01. 数字与字符串函数
1.1 数值函数
1.1.1 ABS求绝对值
ABS(字段/数据)函数用于求字段的绝对值或者数据的绝对值。SELECT ABS(10); -- 10SELECT ABS(0); -- 0SELECT ABS(-10); -- 10
1.1.2 CEIL向上取整
CEIL(字段/数据)函数用于对数据进行向上取整。SELECT CEIL(17.9); -- 18SELECT CEIL(-17.9); -- -17
1.1.3 FLOOR向下取整
FLOOR(字段/数据)函数用于对数据进行向下取整。SELECT FLOOR(17.9); -- 17SELECT FLOOR(-17.9); -- -18
1.1.4 ROUND四舍五入
ROUND(字段/数据)函数对数据进行四舍五入取整。SELECT ROUND(27.567); -- 28
ROUND(字段/数据, N)函数对数据进行四舍五入保留N位小数。SELECT ROUND(27.4578, 2); -- 27.46
示例:查询每个部门的平均基本工资,结果四舍五入保留两位小数。
SELECT deptno, ROUND(AVG(ebsalary), 2) AS avg_salFROM employeeGROUP BY deptno;
1.1.5 PI圆周率
PI()函数可以用于获取圆周率。SELECT PI(); -- 3.141593
1.1.6 RAND随机数
RAND()函数用于生成一个 之间的随机数。
之间的随机数。SELECT RAND(); -- 0.9019443159009742
1.1.7 POW幂函数
POW(x, y)函数用于求x的y次幂,即 ;
;SELECT POW(2, 3); -- 8
1.1.8 GREATEST最大值
GREATEST(datas)函数用于从数据datas中找出最大的数据。SELECT GREATEST(19, 39, 45, 6, 89); -- 89
1.1.9 LEAST最小值
LEAST(datas)函数用于从数据datas中找出最小的数据。SELECT LEAST(19, 39, 45, 6, 89); -- 6
1.2 字符串函数
1.2.1 CHAR_LENGTH字符串长度
CHAR_LENGTH(str)函数用于获取字符串str中字符的个数(即字符串str的长度)。SELECT CHAR_LENGTH('abcdefg'); -- 7
示例:查询出名字长度是3个字的学生数据。
SELECT * FROM studentWHERE CHAR_LENGTH(sname) = 3;
1.2.2 LEFT获取左边指定个数的字符
LEFT(str, N)函数用于从字符串str左边获取N个字符的子字符串。SELECT LEFT('abcdefg', 3); -- abc
1.2.3 RIGHT获取右边指定个数的字符
RIGHT(str, N)函数用于从字符串str右边获取N个字符的子字符串。SELECT RIGHT('abcdefg', 3); -- efg
示例:查询姓“刘”的同学的信息和名字为“鹏”的同学的信息。
SELECT * FROM student WHERE LEFT(sname, 1) = '刘'UNIONSELECT * FROM student WHERE RIGHT(sname, 1) = '鹏';
1.2.4 INSTR是否包含子字符串
INSTR(str1, str2)函数用于判断字符串str1中是否包含子字符串str2;若包含则返回1,否则返回0。SELECT INSTR('abcdefg', 'ab'); -- 1SELECT INSTR('abcdefg', 'bh'); -- 0
示例:查找出名字中包含“晓”的学生信息。
SELECT * FROM studentWHERE INSTR(sname, '晓');
1.2.5 CONCAT字符串拼接(不可指定连接符)
CONCAT(datas)函数用于将数据序列datas中的所有数据拼接在一起。(datas中的数据可以是任意类型的)SELECT CONCAT(1, '2', '01'); -- 1201
1.2.6 CONCAT_WS字符串拼接(可指定连接符)
CONCAT_WS(连接符, datas)函数是CONCAT函数的升级,它会将第一个参数作为后续元素的连接符。SELECT CONCAT_WS('_', 1, '2', '01'); -- 1_2_01
1.2.7 LOCATE查找子串
LOCATE(str1, str2)函数用于从字符串str2中查找子字符串str1第一次出现的位置。(SQL中字符串的下标是从1开始的)SELECT LOCATE('ab', 'helloabcdegoodab'); -- 6
