- 01. 模块与包
- 定义一个模块,tools.py
- 在其他文件中使用这个默认。
- 方式一:使用
模块.内容的方式使用 - 方式二:直接使用导入的内容
- 方式三:使用all中的内容
- pack2.test1
- pack2.test2
- pack2.test1.py文件
- 02. 时间模块
- 获取年信息
- 获取月信息
- 获取其他信息同理
- 2.3 calender模块
- 03. math数学模块
- 导入方式一
- 从字符串”HelloWorld”随机获取一个字符
- 导入方式二
- 从1~100中随机获取一个数。
- 获取Base64编码数据
- Base64编码数据解码成字节数据。
- 分批次加密data
- 因为先将12合并到开头,得到deque([12, 56, 78, 90])
- 然后再将34合并到开头,得到deque([34, 12, 56, 78, 90])
- 09. os文件系统模块
- 尝试再次创建./test目录。
- D:\abc中还有def目录,因此不属于最有一级空目录。
01. 模块与包
1.1 模块的概念与导入方式
1.1.1 模块的概念
- 这部分内容实际上在02. Python基础语法 — 03. 流程控制结构 — 5.1 模块的概念中由提及过。
Python中所谓的模块就是一个Python文件,Python中的模块分为三种:
模块在使用时需要导入,导入方式有直接import和from两种。
import [包名.]模块名:使用这种方式导入时,使用模块下的内容需要用模块名.内容的形式。from [包名.]模块名 import 内容1, 内容2, …, 内容n:- 这种方式可以一次性导入一个模块中的多个内容,不同内容之间用逗号分割即可。
- 使用这种方式导入,可以直接使用模块中已经导入的内容。注意,这种方式同一个模块中未导入的内容不能使用。
from [包名.]模块名 import *可以导入指定模块下所有的内容。注意,若导入的模块中设置了__all__引入资源的列表,则这种方式导入时只能使用__all__中指定的内容。
- 示例:
```python
定义一个模块,tools.py
all = [“add”, “sub”]
MAX = 100
def add(a, b): return a + b
def sub(a, b): return a - b
在其他文件中使用这个默认。
方式一:使用模块.内容的方式使用
import tools
print(tools.MAX) # 100 print(tools.add(10, 20)) # 30 print(tools.sub(10, 20)) # -10
方式二:直接使用导入的内容
from tools import add, sub
print(add(10, 20)) # 30 print(sub(10, 20)) # -10 print(MAX) # NameError: name ‘MAX’ is not defined,MAX未导入,不能使用
方式三:使用all中的内容
from tools import *
print(add(10, 20)) # 30 print(sub(10, 20)) # -10 print(MAX) # NameError: name ‘MAX’ is not defined,MAX不在tools.py模块中的all中,不能直接使用
<a name="jjCvF"></a>### 1.2 第三方库管理工具pip<a name="FgAKQ"></a>#### 1.2.1 PyPi网站介绍- PyPi是Python官网提供的第三方库下载地址(类似于Maven官方仓库),在这里可以搜索到世界上所有公开的Python第三方库。- PyPi网站地址:[https://pypi.org/](https://pypi.org/)<a name="TZ0J2"></a>#### 1.2.2 pip工具介绍- pip是Python自带的一款第三方库管理工具,存在于Python安装目录中的Scripts目录中。- 其主要作用是完成第三方库的下载、安装、卸载、查看已安装模块等操作,并将按照好的第三方库提供给Python程序使用。- pip的默认下载地址就是PyPi,但由于其服务器在国外,因此建议国内开发者在使用pip下载安装时进行换源。- pip安装的第三方库,其物理路径为Python安装目录中的Lib\site-packages。<a name="ZzgCa"></a>#### 1.2.3 pip命令基础- pip工具是通过命令的形式执行的,命令可以通过Win + R >> CMD打开命令提示符后执行。- pip命令格式:`pip <command> [options]`- 常用的pip命令:- 查看pip帮助文档:`pip --help`或直接输入`pip`- 下载第三方模块但不安装(一般不用):`pip download 模块名`- 下载并安装第三方模块(常用):`pip install 模块名`- `pip install 模块名==版本号`可以实现指定版本安装。- 卸载当前系统中已经安装的指定模块:`pip uninstall 模块名`- 列出当前系统中所有已经安装的模块:`pip list`- 打包当前系统中已经安装的所有第三方库:`pip freeze > 文件路径`- 打包完成后,可以在其他电脑上使用`pip install -r 文件路径`将打包好的所有第三方库进行安装。- 对pip命令的相关内容进行设置:`pip config 设置内容`- 升级pip:`python -m pip install --upgrade pip`<a name="aDsry"></a>#### 1.2.4 pip换源- 国内常用的一些镜像地址:- 阿里云:[http://mirrors.aliyun.com/pypi/simple/](http://mirrors.aliyun.com/pypi/simple/)- 中国科技大学:[https://pypi.mirrors.ustc.edu.cn/simple/](https://pypi.mirrors.ustc.edu.cn/simple/)- 豆瓣(douban):[http://pypi.douban.com/simple/](http://pypi.douban.com/simple/)- 清华大学:[https://pypi.tuna.tsinghua.edu.cn/simple/](https://pypi.tuna.tsinghua.edu.cn/simple/)- 中国科学技术大学:[http://pypi.mirrors.ustc.edu.cn/simple/](http://pypi.mirrors.ustc.edu.cn/simple/)- 修改源方法(临时使用):在使用pip的时候在后面加上-i参数,并指定pip源,如安装scrapy库时:```pythonpip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
修改源方法(永久有效):
Linux:修改~/.pip/pip.conf(没有就创建一个), 内容如下:
[global]index-url = https://pypi.tuna.tsinghua.edu.cn/simple
Windows:
- 打开用户目录:Win + R输入%HOMEPATH%后回车。
- 创建pip.ini文件:在用户目录中创建pip目录,在pip目录中创建pip.ini文件。
- 永久配置镜像源:在pip.ini文件中写入以下配置信息:
[global]timeout = 6000index-url = https://pypi.tuna.tsinghua.edu.cn/simpletrusted-host = pypi.tuna.tsinghua.edu.cn
Linux和Windows都通用的方式:直接Win + R >> CMD(Linux打开Terminal),输入以下命令:
pip config set global.index-url https://pypi.douban.com/simple/
1.2.5 pip Error的解决方式
运行有些命令时会出现Error报错,如提示没有config等信息。
- 此时可以打开当前系统用户,创建一个名为pip的目录,然后在该目录下创建pip.ini文件,输入以下内容: ```python [global] index-url=https://pypi.tuna.tsinghua.edu.cn/simple/
[install] trusted-host=pypi.tuna.tsinghua.edu.cn
- 保存关闭后,重启CMD,再运行pip命令即可。<a name="GU4d2"></a>### 1.3 包的概念<a name="NcTz3"></a>#### 1.3.1 包的介绍与创建- 包(Package)是项目中一种特殊的文件目录,包的作用是:- 增加模块的命名空间:同一个物理路径下是不能存在两个完全相同的文件的,比如现在有两个demo.py文件,那么就可以通过创建包,将一个demo.py放到a包下,另一个放到b包下,形成`/a/demo.py`和`/b/demo.py`。- 对模块进行分类管理:把相同功能下创建Python模块文件分类到同一个包中,比如login包下的所有py文件都是为了实现登录功能而创建的。- 在PyCharm的目录中右键 >> New >> Python Package >> 输入包名即可创建一个包,然后会在包中自动创建一个`__init__.py`文件(包的初始化文件)。<a name="MiAWF"></a>#### 1.3.2 包中模块的导入方式- 如果使用的某个模块被某个Package包含着,导入时就需要从包开始定位,一直到模块。- 导入方式1:`import 外层包.内层包.模块`;使用:`包名.模块名.内容````python## pack1包下的test.py文件def mul(a, b):return a * bdef get_sum(*args, **kwargs):result = 0for ele in args + tuple(kwargs.values()):result += elereturn result## 在其他文件中调用import pack1.testprint(pack1.test.mul(12, 34)) # 408
- 导入方式2:
import 外层包.内层包.模块 as 别名;使用:别名.内容- 当Package的层级比较多时,使用方式1导入在使用时就很麻烦。
- 此时就可以在导入时给导入内容起别名,调用时也可以直接通过别名调用。 ```python import pack1.test as p1_test
print(p1_test.mul(12, 34)) # 408
- 导入方式3:`from 外层包.内层包.模块 import 内容`;使用:直接使用导入的内容。```pythonfrom pack1.test import mulprint(mul(12, 34)) # 408
1.3.3 包与普通目录的区别(init.py文件的作用)
- 在项目中创建一个普通的目录,也可以实现1.3.1与1.3.2中描述的内容,但是普通目录与包目录最大的区别就在于
__init__.py文件。 __init__.py表示着对包的初始化,当导入包时,默认就是导入__init__.py文件。__init__.py文件的优点在于它可以指定包下所有模块中对外开放的内容,引入包时这些开放的内容就会一次性全部被引入了。- 示例,创建包pack2,在包pack2中创建test1.py和test2.py两个文件。
```python
pack2.test1
def mul(a, b): return a * b
def get_sum(args, *kwargs): result = 0 for ele in args + tuple(kwargs.values()): result += ele return result
