01. 爬虫简介
1.1 网络数据采集概念
- 网络数据采集指的就是爬虫程序,简称爬虫,也称为Spider蜘蛛程序。
- 爬虫属于数据分析流程中第二部分“获取数据”的内容,主要用于自动化批量获取网上的既有数据。
- 自动化:所谓自动化就是编程,让编程自动去完成一些工作。
- 批量:假如就只需要获取一两条数据,那其实根本没有必要去写一个爬虫程序;爬虫重复常用来获取大量的数据。
- 既有:爬虫只能用来获取网站中提供的数据,对于网站不提供的数据法律是不允许采集的。
- 获取网站不提供的数据本质上不能被称为爬虫,而是一种渗透行为。未经许可的渗透行为都是违法的。
- 除此之外,爬虫还有可能造成其他违法行为,如一次分布式爬虫把网站服务器爬瘫痪了,对网站公司的运营造成了损失,这就是一种违法行为。
- 当然了,网站中提供的数据并不仅指页面中提供的数据;只要网站服务器中存在的数据,爬虫程序都可能有办法获取得到。
- 爬虫合法性总结:爬虫程序本身的不违法的,但爬虫可能会造成一些违法的后果。因此,开发者一定要在合法的范围内使用爬虫程序。
相对于人类正常上网获取数据而言,爬虫主要针对于批量、高效的数据获取,因此对于获取小量的数据而言,爬虫没有任何优势。
1.2 爬虫程序工作的基本流程
数据获取:模拟人类发起上网请求,并获取网页响应的数据(网页的数据由HTML进行组织)。
- 补充:很多网站都会有反扒机制。当爬虫程序模拟的越像人,被反扒机制检测到的概率越低。
- 数据提取:从HTML中提取出相关的数据,常用的提取方式有:正则表达式匹配、CSS选择器提取、XPath路径获取。
数据存储:对获取到数据进行存储,常见的存储方式有:非文字(二进制存储),文字(Excel文件、CSV文件、数据库)。
1.3 爬虫合法性探究
1.3.1 爬虫可能文法
爬虫这门技术本身在法律中是不被禁止的,但这门技术在使用过程中存在违法犯罪的风险。
由于爬虫技术的发展和互联网法规的完善,近几年因爬虫程序面临牢狱之灾的开发者不在少数。因此在正式学习爬虫之前,了解相关的法律知识是十分有必要的。
1.3.2 涉及违法犯罪行为的爬虫
配合爬虫使用黑客技术对网站进行攻击行为。
- 使用爬虫窃取网站未公开的、私密的、受到法律保护的数据。
-
