01. Pandas介绍
1.1 Pandas的基本认识
- Pandas以NumPy为基础,为数据分析、数据挖掘、数据清洗提供了业务逻辑操作的支持。
Pandas中有两种常见的数据结构:
Anaconda中默认带有Pandas库,因此Anaconda环境无需再次手动下载Pandas,直接导入即可。
普通Python环境中可以通过pip命令来安装Pandas。
pip install pandas
Pandas导入:
import numpy as npimport pandas as pdfrom pandas import Series, DataFrame
02. Series
2.1 Series的基本介绍
Series是一个类似于一维数组的一维数据对象,有显式索引和隐式索引两种访问值的方式。
- Series除了可以用下标索引标记元素外,每个元素还有自己独特的标记,这个标记类似于字典的键。
- 对于列表而言,它可以存储值,也可以通过索引访问值,但却无法表示每个值的含义。如一个成绩列表
[77, 67, 89, 65, 49],可以通过索引快速定位元素,但无法直观的表达每个成绩是谁的成绩。
- 对于列表而言,它可以存储值,也可以通过索引访问值,但却无法表示每个值的含义。如一个成绩列表
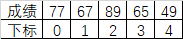
- Series就很好的解决了这个问题,根据上述例子,可以将姓名作为键,将实际的成绩作为值,存储到Series中后,不仅可以通过姓名(键)访问成绩(值),还可以通过下标访问成绩。
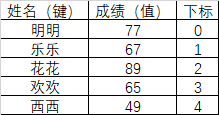
- 创建结构:
s = Series(data=一维数组, index=显式索引[, name=series的名称])- 注意:显式索引的个数要与一维数组中数据的个数一致。
示例:根据2.1中的数据创建Series对象。
>>> data = np.array([77, 67, 89, 65, 49])>>> index = np.array(["明明", "乐乐", "花花", "欢欢", "西西"])>>> s = Series(data=data, index=index, name="Student Score")>>> s明明 77乐乐 67花花 89欢欢 65西西 49Name: Student Score, dtype: int32
若没有手动指定显式索引,则默认使用隐式索引(下标)的数据作为显式索引。
>>> data = np.array([77, 67, 89, 65, 49])>>> s = Series(data=data, name="Student Score")>>> s0 771 672 893 654 49Name: Student Score, dtype: int32
2.2.2 通过字典的方式创建
创建结构:
s = Series(data=字典对象[, index=显式索引][, name=series的名称])- 字典的键会作为显式索引,字典的值会作为一维数组的数据。
示例:根据2.1中的数据,使用字典的形式创建Series对象。
>>> score_data = {... "明明": 77,... "乐乐": 67,... "花花": 89,... "欢欢": 65,... "西西": 49... }>>> s = Series(data=score_data)>>> s明明 77乐乐 67花花 89欢欢 65西西 49dtype: int64
通过字典的方式构建Series不推荐自行定义显式索引,但也可以自行定义显式索引。
但若自定定义显式索引,则会和字典中的键进行匹配。
- 若字典中有这个键,则用字典中键对应的值,否则就为空值。
- 若字典中有的键值对,但显式索引中没有,则该键值对也不会被添加到Series中。
>>> s = Series(data=score_data, index=["凯凯", "乐乐", "西西", "冬冬"])>>> s凯凯 NaN乐乐 67.0西西 49.0冬冬 NaNdtype: float64
2.3 Series常用属性
2.3.1 实验数据构建
>>> data = np.array([77, 67, 77, 65, 77])>>> index = np.array(["明明", "乐乐", "花花", "欢欢", "西西"])>>> s = Series(data=data, index=index, name="Student Score")
2.3.2 name获取Series的名称
Series对象.name属性可以获取Series对象的名称,若Series对象没有设置名称,则为None。>>> s.name'Student Score'
