01. Scrapy简介
1.1 Scrapy基本认识
- Scrapy是目前为止最牛的,一个用纯Python实现的为了爬取网站数据、提取结构性数据而编写的爬虫框架。
- 爬虫的三大步骤为:数据爬取、数据提取、数据存储,在Scrapy中完全内置了数据爬取与提取功能,唯一不足的是数据存储需要开发者自己手写大部分功能。
- 框架的优点:
- 所有框架(不管是Scrapy这种爬虫框架,还是Django这种Web框架)都是为了简化开发而出现的。
- 如果使用框架反而使得开发复杂化,那就没有理由使用框架了,而是可以直接开发,比如直接用requests爬取数据就好了,干嘛还要Scrapy。
- 框架在设计时会预留很多功能,假如开发者只使用了其中的一个功能,那可能代码会比直接开发来的多,但是若使用了一百个甚至更多的功能,那肯定是使用框架的代码更简洁。
- 而且框架会使得开发更加的规范性,使程序有更好的健壮性与可扩展性,并且更加的易于维护。
框架的缺点:框架需要一下子接收很多预留的功能,这就要求开发者至少了解这个框架的基本思想,才能更好的上手开发。
1.2 相关资料
Scrapy官网:https://scrapy.org/
- GitHub:https://github.com/scrapy/scrapy
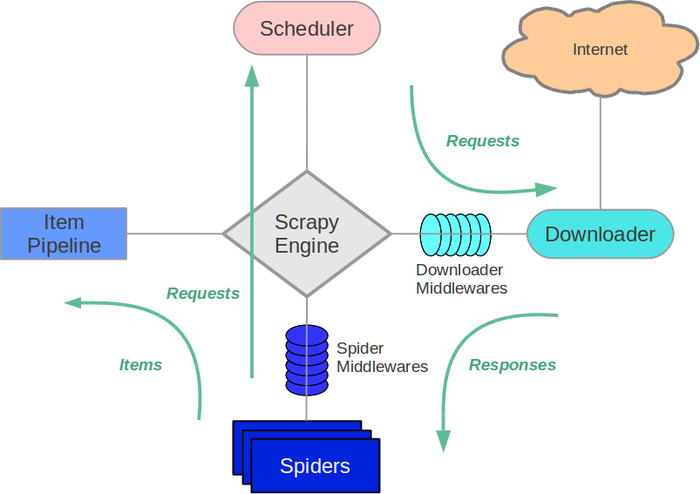
Scrapy框架由一些核心组件与一些中间件组成。
- Scrapy的五大核心组件:
- Scrapy Engine:Scrapy框架的引擎。是Scrapy框架的核心,用于整个系统的数据流处理、触发事务。
- Scheduler:调度器。
- Scrapy爬虫会有很多很多的请求,这些引擎发送出来的请求会先进入调度器。
- 调度器中存在一个请求队列,所有的请求会先进入这个队列,然后由调度器根据规则发出去。
- 队列可以是顺序队列,也可以是优先级队列,即请求发送的先后顺序由调度器决定。
- Downloader:下载器。处理Scheduler的请求,去网络中实际下载页面内容,并将请求的响应返回给Spider。
- Spider:爬虫。
- 在这里定义了数据爬取的逻辑与网页解析的规则,主要负责解析Downloader提供的响应并生成提取结果和新的请求。
- 一个Scrapy程序可以有许多个Spider。
- Item Pipeline:项目管道。
- Spider的结果会封装成一个个的Item,Item中定义了爬取数据的数据结构。
- Item Pipeline负责处理爬虫从网页中抽取的Item,主要包括数据清洗、验证和存储。
Scrapy的两个中间件:
开发者会在Spider中编写爬虫程序,当Scrapy启动时,会根据Spiders中的程序构造请求。
- 请求首先会进入Scheduler调度器中,然后在Scheduler中所有的请求会组成队列。
- 按照队列的先后顺序,Scheduler中的请求会通过Downloader Middleware转发给Downloader,Downloader此时会实际去Internet中下载数据。
- 数据下载完成后,Downloader会生成Response,然后再通过Downloader Middleware将Response转发给引擎。
- 引擎从Downloader中接受Response,并将其通过Spider Middleware发送给Spider进行进一步处理,包括:
- 数据的提取:根据前面的开发经验,Response过来的数据需要经过提取才可以变成我们想要的数据。
- 构建新的请求:
- 像新片场爬虫中,我们请求完广告页后,还要请求详情页;
- 再比如有些网站有很多页,一个页面的数据请求完成后,还需要继续请求下一个页面的数据。
