01. 动态数据的获取
1.1 动态数据与静态数据
- 静态数据与动态数据的概念:
- 静态数据:HTML中写死的数据,不管什么时候打开都是这样的,不会发生变化。
- 动态数据:前端没有的数据,即需要向后端服务器请求的数据。
- 动态数据产生的原因:客户端HTML文件中无法存储体量较大的数据,因此很多数据都是存储在服务器上的,只有当客户端需要的时候,才会进行请求并由服务器完全响应,以此减轻了服务器向客户端响应的IO压力以及客户端的存储压力。
- requests模拟浏览器发送请求的方式只能获取静态数据。
- 若想要获取动态数据,则需要自己监测浏览器的Network。捕捉发出去的请求,获取请求地址,然后通过这个地址就可以获取动态的数据。
- 动态请求响应的数据一般是JSON格式的数据,JSON类似于Python中的列表嵌套字典或者字典嵌套列表。
动态数据选用JSON作为数据格式的原因:
现有王者荣耀英雄介绍的网站:https://pvp.qq.com/web201605/herolist.shtml
- 用request获取这些英雄的名字,会发现总是少一些英雄。这是因为排在前面的英雄相较于后面而言,是最近才出的一些新英雄,王者荣耀官方还没有将这部分内容固定写到其HTML页面中,因此需要向服务器动态请求。
- 通过F12 >> Network >> Fetch/XHR即可监控到所有动态数据,若没有监控到则打开Fetch/XHR后刷新一下页面即可。
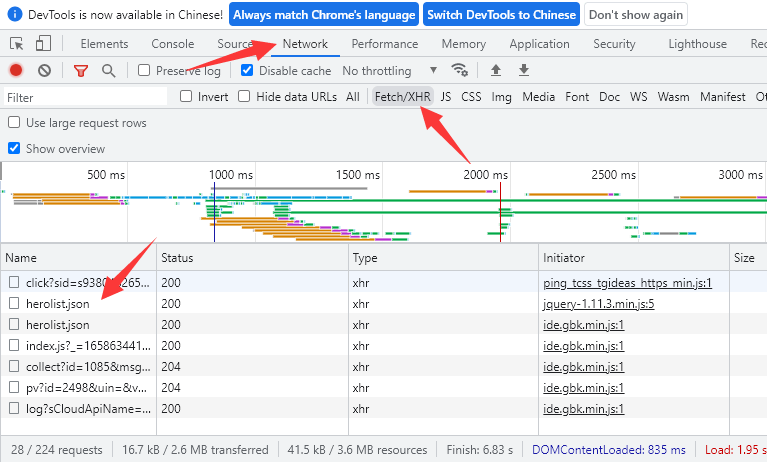
- 在Fetch/XHR中,我们可以双击下载与英雄信息相关的herolist.json文件,打开可以发现其中存储的是所有英雄的数据,包括新英雄在内。
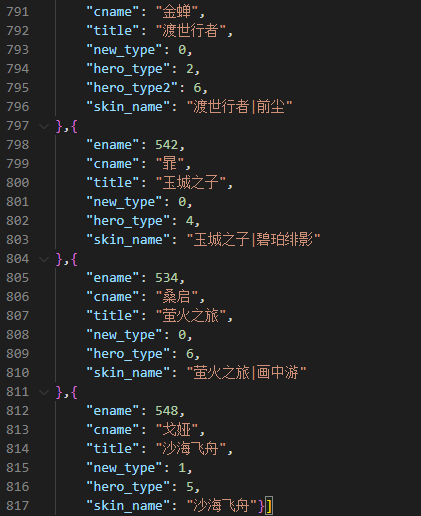
1.2.2 Python捕捉动态数据。
- Python捕捉动态数据常用的有两种方式,第一种方式较为愚钝,就是手动打开Fetch/XHR,然后单击需要的动态数据文件,在Headers中的General中即可获取该动态数据文件的URL。
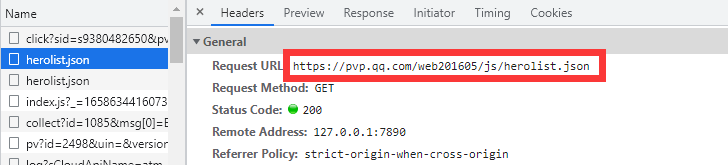
- 然后用requests模块请求该地址即可。 ```python import requests
resp = requests.get(url=”https://pvp.qq.com/web201605/js/herolist.json“) if resp.status_code == 200: print(resp.json()) # json()函数可以获取JSON格式的数据。 else: print(f”数据请求失败,状态码为:{resp.status_code}”)
- 第二种方式,就是使用selenium自动化测试工具捕捉动态数据。- 示例:从[https://101.qq.com/#/hero](https://101.qq.com/#/hero)中获取英雄名称、英雄职业、技能名称。- 注:英雄数据列表和英雄详情页链接都是动态数据。```pythonimport requests# 这个地址也是个动态数据,即Fetch/XHR中的hero_list.js?ts=2764419地址。resp = requests.get(url="https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2764419")if resp.status_code == 200:hero_list = resp.json()heroes = hero_list.get("hero") # 所有的英雄信息被封装成一个列表,是字典hero_list中键hero的值。for hero in heroes:hero_id = hero.get("heroId")hero_name = hero.get("name")hero_roles = "、".join(hero.get("roles"))# 动态地址,在英雄列表页面点击进入英雄的详情页,然后在Fetch/XHR中找到{hero_id}.js?ts=2764423文件的地址。hero_detail_url = f"https://game.gtimg.cn/images/lol/act/img/js/hero/{hero_id}.js?ts=2764423"resp_hero_detail = requests.get(url=hero_detail_url)if resp_hero_detail.status_code == 200:detail_data = resp_hero_detail.json()skills = detail_data.get("spells") # 英雄技能是一个列表,是字典detail_data中键spells的值。hero_skills = "、".join([skill.get("name") for skill in skills]) # 将所有技能名称提取出来,然后用“、”连接成字符串。print(hero_name, hero_roles, hero_skills)else:print(f"英雄详情页数据请求失败,状态码为:{resp.status_code}")else:print(f"数据请求失败,状态码为:{resp.status_code}")
