01. XPath
参考W3School XPath语法手册:https://www.w3school.com.cn/xpath/index.asp
1.1 文本提取技术
1.1.1 文本提取技术概述
文本提取技术即从一段文本中提取出想要内容的技术。
- 在爬虫中使用文本技术,必须要保证需要的数据存在于文本中。
- 一般来说Re正则和XPath都用来在HTML源码中提取数据。
- 所以前提就要保证你提取的数据在HTML中存在。
- 如何判断数据在网页源代码中:在网页中右键 >> 查看网页源代码,若在这里找得到需要的数据,就可以用文本提取技术爬取。
若所需要的信息在网页源代码中不存在,则可以直接放弃文本提取技术,使用网络接口或者Selenium程序的方式进行爬虫。
1.1.2 正则表达式
正则表达式是一种特殊的字符串,是一款常用于校验、筛选、检索、替换字符串内容的工具。
- 正则表达式有其自己独特的语法,以及处理引擎,在所有编码语言中几乎都存在。(具体的语法在01. Python与SQL — 01. Python语法 — 06. Python高级 — 03. 正则表达式中有详细讲解)
正则表达式可以用在爬虫的文本匹配与提取中,但是不推荐,主要是因为正则表达式存在以下一些缺点:
- 缺点1:写起来麻烦
缺点2:由于浏览器功能强大,当HTML非正常编写时,浏览器也能正常解析,如下面的代码明显缺少了四个
</li>。<ul><li>AAAA<li>BBBB<li>CCCC<li>DDDD</ul>
- 但是浏览器照样可以正常显示无序列表的效果。

- 缺点3:HTML中有一些特殊字符,比如HTML中需要用
来表示空格,因此<p>aa aa</p>在浏览器中显示的结果是aa aa,但是源码中的内容依旧是aa aa。这种情况也会为正则的匹配制造很多麻烦。1.1.3 HTML、XML、XPath介绍
- ML:Markup Language,标记性语言。
- HTML:Hyper Text Markup Language,超文本标记语言。
- HTML主要用于网页骨架设计上。
- 其标签都是内置的,如
<p>、<img>、<a>等。 - HTML的标签有单标签,也有双标签。
- XML:Extensible Markup Language,可扩展标记语言。
- XML主要用于标记数据、定义数据类型等场景。
- 其标签都是自定义的,如
<hehe>、<haha>等都可以。 - XML比较严格,其标签必须是双标签。
XPath(XML Path Language,XML路径语言),是一种专门用于从XML和HTML中提取内容的语言。
1.2 XPath结构
1.2.1 元素树
在01. 爬虫前置基础知识 — 02. 爬虫前端知识基础 — 3.9.2 Document对象中提到,DOM模型会将一个HTML文档转换成一个有树形层级关系的对象进行管理。
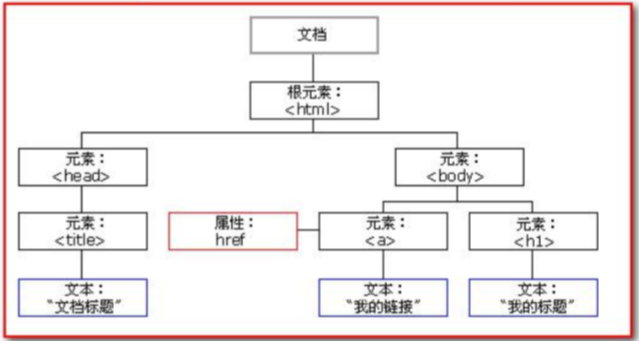
在XPath中也采用这样的思想将一个完整的HTML/XML文件转换成一颗元素树(也可称文档树、标签树)。
1.2.2 节点(Node)
在XPath中有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
- XML文档是被作为节点树来对待的,树的根被称为文档节点或者根节点。
- 以下面这个XML文档为例: ```xml <?xml version=”1.0” encoding=”ISO-8859-1”?>
- 上面的XML文档中的节点例子:- `<bookstore>`:文档节点。- `<author>J K. Rowling</author>`:元素节点。- `lang="en"`:属性节点。<a name="v5Zzw"></a>#### 1.2.3 基本值(亦称原子值,Atomic Value)- 基本值指的是无父或无子的节点。- 如1.2.2中的`J K. Rowling`和`en`都没有子节点,属于基本值。<a name="FH3cN"></a>#### 1.2.4 项目(Item)- 项目指的是基本值或者节点。<a name="CzgPq"></a>### 1.3 节点关系<a name="bl8vw"></a>#### 1.3.1 父(Parent)- 每个元素节点(非文档节点的元素标签)以及属性节点都有一个父节点。- 如下XML中,title、author、year、price的父是book。```xml<book><title>Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book>