1.3.3 爬虫开发者如何避免违法犯罪
数据脱敏:涉及到个人隐私的敏感数据(如网站用户的手机号码、身份证号码、邮箱地址、家庭住址等)以及涉及商业机密的数据不要爬,容易触碰法律的红线。
- 不要公开招标:有些技术你可以用,但是不要拿到明面上来公开招标盈利,否则就可能犯罪。
- 如之前有个很火的新闻,一个研究生用爬虫程序帮她女朋友抢HPV的九价疫苗。
- 这本身没什么问题,但是这个研究生后续将这项技术公开招标,用收费帮人抢疫苗来盈利。
- 这时那些没有抢到疫苗的人就把他举报了,因为他不仅打破了市场的公平,还以此盈利。
- 再比如02. 基础爬虫技术 — 04. Cookie、JSON、XPath — 1.3 自动刷粉中介绍的自动批量刷粉丝,包括相关的刷评论、刷点赞这些生意其实都可以做,但是不能拿到明面上来做。因为这种程序说轻点那确实没什么,但要是往重了说,那属于控制舆论的行为了,因此一定要注意。
不要响应企业的正常运转:这种情况尤其针对分布式多线程爬虫,一个多线程高并发的爬虫程序很容易会把网站的后台服务器爬崩溃,那人家企业是要靠这个网站来赚钱的,你的程序把人家的服务器爬崩溃了,那么由此造成的损失肯定要有你来负责。
1.4 常见的爬扒机制
1.4.1 反爬机制与反反爬策略
一些门户网站通过相应的策略和技术手段,达到防止爬虫程序进行数据爬取的目的。
- 这些阻止数据爬取的一些列手段就被称为反爬机制。
- 反反爬策略与反爬机制是一套对立的程序。
反反爬策略就是指爬虫程序通过一系列的技术手段,破解门户网站建立的爬虫机制,从而技术达到数据爬取的目的。
1.4.2 robots协议
rebots协议是90年代就出现的一种反爬机制,它规定了网站中哪些内容是可以被爬取,哪些内容是不能够被爬取的。
- rebots协议可以在主观上去遵守,也可以不遵守,直接无视。因此robots协议也被称为君子协议。(为了不引火烧身,建议开发者还是要遵守robots协议的)
- robots协议的地址一般就是
网站URL/robots.txt,以淘宝为例:- 淘宝网的首页网址为:https://www.taobao.com/
- 那么淘宝的robots协议的地址为:https://www.taobao.com/robots.txt