02. selenium自动化测试
2.1 selenium概述与安装
2.1.1 selenium介绍
- selenium是一款自动化测试工具,被称为爬虫的万金油。
- selenium会自动调动浏览器,并展示页面信息。只要是浏览器上出现的数据,selenium都可以请求到。
- 缺点:网页上隐藏的数据无法用selenium获取。
- 所谓隐藏的数据,以英雄联盟狂战士的英雄详情页:https://101.qq.com/#/hero-detail?heroid=2&datatype=5v5为例,其技能描述只有当鼠标悬停在其技能图标上时才会显示,其他时候是不显示的。对于这种只有在特定场景下才显示的数据就称之为隐藏的数据。
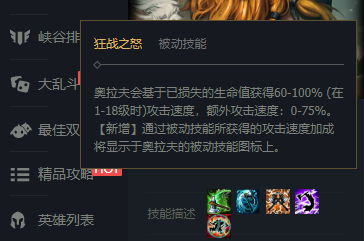
总结:
selenium也是一款第三方工具库,也需要用pip工具进行安装。
pip install selenium
2.1.3 ChromeDriver驱动安装
安装完第三方工具库selenium直接使用会报错:
Message: 'chromedriver' executable needs to be in PATH.,报错原因是谷歌浏览器驱动没有被正常安装。- 第一步:查看Chrome谷歌浏览器版本。
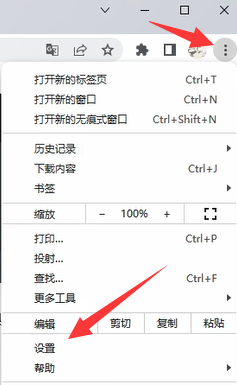
- 点击浏览器右上角的菜单按钮,再点击设置。
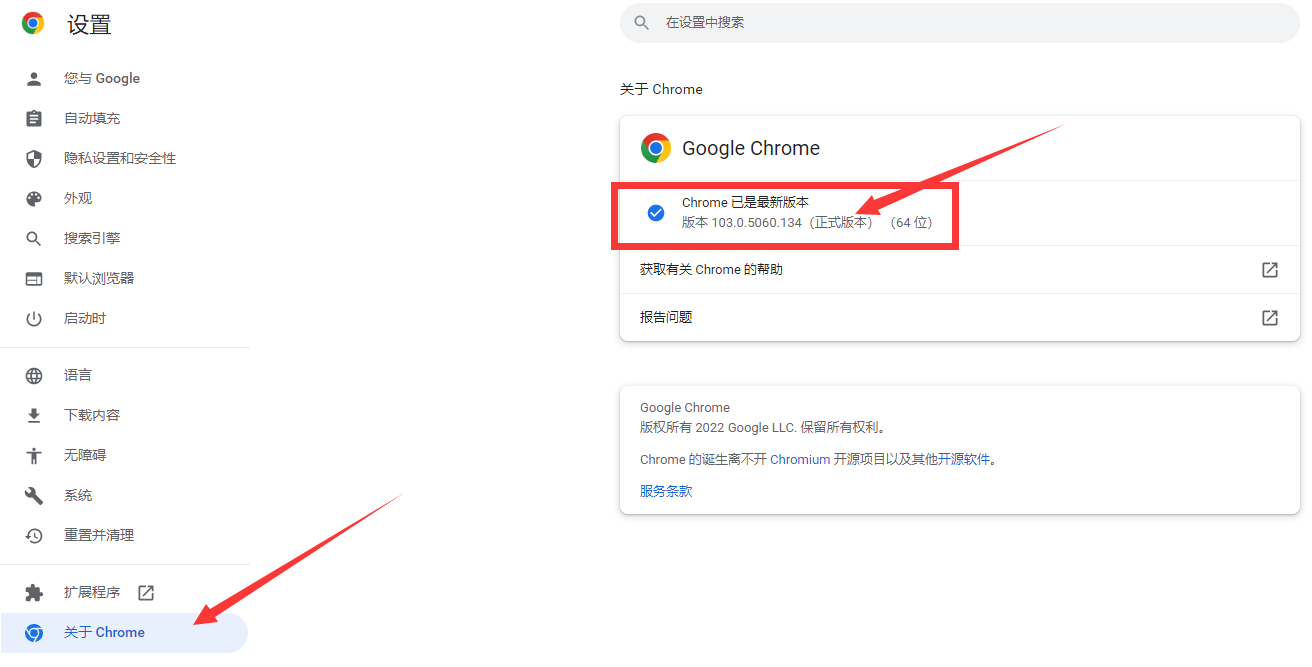
- 接着点击左侧导航栏中的“关于 Chrome”,在右侧即可看到当前谷歌浏览器的版本。
- 第二步:访问版本连接https://chromedriver.storage.googleapis.com/LATEST_RELEASE_103.0.5060,地址的组成如下:
- 以上图中的版本“103.0.5060.134”为例,取其前3个数字,即“103.0.5060”。
- 将取到的3位版本拼接在“https://chromedriver.storage.googleapis.com/LATEST_RELEASE_”的最后即可得到当前驱动的下载连接。
- 第三步:访问下载地址https://chromedriver.storage.googleapis.com/index.html?path=103.0.5060.134/,地址的组成如下:
- 访问第二步的URL将得到一个小版本号:103.0.5060.134(具体根据实际情况而变)
- 对于版本103.0.5060.134,URL 将为“https://chromedriver.storage.googleapis.com/index.html?path=103.0.5060.134/”。
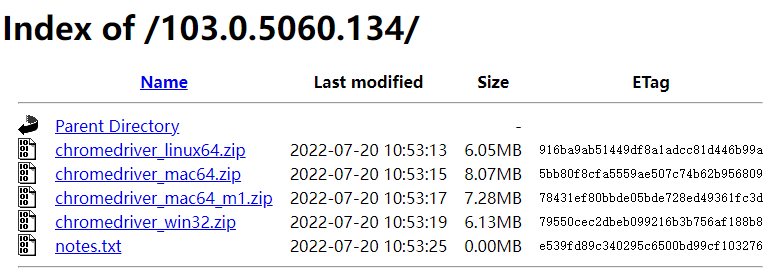
- 第四步:第三步会访问到一个FTP连接,选择当前操作系统对应的版本进行下载。
- 这里以Windows为例,故下载chromedriver_win32.zip文件。
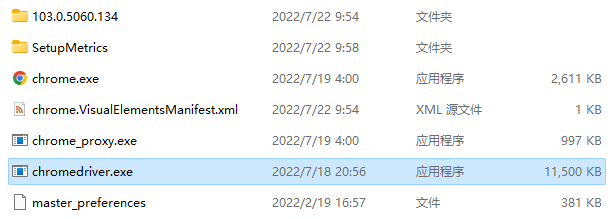
- 第五步:将下载好的压缩文件进行解压,得到chromedriver.exe驱动文件,然后右键谷歌浏览器图标 >> 打开文件所在的位置,将解压得到的chromedriver.exe驱动文件移动到打开的目录中。
- 第六步:将打开的谷歌浏览器目录地址添加到PATH中。
- 补充(第二、三步无法正常访问的解决方案):
- 上述下载方式是谷歌官方提供的下载方式,其中的连接可能因为一些网络问题无法正常访问。
- 替代方式:完成步骤一后,记录前三个数(即大版本号),然后去镜像地址:https://registry.npmmirror.com/binary.html?path=chromedriver/,根据大版本号寻找对应的资源。(即资源的最后第四位小版本号可以与浏览器实际的版本不同,但前三位要相同)
安装完成后,重启一下PyCharm,即可正常运行selenium程序了。
2.2 selenium的常用操作
