- 01. Pandas基本数据处理
- 获取上映时间对应的字符串数据。
- 用slice()函数提取目标子串(首个年份即前4个字符)
- 将处理完的时间数据写回给上映时间字段。
- 获取类型字段的字符串数据
- 调用contains()函数判断字符串数据中是否包含喜剧。
- 利用第二步得到的布尔索引获取目标数据。
- 映射函数,传入一个年龄,返回一个结果
- 遍历每个年龄,得到每个结果
- 打印结果
- 根据年份进行分组
- 查看每个年份对应的电影数。
- 将第二步的结果根据年份降序排序。
- 03. 数据清洗
- Column Non-Null Count Dtype
- 最常用的搭配是
DF对象.isnull().any(),可以定位到含有空值的列。 - 这种搭配下布尔索引为True则存在空值。如下列结果说明B、C两列中存在空值。
- 相似的搭配还有
DF对象.notnull().all()。 - 这种搭配下布尔索引为False则存在空值。如下列结果说明2、3行中存在空值。
- 首先,查看一行中是否有空值。
- 接着,用第一步得到的结果就可以过滤出带有空值的行。
- 那么使用一个取反操作,就可以过滤掉含有空值的行。
- 插入一列全为空的测试列Test_Col
- 对全为空的Test_Col列进行删除。
- 可以发现,对于原数据而言,Test_Col列依旧存在。
- 可以发现,此时dropna()函数没有返回值了。
- 并且在原数据中,Test_Col空列也不存在了。
- 3.4 重复数据处理
- 3.4 异常值处理
- 生成10000个满足正态分布的数据。
- 确定这组数据的均值和标准差
- 用三倍标准方差法过滤出异常值数据
- 04. 数据合并(前置课Day18)
01. Pandas基本数据处理
1.1 数据读取
1.1.1 读取Excel文件
- Pandas中的
read_excel()函数可以读取Excel文件,常见的参数有:- io:被读取文件的路径。
- sheet_name:指定工作簿中需要被读取的工作表。
- 这个参数的值可以是字符串,表示的是工作表的表名。
- 也可以是一个整数,表示的是工作表的索引。
- 这个参数的缺省值为0,表示默认加载的是指定工作簿中第一个工作表。
- header:默认为0,即默认将第一行数据当作DataFrame的列索引。
- index_col:默认为None,即默认把行隐式索引当成显示索引。
- 这个参数的值可以自己设置,其值是一个int类型的整数。
- 这个整数表示的是列下标,即将哪一列的值当作DF的行索引。
read_excel()函数支持读取的文件格式包括:xls、xlsx、xlsm、xlsb、odf、ods、odt。示例1:现有一个文件top250.xlsx,将其放到项目的data目录下,然后用Pandas读取出来。
top_250 = pd.read_excel('./data/top250.xlsx')top_250
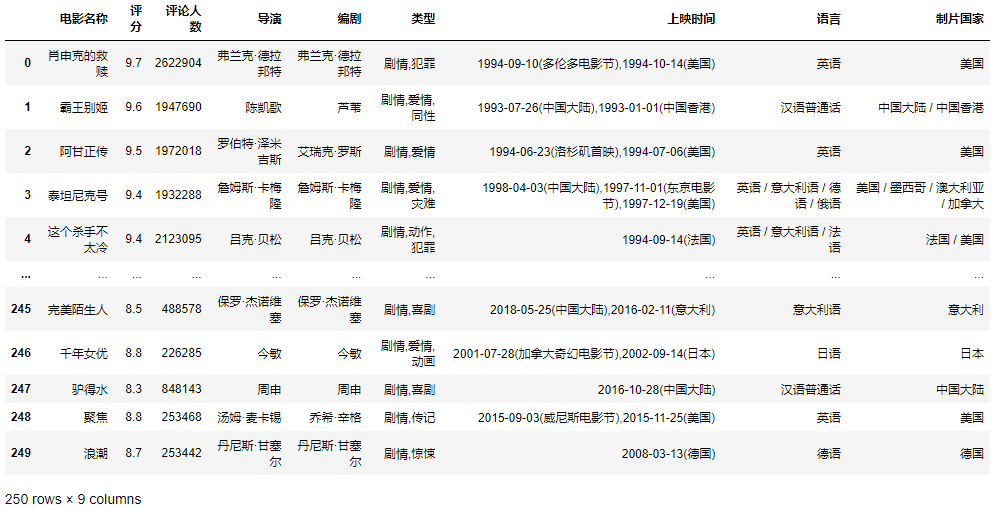
示例2:还是读取top250.xlsx文件,然后将电影名称作为DF的行索引,并查询出肖申克的救赎、泰坦尼克号、完美陌生人的数据。
top_250 = pd.read_excel(io='./data/top250.xlsx', index_col=0)top_250.loc[['肖申克的救赎', '泰坦尼克号', '完美陌生人']]
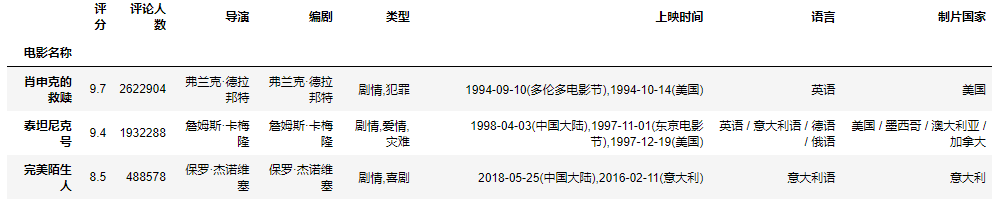
示例3:在示例2的基础上,查询出评分在9.5以上的电影信息以及陈凯歌导演的电影信息。
CSV文件又被称为逗号分隔符文件,在默认情况下,该文件下多个值之间是通过逗号
,来分割的。- Pandas中的
read_csv()函数可以读取CSV文件,常见的参数有:- filepath:文件的路径。
- sep:数据的分隔符,默认是逗号。
- header:列索引。默认为0,即默认将第一行数据当作DataFrame的列索引。
- index_col:行索引。默认为None,即默认把行隐式索引当成显示索引。
- 这个参数的值可以自己设置,其值是一个int类型的整数。
- 这个整数表示的是列下标,即将哪一列的值当作DF的行索引。
示例:现有一个文件penguins.csv,将其放到项目的data目录下,然后用Pandas读取出来。
penguin = pd.read_csv('./data/penguins.csv')
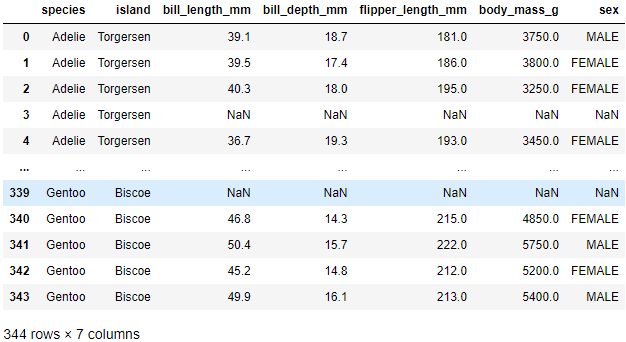
penguins.csv字段解读:species(企鹅的种类)、island(生存的岛屿)、bill_length_mm(喙长)、bill_depth_mm(喙宽)、flipper_length_mm(鳍长)、body_mass_g(体重)、sex(性别)
1.1.3 读取其他文件
Pandas除了可以读取Excel、CSV文件之外,还可以读取其他很多类型的文件。
常见的有:
pd.read_html()读取HTML文件、pd.read_json()读取JSON数据、pd.read_sql()读取数据库、pd.read_xml()读取XML文件、……。1.2 Pandas中的字符串操作
1.2.1 获取字符串数据
Pandas数据对象.str可以获取字符串类型的数据。示例:从top_250中提取语言字段的字符串数据。
>>> top_250['语言'].str<pandas.core.strings.accessor.StringMethods at 0x17c052e39a0>
1.2.2 slice()提取子串
字符串数据对象.slice()函数用于截取子字符串,具体参数如下:- start:起始下标,缺省为0。- stop:结束下标。- step:截取步长,缺省为1。
- 示例:处理top_250中的上映时间数据,具体要求如下:
- 时间数据只保留年份。
- 对于有多个上映时间的电影,只保留首映时间(即第一个时间数据)。
- 编码实现:
```python
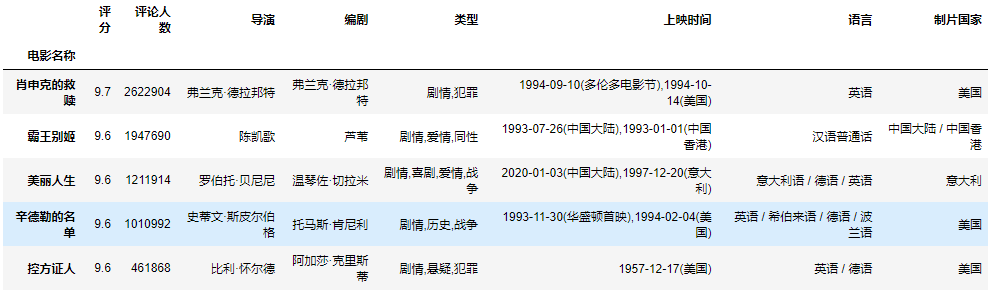
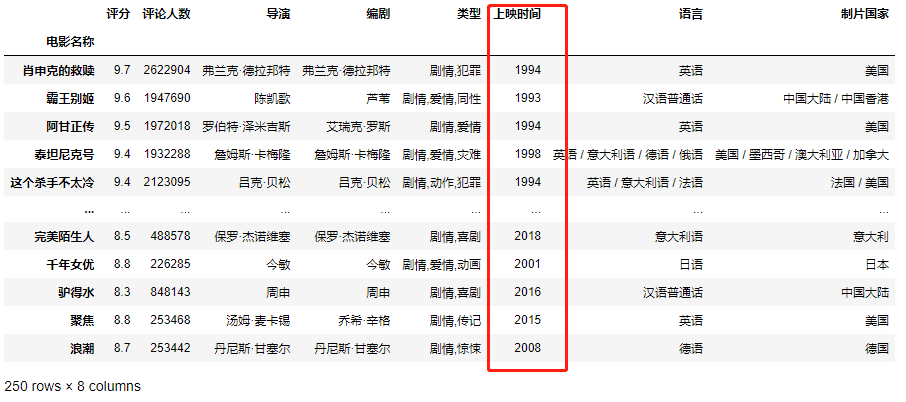
获取上映时间对应的字符串数据。
top_250[“上映时间”].str

用slice()函数提取目标子串(首个年份即前4个字符)
top_250[“上映时间”].str.slice(stop=4) 电影名称 肖申克的救赎 1994 霸王别姬 1993 阿甘正传 1994 泰坦尼克号 1998 这个杀手不太冷 1994 … 完美陌生人 2018 千年女优 2001 驴得水 2016 聚焦 2015 浪潮 2008 Name: 上映时间, Length: 250, dtype: object