- 在robots.txt中,Allow的内容是允许爬取的,Disallow的内容是不允许爬取的。
补充:一个规范的网站应该有robots.txt协议,但是国内外大部分的小网站都没有这个协议(主要还是因为建站者不懂爬虫)。
1.4.3 封IP
出现原因:访问频率过快。
- 解决方式一:比如爬一条数据,休眠一会,不要一下载爬几万条。
- 解决方式二:有些网页会采用分页显示数据,可以增加一次请求的数据总量,降低请求的次数。
-
1.5 爬虫的分类
1.5.1 通用爬虫
是搜索引擎抓取系统的重要组成部分,如百度、谷歌等的搜索引擎都会有一套抓取系统(本质上就是一套通用爬虫)。
通用爬虫的一大特性是其抓取的是互联网中一整张完整的页面数据。
1.5.2 聚焦爬虫
聚焦爬虫建立在通用爬虫之上。
- 聚焦爬虫抓取的是页面中特定的局部内容,一般就是爬虫使用者所需要的数据。
-
1.5.3 增量式爬虫
增量式爬虫用于检测网站中数据更新的情况。
-
1.5.4 暗网爬虫
暗网爬虫可以是通用爬虫,也可以是聚焦爬虫,还可以是增量式爬虫。
- 为什么把暗网爬虫独立出来呢?主要是因为它爬的领域比较特殊——暗网。
- 平时我们能访问到的网络资源只占整个网络的4%,剩下的96%都是普通人无法访问到的,这96%的内容被称为暗网。

- 暗网是指隐藏的网络,普通网民无法通过常规手段搜索访问,需要使用一些特定的软件、配置或者授权等才能登录。
- 由于暗网具有匿名性等特点,容易滋生以网络为勾联工具的各类违法犯罪。
- 记者在中国裁判文书网上搜索显示,涉暗网的案件共有21例,涉及贩卖毒品、传播色情恐怖非法信息、侵害公民个人信息等犯罪行为。
- 实际上涉暗网的案件可能远远不止21列,但是由于暗网加密等级极高,路由跳转极其复杂,所以溯源难度特别大,网警很难侦破。
- 比特币为什么那么火那么珍贵,实际上也与暗网有着脱不开的关系。比特币的特点就是不好溯源,因此暗网中绝大多数的交易都通过比特币完成。
- 普通人尽量不要去碰暗网,因为据说国家养了一批网络安全工程师在暗网中“钓鱼执法”,你想在暗网中干点什么坏事,可能直接就被抓起来了。所以哪怕你有进暗网的技术能力,也要做个遵纪守法的好公民。
-
02. 基本的网络概念