1.2.8 REPLACE子串替换
REPLACE(str1, str2, str3)函数用于从字符串str1中找出子字符串str2,并将str2替换成str3。SELECT REPLACE('helloabcdegoodab', 'ab', 'AB'); -- helloABcdegoodAB
1.2.9 TRIM移除两端内容
TRIM函数有多种用法,其中TRIM(str)用于去除字符串str前后的空格。SELECT TRIM(' Python Data Analysis '); -- Python Data AnalysisSELECT CHAR_LENGTH(TRIM(' Python Data Analysis ')); -- 20
TRIM(str2 FROM str1)用于去除字符串str1前后的str2。SELECT TRIM('a' FROM 'aaaMySQLaaa'); # MySQL
TRIM(LEADING str2 FROM str1)用于去除字符串str1前面的str2。SELECT TRIM(LEADING 'a' FROM 'aaaMySQLaaa'); # MySQLaaa
TRIM(TRAILING str2 FROM str1)用于去除字符串str1后面的str2。SELECT TRIM(TRAILING 'a' FROM 'aaaMySQLaaa'); # aaaMySQL
1.2.10 UPPER大写转换
UPPER(str)函数用于将字符串str中所有英文字符都转换成大写。SELECT UPPER('PythonMySQLPowerBI'); -- PYTHONMYSQLPOWERBI
1.2.11 LOWER小写转换
LOWER(str)函数用于将字符串str中所有英文字符都转换成小写。SELECT LOWER('PythonMySQLPowerBI'); -- pythonmysqlpowerbi
1.2.12 SUBSTR提取子字符串
SUBSTR函数有两种用法,其中SUBSTR(str, index)用于在str中截取index位到最后的子字符串。(字符串的索引从1开始)SELECT SUBSTRING("Kevin Durant", 7); -- Durant
SUBSTR(str, index, length)用于在str中截取从index位开始,长度为length的子字符串。SELECT SUBSTRING("Kevin Durant", 1, 5); -- Kevin
注意:
SUBSTR是SUBSTRING的简写,即这两个字面量所代表的函数是一样的。1.2.13 STRCMP字符串大小比较
STRCMP(str1, str2)函数用于比较字符串str1和字符串str2的大小,比较规则为:若str1 > str2,则返回1。
SELECT STRCMP('J', 'D'); -- 1
若str1 = str2,则返回0。
SELECT STRCMP('Z', 'Z'); -- 0
若str1 < str2,则返回-1。
SELECT STRCMP('A', 'D'); -- -1
字符串大小比较的本质是从左到右依次比较每个字符对应的十进制数据。
02. 阶段练习二
数据准备。(直接复制进去即可) ```sql — 创建数据库 DROP DATABASE IF EXISTS myemp2; CREATE DATABASE IF NOT EXISTS myemp2; USE myemp2;
— 创建部门表 DROP TABLE IF EXISTS dept; CREATE TABLE IF NOT EXISTS dept ( deptno INT PRIMARY KEY COMMENT ‘部门编号’, dname VARCHAR(14) COMMENT ‘部门名’, loc VARCHAR(13) COMMENT ‘部门位置’ ); INSERT INTO dept VALUES (10, ‘accounting’, ‘NEW YORK’); INSERT INTO dept VALUES (20, ‘research’, ‘DALLAS’); INSERT INTO dept VALUES (30, ‘sales’, ‘CHICAGO’); INSERT INTO dept VALUES (40, ‘operations’, ‘BOSTON’);