将处理完的时间数据写回给上映时间字段。
top_250[‘上映时间’] = top_250[“上映时间”].str.slice(stop=4) top_250 ```
1.2.3 contains()是否包含子字符串
字符串数据对象.contains(sub_string)函数判断字符串数据中是否包含子字符串sub_string。- 若包含子字符串sub_string则该行数据映射为True,否则映射为False。
- 示例:筛选出类型中含有戏剧的电影。
- 编码实现:
```python
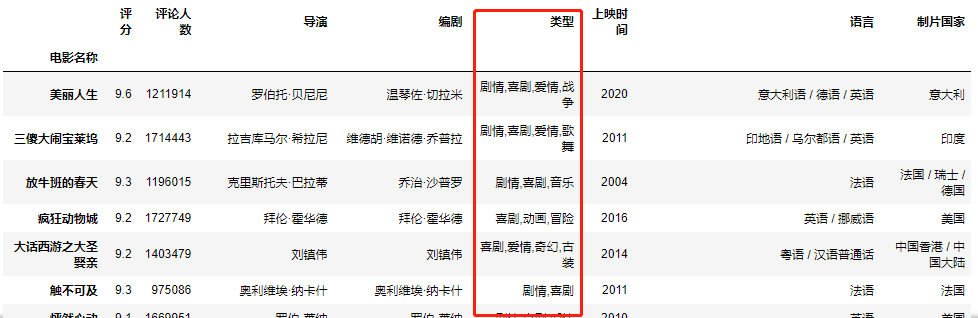
获取类型字段的字符串数据
top_250[‘类型’].str
调用contains()函数判断字符串数据中是否包含喜剧。
top_250[‘类型’].str.contains(‘喜剧’) 电影名称 肖申克的救赎 False 霸王别姬 False 阿甘正传 False 泰坦尼克号 False 这个杀手不太冷 False …
完美陌生人 True 千年女优 False 驴得水 True 聚焦 False 浪潮 False Name: 类型, Length: 250, dtype: bool
利用第二步得到的布尔索引获取目标数据。
top_250[top_250[‘类型’].str.contains(‘喜剧’)] ```
02. 数据的映射与分组操作
2.1 Pandas数据映射操作
2.1.1 映射的概念
- 所谓的映射,就是根据既定的规则,将数据从一种形态转化为另外一种形态。
- 如,现有一个年龄列表
ages = [17, 20, 19, 18, 24, 16],要将18岁以下的映射成未成年,将18岁及以上的映射成成年。 - 这个需求用Python的基础语法可以这么写: ```python ages = [17, 20, 19, 18, 24, 16]
映射函数,传入一个年龄,返回一个结果
def is_adult(age): if age < 18: return “未成年” else: return “成年”
遍历每个年龄,得到每个结果
new_ages = [] for age in ages: result = is_adult(age) new_ages.append(result)
打印结果
print(new_ages) # [‘未成年’, ‘成年’, ‘成年’, ‘成年’, ‘成年’, ‘未成年’]
<a name="cCABg"></a>#### 2.1.2 map()映射操作- `Pandas数据对象.map(func)`会根据函数func中指定的规则,对目标数据进行转换。- 这个函数func需要满足以下两个要求:- 函数有一个形参:用来接收数据。- 函数有一个返回值:返回的是规则对应的映射结果。- 根据4.3.1中的例子,我们知道映射操作需要遍历原始数据。而`map()`函数实际上已经把遍历操作进行了封装,只需要用户给定一个映射函数,`map()`函数就会自动遍历既有数据,并把每个数据传递到函数中,完成对应的映射。- 示例:给电影评分分等级就是一个映射操作,具体可以表现为:- 9.5分以上:评A级;- 9.0~9.5分:评B级;- 8.5~9.0分:评C级;- 8.5分以下:评D级。- 定义一个映射函数:```pythondef movie_level(score):if score > 9.5:return 'A'elif 9.0 < score <= 9.5:return 'B'elif 8.5 < score <= 9.0:return 'C'else:return 'D'
用
map()实现电影评分的映射:# 注意,传递给map()函数的参数是映射函数本身>>> top_250['评分'].map(movie_level)电影名称肖申克的救赎 A霸王别姬 A阿甘正传 B泰坦尼克号 B这个杀手不太冷 B..完美陌生人 D千年女优 C驴得水 D聚焦 C浪潮 CName: 评分, Length: 250, dtype: object
2.2 Pandas数据分组操作
2.2.1 分组的概念
分组是指按照数据中的某个指标对数据进行分类,然后统计一些常见的数学指标。
-
2.2.2 groupby()分组操作
Pandas数据对象.groupby(by='分组字段')会对数据按照指定的内容分组,进而实现一些分组统计操作。- by:用于指定分组的字段;当需要根据多个字段分组时,参数的值是由多个字段构成的列表。
示例:将
top_250数据根据导演进行分组。>>> gp = top_250.groupby(by='导演')>>> gp<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000023B804B4670>
2.2.3 groups查看分组情况
分组对象.groups属性会返回数据的分组情况。groupby属性的值是一个字段,具体为:- Key:分组指标。
- Value:分到Key对应的组下的数据的索引。
示例:查看
top_250数据根据导演进行分组的分组情况。>>> gp.groups{'M·奈特·沙马兰': ['第六感'], '万籁鸣': ['大闹天宫'], '中岛哲也': ['被嫌弃的松子的一生', '告白'], '丹尼·博伊尔': ['贫民窟的百万富翁'], '丹尼斯·甘塞尔': ['浪潮'], '乔·赖特': ['傲慢与偏见'], '乔治·米勒': ['疯狂的麦克斯4:狂暴之路'], '乔纳森·戴米': ['沉默的羔羊'], '亚当·艾略特': ['玛丽和马克思'], '今敏': ['红辣椒', '未麻的部屋', '东京教父', '千年女优'], '伦尼·阿伯拉罕森': ['房间'], '保罗·杰诺维塞': ['完美陌生人'], '保罗·格林格拉斯': ['谍影重重3', '谍影重重2'], '克林特·伊斯特伍德': ['完美的世界'], '克里斯·哥伦布': ['哈利·波特与魔法石', '哈利·波特与密室'], '克里斯托夫·巴拉蒂': ['放牛班的春天'], '克里斯托弗·史密斯': ['恐怖游轮'], '克里斯托弗·诺兰': ['盗梦空间', '星际穿越', '蝙蝠侠:黑暗骑士', '致命魔术', '蝙蝠侠:黑暗骑士崛起', '记忆碎片'], '刘伟强': ['无间道', '无间道2'], '刘镇伟': ['大话西游之大圣娶亲', '大话西游之月光宝盒', '射雕英雄传之东成西就'], '加布里埃莱·穆奇诺': ['当幸福来敲门'], '北野武': ['菊次郎的夏天'], '卡洛斯·沙尔丹哈': ['冰川时代'], '卢卡·瓜达尼诺': ['请以你的名字呼唤我'], '史蒂文·斯皮尔伯格': ['辛德勒的名单', '猫鼠游戏', '拯救大兵瑞恩', '幸福终点站', '头号玩家', '人工智能'], '史蒂芬·戴德利': ['朗读者'], '吕克·贝松': ['这个杀手不太冷'], '吴宇森': ['英雄本色', '纵横四海'], '周星驰': ['喜剧之王', '功夫'], '周申': ['驴得水'], '唐·霍尔': ['超能陆战队'], '埃里克·布雷斯': ['蝴蝶效应'], '大卫·叶茨': ['哈利·波特与死亡圣器(下)'], '大卫·芬奇': ['搏击俱乐部', '本杰明·巴顿奇事', '七宗罪', '消失的爱人'], '大森贵弘': ['萤火之森'], '奉俊昊': ['杀人回忆', '寄生虫'], '奥利维埃·纳卡什': ['触不可及'], '奥里奥尔·保罗': ['看不见的客人'], '姜文': ['鬼子来了', '让子弹飞', '阳光灿烂的日子'], '姜炯哲': ['阳光姐妹淘'], '威廉·惠勒': ['罗马假日'], '娜丁·拉巴基': ['何以为家'], '宁浩': ['疯狂的石头'], '安德鲁·尼科尔': ['千钧一发', '战争之王'], '安德鲁·斯坦顿': ['机器人总动员'], '宫崎骏': ['千与千寻', '龙猫', '哈尔的移动城堡', '天空之城', '幽灵公主', '风之谷', '魔女宅急便', '崖上的波妞'], '尼克·卡萨维蒂': ['恋恋笔记本'], '岩井俊二': ['情书'], '巴瑞·莱文森': ['雨人'], '布莱恩·辛格': ['波西米亚狂想曲'], '延尚昊': ['釜山行'], '弗兰克·德拉邦特': ['肖申克的救赎', '绿里奇迹'], '弗朗西斯·福特·科波拉': ['教父', '教父2', '教父3'], '弗洛里安·亨克尔·冯·多纳斯马尔克': ['窃听风暴'], '张艺谋': ['活着'], '彼得·威尔': ['楚门的世界', '死亡诗社'], '彼得·杰克逊': ['指环王3:王者无敌', '指环王2:双塔奇兵', '指环王1:护戒使者'], '彼得·法雷里': ['绿皮书'], '彼特·道格特': ['飞屋环游记', '怪兽电力公司', '头脑特工队', '心灵奇旅'], '徐克': ['青蛇'], '忻钰坤': ['心迷宫'], '戈尔·维宾斯基': ['加勒比海盗'], '托尼·凯耶': ['超脱'], '托德·菲利普斯': ['小丑'], '托马斯·温特伯格': ['狩猎'], '拉吉库马尔·希拉尼': ['三傻大闹宝莱坞'], '拉娜·沃卓斯基': ['黑客帝国3:矩阵革命', '黑客帝国2:重装上阵'], '拉斯·霍尔斯道姆': ['忠犬八公的故事'], '拜伦·霍华德': ['疯狂动物城'], '文牧野': ['我不是药神'], '斯坦利·多南': ['雨中曲'], '斯坦利·库布里克': ['2001太空漫游'], '斯蒂芬·卓博斯基': ['奇迹男孩'], '新海诚': ['你的名字。'], '昆汀·塔伦蒂诺': ['低俗小说', '被解救的姜戈', '无耻混蛋'], '是枝裕和': ['无人知晓', '海街日记', '小偷家族', '步履不停'], '普特鹏·普罗萨卡·那·萨克那卡林': ['初恋这件小事'], '朗·霍华德': ['美丽心灵'], '朱塞佩·托纳多雷': ['海上钢琴师', '天堂电影院', '西西里的美丽传说'], '朴勋政': ['新世界'], '李·昂克里奇': ['寻梦环游记', '玩具总动员3'], '李力持': ['唐伯虎点秋香'], '李安': ['少年派的奇幻漂流', '饮食男女', '断背山', '喜宴', '色,戒'], '李惠民': ['新龙门客栈'], '李濬益': ['素媛'], '李焕庆': ['7号房的礼物'], '杨宇硕': ['辩护人'], '杨德昌': ['一一', '牯岭街少年杀人事件'], '杰茜·尼尔森': ['我是山姆'], '查理·卓别林': ['摩登时代', '城市之光'], '柯克·德·米科': ['疯狂原始人'], '格斯·范·桑特': ['心灵捕手'], '梅尔·吉布森': ['勇敢的心', '血战钢锯岭'], '森淳一': ['小森林 夏秋篇', '小森林 冬春篇'], '比利·怀尔德': ['控方证人'], '汉内斯·赫尔姆': ['一个叫欧维的男人决定去死'], '汤姆·提克威': ['香水'], '汤姆·麦卡锡': ['聚焦'], '泷田洋二郎': ['入殓师'], '涅提·蒂瓦里': ['摔跤吧!爸爸'], ...}
2.2.4 size()查看每组的数据量
分组对象.size()返回分组后每一组中的数据量,即统计groupby属性中每个Value的长度。示例1:查看
top_250中每个导演的电影数量。>>> gp.size()导演M·奈特·沙马兰 1万籁鸣 1中岛哲也 2丹尼·博伊尔 1丹尼斯·甘塞尔 1..高畑勋 1黄东赫 1黄信尧 1黄建新 1黑泽明 2Length: 174, dtype: int64
示例2:将导演按照电影的数量降序排序。
>>> gp.size().sort_values(ascending=False)导演宫崎骏 8史蒂文·斯皮尔伯格 6克里斯托弗·诺兰 6李安 5王家卫 5..加布里埃莱·穆奇诺 1北野武 1新海诚 1斯蒂芬·卓博斯基 1M·奈特·沙马兰 1Length: 174, dtype: int64
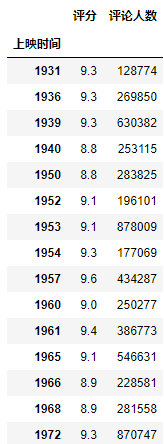
示例3:查看每个年份对应的电影数,并根据年份降序排序。 ```python
根据年份进行分组