- 这些新的请求都在Spider中构建。
- Spiders中的数据提取完成后,会封装成Item,Item会进入Item Pipeline进行数据清洗与验证,最后实现存储。
- 而Spiders中新构建出来的请求则会循环上述步骤,直到所有请求都被处理完成,则Scrapy结束。
02. 第一个Scrapy程序
2.1 Scrapy模块的安装
Scrapy依旧可以使用pip工具进行安装,命令如下:
pip install scrapy
2.2 Scrapy工程的创建
2.2.1 创建Scrapy基本工程
Scrapy是一个比较庞大的框架,因此Scrapy需要使用指令创建工程。
- Scrapy创建工程的指令:
scrapy startproject ProjectName```shell进入项目目录
(base) D:>cd Project\Python
创建一个名为HelloScrapy的工程。
(base) D:\Project\Python>scrapy startproject HelloScrapy New Scrapy project ‘HelloScrapy’, using template directory ‘C:\ProgramData\Anaconda3\lib\site-packages\scrapy\templates\project’, created in: D:\Project\Python\HelloScrapy
You can start your first spider with: cd HelloScrapy scrapy genspider example example.com
<a name="U9ord"></a>#### 2.2.2 使用PyCharm打开Scrapy工程- 点击File >> Open >> 找到刚生成的Scrapy工程 >> 点击OK。- 指的注意的是,`scrapy startproject ProjectName`命令生成的工程会有两级目录。- 我们需要打开的是第一层目录(一定不能打开第二层),否则后续开发中会出现各种错误。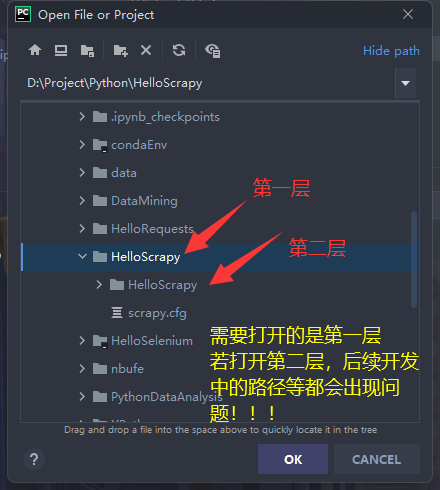- 正确打开之后,PyCharm中的项目结构如下图所示。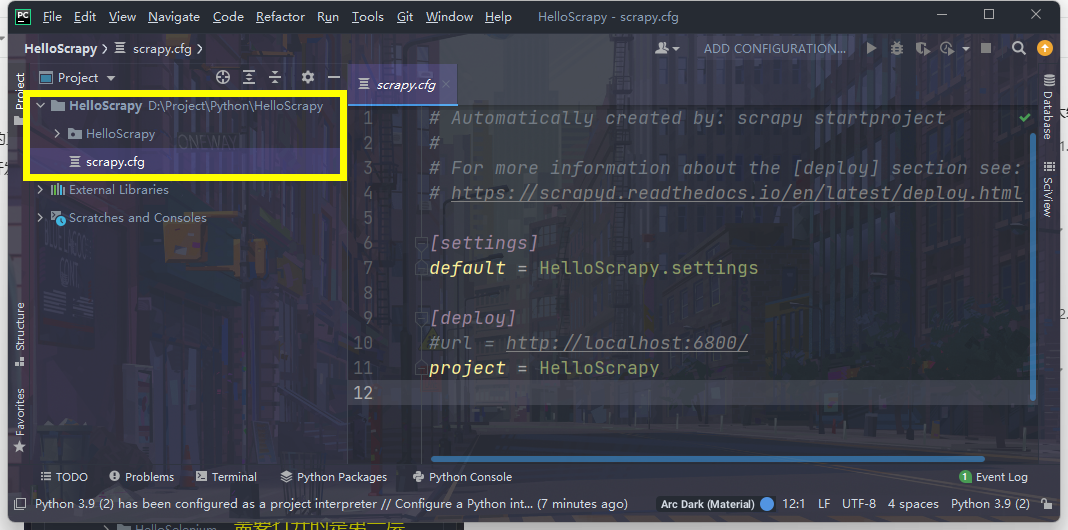<a name="RWboL"></a>### 2.3 Scrapy工程结构描述- 以HelloScrapy这个工程名为为例,创建出来项目结构为:- 可以看到,项目中没有Scrapy Engine、Scheduler、Downloader这些结构。- 这是因为Scrapy不需要开发者实现调度、加载这些过程,框架会自动解决这些问题。```pythonHelloScrapy|- HelloScrapy -- 与工程同名的一个包|- spiders -- 爬虫包,Scrapy工程的所有spider代码都写在这个包下|- init.py|- init.py|- items.py -- 项目存储结构|- middlewares.py -- 中间件|- pipelines.py -- 项目管道|- settings.py -- 配置文件|- scrapy.cfg
开发Scrapy项目主要在spiders中进行编码,即开发者要做的只有构建请求、提取并存储数据。
2.4 生成Scrapy工程与结构基本认识
还是爬新片场,地址:https://www.xinpianchang.com/
2.4.1 生成Scrapy工程
Scrapy程序需要在工程根目录下使用命令生成爬虫,其命令格式为:
scrapy genspider SipderName URL- 注意:URL仅有地址,不包含协议。
