- 01. 动态数据获取
- 02. 酷我音乐爬取(半自动获取动态数据)
- 跟随网站
- 直接请求
- 3.2 构建浏览器与网页访问
- 配置浏览器选项,使Selenium程序在工作时不显示浏览器。
- 让Chrome打开有道翻译。
- 输入需要翻译的文字。
- 得到翻译后的结果。
- window_handles返回的是一个列表,因为当前浏览器只打开了一个窗口,因此这个列表中只有对象。
- 打开浏览器并访问百度。
- 此时只有一个窗口。
- 新建一个窗口并访问搜狗。
- 此时有两个窗口。
- 打开浏览器,访问百度。
- 新建窗口,访问搜狗。
- 切换到搜狗窗口,并关闭搜狗。
- 切换到百度窗口,并关闭百度。
- 因为百度窗口是当前浏览器中最后一个窗口,所以此时关闭窗口操作会顺带关闭浏览器。
- 构造浏览器对象
- 访问王者荣耀首页
- 图标图片保存函数
- 遍历每个英雄,获取英雄的名称和图标链接并下载
- 打开百度。
- 在搜索框中输入“你好,Selenium!”
- 点击“百度一下”按钮,实现搜索。
- 调用浏览器访问英雄联盟官网
- 查找游戏资料的链接标签
- 点击链接标签
- 打开浏览器,访问北京链家。
- 搜索北京。
- 进入第一套房源的详情页。
- 用text和innerHTML两种方式获取房屋户型。
- 打开浏览器,访问王者荣耀资料页。
- 爬取英雄名称与详情页链接。
- 创建WZRY目录,若已存在则忽略。
- 皮肤大图下载函数
- 进入详情页,爬取皮肤大图。
- 启动浏览器并打开网页
- 获取用户名、密码、验证码的输入表单标签并输入数据
- 方式一:获取img标签内的src,其值是Base64编码的图片
- 方式二:截图获取获取验证码图片。
- 方式三:直接获取字节数据。
- 用超级鹰识别验证码
- 若正常获取验证码识别结果,则将验证码输入,然后点击登录
01. 动态数据获取
1.1 动态数据与静态数据
- 静态数据与动态数据的概念:
- 静态数据:HTML中写死的数据,不管什么时候打开都是这样的,不会发生变化。
- 动态数据:前端没有的数据,即需要向后端服务器请求的数据。
- 动态数据产生的原因:
- 类型一:从JS代码中解析出来的数据。
- 类型二:客户端HTML文件中无法存储体量较大的数据,因此很多数据都是存储在服务器上的,只有当客户端需要的时候,才会进行请求并由服务器完全响应,以此减轻了服务器向客户端响应的IO压力以及客户端的存储压力。
- requests模拟浏览器发送请求的方式只能获取静态数据。
- 若想要获取动态数据,则需要自己监测浏览器的Network。捕捉发出去的请求,获取请求地址,然后通过这个地址就可以获取动态的数据。
- 动态请求响应的数据一般是JSON格式的数据,JSON类似于Python中的列表嵌套字典或者字典嵌套列表。
动态数据选用JSON作为数据格式的原因:
现有王者荣耀英雄介绍的网站:https://pvp.qq.com/web201605/herolist.shtml
- 用request获取这些英雄的名字,会发现总是少一些英雄。这是因为排在前面的英雄相较于后面而言,是最近才出的一些新英雄,王者荣耀官方还没有将这部分内容固定写到其HTML页面中,因此需要向服务器动态请求。
- 通过F12 >> Network >> Fetch/XHR即可监控到所有动态数据,若没有监控到则打开Fetch/XHR后刷新一下页面即可。
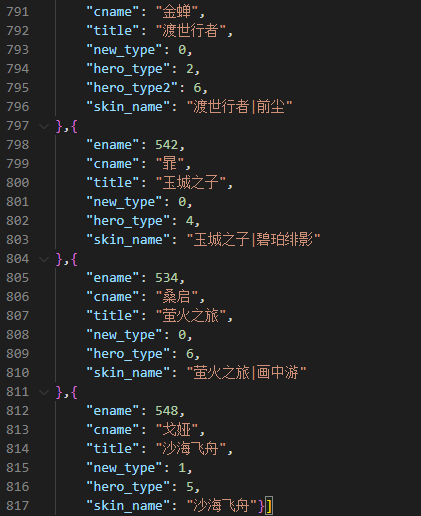
- 在Fetch/XHR中,我们可以双击下载与英雄信息相关的herolist.json文件,打开可以发现其中存储的是所有英雄的数据,包括新英雄在内。
1.2.2 Python捕捉动态数据。
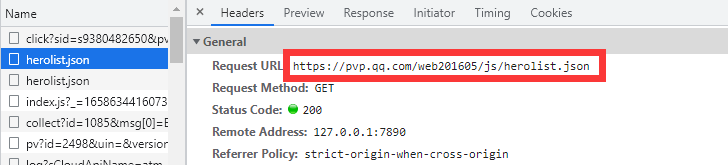
- Python捕捉动态数据常用的有两种方式,第一种方式较为愚钝,就是手动打开Fetch/XHR,然后单击需要的动态数据文件,在Headers中的General中即可获取该动态数据文件的URL。
- 然后用requests模块请求该地址即可。 ```python import requests
resp = requests.get(url=”https://pvp.qq.com/web201605/js/herolist.json“) if resp.status_code == 200: print(resp.json()) # json()函数可以获取JSON格式的数据。 else: print(f”数据请求失败,状态码为:{resp.status_code}”)
- 示例:从[https://101.qq.com/#/hero](https://101.qq.com/#/hero)中获取英雄名称、英雄职业、技能名称。- 注:英雄数据列表和英雄详情页链接都是动态数据。```pythonimport requests# 这个地址也是个动态数据,即Fetch/XHR中的hero_list.js?ts=2764419地址。resp = requests.get(url="https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2764419")if resp.status_code == 200:hero_list = resp.json()heroes = hero_list.get("hero") # 所有的英雄信息被封装成一个列表,是字典hero_list中键hero的值。for hero in heroes:hero_id = hero.get("heroId")hero_name = hero.get("name")hero_roles = "、".join(hero.get("roles"))# 动态地址,在英雄列表页面点击进入英雄的详情页,然后在Fetch/XHR中找到{hero_id}.js?ts=2764423文件的地址。hero_detail_url = f"https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js?ts=2764423"resp_hero_detail = requests.get(url=hero_detail_url)if resp_hero_detail.status_code == 200:detail_data = resp_hero_detail.json()skills = detail_data.get("spells") # 英雄技能是一个列表,是字典detail_data中键spells的值。hero_skills = "、".join([skill.get("name") for skill in skills]) # 将所有技能名称提取出来,然后用“、”连接成字符串。print(hero_name, hero_roles, hero_skills)else:print(f"英雄详情页数据请求失败,状态码为:{resp.status_code}")else:print(f"数据请求失败,状态码为:{resp.status_code}")
第二种方式,就是使用selenium自动化测试工具捕捉动态数据。
02. 酷我音乐爬取(半自动获取动态数据)
2.1 酷我音乐数据理解
酷我音乐地址:http://www.kuwo.cn/
- 每当播放一首歌曲,在Fetch/XHR中就可以动态的获取到这首歌相关的信息,如在data里就有着这首歌的URL地址。

- 选择第一首VIP歌曲,进入详情页播放,会提示我们需要付费。
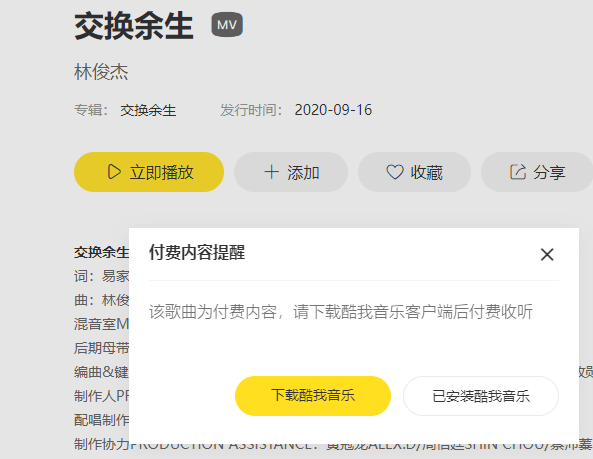
- 此时回到歌曲列表,按F12打开Network中的Fetch/XHR,接着播放一首免费歌曲,就可以获取到playUrl?mid的动态数据。
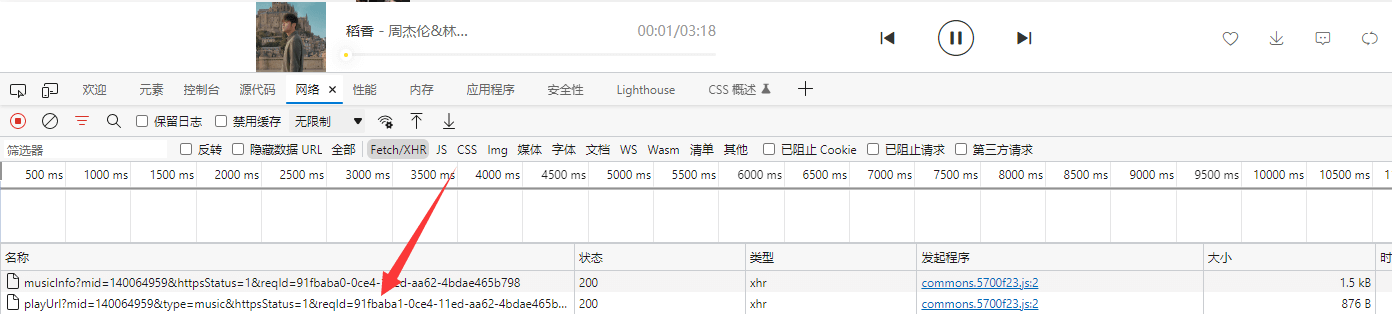
- 获取playUrl?mid的Request URL,并用浏览器进行访问。

- 访问得到是一串JSON格式的数据,其中包含着歌曲的URL。(这与1.1.1中拿到的数据是一样的)

现在,我们尝试删除playUrl?mid的Request URL中附带的信息,当参数中只剩下mid时,依旧可以获取到歌曲的JSON数据,但当mid删除后,就无法获取数据。
http://www.kuwo.cn/api/v1/www/music/playUrl?mid=140064959
由此可以猜测,只要通过
http://www.kuwo.cn/api/v1/www/music/playUrl?mid=,拼接上歌曲的ID,即mid,就可以获取到任意一首歌的URL地址(包括付费歌曲)。- 对于歌曲的mid,在搜索时得到的歌曲列表中,就有一个名为searchMusicBykeyWord的动态数据中存储着对应的数据。
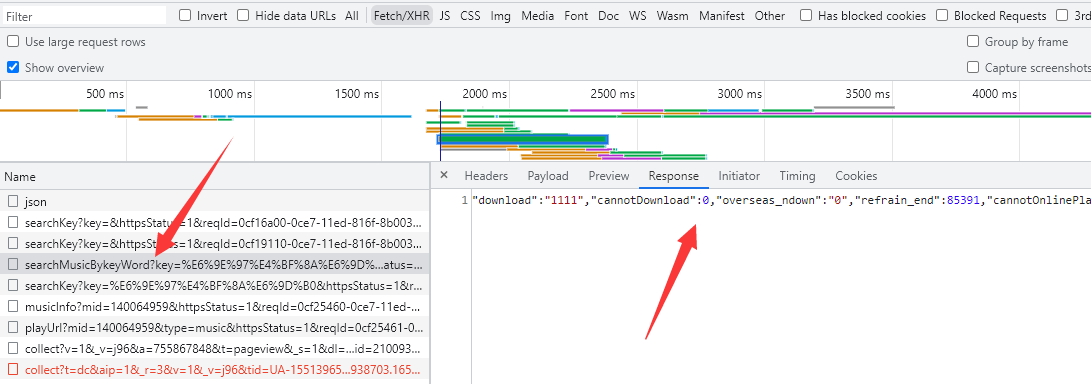
- 将searchMusicBykeyWord中的Response的JSON数据拿去用JSON解析工具一解析,即可得到歌曲对应的rid(这个rid实际上就是mid)。
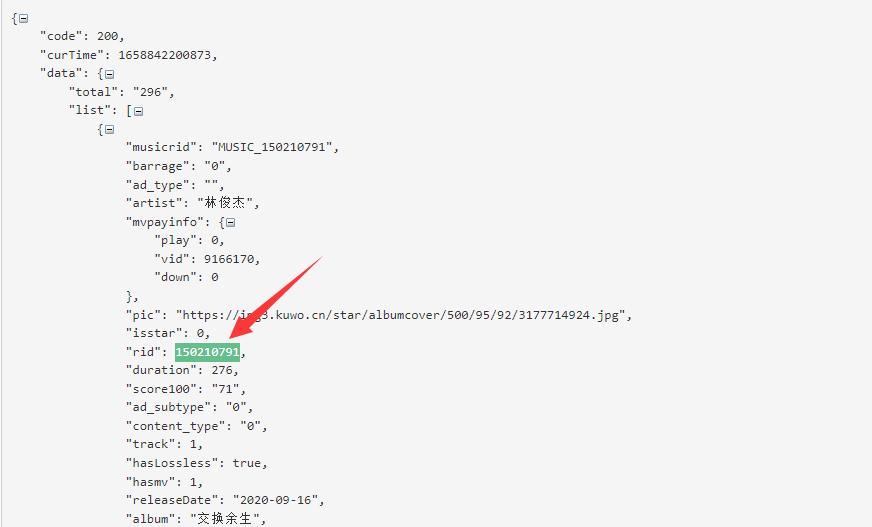
- 拿着rid:150210791与前面的步骤中得到的URL拼接即可得到:http://www.kuwo.cn/api/v1/www/music/playUrl?mid=150210791
访问后会得到以下数据,提醒你该歌曲为付费内容:
{"code":-1,"msg":"该歌曲为付费内容,请下载酷我音乐客户端后付费收听","reqId":"ed13c1962dd57ce1d30c184a63e00d9e","tId":"","profileId":"site","curTime":1658842508687,"success":false}
在酷我的新接口(即type=music)中,会识别付费歌曲,但酷我的老接口(type=mp3)还可以用。
- 故在请求参数中加上老接口信息,即请求:http://www.kuwo.cn/api/v1/www/music/playUrl?mid=150210791&type=mp3
此时返回的是:
{"code": 200,"msg": "success","reqId": "37ccf893be377693c746ccf86670f17c","tId": "","data": {"url": "https://lj-sycdn.kuwo.cn/c835e5e3861dd9dffe2c0913ef66e102/62dfee86/resource/n2/45/14/3100771860.mp3"},"profileId": "site","curTime": 1658842780690,"success": true}