2.3.3 index获取显式索引
Series对象.index属性可以获取Series对象的显示索引的数据。>>> s.indexIndex(['明明', '乐乐', '花花', '欢欢', '西西'], dtype='object')
2.3.4 values获取所有数据值
Series对象.values属性可以获取Series对象的所有数据值。>>> s.valuesarray([77, 67, 77, 65, 77])
2.4 Series常用函数
2.4.1 value_counts()值频统计
Series对象.value_counts()函数可以统计Series对象中每个值出现的次数。>>> s.value_counts()77 367 165 1Name: Student Score, dtype: int64
2.4.2 head()获取前几条数据
Series对象.head()函数可以获取前几条数据,当head()函数空参数时,默认获取前5条数据。>>> s.head()明明 77乐乐 67花花 77欢欢 65西西 77Name: Student Score, dtype: int32
采用
Series对象.head(n)的形式可以获取前n条数据。 ```python获取前1条数据。
s.head(1) 明明 77 Name: Student Score, dtype: int32
获取前3条数据。
s.head(3) 明明 77 乐乐 67 花花 77 Name: Student Score, dtype: int32 ```
2.4.3 tail()获取后几条数据
Series对象.tail()函数可以获取后几条数据,使用方式与head()函数基本一致。 ```python默认获取后五条数据。
s.tail() 明明 77 乐乐 67 花花 77 欢欢 65 西西 77 Name: Student Score, dtype: int32
获取后两条数据。
s.tail(2) 欢欢 65 西西 77 Name: Student Score, dtype: int32 ```
2.4.4 sort_values()根据值排序
Series对象.sort_values([ascending=排序方式])函数根据数组的值进行排序。
根据成绩进行降序排序。
s.sort_values(ascending=False) 明明 77 花花 77 西西 77 乐乐 67 欢欢 65 Name: Student Score, dtype: int32 ```
2.4.5 sort_index根据显式索引排序
Series对象.sort_index([ascending=排序方式])函数根据数组的显式索引进行排序,用法与sort_values()函数基本一致。
按照显式索引降序排序。
s.sort_index(ascending=False) 西西 77 花花 77 欢欢 65 明明 77 乐乐 67 Name: Student Score, dtype: int32 ```
2.5 Series的索引与切片
2.3.1 实验数据构建
显式索引为26个英文字母,值在50到70之间随机生成。
>>> data = np.random.randint(50, 70, size=26)>>> index = list("ABCDEFGHIJKLMNOPQRSTUVWXYZ")>>> s = Series(data=data, index=index, name="随机数据")>>> sA 66B 57C 54D 60E 61F 67G 59H 59I 61J 51K 61L 69M 68N 59O 58P 61Q 60R 59S 57T 58U 60V 52W 65X 65Y 66Z 51Name: 随机数据, dtype: int32
2.5.2 索引
Series有显式索引和隐式索引两种索引。
显示索引:
方式三:
s.loc[[“D”, “G”, “J”]] D 60 G 59 J 51 Name: 随机数据, dtype: int32 ```
索引多个元素。
s.iloc[[0, 2, 3]] A 66 C 54 D 60 Name: 随机数据, dtype: int32 ```
- 布尔索引:
Series对象.loc[布尔序列]- 布尔序列中元素的个数要与Series对象中元素的个数相同。
- True对应的元素会被保留,False对应的元素会被移除。
```python
随机选择26个布尔类型的值组成数组