pack2.test2
def mod(a, b): return a % b
- 用以前的方法,可以将两个模块进行分别导入:```pythonimport pack2.test1 as pt1import pack2.test2 as pt2print(pt1.mul(12, 34))print(pt2.mod(12, 5))
但是在包中,可以将所有要公开的内容导入到包的
__init__.py文件中。## pack2.__init__.py文件。# .代表当前包from .test1 import *from .test2 import *
此时,只需要在需要使用的地方导入该包,然后就可以直接调用该包中所有开放的内容了。

1.4 模块名与main
1.4.1 name获取模块名操作
__name__可以获取模块的模块名。- 示例:在pack2.test1.py文件的第一行打印一下模块名。
```python
pack2.test1.py文件
print(f”test1的模块名:{name}”)
def mul(a, b): return a * b
def get_sum(args, *kwargs): result = 0 for ele in args + tuple(kwargs.values()): result += ele return result
- 接着,在外部调用该模块。```pythonimport pack2.test1"""运行结果:test1的模块名:pack2.test1"""
1.4.2 main模块
- 在任意文件中运行这行代码:
print(f"当前模块名:{__name__}"),得到的结果一定是当前模块名:__main__。 - 产生这种结果的原因:
- 一个项目的启动模块的模块名不再是原有的文件名,而是
__main__。 - 比如一个项目的启动文件是
start.py文件,但是在start.py模块中获取到的__name__一定是__main__。
- 一个项目的启动模块的模块名不再是原有的文件名,而是
通常,有以下代码的文件就是项目的启动文件:
time模块中以时间元组的形式封装时间信息。
时间元组中的数据属性解析:
time.localtime()可以获取当前系统时间。 ```python import time
current_time = time.localtime() print(current_time) # time.struct_time(tm_year=2022, tm_mon=9, tm_mday=16, tm_hour=20, tm_min=13, tm_sec=29, tm_wday=4, tm_yday=259, tm_isdst=0)
- 此外,`time.localtime(timestamp)`还可以获取指定时间戳的时间元组。```pythonimport timetimestamp = 1656389792get_time = time.localtime(timestamp)print(get_time) # time.struct_time(tm_year=2022, tm_mon=6, tm_mday=28, tm_hour=12, tm_min=16, tm_sec=32, tm_wday=1, tm_yday=179, tm_isdst=0)
- 接着,可以通过
时间对象[属性索引]和时间对象.属性两种方式来获取时间对象中具体的时间信息。 ```python import time
current_time = time.localtime()
获取年信息
print(current_time[0]) # 2022 print(current_time.tm_year) # 2022
获取月信息
print(current_time[1]) # 9 print(current_time.tm_mon) # 9
获取其他信息同理
<a name="P7U3h"></a>#### 2.1.3 time()获取当前时间(时间戳形式)- 时间戳是指定时间到1970年1月1日00:00:00这个时间点所经历的秒数。- `time.time()`可以获取到当前时间的时间戳。```pythonimport timetimestamp = time.time()print(timestamp) # 1663312120.2858465
2.1.4 mktime()时间元组转换为时间戳
time.mktime(时间元组)可以将指定的时间元组转换成对应的时间戳。 ```python import time
current_time = time.localtime() timestamp1 = time.mktime(current_time) print(timestamp1) # 1663330904.0 print(time.time()) # 1663330904.3545728
- 可以发现,这种方式得到的`timestamp1`小数部分始终为0,因此在精度上不如`time.time()`<a name="m77pF"></a>#### 2.1.5 strftime()时间格式化- `time.strftime(要显示的时间格式字符串, 时间元组对象)`可以将指定的时间元组对象按照指定的时间格式进行转换,最后得到的是一个时间字符串。```pythonimport timecurrent_time = time.localtime()format_time1 = time.strftime("%Y-%m-%d %H:%M:%S", current_time)print(format_time1) # 2022-09-16 21:53:15format_time2 = time.strftime("%Y年%m月%d日 (%p)%I点%M分%S秒", current_time)print(format_time2) # 2022年09月16日 (PM)09点53分15秒
时间格式符:https://wenku.baidu.com/view/e40fa6538bd63186bdebbc64.html
time.strptime(按照指定格式显示的时间字符串, 解析时间的格式化字符串)可以将一个时间字符串转换成对应的时间元组。 ```python import time
time_obj = time.strptime(“2022-09-16 21:53:15”, “%Y-%m-%d %H:%M:%S”) print(time_obj) # time.struct_time(tm_year=2022, tm_mon=9, tm_mday=16, tm_hour=21, tm_min=53, tm_sec=15, tm_wday=4, tm_yday=259, tm_isdst=-1)
- 注意:时间字符串和格式化字符串在格式化上一定要匹配,否则会因为解析失败而报错。```pythonimport timetime_obj = time.strptime("2022-09-16 21:53:15", "%Y年%m月%d日 (%p)%I点%M分%S秒")print(time_obj)"""运行结果:ValueError: time data '2022-09-16 21:53:15' does not match format '%Y年%m月%d日 (%p)%I点%M分%S秒'"""
2.1.7 sleep()休眠
time.sleep(num)可以让程序停止num秒后再继续运行。 ```python import time
start_time1 = time.time() sum1 = 0 for i in range(1, 10): sum1 += i end_time1 = time.time() print(f”程序1运行时间:{end_time1 - start_time1}秒”) # 程序1运行时间:0.0秒
start_time2 = time.time() sum2 = 0 for i in range(1, 10): sum2 += i time.sleep(2) end_time2 = time.time() print(f”程序2运行时间:{end_time2 - start_time2}秒”) # 程序2运行时间:18.07093906402588秒
<a name="sOHjY"></a>### 2.2 dateatime模块<a name="indQB"></a>#### 2.2.1 datatime模块介绍- datetime模块有以下四个重点类:- date类:记录年月日。- time类:记录时分秒。(不做介绍)- datetime类:记录年月日、时分秒。- timedelta类:用于处理两个时间点的差值。<a name="arXiW"></a>#### 2.2.2 now()获取当前时间- `datetime`类中的`now()`可用于获取当前时间,当前时间是一个datetime类型的数据。```pythonfrom datetime import datetimecurrent_time = datetime.now()print(current_time) # 2022-09-19 11:14:15.353457print(type(current_time)) # <class 'datetime.datetime'>
2.2.3 date()获取年月日
datetime对象.date()可以从datetime对象中获取年月日的信息,年月日的信息是一个date类型的数据。 ```python from datetime import datetime
current_time = datetime.now()
current_day = current_time.date()
print(current_day) # 2022-09-19
print(type(current_day)) #
<a name="y0eUP"></a>#### 2.2.4 查看年、月、日、时、分、秒- 用`datetime对象.year`这样的形式可以获取一个datetime对象的年、月、日、时、分、秒等数据。```pythonfrom datetime import datetimecurrent_time = datetime.now()print(current_time) # 2022-09-20 14:36:29.527696print(current_time.year) # 2022print(current_time.month) # 9print(current_time.day) # 20print(current_time.hour) # 14print(current_time.minute) # 36print(current_time.second) # 29
2.2.5 datetime()构建时间对象
datetime(时间数据)可以构建一个时间对象。- 年:传值范围需要在1~9999之间。
- 月:传值范围需要在1~12之间。
- 日:传值范围需要在月份对应的日期范围之间。
- hour、minute、second三个参数可以不传值,默认为0。 ```python from datetime import datetime
datetime_obj1 = datetime(2022, 10, 11) print(datetime_obj1) # 2022-10-11 00:00:00
datetime_obj2 = datetime(2022, 10, 11, 13, 25, 31) print(datetime_obj2) # 2022-10-11 13:25:31
<a name="zboUR"></a>#### 2.2.6 timestamp()通过时间对象获取时间戳- `时间对象.timestamp()`可以获取指定时间对象对应的时间戳。```pythonfrom datetime import datetimedatetime_obj = datetime(2022, 10, 11, 13, 25, 31)print(datetime_obj.timestamp()) # 1665465931.0