gp_by_year = top_250.groupby(by=’上映时间’) gp_by_year.groups {‘1931’: [‘城市之光’], ‘1936’: [‘摩登时代’], ‘1939’: [‘乱世佳人’], ‘1940’: [‘魂断蓝桥’], ‘1950’: [‘罗生门’], ‘1952’: [‘雨中曲’], ‘1953’: [‘罗马假日’], ‘1954’: [‘七武士’], ‘1957’: [‘控方证人’, ‘十二怒汉’], ‘1960’: [‘惊魂记’], ‘1961’: [‘大闹天宫’], ‘1965’: [‘音乐之声’], ‘1966’: [‘虎口脱险’], ‘1968’: [‘2001太空漫游’], ‘1972’: [‘教父’], ‘1974’: [‘教父2’], ‘1975’: [‘飞越疯人院’], ‘1979’: [‘哪吒闹海’], ‘1982’: [‘茶馆’], ‘1984’: [‘美国往事’], ‘1987’: [‘末代皇帝’, ‘忠犬八公物语’], ‘1988’: [‘雨人’, ‘萤火虫之墓’], ‘1989’: [‘死亡诗社’, ‘魔女宅急便’], ‘1990’: [‘剪刀手爱德华’, ‘教父3’], ‘1991’: [‘沉默的羔羊’, ‘纵横四海’, ‘牯岭街少年杀人事件’, ‘终结者2:审判日’, ‘末路狂花’], ‘1992’: [‘天空之城’, ‘闻香识女人’, ‘风之谷’], ‘1993’: [‘霸王别姬’, ‘辛德勒的名单’, ‘唐伯虎点秋香’, ‘完美的世界’, ‘射雕英雄传之东成西就’, ‘喜宴’, ‘青蛇’], ‘1994’: [‘肖申克的救赎’, ‘阿甘正传’, ‘这个杀手不太冷’, ‘活着’, ‘饮食男女’, ‘低俗小说’, ‘重庆森林’, ‘九品芝麻官’, ‘东邪西毒’, ‘背靠背,脸对脸’, ‘燃情岁月’], ‘1995’: [‘狮子王’, ‘七宗罪’, ‘勇敢的心’, ‘爱在黎明破晓前’, ‘阳光灿烂的日子’, ‘侧耳倾听’], ‘1997’: [‘小鞋子’, ‘心灵捕手’, ‘春光乍泄’, ‘幽灵公主’, ‘未麻的部屋’, ‘千钧一发’], ‘1998’: [‘泰坦尼克号’, ‘楚门的世界’, ‘两杆大烟枪’, ‘拯救大兵瑞恩’], ‘1999’: [‘搏击俱乐部’, ‘情书’, ‘喜剧之王’, ‘第六感’, ‘绿里奇迹’], ‘2000’: [‘鬼子来了’, ‘黑客帝国’, ‘西西里的美丽传说’, ‘花样年华’, ‘记忆碎片’], ‘2001’: [‘美丽心灵’, ‘天使爱美丽’, ‘怪兽电力公司’, ‘我是山姆’, ‘人工智能’, ‘千年女优’], ‘2002’: [‘哈利·波特与魔法石’, ‘钢琴家’, ‘指环王1:护戒使者’, ‘上帝之城’, ‘冰川时代’, ‘谍影重重’], ‘2003’: [‘无间道’, ‘猫鼠游戏’, ‘指环王2:双塔奇兵’, ‘致命ID’, ‘杀人回忆’, ‘加勒比海盗’, ‘哈利·波特与密室’, ‘大鱼’, ‘黑客帝国3:矩阵革命’, ‘真爱至上’, ‘无间道2’, ‘东京教父’, ‘黑客帝国2:重装上阵’], ‘2004’: [‘放牛班的春天’, ‘指环王3:王者无敌’, ‘哈尔的移动城堡’, ‘蝴蝶效应’, ‘功夫’, ‘哈利·波特与阿兹卡班的囚徒’, ‘无人知晓’, ‘爱在日落黄昏时’, ‘电锯惊魂’, ‘卢旺达饭店’, ‘恋恋笔记本’, ‘可可西里’, ‘谍影重重2’], ‘2005’: [‘断背山’, ‘幸福终点站’, ‘傲慢与偏见’, ‘哈利·波特与火焰杯’, ‘战争之王’], ‘2006’: [‘窃听风暴’, ‘致命魔术’, ‘被嫌弃的松子的一生’, ‘红辣椒’, ‘疯狂的石头’, ‘血钻’, ‘穿越时空的少女’, ‘香水’], ‘2007’: [‘谍影重重3’, ‘色,戒’, ‘遗愿清单’, ‘地球上的星星’], ‘2008’: [‘机器人总动员’, ‘当幸福来敲门’, ‘蝙蝠侠:黑暗骑士’, ‘本杰明·巴顿奇事’, ‘穿条纹睡衣的男孩’, ‘步履不停’, ‘朗读者’, ‘浪潮’], ‘2009’: [‘忠犬八公的故事’, ‘飞屋环游记’, ‘海豚湾’, ‘玛丽和马克思’, ‘贫民窟的百万富翁’, ‘恐怖游轮’, ‘无耻混蛋’], ‘2010’: [‘盗梦空间’, ‘怦然心动’, ‘让子弹飞’, ‘阿凡达’, ‘禁闭岛’, ‘借东西的小人阿莉埃蒂’, ‘驯龙高手’, ‘玩具总动员3’, ‘告白’, ‘神偷奶爸’, ‘岁月神偷’, ‘黑天鹅’, ‘你看起来好像很好吃’], ‘2011’: [‘三傻大闹宝莱坞’, ‘熔炉’, ‘触不可及’, ‘哈利·波特与死亡圣器(下)’, ‘超脱’, ‘倩女幽魂’, ‘萤火之森’, ‘阳光姐妹淘’, ‘源代码’, ‘海洋’, ‘我爱你’], ‘2012’: [‘少年派的奇幻漂流’, ‘狩猎’, ‘蝙蝠侠:黑暗骑士崛起’, ‘无敌破坏王’, ‘初恋这件小事’, ‘新龙门客栈’], ‘2013’: [‘素媛’, ‘辩护人’, ‘7号房的礼物’, ‘时空恋旅人’, ‘被解救的姜戈’, ‘恐怖直播’, ‘新世界’, ‘达拉斯买家俱乐部’, ‘疯狂原始人’, ‘爱在午夜降临前’, ‘彗星来的那一夜’], ‘2014’: [‘星际穿越’, ‘大话西游之大圣娶亲’, ‘大话西游之月光宝盒’, ‘布达佩斯大饭店’, ‘小森林 夏秋篇’, ‘消失的爱人’, ‘荒蛮故事’, ‘爆裂鼓手’], ‘2015’: [‘超能陆战队’, ‘小森林 冬春篇’, ‘甜蜜蜜’, ‘一个叫欧维的男人决定去死’, ‘模仿游戏’, ‘头脑特工队’, ‘心迷宫’, ‘海街日记’, ‘房间’, ‘疯狂的麦克斯4:狂暴之路’, ‘再次出发之纽约遇见你’, ‘火星救援’, ‘聚焦’], ‘2016’: [‘疯狂动物城’, ‘釜山行’, ‘血战钢锯岭’, ‘你的名字。’, ‘驴得水’], ‘2017’: [‘寻梦环游记’, ‘摔跤吧!爸爸’, ‘看不见的客人’, ‘请以你的名字呼唤我’, ‘一一’, ‘英雄本色’, ‘大佛普拉斯’, ‘海边的曼彻斯特’, ‘二十二’, ‘爱乐之城’], ‘2018’: [‘龙猫’, ‘我不是药神’, ‘头号玩家’, ‘三块广告牌’, ‘小偷家族’, ‘奇迹男孩’, ‘阿飞正传’, ‘完美陌生人’], ‘2019’: [‘千与千寻’, ‘海上钢琴师’, ‘何以为家’, ‘海蒂和爷爷’, ‘绿皮书’, ‘寄生虫’, ‘小丑’, ‘波西米亚狂想曲’], ‘2020’: [‘美丽人生’, ‘菊次郎的夏天’, ‘崖上的波妞’, ‘心灵奇旅’], ‘2021’: [‘天堂电影院’, ‘入殓师’]}
查看每个年份对应的电影数。
gp_by_year.size() 上映时间 1931 1 1936 1 1939 1 1940 1 …… 2018 8 2019 8 2020 4 2021 2 dtype: int64
将第二步的结果根据年份降序排序。
gp_by_year.size().sort_values(ascending=False) 上映时间 2003 13 2004 13 2010 13 2015 13 …… 1979 1 1982 1 1984 1 1931 1 dtype: int64 ```
2.2.5 mean()求分组数据均值
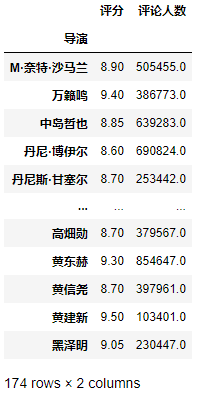
分组对象.mean()会将所有的数值型数据按照分组字段求均值。示例:查看top_250按照导演分组后所有数值型字段的平均值。
gp.mean()
注意:
mean()会根据分组计算所有数值型字段的平均值,若要获取某些指定字段的平均值,可以通过索引实现。示例:获取每位导演的电影的平均评分。