2.1 客户端与服务器
客户端:客户端就是供给用户使用的一端,最主要的作用就是对服务器发起请求,并组织与显示服务器响应的数据。
服务端:主要用于存储网站的数据与响应客户端的请求。
请求:客户端连接服务器并向服务器传达需要哪些数据,这个过程叫做请求。
- 响应:服务器把客户端请求的数据发送给客户端的过程称之为响应。

2.3 协议与请求
2.3.1 URL与协议
- URL即统一资源定位符(Uniform Resource Locator),用于用字符串的形式表示网络中资源的具体位置(即定位网络资源)。
URL的格式为:
协议://服务器地址或域名:端口号/资源路径?参数#锚点
协议(Schema)的基本概念:客户端和服务器之间传递数据需要遵守一定的规则,这种传输规则就称之为协议。
- 参数:
- 官方名称为查询参数,也有人称之为GET请求参数,因为一般来说只有HTTP/HTTPS协议中的GET请求会有这个东西。
- 参数是以键值对的形式出现的,多个参数之间用与符号
&连接:?Key0=Value0&Key1=Value1&……。
锚点(footer):常用于定位网页中的位置。(注意:只有当页面中存在锚点时才可以使用)
2.3.2 常见的应用层协议
FTP(File Transfer Protocol):文件传输协议。FTP会使用两个TCP连接(需要开启TCP的21号端口来建立控制连接,20号端口来建立数据连接)。
- HTTP(Hypertext Transfer Protocol):超文本传输协议(又称请求响应协议),HTTP协议使用80端口。
- HTTPS(Hyper Text Transfer Protocol over SecureSocket Layer):在HTTP的基础上再加了一层SSL协议,即加密版的HTTP协议。
- 现在一般的网站都会使用HTTPS协议,因为HTTPS用SSL协议进行加密,使得数据传输更加安全。
- HTTPS协议使用443端口。
SSH(Secure Shell):安全外壳协议,连接Linux远程服务器一般都使用SSH协议。SSH协议使用的默认监听端口是22。
2.3.3 GET/POST请求方式