发现data中包含着url,即交换余生的下载地址为:https://lj-sycdn.kuwo.cn/c835e5e3861dd9dffe2c0913ef66e102/62dfee86/resource/n2/45/14/3100771860.mp3
2.3 爬虫获取音频
2.3.1 对搜索内容进行编码(urllib.parse.quote()函数)
在搜索林俊杰时,参数内的key为林俊杰。

但是一旦把这个URL复制过来,林俊杰就变成了编码的形式(实际上浏览器发送的也是编码的形式)。
http://www.kuwo.cn/search/list?key=%E6%9E%97%E4%BF%8A%E6%9D%B0
因此爬虫程序在发送HTTP请求时,也可以发送的是编码后的URL。
- 在
urllib.parse中有一个quote()函数,可以将字符编码成浏览器可识别的形式。 ```python from urllib.parse import quote
key = input(“请输入歌手/歌曲的名称:”) url = f”http://www.kuwo.cn/search/list?key={quote(key)}“ print(url)
“”” 运行结果: 请输入歌手/歌曲的名称:林俊杰 http://www.kuwo.cn/search/list?key=%E6%9E%97%E4%BF%8A%E6%9D%B0 “””
- 因此要搜索什么歌曲,只需要输入key后用`quote()`函数进行编码处理,再拼接到URL后用`requests`请求即可。<a name="Wzmzg"></a>#### 2.3.2 解决响应403- 在2.2中提到,搜索音乐时,会返回一个包含歌曲基本信息的动态数据searchMusicBykeyWord。- 但是直接去访问这个searchMusicBykeyWord的Request URL:[http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%E6%9E%97%E4%BF%8A%E6%9D%B0&pn=1&rn=30&httpsStatus=1&reqId=538fa981-0d42-11ed-ac4f-b9b3b3f4b8de](http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%E6%9E%97%E4%BF%8A%E6%9D%B0&pn=1&rn=30&httpsStatus=1&reqId=538fa981-0d42-11ed-ac4f-b9b3b3f4b8de),发现会出现403错误,说明是请求头中缺少了一些必要的信息。- 分析请求头:- 从酷我官网搜索框中提交的请求的请求头:```jsonAccept: application/json, text/plain, */*Accept-Encoding: gzip, deflateAccept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8Cache-Control: no-cacheCookie: _ga=GA1.2.1233049029.1658747509; _gid=GA1.2.2100938703.1658841537; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1658747509,1658841537,1658881280; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1658881329; _gat=1; kw_token=GVFIASLXX68csrf: GVFIASLXX68Host: www.kuwo.cnPragma: no-cacheProxy-Connection: keep-aliveReferer: http://www.kuwo.cn/search/list?key=%E6%9E%97%E4%BF%8A%E6%9D%B0User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
直接请求searchMusicBykeyWord的Request URL的请求头:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9Accept-Encoding: gzip, deflateAccept-Language: zh-CN,zh;q=0.9,zh-TW;q=0.8Cache-Control: no-cacheCookie: _ga=GA1.2.1233049029.1658747509; _gid=GA1.2.2100938703.1658841537; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1658747509,1658841537,1658881280; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1658881329; kw_token=0XG0TE67AYHQHost: www.kuwo.cnPragma: no-cacheProxy-Connection: keep-aliveUpgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
删除掉一些无影响的字典,以及相同的字段,最后发现直接请求的内容中,Cookie缺少一些数据,csrf和Referer字段直接没有了。 ```json
跟随网站
Cookie: _ga=GA1.2.1233049029.1658747509; _gid=GA1.2.2100938703.1658841537; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1658747509,1658841537,1658881280; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1658881329; _gat=1; kw_token=GVFIASLXX68 csrf: GVFIASLXX68 Referer: http://www.kuwo.cn/search/list?key=%E6%9E%97%E4%BF%8A%E6%9D%B0
直接请求
Cookie: _ga=GA1.2.1233049029.1658747509; _gid=GA1.2.2100938703.1658841537; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1658747509,1658841537,1658881280; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1658881329; kw_token=0XG0TE67AYHQ
- 因此在请求searchMusicBykeyWord的Request URL时,只需要想办法将这些请求头填充上即可。- 通过响应流程分析,可以发现csrf是请求搜索内容时,cookie中响应过来的kw_token的值;而Referer就是经过编码的URL。```pythonimport requestsfrom urllib.parse import quotekey = input("请输入歌手/歌曲的名称:")url = f"http://www.kuwo.cn/search/list?key={quote(key)}"resp = requests.get(url=url)if resp.status_code == 200:csrf = resp.cookies.get("kw_token")# 请求searchMusicBykeyWord的URL。# 这是请求的页码,pn值第几页,rn指一页又多少个true_url = f"http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?" \f"key={quote(key)}" \f"&pn=1&rn=30" \f"&httpsStatus=1&reqId=54d53921-0d53-11ed-bb89-135a5029dc0a"sing_list_resp = requests.get(url=true_url,headers={'Referer': f'http://www.kuwo.cn/search/list?key={quote(key)}','csrf': f'{csrf}','Cookie': f'kw_token={csrf}'})if sing_list_resp.status_code == 200:print("歌曲信息请求成功")sing_data = sing_list_resp.json()print(sing_data)else:print(f"歌曲信息请求失败,响应状态码为:{sing_list_resp.status_code}")else:print(f"请求失败,响应状态码为:{resp.status_code}")
2.3.3 获取歌曲总数、歌曲名、歌曲的下载地址
- 当json数据中的code为200时,代表歌曲数据获取成功。
- 歌曲总数是json数据中的data中的total,歌曲的信息在data的list中,list是一个列表,列表中的每个字典元素就是歌曲的信息。
- 请求到每首歌的字典信息后,解析字典即可得到歌曲的名称以及rid,将rid与02中介绍的思路结合起来,即可得到歌曲的下载信息。 ```python import requests from urllib.parse import quote
key = input(“请输入歌手/歌曲的名称:”) url = f”http://www.kuwo.cn/search/list?key={quote(key)}“
resp = requests.get(url=url) if resp.status_code == 200: csrf = resp.cookies.get(“kw_token”)