2.2.7 fromtimestamp()通过时间戳获取时间对象
datetime.fromtimestamp(时间戳)可以获取指定时间戳对应的时间对象。 ```python from datetime import datetime
datetime_obj = datetime.fromtimestamp(1665465931.0)
print(datetime_obj) # 2022-10-11 13:25:31
print(type(datetime_obj)) #
<a name="JtMvZ"></a>#### 2.2.8 strftime()时间格式化- `时间对象.strftime(时间格式化字符串)`可以将时间对象格式化成指定的格式时间字符串。```pythonfrom datetime import datetimedatetime_obj = datetime(2022, 10, 11, 13, 25, 31)print(datetime_obj) # 2022-10-11 13:25:31print(datetime_obj.strftime("%Y年%m月%d日%H时%M分%S秒")) # 2022年10月11日13时25分31秒
2.2.9 strptime()反格式化
datetime.strptime(时间字符串, 时间格式)可以将一个时间字符串解析成一个时间对象。 ```python from datetime import datetime
datetime_obj = datetime.strptime(“2022/01/19 pm 05:17:29”, “%Y/%m/%d %p %I:%M:%S”)
print(datetime_obj) # 2022-01-19 17:17:29
print(type(datetime_obj)) #
<a name="Cp0LW"></a>#### 2.2.10 时间差- `date2 - date1`两个时间对象相减即可获取时间差,得到的结果是一个timedelta时间差值对象。```pythonfrom datetime import datetimedate1 = datetime(2021, 12, 15, 17, 24, 32)date2 = datetime(2022, 9, 20, 15, 35, 25)date_diff = date2 - date1print(date_diff) # 278 days, 22:10:53print(type(date_diff)) # <class 'datetime.timedelta'>
- 然后可以通过
时间差值对象.days获取两个时间相差的天数;通过时间差值对象.seconds可以获取除去天数之外对应的秒数。(无法获取时分秒);通过时间差值对象.total_seconds()可以获取包含天数在内对应的秒数。 ```python from datetime import datetime
date1 = datetime(2021, 12, 15, 17, 24, 32) date2 = datetime(2022, 9, 20, 15, 35, 25) date_diff = date2 - date1 print(date_diff) # 278 days, 22:10:53 print(date_diff.days) # 278 print(date_diff.seconds) # 79853 print(date_diff.total_seconds()) # 24099053.0
<a name="LAwFG"></a>#### 2.2.11 时间加运算(多久后(前)的时间)- 时间对象加上(减去)一个时间差值对象,即可得到指定时间对象之后(之间)的时间。- 示例1:计算当前时间3天后的时间。```pythonfrom datetime import datetimefrom datetime import timedeltaafter_tree = datetime.now() + timedelta(days=3)print(after_tree) # 2022-09-23 16:31:50.615103
- 示例2:计算当前时间一周前的时间。 ```python from datetime import datetime from datetime import timedelta
after_week = datetime.now() - timedelta(weeks=1) print(after_week) # 2022-09-13 16:37:11.240852
- 示例3:计算当前时间17天后的时间。(17天等于两周加三天)```pythonfrom datetime import datetimefrom datetime import timedeltaafter_week = datetime.now() + timedelta(weeks=2, days=3)print(after_week) # 2022-09-27 16:32:29.930922
timedelta()中可传入的参数:-
2.3.1 calendar()查看指定年的日历
calendar.calendar(year)可以查看指定年的日历。 ```python import calendar
print(calendar.calendar(2022)) “”” 运行结果: 2022
January February March
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su 1 2 1 2 3 4 5 6 1 2 3 4 5 6 3 4 5 6 7 8 9 7 8 9 10 11 12 13 7 8 9 10 11 12 13 10 11 12 13 14 15 16 14 15 16 17 18 19 20 14 15 16 17 18 19 20 17 18 19 20 21 22 23 21 22 23 24 25 26 27 21 22 23 24 25 26 27 24 25 26 27 28 29 30 28 28 29 30 31 31
April May June
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su 1 2 3 1 1 2 3 4 5 4 5 6 7 8 9 10 2 3 4 5 6 7 8 6 7 8 9 10 11 12 11 12 13 14 15 16 17 9 10 11 12 13 14 15 13 14 15 16 17 18 19 18 19 20 21 22 23 24 16 17 18 19 20 21 22 20 21 22 23 24 25 26 25 26 27 28 29 30 23 24 25 26 27 28 29 27 28 29 30 30 31
July August September
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su 1 2 3 1 2 3 4 5 6 7 1 2 3 4 4 5 6 7 8 9 10 8 9 10 11 12 13 14 5 6 7 8 9 10 11 11 12 13 14 15 16 17 15 16 17 18 19 20 21 12 13 14 15 16 17 18 18 19 20 21 22 23 24 22 23 24 25 26 27 28 19 20 21 22 23 24 25 25 26 27 28 29 30 31 29 30 31 26 27 28 29 30
October November December
Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su 1 2 1 2 3 4 5 6 1 2 3 4 3 4 5 6 7 8 9 7 8 9 10 11 12 13 5 6 7 8 9 10 11 10 11 12 13 14 15 16 14 15 16 17 18 19 20 12 13 14 15 16 17 18 17 18 19 20 21 22 23 21 22 23 24 25 26 27 19 20 21 22 23 24 25 24 25 26 27 28 29 30 28 29 30 26 27 28 29 30 31 31 “””
<a name="K5pOB"></a>#### 2.3.2 month()查看指定月的日历- `calendar.month(year, month)`可以查看指定年中指定月的日历。```pythonimport calendarprint(calendar.month(2022, 6))"""运行结果:June 2022Mo Tu We Th Fr Sa Su1 2 3 4 56 7 8 9 10 11 1213 14 15 16 17 18 1920 21 22 23 24 25 2627 28 29 30"""
2.3.3 isleap()判断是否为闰年
calendar.isleap(year)可以判断指定年份是否是闰年。 ```python import calendar
print(calendar.isleap(2022)) # False print(calendar.isleap(2000)) # True
<a name="GFN2N"></a>#### 2.3.4 leapdays()计算两年间闰年的个数- `calendar.leapdays(start_year, end_year)`可以计算两个指定的年份之间,有多少个闰年。```pythonimport calendarprint(calendar.leapdays(1900, 2022)) # 30,查看两年之间,闰年的个数
03. math数学模块
3.1 math模块介绍
- math数学模块中封装了一些常用的数学计算操作。
-
3.2 math模块中的常用操作
3.2.1 fabs()求绝对值
math.fabs(num)可以求数字num的绝对值,即 ```python
import math
```python
import math
num = -3.27 print(f”{num}的绝对值:{math.fabs(num)}”) # -3.27的绝对值:3.27
<a name="PvqNF"></a>#### 3.2.2 floor()向下取整- `math.floor(num)`的返回值是比num小,但是最接近num的整数。即向下取整。```pythonimport mathnum1, num2 = -2.7, 3.2print(f"{num1}向下取整为:{math.floor(num1)}") # -2.7向下取值为:-3print(f"{num2}向下取整为:{math.floor(num2)}") # 3.2向下取值为:3
3.2.3 ceil()向上取整
math.ceil(num)的返回值是比num大,但是最接近num的整数。即向上取整。 ```python import math
num1, num2 = -2.7, 3.2 print(f”{num1}向上取整为:{math.ceil(num1)}”) # -2.7向上取值为:-2 print(f”{num2}向上取整为:{math.ceil(num2)}”) # 3.2向上取值为:4
<a name="ixJif"></a>#### 3.2.4 pi圆周率- 通过`math.pi`可以查看圆周率。```pythonimport mathprint(math.pi) # 3.141592653589793
3.2.5 e欧拉数
- 通过
math.e可以查看欧拉数。 ```python import math
print(math.e) # 2.718281828459045