1.3.2 子(Children)
- 父与子是相对的关系,如3.3.1中的title、author、year、price都是book的子。
-
1.3.3 同胞(Sibling)
同胞节点也可称为兄弟节点,指的是具有相同父的节点。
如3.3.1中title、author、year、price的父都是book,因此认为title、author、year、price四个是同胞节点。
1.3.4 先辈(Ancestor)
一个节点的父节点、父节点的父节点、父节点的父节点的父节点、……,都称为是这个节点的先辈节点。
如title的先辈节点是book元素节点和bookstore元素节点
<bookstore><book><title>Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book></bookstore>
1.3.5 后代(Descendant)
一个节点的子节点、子节点的子节点、子节点的子节点的子节点、……,都称为是这个节点的后代节点。
- 可以说后代与先辈是一个相对的概念。
如1.3.4中的book元素节点、title元素节点、author元素节点、year元素节点、price元素节点都是bookstore元素节点的后代。
1.4 XPath语法
1.4.1 XPath提取内容的方式
XPath使用路径表达式来选取HTML/XML文档中的节点或者节点集。
节点是通过沿着路径(Path)或者步(Steps)来选取的。
1.4.2 实验数据
本小节的所有示例将使用以下这个XML文档进行。 ```xml <?xml version=”1.0” encoding=”ISO-8859-1”?>
<a name="b31wY"></a>#### 1.4.3 选取节点- `nodename`:采用节点名称的方式可以选取此节点中的所有子节点。- 示例:选取bookstore的所有子节点,即两个book节点。```xmlbookstore
/:从根节点选取。(假如路径以斜杠/开头,则代表到某元素的绝对路径)示例1:选取根元素bookstore。
/bookstore
示例2:选取属于bookstore的子元素中的book元素。
bookstore/book
//:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。(简单来说就是全局搜索指定的节点)示例1:搜索文档中所有的book子元素,而不考虑它们在文档中的位置。(即全局搜索book)
//book
示例2:选择bookstore元素的后代的所有book元素,不管它们位于bookstore之下的什么位置。
bookstore//book
@:选取属性。示例:选取名为lang的所有属性。
//@lang
.:选取当前节点。-
1.4.4 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,谓语被嵌在方括号中。
- 选择属于bookstore子元素的第一个book元素:
/bookstore/book[1] - 选择属于bookstore子元素的最后一个book元素:
/bookstore/book[last()] - 选择属于bookstore子元素的倒数第二个book元素:
/bookstore/book[last()-1] - 选择属于bookstore子元素的最前面的两个book元素:
/bookstore/book[position()<3] - 选择拥有lang属性的title元素:
//title[@lang] - 选择拥有lang属性,并且值为eng的title元素:
//title[@lang='eng'] - 选择属于bookstore子元素的所有book元素,但要求price元素的值必须大于35.00:
/bookstore/book[price>35.00] 选择属于bookstore子元素的所有book元素中的所有title元素,但要求price元素的值必须大于35.00:
/bookstore/book[price>35.00]/title1.4.5 选取未知节点
XPath通配符可用来选取未知的XML元素。
*:匹配任何元素节点。示例1:选取bookstore元素的所有子元素。
/bookstore/*
示例2:选取文档中的所有元素。
//*
@*:匹配任何属性节点。示例:选取所有带有属性的title元素。
//title[@*]
-
1.4.6 选取若干路径
通过在路径表达式中使用或运算符
|,来实现若干路径的选择。- 选取book子元素中的所有title元素和price元素:
//book/title | //book/price。 - 选取文档中所有的title元素和所有的price元素:
//title | //price。 选取属于bookstore子元素的book元素中的所有title元素,以及文档中的price元素:
/bookstore/book/title | //price。1.4.7 函数
XPath的函数其实很少会被使用,但是
text()和contains()使用的还是比较多的。text()函数:- 在XPath表达式的末尾写上
/text()即可从节点中提取出值。 - 选取出book子元素中的所有price元素的值:
//book/price/text()。 - 注意:一个XPath可能取回来的是一类数据,因此lxml模块获取到的可能是一个列表,因此处理值需要处理列表中的内容。
- 在XPath表达式的末尾写上
contains()函数:在Python中使用XPath需要结合
lxml这个XPath格式解析模块完成。lxml模块可以通过pip命令安装。pip install lxml
1.5.2 构建元素树
首先,要导入
lxml模块中的etree,然后通过etree.HTML(HTML文本)构建一个元素树。- 代码实现:用requests获取懂车帝(https://www.dongchedi.com/)页面的源码,然后构建成一颗文档树。 ```python import requests from lxml import etree
resp = requests.get(“https://www.dongchedi.com/“) page_source = resp.text
tree = etree.HTML(page_source)
print(tree) #
<a name="cVZT9"></a>#### 1.5.3 xpath()规则匹配- `元素树对象.xpath('XPath表达式')`可以根据XPath表达式从HTML/XML文档中匹配提取需要的内容。- `xpath()`中的XPath表达式字符串建议使用单引号`'`。- 因为在XPath表达式中可能出现双引号`"`。- 示例:编写XPath,从阿凡达:水之道的短评页面(https://movie.douban.com/subject/4811774/comments)中爬取数据。- 首先打开阿凡达:水之道的短评页面,然后右键 >> 查看网页源代码,检查一下评论数据是否存在网页源代码中。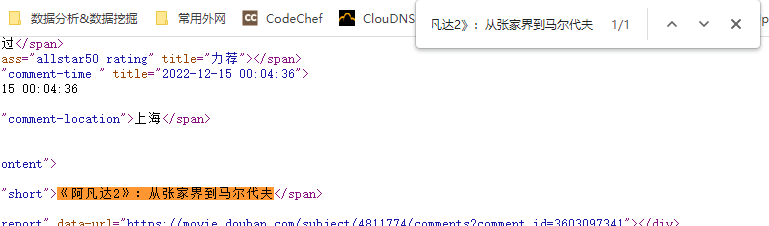- 从搜索结果中可以看出,评论存在与网页HTML的源代码中,因此可以使用XPath提取。- 接着为了方便获取,可以将网页源代码放到IDE中格式化一下,方便查看网页结构以编写XPath。- 分析得出,评论数据的XPath为:`//span[@class="short"]/text()`,即从文档中查到带有short类的span节点。- 最后,编码获取数据。