01. 什么是Python
1.1 Python简介
- Python是一门完全开源的,通用的高级编程语言。
- Python由荷兰数学和计算机研究学会的吉多·范·罗苏姆(Guido Van Rossum)于1990年代初设计,有Python 2.x和Python 3.x两大版本,目前主流的是Python 3.x版本。
Python的哲学:
Python是一门高级的面向对象的编程语言。
- Python语言中包含了面向对象的特性,但是可以用面向过程或者函数式进行编码。
- Python是动态解释性语言。
- Python可以在代码运行过程中,为对象添加新的属性或方法。
- Python的程序脚本可以直接被Python解释器执行,不需要预先编译。
- Python拥有着优雅的结构和清晰的语法,简单易学。
- Python拥有丰富的第三方库。
Python可以调用其他语言所写的代码,因此又被称为胶水语言。
1.3 Python的应用领域
由于Python具有非常丰富的第三方库,加上Python语言本身的优点,所以Python可以在非常多的领域内应用。
Python常见的应用领域:
Python的运行环境主要分为Python 2和Python 3两大版本,这两大官方的版本安装步骤都是一样的。
- Anaconda:是一款集成了许多第三方库的Python解释器,在人工智能和科学计算等领域使用广泛。(也有2和3)
- Python的集成开发环境有非常之多,常用的有以下一些:
- Jupyter Notebook:基于Web页面的交互式计算环境。
- Anaconda:除了带有Python解释器和大量的第三方库外,还带有了许多集成开发环境。
- PyCharm:功能及其强大的开发环境,集成了许多便捷的功能。
- Eclipse:使用广泛的一个开发工具,多用于Java,也支持Python。
- ……
- Anaconda安装教程:https://blog.csdn.net/weixin_50888378/article/details/109022585
PyCharm编写程序教程:https://blog.csdn.net/hju22/article/details/85018116
02. Python基础知识
2.1 Python中的注释
Python中用#号表示单行注释,用三引号表示多行注释。 ```python
单行注释一
单行注释二
单行注释三
“”” 多行注释一 多行注释二 多行注释三 “””
<a name="fxRrz"></a>### 2.2 Python缩进- Python中的缩进是强制的,并且不能乱用,他用来划分代码块。- 如下列代码中,b前面的一个空格就会被识别成缩进。- 因为这里的缩进是不合理的,因此会报“IndentationError: unexpected indent”错误,即非法缩进。```pythona = 1b = 1
Python中缩进推荐使用四个空格或者一个Tab键。
result = 10if result == 0:print("等于0")elif result > 0:print("大于0")else:print("小于0")
2.3 Python中的输入输出
Python中使用input()函数进行数据输入,使用print()函数进行打印输出。
name = input("请输入你的姓名:")print("你好,", name, "!")
2.4 import导包
Python可以使用“import 包名”的方式导入一整个包。
- 还可以使用“from 包名 import 模块名”的方式导入一个包中指定的模块。
包或模块导入后,还可以使用as为导入的内容取别名。
import numpy as npfrom matplotlib import pyplot as pltx = np.arange(0, 3 * np.pi, 0.1)y = np.sin(x)plt.title("sine wave image")plt.plot(x, y)plt.show()
2.5 变量
在Python中定义变量时不需要声明类型(动态类型的弱类型语言),解释器会根据赋值的数据自动分配类型。 ```python a = 10 print(type(a), a) #
10
a = 21.455
print(type(a), a) #
a = “Food”
print(type(a), a) #
- 变量命名规则:- 由字母、数字、下划线组成,但不能用数字开头。- 不能用关键字作为变量名。- Python可以同时对多个变量赋值,也可以为多个对象指定多个变量。```pythona = b = c = 3a, b = 1, 2a, b = b, aprint(a, b, c) # 2 1 3
变量根据作用范围可以分为两种:
Python中有大量的关键字,具体可以查看keyword.kwlist。
import keywordprint(keyword.kwlist)
2.7 地址引用
Python中变量是对数据存储地址的应用,因此Python的变量才可以存储不同类型的数据。
- 数据在计算机上进行存储,会得到一个相应的存储地址。
给变量赋值,并不是将数据赋予变量,而是将数据所在的存储地址赋值给了变量。
03. Python中的数据类型
3.1 Python数据类型概述
Python中内置的数据结构有六种:
- Number:数值型。
- String:字符串。
- List:列表。
- Tuple:元组。
- Dictionary:字典。
- Set集合。
- 这些数据类型不仅可以提高Python的运行效率,还极大地提高了开发效率,让Python的操作变得简单便捷。
-
3.2 数值类型
Python 3支持int、float、bool、complex(复数)四种数值类型。
-
3.2.1 整数类型
int整数类型:在Python3里,只有一种整数类型int,表示长整型,因此int类型的长度没有限制。
int_num1 = 12345print(type(int_num1), int_num1) # <class 'int'> 12345int_num2 = 98754091327643297036847print(type(int_num2), int_num2) # <class 'int'> 98754091327643297036847
3.2.2 布尔类型
Python 3中bool布尔类型继承了int类型,因此也是数值类型的一部分。
- 0为False,其他都为True。 ```python if 0: print(True) else: print(False) # False
if 4: print(True) else: print(False) # True
- False可以当作0进行运算,True可以当作1运算。```pythonprint(False + True) # 1,即 0 + 1 = 1
3.2.3 浮点数类型
Python 3中只有一种浮点数即float,即对精度没有限制。
float_num = 324.1252345342632411print(type(float_num), float_num) # <class 'float'> 324.12523453426326
3.2.4 复数类型