# 请求searchMusicBykeyWord的URL。# `&pn=1&rn=30`这是请求的页码,pn只第几页,rn指一页有多少个数据true_url = f"http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?" \f"key={quote(key)}" \f"&pn=1&rn=30" \f"&httpsStatus=1&reqId=54d53921-0d53-11ed-bb89-135a5029dc0a"sing_list_resp = requests.get(url=true_url,headers={'Referer': f'http://www.kuwo.cn/search/list?key={quote(key)}','csrf': f'{csrf}','Cookie': f'kw_token={csrf}'})if sing_list_resp.status_code == 200:sing_data = sing_list_resp.json()if sing_data.get("code") == 200:total = sing_data.get("data").get("total")print(f"歌曲数据请求成功,歌曲总数为{total}")sing_list = sing_data.get("data").get("list")for sing in sing_list:sing_name = sing.get("name")rid = sing.get("rid")resource_url = f"http://www.kuwo.cn/api/v1/www/music/playUrl?mid={rid}&type=mp3"resource_resp = requests.get(url=resource_url)if resource_resp.status_code == 200:resource_data = resource_resp.json()music_down_url = resource_data.get("data").get("url")print(f"歌曲“{sing_name}”下载地址:{music_down_url}")else:print(f"资源请求失败,响应状态码为:{resource_resp.status_code}")else:print(f"歌曲信息请求失败,响应状态码为:{sing_list_resp.status_code}")
else: print(f”请求失败,响应状态码为:{resp.status_code}”)
<a name="RICbT"></a>## 03. Selenium自动化测试工具<a name="SwFFl"></a>### 3.1 Selenium概述与安装<a name="IfVhi"></a>#### 3.1.1 Selenium介绍- selenium是一款自动化测试工具,被称为爬虫的万金油。- selenium会自动调动浏览器,并展示页面信息。只要是浏览器上出现的数据,selenium都可以请求到。- 缺点:网页上隐藏的数据无法用selenium获取。- 所谓隐藏的数据,以英雄联盟狂战士的英雄详情页:[https://101.qq.com/#/hero-detail?heroid=2&datatype=5v5](https://101.qq.com/#/hero-detail?heroid=2&datatype=5v5)为例,其技能描述只有当鼠标悬停在其技能图标上时才会显示,其他时候是不显示的。对于这种只有在特定场景下才显示的数据就称之为隐藏的数据。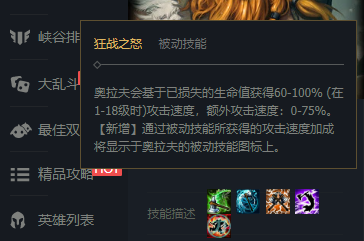- 总结:- requests可以获取网页的HTML源码,因此只要是HTML源码中存在的数据,都可以用requests爬取;动态数据HTML源码中不存在,因此无法爬取。- selenium可以获取element中的数据,selenium会打开浏览器渲染页面,因此只要是页面中存在的数据,都可以用selenium获取,包括动态数据。但无法获取隐藏的数据,哪怕隐藏的数据存在于HTML源码中。- 因此可以说requests和selenium是两个互补的模块。<a name="SwYbj"></a>#### 3.1.2 Selenium安装- selenium也是一款第三方工具库,也需要用pip工具进行安装。```python# 命令行安装pip install selenium# Jupyter Notebook安装!pip install selenium
3.1.3 ChromeDriver驱动下载
- 安装完第三方工具库selenium直接使用会报错:
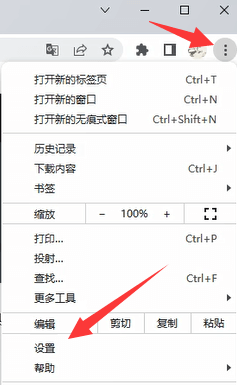
Message: 'chromedriver' executable needs to be in PATH.,报错原因是谷歌浏览器驱动没有被正常安装,因此需要先去下载驱动。 - 第一步:查看Chrome谷歌浏览器版本。
- 点击浏览器右上角的菜单按钮,再点击设置。
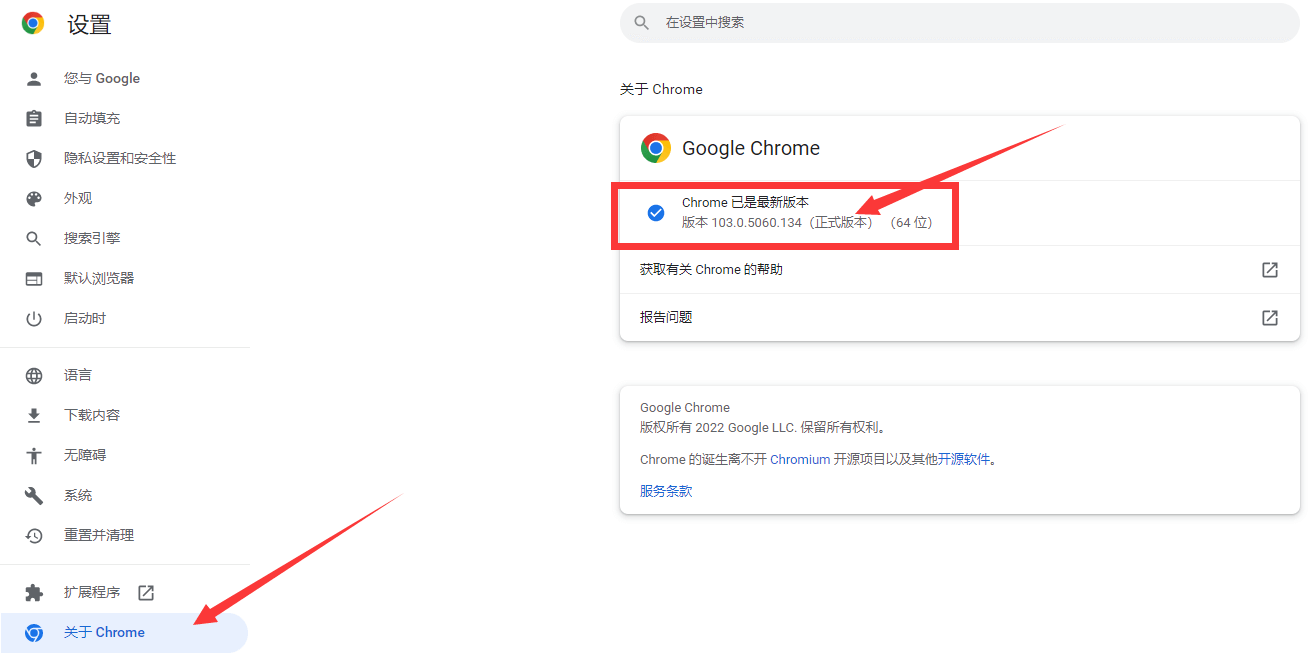
- 接着点击左侧导航栏中的“关于 Chrome”,在右侧即可看到当前谷歌浏览器的版本。
- 第二步:访问版本连接https://chromedriver.storage.googleapis.com/LATEST_RELEASE_103.0.5060,地址的组成如下:
- 以上图中的版本“103.0.5060.134”为例,取其前3个数字,即“103.0.5060”。
- 将取到的3位版本拼接在“https://chromedriver.storage.googleapis.com/LATEST_RELEASE_”的最后即可得到当前驱动的下载连接。
- 第三步:访问下载地址https://chromedriver.storage.googleapis.com/index.html?path=103.0.5060.134/,地址的组成如下:
- 访问第二步的URL将得到一个小版本号:103.0.5060.134(具体根据实际情况而变)
- 对于版本103.0.5060.134,URL 将为“https://chromedriver.storage.googleapis.com/index.html?path=103.0.5060.134/”。
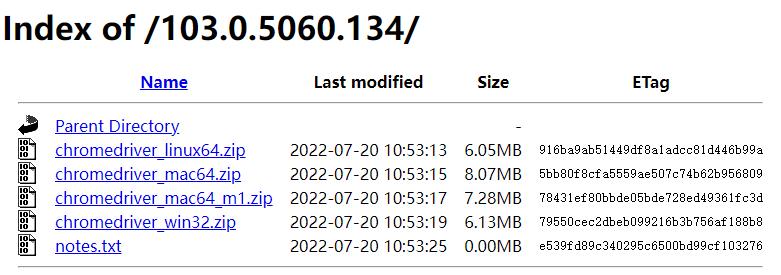
- 第四步:第三步会访问到一个FTP连接,选择当前操作系统对应的版本进行下载。
- 这里以Windows为例,故下载chromedriver_win32.zip文件。
- 注意:目前Windows端的ChromeDriver只提供了32位,未提供64位。但是32位在64位操作系统上也能用。
- 第五步:将下载好的压缩文件进行解压,即可得到chromedriver.exe驱动文件。
补充(第二、三步无法正常访问的解决方案):
- 上述下载方式是谷歌官方提供的下载方式,其中的连接可能因为一些网络问题无法正常访问。
- 替代方式:完成步骤一后,记录前三个数(即大版本号),然后去镜像地址:https://registry.npmmirror.com/binary.html?path=chromedriver/,根据大版本号寻找对应的资源。(即资源的最后第四位小版本号可以与浏览器实际的版本不同,但前三位要相同)
3.1.4 ChromeDriver安装(系统中安装)
第一步:右键谷歌浏览器图标 >> 打开文件所在的位置。
- 第二步:将解压得到的chromedriver.exe驱动文件移动到打开的目录中。
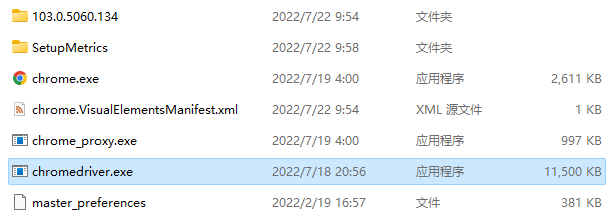
- 第三步:将打开的谷歌浏览器目录地址添加到PATH中。
安装完成后,重启一下PyCharm,即可正常运行selenium程序了。
3.1.5 ChromeDriver安装(项目中安装)
若只是偶尔使用一下Selenium程序,那么这种方式相比于3.1.4中介绍的在系统中安装ChromeDriver要来的更为方便、灵活。
- 相反,若是Selenium的重度用户,那么还是建议使用3.1.4中介绍的方式(当然,也有其他的方案,即填充executable_path参数,将在3.2.1中介绍)。
- 这种方式只需要将ChromeDriver驱动文件与Selenium程序源代码文件放在同一路径下即可。
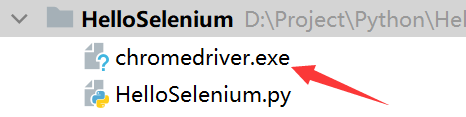
3.2 构建浏览器与网页访问
3.2.1 Chrome()启动谷歌浏览器
- 第三方库selenium中有一个webdriver模块,这个模块下的
Chrome()函数可以创建一个谷歌浏览器对象,并在当前操作系统中打开谷歌浏览器。 ```python from selenium import webdriver
browser = webdriver.Chrome()
- 注意:`Chrome()`函数中存在一个executable_path参数,这个参数用于指定ChromeDriver驱动的路径。- executable_path参数存在一个默认值chromedriver,即在默认情况下,它会先在当前路径下查找chromedriver驱动,若当前路径下没有,则在PATH中查找。- 当executable_path指定的路径和PATH中都找不到ChromeDriver驱动,则报`Message: 'chromedriver' executable needs to be in PATH.`错误。```python# 例如,将chromedriver.exe放到D:\Driver目录中,则代码可以这么写。from selenium import webdriverbrowser = webdriver.Chrome(executable_path="D:\Driver\chromedriver.exe")
3.2.2 get()访问指定网站
浏览器对象.get(网址字符串)可以让浏览器在当前窗口中访问指定的网址。 ```python from selenium import webdriver
browser = webdriver.Chrome() browser.get(“https://www.baidu.com/“) # 访问百度
<a name="FVeLU"></a>#### 3.2.3 浏览器配置项- 在Selenium构建Chrome时,可能对浏览器有着特殊的要求,比如:- 浏览器需要有网络代理功能。- 爬虫在工作时不显示浏览器界面。- 若对浏览器有特殊要求,则可以在构建浏览器时设置浏览器的配置项来实现自定义的需求。- 首先,实例化一个配置项类`selenium.webdriver.chrome.options.Options`的对象。- 接着,通过`配置项类的对象.add_argument()`函数来添加参数。- 最后,在构建浏览器时通过指定`options`参数来给构建的浏览器添加上特殊的功能。- 示例1:让浏览器有本地网络代理功能,以此实现快速访问GitHub。- 参数:`--proxy-server=地址:端口号````pythonfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options# 配置浏览器选项,添加本地Clash网络代理。options = Options()options.add_argument("--proxy-server=localhost:7890")# 用配置好的浏览器选项构建浏览器。browser = webdriver.Chrome(options=options)# 访问谷歌。browser.get("https://github.com/")