```python# 导入模块import requestsfrom lxml import etree# 构建请求url = "https://movie.douban.com/subject/4811774/comments"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}resp = requests.get(url=url, headers=headers)# 获取网页源代码,构建元素树page_source = resp.texttree = etree.HTML(page_source)# 用XPath提取评论数据comments = tree.xpath('//span[@class="short"]/text()')for comment in comments:print(comment)
1.6 XPath辅助工具
1.6.1 Copy XPath
- 以新片场的广告页面为例:https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator。
- 要用XPath获取第一个视频的标题,当然可以自己手动写XPath,但是浏览器提供了一种更方便的方法。
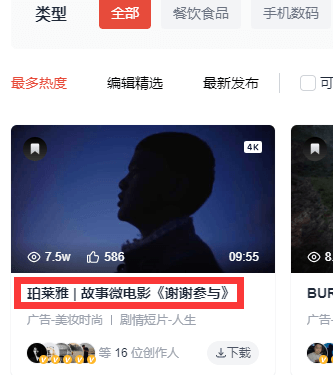
- 在需要的元素的位置上右键 >> 检查,即可在Element中定位到代码块。
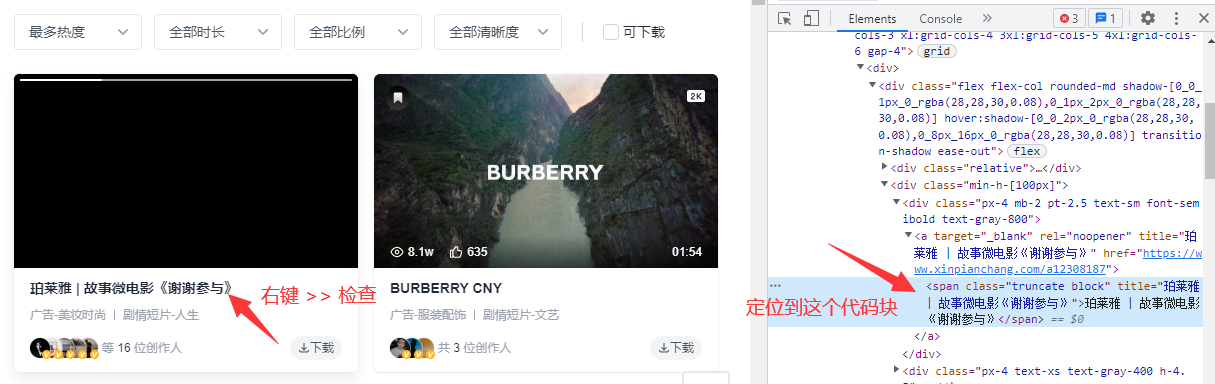
然后右键代码块 >> Copy >> Copy XPath即可得到目标元素对应的XPath,如这里是:
//*[@id="__next"]/section/main/div/div[3]/div[1]/div/div[2]/div[1]/a/span。1.6.2 XPath Helper
XPath Helper是个浏览器扩展程序,Google Chrome地址为:https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl?hl=zh-CN。
- XPath Helper主要用来验证XPath的正确性,还是以新片场广告页面为例。
- 点击浏览器右上角的扩展程序列表,点击其中的中的XPath Helper。
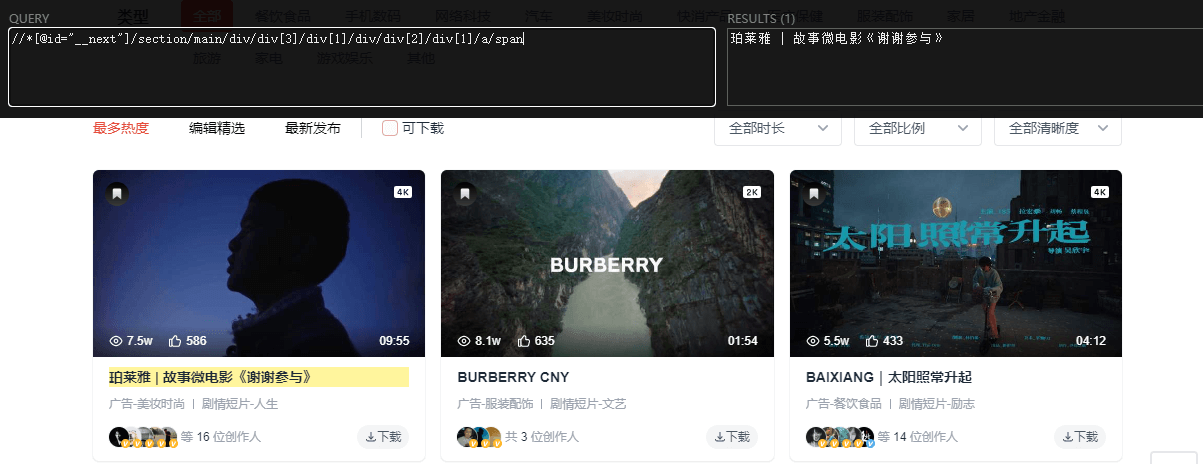
- 此时在页面顶部就会出现QUERY和RESULTS两个窗口。

- 在QUERY中输入XPath表达式(这里就以3.6.1中Copy XPath得到的为例),此时在RESULT中即可得到匹配的结果,并且匹配的元素会在页面中高亮显示。
02. 新片场爬虫
2.1 项目描述
- 项目根页面:新片场广告页面(https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator)
需求:
该项目需要爬取的信息大多都是在广告的详情页中,因此需要先获取所有广告的详情页链接。
- 从UI的角度上看,点击广告页面每个广告的标题,就可以进入详情页。这就意味着这个标题中存在一个
<a>标签,它的href中存储着详情页的地址。
- 因此获取详情页链接的程序实现思路为:
- 请求新片场广告页面地址,根据相应的内容构建XPath元素树。
- 编写相应的XPath规则获取详情页地址。
- 代码实现: ```python import requests from lxml import etree
发送GET请求,构建元素树。
resp = requests.get(“https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator“) tree = etree.HTML(resp.text)
编写XPath规则,获取详情页地址。
movies_element = tree.xpath(‘//div[@id=”__next”]//main/div[1]/div[3]/div’) # 所有广告的集合。 for movie_element in movies_element:
# 遍历每个广告,获取详情页链接。detail_url = movie_element.xpath('.//div[@class="relative"]/a/@href')[0]print(detail_url)
<a name="SgtZN"></a>#### 2.2.2 爬取基本信息(单个)- 广告的广告标题、点赞量、收藏量、分享量、播放量实际上都在广告的详情页中。- 以中国山河,很有橙意!([https://www.xinpianchang.com/a12316708](https://www.xinpianchang.com/a12316708))这则广告为例: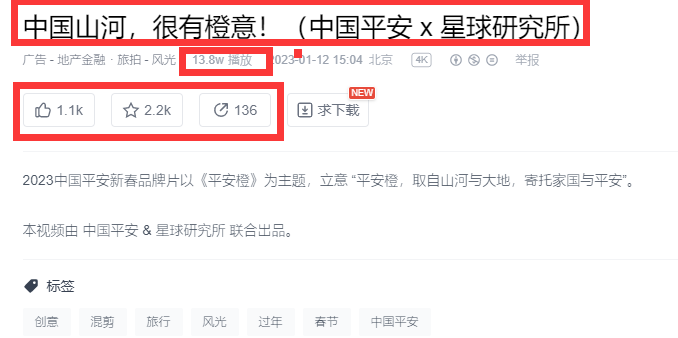- 这些数据经过分析,发现在网页源代码中都可以找到,因此都可以使用XPath提取。- 故爬取这部分数据的思路即为:- 请求详情页链接,通过响应构建元素树。- 编写XPath规则提取数据。- 代码实现:```pythonimport requestsfrom lxml import etree# 请求《中国山河,很有橙意!》的详情页链接,构建元素树。sub_page_resp = requests.get("https://www.xinpianchang.com/a12316708")sub_page_tree = etree.HTML(sub_page_resp.text)# 通过XPath获取目标数据。title = sub_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[1]/h2/text()')[0] # 广告标题likes = sub_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[1]/span/text()')[0] # 点赞量collection = sub_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[2]/span/text()')[0] # 收藏量share = sub_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[3]/span/text()')[0] # 分享量playback = sub_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[2]/div[1]/span[2]/text()')[0] # 播放量# 输出结果。print([title, likes, collection, share, playback]) # ['中国山河,很有橙意!(中国平安 x 星球研究所)', '1.1k', '2.2k', '136', '13.8w']
2.2.3 爬取基本信息(所有)
- 2.2.2中爬取的是单个详情页的数据,要爬取所有详情页的数据实际上只需要请求所有详情页,然后构建元素树,编写XPath即可。
- 实际上就是2.2.1和2.2.2两部分代码的整合。 ```python import requests from lxml import etree
对广告页面发送GET请求,构建元素树。
resp = requests.get(“https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator“) tree = etree.HTML(resp.text)
获取详情页链接,请求详情页构建元素树并通过XPath爬取数据。
movies_element = tree.xpath(‘//*[@id=”__next”]//main/div[1]/div[3]/div’) for movie_element in movies_element: detail_url = movie_element.xpath(‘.//div[@class=”relative”]/a/@href’)[0]