- 如百度(https://www.baidu.com/)在这里的URL为:
www.baidu.com
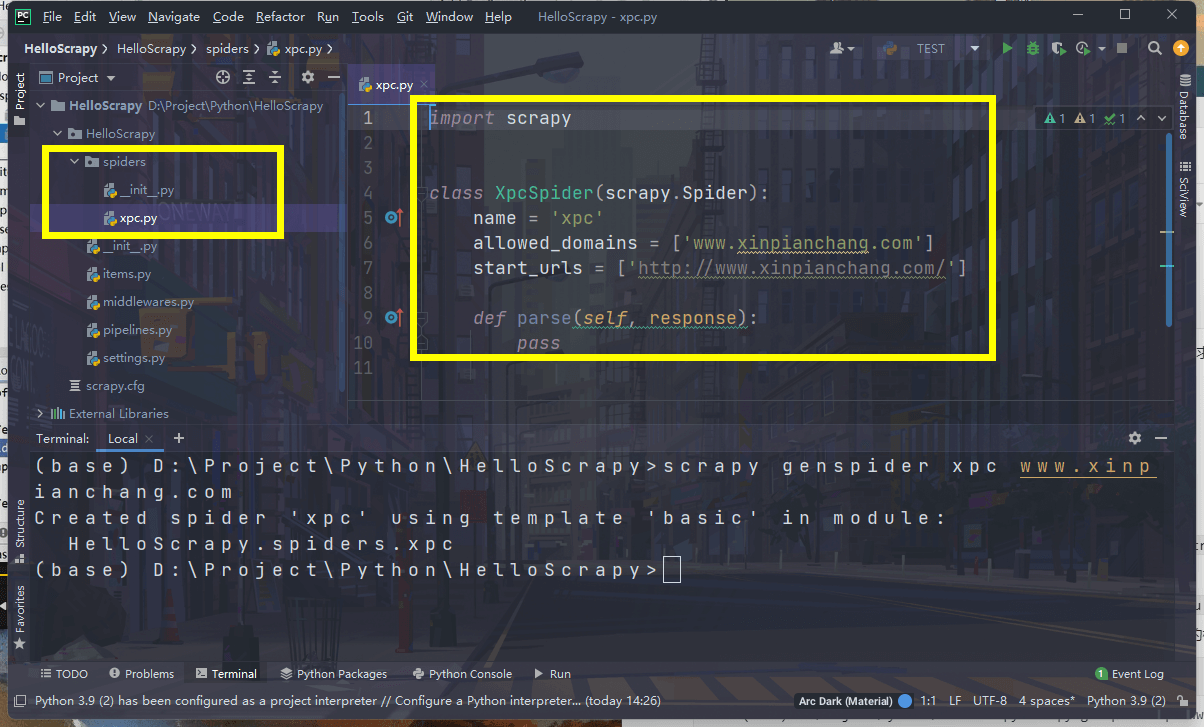
示例:在HelloScrapy中生成一个xpc的爬虫,需要在HelloScrapy项目的根目录下输入以下命令:
(base) D:\Project\Python\HelloScrapy>scrapy genspider xpc www.xinpianchang.comCreated spider 'xpc' using template 'basic' in module:HelloScrapy.spiders.xpc
此时,spiders包中会一个
xpc.py的文件,这个文件中包含一些新片场爬虫的初始化信息。
2.4.2 spider程序结构分析
- 在2.4.1中使用
scrapy genspider xpc www.xinpianchang.com生成了一个新片场爬虫,这个程序的代码如下: ```python import scrapy
class XpcSpider(scrapy.Spider): name = ‘xpc’ allowed_domains = [‘www.xinpianchang.com’] start_urls = [‘http://www.xinpianchang.com/‘]
def parse(self, response):pass
- 从代码中可以看出,这是一个纯OOP的结构。并且一个类如果想要是Scrapy的爬虫的话,需要继承`scrapy.Spider`类。- 这个类中有三个基础属性:- name:爬虫的名字。- allowed_domains:允许的主站。- 即只有allowed_domains这个列表中存在的网站是可以爬取的,如XpcSpider允许爬虫的网站是新片场。- allowed_domains中不存在的网站是不允许爬取的,若要爬取其他的网站,如XpcSpider若要爬取百度,那么就需要将百度的URL写入到allowed_domains中。- 此时allowed_domains的值为:`allowed_domains = ['www.xinpianchang.com', 'www.baidu.com']`- start_urls:爬虫程序开始的起始地址。- 这个地址后期通常都是需要更改的。- 因为start_urls的初始值与allowed_domains相同,一般都是目标网站的主页。- 但是爬虫程序想要的目标数据一般都不在主页中,以之前的例子为例,想要爬取新片场广告页面的数据,那么allowed_domains和start_urls的值分别为:```pythonallowed_domains = ['www.xinpianchang.com']start_urls = ['https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator']
此外,这个类中还存在一个parse回调函数。Scrapy Engine会将start_urls中的地址依次加入到Schedule的队列中,然后Downloader会依次请求start_urls中的地址,生成的response将由parse函数的response所接收。
2.4.3 items程序结构分析
items.py文件中其实没有太多的内容,它只是生成了一个类似于模板的文件。 ```python
Define here the models for your scraped items
#
See documentation in:
https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class HelloscrapyItem(scrapy.Item):
# define the fields for your item here like:# name = scrapy.Field()pass
- 首先,它还是一个OOP的Class,并且继承自scrapy.Item类。- 接着,这个类中存在着一句话“define the fields for your item here like: name = scrapy.Field()”。- 它的意思就是爬取的数据在Item中需要封装成`数据标签 = 值`这样的KeyValue结构。<a name="UtUU5"></a>#### 2.4.4 middlewares程序结构分析- middlewares.py这个文件中存在着两个类,分别对应着SpiderMiddleware和DownloaderMiddleware。- 在1.3.2中的图中可看出,DownloaderMiddleware是介于请求和响应之间的一个中间件,因此这个类的函数也是针对于请求和响应的。- DownloaderMiddleware中的六个函数:构建`from_crawler()`、处理请求`process_request()`、处理响应`process_response()`、处理请求响应中出现的异常`process_exception()`、启动爬虫`spider_opened()`- SpiderMiddleware爬虫中间件与DownloaderMiddleware类似,它的七个函数为:构建`from_crawler()`、处理爬虫输入`process_spider_input()`、处理爬虫输出`process_spider_output()`、处理爬虫中出现的异常`process_spider_exception()`、处理启动请求`process_start_requests()`、启动爬虫`spider_opened()`<a name="hP5Nx"></a>#### 2.4.5 pipeline程序结构分析- pipeline.py文件中编写的是处理Item的逻辑,默认情况下是直接将Item返回了。```pythonfrom itemadapter import ItemAdapterclass HelloscrapyPipeline:def process_item(self, item, spider):return item
一般情况下,这里写的内容是Item的数据清洗、验证、存储逻辑。
2.4.5 settings程序结构分析
settings.py实际上是一个配置文件,这个文件中编写这大量的配置信息。
- 详细配置信息可以参考手册:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html#topics-settings-ref
以下是一些常用的配置字段:(根据settings.py默认模板从上到下排序)
- BOT_NAME:Scrapy把自己看成一个机器,这个字段直译是机器人名字,说白了就是爬虫的名字。
- SPIDER_MODULES:爬虫模块的位置,一般是
ProjectName.spiders,指定了爬虫程序所处的包。 - NEWSPIDER_MODULE:在执行
scrapy genspider命令时,在哪个包下创建新的爬虫程序。 - USER_AGENT:就是在
requests.get()的headers中配置的UA,只不过Scrapy可以写在settings.py中。 - ROBOTSTXT_OBEY:是否遵行robots.txt君子协议。