2.2.1 Chrome()启动谷歌浏览器
第三方库selenium中有一个webdriver模块,这个模块下的Chrome()函数可以创建一个谷歌浏览器对象,并在当前操作系统中打开谷歌浏览器。 ```python from selenium import webdriver
browser = webdriver.Chrome()
<a name="pVjnp"></a>#### 2.2.2 get()访问指定网站- `浏览器对象.get(网址字符串)`可以让浏览器在当前窗口中访问指定的网址。```pythonfrom selenium import webdriverbrowser = webdriver.Chrome()browser.get("https://www.baidu.com/") # 访问百度
2.2.3 find_elements()查找浏览器上的标签元素
浏览器对象.find_elements(by=By.ID, value=值)函数可以查询符合条件的所有标签元素。- 参数by:用于指定查找的参数,常用的参数如下:
- ID:根据HTML标签的id属性来获取元素。
- CLASS_NAME:根据HTML标签的类名来获取元素。
- CSS_SELECTOR:根据CSS选择器来获取元素。
- XPATH:更具XPath来获取元素。
- 注意:上述所有的值都是selenium.webdriver.common.by.By中的对象。
- 参数value:参数by指定的查找参数对应的值。
- 参数by:用于指定查找的参数,常用的参数如下:
browser.find_element():browser.find_elements()函数查找的是符合条件的所有标签,是一个列表;browser.find_element()函数是查找符合条件的所有标签中的第一个,即browser.find_element()等价于browser.find_elements()[0]
-
2.2.4 click()鼠标点击
一般会先用
browser.find_element()函数选出标签对象,然后再用标签对象.click()函数执行鼠标点击事件。- 示例:访问英雄联盟官网:https://lol.qq.com/main.shtml,然后点击网站顶部导航栏中的游戏资料。 ```python from selenium import webdriver from selenium.webdriver.common.by import By import time
调用浏览器访问英雄联盟官网
browser = webdriver.Chrome() browser.get(“https://lol.qq.com/main.shtml“)
查找游戏资料的链接标签,并进行点击
time.sleep(3) # 点击前先短暂休眠,以防服务器误认为是攻击行为 game_info = browser.find_element( by=By.CSS_SELECTOR, value=”#J_headNav > li > a” ) game_info.click()
<a name="NaErp"></a>#### 2.2.5 ActionChains鼠标工具执行点击- 在selenium.webdriver中有一个ActionChains鼠标工具,封装了一系列的鼠标操作。```pythonfrom selenium.webdriver import ActionChains
- 实例化鼠标对象:
鼠标对象 = ActionChains(浏览器对象) - 让鼠标点击目标标签:
鼠标对象.click(标签对象).perform()- click(标签对象):鼠标点击事件,点击指定的标签。(事件不会立刻点击)
- perform():执行事件,调用perform()函数后事件会立刻执行。
- 示例:用ActionChains点击游戏资料。 ```python from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By import time
调用浏览器访问英雄联盟官网
browser = webdriver.Chrome() browser.get(“https://lol.qq.com/main.shtml“)
查找游戏资料的链接标签
time.sleep(3) game_info = browser.find_element(by=By.CSS_SELECTOR, value=”#J_headNav > li > a”)
点击链接标签
action = ActionChains(browser) action.click(game_info).perform()