<a name="JesUv"></a>#### 3.2.6 fmod()取模- `math.fmod(num1, num2)`用于对两数取模,结果是一个浮点数,即等价于`float(num1 % num2)`。```pythonimport mathprint(float(10 % 4)) # 2.0print(math.fmod(10, 4)) # 2.0
3.2.7 fsum()求和
sum(序列)可以对一个序列中所有元素进行求和运算,但当这个序列中有浮点型数据时,这种求和方式可能出现精度问题。 ```python import math
data = [0.1] * 10 print(sum(data)) # 0.9999999999999999
- 但是通过`math.fsum(序列)`的方式可以解决这种精度问题。```pythonimport mathdata = [0.1] * 10print(math.fsum(data)) # 1.0
3.2.8 pow()幂函数
math.pow(a, b)用于求a的b次幂,即 。
```python
import math
。
```python
import math
print(math.pow(2, 3)) # 8.0 print(math.pow(10, 2)) # 100.0
<a name="GB973"></a>#### 3.2.9 log()指数函数- `math.log(N)`用于求以e为底N的对数,即,亦可简写为。```pythonimport mathprint(math.log(100)) # 4.605170185988092print(math.log(math.e ** 3)) # 3.0
math.log(N, a)用于求以a为底N的对数,即 。
```python
import math
。
```python
import math
print(math.log(100, 10)) # 2.0 print(math.log(32, 2)) # 5.0
- 除此之外,math模块还提供了`log2()`以2为底、`log10()`以10为底、`log1p()`以e为底三个函数。<a name="k7etJ"></a>#### 3.2.10 sin()/cos()/tan()三角函数- `sin(x)`正弦函数、`cos(x)`余弦函数、`tan(x)`正切函数。```pythonimport mathprint(math.sin(math.pi / 2)) # 1.0print(math.cos(0)) # 1.0print(math.tan(math.pi / 4)) # 0.9999999999999999
3.2.11 factorial()求阶乘
math.factorial(n)用于求n的阶乘,即 。
```python
import math
。
```python
import math
print(math.factorial(5)) # 5 print(1 2 3 4 5) # 5
<a name="Oz9UP"></a>#### 3.2.12 gcd()求最大公约数- `math.gcd(data)`用于求多个数据的最大公约数,data可以是两个及以上的数据,数据之间用逗号分割。```pythonimport mathprint(math.gcd(12, 36)) # 12print(math.gcd(12, 36, 8)) # 4
3.2.13 sqrt()平方根
math.sqrt(n)用于对n开平方,即 。
```python
import math
。
```python
import math
print(math.sqrt(16)) # 4.0 print(math.sqrt(36)) # 6.0
<a name="O8AM3"></a>## 04. random随机模块<a name="LIICR"></a>### 4.1 随机模块介绍- random模块通过随机算法获取一些随机信息。- 随机算法简介:- 随机算法以随机种子为起源,将随机种子套入随机算法进行一定的算法运算,最后获得随机数。- 因为随机算法是固定的,因此只要随机种子一样,随机得到的结果也就一样。```pythonimport randomrandom.seed(10) # 将随机种子设置为10print(random.random()) # 0.5714025946899135random.seed(10)print(random.random()) # 0.5714025946899135# 可以发现两次获取到的随机数是一样的。# 并且在不同设备、不同时段上、不同Python解释器上运行的结果都是一样的。# 即不管在哪里,只要将随机种子设置为10,random.random()的结果一定是0.5714025946899135
-
4.2 random模块中的常用操作
4.2.1 choice()随机选择一个元素
choice(容器序列)可以随机抽取容器内的其中一个并返回。 ```python导入方式一
import random
从字符串”HelloWorld”随机获取一个字符
ch = random.choice(“HelloWorld”) print(ch)
导入方式二
from random import choice
从1~100中随机获取一个数。
num = choice(range(1, 101)) print(num)
<a name="woVpV"></a>#### 4.2.2 choices()随机选择多个元素- `choices(容器序列, k=num)`可以随机抽取容器中的num个序列,并封装成列表返回。(列表中的元素可能会重复)```pythonimport randomchs = random.choices("1234567890qwertyuiopasdfghjklzxcvbnm", k=5)print(chs) # ['9', 's', 'k', '0', 'k']
- k的默认值为1,即不手动指定k,会随机返回1个元素,但是也是个列表。 ```python import random
chs = random.choices(“1234567890qwertyuiopasdfghjklzxcvbnm”) print(chs) # [‘e’]
<a name="gGnqF"></a>#### 4.2.3 sample()随机选择多个元素- `sample(容器序列, k=num)`可以随机抽取容器中的num个序列,并封装成列表返回。- 与`choices()`最大的区别在于,列表中的元素不会重复。```pythonimport randomchs = random.sample("1234567890qwertyuiopasdfghjklzxcvbnm", k=5)print(chs) # ['f', 'e', '1', 'u', 'n']
4.2.4 random()随机小数
random()函数:在[0, 1)中随机返回一个小数。
import randomnum = random.random()print(num)
4.2.5 randint()随机整数
randint()函数:在[start, end]中随机返回一个整数。(注意:这是唯一一个将结束位置元素包含在内的函数)
import randomnum = random.randint(10, 20)print(num)
4.2.6 shuffle()洗牌序列
shuffle(序列)可以打乱一个序列的顺序,类似于洗牌。 ```python import random
nums = [29, 33, 56, 71, 28, 41] random.shuffle(nums) print(nums) # [41, 28, 33, 71, 56, 29]
<a name="qQGSJ"></a>## 05. Base64模块<a name="T4yM5"></a>### 5.1 Base64介绍- base64是一种编码方式,是网络上传输字节码数据的一种编码形式。- base64编码常用于网络中图片的传递。- 一般来说会先对图片的字节数据进行编码,编码之后的数据具有不可读性,需要先进行解码,才能显示数据原本的含义。- 如:千峰学员辅学系统的验证码图片就是以Base64编码传输的。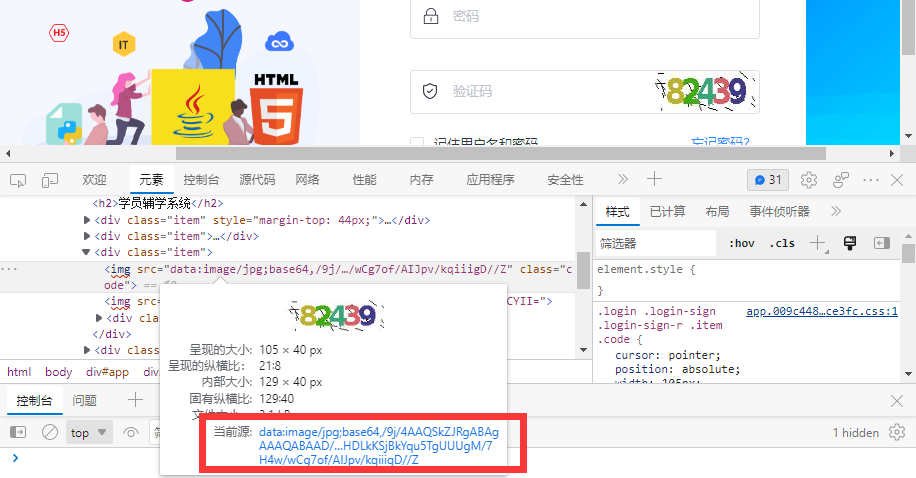- Python中使用base64模块来操作Base64编码的数据。<a name="goKlV"></a>### 5.2 Base64编码/解码<a name="VLiC7"></a>#### 5.2.1 b64decode()解码- 获取千峰学员辅学系统的验证码图片的Base64编码:> data:image/jpg;base64,/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAoAIEDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+se+0a/u7ySeHxNqtlG2MQQR2pRMADgvCzc9eSevpxWhfTXFvZyS2tr9qmTBEIkCFxkbgpPG7GcAkAnAJUHcPPzr+t6Jpg8TQ6foaaBf+TKyHVpVRXnkQLOC1svlqfM3SAjn72A2/eAeiQRtDbxRPNJO6IFaWQKGcgfeO0AZPXgAegFMmvbW2cJPcwxMRkK8gU49eaybu91aHw5dz39raWl0DtRbW6eddpIG7cUjIbk8Y7A57VzOj6PJrk1wzXOzZgs7DczE59/Y85rz8VjJ06saNON5PX+vuNIwTV2zvYLq3ud32eeKXb97y3DY+uKdPcQ2sLTXE0cMS43PIwVR25JrzzU7CbQtRWOO5JbYHSRMqcHI/Doe9Zk/hbxBrs13qxgBEkhkVXkw8qZPEYJxkKPlDFQfl+YDkYwzGrKTp+z99een9f1cxxDlTScFe56dBq+mXUyw2+o2k0rZ2pHOrMe/ABq5Xj2p+FBbeHrbXdPv1vrCeNJQ/lGIhHAKNgnPORxwRkcdcdD4F8V2sdoNK1TUraGbzFjsluLhVeUNwI0BwWwcdM/eA9K2o4ybq+xrRs2c1PESdT2dSNmd1c3dtZxiS6uIoEJ2hpXCgn0yfpUdtqVheSGO1vbadwNxWKVWIHrgH3rzTxBqE/izVpxZFTZWMEkqFht+QAFm9TkgAD6cDmo/BVs95e6naxlQ82nSxqW6AkqBn867rmcMZz11TS91u1z0TUfEujaVbzTXWoRYhO144syyA5xjYgLHnrgcc56VZ07VLHVrdZ7G5SZGRXwOGUMMjcp5U+xAPBrzyfwS9le20V9frFb3AVEuVi3Is5OPLbkbd2QEboxyp2sUD5Wr6Zd+GNWWJbrEuzzI5YWKnaSV/A8Hjnr1rN1JR1aPo6eDw9V8tOpd+h7DLLHBC800iRxRqWd3YBVUckknoKxrjWPDGsw/2fJq+m3AnZVWOO8TeXyCpQq24OGAKleQQCMECvFPF/ijU/Gmt22mQ5EKukMNsuEDzkBWY5J/iJAJPC+hJzp658I7/R/D0upRajFdTW8fmzwCPYFUDLlWJ+bHuBkZ78H0o4aCiueVmzy5JptHqn2698PfJqsk9/pv3jqrLGrW47/aFXaNoOMSIuAud4UIXbcmnhtkDzyxxIXVAzsFBZmCqOe5YgAdyQK8p+EnjC6upj4cv5UkjjhL2kkj4cBcfux/eGCSO4CntjHq08EN1by29xFHNBKhSSORQyupGCCDwQRxiuerSdOXKwJKK5//AIQ3S/8An61z/wAHt7/8eorMDoKx9TsdGsfD2si