# 防止数据爬取过程中出现异常。# 通过try-except结构增加程序的健壮性。try:# 构建详情页元素树。detail_page_resp = requests.get(detail_url)detail_page_tree = etree.HTML(detail_page_resp.text)# 爬取基本信息。title = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[1]/h2/text()')[0] # 广告标题likes = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[1]/span/text()')[0] # 点赞量collection = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[2]/span/text()')[0] # 收藏量share = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[3]/span/text()')[0] # 分享量playback = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[2]/div[1]/span[2]/text()')[0] # 播放量print([title, likes, collection, share, playback])except Exception as e:pass
<a name="QuKS6"></a>#### 2.2.4 基本信息存储- 当前项目的数据是标准的二维数据,可以考虑使用Excel、CSV、数据库等方式存储。- 但最方便的存储方式就是使用CSV存储。```pythonimport requestsimport csvfrom lxml import etree# 对广告页面发送GET请求,构建元素树。resp = requests.get("https://www.xinpianchang.com/discover/article-1-0-all-all-0-0-hot?from=navigator")tree = etree.HTML(resp.text)# 获取详情页链接,请求详情页构建元素树并通过XPath爬取数据。datas = [] # 用于存储所有数据。movies_element = tree.xpath('//*[@id="__next"]//main/div[1]/div[3]/div')for movie_element in movies_element:detail_url = movie_element.xpath('.//div[@class="relative"]/a/@href')[0]# 防止数据爬取过程中出现异常。# 通过try-except结构增加程序的健壮性。try:# 构建详情页元素树。detail_page_resp = requests.get(detail_url)detail_page_tree = etree.HTML(detail_page_resp.text)# 爬取基本信息。title = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[1]/h2/text()')[0] # 广告标题likes = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[1]/span/text()')[0] # 点赞量collection = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[2]/span/text()')[0] # 收藏量share = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[3]/div/button[3]/span/text()')[0] # 分享量playback = detail_page_tree.xpath('//*[@id="__next"]/section/main/section[2]/section/main/section/header/div[2]/div[1]/span[2]/text()')[0] # 播放量# 将数据封装成一个列表,然后添加到datas中。data = [title, likes, collection, share, playback]datas.append(data)print(data)except Exception as e:pass# 数据持久化with open('./movies_base_info.csv', 'w', encoding='utf-8', newline='') as file:handle = csv.writer(file)handle.writerow(['广告标题', '点赞量', '收藏量', '分享量', '播放量'])handle.writerows(datas)