Python 3中复数的表示方法为:r+ij,其中r为实数部分,i为虚数部分,j为虚数的标记。
用复数对象调用real属性可以获取该复数的实数部分,调用imag属性可以获取该复数的虚数部分。
complex_num = 123 - 12jprint("123-12j的实数部分:", complex_num.real) # 123-12j的实数部分: 123.0print("123-12j的虚数部分:", complex_num.imag) # 123-12j的虚数部分: -12.0
3.2.5 数值类型的基本计算
加(+)、减(-)、乘()、除(/)、整除(//)、取模(%)、次幂(*)
print(4 + 3) # 7print(4 - 3) # 1print(4 * 3) # 12print(56 / 12) # 4.666666666666667print(56 // 12) # 4,注意:整除不是四舍五入,而是将小数点后的数据直接截断print(56 % 12) # 8print(2 ** 4) # 16
如果不同类型的数字(如int和float)进行运算,则结果类型为精度较高的那个类型(即float)。
num1 = 213num2 = 324.1324result = num1 + num2print(type(num2), num2) # <class 'float'> 324.1324
3.2.6 数值的精度处理
int(float_num):将一个浮点数的小数部分截断,进行取整。
float_number1 = 3.745int_number1 = int(float_number1)print(int_number1) # 3
round(num, digits):将一个数字num四舍五入到小数点后digits位。(小数点后小于等于digits位的则不处理)
print(round(3.72, 2)) # 3.72print(round(3.7276, 2)) # 3.73
使用格式化输出。
number_str = '%.2f' % 3.1415926number_float = float(number_str)print(type(number_float), number_float) # <class 'float'> 3.14
3.2.7 高精度数据的处理
Python默认的是17位精度,也就是小数点后16位,当计算需要使用更高的精度(超过16位小数)时,可以使用以下两种方式:
继续使用格式化输出。(数据有较大的误差)
print(10 / 3) # 3.3333333333333335print('%.30f' % (10 / 3)) # 3.333333333333333481363069950021
使用decimal模块。 ```python from decimal import Decimal, getcontext
result1 = Decimal(1) / Decimal(3) print(result1) # 0.3333333333333333333333333333
getcontext().prec = 10 # 使用getcontext的prec空值精度 result2 = Decimal(1) / Decimal(3) print(result2) # 0.3333333333
<a name="ubU6i"></a>### 3.3 String字符串类型<a name="WIVry"></a>#### 3.3.1 String字符串概述- Python中的字符串是一个由多个字符组成的有序序列。注意,字符串、列表、元素都是有序的序列,这里的有序不等于排序,只是说写入的顺序与读取的顺序是一致的,可以通过索引下标获取到其中的元素。- 字符的个数即为字符串的长度,所以在Python中是没有字符的,单个字符被认作是长度位1的字符串。```pythonstr1 = "abc"print(type(str1), str1, len(str1)) # <class 'str'> abc 3str2 = 'a'print(type(str2), str2, len(str2)) # <class 'str'> a 1
- 由于Python没有字符的概念,因此字符串可以使用单引号、双引号,甚至三引号表示。
- 在字符串中可以使用转义字符()和原始字符串r。 ```python str3 = “Hello \n World” print(str3)
str4 = r”Hello \n World” print(str4)
- 运行结果:```pythonHelloWorldHello \n World
-
3.3.2 字符串的常用方法
字符串的切割:str1.split(str2),在str1中根据str2作为分隔符,将一个字符串切割成一个列表。
list1 = "Hello Linux Hello Python".split(" ")print(list1) # ['Hello', 'Linux', 'Hello', 'Python']
字符串的拼接:
方式一:使用str.join(list),将列表中的所有元素进行拼接,连接符位str。
get_str = "--".join(list1)print(get_str) # Hello--Linux--Hello--Python
方式二:使用“+”号作为连字符,得到一个新的字符串。
string1 = "abc"string2 = "def"new_str = string1 + string2print(new_str) # abcdef
方式三:字符串乘以一个数字可以得到重复次数的新的字符串。
duplicate_string = "abc" * 3print(duplicate_string) # abcabcabc
获取字符串中的字符元素:
- 正向获取单个元素:str[n],n从0开始,每次递增一。
逆向获取单个元素:str[n],n从-1开始,每次递减一。
str = "Hello"print(str[1]) # eprint(str[-1]) # o
批量获取元素(切片):str[a: b: c]。
- a位起始元素位置且缺省为0。
- b位终止元素位置且缺省为字符串最后一个元素。
- c为步长且缺省为1。
str = "Hello Python"print(str[:2]) # Heprint(str[3:]) # lo Pythonprint(str[3: 10: 3]) # lPh
替换:str1.replace(str2, str3, num),将str1中的str2子字符串替换成str3,num决定了替换的个数,缺省为全部替换。
str = "Hello Python Hello Linux"print(str.replace("Hello", "Hi")) # Hi Python Hi Linuxprint(str.replace("Hello", "Hi", 1)) # Hi Python Hello Linux
大小写转换:
Python中的字符串支持格式化输出,即将字符串中的数组按照我们需要的形式进行输出。
- 方式一:通过百分号%将对应位置上的内容进行格式化。 ```python name = “Adam” age = 18 gender = “male” salary = 150000 print(“我是%s,今年%03d岁,性别:%s,月薪为%+011.2f” % (name, age, gender, salary))