+j8vSpop5r5Qz7djIfNIC8rkbmOzGWLN95iTsUUAcf4bmg0vwSbbUZZZJLZjZ3Vv8q+XKAFdYlG0rG3MqA4xHIu0Ku1VyLG0v7md5NJiuY1xjcJcemQW4B7HFb934Yg0/wnBpumRk/ZEiGdo8yfy4xECxAGW2KvOP4QAOlY+jeIZNIheH7OssTMX+9tbPA688celeFmMovExjWfLG263N6fw6bkEsEtpqKtrVvcyBiMnzOWxj+LndxxgEfUV3cWqWUkMUhuYk82Fp1V5FDbFxvOM9FLKCegJGetcPq2rza3PCogCBCRGi5ZiTjj35HpXKa7f3dw8emXIVYtPlcJGOcSZYFifXlhnsCfU558Ni4Yac+T3ovZ9b+b+8wxlZUYKUty5rmusG1HS9Luo5dFubj7Uim3Kujud8i7iSWUyEvyAQWIHygCo7e+GleHZ7SGZTd6gR9oVXO6GIDKAjHBcMT1PyFTj5s1mWVxbW4lM0MrysAIpI2j/d88nbJG6tkccg4ye+COlhkXx3qkAvrqOwvFt0hXZCzJO43M23JwpxkhCScKxGQrEdGDqKtX9pUl73RaniOU615J+89EvI37VNG0bwdfWkepafLeS20nmvHMpMjlTgDnJxnA/PHJrA8A3dtZ67PJdXEUCG2ZQ0rhQTuXjJ+lXr/wCHn2LTrm7/ALU3+RE0m37PjdtBOM7vauSsrF7yO7ZNxNvB5xVVzuG5VP0wGJz7V7TdtSlGs69KnypPZanfeL9M1rWbhRpm+fTZ7UJIiXCiOUMWyCpbDAqR7EVxssV1o2to+rWfnSq4lkinbIlB5zuB5+vIyOc8iuh034gPY6bbWj6aspgjEYdZtuQBgcbT2x3rI1vW73xTfwrHasAgIht4gXbpljkDJ6fgB9ScJuL1T1PusHDEQXJVglG2/X8/8jkPGMbaT4vj1zTpXEV9IdQtJJFyVkD5dSCMEq/bkYK5JzW5q/xX1PX9EOj2mlJDd3aiCWSNzIZAwwyom3gtnA5JAPrgjU8Q69e+CxpmjajpVtqekz2ayTW9zENvnCR2IVuQSpMechvugjGc1xE/i5bbV9S1HQNMi0mW/gELNHKzGFcKGEQG1FB2Kc7CwJY7uQF96lzVIRc4Xfe54FVRU5KD0voWPhh/yUXSv+23/op6+jK8q+EnhXUdLvL7VNTsbm0LwLFbiXC7wWJfKfeBBRMZA4bjPb0XWLW8urNG0+48m8glSaLc5VJNp+aN8Z+V1LLkhtu4MAWUVy4yalU06EI0KK5//hIdU/6EzXP+/wBZf/JFFcozoKp6nqUOlWqXE6yMj3EFuAgBO6WVYlPJHG5wT7Z69KKKALlQTWVrcuHntoZWAwGeMMcenNFFJxUlZoBYLW3tt32eCKLd97y0C5+uKy9a8Mafq2lajbR29tbXV3BJGt4tupeJ3UgSA8EkE56g5HWiilyRtawmk9xYfC2jQ3lzcCwt2WfaTC8KMiMBglcjK5G3IB2/LkAEsWyPE+h6dZ/YdTS2+y2lvL5d81k7WsiwSYG/zIirBUcIzZYJsDsQWVCCikqcU7pCUYrVI1oNEl0+O5Ftf3l7A0DJFp+oTiSLceeZWRpjk5HzM4AY4XAAGHpjW3h62sYr3w1q9q9lGsP2+CMXf2hwm07vs5MkgblsyRqMgEhW2iiirG0m7m/af8I/4gSS9t4bG8YP5czNCpkjcAZSQEbkcAjKsAR0IFLdm40eOP8AsnQ4rm2JZp4raVIZc8BSisAje+50wBxuPFFFKyLc5NWb0K8euaFrTjR74RR3k33tK1FAkrlfmOI24kUFT86bkJU4Y4zV218P6LY3KXNppGn286Z2yxWyIy5GDggZHBIooqlJpWJNGs/U9Ht9U8qR3nt7qDPkXVtKY5IycZ5HDLkKSjBkYqu5TgUUUgM/7H4w/wCg7of/AIJpv/kqiiigD//Z- 这段数据的格式为:`数据类型标识,Base64编码数据`。- 因此首先要对这段数据文本进行切片(根据逗号`,`切一次),然后获取Base64编码数据(切片后的最后一个数据)```pythondata = 'data:image/jpg;base64,/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAoAIEDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+se+0a/u7ySeHxNqtlG2MQQR2pRMADgvCzc9eSevpxWhfTXFvZyS2tr9qmTBEIkCFxkbgpPG7GcAkAnAJUHcPPzr+t6Jpg8TQ6foaaBf+TKyHVpVRXnkQLOC1svlqfM3SAjn72A2/eAeiQRtDbxRPNJO6IFaWQKGcgfeO0AZPXgAegFMmvbW2cJPcwxMRkK8gU49eaybu91aHw5dz39raWl0DtRbW6eddpIG7cUjIbk8Y7A57VzOj6PJrk1wzXOzZgs7DczE59/Y85rz8VjJ06saNON5PX+vuNIwTV2zvYLq3ud32eeKXb97y3DY+uKdPcQ2sLTXE0cMS43PIwVR25JrzzU7CbQtRWOO5JbYHSRMqcHI/Doe9Zk/hbxBrs13qxgBEkhkVXkw8qZPEYJxkKPlDFQfl+YDkYwzGrKTp+z99een9f1cxxDlTScFe56dBq+mXUyw2+o2k0rZ2pHOrMe/ABq5Xj2p+FBbeHrbXdPv1vrCeNJQ/lGIhHAKNgnPORxwRkcdcdD4F8V2sdoNK1TUraGbzFjsluLhVeUNwI0BwWwcdM/eA9K2o4ybq+xrRs2c1PESdT2dSNmd1c3dtZxiS6uIoEJ2hpXCgn0yfpUdtqVheSGO1vbadwNxWKVWIHrgH3rzTxBqE/izVpxZFTZWMEkqFht+QAFm9TkgAD6cDmo/BVs95e6naxlQ82nSxqW6AkqBn867rmcMZz11TS91u1z0TUfEujaVbzTXWoRYhO144syyA5xjYgLHnrgcc56VZ07VLHVrdZ7G5SZGRXwOGUMMjcp5U+xAPBrzyfwS9le20V9frFb3AVEuVi3Is5OPLbkbd2QEboxyp2sUD5Wr6Zd+GNWWJbrEuzzI5YWKnaSV/A8Hjnr1rN1JR1aPo6eDw9V8tOpd+h7DLLHBC800iRxRqWd3YBVUckknoKxrjWPDGsw/2fJq+m3AnZVWOO8TeXyCpQq24OGAKleQQCMECvFPF/ijU/Gmt22mQ5EKukMNsuEDzkBWY5J/iJAJPC+hJzp658I7/R/D0upRajFdTW8fmzwCPYFUDLlWJ+bHuBkZ78H0o4aCiueVmzy5JptHqn2698PfJqsk9/pv3jqrLGrW47/aFXaNoOMSIuAud4UIXbcmnhtkDzyxxIXVAzsFBZmCqOe5YgAdyQK8p+EnjC6upj4cv5UkjjhL2kkj4cBcfux/eGCSO4CntjHq08EN1by29xFHNBKhSSORQyupGCCDwQRxiuerSdOXKwJKK5//AIQ3S/8An61z/wAHt7/8eorMDoKx9TsdGsfD2si+j8vSpop5r5Qz7djIfNIC8rkbmOzGWLN95iTsUUAcf4bmg0vwSbbUZZZJLZjZ3Vv8q+XKAFdYlG0rG3MqA4xHIu0Ku1VyLG0v7md5NJiuY1xjcJcemQW4B7HFb934Yg0/wnBpumRk/ZEiGdo8yfy4xECxAGW2KvOP4QAOlY+jeIZNIheH7OssTMX+9tbPA688celeFmMovExjWfLG263N6fw6bkEsEtpqKtrVvcyBiMnzOWxj+LndxxgEfUV3cWqWUkMUhuYk82Fp1V5FDbFxvOM9FLKCegJGetcPq2rza3PCogCBCRGi5ZiTjj35HpXKa7f3dw8emXIVYtPlcJGOcSZYFifXlhnsCfU558Ni4Yac+T3ovZ9b+b+8wxlZUYKUty5rmusG1HS9Luo5dFubj7Uim3Kujud8i7iSWUyEvyAQWIHygCo7e+GleHZ7SGZTd6gR9oVXO6GIDKAjHBcMT1PyFTj5s1mWVxbW4lM0MrysAIpI2j/d88nbJG6tkccg4ye+COlhkXx3qkAvrqOwvFt0hXZCzJO43M23JwpxkhCScKxGQrEdGDqKtX9pUl73RaniOU615J+89EvI37VNG0bwdfWkepafLeS20nmvHMpMjlTgDnJxnA/PHJrA8A3dtZ67PJdXEUCG2ZQ0rhQTuXjJ+lXr/wCHn2LTrm7/ALU3+RE0m37PjdtBOM7vauSsrF7yO7ZNxNvB5xVVzuG5VP0wGJz7V7TdtSlGs69KnypPZanfeL9M1rWbhRpm+fTZ7UJIiXCiOUMWyCpbDAqR7EVxssV1o2to+rWfnSq4lkinbIlB5zuB5+vIyOc8iuh034gPY6bbWj6aspgjEYdZtuQBgcbT2x3rI1vW73xTfwrHasAgIht4gXbpljkDJ6fgB9ScJuL1T1PusHDEQXJVglG2/X8/8jkPGMbaT4vj1zTpXEV9IdQtJJFyVkD5dSCMEq/bkYK5JzW5q/xX1PX9EOj2mlJDd3aiCWSNzIZAwwyom3gtnA5JAPrgjU8Q69e+CxpmjajpVtqekz2ayTW9zENvnCR2IVuQSpMechvugjGc1xE/i5bbV9S1HQNMi0mW/gELNHKzGFcKGEQG1FB2Kc7CwJY7uQF96lzVIRc4Xfe54FVRU5KD0voWPhh/yUXSv+23/op6+jK8q+EnhXUdLvL7VNTsbm0LwLFbiXC7wWJfKfeBBRMZA4bjPb0XWLW8urNG0+48m8glSaLc5VJNp+aN8Z+V1LLkhtu4MAWUVy4yalU06EI0KK5//hIdU/6EzXP+/wBZf/JFFcozoKp6nqUOlWqXE6yMj3EFuAgBO6WVYlPJHG5wT7Z69KKKALlQTWVrcuHntoZWAwGeMMcenNFFJxUlZoBYLW3tt32eCKLd97y0C5+uKy9a8Mafq2lajbR29tbXV3BJGt4tupeJ3UgSA8EkE56g5HWiilyRtawmk9xYfC2jQ3lzcCwt2WfaTC8KMiMBglcjK5G3IB2/LkAEsWyPE+h6dZ/YdTS2+y2lvL5d81k7WsiwSYG/zIirBUcIzZYJsDsQWVCCikqcU7pCUYrVI1oNEl0+O5Ftf3l7A0DJFp+oTiSLceeZWRpjk5HzM4AY4XAAGHpjW3h62sYr3w1q9q9lGsP2+CMXf2hwm07vs5MkgblsyRqMgEhW2iiirG0m7m/af8I/4gSS9t4bG8YP5czNCpkjcAZSQEbkcAjKsAR0IFLdm40eOP8AsnQ4rm2JZp4raVIZc8BSisAje+50wBxuPFFFKyLc5NWb0K8euaFrTjR74RR3k33tK1FAkrlfmOI24kUFT86bkJU4Y4zV218P6LY3KXNppGn286Z2yxWyIy5GDggZHBIooqlJpWJNGs/U9Ht9U8qR3nt7qDPkXVtKY5IycZ5HDLkKSjBkYqu5TgUUUgM/7H4w/wCg7of/AIJpv/kqiiigD//Z'base64_data = data.split(",", maxsplit=1)[-1]