— 创建员工表 DROP TABLE IF EXISTS emp; CREATE TABLE IF NOT EXISTS emp ( empno INT PRIMARY KEY COMMENT ‘员工编号’, ename VARCHAR(10) COMMENT ‘员工姓名’, job VARCHAR(9) COMMENT ‘职位’, mgr INT COMMENT ‘员工直属领导编号’, hiredata DATE COMMENT ‘入职时间’, sal DOUBLE COMMENT ‘工资’, comm DOUBLE COMMENT ‘奖金’, deptno INT COMMENT ‘部门编号’ ); INSERT INTO emp VALUES (7369, ‘smith’, ‘clerk’, 7902, ‘1980-12-17’, 800, NULL, 20); INSERT INTO emp VALUES (7499, ‘allen’, ‘salesman’, 7698, ‘1981-02-20’, 1600, 300, 30); INSERT INTO emp VALUES (7521, ‘ward’, ‘salesman’, 7698, ‘1981-02-22’, 1250, 500, 30); INSERT INTO emp VALUES (7566, ‘jones’, ‘manager’, 7839, ‘1981-04-02’, 2975, NULL, 20); INSERT INTO emp VALUES (7654, ‘martin’, ‘salesman’, 7698, ‘1981-09-28’, 1250, 1400, 30); INSERT INTO emp VALUES (7698, ‘blake’, ‘manager’, 7839, ‘1981-05-01’, 2850, NULL, 30); INSERT INTO emp VALUES (7782, ‘clark’, ‘manager’, 7839, ‘1981-06-09’, 2450, NULL, 10); INSERT INTO emp VALUES (7788, ‘scott’, ‘analyst’, 7566, ‘1987-07-03’, 3000, NULL, 20); INSERT INTO emp VALUES (7839, ‘king’, ‘president’, NULL, ‘1981-11-17’, 5000, NULL, 10); INSERT INTO emp VALUES (7844, ‘turner’, ‘salesman’, 7698, ‘1981-09-08’, 1500, 0, 30); INSERT INTO emp VALUES (7876, ‘adams’, ‘clerk’, 7788, ‘1987-07-13’, 1100, NULL, 20); INSERT INTO emp VALUES (7900, ‘james’, ‘clerk’, 7698, ‘1981-12-03’, 950, NULL, 30); INSERT INTO emp VALUES (7902, ‘ford’, ‘analyst’, 7566, ‘1981-12-03’, 3000, NULL, 20); INSERT INTO emp VALUES (7934, ‘miller’, ‘clerk’, 7782, ‘1981-01-23’, 1300, NULL, 10);
— 创建工资等级表 DROP TABLE IF EXISTS salgrade; CREATE TABLE IF NOT EXISTS salgrade ( grade INT COMMENT ‘工资等级’, lowsal DOUBLE COMMENT ‘最低工资’, hisal DOUBLE COMMENT ‘最高工资’ ); INSERT INTO salgrade VALUES (1, 700, 1200); INSERT INTO salgrade VALUES (2, 1201, 1400); INSERT INTO salgrade VALUES (3, 1401, 2000); INSERT INTO salgrade VALUES (4, 2001, 3000); INSERT INTO salgrade VALUES (5, 3001, 9999);
- 找出姓名以a、b、s开始的员工信息。```sql-- LIKE模糊查询方式SELECT * FROM emp WHERE ename LIKE 'a%' OR ename LIKE 'b%' OR ename LIKE 's%';-- 正则表达式方式SELECT * FROM emp WHERE ename REGEXP '^[abs]';-- 字符串函数方式SELECT * FROM emp WHERE LEFT(ename, 1) IN ('a', 'b', 's');
返回员工的详细信息并按姓名排序。
SELECT * FROM emp ORDER BY ename; -- 升序排序SELECT * FROM emp ORDER BY ename DESC; -- 降序排序
