECT查询语句 LIMIT 起始位置, 行数;,表示从指定行索引开始,显示指定行数的数据。(行索引从0开始) - 形式三:
SELECT查询语句 LIMIT N OFFSET M;,表示跳过M行,显示N行的数据。
- 形式一:
示例1:显示成绩表中前10条数据。
SELECT * FROM score_tb LIMIT 10;
示例2:用行索引的方式显示成绩表中的第11~15条数据。(起始行索引为10,行数为5)
SELECT * FROM score_tb LIMIT 10, 5;
示例3:用
OFFSET的方式显示成绩表中的第11~15条数据。(跳过10行,并显示5行数据)SELECT * FROM score_tb LIMIT 5 OFFSET 10;

若有收获,就点个赞吧
0 人点赞