>>> gp.mean()['评分']导演M·奈特·沙马兰 8.90万籁鸣 9.40中岛哲也 8.85丹尼·博伊尔 8.60丹尼斯·甘塞尔 8.70...高畑勋 8.70黄东赫 9.30黄信尧 8.70黄建新 9.50黑泽明 9.05Name: 评分, Length: 174, dtype: float64
2.2.6 agg()多分组统计字段
分组对象.agg(dict)会根据字典dict中的信息进行分组统计。- 其中Key指定分组后统计的字段,Value指定的是运行的操作。
- 如对评分求平均值的Key就是评分,Value就是mean。
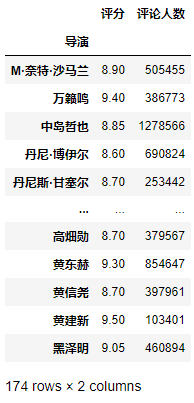
示例1:获取每个导演的电影的评分的平均分,以及评论的总人数。
gp.agg({'评分': 'mean','评论人数': 'sum'})
示例2:每个年份对应的电影中最高的评分以及评论人数最小的数据。
gp_by_year.agg({'评分': 'max','评论人数': 'min'})
03. 数据清洗
3.1 数据清洗的概念
在实际的数据分析过程中,原始数据中可能存在一些错误、缺失、重复、不一致、异常值等问题,这些问题会影响数据的可靠性和准确性,从而对后续的数据分析和决策产生不良影响。
- 数据清洗(Data Cleaning)的目的是使数据更加可靠、准确、完整、一致,并且符合分析需求。通过数据清洗,可以排除无效的数据,提高数据的质量和价值,从而增强数据分析的可信度和实用性。
因此数据清洗是数据分析建模之前必做的一步操作,主要包括缺失值(空值)、异常值(离群点)、重复数据处理这三部分。
3.2 空值处理
3.2.1 空值的认识与基本处理思路
Python数据处理时可能会遇到两种空值,即None和np.nan。
- None:是Python自带的空对象,不能参与到运算中。
- np.nan:是浮点类型,能参与到计算中,但计算的结果永远都是NaN。
- 在Pandas数据处理中,会自动把None转换成np.nan运算,因为None的运行效率比np.nan要慢得多,而对于海量数据的处理而言,效率也是比较重要的。
对于空值一般有填充数据、舍弃数据两种。
生成一个5行5列的DataFrame。
data = np.random.randint(80, 100, size=(5, 5))df = DataFrame(data=data, columns=list('ABCDE'))
将两个单元格设为空。
df.loc[2, 'B'] = df.loc[3, 'C'] = np.nandf
3.2.3 info()查看数据缺失信息
可以通过
DF对象.info()查看每一列中是否存在空值。
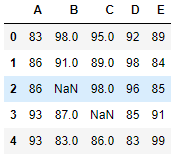
0 A 5 non-null int32 1 B 4 non-null float64 2 C 4 non-null float64 3 D 5 non-null int32 4 E 5 non-null int32 dtypes: float64(2), int32(3) memory usage: 268.0 bytes
<a name="he5UN"></a>#### 3.2.4 isnull()/notnull()/all()/any()定位缺失值- `isnull()`/`notnull()`是一对相反的函数,用于判断某个单元格是否为空。- `DF对象.isnull()`用于判断哪些单元格是空值,若是np.nan则为True,否则为False。- `DF对象.notnull()`用于判断哪些单元格是非空值,若是np.nan则为False,否则为True。```pythondf.isnull()df.notnull()
")
")
all()/any()一般配合着isnull()/notnull()使用,实现定位空值的功能。
相似的搭配还有DF对象.notnull().all()。
这种搭配下布尔索引为False则存在空值。如下列结果说明2、3行中存在空值。
df.notnull().all(axis=1) 0 True 1 True 2 False 3 False 4 True dtype: bool ```
3.2.5 过滤空值数据(索引方式)
- 所谓的过滤空值数据,实际上就是将含有空值的行或列删除掉。
- 一般情况下都会选择删除含有空值的行。
- 在实际业务场景中,缺失值占整个数据集的比例较大(如超过20%),一般会考虑删除包含缺失值的行。
- 数据的过滤可以使用布尔值。(相比于
dropna()函数而言,用索引过滤空值操作更为灵活)
接着,用第一步得到的结果就可以过滤出带有空值的行。
df[df.isnull().any(axis=1)] A B C D E 2 86.0 NaN 98.0 96.0 85.0 3 93.0 87.0 NaN 85.0 91.0
那么使用一个取反操作,就可以过滤掉含有空值的行。
df[~df.isnull().any(axis=1)] A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 4 93.0 83.0 86.0 83.0 99.0 ```
使用
notnull().all()的组合也可以实现同样的效果:>>> df[df.notnull().all(axis=1)]A B C D E0 83.0 98.0 95.0 92.0 89.01 86.0 91.0 89.0 98.0 84.04 93.0 83.0 86.0 83.0 99.0
过滤含有空值的列实际上也是一个思路。首先获取非空的列索引,然后用列索引过滤元素即可。
>>> df.loc[:, df.notnull().all()]A D E0 83.0 92.0 89.01 86.0 98.0 84.02 86.0 96.0 85.03 93.0 85.0 91.04 93.0 83.0 99.0
3.2.6 过滤空值数据(dropna()函数方式)
dropna()默认情况下会过滤掉存在空值的行。>>> df.dropna()A B C D E0 83.0 98.0 95.0 92.0 89.01 86.0 91.0 89.0 98.0 84.04 93.0 83.0 86.0 83.0 99.0
- 指定维度后也可以过滤掉存在空值的列。
>>> df.dropna(axis=1)A D E0 83.0 92.0 89.01 86.0 98.0 84.02 86.0 96.0 85.03 93.0 85.0 91.04 93.0 83.0 99.0
可选参数1:
how指定删除方式。- 参数