- ROBOTSTXT_OBEY一般默认值为True,改成False即可。
- 因为一个网站要么没有robots.txt协议,有的话若ROBOTSTXT_OBEY的值为True,那基本上这个网站没有什么可以爬的数据了。
- CONCURRENT_REQUESTS:请求的并发数。
- 之前所编写的所有爬虫都是单线程爬虫,而Scrapy支持高并发爬虫。
- 但是不建议将这个参数的值改的特别大,否则容易对服务器造成过大的负载。
- CONCURRENT_REQUESTS的默认值为16,一般保持默认即可,不要修改。
- DOWNLOAD_DELAY:下载延迟,单位秒。
- 在之前的爬虫中,为了把爬虫程序模拟的更像人,一般会写
time.sleep(num)这样的代码。 - 在Scrapy中只需要将DOWNLOAD_DELAY配置为需要的数值即可。
- 在之前的爬虫中,为了把爬虫程序模拟的更像人,一般会写
- CONCURRENT_REQUESTS_PER_DOMAIN:对每个网站请求的并发数。思想上与CONCURRENT_REQUESTS一致,一般保持默认即可。
- CONCURRENT_REQUESTS_PER_IP:对每个IP请求的并发数。思想上与CONCURRENT_REQUESTS一致,一般保持默认即可。
- COOKIES_ENABLED:是否启用cookie,默认是启动的,可以手动改为False。
- TELNETCONSOLE_ENABLED:是否启动Telnet远程链接。默认是启动的,但是基本用不到,因此保持默认即可。
- DEFAULT_REQUEST_HEADERS:默认的HTTP请求头。
- 之前的爬虫中需要手动将请求头添加到请求中。
- Scrapy支持配置默认请求头,所有的请求都会遵循DEFAULT_REQUEST_HEADERS值的请求头信息。
- Scrapy中一般不会让开发者手动构建请求,因此这个请求头一般都用于请求start_urls中的地址。
- SPIDER_MIDDLEWARES:爬虫中间件的配置数据。
- DOWNLOADER_MIDDLEWARES:下载器中间件的配置数据。
- EXTENSIONS:配置扩展库。
- ITEM_PIPELINES:项目管道配置。
- AUTOTHROTTLE_ENABLED、AUTOTHROTTLE_START_DELAY、AUTOTHROTTLE_MAX_DELAY:用于配置随机休眠。
- DOWNLOAD_DELAY配置是定时长休眠,而当AUTOTHROTTLE_ENABLED为True时,会开启不定时长休眠,即随机休眠。
- 其中休眠随机时长的选择区间为
 ,即最少休眠AUTOTHROTTLE_START_DELAY秒,最多休眠AUTOTHROTTLE_MAX_DELAY秒。
,即最少休眠AUTOTHROTTLE_START_DELAY秒,最多休眠AUTOTHROTTLE_MAX_DELAY秒。
- HTTPCACHE_ENABLED、HTTPCACHE_EXPIRATION_SECS、HTTPCACHE_DIR、HTTPCACHE_IGNORE_HTTP_CODES、HTTPCACHE_STORAGE:用于配置网络缓存。
- HTTPCACHE_ENABLED为True时会启动网络缓存。
- HTTPCACHE_EXPIRATION_SECS用于设置缓存的过期时间(单位:秒)。
- HTTPCACHE_DIR用于设置缓存的路径。
- HTTPCACHE_IGNORE_HTTP_CODES:缓存忽略哪些HTTP状态码。
- HTTPCACHE_STORAGE:缓存的存储形式。
- 扩展知识点:网络缓存。