在网站中客户端向服务器发送请求时一般用的都是HTTP协议,HTTP协议中大概有十几种请求方法,如:GET、POST、PUT、PATCH、DELETE、HEAD、OPTIONS。
- 而HTTP协议中最常见的两种请求方式就是GET和POST,而GET则是最最常见的。
- GET请求简介:
- GET请求转换成中文是获取的意思,常用于客户端想从服务器中获取某些数据的场景。
- GET请求的特点:
- GET的地址:
服务器IP地址[+?+请求参数]。 - 请求参数的格式:
key1=value&key2=value2&……&keyN=valueN。 - GET是明文传输的,不安全。
- GET有长度限制,当表单值超过100个字符时,超出的部分会被丢弃。
- GET不能发送非ASCII的值。
- GET的地址:
POST请求简介:
互联网中的终端设备是通过IP地址来标识的(服务器、个人PC、手机等都是终端设备)。
- 客户端要与服务器通信,首先要相互知道对方在哪里,此时就可以用IP地址来唯一标识一台互联网中的设备。
- IP地址分为IPv4地址(如
201.23.193.53)和IPv6地址(如fe80::40e5:b3f9:6be6:9a8d%23)。 - 不管那种版本的地址(尤其是IPv6),对人类来说都比较难以记忆,因此就出现了适合人类阅读基于的域名。
- 百度的域名为:
www.baidu.com,其对应的IP为36.152.44.95。
- 百度的域名为:
通过域名与网络中另一台设备通信时,网络首先会通过DNS服务器解析出域名对应的IP,再通过IP与目的设备进行通信。
2.3.5 资源路径
资源路径用于区分同一台网络设备中不同的网络资源。
- 资源路径类似于一台计算机中不同的目录,同一台计算机中不同目录下存放的文件是不同的。
-
2.4 HTTP协议
2.4.1 HTTP协议介绍
HTTP(Hypertext Transfer Protocol)超文本传输协议(又称请求响应协议),是在网络中传输数据需要遵守的一系列规则。
根据网络的不同阶段,HTTP协议可细分为HTTP请求协议和HTTP响应协议。
2.4.2 HTTP协议请求
在用户上网的过程中,浏览器给后台服务器发送的每一个请求都可以被监测到,监测方式:右键网页 >> 检查 >> Network(快捷键F12)。