- ActionChains使用说明:[https://www.cnblogs.com/lxbmaomao/p/10389786.html](https://www.cnblogs.com/lxbmaomao/p/10389786.html)<a name="Bl7xZ"></a>#### 2.2.6 window_handles获取所有窗口- `浏览器对象.window_handles`属性可以获取当前浏览器中所有的窗口对象。- 示例:先访问英雄联盟官网,然后打印窗口列表,接着点击游戏资料,再打印窗口列表。```pythonfrom selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome()action = ActionChains(browser)browser.get("https://lol.qq.com/main.shtml")print(browser.window_handles) # ['CDwindow-8BC3504BA976BA5FA5A14FFC9DBF696A']time.sleep(3)game_info = browser.find_element(by=By.CSS_SELECTOR, value="#J_headNav > li > a")action.click(game_info).perform()print(browser.window_handles) # ['CDwindow-8BC3504BA976BA5FA5A14FFC9DBF696A', 'CDwindow-8074DC80214DEE82C03D784D4AF39CC3']
2.2.7 switch_to.window()切换窗口
浏览器对象.switch_to.window(窗口字符串)函数可以切换selenium程序操作的窗口。switch_to:切换到指定的窗口对象中。window(窗口字符串):根据窗口字符串构造窗口对象。
- 最新打开的窗口:
window_handles中的元素顺序是按照窗口创建的先后顺序添加的,因此最新打开的创建一定是列表的最后一个元素,即window_handles[-1]。 - 示例1:先访问英雄联盟官网,接着点击游戏资料,然后在游戏资料窗口中访问百度。 ```python from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.common.by import By import time
browser = webdriver.Chrome() action = ActionChains(browser)
browser.get(“https://lol.qq.com/main.shtml“) game_info = browser.find_element(by=By.CSS_SELECTOR, value=”#J_headNav > li > a”) action.click(game_info).perform()
time.sleep(2) # 为了实验效果,点击后先等待两秒,再访问百度。
切换操作窗口,并在切换后的窗口中打开网址。
browser.switch_to.window(browser.window_handles[-1]) # 一定要切换过来,否则当前窗口就是英雄联盟官网的窗口。 browser.get(“https://www.baidu.com/“)
- 示例2:获取英雄联盟中所有英雄的个数。```pythonfrom selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.common.by import Byimport timebrowser = webdriver.Chrome()action = ActionChains(browser)browser.get("https://lol.qq.com/main.shtml")game_info = browser.find_element(by=By.CSS_SELECTOR, value="#J_headNav > li > a")action.click(game_info).perform()# 英雄数据在游戏资料页面中,因此要切换浏览器操作的页面browser.switch_to.window(browser.window_handles[-1])time.sleep(3) # 切换后,程序停一会,让浏览器完成页面的加载后再获取数据,否则可能为空hero_list = browser.find_elements(by=By.CSS_SELECTOR, value=".hero-list > li")print(f"英雄的个数为:{len(hero_list)}")