how的默认值为any,表示只要在维度上存在空值,就过滤掉。 ```pythondf.dropna() A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 4 93.0 83.0 86.0 83.0 99.0
- 参数
df.dropna(how=’any’) A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 4 93.0 83.0 86.0 83.0 99.0 ```
- 当参数
how的值为all时,表示只有当维度上全部为空时,才过滤掉。 ```pythondf.dropna(how=’all’) A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 NaN 98.0 96.0 85.0 3 93.0 87.0 NaN 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0
插入一列全为空的测试列Test_Col
df.loc[:, ‘Test_Col’] = np.nan df A B C D E Test_Col 0 83.0 98.0 95.0 92.0 89.0 NaN 1 86.0 91.0 89.0 98.0 84.0 NaN 2 86.0 NaN 98.0 96.0 85.0 NaN 3 93.0 87.0 NaN 85.0 91.0 NaN 4 93.0 83.0 86.0 83.0 99.0 NaN
对全为空的Test_Col列进行删除。
df.dropna(how=’all’, axis=1) A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 NaN 98.0 96.0 85.0 3 93.0 87.0 NaN 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0 ```
- 可选参数2:
inplace替换原数据。inplace的默认值为False,即dropna()函数的操作不会影响到原数据。 ```pythondf.dropna(how=’all’, axis=1) A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 NaN 98.0 96.0 85.0 3 93.0 87.0 NaN 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0
可以发现,对于原数据而言,Test_Col列依旧存在。
df A B C D E Test_Col 0 83.0 98.0 95.0 92.0 89.0 NaN 1 86.0 91.0 89.0 98.0 84.0 NaN 2 86.0 NaN 98.0 96.0 85.0 NaN 3 93.0 87.0 NaN 85.0 91.0 NaN 4 93.0 83.0 86.0 83.0 99.0 NaN ```
- 当
inplace的值为True时,dropna()函数的操作将影响原数据。 ```python可以发现,此时dropna()函数没有返回值了。
df.dropna(how=’all’, axis=1, inplace=True)
并且在原数据中,Test_Col空列也不存在了。
df A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 NaN 98.0 96.0 85.0 3 93.0 87.0 NaN 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0 ```
3.2.7 fillna()填充数据
DF对象.fillna()会向DataFrame对象中的空值中填充数据,并且有以下几个参数:- value:指定填充的内容。
- limit:指定填充的个数。
- method:指定填充的方式,有两类值:
- pad/ffill:使用同维度上的前一个值填充。
- backfill/bfill:使用同维度上的下一个值填充。
示例一:将df中所有的空值都填充为100。(不合理)
>>> df.fillna(value=100)A B C D E0 83.0 98.0 95.0 92.0 89.01 86.0 91.0 89.0 98.0 84.02 86.0 100.0 98.0 96.0 85.03 93.0 87.0 100.0 85.0 91.04 93.0 83.0 86.0 83.0 99.0
示例二:使用同一行中的前一个值填充空值,以及使用同一列中的下一个值填充。 ```python
df.fillna(method=’pad’, axis=1)
A B C D E
0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 86.0 98.0 96.0 85.0 3 93.0 87.0 87.0 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0
df.fillna(method=’bfill’) A B C D E 0 83.0 98.0 95.0 92.0 89.0 1 86.0 91.0 89.0 98.0 84.0 2 86.0 87.0 98.0 96.0 85.0 3 93.0 87.0 86.0 85.0 91.0 4 93.0 83.0 86.0 83.0 99.0 ```
3.2.8 replace()以替换的方式填充空值(推荐)
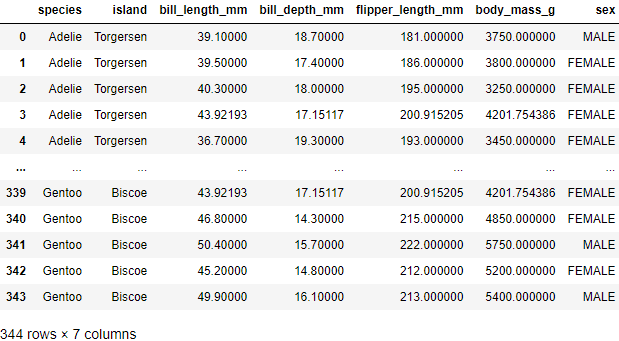
DF对象.replace(字典)会根据字典中指定的规则,将指定字段中的空值替换成指定的内容。(相比于fillna()统一填充,这种方式更为合理)示例:将企鹅penguin数据中的空值进行处理,规则为:
- 将sex字段的空值替换为FEMALE、species字段的空值替换为Adelie、island字段的空值替换为Torgersen。
- 将bill_length_mm、bill_depth_mm、flipper_length_mm、body_mass_g四个字段的空值替换成该字段的平均值。
penguin.replace({'sex': {np.nan: 'FEMALE'},'species': {np.nan: 'Adelie'},'island': {np.nan: 'Torgersen'},'bill_length_mm': {np.nan: penguin.bill_length_mm.mean()},'bill_depth_mm': {np.nan: penguin.bill_depth_mm.mean()},'flipper_length_mm': {np.nan: penguin.flipper_length_mm.mean()},'body_mass_g': {np.nan: penguin.body_mass_g.mean()}})