- 打开后,用搜索引擎发起一次搜索或者直接访问一个网络地址,就可以监测到这次HTTP请求。
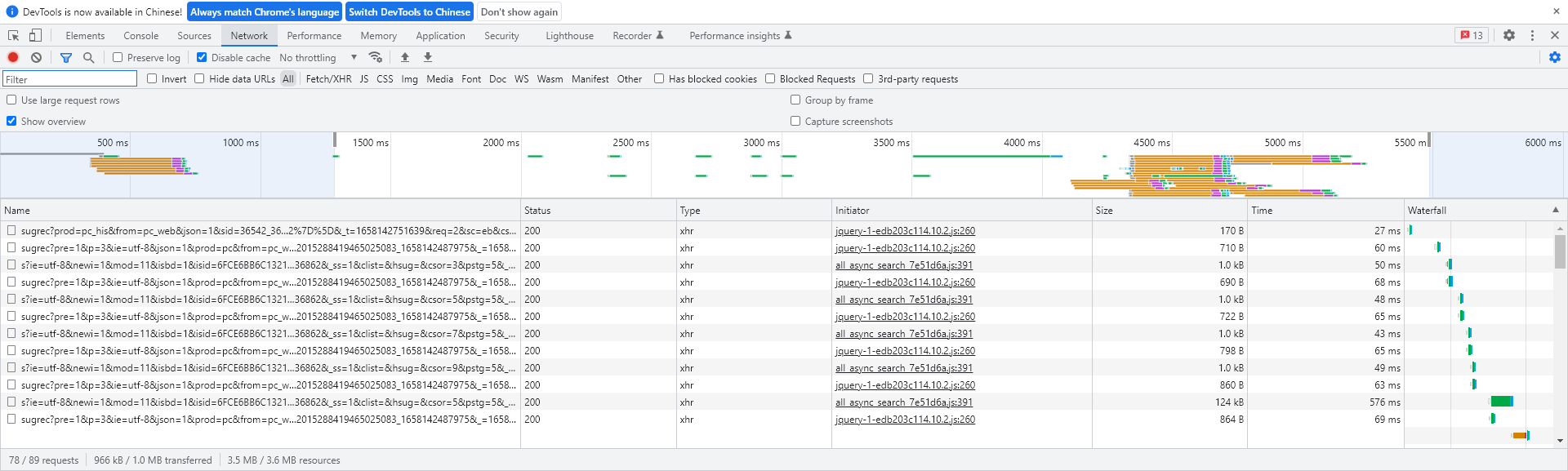
- 点击其中的一个网络资源,在点击Header就可以看到HTTP协议的相关内容(包括General、Response Headers、Requests Header)的详细信息,其中Requests Header就是HTTP请求信息。
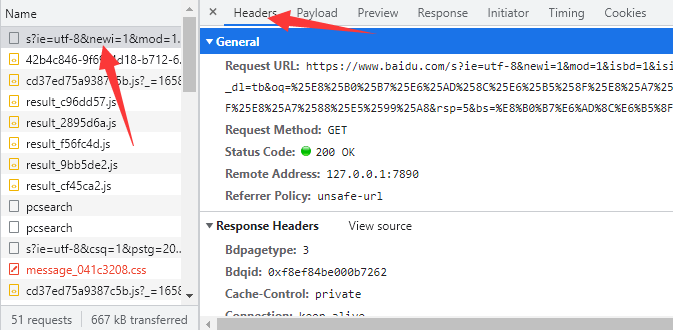
- HTTP请求由四部分组成:请求行、请求头、空行、请求体。
如,在百度搜索链家,就会得到类似于以下的HTTP请求信息:
- 请求行:GET /s HTTP/1.1
- 请求方式:GET
- 资源路径/s
- 协议与版本号:HTTP/1.1
- 请求头:以键值对的形式传递关于客户端的一些要求信息、标记信息,以及设备信息,如:
- Accept:表示客户端可以接收的响应数据格式,如超文本文档(text/html)、xhtml+xml、xml等。
- Accept-Encoding:表示客户端接受的响应数据压缩格式,如gzip压缩格式。
- Accept-Language:表示客户端接受的数据语言,如zh-CN,zh表示接受中文数据。
- Cookie:是客户端存储的一种标记状态,主要用于将Cookie值传递给服务器,帮助服务器进行一些验证操作的。
- Cookie产生的原因是因为HTTP是无记忆的。Cookie是用户唯一标识,也可以用于数据存储。
- 比如有些操作需要登录才能执行,但是HTTP无记忆,若没有Cookie,那么就算是用户已经登录过了,服务器也不会知道。
- 有了Cookie,当用户登录成功时,服务器会通过Cookie把登录成功的标记响应给客户端,客户端再次发起请求时,就会携带这个已经登录的标记,此时服务器就知道该用户已经登录过了。
- Host:服务器的IP地址或者域名。
- User-Agent:用户代理,即客户端发送请求时的设备信息。如下是Windows 64位的操作系统,AppleWebKit的内核,Chrome浏览器。