返回员工的信息并按职位降序工资升序排列。
SELECT * FROM emp ORDER BY job DESC, sal ASC;
返回拥有员工的部门名、部门号。 ```sql — 子查询方式 SELECT deptno, dname FROM dept WHERE deptno IN ( SELECT DISTINCT deptno FROM emp );
— 连接查询方式 SELECT DISTINCT d.deptno, d.dname FROM emp AS e INNER JOIN dept d on e.deptno = d.deptno;
- 工资高于smith的员工信息。```sqlSELECT * FROM empWHERE sal > (SELECT sal FROM emp WHERE ename = 'smith');
返回员工和所属领导的姓名(自连接,领导也是员工的一部分)。
SELECTem.ename AS 员工姓名,ma.ename AS 领导姓名FROM emp AS emINNER JOIN emp AS ma ON em.mgr = ma.empno;
返回员工的入职日期早于其领导的入职日期的员工及其领导姓名和两人的入职日期。
SELECTem.ename AS 员工姓名,em.hiredata AS 员工入职时间,ma.ename AS 领导姓名,ma.hiredata AS 领导入职时间FROM emp AS emINNER JOIN emp AS ma ON em.mgr = ma.empnoWHERE em.hiredata < ma.hiredata;
返回员工姓名及其所在的部门名称。
SELECTe.ename AS 员工名,d.dname AS 部门名FROM emp AS eINNER JOIN dept AS d ON e.deptno = d.deptno;
返回从事clerk工作的员工姓名和所在部门名称。
SELECT ename, dname FROM emp AS eINNER JOIN dept AS d ON e.deptno = d.deptnoWHERE job = 'clerk';
返回部门号及其本部门的最低工资。
SELECT deptno, MIN(sal) FROM emp GROUP BY deptno;
返回销售部(sales)所有员工的姓名。 ```sql — 子查询的方式 SELECT ename FROM emp WHERE deptno = ( SELECT deptno FROM dept WHERE dname = ‘sales’ );
— 连接查询的方式 SELECT ename FROM emp AS e INNER JOIN dept AS d ON e.deptno = d.deptno WHERE d.dname = ‘sales’;
- 返回与scott从事相同工作的员工。```sqlSELECT * FROM empWHERE job = (SELECT job FROM emp WHERE ename = 'scott') AND ename != 'scott';
返回员工的详细信息(包括部门名称及部门地址)。
SELECT e.*, dname, locFROM emp AS eLEFT JOIN dept AS d ON e.deptno = d.deptno
返回员工工作及其从事此工作的最低工资。
SELECTjob,MIN(sal) AS 最低工资FROM empGROUP BY job;
返回工资处于第四级别的员工的姓名。
SELECT * FROM emp AS eINNER JOIN salgrade AS sON e.sal BETWEEN s.lowsal AND s.hisalWHERE grade = 4;
返回工资为二等级的职员名字、部门所在地、二等级的最低工资和最高工资。
SELECTe.ename,d.loc,s.lowsal,s.hisalFROM emp AS eINNER JOIN salgrade AS sON e.sal BETWEEN s.lowsal AND s.hisalINNER JOIN dept AS dON e.deptno = d.deptnoWHERE grade = 2;
工资等级高于smith的员工信息。
SELECT e.* FROM emp AS eINNER JOIN salgrade AS sON e.sal BETWEEN s.lowsal AND s.hisalWHERE s.grade > (SELECT s.grade FROM emp AS eINNER JOIN salgrade AS sON e.sal BETWEEN s.lowsal AND s.hisalWHERE e.ename = 'smith');