- 示例2:让Selenium程序在运行时,不显示浏览器。
- 不显示浏览器是指浏览器是实际存在并且在工作的,但是屏幕上不会显示出来。
- 参数:
--headless```python import time
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By
配置浏览器选项,使Selenium程序在工作时不显示浏览器。
options = Options() options.add_argument(“—headless”)
让Chrome打开有道翻译。
browser = webdriver.Chrome(options=options) browser.get(“https://fanyi.youdao.com/“)
输入需要翻译的文字。
in_ele = browser.find_element(by=By.ID, value=”js_fanyi_input”) in_ele.send_keys(input(“请输入需要翻译的内容:”))
得到翻译后的结果。
time.sleep(1) out_ele = browser.find_element(by=By.ID, value=”js_fanyi_output_resultOutput”) print(f”翻译结果为:{out_ele.text}”)
<a name="ZOZGn"></a>#### 3.2.4 程序运行完成后不自动关闭浏览器- 默认情况下Selenium程序在执行完成后,会自动将浏览器关闭。- 有些情况下,我们可能不想Selenium程序执行完成后关闭浏览器,那么只需要构建一个Options对象,然后添加`add_experimental_option("detach", True)`即可。- 示例:让Selenium程序打开百度页面即可,但程序结束后不关闭浏览器。```pythonfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options# 构建浏览器选项,使Selenium程序运行结束后不会自动关闭浏览器。options = Options()options.add_experimental_option("detach", True)browser = webdriver.Chrome(options=options)browser.get("https://www.baidu.com")
3.3 窗口操作
3.3.1 window_handles获取所有窗口
浏览器对象.window_handles属性可以获取当前浏览器中所有的窗口对象。 ```python from selenium import webdriver
browser = webdriver.Chrome() browser.get(“https://www.baidu.com/“)
windows = browser.window_handles print(windows) # [‘CDwindow-5D1CF9CCA2BADB2CF1960D3FD98A32B4’]
window_handles返回的是一个列表,因为当前浏览器只打开了一个窗口,因此这个列表中只有对象。
<a name="WknQZ"></a>#### 3.3.2 JS-window.open()新建窗口- Selenium中没有封装新建窗口的函数,但是可以通过JavaScript代码来实现这个操作。- JavaScript代码打开新窗口的语句:`windows.open(URL)`。- 然后使用`浏览器对象.execute_script(JS代码)`的方式去实现窗口的新建。```pythonfrom selenium import webdriver# 打开浏览器并访问百度。browser = webdriver.Chrome()browser.get("https://www.baidu.com/")# 此时只有一个窗口。print(browser.window_handles) # ['CDwindow-EDF2F376BF1ED2ED5C50C5E8E4745065']# 新建一个窗口并访问搜狗。js_new_window = 'window.open("https://www.sogou.com");'browser.execute_script(js_new_window)# 此时有两个窗口。print(browser.window_handles) # ['CDwindow-EDF2F376BF1ED2ED5C50C5E8E4745065', 'CDwindow-668913B0265D739F81AB22B1AD84E38F']
3.3.3 current_window_handle查看当前窗口对象
浏览器对象.current_window_handle属性可以获取到当前窗口句柄。 ```python from selenium import webdriver
打开浏览器并访问百度。
browser = webdriver.Chrome() browser.get(“https://www.baidu.com/“)
此时只有一个窗口。
print(browser.window_handles) # [‘CDwindow-3BBBFAE9A78417FAEA490ADB6C9060E3’] print(f”当前窗口为:{browser.current_window_handle}”) # 当前窗口为:CDwindow-3BBBFAE9A78417FAEA490ADB6C9060E3
新建一个窗口并访问搜狗。
js_new_window = ‘window.open(“https://www.sogou.com“);’ browser.execute_script(js_new_window)
此时有两个窗口。
print(browser.window_handles) # [‘CDwindow-3BBBFAE9A78417FAEA490ADB6C9060E3’, ‘CDwindow-AC8A8A37085841D87CB50F573E16BB24’] print(f”当前窗口为:{browser.current_window_handle}”) # 当前窗口为:CDwindow-3BBBFAE9A78417FAEA490ADB6C9060E3
- 从两次可以`print(f"当前窗口为:{browser.current_window_handle}")`的输出结果中可以看出,新建窗口并不会切换当前操作窗口。- 需要注意的是,若当前窗口不切换,那么新建窗口(或者通过鼠标点击按钮元素打开新窗口等操作)之后,Selenium程序操作的依旧是老窗口。- 因此可以说切换窗口是十分重要的操作,否则就可能出现元素找不到、数据发送错误等异常。<a name="eozYi"></a>#### 3.3.4 switch_to.window()切换窗口- `浏览器对象.switch_to.window(窗口字符串)`函数可以切换selenium程序操作的窗口。- `switch_to`:切换到指定的对象中。- `window(窗口字符串)`:根据窗口字符串构造窗口对象。- 最新打开的窗口:`window_handles`中的元素顺序是按照窗口创建的先后顺序添加的,因此最新打开的创建一定是列表的最后一个元素,即`window_handles[-1]`。- 示例:先打开浏览器访问百度,然后打开一个新窗口访问搜狗;接着老窗口访问腾讯,新窗口访问360。```pythonfrom selenium import webdriverimport time# 打开浏览器访问百度。browser = webdriver.Chrome()browser.get("https://www.baidu.com/")time.sleep(3) # 为了实验效果明显,可以休眠几秒# 打开一个新窗口访问搜狗。js_new_window = 'window.open("https://www.sogou.com/");'browser.execute_script(js_new_window)time.sleep(3)# 老窗口访问腾讯(因为是老窗口访问,因此不需要切换窗口)。browser.get("https://www.tencent.com/")time.sleep(3)# 切换到新窗口,然后访问360。window_name = browser.window_handles[-1]browser.switch_to.window(window_name)browser.get("https://www.360.cn/")
3.3.5 close()关闭当前页面
浏览器对象.close()可以关闭浏览器中的当前窗口;当浏览器中只有一个窗口时,执行close()函数会关闭浏览器。- 示例:打开浏览器访问百度,新建窗口访问搜狐;然后关闭搜孤,再关闭浏览器。 ```python from selenium import webdriver import time
打开浏览器,访问百度。
browser = webdriver.Chrome() browser.get(“https://www.baidu.com/“) time.sleep(3)
新建窗口,访问搜狗。
js_new_windows = “window.open(‘https://www.sogou.com/‘);” browser.execute_script(js_new_windows) time.sleep(3)
切换到搜狗窗口,并关闭搜狗。
browser.switch_to.window(browser.window_handles[-1]) browser.close() time.sleep(3)
切换到百度窗口,并关闭百度。
因为百度窗口是当前浏览器中最后一个窗口,所以此时关闭窗口操作会顺带关闭浏览器。
browser.switch_to.window(browser.window_handles[0]) browser.close()