3.4 重复数据处理
3.4.1 重复值的概念与实现数据准备
对于数据中的某两行,其值完全一样时,那这两行就被认为是重复的。
- 对于重复值处理主要有
duplicated()检测重复行、drop_duplicates()删除重复行两个函数。 如以下例子中的第1行和第2行就是重复行。
index = np.array(range(1, 6))columns = np.array(list('ABCD'))data = np.array([['A1', 'B1', 'C1', 'D1'],['A1', 'B1', 'C1', 'D1'],['A2', 'B2', 'C2', 'D2'],['A3', 'B1', 'C1', 'D3'],['A1', 'B1', 'C1', 'D1']])df = DataFrame(data=data, index=index, columns=columns)df
3.4.2 duplicated()检测重复行
DF对象.duplicated([keep='first'][, subset=])在空参时会依次遍历每一行,将该行与之前的所有行进行比较。若该行与之前的所有行有重复,则该行为True,否则为False。示例:判断df中哪些行是重复行。(从结果可以看出,第2行和第5行是重复的)
>>> df.duplicated()1 False2 True3 False4 False5 Truedtype: bool
duplicated()函数参数一:keep参数,存在以下三个值:first(默认值):保留首行,即认为重复数据的第一行不是重复行。
>>> df.duplicated(keep='first')1 False2 True3 False4 False5 Truedtype: bool
last:保留尾行,即认为重复数据的最后一行不是重复行。
>>> df.duplicated(keep='last')1 True2 True3 False4 False5 Falsedtype: bool
False:不保留,即认为所有重复的数据都是重复行。
>>> df.duplicated(keep=False)1 True2 True3 False4 False5 Truedtype: bool
duplicated()函数参数二:subset参数- 在一些场景下,如针对于个人信息表,若两条数据中的身份证号码和姓名是重复的,那么不管其他字段的数据是否是重复的,这两条数据都会被认为是重复数据。
- 如针对于现在这个df而言,第4行数据和第1、2、3、5行数据都是不重复的,但若仅看B列,则第4行与1、2、5行是重复的。
subset参数的值是个列表,用来指定两行数据根据哪些字段判断是否重复的。- 只有当
subset中的所有字段的值全部一样时,两行数据才被认为是重复的。 subset默认是所有字段,即在默认情况下,只有当两行数据中所有字段的数据全部一样时,这两行数据才会被认为重复。
- 只有当
- 示例:仅看B列,检测df中哪些字段是重复的,且不保留任何行。
>>> df.duplicated(keep=False, subset=['B'])1 True2 True3 False4 True5 Truedtype: bool
3.4.3 drop_duplicates()删除重复行
DF对象.drop_duplicates()用于删除DF对象中重复的行,其参数与duplicated()函数一样。示例1:删除df中完全相同的两行,且保留首行。
>>> df.drop_duplicates()A B C D1 A1 B1 C1 D13 A2 B2 C2 D24 A3 B1 C1 D3
示例2:仅看B列,删除df中的重复值,但保留最后一行。
>>> df.drop_duplicates(keep='last', subset=['B'])A B C D3 A2 B2 C2 D25 A1 B1 C1 D1
3.4 异常值处理
3.4.1 异常值的认识
异常值的基本认识:
- 异常值又称为离群值,即超出普遍分布范围的非正常数据。异常值会影响数据模型的精准度,因此异常值处理是数据预处理中最重要的一步。
- 异常值的处理与缺失值相同,有删除和填充两种方式,因此异常值可以和缺失值一起处理。
- 故异常值处理的重点就在于异常值的检测,检测异常值的方法有三种:业务逻辑法、三倍标准方差法、箱线图法。
- 异常值的影响:
- 异常值会增加整体数据的方差,降低统计学检测的权威性。
- 异常值是随机分布,因此可能会改变数据集的正态分布。
- 可能会对回归、ANOVA、T检验等统计学假设的结果产生影响。
现有以下两组数据:可以发现,函数有异常值的数据的均值变高了,标准差也特别大,故异常值会直接严重影响数据的描述性统计。
业务逻辑法查找异常值即根据对业务的理解,确定数据指标的合理范围,凡是超过这个范围的数据都是异常值数据。
如年龄为-35岁、身高为522cm等都是可以用业务逻辑法找到的异常值。
3.4.3 3σ原则
当数据集是服从参数
 的正态分布(也称高斯分布)时,被记作
的正态分布(也称高斯分布)时,被记作 ,此时数据分布图像如下:
,此时数据分布图像如下:- x轴表示数据的大小;y轴表示这个大小的数据在数据集中的个数。

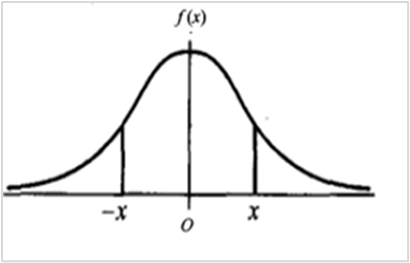
- 这幅图描述的是满足正态分布的数据中数据
 的分布概率与数据集的标准差
的分布概率与数据集的标准差 的关系:
的关系:- 数据分布在
 中的概率为0.6826。(一倍标准差)
中的概率为0.6826。(一倍标准差) - 数据分布在
 中的概率为0.9545。(二倍标准差)
中的概率为0.9545。(二倍标准差) - 数据分布在
 中的概率为0.9973。(三倍标准差)
中的概率为0.9973。(三倍标准差) - 由此可以认为,Y的取值几乎全部集中在
 这个区间内,超出这个范围的概率不到0.3%。
这个区间内,超出这个范围的概率不到0.3%。
- 数据分布在
- 三倍标准法(又称3σ原则)指在满足正态分布的数据中,数据
 与均值
与均值 之间的距离的绝对值大于三倍标准差时,该数据被认为是异常值,即:
之间的距离的绝对值大于三倍标准差时,该数据被认为是异常值,即:

- 注意点:
- 3σ原则仅针对于满足正态分布的数据。(对于不满足正态分布的数据,不能使用3σ原则)