运行结果:我是Adam,今年018岁,性别:male,月薪为+0150000.00
- 方式一辅助教材:[http://c.biancheng.net/view/2177.html](http://c.biancheng.net/view/2177.html)- 方式二:通过format方法将对应位置是的内容进行格式化。```pythonname = "Adam"age = 18gender = "male"salary = 150000print("我是{0},今年{1:03d}岁,性别:{2},月薪为{3:+011.2f}".format(name, age, gender, salary))# 运行结果:我是Adam,今年018岁,性别:male,月薪为+0150000.00
方式二辅助教材:https://www.w3school.com.cn/python/ref_string_format.asp
3.4 List列表类型
3.4.1 列表概述
列表是一个有序的可变序列,可以随时进行进行元素的添加和删除,且它的元素可以是任何数据类型。
列表由一个中括号包裹住元素,元素间用逗号隔开,创建列表的方式有:
列表可以通过下标来获取列表中的元素,同样的还可以用下标对列表进行切片。
l1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]print(l1[3]) # 3print(l1[1:9:2]) # [1, 3, 5, 7]
反过来,列表还可以通过
index(obj)返回元素第一次出现的位置的下标。l2 = [0, 6, 1, 3, 5, 7, 1]print(l2.index(1)) # 2
3.4.3 列表的添加操作
list.append(obj):将参数内的对象添加至列表的尾部。
lst1 = [5, 1, 7, 3, "Hello"]lst1.append("World")print(lst1) # [5, 1, 7, 3, 'Hello', 'World']
list.insert(index, obj):将对象插入到列表的index位置。
lst1.insert(3, 100)print(lst1) # [5, 1, 7, 100, 3, 'Hello', 'World']
list.extend(iter):将可迭代对象的每个元素逐个添加插入到列表的尾部。
new_list = [1, 2, 3]lst1.extend(new_list)print(lst1) # [5, 1, 7, 100, 3, 'Hello', 'World', 1, 2, 3]
lst1 + lst2:将两个列表进行拼接,得到一个新的列表。
lst1 = [1, 2, 3, 4, 5]lst2 = [6, 7, 8, 9, 10]new_lst = lst1 + lst2print(new_lst) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
lst * n:将一个列表重复n次。
print([1, 2, 3] * 4) # [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
3.4.4 列表的删除操作
list.pop([index]):删除下标为index的元素,并将其返回,或不传参数则默认删除最后一位元素。
list1 = [13, 514, 112, 133, 514, 343, 514, 545]list1.pop(2)print(list1) # [13, 514, 133, 514, 343, 514, 545]list1.pop()print(list1) # [13, 514, 133, 514, 343, 514]
list.remove(obj):删除列表中第一个出现的给定元素。
list1.remove(514)print(list1) # [13, 133, 514, 343, 514]list1.remove(514)print(list1) # [13, 133, 343, 514]
还可以使用
del list[index]的方式删除指定索引位上的元素。del list1[3]print(list1) # [13, 133, 343]
3.4.5 列表的其他常用方法
list.sort():直接操作数组本身,进行升序排序;同时,将参数reverse设置为如True可以实现降序排序。 ```python lst1 = [5, 1, 7, 3, 2, 6] lst1.sort() print(lst1) # [1, 2, 3, 5, 6, 7]
lst2 = [3, 7, 1, 4, 5, 8] lst2.sort(reverse=True) print(lst2) # [8, 7, 5, 4, 3, 1]
- list.reverse():直接操作数组本身,将列表中的元素进行逆置。```pythonlst3 = [213, 643, True, "ABC", 132]lst3.reverse()print(lst3) # [132, 'ABC', True, 643, 213]
- sorted(list, reverse):不会直接操作数组本身,将排序的结果返回。
方式二:
records = [89, 78, 98, 56, 91, 75]
必须分开写
records.sort(reverse=True) print(records[0:3]) # [98, 91, 89]
- len(lst):返回元素的个数(即列表的长度)。```pythonlst = [132, 'ABC', True, 643, 213]print(len(lst)) # 5
lst.count(obj):给定元素出现的次数。
lst = [5, 5, 1, 3, 2, 5]print(lst.count(5)) # 3
3.5 Tuple元组类型
3.5.1 元组概述
元组是一个不可变的有序序列,因此在定时时便要确定元组内的元素。
- 因为其不可变性,所以相对于列表而言数据更加安全。
- 元组由一个小括号包裹,元素用逗号隔开。(在声明时可以不写小括号)
```python
tup1 = (1, 2, 3, 4, 5)
print(tup1, type(tup1)) # (1, 2, 3, 4, 5)
tup2 = 1, 2, 3, 4, 5
print(tup2, type(tup2)) # (1, 2, 3, 4, 5)
- 如果在声明元组时只有一个元素,需要在元素后面加上逗号,告诉解释器这不是元素符中的括号。```pythont1 = (1, )print(t1, type(t1)) # (1,) <class 'tuple'>t2 = (1)print(t2, type(t2)) # 1 <class 'int'>t3 = 1,print(t3, type(t3)) # (1,) <class 'tuple'>
3.5.2 元组的相关操作
元组存在不可变性,因此元组并没有添加、删除、修改等方法。