获取每个部门最高薪资的员工信息。
SELECT * FROM (-- 用窗口函数查询部门的最高工资SELECT*,MAX(sal + IFNULL(comm, 0)) OVER(PARTITION BY deptno) AS max_sal_in_deptFROM emp) AS tmp-- 若当前员工的总工资等于他部门的最高工资。-- 那么该员工就是该部门薪资最高的员工。WHERE sal + IFNULL(comm, 0) = max_sal_in_dept;
获取每个部门薪水最高的前两名的员工信息。
SELECT * FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY deptnoORDER BY sal + IFNULL(comm, 0) DESC) AS ranking FROM emp) AS tmpWHERE ranking <= 2;
每个部门中每个工资等级中薪资最高的员工信息。
SELECT * FROM (SELECT *, MAX(sal) OVER(PARTITION BY deptno, grade) AS max_salFROM emp AS e INNER JOIN salgrade AS sON e.sal BETWEEN s.lowsal AND s.hisal) AS tmpWHERE sal = max_sal;
03. 时间函数
3.1 获取当前时间
3.1.1 NOW获取当前时间与日期
NOW()函数用于获取当前时间与日期,格式为年-月-日 时:分:秒SELECT NOW(); -- 2022-11-09 20:22:22
3.1.2 CURDATE获取当前日期
CURDATE()函数用于获取当前日期,格式为年-月-日SELECT CURDATE(); -- 2022-11-09
3.1.3 CURTIME获取当前时间
CURTIME()函数用于获取当前时间,格式为时:分:秒SELECT CURTIME(); -- 20:22:22
3.2 提取时间的基本信息
3.2.1 YEAR获取年份
YEAR()函数用于从时间数据中提取出年份。SELECT YEAR('2022-11-09 20:22:22'); -- 2022
3.2.2 MONTH获取月份
MONTH()函数用于从时间数据中提取出月份。SELECT MONTH('2022-11-09 20:22:22'); -- 11
3.2.3 DAY获取日
DAY()函数用于从时间数据中提取出日期(号)。SELECT DAY('2022-11-09 20:22:22'); -- 9
3.2.4 DATE获取年月日(即日期)
若时间数据是
年-月-日 时:分:秒这种类型的,那么DATE(time)可以提取出年-月-日。SELECT DATE('2022-10-27 15:31:24'); -- 2022-10-27
3.2.5 HOUR获取小时
HOUR()函数用于从时间数据中提取出小时。SELECT HOUR('2022-11-09 20:22:22'); -- 20
3.2.6 MINUTE获取分钟
MINUTE()函数用于从时间数据中提取出分钟。SELECT MINUTE('2022-11-09 20:22:22'); -- 22
3.2.7 SECOND获取秒
SECOND()函数用于从时间数据中提取出秒钟。SELECT SECOND('2022-11-09 20:22:22'); -- 22
3.3 提取时间的隐藏信息
3.3.1 DAYOFWEEK获取星期
DAYOFWEEK()函数用于计算星期(即该天是该周的第几天)。DAYOFYEAR()函数用于计算该天是该年的第几天。SELECT DAYOFYEAR('2022-11-12 20:22:22'); -- 316
3.3.3 WEEK获取年的周数
WEEK(time)函数用于计算时间数据time是所在年的第几周(默认星期是从周日开始的)。SELECT WEEK('2022-10-27'); -- 43
WEEK(time, 1)则可以将星期一设置成起始值。SELECT WEEK('2022-10-27', 1); -- 43
-
3.3.4 QUARTER获取季度
QUARTER(time)函数用于获取时间数据time所处的季度。SELECT QUARTER('2022-10-27'); -- 4
3.4 时间戳处理
3.4.1 UNIX_TIMESTAMP获取时间戳
UNIX_TIMESTAMP()函数的基础用法是获取当前时间对应的时间戳。SELECT UNIX_TIMESTAMP(); -- 1667996542