2.2.8 text获取标签文本
标签对象.text用于获取标签的文本,这个用法与beautifulsoup4中完全一致。-
2.2.9 back()返回上一个页面
browser.back()与element.click()是一对相反的函数,当element.click()进入到一个新页面后,可以用browser.back()函数返回。-
2.2.10 get_attribute()获取标签属性
标签对象.get_attribute(属性名)函数用于获取一个标签中指定属性名的属性值。- 示例:获取英雄联盟中所有英雄的名字、技能、职业、位置、胜率、BAN率、登场率、难度。 ```python import openpyxl import time from selenium import webdriver from selenium.webdriver.common.by import By
heroes_info = [ [“英雄名称”, “技能”, “职业”, “位置”, “胜率”, “BAN率”, “登场率”, “难度”] ] # 用于存储所有英雄数据
构建浏览器对象并访问英雄联盟首页。
browser = webdriver.Chrome() browser.get(“https://lol.qq.com/main.shtml“) time.sleep(2)
点击进入游戏资料页面,并切换窗口
game_info = browser.find_element(by=By.CSS_SELECTOR, value=”#J_headNav > li > a”) game_info.click() browser.switch_to.window(browser.window_handles[-1]) time.sleep(2)
获取英雄列表
hero_list = browser.find_elements(by=By.CSS_SELECTOR, value=”.hero-list > li”) for i in range(1, len(hero_list) + 1):
# 进入详情页hero_li = browser.find_element(by=By.CSS_SELECTOR, value=f".hero-list > li:nth-child({i})")hero_li.click()time.sleep(2)try:# 有些在重做的英雄详情页中没有没有数据,只有“继续浏览”和“返回列表”两个按钮。# 对于这样的英雄,我们不做处理。back_list = browser.find_element(by=By.CSS_SELECTOR, value=".solid-s")back_list.click()time.sleep(2)except Exception as e:# 若没有“继续浏览”和“返回列表”两个按钮的英雄,则被认为是正常英雄,需要获取数据。# 获取数据hero_name = browser.find_element(by=By.CSS_SELECTOR, value=".hero-name").textskills_element = browser.find_elements(by=By.CSS_SELECTOR, value=".spells-list > .spells > img")skills_name = "、".join([skill.get_attribute("alt") for skill in skills_element])occupation = browser.find_element(by=By.CSS_SELECTOR, value=".hero-type").text.strip()position_list = browser.find_elements(by=By.CSS_SELECTOR, value=".filter-box > div:nth-child(2) > a")position = "、".join([i.text for i in position_list])win_rate = browser.find_element(by=By.CSS_SELECTOR, value=".hero-intro .win-text").text.strip()ban_rate = browser.find_element(by=By.CSS_SELECTOR, value=".ban-text").text.strip()appear_rate = browser.find_element(by=By.CSS_SELECTOR, value=".show-text").text.strip()difficulty = f"{len(browser.find_elements(by=By.CSS_SELECTOR, value='.light'))}星"row_data = [hero_name, skills_name, occupation, position, win_rate, ban_rate, appear_rate, difficulty]heroes_info.append(row_data)print(row_data)# 退出当前英雄的详情页,并准备点击下一个英雄的详情页。browser.back()time.sleep(2)
将爬取的数据存储到Excel中