- Referer:上一个页面。比如用百度搜索英雄联盟,然后进入LOL的官网,那么此时Referer的值就可能为https://www.baidu.com/。
- 空行:用于分割请求头和请求体。
- 请求体(GET是没有的,只有POST有):比如某个用户在使用某个社交软件时要上传一个头像,那么这个头像就会被放在请求体中。
GET /s HTTP/1.1Accept: text/html,application/xhtml+xml,application/xml;q=0.9Accept-Encoding: gzip, deflate, brAccept-Language: zh-CN,zh;q=0.9Cache-Control: max-age=0Connection: keep-aliveCookie: BAIDUID=11C1A8285A5C0B0901925F7543C44DBE:FG=1; BIDUPSID=11C1A8285A5C0B09A47060DDD6834684; PSTM=1636856773; BD_UPN=12314753Host: www.baidu.comUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36
- 请求行:GET /s HTTP/1.1
补充,完整抓取请求头的流程:F12 >> Netch >> All >> 刷新页面 >> 点击网络资源 >> Headers >> Request Headers >> View source。
2.4.3 HTTP协议响应
Header中的Response Headers就是HTTP响应信息。
- HTTP响应也由响应行、响应头、空行、响应体这四部分组成。如百度搜索链家的HTTP响应信息:
- 响应行:
- 协议及其版本号:HTTP/1.1
- 响应状态码:200
- 响应状态码的描述信息:200
- 响应头:以键值对的形式描述响应的信息与一些返回标记。
- Content-Encoding:响应数据的压缩方式。
- Content-Type:响应数据的数据类型。
- Date:响应时间。
- Set-Cookie:服务器返回的Cookie标记,让客户端进行存储。