# TypeError: 'tuple' object does not support item assignment# a = (1, 2, 3)# a[1] = 3
但是,元组的不可变是相对的,如果元组中的某个元素是可变的,那么,在不删除这个元素的情况下,可以对这个元素进行修改。 ```python a = (1, [1, 0]) print(a) # (1, [1, 0])
a[1][1] = 1 print(a) # (1, [1, 1])
- 元组和字符串、列表一样,是一个有序的序列,因此获取元素的方式也使用索引。```pythonprint(a[0]) # 1print(a[1]) # [1, 1]
元组也可以使用“+”和“*”进行拼接和重复。
t1 = (1, 2, 3)t2 = (4, 5, 6)print(t1 + t2) # (1, 2, 3, 4, 5, 6)print(t2 * 3) # (4, 5, 6, 4, 5, 6, 4, 5, 6)
3.6 Dictionary字典类型
3.6.1 字典概述
字典是一个无序可变的KeyValue序列,其中键是唯一且不可变的,如果字典有相同的键,则后面的键对应的值会将前面的值覆盖。
- 字典由一堆花括号包裹,元素由逗号隔开,创建字典有如下三种方法:
```python
方式一:直接使用花括号包裹。
dic1 = {“k1”: “v1”, “k2”: “v2”, “k1”: “v3”} print(dic1) # {‘k1’: ‘v3’, ‘k2’: ‘v2’}
方式二:使用dict()函数,参数为一个包含n个(k, v)的二元组的列表或元组。
dic2 = dict([(“k1”, “v1”), (“k2”, “v2”), (“k3”, “v3”)]) # 参数为列表。 print(dic2) # {‘k1’: ‘v1’, ‘k2’: ‘v2’, ‘k3’: ‘v3’} dic3 = dict(((“k1”, “v1”), (“k2”, “v2”), (“k3”, “v3”))) # 参数为元组。 print(dic3) # {‘k1’: ‘v1’, ‘k2’: ‘v2’, ‘k3’: ‘v3’}
方式三:使用dict()函数的可变形参
dic4 = dict(k1=”v1”, k2=”v2”, k3=”v3”) print(dic4) # {‘k1’: ‘v1’, ‘k2’: ‘v2’, ‘k3’: ‘v3’}
<a name="ijdB8"></a>#### 3.6.2 添加/修改元素- 字典可以使用dict[newKey] = value的方式添加元素,但当key已经存在,则会修改现有Key的值。```pythondic = {} # 空字典dic["k1"] = "value1"dic["k2"] = "value1"print(dic) # {'k1': 'value1', 'k2': 'value1'}dic["k1"] = "new Value1"print(dic) # {'k1': 'new Value1', 'k2': 'value1'}
3.6.3 删除元素
dict.pop(key):删除并返回key对应的值。
dic = {"k1": "v1", "k2": "v2", "k3": "v3", "k4": "v4", "k5": "v5"}delete = dic.pop("k3")print(dic, delete) # {'k1': 'v1', 'k2': 'v2', 'k4': 'v4', 'k5': 'v5'} v3
dict.popitem():随机删除并返回被删掉的(key, value)。(一般都是删最后一个)
delete = dic.popitem()print(dic, delete) # {'k1': 'v1', 'k2': 'v2', 'k4': 'v4'} ('k5', 'v5')
dict.clear():清空字典。
dic.clear()print(dic) # {}
del dict:clear()只是清空字典中的所有元素,这个字典还是存在的;而del则是将字典从内存空间中删除。
deldic = {"k1": "v1", "k2": "v2"}del deldic# print(deldic) # NameError: name 'deldic' is not defined
3.6.4 查询元素
字典是无序的序列,因此不能通过下标索引获取成员。
可以使用dic[key]的方式获取key对应的value,但当key不存在时,会报错。
dic = {"k1": "v1", "k2": "v2", "k3": "v3"}print(dic["k1"], dic["k3"]) # v1 v3# KeyError: 'abcd'# print(dic["abcd"])
还可以使用字典对象的get(“key”, defaultValue)方法,若Key不存在,则会返回默认值。
print(dic.get("k1", "Null")) # v1print(dic.get("abcd", "Null")) # Null
除了获取指定Key的Value外,字典对象还支持用item()函数获取所有KeyValue元组、用keys()函数获取所有key、用values()函数获取所有value。
print(dic.items()) # dict_items([('k1', 'v1'), ('k2', 'v2'), ('k3', 'v3')])print(dic.keys()) # dict_keys(['k1', 'k2', 'k3'])print(dic.values()) # dict_values(['v1', 'v2', 'v3'])
3.6.5 更新字典
所谓的更新字典,实际上就是用dic1.update(dic2)函数将dic2合并到dic1中。
合并规则:如果dic2中的key在dic1中不存在,则对dic1进行扩展;如果dic2中的key在dic1中存在,则对dic1进行更新。
dic1 = {"k1": "v1", "k2": "v2"}dic2 = {"k2": "value2", "k3": "v3"}dic1.update(dic2)print(dic1) # {'k1': 'v1', 'k2': 'value2', 'k3': 'v3'}
3.7 Set集合类型
3.7.1 集合概述
集合可以看作是一个只有键的字典,是一个无序的可变序列。
- 集合中的元素是唯一的,重复的元素会被删除,和数学中的集合十分相似。
集合由一个花括号包裹,内部元素以逗号隔开。
set1 = {1, 1, 2, 3, 3, 5, 1}print(set1) # {1, 2, 3, 5},重复元素被删除了
注意:空集在定义时不能直接使用花括号,会被识别成一个字典,应该使用set()函数。
set2 = {}print(type(set2), set2) # <class 'dict'> {}set2 = set()print(type(set2), set2) # <class 'set'> set()
3.7.2 添加元素
set.add(obj):将obj添加到集合中,但如果元素已存在,则不会进行任何操作。
s1 = {1, 2, 3}s1.add(5)s1.add("abc")s1.add(5)print(s1) # {1, 2, 3, 5, 'abc'},已有的元素不会被添加