wb = openpyxl.Workbook() wb.worksheets[0].title = “英雄信息” hero_ws = wb[“英雄信息”]
for line, line_data in enumerate(heroes_info): for column, data in enumerate(line_data): hero_ws.cell(line + 1, column + 1, data)
wb.save(“./excel/英雄联盟.xlsx”)
<a name="xBeDD"></a>#### 2.2.11 move_to_element()移动鼠标到指定元素- 让鼠标移动到目标标签上方:`鼠标对象.move_to_element(标签对象).perform()`- 示例:进入[https://lol.qq.com/main.shtml](https://lol.qq.com/main.shtml)官网,点击游戏资料 >> 装备列表,当鼠标悬浮在每个装备上时,会出现关于装备的隐藏数据,获取这些数据。```pythonimport timefrom selenium import webdriverfrom selenium.webdriver import ActionChainsfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome()mouse = ActionChains(browser)browser.get("https://lol.qq.com/main.shtml")time.sleep(2)# 点击进入游戏资料页面,并切换窗口game_info = browser.find_element(by=By.CSS_SELECTOR, value="#J_headNav > li > a")mouse.click(game_info).perform()browser.switch_to.window(browser.window_handles[-1])time.sleep(2)# 进入装备页面equip_list_page = browser.find_element(by=By.CSS_SELECTOR, value=".left-menu-nav > li:nth-child(6)")mouse.click(equip_list_page).perform()time.sleep(2)equip_list = browser.find_elements(by=By.CSS_SELECTOR, value=".equipment-list > li")for equip in equip_list:mouse.move_to_element(equip).perform() # 移动鼠标到各个装备上悬浮,以此获得隐藏数据。time.sleep(1)# 鼠标移动后,隐藏数据会显示出来,因此可获取数据。equip_name = equip.find_element(by=By.CSS_SELECTOR, value=".prop-name").textequip_price = equip.find_element(by=By.CSS_SELECTOR, value=".price > span").textsynthesis_price = browser.find_element(by=By.CSS_SELECTOR, value=".component-dialog .price").textequip_desc = browser.find_element(by=By.CSS_SELECTOR, value=".component-dialog .desc").textprint(f"装备名称:{equip_name}")print(f"装备购买价格:{equip_price}")print(f"合成价格:{synthesis_price}")print(f"装备描述:{equip_desc}")print("=" * 20)
03. 项目

若有收获,就点个赞吧
0 人点赞