- 接着使用base64模块中的
b64decode(base64编码数据)将Base64编码数据解码成字节数据。 ```python import base64
获取Base64编码数据
data = ‘data:image/jpg;base64,/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAoAIEDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+se+0a/u7ySeHxNqtlG2MQQR2pRMADgvCzc9eSevpxWhfTXFvZyS2tr9qmTBEIkCFxkbgpPG7GcAkAnAJUHcPPzr+t6Jpg8TQ6foaaBf+TKyHVpVRXnkQLOC1svlqfM3SAjn72A2/eAeiQRtDbxRPNJO6IFaWQKGcgfeO0AZPXgAegFMmvbW2cJPcwxMRkK8gU49eaybu91aHw5dz39raWl0DtRbW6eddpIG7cUjIbk8Y7A57VzOj6PJrk1wzXOzZgs7DczE59/Y85rz8VjJ06saNON5PX+vuNIwTV2zvYLq3ud32eeKXb97y3DY+uKdPcQ2sLTXE0cMS43PIwVR25JrzzU7CbQtRWOO5JbYHSRMqcHI/Doe9Zk/hbxBrs13qxgBEkhkVXkw8qZPEYJxkKPlDFQfl+YDkYwzGrKTp+z99een9f1cxxDlTScFe56dBq+mXUyw2+o2k0rZ2pHOrMe/ABq5Xj2p+FBbeHrbXdPv1vrCeNJQ/lGIhHAKNgnPORxwRkcdcdD4F8V2sdoNK1TUraGbzFjsluLhVeUNwI0BwWwcdM/eA9K2o4ybq+xrRs2c1PESdT2dSNmd1c3dtZxiS6uIoEJ2hpXCgn0yfpUdtqVheSGO1vbadwNxWKVWIHrgH3rzTxBqE/izVpxZFTZWMEkqFht+QAFm9TkgAD6cDmo/BVs95e6naxlQ82nSxqW6AkqBn867rmcMZz11TS91u1z0TUfEujaVbzTXWoRYhO144syyA5xjYgLHnrgcc56VZ07VLHVrdZ7G5SZGRXwOGUMMjcp5U+xAPBrzyfwS9le20V9frFb3AVEuVi3Is5OPLbkbd2QEboxyp2sUD5Wr6Zd+GNWWJbrEuzzI5YWKnaSV/A8Hjnr1rN1JR1aPo6eDw9V8tOpd+h7DLLHBC800iRxRqWd3YBVUckknoKxrjWPDGsw/2fJq+m3AnZVWOO8TeXyCpQq24OGAKleQQCMECvFPF/ijU/Gmt22mQ5EKukMNsuEDzkBWY5J/iJAJPC+hJzp658I7/R/D0upRajFdTW8fmzwCPYFUDLlWJ+bHuBkZ78H0o4aCiueVmzy5JptHqn2698PfJqsk9/pv3jqrLGrW47/aFXaNoOMSIuAud4UIXbcmnhtkDzyxxIXVAzsFBZmCqOe5YgAdyQK8p+EnjC6upj4cv5UkjjhL2kkj4cBcfux/eGCSO4CntjHq08EN1by29xFHNBKhSSORQyupGCCDwQRxiuerSdOXKwJKK5//AIQ3S/8An61z/wAHt7/8eorMDoKx9TsdGsfD2si+j8vSpop5r5Qz7djIfNIC8rkbmOzGWLN95iTsUUAcf4bmg0vwSbbUZZZJLZjZ3Vv8q+XKAFdYlG0rG3MqA4xHIu0Ku1VyLG0v7md5NJiuY1xjcJcemQW4B7HFb934Yg0/wnBpumRk/ZEiGdo8yfy4xECxAGW2KvOP4QAOlY+jeIZNIheH7OssTMX+9tbPA688celeFmMovExjWfLG263N6fw6bkEsEtpqKtrVvcyBiMnzOWxj+LndxxgEfUV3cWqWUkMUhuYk82Fp1V5FDbFxvOM9FLKCegJGetcPq2rza3PCogCBCRGi5ZiTjj35HpXKa7f3dw8emXIVYtPlcJGOcSZYFifXlhnsCfU558Ni4Yac+T3ovZ9b+b+8wxlZUYKUty5rmusG1HS9Luo5dFubj7Uim3Kujud8i7iSWUyEvyAQWIHygCo7e+GleHZ7SGZTd6gR9oVXO6GIDKAjHBcMT1PyFTj5s1mWVxbW4lM0MrysAIpI2j/d88nbJG6tkccg4ye+COlhkXx3qkAvrqOwvFt0hXZCzJO43M23JwpxkhCScKxGQrEdGDqKtX9pUl73RaniOU615J+89EvI37VNG0bwdfWkepafLeS20nmvHMpMjlTgDnJxnA/PHJrA8A3dtZ67PJdXEUCG2ZQ0rhQTuXjJ+lXr/wCHn2LTrm7/ALU3+RE0m37PjdtBOM7vauSsrF7yO7ZNxNvB5xVVzuG5VP0wGJz7V7TdtSlGs69KnypPZanfeL9M1rWbhRpm+fTZ7UJIiXCiOUMWyCpbDAqR7EVxssV1o2to+rWfnSq4lkinbIlB5zuB5+vIyOc8iuh034gPY6bbWj6aspgjEYdZtuQBgcbT2x3rI1vW73xTfwrHasAgIht4gXbpljkDJ6fgB9ScJuL1T1PusHDEQXJVglG2/X8/8jkPGMbaT4vj1zTpXEV9IdQtJJFyVkD5dSCMEq/bkYK5JzW5q/xX1PX9EOj2mlJDd3aiCWSNzIZAwwyom3gtnA5JAPrgjU8Q69e+CxpmjajpVtqekz2ayTW9zENvnCR2IVuQSpMechvugjGc1xE/i5bbV9S1HQNMi0mW/gELNHKzGFcKGEQG1FB2Kc7CwJY7uQF96lzVIRc4Xfe54FVRU5KD0voWPhh/yUXSv+23/op6+jK8q+EnhXUdLvL7VNTsbm0LwLFbiXC7wWJfKfeBBRMZA4bjPb0XWLW8urNG0+48m8glSaLc5VJNp+aN8Z+V1LLkhtu4MAWUVy4yalU06EI0KK5//hIdU/6EzXP+/wBZf/JFFcozoKp6nqUOlWqXE6yMj3EFuAgBO6WVYlPJHG5wT7Z69KKKALlQTWVrcuHntoZWAwGeMMcenNFFJxUlZoBYLW3tt32eCKLd97y0C5+uKy9a8Mafq2lajbR29tbXV3BJGt4tupeJ3UgSA8EkE56g5HWiilyRtawmk9xYfC2jQ3lzcCwt2WfaTC8KMiMBglcjK5G3IB2/LkAEsWyPE+h6dZ/YdTS2+y2lvL5d81k7WsiwSYG/zIirBUcIzZYJsDsQWVCCikqcU7pCUYrVI1oNEl0+O5Ftf3l7A0DJFp+oTiSLceeZWRpjk5HzM4AY4XAAGHpjW3h62sYr3w1q9q9lGsP2+CMXf2hwm07vs5MkgblsyRqMgEhW2iiirG0m7m/af8I/4gSS9t4bG8YP5czNCpkjcAZSQEbkcAjKsAR0IFLdm40eOP8AsnQ4rm2JZp4raVIZc8BSisAje+50wBxuPFFFKyLc5NWb0K8euaFrTjR74RR3k33tK1FAkrlfmOI24kUFT86bkJU4Y4zV218P6LY3KXNppGn286Z2yxWyIy5GDggZHBIooqlJpWJNGs/U9Ht9U8qR3nt7qDPkXVtKY5IycZ5HDLkKSjBkYqu5TgUUUgM/7H4w/wCg7of/AIJpv/kqiiigD//Z’ base64_data = data.split(“,”, maxsplit=1)[-1]
Base64编码数据解码成字节数据。
imgdata = base64.b64decode(base64_data)
print(img_data) # b’\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x02\x00\x00\x01\x00\x01\x00\x00\xff\xdb\x00C\x00\x08\x06\x06\x07\x06\x05\x08\x07\x07\x07\t\t\x08\n\x0c\x14\r\x0c\x0b\x0b\x0c\x19\x12\x13\x0f\x14\x1d\x1a\x1f\x1e\x1d\x1a\x1c\x1c $.\’ “,#\x1c\x1c(7),01444\x1f\’9=82<.342\xff\xdb\x00C\x01\t\t\t\x0c\x0b\x0c\x18\r\r\x182!\x1c!22222222222222222222222222222222222222222222222222\xff\xc0\x00\x11\x08\x00(\x00\x81\x03\x01”\x00\x02\x11\x01\x03\x11\x01\xff\xc4\x00\x1f\x00\x00\x01\x05\x01\x01\x01\x01\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\xff\xc4\x00\xb5\x10\x00\x02\x01\x03\x03\x02\x04\x03\x05\x05\x04\x04\x00\x00\x01}\x01\x02\x03\x00\x04\x11\x05\x12!1A\x06\x13Qa\x07”q\x142\x81\x91\xa1\x08#B\xb1\xc1\x15R\xd1\xf0$3br\x82\t\n\x16\x17\x18\x19\x1a%&\’()456789:CDEFGHIJSTUVWXYZcdefghijstuvwxyz\x83\x84\x85\x86\x87\x88\x89\x8a\x92\x93\x94\x95\x96\x97\x98\x99\x9a\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xff\xc4\x00\x1f\x01\x00\x03\x01\x01\x01\x01\x01\x01\x01\x01\x01\x00\x00\x00\x00\x00\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\xff\xc4\x00\xb5\x11\x00\x02\x01\x02\x04\x04\x03\x04\x07\x05\x04\x04\x00\x01\x02w\x00\x01\x02\x03\x11\x04\x05!1\x06\x12AQ\x07aq\x13”2\x81\x08\x14B\x91\xa1\xb1\xc1\t#3R\xf0\x15br\xd1\n\x16$4\xe1%\xf1\x17\x18\x19\x1a&\’()56789:CDEFGHIJSTUVWXYZcdefghijstuvwxyz\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x92\x93\x94\x95\x96\x97\x98\x99\x9a\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xff\xda\x00\x0c\x03\x01\x00\x02\x11\x03\x11\x00?