set.update(obj):与字典的update()函数类似,这里的obj可以是列表、字典等,也可以是多个,中间用逗号隔开。
- 注意:当obj为字典时,只会把字典中的key添加到集合中。 ```python s1 = {1, 2, 3} s2 = [4, 61, “aa”] s3 = {“k1”:”v1”, “k2”:”v2”}
方式一:
s1.update(s2) print(s1) # {1, 2, 3, 4, ‘aa’, 61} s1.update(s3) print(s1) # {1, 2, 3, 4, ‘k1’, ‘aa’, 61, ‘k2’}
方式二:
s1.update(s2, s3) print(s1) # {1, 2, 3, 4, ‘k2’, ‘k1’, ‘aa’, 61}
<a name="ZuyzB"></a>#### 3.7.3 删除元素- set.remove(obj):将obj从集合中删除,但如果obj在集合中不存在,则会报错。```pythons1 = {1, 2, 3, 4}s1.remove(3)print(s1) # {1, 2, 4}s1.remove(3000) # 报错KeyError: 3000
set.discard(obj):可以理解为remove的升级版,如果obj在集合中存在,则删除;不存在,则不做任何处理。
s1 = {1, 2, 3, 4}s1.discard(3)print(s1) # {1, 2, 4}s1.discard(3000) # 不做任何处理
set.clear():清空集合。
s = {1, 2, 3, 4}s.clear()print(s) # set()
set.pop():随机删除一个元素。
s = {1, 2, 3, 4}s.pop()print(s) # {2, 3, 4}
3.7.4 集合的逻辑运算
注意:只有集合才能运算,前面的列表、元组等都不能进行运算。
set1 & set2:求交集,得到两个集合中相同的元素的集合。
s1 = {1, 2, 3, 4}s2 = {3, 4, 5, 6}s3 = s1 & s2print(s3) # {3, 4}
set1 | set2:求并集,得到存在于set1或者set2中的元素的集合。
s1 = {1, 2, 3, 4}s2 = {3, 4, 5, 6}s3 = s1 | s2print(s3) # {1, 2, 3, 4, 5, 6}
set1 - set2:求差集,得到存在于set1但不存在于set2的元素的集合。
s1 = {1, 2, 3, 4}s2 = {3, 4, 5, 6}s3 = s1 - s2print(s3) # {1, 2}
set1 ^ set2:求对称差集,得到两个集合中特有元素的集合。(即交集减去并集)
s1 = {1, 2, 3, 4}s2 = {3, 4, 5, 6}s3 = s1 ^ s2print(s3) # {1, 2, 5, 6}
3.8 数据类型的公共方法
3.8.1 len(obj)
len(obj):返回数据的长度。
lst = [1, 42, 54, "Abc", True]print(len(lst)) # 5
3.8.2 type(obj)
type(obj):返回数据的类型。
flag = Falseprint(type(flag)) # <class 'bool'>
3.8.3 enumerate(iter)
enumerate(iter):返回一个可迭代对象,对象中元素为下标和数据组成的元组。 ```python lst = [5, 1, 7, 3] for index, tmp in enumerate(lst): print(index, tmp)
“”” 运行结果: 0 5 1 1 2 7 3 3 “””
<a name="n8Ber"></a>#### 3.8.4 id(obj)- id(obj):返回数据所在内存中的存储地址。```pythonstr = "abc"print(id(str)) # 2432064349616
3.8.5 in(obj)
in(obj):判断数据是否在给定的数据之中。
lst = [12, 321, False, "Apple", "Mac"]print("Apple" in lst) # True
3.8.6 max(obj)/min(obj)
max(obj):返回数据中的最大值。
min(obj):返回数据中的最小值。
lst = [5, 1, 7, 3]max_num = max(lst)min_num = min(lst)print(min_num, max_num) # 1 7
3.8.7 del(obj)
del(obj):删除对象。
注意,对象删除后,再调用该对象会报该对象未定义的错误。
obj = "ABC"print(obj) # ABCdel obj# print(obj) # 报错,NameError: name 'obj' is not defined
3.8.8 zip(list1, list2)
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象。
lst1 = [1, 3, 4, 6]lst2 = ['A', 'C', 'D', 'F']lst3 = list(zip(lst1, lst2))print(lst3) # [(1, 'A'), (3, 'C'), (4, 'D'), (6, 'F')]
如果各个迭代器的元素个数不一致,则返回的列表长度与最短的对象相同。
lst1 = [1, 3, 4, 6]lst2 = ['A', 'C', 'D', 'F', 'G', 'H', 'Z']lst3 = list(zip(lst1, lst2))print(lst3) # [(1, 'A'), (3, 'C'), (4, 'D'), (6, 'F')]
与zip相反,zip(*)可理解为解压,返回二维矩阵式。
lst1 = [1, 3, 4, 6]lst2 = ['A', 'C', 'D', 'F']my_zip = zip(lst1, lst2)l1, l2 = zip(*my_zip)print(list(l1)) # [1, 3, 4, 6]print(list(l2)) # ['A', 'C', 'D', 'F']
3.8.9 isinstance(val, type)
判断一个数据或一个变量是否是某种类型的。
print(isinstance(3.14, int)) # Falseprint(isinstance(5, int)) # True
3.8.10 count(obj)
list.cout(obj)函数可以统计obj这个对象在list中出现了多少次。
lst = [1, 1, 4, 5, 1, 3, 2, 1, 6, 1]print(lst.count(1)) # 5
3.8.11 类型转换
str(obj):将obj转换成一个字符串。
num = 123str_num = str(num)print(type(str_num), str_num) # <class 'str'> 123
list(obj):将obj转换成一个列表。