<a name="ILekk"></a>#### 3.3.6 back()返回上一个页面- `浏览器.back()`函数类似于浏览器右上角的后退按钮,用于返回上一级页面。- 示例:打开百度,搜索Python,然后再退回百度首页。```pythonimport timefrom selenium import webdriverfrom selenium.webdriver.common.by import By# 打开百度。browser = webdriver.Chrome()browser.get("https://www.baidu.com/")# 在搜索框中输入“Python”kw = browser.find_element(by=By.ID, value="kw")kw.send_keys("Python")# 点击“百度一下”按钮,这会跳转到一个新页面。su = browser.find_element(by=By.ID, value="su")su.click()time.sleep(3)# 返回百度首页,即返回上一级页面。browser.back()
3.4 元素查找 & 数据提取
3.4.1 元素获取说明
- 在Selenium程序中,元素查找基本上是
find_element_by_xxx/find_elements_by_xxx这样的一对方法。 - 其中:
find_elements_by_xxx返回的是符合条件的所有元素对象,是一个列表。find_element_by_xxx返回的是符合条件的第一个元素对象,可以看作是find_elements_by_xxx[0]。
- 元素获取方法可以作用在浏览器对象上,这种方法会从
<html>开始向下查找符合条件的元素。 元素获取方法也可以作用在指定的元素对象上,这种方法会从制定的元素对象开始向下查找符合条件的元素。
3.4.2 find_elements()查找元素的基本方法
浏览器对象/元素对象.find_elements(by=By.ID, value=值)函数可以查询符合条件的所有标签元素。- 参数by:用于指定查找的参数,常用的参数如下:
- ID:根据HTML标签的id属性来获取元素。
- CLASS_NAME:根据HTML标签的类名来获取元素。
- CSS_SELECTOR:根据CSS选择器来获取元素。
- XPATH:更具XPath来获取元素。
- 注意:上述所有的值都是
selenium.webdriver.common.by.By中的对象。
- 参数value:参数by指定的查找参数对应的值。
- 参数by:用于指定查找的参数,常用的参数如下:
- 示例:王者荣耀英雄资料界面地址为:https://pvp.qq.com/web201605/herolist.shtml,用CSS选择器提取出页面中的“英雄介绍”。

from selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()browser.get("https://pvp.qq.com/web201605/herolist.shtml")# text用于获取标签的文本。target = browser.find_element(by=By.CSS_SELECTOR, value=".zkcontent .herolist-title").textprint(target)
3.4.3 find_element_by_id()按照ID查找元素
浏览器对象/元素对象.find_element_by_id(ID)可以查找出id=ID的元素,实际上就是一个CSS中的ID选择器。- Selenium4版本开始删除了这个方法,可以使用
浏览器对象/元素对象.find_element(by=By.ID, value="id值")代替。 -
3.4.4 find_element_by_class_name()按照类名查找元素
浏览器对象/元素对象.find_element_by_class_name(ClassName)可以查找出class=ClassName的元素,实际上就是一个CSS中的类选择器。- Selenium4版本开始删除了这个方法,可以使用
浏览器对象/元素对象.find_element(by=By.CLASS_NAME, value="类名")代替。 -
3.4.5 find_element_by_tag_name()按照标签名查找元素
浏览器对象/元素对象.find_element_by_tag_name(TagName)可以指定标签的元素。- Selenium4版本开始删除了这个方法,可以使用
浏览器对象/元素对象.find_element(by=By.TAG_NAME, value="标签名")代替。 -
3.4.6 爬取所有的英雄名称与图标
首先,第一步必然是构造浏览器对象,访问王者荣耀首页。 ```python from selenium import webdriver
构造浏览器对象
browser = webdriver.Chrome()
访问王者荣耀首页
hero_list_url = “https://pvp.qq.com/web201605/herolist.shtml“ browser.get(hero_list_url)
- 通过鼠标小手工具分析Element可以发现,所有的单个英雄都是herolist这个类的ul中的一个li。- 因此可以先用`find_element_by_class_name()`函数获取到最外层的ul,然后再用`find_elements_by_tag_name()`获取其中的li。、- 然后,可以遍历每个英雄,并去解析得到英雄名称和图标的图片链接。```python# 获取英雄列表hero_list = browser.find_element(by=By.CLASS_NAME, value="herolist")# 从英雄列表中获取每个英雄lis = hero_list.find_elements(by=By.TAG_NAME, value="li")# 遍历每个英雄,获取英雄的名称和图标链接for li in lis:# 提取英雄名称a = li.find_element(by=By.TAG_NAME, value="a")hero_name = a.text# 提取英雄图标图片的路径img = a.find_element(by=By.TAG_NAME, value="img")hero_icon_url = img.get_attribute("src")print(hero_name, hero_icon_url)
- 接着,可以单独定义一个图片下载方法,然后传入第二步中拿到的英雄名称和图标的图片链接,将需要的图片下载下来。 ```python import requests
图标图片保存函数
def save_hero_icon(hero_name, hero_icon_url): hiu_resp = requests.get(hero_icon_url) if hiu_resp.status_code == 200: with open(f”./hero_icon/{hero_name}.jpg”, ‘wb’) as file: file.write(hiu_resp.content) else: print(f”{hero_name}图标爬取失败”)
遍历每个英雄,获取英雄的名称和图标链接并下载
for li in lis:
# 提取英雄名称a = li.find_element(by=By.TAG_NAME, value="a")hero_name = a.text# 提取英雄图标图片的路径img = a.find_element(by=By.TAG_NAME, value="img")hero_icon_url = img.get_attribute("src")# 打印数据并保存数据save_hero_icon(hero_name, hero_icon_url)print(hero_name, hero_icon_url)
- 项目代码汇总:```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport requests# 构造浏览器对象browser = webdriver.Chrome()# 访问王者荣耀首页hero_list_url = "https://pvp.qq.com/web201605/herolist.shtml"browser.get(hero_list_url)# 获取英雄列表hero_list = browser.find_element(by=By.CLASS_NAME, value="herolist")# 从英雄列表中获取每个英雄lis = hero_list.find_elements(by=By.TAG_NAME, value="li")# 图标图片保存函数def save_hero_icon(hero_name, hero_icon_url):hiu_resp = requests.get(hero_icon_url)if hiu_resp.status_code == 200:with open(f"./hero_icon/{hero_name}.jpg", 'wb') as file:file.write(hiu_resp.content)else:print(f"{hero_name}图标爬取失败")# 遍历每个英雄,获取英雄的名称和图标链接并下载for li in lis:# 提取英雄名称a = li.find_element(by=By.TAG_NAME, value="a")hero_name = a.text# 提取英雄图标图片的路径img = a.find_element(by=By.TAG_NAME, value="img")hero_icon_url = img.get_attribute("src")# 打印数据并保存数据save_hero_icon(hero_name, hero_icon_url)print(hero_name, hero_icon_url)
3.5 鼠标 & 键盘操作
3.5.1 send_keys()发送内容
元素对象.send_keys(value)可以向元素对象(一般是搜索框等需要键盘输入的元素)发送信息value。-
3.5.2 click()鼠标点击
元素对象.click()类似于用鼠标左键单击一下指点的元素对象。- 示例:在百度的搜索栏中输入“你好,Selenium!”,然后点击百度一下按钮实现搜索。 ```python from selenium import webdriver from selenium.webdriver.common.by import By
打开百度。
browser = webdriver.Chrome() browser.get(“https://www.baidu.com/“)
在搜索框中输入“你好,Selenium!”
kw = browser.find_element(by=By.ID, value=”kw”) kw.send_keys(“你好,Selenium!”)