bool_flag = np.random.choice([True, False], size=26) bool_flag array([False, False, True, True, True, False, True, True, False, True, True, False, False, True, True, False, False, True, False, False, False, True, True, False, False, True])
根据布尔数组索引值。
s.loc[bool_flag] C 54 D 60 E 61 G 59 H 59 J 51 K 61 N 59 O 58 R 59 V 52 W 65 Z 51 Name: 随机数据, dtype: int32 ```
2.5.2 切片
- 由于索引有显式索引和隐式索引两种,因此切片也可以通过显式索引和隐式索引两种方式实现。
显式索引切片:(显式索引包含结束元素)
方法一:
Series对象.loc[显式索引1:显示索引2:步长]>>> s.loc['A':'Z':3]A 66D 60G 59J 51M 68P 61S 57V 52Y 66Name: 随机数据, dtype: int32
方法二:
Series对象[显式索引1:显示索引2:步长]>>> s["J":"P":2]J 51L 69N 59P 61Name: 随机数据, dtype: int32# ["J":"P":2]的结果包含P是因为显式索引切片结果中会包含结束元素
隐式索引切片:
Series对象.iloc[下标1:下标2:步长](隐式索引不包含结束位置元素)>>> s.iloc[3:10]D 60E 61F 67G 59H 59I 61J 51Name: 随机数据, dtype: int32
2.6 Series的相关运算与判断
2.6.1 运算概述与数据准备
Pandas中的数据运算是基于NumPy的,因此NumPy中有的运算Pandas中也是有的。
- Series中的运算实际上就是矢量化运算。
数据准备:
>>> score_data = {... "明明": 77,... "乐乐": 67,... "花花": 89,... "西西": 49... }>>> s = Series(data=score_data, index=["凯凯", "乐乐", "西西", "冬冬"])>>> s凯凯 NaN乐乐 67.0西西 49.0冬冬 NaNdtype: float64
2.6.2 Series的矢量化运算
给所有值进行加一操作。(与NumPy中一样,NaN为缺失值,缺失值运算后还是缺失值)
>>> s + 1凯凯 NaN乐乐 68.0西西 50.0冬冬 NaNdtype: float64
但是NaN可以参与逻辑运算。 ```python
判断成绩是否大于60分,NaN > 60 is False
s > 60 凯凯 False 乐乐 True 西西 False 冬冬 False dtype: bool
筛选出成绩大于60的数据。
s[s > 60] 乐乐 67.0 dtype: float64 ```
2.6.3 Series的集合函数
求最大值
2.6.4 isnull()判断数据是否为空值
Series对象.isnull()函数可以判断Series对象中的每个数据是否是空值,若为空值则True,否则为False。>>> s.isnull()凯凯 True乐乐 False西西 False冬冬 Truedtype: bool
2.6.5 any()判断是否有空值数据
Series对象.isnull().any()函数会根据isnull()函数的结果进行判断,结果中只要有一个True就为True,表示Series对象中存在空值。>>> s.isnull().any()True
03. DataFrame
3.1 DataFrame介绍
DataFrame是一个二维数据结构,类似于Excel表格。
- DataFrame可以看做是一个由多个Series数据构成的集合。
DataFrame的数据可以分为三部分:数据区、行索引、列索引。
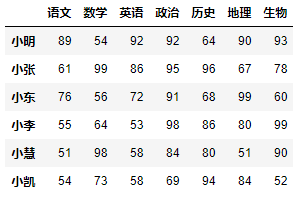
3.2 DataFrame的创建
构建语法:
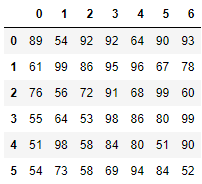
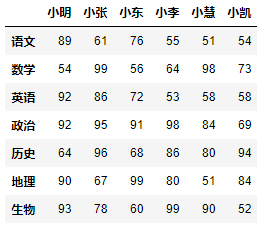
df = DataFrame(data=数据, index=行索引序列, columns=列索引序列)- 示例:生成以下表格。
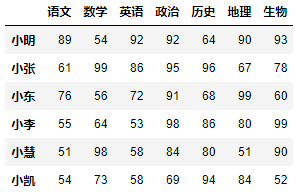
代码实现:
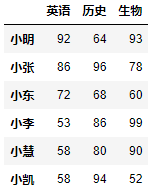
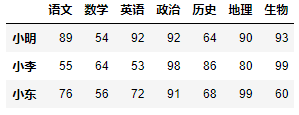
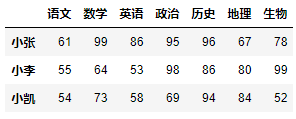