tup = (1, 2, 3, 4)lst = list(tup)print(type(lst), lst) # <class 'list'> [1, 2, 3, 4]
tuple(obj):将obj转换成一个元素。
lst = [1, 2, 3, 4]tup = tuple(lst)print(type(tup), tup) # <class 'tuple'> (1, 2, 3, 4)
set(obj):将obj转换成一个集合。
lst = [1, 2, 3, 1, 2, 4]s = set(lst)print(type(s), s) # <class 'set'> {1, 2, 3, 4}
dict(obj):将obj转换成一个字典。
x_loc = ('x', 5.1)y_loc = ('y', 31.6)z_loc = ('z', -19.7)loc = dict([x_loc, y_loc, z_loc])print(type(loc), loc) # <class 'dict'> {'x': 5.1, 'y': 31.6, 'z': -19.7}
int(obj):将obj转换成整形数据。
float(obj):将obj转换成浮点型数据。
pi = 3.14i = int(pi)print(i) # 3f = float(i)print(f) # 3.0
3.9 深拷贝和浅拷贝
在Python中对于数据的拷贝可以根据拷贝形式的不同分为深拷贝和浅拷贝。
3.9.1 Python中的赋值
Python中的赋值都是地址引用,即将等号右边的地址赋值给等号左边的变量,而非将值本身赋值给左边的变量。
如下操作是一个列表变量的赋值:
lst1 = [5, 1, [7, 3]]lst2 = lst1
- 在内存中其大致结构如下:
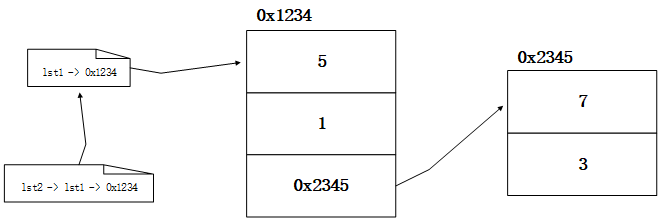
- 可以用id()函数来验证,可以发现id(lst1)和id(lst2)的结果是一样的。
print(id(lst1)) # 2058910520000print(id(lst2)) # 2058910520000
因此在这种情况下,对lst2做修改,实际上就是对0x1234做修改,故lst2的修改结果会影响到lst1。
lst2[1] = 300print(lst1) # [5, 300, [7, 3]]
3.9.2 浅拷贝
浅拷贝即将数据的表面结构进行拷贝,如果数据为嵌套的结构,则嵌套结构里面的元素是对之前数据的引用。修改之前的数据会影响拷贝得到的数据。
- 浅拷贝通过copy模块中的copy(obj)方法实现: ```python import copy
lst1 = [5, 1, [7, 3]] lst2 = copy.copy(lst1)
- 在内存中其大致结构如下: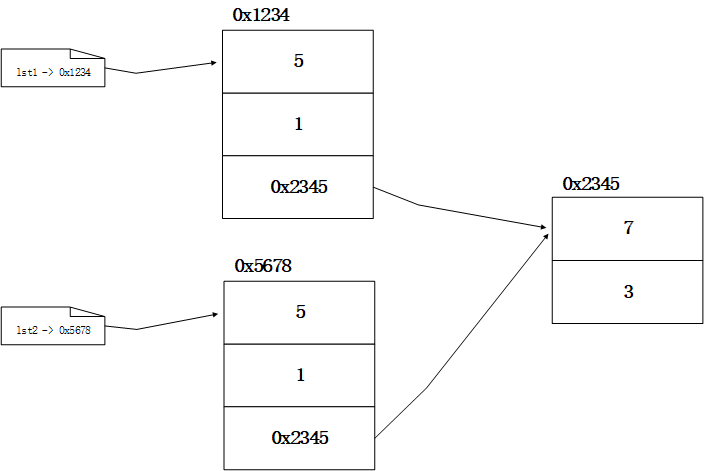- 这种情况下,直接看两个变量的id那肯定是不一样的,但是这两个列表中还有列表,这个列表还是引用同一个变量。```pythonprint(id(lst1), id(lst2)) # 1729082378176 1729085617728print(id(lst1[2]), id(lst2[2])) # 1729085600576 1729085600576
- 此时,修改lst1中的普通数据类型的数据,对lst2不会有影响;但如果修改引用的变量,就会对lst2产生影响。 ```python lst1[1] = 100 print(lst1, lst2) # [5, 100, [7, 3]] [5, 1, [7, 3]]
lst1[2][1] = 400 print(lst1, lst2) # [5, 100, [7, 400]] [5, 1, [7, 400]]
<a name="HBMkS"></a>#### 3.9.3 深拷贝- 深拷贝,解决了嵌套结构中深层结构只是引用的问题,它会对所有的数据进行一次复制,修改之前的数据则不会改变拷贝得到的数据。- 深拷贝通过copy模块中的deepcopy(obj)方法实现:```pythonimport copylst1 = [5, 1, [7, 3]]lst2 = copy.deepcopy(lst1)lst1[1] = 100lst1[2][1] = 400print(lst1, lst2) # [5, 100, [7, 400]] [5, 1, [7, 3]]
04. 判断与循环语句
4.1 分支结构
4.1.1 if分支语句概述
- Python中的条件控制是通过条件语句的执行结果(True或者False)来决定执行的代码块。
Python中使用if来控制程序的执行,如果有多个条件的判断,可以使用if-elif-else的形式。
if 判断条件1:执行的代码块1elif 判断条件2:执行的代码块2else:执行的代码块3
4.1.2 分支语句中常用的运算符
![IJ`2{IPKKJZW(}LK%B5PB1.png
4.2 循环结构
4.2.1 while循环
Python语言中while语句用于执行循环程序,在某条件下,循环执行某段程序,以处理需要重复处理的相同任务。
# 计算n的阶乘n = eval(input("Enter n: "))result = i = 1while i <= n:result *= ii += 1print(result)
当while语句的条件永远为真时,循环永远不会结束,形成无限循环,也称死循环。
while True:print("Hello World")
可以在while后面加入else语句块,在条件为假时执行(可以不加else)。
n = 1while n <= 10:print(n)n += 1else:print("循环结束")
-
4.2.2 for循环
Python中的for语句与传统的for语句不太一样,它接受可迭代对象(如序列)作为其参数,每次迭代其中的一个元素。 ```python
迭代range对象。
for i in range(1, 100): print(i)
迭代列表。
lst = [1, 3.1, True, “ABC”] for i in lst: print(i)
- Python的for可以拥有else语句块,代表当for正常执行完毕退出(即循环没有被break终止)后执行的语句块。```pythonfor i in range(1, 10):print(i)else:print("Hello Python")
4.3 流程控制的三个关键字
- 如果满足某个条件时,我们想让程序什么都不做,那么可以使用pass关键字。
- 在循环进行时,如果我们需要打断循环可以使用break和continue来实现。
break和continue语句都可用在while和for循环中。
4.3.1 pass
和它的字面意思一样,pass就是什么都不做,跳过的意思。
如,打印1~100以内所有的偶数就可以用pass关键字。(当num % 2不等于0的时候,说明是一个奇数,直接pass)
for i in range(1, 101):if i % 2 != 0:passelse:print(i)
4.3.2 break
break语句结束整个循环。如果触发了break,则当前循环终止,循环对应的else也不会执行。
- 如果在嵌套循环中使用break语句,将停止执行break所在的那一层循环,并开始执行下一行代码。