点击“百度一下”按钮,实现搜索。
su = browser.find_element(by=By.ID, value=”su”) su.click()
<a name="NaErp"></a>#### 3.5.3 ActionChains鼠标工具- 在selenium.webdriver中有一个ActionChains鼠标工具,封装了一系列的鼠标操作。```pythonfrom selenium.webdriver import ActionChains
- 要使用这个工具需要先实例化鼠标对象:
鼠标对象 = ActionChains(浏览器对象) - 常用的两个鼠标动作:(这两个动作都不会立即执行,必须需要
perform()函数)鼠标对象.click(标签对象):鼠标点击事件,点击指定的标签对象。鼠标对象.move_to_element(标签对象):鼠标移动事件,将鼠标移动到目标标签上方。
- 执行事件:事件函数在被调用后不会立刻执行,只有当
perform()函数被调用后才会执行。- 例如
鼠标对象.click(百度一下)不会点击百度一下按钮。 - 只有
鼠标对象.click(百度一下).perform()才会点击百度一下按钮。
- 例如
- 示例1:用ActionChains点击英雄联盟官网页面中的游戏资料。 ```python from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By import time
调用浏览器访问英雄联盟官网
browser = webdriver.Chrome() browser.get(“https://lol.qq.com/main.shtml“) time.sleep(3)
查找游戏资料的链接标签
game_info = browser.find_element(by=By.CSS_SELECTOR, value=”#J_headNav > li > a”)
点击链接标签
action = ActionChains(browser) action.click(game_info).perform()
- 示例2:这是英雄联盟攻略中心的装备列表页面:[https://101.qq.com/#/equipment](https://101.qq.com/#/equipment),当鼠标悬浮在每个装备上时,会出现关于装备的隐藏数据,获取这些数据中的装备描述信息。```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver import ActionChainsimport time# 构建浏览器对象,并访问英雄联盟装备页。browser = webdriver.Chrome()browser.get("https://101.qq.com/#/equipment")time.sleep(3)# 构建鼠标对象。mouse = ActionChains(browser)# 获取武器元素。equips = browser\.find_element(by=By.CLASS_NAME, value="equipment-list")\.find_elements(by=By.TAG_NAME, value="li")# 遍历每个武器元素,让鼠标移动到每个元素上,并获取需要的数据。for equip in equips:mouse.move_to_element(equip).perform()equip_name = browser.find_element(by=By.CSS_SELECTOR, value=".component-dialog .title em").textequip_desc = browser.find_element(by=By.CSS_SELECTOR, value=".component-dialog .desc").textprint(f"{equip_name}:{equip_desc}")time.sleep(1)
ActionChains使用详细说明:https://www.cnblogs.com/lxbmaomao/p/10389786.html
3.6 获取信息
3.6.1 text提取文本
标签对象.text用于获取标签的文本,这个用法与01. Request静态数据爬取 2.3.3介绍的BeautifulSoup4的text完全一致。- 示例:获取豆瓣Top250中电影的电影名称、电影评分、评价人数。 ```python from selenium import webdriver from selenium.webdriver.common.by import By
browser = webdriver.Chrome() browser.get(“https://movie.douban.com/top250“)
movie_list = browser.find_elements(by=By.CSS_SELECTOR, value=”.grid_view li”) for movie in movie_list: movie_name = movie.find_element(by=By.CLASS_NAME, value=”title”).text rating = movie.find_element(by=By.CLASS_NAME, value=”rating_num”).text evaluators = movie.find_element(by=By.CSS_SELECTOR, value=”.star > span:nth-child(4)”).text.strip(“人评价”) print(f”电影名称:{movie_name},电影评分:{rating},评价人数:{evaluators}。”)
<a name="lMBbg"></a>#### 3.6.2 get_attribute提取属性- `标签对象.get_attribute("attribute")`用于获取标签的指定属性的值。- 示例:获取豆瓣Top250中电影的电影名称和电影海报的图片地址。```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()browser.get("https://movie.douban.com/top250")movie_list = browser.find_elements(by=By.CSS_SELECTOR, value=".grid_view li")for movie in movie_list:movie_name = movie.find_element(by=By.CLASS_NAME, value="title").text# 图片地址一般是img标签的src属性值。pic_url = movie.find_element(by=By.CSS_SELECTOR, value=".pic > a > img").get_attribute("src")print(f"电影名称:{movie_name},海报地址:{pic_url}。")
3.6.3 innerHTML属性
- innerHTML的作用也是获取标签内的信息,与text类似,但存在以下差别。
- innerHTML:不会忽略标签内容。
- text:会忽略标签内容。
如这样一段HTML代码:
<li><span class="label">房屋户型</span>"3室1厅1厨1卫"</li>
用
li标签对象.get_attribute("innerHTML")提取出来的数据是:<span class="label">房屋户型</span>3室1厅1厨1卫。- 用
li标签对象.text提取出来的数据是:房屋户型3室1厅1厨1卫 - 示例:从北京链家中爬取第一套房源的房屋户型。(用text和innerHTML两种方式) ```python from selenium import webdriver from selenium.webdriver.common.by import By import time
打开浏览器,访问北京链家。
browser = webdriver.Chrome() browser.get(“https://bj.lianjia.com/“) time.sleep(3)
搜索北京。
search_input = browser.find_element(by=By.CSS_SELECTOR, value=”.searchBox input”) search_input.send_keys(“北京”) search_btn = browser.find_element(by=By.ID, value=”findHouse”) search_btn.click() time.sleep(3)
进入第一套房源的详情页。
house_list = browser.find_elements(by=By.CSS_SELECTOR, value=”.sellListContent > li”) first_house = house_list[0] house_title = first_house.find_element(by=By.CLASS_NAME, value=”title”) house_title.click() browser.switch_to.window(browser.window_handles[-1]) time.sleep(3)
用text和innerHTML两种方式获取房屋户型。
base_info = browser.find_element(by=By.CLASS_NAME, value=”introContent”) house_type = base_info.find_element(by=By.TAG_NAME, value=”li”) print(f”text: {house_type.text}”) print(f”innerHTML: {house_type.get_attribute(‘innerHTML’)}”)
<a name="toyXK"></a>#### 3.6.4 page_source获取源码- `浏览器对象.page_source`可以用于获取浏览器当前页面当前状态的源码。- 示例:获取百度首页的源码。```pythonfrom selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.baidu.com/")print(browser.page_source)
注意:
page_source获取的是当前页面的当前状态的网页代码,即浏览器状态改变前与改变后获取到的代码是不一样的。3.7 阶段性项目实战
3.7.1 项目描述
这是王者荣耀的英雄资料页地址:https://pvp.qq.com/web201605/herolist.shtml。