- 空行:分割响应头和响应体。
- 响应体:服务器正对于HTTP请求响应给客户端的实际数据。 ```bash HTTP/1.1 200 OK Content-Encoding: br Content-Type: text/html;charset=utf-8 Date: Fri, 20 May 2022 03:00:20 GMT Server: BWS/1.1 Set-Cookie: delPer=0; path=/; domain=.baidu.com Set-Cookie: BD_CK_SAM=1;path=/
- 响应行:
2.4.4 常见的HTTP响应码
- 常见的HTTP网络请求响应状态码可以分为几个大类:2XX(成功)、3XX(重定向)、4XX(客户端错误)、5XX(服务器错误)。
常见的HTTP网络请求响应状态码有:
-
3.1 鼠标小手
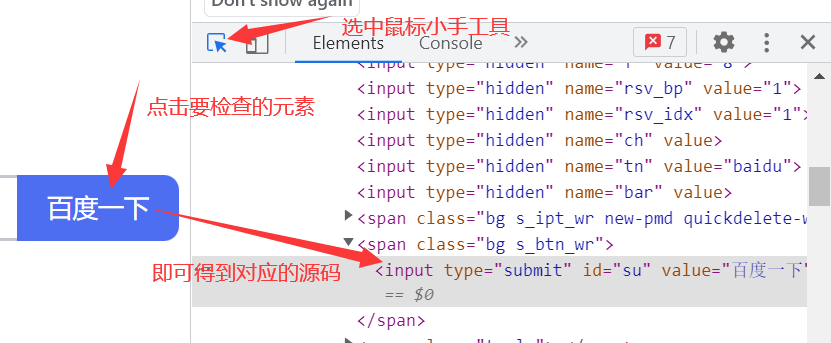
在浏览器调试工具左上角处有一个鼠标小手工具,可以用来定位元素在页面中的位置。
- 这个工具用于在页面中选择一个元素并检查它(查看它的源码以及其他相关信息)。
3.2 Elements元素界面
- Elements页面中有整个网页的源码,以及网页中每个元素的相关信息(如CSS、事件监听器等)
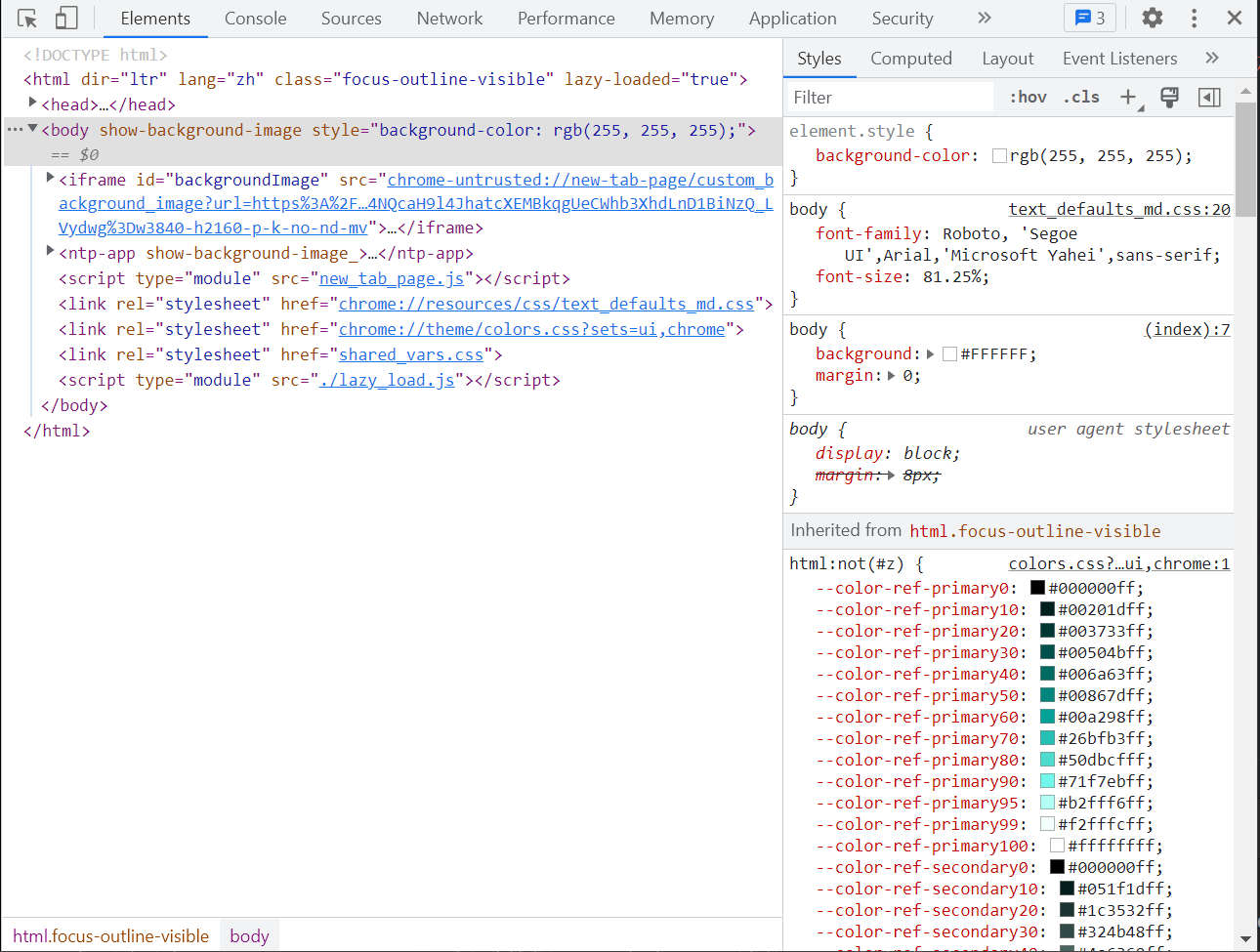
注意:
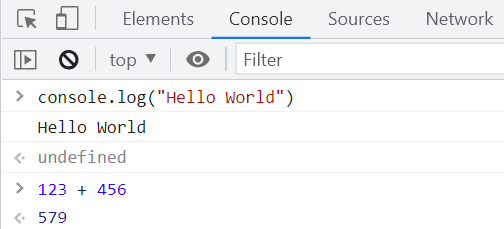
Console是一个控制台,是命令行工具。
- 在console中可以输入JavaScript代码,并以交互式的形式执行。
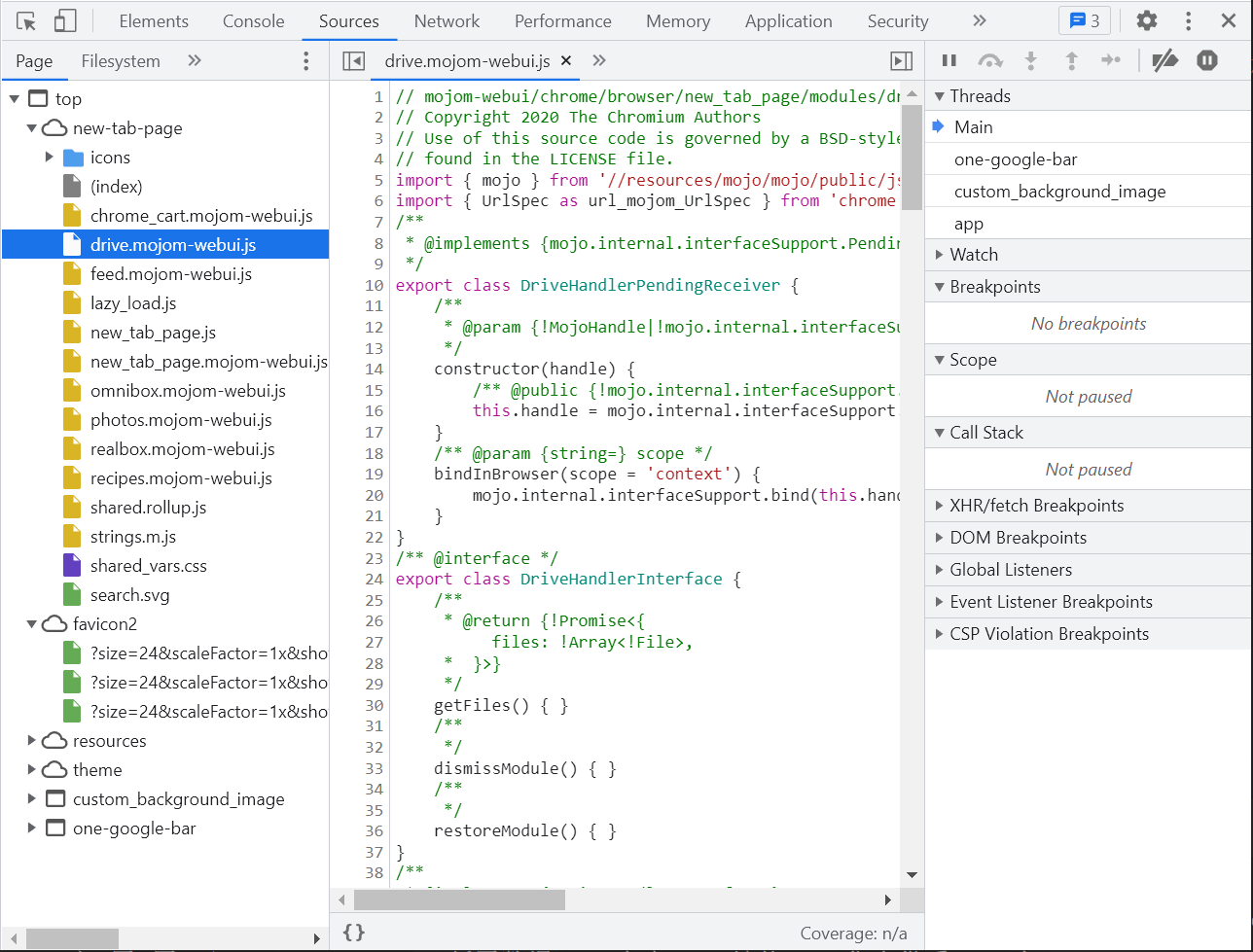
3.4 Source原始资源界面
- 网页的原始内容(包括网页的工程源码以及网页中的各种资源)。
3.5 Network网络映像界面
- 浏览器中的所有的网络请求映像、响应映像都会被记录在这里。
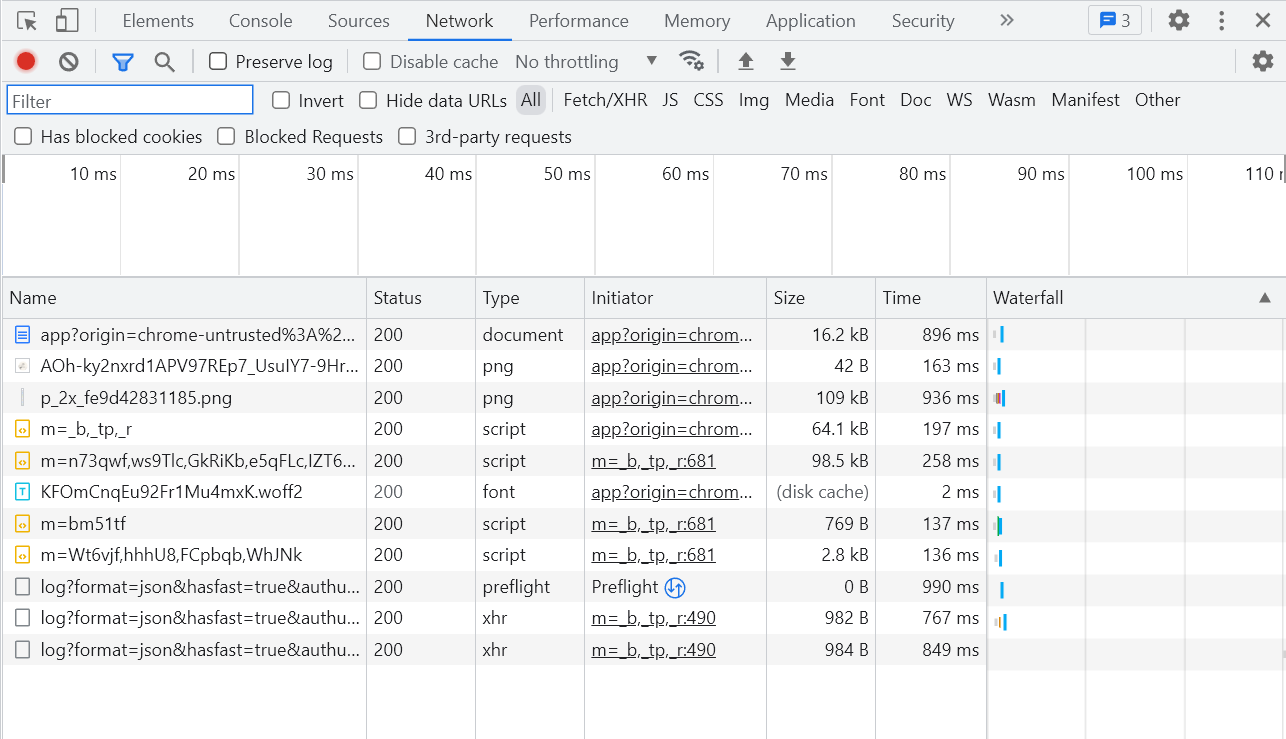
- Network可以当作一个网站的抓包工具来使用。

若有收获,就点个赞吧
0 人点赞