\x00\xf7\xfa\xc7\xbe\xd1\xaf\xee\xef$\x9e\x1f\x13j\xb6Q\xb61\x04\x11\xda\x94L\x008/\x0b7=y\’\xaf\xa7\x15\xa1}5\xc5\xbd\x9c\x92\xda\xda\xfd\xaad\xc1\x10\x89\x02\x17\x19\x1b\x82\x93\xc6\xecg\x00\x90\t\xc0%A\xdc<\xfc\xeb\xfa\xde\x89\xa6\x0f\x13C\xa7\xe8i\xa0\xf92\xb2\x1dZUEy\xe4@\xb3\x82\xd6\xcb\xe5\xa9\xf37H\x08\xe7\xef6\xfd\xe0\x1e\x89\x04m\r\xbcQ<\xd2N\xe8\x81ZY\x02\x86r\x07\xde;@\x19=x\x00z\x01L\x9a\xf6\xd6\xd9\xc2Os\x0cLFB\xbc\x81N=y\xac\x9b\xbb\xddZ\x1f\x0e]\xcf\x7fkiit\x0e\xd4[[\xa7\x9dv\x92\x06\xed\xc5#!\xb9<c\xb09\xed\\\xce\x8f\xa3\xc9\xaeMp\xcds\xb3f\x0b;\r\xcc\xc4\xe7\xdf\xd8\xf3\x9a\xf3\xf1X\xc9\xd3\xab\x1a4\xe3y=\x7f\xaf\xb8\xd20M]\xb3\xbd\x82\xea\xde\xe7w\xd9\xe7\x8a]\xbf{\xcbp\xd8\xfa\xe2\x9d=\xc46\xb0\xb4\xd7\x13G\x0cK\x8d\xcf#\x05Q\xdb\x92k\xcf5;\t\xb4-Ec\x8e\xe4\x96\xd8\x1d$L\xa9\xc1\xc8\xfc:\x1e\xf5\x99?\x85\xbcA\xae\xcdw\xab\x18\x01\x12HdUy0\xf2\xa6O\x11\x82q\x90\xa3\xe5\x0cT\x1f\x97\xe6\x03\x91\x8c3\x1a\xb2\x93\xa7\xec\xfd\xf5\xe7\xa7\xf5\xfd\\\xc7\x10\xe5M\'\x05{\x9e\x9d\x06\xaf\xa6]L\xb0\xdb\xea6\x93J\xd9\xda\x91\xce\xac\xc7\xbf\x00\x1a\xb9^=\xa9\xf8P[xz\xdb]\xd3\xef\xd6\xfa\xc2x\xd2P\xfeQ\x88\x84p\n6\t\xcf9\x1cpFG\x1dq\xd0\xf8\x17\xc5v\xb1\xda\r+T\xd4\xad\xa1\x9b\xccX\xec\x96\xe2\xe1U\xe5\r\xc0\x8d\x01\xc1l\x1ct\xcf\xde\x03\xd2\xb6\xa3\x8c\x9b\xab\xeckF\xcd\x9c\xd4\xf1\x12u=\x9dH\xd9\x9d\xd5\xcd\xdd\xb5\x9cbK\xab\x88\xa0Bv\x86\x95\xc2\x82}2~\x95\x1d\xb6\xa5ay!\x8e\xd6\xf6\xdaw\x03qX\xa5V z\xe0\x1fz\xf3O\x10j\x13\xf8\xb3V\x9cY\x156V0I*\x16\x1b~@\x01f\xf59 \x00>\x9c\x0ej?\x05[=\xe5\xee\xa7k\x19P\xf3i\xd2\xc6\xa5\xba\x02J\x81\x9f\xce\xbb\xaeg\x0cg=uM/u\xbb\\\xf4MG\xc4\xba6\x95o4\xd7Z\x84X\x84\xedx\xe2\xcc\xb2\x03\x9ccb\x02\xc7\x9e\xb8\x1cs\x9e\x95gN\xd5,uku\x9e\xc6\xe5&FE|\x0e\x19C\x0c\x8d\xcayS\xec@<\x1a\xf3\xc9\xfc\x12\xf6W\xb6\xd1__\xacV\xf7\x01Q.V-\xc8\xb3\x93\x8f-\xb9\x1bwd\x04n\x8cr\xa7k\x14\x0f\x95\xab\xe9\x97~\x18\xd5\x96%\xba\xc4\xbb<\xc8\xe5\x85\x8a\x9d\xa4\x95\xfc\x0f\x07\x8ez\xf5\xac\xddIGV\x8f\xa3\xa7\x83\xc3\xd5|\xb4\xea]\xfa\x1e\xc3,\xb1\xc1\x0b\xcd4\x89\x1cQ\xa9gw\x15TrI\’\xa0\xack\x8dc\xc3\x1a\xcc?\xd9\xf2j\xfam\xc0\x9d\x95V8\xef\x13y|\x82\xa5\n\xb6\xe0\xe1\x80W\x90@#\x04\n\xf1O\x17\xf8\xa3S\xf1\xa6\xb7m\xa6C\x91\n\xbaC\r\xb2\xe1\x03\xce@Vc\x92\x7f\x88\x90\t</\xa1\’:z\xe7\xc2;\xfd\x1f\xc3\xd2\xeaQj1]Mo\x1f\x9b<\x02=\x81T\x0c\xb9V\’\xe6\xc7\xb8\x19\x19\xef\xc1\xf4\xa3\x86\x82\x8a\xe7\x95\x9b<\xb9&\x9bG\xaa}\xba\xf7\xc3\xdf&\xab$\xf7\xfao\xde:\xab,j\xd6\xe3\xbf\xda\x15v\x8d\xa0\xe3\x12”\xe0.w\x85\x08]\xb7&\x9e\x1bd\x0f<\xb1\xc4\x85\xd5\x03;\x05\x05\x99\x82\xa8\xe7\xb9b\x00\x1d\xc9\x02\xbc\xa7\xe1\’\x8c.\xae\xa6>\x1c\xbf\x95$\x8e8K\xdaI#\xe1\xc0\~\xec\x7fx`\x92;\x80\xa7\xb61\xea\xd3\xc1\r\xd5\xbc\xb6\xf7\x11G4\x12\xa1I#\x91C+\xa9\x18 \x83\xc1\x04q\x8a\xe7\xabI\xd3\x97+\x02J+\x9f\xff\x00\x847K\xff\x00\x9f\xads\xff\x00\x07\xb7\xbf\xfcz\x8a\xcc\x0e\x82\xb1\xf5;\x1d\x1a\xc7\xc3\xda\xc8\xbe\x8f\xcb\xd2\xa6\x8ay\xaf\x943\xed\xd8\xc8|\xd2\x02\xf2\xb9\x1b\x98\xec\xc6X\xb3}\xe6$\xecQ@\x1c\x7f\x86\xe6\x83K\xf0I\xb6\xd4e\x96I-\x98\xd9\xdd[\xfc\xab\xe5\xca\x00WX\x94m+\x1bs\x03\x8cG”\xed\n\xbbUr,m/\xeegy4\x98\xaec\cp\x97\x1e\x99\x05\xb8\x07\xb1\xc5o\xdd\xf8b\r?\xc2pi\xbadd\xfd\x91”\x19\xda<\xc9\xfc\xb8\xc4@\xb1\x00e\xb6\xf3\x8f\xe1\x00\x0e\x95\x8f\xa3x\x86M”\x17\x87\xec\xeb,L\xc5\xfe\xf6\xd6\xcf\x03\xaf<q\xe9^\x16c(\xbcLcY\xf2\xc6\xdb\xad\xcd\xe9\xfc:nA,\x12\xdaj\xda\xd5\xbd\xcc\x81\x88\xc9\xf39lc\xf8\xb9\xdd\xc7\x18\x04}Ewqj\x96RC\x14\x86\xe6$\xf3ai\xd5^E\r\xb1q\xbc\xe3=\x14\xb2\x82z\x02Fz\xd7\x0f\xabj\xf3ks\xc2\xa2\x00\x81\t\x11\xa2\xe5\x98\x93\x8e=\xf9\x1e\x95\xcak\xb7\xf7w\x0f\x1e\x99r\x15b\xd3\xe5p\x91\x8eq&X\x16\’\xd7\x96\x19\xec\t\xf59\xe7\xc3b\xe1\x86\x9c\xf9=\xe8\xbd\x9f[\xf9\xbf\xbc\xc3\x19YQ\x82\x94\xb7.k\x9a\xeb\x06\xd4t\xbd.\xea9t[\x9b\x8f\xb5”\x9br\xae\x8e\xe7|\x8b\xb8\x92YL\x84\xbf \x10X\x81\xf2\x80;{\xe1\xa5xv{HfSw\xa8\x11\xf6\x85W;\xa1\x88\x0c\xa0#\x1c\x17\x0cOS\xf2\x158\xf9\xb3Y\x96W\x16\xd6\xe2S42\xbc\xac\x00\x8aH\xda?\xdd\xf3\xc9\xdb$n\xad\x91\xc7 \xe3\’\xbe\x08\xe9a\x91|w\xaa@/\xae\xa3\xb0\xbc[t\x85vB\xcc\x93\xb8\xdc\xcd\xb7\’\nq\x92\x10\x92p\xacFB\xb1\x1d\x18:\x8a\xb5\x7fiR^\xf7E\xa9\xe29N\xb5\xe4\x9f\xbc\xf4K\xc8\xdf\xb5M\x1bF\xf0u\xf5\xa4z\x96\x9f-\xe4\xb6\xd2y\xaf\x1c\xcaL\x8eT\xe0\x0erq\x9c\x0f\xcf\x1c\x9a\xc0\xf0\r\xdd\xb5\x9e\xbb<\x97W\x11@\x86\xd9\x944\xae\x14\x13\xb9x\xc9\xfaU\xeb\xff\x00\x87\x9fb\xd3\xaen\xff\x00\xb57\xf9\x114\x9b~\xcf\x8d\xdbA8\xce\xefj\xe4\xac\xac^\xf2;\xb6M\xc4\xdb\xc1\xe7\x15U\xce\xe1\xb9T\xfd0\x18\x9c\xfbW\xb4\xdd\xb5)F\xb3\xafJ\x9fOe\xa9\xdfx\xbfL\xd6\xb5\x9b\x85\x1af\xf9\xf4\xd9\xedBH\x89p\xa29C\x16\xc8[\x0c\n\x91\xecEq\xb2\xc5u\xa3kh\xfa\xb5\x9f\x9d\xb8\x96H\xa7l\x89A\xe7;\x81\xe7\xeb\xc8\xc8\xe7<\x8a\xe8t\xdf\x88\x0fc\xa6\xdbZ>\x9a\xb2\x98#\x11\x87Y\xb6\xe4\x01\x81\xc6\xd3\xdb\x1d\xeb#[\xd6\xef|S\x7f\n\xc7j\xc0 “\x1bx\x81v\xe9\x969\x03\’\xa7\xe0\x07\xd4\x9c&\xe2\xf5OS\xee\xb0p\xc4ArU\x82Q\xb6\xfd\x7f?\xf29\x0f\x18\xc6\xdaO\x8b\xe3\xd74\xe9\E}!