示例:打印一个10 * 10的数字方阵,但第五层不要打印数据,为空行。
for i in range(1, 11):for j in range(1, 11):if i == 5:breakprint(i, end="\t")print()
4.3.3 continue
continue语句用来告诉Python跳过当前循环的剩余语句,然后继续进行下一轮循环。
示例:打印1~10的所有奇数。
for i in range(1, 11):if i % 2 == 0:continueprint(i)
05. 函数
5.1 函数的概念
函数是组织好的,可重复使用的,用来实现单一或相关联功能的代码段。
- 函数能提高应用的模块性,和代码的重复利用率。
Python提供了许多内建函数,比如print()。也可以自己创建函数,这被叫做用户自定义函数。
5.2 函数的定义与调用
函数的定义:
- 在Python中用关键字def声明函数,后面跟函数名和小括号,括号内可以放置所需参数。
- 函数体中的第一行可以选择性地使用文档字符串,存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return标志着函数的结束,用于返回一个函数执行的结果。
- 函数的调用:函数名加小括号即可调用,可在括号内传入所需的参数。 ```python def function(param): # 定义函数和所需参数 “”” 函数的说明文档 “”” # 函数说明 函数体 # 函数所需要执行的内容 return 返回值 # 函数的返回值
function(param=value) # 函数的调用
- 示例:用Python定义函数实现的功能,并用其计算。```pythondef f(x):"""计算参数x的平方:param x: 数值类型:return: x的平方"""result = x ** 2return resultf10 = f(10)print(f10) # 100
5.3 函数的返回值
- 函数可以根据返回值分为有返回值函数和无返回值函数。
- 无返回值:函数体中没有return,函数返回None值。
- 有返回值:函数体中有return语句,并且返回了相应的表达式或者数值。
Python中函数可以有多个返回值(不是return多次,是一个return后跟多个返回值),默认以元组的形式返回。
5.4 函数中的参数
Python中函数的参数可以分为:必备参数、关键字参数、默认参数、不定长参数四种。
5.4.1 必备参数
必备参数必须以正确的顺序传入函数,调用时的数量必须和声明时的一致。 ```python def sum(num1, num2): return num1 + num2
print(sum(10, 23)) # 33
<a name="vhLKz"></a>#### 5.4.2 关键字参数- 函数调用时可以使用“参数名 = 值”的方式传入参数,这种时候对赋值的先后顺序没有要求。```pythondef sum(num1, num2):return num1 + num2print(sum(num2=132, num1=423)) # 555
5.4.3 默认参数
- 声明函数式,处理定义形参名外,还要为形参赋予默认值。
- 调用函数时,缺省参数的值如果没有传入,则被仍为使用默认值。 ```python def fuc(num1, num2, num3=100): return sum([num1, num2, num3])
print(fuc(100, 200, 300)) # 600 print(fuc(100, 200)) # 400
- 注意:如果一个函数的参数中含有默认参数,则这个默认参数后的所有参数都必须是默认参数 。即没有默认值的参数要放在参数列表的前面,有默认值的参数要放在参数列表的后面。<a name="J0Ngm"></a>#### 5.4.4 不定长参数- 有时可能需要一个函数能处理比当初声明时更多的参数,这些参数叫做不定长参数,声明时不会命名。- 两个不定长参数:- *args:将不定长参数中的所有元素封装成一个元素处理。- **kwargs:存放命名参数,并解析成“参数名=值”的键值对,封装成一个字典。```pythondef fun(a, b, c=100, *args, **kwargs):print(a, b, c)print(type(args), args)print(type(kwargs), kwargs)fun(1, 2, 3, 4, 5, 6, 7, k1="v1", k2="v2")"""运行结果:1 2 3<class 'tuple'> (4, 5, 6, 7)<class 'dict'> {'k1': 'v1', 'k2': 'v2'}"""
5.4.5 参数声明的先后顺序
根据Python的语法规则与实践的到的编码习惯,建议声明顺序为:普通参数 默认参数 一颗星 两颗星
def func(a, b, c=100, *args, **kwargs):pass
5.5 lambda表达式
Python中除了def可以创建函数外,还提供了lambda来创建匿名函数。
- 相比于普通函数,匿名函数有以下特点:
- lambda只是一个表达式,函数体比def简单的多。(lambda表达式只能有一行)
- lambda不是一个代码块,仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 定义匿名函数:
lambda x: x + 1- lambda:匿名函数声明符号
- x:匿名函数的参数
- x + 1:函数体(包括返回值)
- 匿名函数与普通函数:
函数调用
print(add(10, 20))
- 匿名函数:```python# 函数声明lambda_add = lambda num1, num2: num1 + num2# 函数调用print(lambda_add(10, 20))
06. Python基础部分练习
- 把字符串
s = "Hello World Hello Linux Hello Hadoop"中前两个hello替换成NiHao。 - 把上一步的字符串以空格分割,赋值给lst变量。
- 把lst中最后一个成员大写、小写。
- 把lst以“-”连接成一个字符串,并赋值给str2。 ```python s = “Hello World Hello Linux Hello Hadoop” new_str = s.replace(“Hello”, “NiHao”, 2) print(new_str) # NiHao World NiHao Linux Hello Hadoop
lst = new_str.split(“ “) print(lst) # [‘NiHao’, ‘World’, ‘NiHao’, ‘Linux’, ‘Hello’, ‘Hadoop’]
last = lst[-1] print(last.upper()) # HADOOP print(last.lower()) # hadoop
str2 = “-“.join(lst) print(str2) # NiHao-World-NiHao-Linux-Hello-Hadoop