- 通过这个地址,我们可以进入王者荣耀现阶段已经发布的每个英雄的详情页,我们需要爬取英雄的皮肤大图。
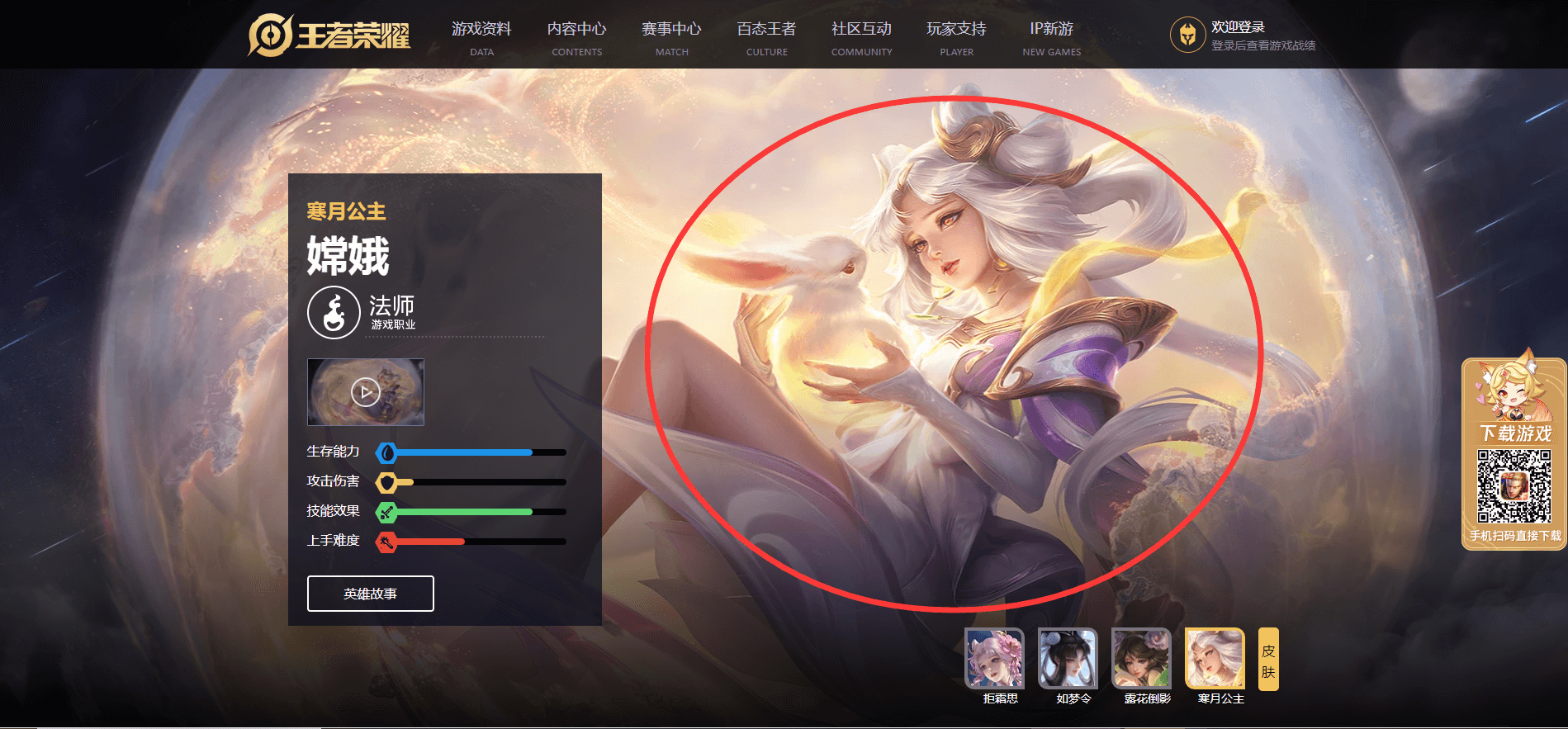
需求补充:要求爬取已发布的所有英雄的所有皮肤大图,要求文件名是该皮肤的皮肤名称,并且每个英雄分目录存储。
3.7.2 步骤一:获取英雄名称与详情页连接
随便右键一个英雄的头像,点击检查。可以发现每个英雄都是herolist-content类的无序列表中的一个li。
- 这个li中有一个a标签,a标签的href就是详情页的链接;a标签的文本内容就是英雄名称。
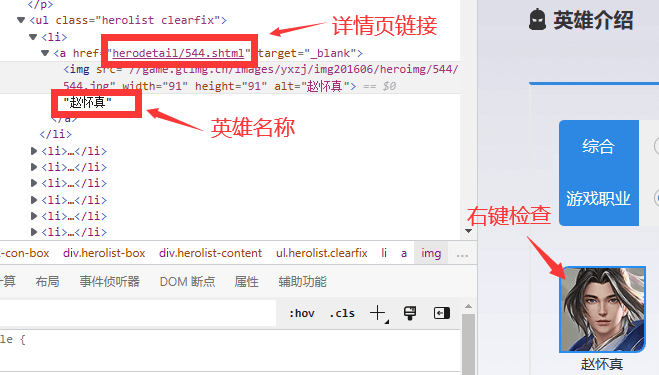
- 编码爬取英雄名称和对应的详情页链接: ```python from selenium import webdriver from selenium.webdriver.common.by import By import time
打开浏览器,访问王者荣耀资料页。
browser = webdriver.Chrome() hero_list_url = “https://pvp.qq.com/web201605/herolist.shtml“ browser.get(hero_list_url) time.sleep(3)
爬取英雄名称与详情页链接。
hero_list = browser.find_elements(by=By.CSS_SELECTOR, value=”.herolist-content > .herolist > li”) hero_infos = [] for hero in hero_list: detail_a = hero.find_element(by=By.TAG_NAME, value=”a”) hero_name = detail_a.text hero_detail_url = detail_a.get_attribute(“href”) hero_infos.append((hero_name, hero_detail_url))
<a name="GIM4Q"></a>#### 3.7.3 步骤二:进入详情页获取皮肤名称和下载链接- 皮肤头像与皮肤大图的关系分析:因为页面中展示完全的只有头像,而皮肤大图只展示选中的那个皮肤。 因此需要分析头像与皮肤大图的关系。- 列表中的第一个英雄一般来说都是刚出不久的新英雄,皮肤很少,这里需要找一个皮肤较多的英雄。- 以嫦娥为例:[https://pvp.qq.com/web201605/herodetail/515.shtml](https://pvp.qq.com/web201605/herodetail/515.shtml)。- 先选中一个皮肤头像,然后右键检查。发现这个img的src为://game.gtimg.cn/images/yxzj/img201606/heroimg/515/515-smallskin-3.jpg,并且这个li中有一个i的子标签为curr类(curr=current)。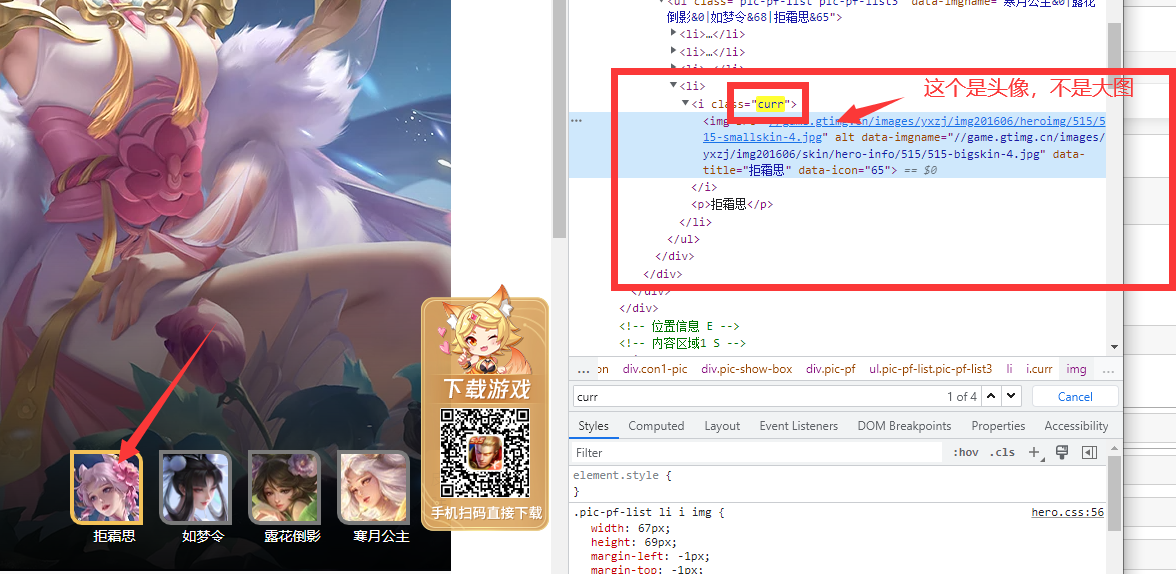- 此时再检查与这个头像对应的皮肤大图,发现这个div中有一个url,为://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/515/515-bigskin-3.jpg。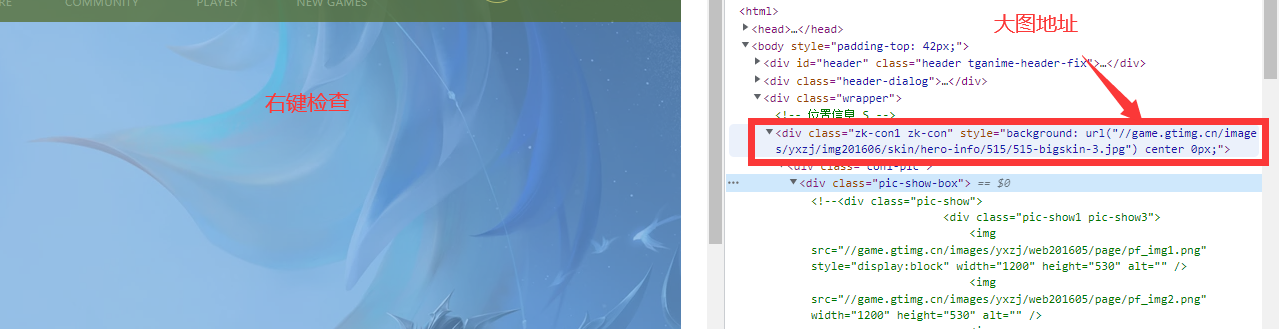- 分析地址可以发现:将头像地址的资源路径的“heroimg”替换成“skin/hero-info”,文件名的“smallskin”替换成“bigskin”即可获取大图地址。- 即只需要获取全部的头像地址,然后根据找到的规律,将头像地址中的特定数据进行一个替换,就可以获取皮肤大图的地址。- 编码爬取皮肤名称和对应的皮肤大图链接:```python# 爬取皮肤名称和皮肤大图链接for hero_info in hero_infos:hero_name = hero_info[0]hero_detail_url = hero_info[1]browser.get(hero_detail_url)print(hero_name)# 提取皮肤列表。skin_list = browser.find_element(by=By.CLASS_NAME, value="pic-pf-list")skins = skin_list.find_elements(by=By.TAG_NAME, value="li")# 提取皮肤名称和皮肤大图地址。for skin in skins:# 提取皮肤名称skin_name = skin.find_element(by=By.TAG_NAME, value="p").text# 提取皮肤头像地址skin_smallskin_url = skin.find_element(by=By.TAG_NAME, value="img").get_attribute("src")# 替换头像地址中的一些信息,得到皮肤地址。skin_bigskin_url = skin_smallskin_url.replace("heroimg", "skin/hero-info").replace("smallskin", "bigskin")print(skin_name, skin_bigskin_url)time.sleep(3)
3.7.4 步骤三:下载图片
- 其实3.7.3中已经获取到了皮肤名称和皮肤图片的下载链接了,那么用requests模块发送请求下载图片即可。 ```python import os import requests
创建WZRY目录,若已存在则忽略。
try: os.mkdir(“WZRY”) except Exception as e: pass
皮肤大图下载函数
def download_skin(skin_url, skin_name, dirname): response = requests.get(skin_url) if response.status_code == 200: with open(f”{dirname}/{skin_name}.jpg”, ‘wb’) as file: file.write(response.content) else: print(f”{skin_name}下载失败”)
进入详情页,爬取皮肤大图。
for hero_info in hero_infos:
# 为每个英雄创建单独的目录。hero_name = hero_info[0]try:os.mkdir(f"WZRY/{hero_name}")except Exception as e:pass# 进入详情页。hero_detail_url = hero_info[1]browser.get(hero_detail_url)# 提取皮肤列表。skin_list = browser.find_element(by=By.CLASS_NAME, value="pic-pf-list")skins = skin_list.find_elements(by=By.TAG_NAME, value="li")# 提取皮肤名称和皮肤大图地址。for skin in skins:# 提取皮肤名称skin_name = skin.find_element(by=By.TAG_NAME, value="p").text# 提取皮肤头像地址skin_smallskin_url = skin.find_element(by=By.TAG_NAME, value="img").get_attribute("src")# 替换头像地址中的一些信息,得到皮肤地址。skin_bigskin_url = skin_smallskin_url.replace("heroimg", "skin/hero-info").replace("smallskin", "bigskin")# 下载皮肤。download_skin(skin_bigskin_url, skin_name, f"WZRY/{hero_name}")time.sleep(3)
<a name="bSXcA"></a>#### 3.7.5 项目代码整合```pythonfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport timeimport requestsimport os# 皮肤大图下载函数def download_skin(skin_url, skin_name, dirname):response = requests.get(skin_url)if response.status_code == 200:with open(f"{dirname}/{skin_name}.jpg", 'wb') as file:file.write(response.content)else:print(f"{skin_name}下载失败")if __name__ == '__main__':# 打开浏览器,访问王者荣耀资料页。browser = webdriver.Chrome()hero_list_url = "https://pvp.qq.com/web201605/herolist.shtml"browser.get(hero_list_url)time.sleep(3)# 爬取英雄名称与详情页链接。hero_list = browser.find_elements(by=By.CSS_SELECTOR, value=".herolist-content > .herolist > li")hero_infos = []for hero in hero_list:detail_a = hero.find_element(by=By.TAG_NAME, value="a")hero_name = detail_a.texthero_detail_url = detail_a.get_attribute("href")hero_infos.append((hero_name, hero_detail_url))# 创建WZRY目录。try:os.mkdir("WZRY")except Exception as e:pass# 进入详情页,爬取皮肤大图。for hero_info in hero_infos:# 为每个英雄创建单独的目录。hero_name = hero_info[0]try:os.mkdir(f"WZRY/{hero_name}")except Exception as e:pass# 进入详情页。hero_detail_url = hero_info[1]browser.get(hero_detail_url)# 提取皮肤列表。skin_list = browser.find_element(by=By.CLASS_NAME, value="pic-pf-list")skins = skin_list.find_elements(by=By.TAG_NAME, value="li")# 提取皮肤名称和皮肤大图地址。for skin in skins:# 提取皮肤名称skin_name = skin.find_element(by=By.TAG_NAME, value="p").text# 提取皮肤头像地址skin_smallskin_url = skin.find_element(by=By.TAG_NAME, value="img").get_attribute("src")# 替换头像地址中的一些信息,得到皮肤地址。skin_bigskin_url = skin_smallskin_url.replace("heroimg", "skin/hero-info").replace("smallskin", "bigskin")# 下载皮肤。download_skin(skin_bigskin_url, skin_name, f"WZRY/{hero_name}")time.sleep(3)