UNIX_TIMESTAMP(time_data)则可用于获取指定时间数据time_data对应的时间戳。FROM_UNIXTIME(timestamp_data)函数用于将一个时间戳数据转换成时间数据,并且默认格式为年-月-日 时:分:秒。SELECT FROM_UNIXTIME(1649828585); -- 2022-04-13 13:43:05
FROM_UNIXTIME(timestamp_data, time_format)还可以以指定的时间格式time_format进行时间戳数据的转换。DATA_FORMAT(time_data, time_format)函数用于将时间数据格式化成指定形式。SELECT DATE_FORMAT(NOW(), '%Y年%m月%d日'); -- 2022年11月09日
3.5.2 STR_TO_DATA时间反格式化
STR_TO_DATA(time_str, time_format)函数用于将一个时间字符串反格式化成时间数据。SELECT STR_TO_DATE('2022年11月09日', '%Y年%m月%d日'); -- 2022-11-09
3.6 时间运算
3.6.1 DATEDIFF/TIMESTAMPDIFF时间差计算
DATEDIFF(time1, time2)函数用于计算两个时间数据所相差的天数。SELECT DATEDIFF('2022-10-15 14:23:11', '2020-01-01 12:24:30'); -- 1018
DATEDIFF只能用于计算两个时间相差的天数,若要获取其他的差值数据,可以使用TIMESTAMPDIFF(差值类型, 大时间, 小时间)函数。- 差值类型:YEAR年、MONTH月、DAY天数、HOUR小时、MINUTE分钟、SECOND秒、WEEK周、QUARTER季度。
SELECT TIMESTAMPDIFF(YEAR, '2021-01-01 12:22:23', '2022-11-09 20:22:22'); -- 1SELECT TIMESTAMPDIFF(MONTH, '2021-01-01 12:22:23', '2022-11-09 20:22:22'); -- 22SELECT TIMESTAMPDIFF(WEEK, '2021-01-01 12:22:23', '2022-11-09 20:22:22'); -- 96
3.6.2 DATE_ADD/DATE_SUB时间加减
- 差值类型:YEAR年、MONTH月、DAY天数、HOUR小时、MINUTE分钟、SECOND秒、WEEK周、QUARTER季度。
函数介绍:
DATE_ADD(已知时间, INTERVAL 时间差值 差值类型)函数可以在已知时间的基础上加上一个时间,得到另一个时间。DATE_SUB(已知时间, INTERVAL 时间差值 差值类型)函数可以在已知时间的基础上减去一个时间,得到另一个时间。
- 差值类型与函数示例:(差值类型详细说明:https://dev.mysql.com/doc/refman/8.0/en/expressions.html#temporal-intervals)
- 这两个函数基础的差值类型与
DATEDIFF函数一样,即:YEAR年、MONTH月、DAY天数、HOUR小时、MINUTE分钟、SECOND秒、WEEK周、QUARTER季度。 ```sql — 计算2022年11月3号 21:35:59这个时间一周后的时间。 SELECT DATE_ADD(‘2022-11-3 21:35:59’, INTERVAL 1 WEEK); — 2022-11-10 21:35:59
- 这两个函数基础的差值类型与
— 计算2022年11月3号 21:35:59这个时间三年前的时间。 SELECT DATE_SUB(‘2022-11-3 21:35:59’, INTERVAL 3 YEAR); — 2019-11-03 21:35:59
- 此外,这两个函数还有一些高级的组合差值类型:- YEAR_MONTH:差几年几月。时间差值数据格式为`Y-m`,如差五年三个月可写成`5-3`。```sql-- 计算2022年11月3号 21:35:59这个时间两年六个月之后的时间。SELECT DATE_ADD('2022-11-3 21:35:59', INTERVAL '2-6' YEAR_MONTH); -- 2025-05-03 21:35:59
- DAY_HOUR:差几天几小时。时间差值数据格式为`d H`,如差六天两小时可写成`6 2`。
-- 计算2022年11月3号 21:35:59这个时间一天两小时之前的时间。SELECT DATE_SUB('2022-11-3 21:35:59', INTERVAL '1 2' DAY_HOUR); -- 2022-11-02 19:35:59