- 格式化输出:- 现有字符串:s = "name=Adam|age=21|gender=male"- 实现输出:姓名=Adam,年龄=21,性别=male```pythons = "name=Adam|age=21|gender=male"data = s.split("|")name = data[0].split("=")[1]age = int(data[1].split("=")[1])gender = data[2].split("=")[1]print("姓名={0},年龄={1},性别={2}".format(name, age, gender))
- 定义一个列表lst,成员为7、1、3、5。
- 在末尾追加’TengKe’。
- 删除第二个元素1。
- 在3的后面插入’Adam’。
删除元素5。
lst = [7, 1, 3, 5]lst.append("TenKe")lst.pop(1)lst.insert(2, "Adam")lst.remove(5)print(lst) # [7, 3, 'Adam', 'TenKe']
有如下列表lst2:5、1、7、3。
对列表进行降序排序。
lst2 = [5, 1, 7, 3]lst2.sort(reverse=True)print(lst2) # [7, 5, 3, 1]
定义一个元组,只有一个成员100。
tup = (100,)print(type(tup), tup) # <class 'tuple'> (100,)
定义一个字典dic1,其中:name=Adam、age=21、gender=male。
- 获取name和city键对应的值,如果键不存在,则输出“此键不存在”。
- 添加一个键:city=Shanghai。
- 把字典
dic2 = {'class':'c1', 'school':'FuDan'}中的键值对添加到dic1中 删除school这个键值对。
dic1 = {"name": "Adam", "age": 21, "gender": "male"}name = dic1.get("name", "此键不存在")city = dic1.get("city", "此键不存在")print(name, city) # Adam 此键不存在dic1["city"] = "Shanghai"dic2 = {'class': 'c1', 'school': 'FuDan'}dic1.update(dic2)dic1.pop("school")print(dic1) # {'name': 'Adam', 'age': 21, 'gender': 'male', 'city': 'Shanghai', 'class': 'c1'}
定义一个集合set1:a、b、c、d。
添加一个元素e,删除一个元素d。
set1 = {"a", "b", "c", "d"}set1.add("e")set1.discard("d")print(set1) # {'e', 'c', 'a', 'b'}
定义一个列表lst1 = [1, 2, [3, 4, 5]],分别对该列表进行深拷贝和浅拷贝,并加以验证。 ```python import copy
lst1 = [1, 2, [3, 4, 5]] lst2 = copy.copy(lst1) lst3 = copy.deepcopy(lst1)
print(id(lst1) == id(lst2), id(lst1[2]) == id(lst2[2])) # False True print(id(lst1) == id(lst3), id(lst1[2]) == id(lst3[2])) # False Flase
- 定义函数实现斐波那契数列,需要递归和非递归方式实现两种。- 斐波那契数列:1、1、2、3、5、……- 解读:前两个数固定为1,第三个数开始为前两个数的和。```python# 递归方式def feibo1(num):if num <= 2:return 1else:return feibo1(num - 2) + feibo1(num - 1)# 非递归方式def feibo2(num):if num > 2 and isinstance(num, int):result = [1, 1]for i in range(2, num):tmp = result[i - 1] + result[i - 2]result.append(tmp)return resultelse:return "输入的必须是一个大于2的整形数据"print(feibo1(5)) # 5print(feibo2(5)) # [1, 1, 2, 3, 5]
现有两个列表:
lst1 = ['col1', 'col2', 'col3', 'col4', 'col5']和lst2 = [5, 1, 7, 3, 6]。- 需求一:把lst1和lst2结合起来,形成:
[('col1', 5), ('col2', 1), ('col3', 7), ('col4', 3), ('col5', 6)] - 需求二:按照元组的第二个成员进行排序,并取出前三个col。
lst1 = ['col1', 'col2', 'col3', 'col4', 'col5']lst2 = [5, 1, 7, 3, 6]lst3 = list(zip(lst1, lst2))lst3.sort(key=lambda data: data[1], reverse=True)print(lst3[:3]) # [('col3', 7), ('col5', 6), ('col1', 5)]
- 需求一:把lst1和lst2结合起来,形成:
定义一个函数,函数实现对列表进行冒泡排序。
- 注意:不可以调用自带的排序以及内置函数,需要手动实现排序算法。
- reverse的值为False,代表升序排序,为True代表降序排序。
```python
def func(lst, reverse=True):
for i in range(len(lst) - 1):
for j in range(0, len(lst) - 1 - i):
if reverse:if lst[j] > lst[j + 1]:lst[j], lst[j + 1] = lst[j + 1], lst[j]else:if lst[j] < lst[j + 1]:lst[j], lst[j + 1] = lst[j + 1], lst[j]
lst = [5, 1, 3, 6, 2] func(lst, False) print(lst) # [6, 5, 3, 2, 1] func(lst) print(lst) # [1, 2, 3, 5, 6]
- 统计每个成员个数:- 现有数据:`lst = [2, 2, 1, 3, 2, 1, 3, 4, 1, 2, 4]`- 返回结果:`{1: 3, 2: 4, 3: 2, 4: 2}````pythondef func(lst):dic = {}set_data = set(lst)for i in set_data:dic[i] = lst.count(i)return diclst = [2, 2, 1, 3, 2, 1, 3, 4, 1, 2, 4]print(func(lst))

若有收获,就点个赞吧
0 人点赞

{kind=link}