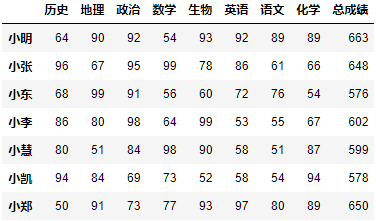
row_index = ["小明", "小张", "小东", "小李", "小慧", "小凯"]column_index = ["语文", "数学", "英语", "政治", "历史", "地理", "生物"]datas = [[89, 54, 92, 92, 64, 90, 93],[61, 99, 86, 95, 96, 67, 78],[76, 56, 72, 91, 68, 99, 60],[55, 64, 53, 98, 86, 80, 99],[51, 98, 58, 84, 80, 51, 90],[54, 73, 58, 69, 94, 84, 52]]df = DataFrame(data=datas, index=row_index, columns=column_index)df
若没有声明显式索引,则会使用隐式索引所谓索引。
df = DataFrame(data=datas)df
3.3 DataFrame的相关属性
3.3.1 数据准备
使用中第一个df作为实验数据。
row_index = ["小明", "小张", "小东", "小李", "小慧", "小凯"]column_index = ["语文", "数学", "英语", "政治", "历史", "地理", "生物"]datas = [[89, 54, 92, 92, 64, 90, 93],[61, 99, 86, 95, 96, 67, 78],[76, 56, 72, 91, 68, 99, 60],[55, 64, 53, 98, 86, 80, 99],[51, 98, 58, 84, 80, 51, 90],[54, 73, 58, 69, 94, 84, 52]]df = DataFrame(data=datas, index=row_index, columns=column_index)
3.3.2 index获取行索引
DataFrame对象.index属性可以获取DataFrame对象的行索引。>>> df.indexIndex(['小明', '小张', '小东', '小李', '小慧', '小凯'], dtype='object')
3.3.3 columns获取列索引
DataFrame对象.columns属性可以获取DataFrame对象的列索引。>>> df.columnsIndex(['语文', '数学', '英语', '政治', '历史', '地理', '生物'], dtype='object')
3.3.3 values获取数据
DataFrame对象.values属性可以获取DataFrame对象的数据值。>>> df.valuesarray([[89, 54, 92, 92, 64, 90, 93],[61, 99, 86, 95, 96, 67, 78],[76, 56, 72, 91, 68, 99, 60],[55, 64, 53, 98, 86, 80, 99],[51, 98, 58, 84, 80, 51, 90],[54, 73, 58, 69, 94, 84, 52]], dtype=int64)
3.4 DataFrame索引
DataFrame是一个二维的表结构,有行索引和列索引两种。对于这两种索引也分为显示索引和隐式索引两类。
3.4.1 列索引
DataFrame对象.列名可以索引单列数据,其结果是一个Series结构的数据。>>> df.语文小明 89小张 61小东 76小李 55小慧 51小凯 54Name: 语文, dtype: int64
DataFrame对象[列名]是索引单列数据的另一种方式。>>> df['数学']小明 54小张 99小东 56小李 64小慧 98小凯 73Name: 数学, dtype: int64
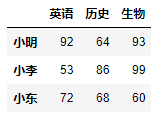
DataFrame对象[[列名1, 列名2, 列名3, …]]可以获取多列数据。其结果是一个DataFrame结构的数据。df[['英语', '历史', '生物']]
3.4.2 行索引
DataFrame对象.loc[行标题]可以索引单行数据,其结果是一个Series结构的数据。>>> df.loc['小明']语文 89数学 54英语 92政治 92历史 64地理 90生物 93Name: 小明, dtype: int64
DataFrame对象.loc[[行标题1, 行标题2, 行标题3, …]]可以获取多行数据。其结果是一个DataFrame结构的数据。df.loc[['小明', '小李', '小东']]
3.4.3 行列复合索引
行列复合索引的格式为:
DataFrame对象.loc[行索引, 列索引]一个单元格由确定的行与确定的列组成,比如要查询小明的语文成绩,代码为:
>>> df.loc['小明', '语文']89
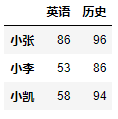
行列复合索引还可以从指定多行中获取指定多列的数据,如要查询小明、小李、小东这三个人的英语、历史、生物这三门课的成绩。
df.loc[['小明', '小李', '小东'], ['英语', '历史', '生物']]
3.4.4 DataFrame隐式索引
DataFrame中隐式索引使用的依旧是下标,语法格式为:
DataFrame对象.iloc[行索引, 列索引]示例:返回第0、2、4行的第1、3、6列数据。
df.iloc[[0, 2, 4], [1, 3, 6]]
3.5 DataFrame切片
DataFrame的切片也分为显示索引切片(包含结束位置)以及隐式索引切片(不包含结束位置)。
3.5.1 行切片
使用显示索引来实现行切片的语法格式为:
DataFrame对象.loc[起始行索引:结束行索引:步长]df.loc["小张":"小慧"]
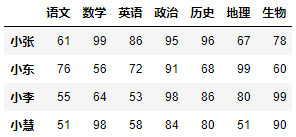
df.loc["小张":"小慧":2]
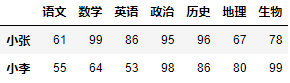
df.loc[::2]
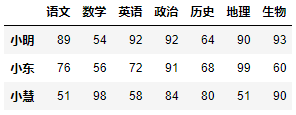
使用隐式索引来实现行切片的语法格式为:
DataFrame对象.iloc[起始下标:结束下标:步长]df.iloc[1::2]
3.5.2 列切片
显示索引列切片:
DataFrame对象.loc[行切片, 起始列索引:结束列索引:步长]>>> df.loc['小明', '数学':'地理':2]数学 54政治 92地理 90Name: 小明, dtype: int64
df.loc[:, '数学'::2] # 行切片为“:”,则表示在所有行中切列。
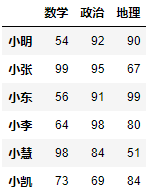
隐式索引列切片:
DataFrame对象.iloc[行下标切片, 起始下标:结束下标:步长]df.iloc[1::2, 2:6:2]
3.6 DF描述性操作
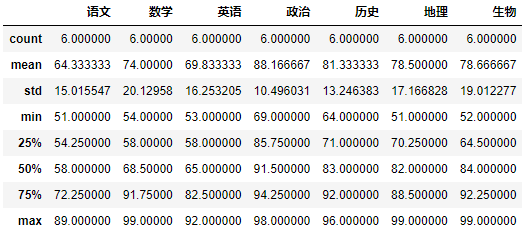
3.6.1 describe()获取数据描述
DataFrame对象.describe()可实现对数据对象进行简单的数学描述,描述指标包括:DataFrame对象.describe()是对表的总体数据进行数学指标层面的描述。DataFrame对象.info()可实现在表规格上对数据表进行描述。
 即可得到该列中有几个空值。
即可得到该列中有几个空值。0 语文 6 non-null int64 1 数学 6 non-null int64 2 英语 6 non-null int64 3 政治 6 non-null int64 4 历史 6 non-null int64 5 地理 6 non-null int64 6 生物 6 non-null int64 dtypes: int64(7) memory usage: 556.0+ bytes
<a name="ikxz8"></a>#### 3.6.3 count()获取个数- `DataFrame对象.count()`可以获取每个字段的数据个数。```python>>> df.count()语文 6数学 6英语 6政治 6历史 6地理 6生物 6dtype: int64
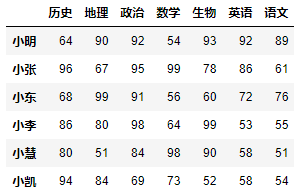
3.6.4 T转置
DataFrame对象.T可实现数据对象的行列互换。DataFrame对象.sort_index()可以将数据表根据行索引或列索引进行排序。- axis:0根据行索引排序(缺省值),1根据列索引排序。
- ascending:True升序排序(缺省值),False降序排序。
- inplace:是否修改原数据。
- 默认为False,即不会修改原数据,而是把排序后的结果直接返回。
- True:会修改原数据,且不会返回任何内容。
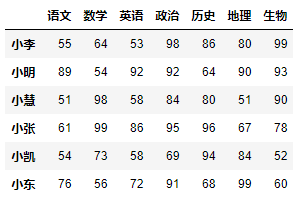
示例1:根据行索引降序排序,不修改原数据。
df.sort_index(ascending=False)# 结果会直接返回
示例2:再根据列索引升序排序,并修改原数据。
df.sort_index(axis=1, inplace=True)df # 修改原数据后不会有返回,因此需要手动调用df查看内容。
3.7.2 sort_values()根据数据值排序