- DAY_MINUTE:差几天几小时几分钟。时间差值数据格式为`d H:M`,如差三天五小时九分钟可写成`3 5:9`。
-- 计算2022年11月3号 21:35:59这个时间两天六分钟之后的时间。-- 这个例子中,小时数没有相差,因此H应该为0。SELECT DATE_ADD('2022-11-3 21:35:59', INTERVAL '2 0:6' DAY_MINUTE); -- 2022-11-05 21:41:59
- DAY_SECOND:差几天几小时几分钟几秒。时间差值数据格式为`d H:M:S`,如差三天五小时九分钟二十秒可写成`3 5:9:20`。
-- 计算2022年11月3号 21:35:59这个时间两天十小时二十七秒之前的时间。SELECT DATE_SUB('2022-11-3 21:35:59', INTERVAL '2 10:0:27' DAY_SECOND); -- 2022-11-01 11:35:32
- HOUR_MINUTE:差几小时几分钟。时间差值数据格式为`H:M`,如差一小时十五分可写成`1:15`。
-- 计算2022年11月3号 21:35:59这个时间四小时九分钟之后的时间。SELECT DATE_ADD('2022-11-3 21:35:59', INTERVAL '4:9' HOUR_MINUTE); -- 2022-11-04 01:44:59
- HOUR_SECOND:差几小时几分钟几秒。时间差值数据格式为`H:M:S`,如差一小时十五分十秒可写成`1:15:10`。
-- 计算2022年11月3号 21:35:59这个时间八小时三十五分二十六秒之前的时间。SELECT DATE_SUB('2022-11-3 21:35:59', INTERVAL '8:35:26' HOUR_SECOND); -- 2022-11-03 13:00:33
- MINUTE_SECOND:差几分钟几秒。时间差值数据格式为`M:S`,如差三十一分四十九秒可写成`31:49`。
-- 计算2022年11月3号 21:35:59这个时间十三分二十秒之后的时间。SELECT DATE_ADD('2022-11-3 21:35:59', INTERVAL '13:20' MINUTE_SECOND); -- 2022-11-03 21:49:19
3.7 时间函数例题
- 示例1:查询2000年出生的学生信息。 ```sql — 老方法,使用模糊查询 SELECT * FROM student WHERE birthday LIKE ‘2000%’;
— 新方法,使用时间函数 SELECT * FROM student WHERE YEAR(birthday) = 2000;
- 示例2:求所有学生的年龄。(年龄计算公式:)```sqlSELECTsno,sname,TIMESTAMPDIFF(YEAR, birthday, NOW()) + 1 AS ageFROM student;
示例3:查询本月过生日的学生信息。
SELECT * FROM studentWHERE MONTH(birthday) = MONTH(NOW());
示例4:查询当前季度过生日的学生信息。
SELECT * FROM studentWHERE QUARTER(birthday) = QUARTER(NOW());
示例5:查询本周过生日的学生信息。 ```sql — 两个不同年份的XX月XX日可能不是同一周,如2001年5月1号和2021年5月1号就不是同一周。 SELECT WEEK(‘2001-05-01’, 1); — 18 SELECT WEEK(‘2021-05-01’, 1); — 17
— 故直接使用WEEK操作数据可能出现错误。 SELECT * FROM student WHERE WEEK(birthday, 1) = WEEK(NOW(), 1);
— 故需要将学生生日中的年份替换成当前年份 SELECT sname, birthday, CONCAT_WS(‘-‘, YEAR(NOW()), SUBSTR(birthday, 6)) AS new_bir FROM student;
— 此时,对处理完的新生日数据再用WEEK函数进行计算,就可以得到准确的结果。 SELECT * FROM student WHERE WEEK(CONCAT_WS(‘-‘, YEAR(NOW()), SUBSTR(birthday, 6)), 1) = WEEK(NOW());