- 三倍标准差只是一个普遍通用的标准,具体取几倍标准差可能会根据公司口径和具体业务场景出现一些偏差。
- 示例:用
numpy.random.randn函数生成一万个满足正态分布的数据,然后定位出这组数据中的异常值。 ```python import numpy as np
生成10000个满足正态分布的数据。
data = np.random.randn(10000)
确定这组数据的均值和标准差
data_mean = data.mean() data_std = data.std()
用三倍标准方差法过滤出异常值数据
for tmp in data: if abs(tmp - data_mean) >= 3 * data_std: print(tmp)
- 对于检测到的异常值,可以将其修改为均值,这样就可以确保填充的数据是在三倍标准方差这个区间内的,从而不会产生新的异常数据。- 判断是否有异常值。```python# 判断一个数据与均值的距离是否大于三倍标准方差。>>> (np.abs(data - data_mean) >= 3 * data_std).any()True
将异常值替换为总体均值。
data[np.abs(data - data_mean) >= 3 * data_std] = data.mean()
再次进行检测,发现已经没有异常数据了。
>>> (np.abs(data - data_mean) >= 3 * data_std).any()False
3.4.4 箱线图法
- 箱线图法是根据数据的两个四分卫点和实际数据确定数据的上下边缘,落在上下边缘外的数据就被认为是异常值数据。
- 箱线图的绘制方法:(数据:170、176、175、172、170、180、165、170、200)
- 拿到数据后先对数据进行排序:165、170、170、170、172、175、176、180、200。
- 接着得出:中位数
 ;下半部分数据:165、170、170、170;下半部分数据:175、176、180、200。
;下半部分数据:165、170、170、170;下半部分数据:175、176、180、200。 - 接着可以计算出:下四分位数
 ;上四分位数
;上四分位数 。
。 - 由此可以计算出这组数据的四分位距:
 。
。 - 接着,Q3和Q1都各自向上、下延申1.5倍IQR,得到:上界
 ,下界
,下界 。
。 - 但是原数据中大于下界的最大值为165,小于上界的最大值为180,因此上下界会调整为:上界180,下界165。
- 在
 这个区间外的数据,就被认为是异常值,故这里的异常值为200。
这个区间外的数据,就被认为是异常值,故这里的异常值为200。
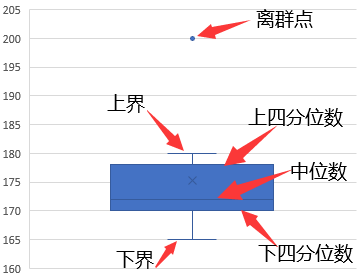
(扩展)Pandas中对于n项数据的四分位数的默认计算方法:
Pandas Source Document: interpolation : {‘linear’, ‘lower’, ‘higher’, ‘midpoint’, ‘nearest’}
This optional parameter specifies the interpolation method to use,when the desired quantile lies between two data points `i` and `j`:* linear: `i + (j - i) * fraction`, where `fraction` is thefractional part of the index surrounded by `i` and `j`.* lower: `i`.* higher: `j`.* nearest: `i` or `j` whichever is nearest.* midpoint: (`i` + `j`) / 2.
Other Document:https://www.lmlphp.com/user/59082/article/item/2676703/
- 确定p分为数的位置:

- 分位数:fraction的值为pos的小数部分。
- 若
 :
: ,data的索引从1开始。
,data的索引从1开始。 - 若
 :
: ,i是pos左边的数据,j是pos右边的数据。
,i是pos左边的数据,j是pos右边的数据。
- 若
- 以上述数据为例:

- 使用matplotlib绘制箱线图:
- 首先将数据封装成Series。
- 首先导入
matplotlib.pyplot模块。 - 接着,这个模块中的
boxplot()函数会根据传入的参数绘制箱线图。 - 最后,用模块中的
show()函数将绘制的图表展示出来即可。 ```python import numpy as np import matplotlib.pyplot as plt
data = np.array([170, 176, 175, 172, 170, 180, 165, 170, 200])
plt.boxplot(arr) plt.show()
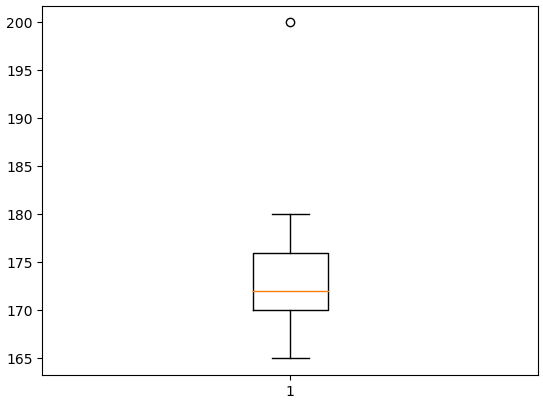- 使用箱线图法处理异常数据:- 先用`np.quantile(a=数据, q=分位点)`函数获取Q1和Q3,然后计算出IQR。- 接着,过滤出在延申1.5倍IQR后范围外的数据。```pythonimport numpy as npimport matplotlib.pyplot as pltdata = np.array([170, 176, 175, 172, 170, 180, 165, 170, 200])# 计算极差Q1, Q3 = np.quantile(a=data, q=[0.25, 0.75])IQR = Q3 - Q1# 过滤出异常值print(data[(data < Q1 - 1.5 * IQR) | (data > Q3 + 1.5 * IQR)]) # [200]
此时,可以将定位到的异常值替换为均值。
data[(data < Q1 - 1.5 * IQR) | (data > Q3 + 1.5 * IQR)] = data.mean()
处理完成后,再尝试定位一次异常值,验证处理结果。
>>> data[(data < Q1 - 1.5 * IQR) | (data > Q3 + 1.5 * IQR)][]
04. 数据合并(前置课Day18)
4.1 合并数据的概念
- Pandas中的DataFrame实际上就是一种二维表结构。
- SQL阶段有讲过,在一些业务场景下会存在着多张表,而这些表之间会存在着一些联系,此时就可以根据这些表中
- 阿斯顿
- 阿斯顿

若有收获,就点个赞吧
0 人点赞