DataFrame对象.sort_values()可以将数据表根据行索引或列索引进行排序。- by:指定数据基于哪个字段进行排序,可以是一个字符串;当涉及到多字段排序时,by的值是由多个字段名构成的一个列表。
- 当by的值为一个列表时,会先按照列表中第0个字段排序。
- 若第0个字段值相同,则按照第1个字段排序,以此类推,直到排序完成。
- axis:0根据行索引排序(缺省值),1根据列索引排序。
- ascending:True升序排序(缺省值),False降序排序。
- inplace:是否修改原数据。
- 默认为False,即不会修改原数据,而是把排序后的结果直接返回。
- True:会修改原数据,且不会返回任何内容。
- by:指定数据基于哪个字段进行排序,可以是一个字符串;当涉及到多字段排序时,by的值是由多个字段名构成的一个列表。
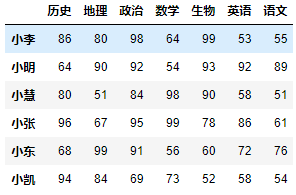
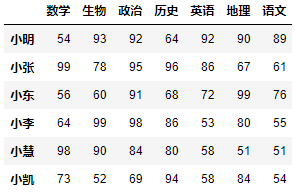
示例1:根据生物成绩,对学生进行降序排序。
df.sort_values(by='生物', ascending=False)
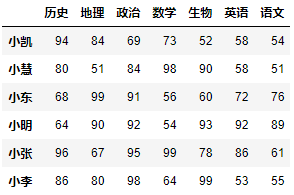
示例2:根据政治成绩以及数学成绩,对学生进行升序排序。
df.sort_values(by=['政治', '数学'])
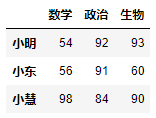
示例3:将小慧的考试科目按照从大到小的顺序排序。
DataFrame对象.loc[新行索引] = 数据值可以在DF对象中添加一行数据。- 数据值中数据的个数需要与DF的列数相同。
- 空值可以使用np.nan填充。
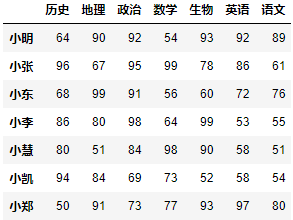
示例:在数据表中添加小郑的成绩。
data = np.array([50, 91, 73, 77, 93, 97, 80])df.loc['小郑'] = datadf
3.8.2 添加一列数据
DataFrame对象.loc[:, 新列索引] = 数据值可以在DF对象中添加一列数据。- 数据值中数据的个数需要与DF的行数相同。
- 空值可以使用np.nan填充。
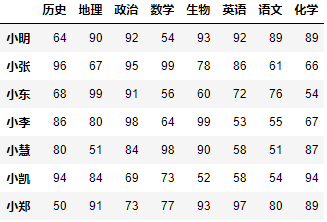
示例1:增加一列化学成绩。
df.loc[:, '化学'] = np.array([89, 66, 54, 67, 87, 94, 89])df
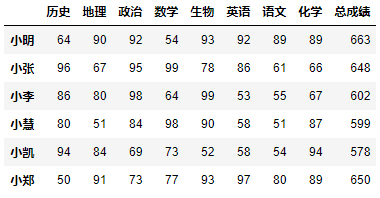
示例2:增加一列总成绩。(总成绩可以通过
df.sum(axis=1)计算得到)df.loc[:, '总成绩'] = df.sum(axis=1)df
3.8.3 drop()删除数据
DataFrame对象.drop()可以在DF对象中删除指定的数据。- labels:要删除的标题(可以是行标题也可以是列标题),要删除多行或多列时可以封装成列表。
- axis:0删除行(默认值),1删除列。
示例1:删除小东的数据。
df.drop(labels='小东')
示例2:删除政治、历史的数据。
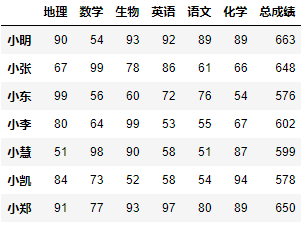
df.drop(labels=['政治', '历史'], axis=1)
3.9 DF运算操作
示例1:查找出语文成绩大于70分的学生信息。
首先:索引出语文的所有数据。
>>> df['语文']小明 89小张 61小东 76小李 55小慧 51小凯 54小郑 80Name: 语文, dtype: int64
然后判断语文成绩是否大于70分。
>>> df['语文'] > 70小明 True小张 False小东 True小李 False小慧 False小凯 False小郑 TrueName: 语文, dtype: bool
最后,用第二步中得到的布尔值过滤出语文大于70的学生数据。
df[df['语文'] > 70]
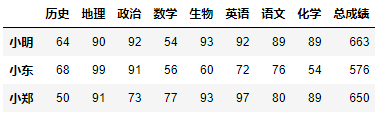
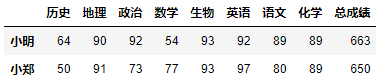
示例2:过滤出语文在70分以上,化学在80分以上的学生信息。
df[(df['语文'] > 70) & (df['化学'] > 80)]
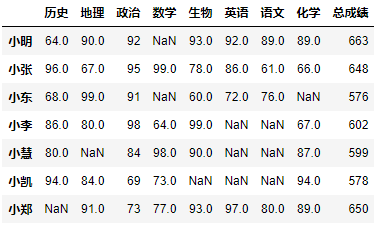
示例3:判断数据表中哪些成绩是合格的。
首先,判断整张表中所有的数据是否大于等于60。
df >= 60

接着,用布尔索引过滤数据,此时False对应的数据会变成np.nan。
df[df >= 60]

若有收获,就点个赞吧
0 人点赞