- 示例6:查询昨天过生日的学生信息。(不考虑年份的昨天就是:Month一样,Day相差一天)```sqlSELECT * FROM studentWHERE MONTH(birthday) = MONTH(NOW()) -- Month一样AND DAY(birthday) + 1 = DAY(NOW()); -- Day差一天
04. 分支函数
-
4.1 IF分支函数
IF函数的语法格式:
IF(条件表达式, 表达式1, 表达式2);当条件表达式为真时,执行表达式1,否则执行表达式2。示例1:根据学生的成绩进行分级。其中90及以上为A、80~89为B、70~79为C、60~69为D、60以下为E。
SELECT*,IF(score >= 90, 'A',IF(score >= 80, 'B',IF(score >= 70, 'C',IF(score >= 60, 'D', 'E')))) AS gradeFROM score_tb;
示例2:查询得到以下表:
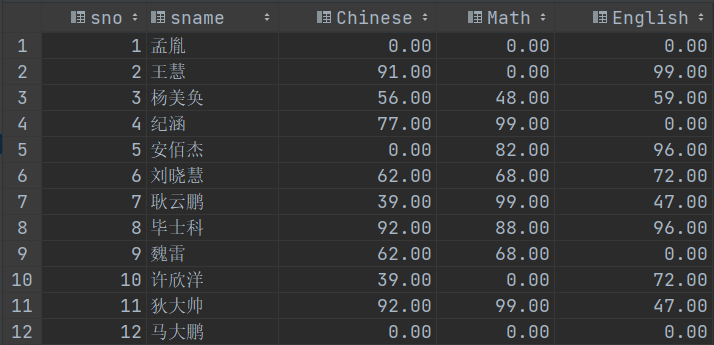
-- 首先,这张表用到了学生信息、课程名称、课程成绩等信息。-- 因此需要先用连接查询将这些基础数据查出来。(数据涉及student、score_tb、course三张表)SELECT * FROM student AS stuLEFT OUTER JOIN score_tb AS sco ON stu.sno = sco.snoLEFT OUTER JOIN course AS c ON sco.cid = c.cid;-- 接着,需要查询出三个成绩字段,并且过滤掉不需要的字段。SELECTstu.sno,stu.sname,IF(c.cname = '语文', score, 0) AS Chinese, -- 当课程名称为语文的时候,就显示原有成绩,否则显示0。IF(c.cname = '数学', score, 0) AS Math, -- 当课程名称为数学的时候,就显示原有成绩,否则显示0。IF(c.cname = '英语', score, 0) AS English -- 当课程名称为英语的时候,就显示原有成绩,否则显示0。FROM student AS stuLEFT OUTER JOIN score_tb AS sco ON stu.sno = sco.snoLEFT OUTER JOIN course AS c ON sco.cid = c.cid;-- 因为课程字段与cname不对应的数据都是0,只有对应的才是分数。-- 因此,将这些数据用SUM()函数加起来,实际上也还是原来那个成绩。-- 这样就可以过滤掉多余的行,SELECTstu.sno,stu.sname,SUM(IF(c.cname = '语文', score, 0)) AS Chinese,SUM(IF(c.cname = '数学', score, 0)) AS Math,SUM(IF(c.cname = '英语', score, 0)) AS EnglishFROM student AS stuLEFT OUTER JOIN score_tb AS sco ON stu.sno = sco.snoLEFT OUTER JOIN course AS c ON sco.cid = c.cidGROUP BY stu.sno;
4.2 CASE-WHEN分支
MySQL的
CASE-WHEN结构有两种格式:格式一:类似于Java中的switch-case,用来做等值判断。
CASE 表达式WHEN 值1 THEN 返回的值1或语句1;WHEN 值2 THEN 返回的值2或语句2;……WHEN 值n-1 THEN 返回的值n-1或语句n-1;ELSE 返回的值n或语句n;END
格式二:类似于Java中的多重if语句,用于实现区间判断。
CASEWHEN 要判断的条件1 THEN 返回的值1或语句1;WHEN 要判断的条件2 THEN 返回的值2或语句2;……WHEN 要判断的条件n-1 THEN 返回的值n-1或语句n-1;ELSE 返回的值n或语句n;END
示例1:用
CASE-WHEN结构,根据课程编号,找到与其对应的课程名称。SELECT*,CASE cidWHEN 10001 THEN '语文'WHEN 10002 THEN '数学'WHEN 10003 THEN '英语'ELSE '未匹配的课程编号'END AS 课程名称FROM score_tb;
示例2:用
CASE-WHEN结构给学生成绩分级。SELECT*,CASEWHEN score >= 90 THEN 'A'WHEN score >= 80 THEN 'B'WHEN score >= 70 THEN 'C'WHEN score >= 60 THEN 'D'ELSE 'E'END AS gradeFROM score_tb;

若有收获,就点个赞吧
0 人点赞