2.3 爬取播放链接
2.3.1 爬取播放地址(单个)
- 以中国山河,很有橙意!(https://www.xinpianchang.com/a12316708)这则广告为例(不一定要是这个,在新片场广告页面中随机选取一个即可),审查它的Elements可以发现视频的播放链接存在于
<video>标签中,但是在网页源代码中却找不到<video>标签,这就表明视频是一个动态加载的数据。


- 因此需要分析Fetch/XHR中的内容,最后在Fetch/XHR中的名为
POpZQXYnP517Er5a?appKey=61a2f329348b3bf77&extend=userInfo%2CuserStatus的资源中发现了相关数据。
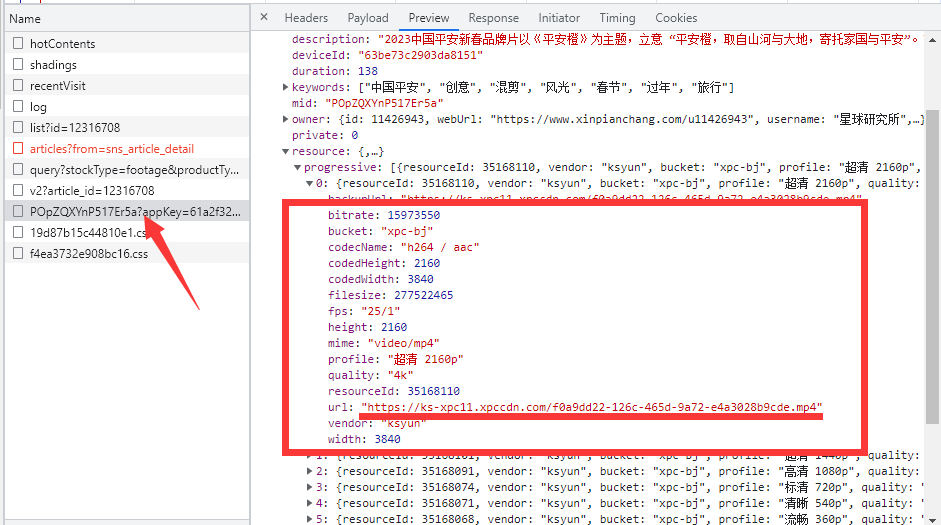
- 这个资源对应的Request URL为:https://mod-api.xinpianchang.com/mod/api/v2/media/POpZQXYnP517Er5a?appKey=61a2f329348b3bf77&extend=userInfo%2CuserStatus
- 从这个URL中可以提取出的内容有:
https://mod-api.xinpianchang.com/mod/api/v2/media/:地址。POpZQXYnP517Er5a:可能是视频的标识什么的,大概率有价值。61a2f329348b3bf77:appKey,应用标识,可能有价值。extend=userInfo%2CuserStatus:没什么用,因为删掉之后https://mod-api.xinpianchang.com/mod/api/v2/media/POpZQXYnP517Er5a?appKey=61a2f329348b3bf77一样可以获取到数据。
- 因此需要想办法获取到的数据只有
POpZQXYnP517Er5a和61a2f329348b3bf77两部分,然后再拼到https://mod-api.xinpianchang.com/mod/api/v2/media/{视频的标识}?appKey={应用标识}地址上,就可以获取到含有播放地址的API地址。 - 而这两个数据恰巧在详情页(https://www.xinpianchang.com/a12316708)的网页源代码的
<script id="__NEXT_DATA__" type="application/json"></script>标签对中可以找到。<script id="__NEXT_DATA__" type="application/json">中的是JSON数据。- 因此可以借助Python的
json标准库来解析JSON,从而提取数据。


- 因此,这个程序可以分两步实现:
- 首先,获取
POpZQXYnP517Er5a?appKey=61a2f329348b3bf77&extend=userInfo%2CuserStatus这个资源的Request URL地址。 - 然后请求Request URL,得到的响应是个JSON。解析这个JSON,即可得到广告视频的播放地址。 ```python import json import requests from lxml import etree
- 首先,获取
请求详情页,构建元素树。
detail_resp = requests.get(‘https://www.xinpianchang.com/a12316708‘) detail_tree = etree.HTML(detail_resp.text)
从

若有收获,就点个赞吧
0 人点赞