- 假设没有缓存,客户端要请求100次百度,那么客户端会真真实实的向百度的服务器发送100次HTTP请求。
- 若网络中都采取这样的方式,那这无疑会给服务器造成过大的负载。
- 而存在缓存时,并且假设缓存的过期时间为10秒(真实情况不会有那么短),客户端发送请求的频率为1秒/次。
- 那么当客户端在第一秒时发送了请求并且成功接收到响应后,那么之后的10秒(10次请求)客户端会先查看本地缓存,然后将本地缓存的数据直接返回给相关端口,也就是说之后的9秒中客户端根本不会向服务器发送网络请求。
- 当时间到达10后,也就是缓存到期了,那么客户端会再次向服务器发送一次请求,以此往复循环。
- 由此可见,网络请求的存在可以大大减少访问服务器的频率,降低服务器负载。并且数据直接从本地缓存中拿了,提高了网络的效率。
- 有些网站的数据更新周期时间是很长的,比如有些视频网站,一般都是好几天更新一次。而像腾讯视频、爱奇艺等视频巨头的更新频率一般也在一天一更。
- 因此在爬取这些网站时,实际上可以把HTTPCACHE_EXPIRATION_SECS的值设置为86400(60 60 24,即一天)。
- 而电影的影评是在实时更新的,但是一下子也不可能更新很多数据,因此在爬电影影评数据时,HTTPCACHE_EXPIRATION_SECS设置为10800(60 60 3,即三个小时)也差不多了,没有必要将爬虫频率设置的太高。
2.5 编写回调函数并执行Scrapy
2.5.1 settings配置文件初始化
在settings.py文件的默认信息中,为了方便后续的开发,需要简单调整一些配置信息。
关闭robots.txt君子协议。
ROBOTSTXT_OBEY = False
设置下载延迟为1秒。
DOWNLOAD_DELAY = 1
启动默认的HTTP请求头。
DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',}
2.5.2 编写最简单的回调函数
一个最简单的requests爬虫为:发送请求、接受请求。 ```python import requests
resp = requests.get(‘https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator‘) print(resp.text)
- Spider类中的`parse()`回调函数会接收response将由parse函数的response所接收,那么对应的爬虫在回调函数中可以写:```pythonimport scrapyclass XpcSpider(scrapy.Spider):name = 'xpc'allowed_domains = ['www.xinpianchang.com']start_urls = ['https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator']def parse(self, response):print(response.text)
2.5.3 启动并运行Scrapy程序
- 回调函数编写完成后,那么其实一个最简单的Scrapy爬虫已经完成了,下一步就是让爬虫运行起来获取数据。
- Scrapy是个框架,框架的运行方式有区别于单个Python Script右键RUN的运行方式。
- 要运行Scrapy程序,可以在Terminal中进入Scrapy工程的根目录,然后执行命令:
scrapy crawl SipderName(base) D:\Project\Python\HelloScrapy>scrapy crawl xpc

若有收获,就点个赞吧
0 人点赞