04. 自动登录
4.1 前置知识一:Base64编码
4.1.1 Base64编码介绍
Base64是一种常用的,在网络中传递字节数据的编码解码方式。
4.1.2 Python处理Base64编码
实验数据:这里有张图片(4.2 超级鹰中也要使用),将其保存到项目目录的limg目录内,并命名为yzm.png。

- Python中有一个官方库:
base64,就是专门用来处理base64编码格式的字节数据的。 - 编码:
b64 = base64.b64encode(普通的字节数据)```python import base64
with open(“./img/yzm.png”, “rb”) as file: ima_data = file.read() print(ima_data) # b’\x89PNG\r\n\x……
b64 = base64.b64encode(ima_data) # 将普通的字节数据转换成Base64编码的字节数据 print(b64) # b’iVBORw0KGgoAAAANS……
- 解码:`code = base64.b64decode(Base64编码的数据)````pythonimport base64with open("./img/yzm.png", "rb") as file:ima_data = file.read()print(ima_data) # b'\x89PNG\r\n\x……b64 = base64.b64encode(ima_data)print("\n" * 10)b64_to_img_data = base64.b64decode(b64)print(b64_to_img_data) # b'\x89PNG\r\n\x,发现与原来完成一样# 写一张新图片,图片也与原图完全一致with open("./img/yzm1.png", "wb") as file:file.write(b64_to_img_data)
4.2 前置知识二:超级鹰验证码识别工具
4.2.1 超级鹰工具概述
- 超级鹰是一个验证码识别平台,提供了识别接口,是需要将数据传递给超级鹰平台,就可以获取到识别的结果。
- 官网:https://www.chaojiying.com/
超级鹰的收费很便宜,根据验证码的类型收取费用。验证码类型、验证码描述、官方单价可以参考超级鹰的官方价格体系:https://www.chaojiying.com/price.html
4.2.2 API接入
超级鹰官方提供了各个语言的SDK示例:https://www.chaojiying.com/api-5.html
- 因为它提供的Python示例是基于Python 2开发的,无法直接使用。因此若项目中要接入超级鹰API,可创建
chaojiying.py文件,然后输入以下代码: ```python import requests from hashlib import md5
class ChaojiyingClient(object): def _init(self, username, password, soft_id): self.username = username password = password.encode(‘utf8’) self.password = md5(password).hexdigest() self.soft_id = soft_id self.base_params = { ‘user’: self.username, ‘pass2’: self.password, ‘softid’: self.soft_id, } self.headers = { ‘Connection’: ‘Keep-Alive’, ‘User-Agent’: ‘Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)’, }
def PostPic(self, im, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,}params.update(self.base_params)files = {'userfile': ('ccc.jpg', im)}r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)return r.json()def PostPic_base64(self, base64_str, codetype):"""im: 图片字节codetype: 题目类型 参考 http://www.chaojiying.com/price.html"""params = {'codetype': codetype,'file_base64':base64_str}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)return r.json()def ReportError(self, im_id):"""im_id:报错题目的图片ID"""params = {'id': im_id,}params.update(self.base_params)r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)return r.json()
<a name="jtbR9"></a>#### 4.2.3 API的应用- 首先导入超级鹰客户端,接着构造用户信息,需要传入用户名、密码、软件ID。- 接着读取文件数据,再确定验证码类型,用超级鹰用户对象的`PostPic()`函数即可获取识别的数据。```python# 导入超级鹰客户端from chaojiying import Chaojiying_Client# 构造用户信息。cjy = Chaojiying_Client(username="xiaomu0217",password="xiaomu0217",soft_id="921472" # 软件ID,在用户中心 > 软件ID中可查看。)# 通过用户传递数据信息with open("./img/yzm.png", "rb") as file:img_data = file.read()resp = cjy.PostPic(img_data, # 图片文件数据1902 # 验证码类型,参考价格体系中的信息。)print(resp) # {'err_no': 0, 'err_str': 'OK', 'pic_id': '2184916210691910043', 'pic_str': '7364', 'md5': '910ea36fb879363476fef9556dce6c5d'}
识别结果是一个字典,其中键
pic_str的值就是识别到的数据。2.2.2 解决IP受限问题
当前计算机的IP地址若不在超级鹰的白名单中,就会出现以下错误。
{'err_no': -10071, 'err_str': 'IP受限(39.171.189.8,69191)', 'pic_id': '0', 'pic_str': '', 'md5': ''}
首先查看当前计算机的IP地址:https://www.ip138.com/。
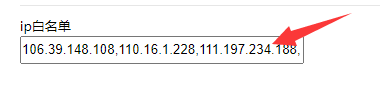
- 获取到当前计算机的IP地址后,到超级鹰的用户中心的IP名单中,将当前IP地址添加到ip白名单中即可。
- ip白名单可以指定多个IP地址,各个IP地址之间用英文逗号分割。
- 设置完成后记得点击提交按钮提交修改。
-
4.3 自动化登录
4.3.1 项目目标与实现流程分析
项目目标:自动登录千峰学员辅学系统:http://stu.1000phone.net/login
- 项目实现流程:
启动浏览器并打开网页
browser = webdriver.Chrome() browser.get(“http://stu.1000phone.net/login“) time.sleep(2)
获取用户名、密码、验证码的输入表单标签并输入数据
username, password, code = browser.find_elements(by=By.CSS_SELECTOR, value=”.el-input__inner”) username.send_keys(“230882199811203111”) password.send_keys(“as168865”)
“””
方式一:获取img标签内的src,其值是Base64编码的图片
方式二:截图获取获取验证码图片。
img = browser.find_element(by=By.CSS_SELECTOR, value=”.code”) img.screenshot(“./img/qfyzm.png”) “””
方式三:直接获取字节数据。
img = browser.find_element(by=By.CSS_SELECTOR, value=”.code”) img_data = img.screenshot_as_png # 直接获取图片的字节数据 print(img_data)
用超级鹰识别验证码
cjy = Chaojiying_Client(username=”xiaomu0217”, password=”xiaomu0217”, soft_id=”921472”) resp = cjy.PostPic(img_data, 1902)
若正常获取验证码识别结果,则将验证码输入,然后点击登录
if resp.get(“err_no”) == 0: code.send_keys(resp.get(“pic_str”)) browser.find_element(By.CSS_SELECTOR, value=”.el-button”).click() # 获取登录标签,并点击登录 time.sleep(60) ```

若有收获,就点个赞吧
0 人点赞