\xd4-$\x91rV@\xf9u \x8c\x12\xaf\xdb\x91\x82\xb9\’5\xb9\xab\xfcW\xd4\xf5\xfd\x10\xe8\xf6\x9aRCwv\xa2\td\x8d\xcc\x86@\xc3\x0c\xa8\x9bx-\x9c\x0eI\x00\xfa\xe0\x8dO\x10\xeb\xd7\xbe\x0b\x1af\x8d\xa8\xe9V\xda\x9e\x93=\x9a\xc95\xbd\xccCo\x9c$v![\x90J\x93\x1er\x1b\xee\x821\x9c\xd7\x11?\x8b\x96\xdbW\xd4\xb5\x1d\x03L\x8bI\x96\xfe\x01\x0b4r\xb3\x18W\n\x18D\x06\xd4Pv)\xce\xc2\xc0\x96;\xb9\x01}\xea\\xd5!\x178]\xf7\xb9\xe0UQS\x92\x83\xd2\xfa\x16>\x18\x7f\xc9E\xd2\xbf\xed\xb7\xfe\x8az\xfa2\xbc\xab\xe1\’\x85u\x1d.\xf2\xfbT\xd4\xecnm\x0b\xc0\xb1[\x89p\xbb\xc1b)\xf7\x81\x05\x13\x19\x03\x86\xe3=\xbd\x17X\xb5\xbc\xba\xb3F\xd3\xee<\x9b\xc8%I\xa2\xdc\xe5RM\xa7\xe6\x8d\xf1\x9f\x95\xd4\xb2\xe4\x86\xdb\xb80\x05\x94W.2jU4\xe8B4(\xae\x7f\xfe\x12\x1dS\xfe\x84\xcds\xfe\xff\x00Y\x7f\xf2E\x15\xca3\xa0\xaaz\x9e\xa5\x0e\x95j\x97\x13\xac\x8c\x8fq\x05\xb8\x08\x01;\xa5\x95bS\xc9\x1cnpO\xb6z\xf4\xa2\x8a\x00\xb9PMekr\xe1\xe7\xb6\x86V\x03\x01\x9e0\xc7\x1e\x9c\xd1E\’\x15%f\x80X-m\xed\xb7}\x9e\x08\xa2\xdd\xf7\xbc\xb4\x0b\x9f\xae+/Z\xf0\xc6\x9f\xabiZ\x8d\xb4v\xf6\xd6\xd7WpI\x1a\xde-\xba\x97\x89\xddH\x12\x03\xc1$\x13\x9e\xa0\xe4u\xa2\x8a\\x91\xb5\xac&\x93\xdcX|-\xa3Cysp,-\xd9g\xdaL/\n2#\x01\x82W#+\x91\xb7 \x1d\xbf.@\x04\xb1l\x8f\x13\xe8zu\x9f\xd8u4\xb6\xfb-\xa5\xbc\xbe]\xf3Y;Z\xc8\xb0I\x81\xbf\xcc\x88\xab\x05G\x08\xcd\x96\t\xb0;\x10YP\x82\x8aJ\x9cS\xbaBQ\x8a\xd5#Z\r\x12]>;\x91m\x7fy{\x03@\xc9\x16\x9f\xa8N$\x8bq\xe7\x99Y\x1ac\x93\x91\xf33\x80\x18\xe1p\x00\x18zc[xz\xda\xc6+\xdf\rj\xf6\xafe\x1a\xc3\xf6\xf8#\x17\x7fhp\x9bN\xef\xb3\x93$\x81\xb9l\xc9\x1a\x8c\x80HV\xda(\xa2\xacm&\xeeo\xda\x7f\xc2?\xe2\x04\x92\xf6\xde\x1b\x1b\xc6\x0f\xe5\xcc\xcd\n\x99#p\x06R@F\xe4p\x08\xca\xb0\x04t R\xdd\x9b\x8d\x1e8\xff\x00\xb2t8\xaem\x89f\x9e+iR\x19s\xc0R\x8a\xc0#{\xeet\xc0\x1cn<QE+”\xdc\xe4\xd5\x9b\xd0\xaf\x1e\xb9\xa1kN4{\xe1\x14w\x93}\xed+Q@\x92\xb9\x98\xe26\xe2E\x05O\xce\x9b\x90\x958c\x8c\xd5\xdb_\x0f\xe8\xb67)si\xa4i\xf6\xf3\xa6v\xcb\x15\xb2#.F\x0e\x08\x19\x1c\x12(\xa2\xa9I\xa5bM\x1a\xcf\xd4\xf4{}S\xca\x91\xde{{\xa83\xe4][Jc\x922q\x9eG\x0c\xb9\nJ0db\xab\xb9N\x05\x14R\x03?\xec~0\xff\x00\xa0\xee\x87\xff\x00\x82i\xbf\xf9*\x8a(\xa0\x0f\xff\xd9’
- 最后,还可以将字节数据写入到文件中。```pythonimport base64# 数据解析data = 'data:image/jpg;base64,/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAoAIEDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+se+0a/u7ySeHxNqtlG2MQQR2pRMADgvCzc9eSevpxWhfTXFvZyS2tr9qmTBEIkCFxkbgpPG7GcAkAnAJUHcPPzr+t6Jpg8TQ6foaaBf+TKyHVpVRXnkQLOC1svlqfM3SAjn72A2/eAeiQRtDbxRPNJO6IFaWQKGcgfeO0AZPXgAegFMmvbW2cJPcwxMRkK8gU49eaybu91aHw5dz39raWl0DtRbW6eddpIG7cUjIbk8Y7A57VzOj6PJrk1wzXOzZgs7DczE59/Y85rz8VjJ06saNON5PX+vuNIwTV2zvYLq3ud32eeKXb97y3DY+uKdPcQ2sLTXE0cMS43PIwVR25JrzzU7CbQtRWOO5JbYHSRMqcHI/Doe9Zk/hbxBrs13qxgBEkhkVXkw8qZPEYJxkKPlDFQfl+YDkYwzGrKTp+z99een9f1cxxDlTScFe56dBq+mXUyw2+o2k0rZ2pHOrMe/ABq5Xj2p+FBbeHrbXdPv1vrCeNJQ/lGIhHAKNgnPORxwRkcdcdD4F8V2sdoNK1TUraGbzFjsluLhVeUNwI0BwWwcdM/eA9K2o4ybq+xrRs2c1PESdT2dSNmd1c3dtZxiS6uIoEJ2hpXCgn0yfpUdtqVheSGO1vbadwNxWKVWIHrgH3rzTxBqE/izVpxZFTZWMEkqFht+QAFm9TkgAD6cDmo/BVs95e6naxlQ82nSxqW6AkqBn867rmcMZz11TS91u1z0TUfEujaVbzTXWoRYhO144syyA5xjYgLHnrgcc56VZ07VLHVrdZ7G5SZGRXwOGUMMjcp5U+xAPBrzyfwS9le20V9frFb3AVEuVi3Is5OPLbkbd2QEboxyp2sUD5Wr6Zd+GNWWJbrEuzzI5YWKnaSV/A8Hjnr1rN1JR1aPo6eDw9V8tOpd+h7DLLHBC800iRxRqWd3YBVUckknoKxrjWPDGsw/2fJq+m3AnZVWOO8TeXyCpQq24OGAKleQQCMECvFPF/ijU/Gmt22mQ5EKukMNsuEDzkBWY5J/iJAJPC+hJzp658I7/R/D0upRajFdTW8fmzwCPYFUDLlWJ+bHuBkZ78H0o4aCiueVmzy5JptHqn2698PfJqsk9/pv3jqrLGrW47/aFXaNoOMSIuAud4UIXbcmnhtkDzyxxIXVAzsFBZmCqOe5YgAdyQK8p+EnjC6upj4cv5UkjjhL2kkj4cBcfux/eGCSO4CntjHq08EN1by29xFHNBKhSSORQyupGCCDwQRxiuerSdOXKwJKK5//AIQ3S/8An61z/wAHt7/8eorMDoKx9TsdGsfD2si+j8vSpop5r5Qz7djIfNIC8rkbmOzGWLN95iTsUUAcf4bmg0vwSbbUZZZJLZjZ3Vv8q+XKAFdYlG0rG3MqA4xHIu0Ku1VyLG0v7md5NJiuY1xjcJcemQW4B7HFb934Yg0/wnBpumRk/ZEiGdo8yfy4xECxAGW2KvOP4QAOlY+jeIZNIheH7OssTMX+9tbPA688celeFmMovExjWfLG263N6fw6bkEsEtpqKtrVvcyBiMnzOWxj+LndxxgEfUV3cWqWUkMUhuYk82Fp1V5FDbFxvOM9FLKCegJGetcPq2rza3PCogCBCRGi5ZiTjj35HpXKa7f3dw8emXIVYtPlcJGOcSZYFifXlhnsCfU558Ni4Yac+T3ovZ9b+b+8wxlZUYKUty5rmusG1HS9Luo5dFubj7Uim3Kujud8i7iSWUyEvyAQWIHygCo7e+GleHZ7SGZTd6gR9oVXO6GIDKAjHBcMT1PyFTj5s1mWVxbW4lM0MrysAIpI2j/d88nbJG6tkccg4ye+COlhkXx3qkAvrqOwvFt0hXZCzJO43M23JwpxkhCScKxGQrEdGDqKtX9pUl73RaniOU615J+89EvI37VNG0bwdfWkepafLeS20nmvHMpMjlTgDnJxnA/PHJrA8A3dtZ67PJdXEUCG2ZQ0rhQTuXjJ+lXr/wCHn2LTrm7/ALU3+RE0m37PjdtBOM7vauSsrF7yO7ZNxNvB5xVVzuG5VP0wGJz7V7TdtSlGs69KnypPZanfeL9M1rWbhRpm+fTZ7UJIiXCiOUMWyCpbDAqR7EVxssV1o2to+rWfnSq4lkinbIlB5zuB5+vIyOc8iuh034gPY6bbWj6aspgjEYdZtuQBgcbT2x3rI1vW73xTfwrHasAgIht4gXbpljkDJ6fgB9ScJuL1T1PusHDEQXJVglG2/X8/8jkPGMbaT4vj1zTpXEV9IdQtJJFyVkD5dSCMEq/bkYK5JzW5q/xX1PX9EOj2mlJDd3aiCWSNzIZAwwyom3gtnA5JAPrgjU8Q69e+CxpmjajpVtqekz2ayTW9zENvnCR2IVuQSpMechvugjGc1xE/i5bbV9S1HQNMi0mW/gELNHKzGFcKGEQG1FB2Kc7CwJY7uQF96lzVIRc4Xfe54FVRU5KD0voWPhh/yUXSv+23/op6+jK8q+EnhXUdLvL7VNTsbm0LwLFbiXC7wWJfKfeBBRMZA4bjPb0XWLW8urNG0+48m8glSaLc5VJNp+aN8Z+V1LLkhtu4MAWUVy4yalU06EI0KK5//hIdU/6EzXP+/wBZf/JFFcozoKp6nqUOlWqXE6yMj3EFuAgBO6WVYlPJHG5wT7Z69KKKALlQTWVrcuHntoZWAwGeMMcenNFFJxUlZoBYLW3tt32eCKLd97y0C5+uKy9a8Mafq2lajbR29tbXV3BJGt4tupeJ3UgSA8EkE56g5HWiilyRtawmk9xYfC2jQ3lzcCwt2WfaTC8KMiMBglcjK5G3IB2/LkAEsWyPE+h6dZ/YdTS2+y2lvL5d81k7WsiwSYG/zIirBUcIzZYJsDsQWVCCikqcU7pCUYrVI1oNEl0+O5Ftf3l7A0DJFp+oTiSLceeZWRpjk5HzM4AY4XAAGHpjW3h62sYr3w1q9q9lGsP2+CMXf2hwm07vs5MkgblsyRqMgEhW2iiirG0m7m/af8I/4gSS9t4bG8YP5czNCpkjcAZSQEbkcAjKsAR0IFLdm40eOP8AsnQ4rm2JZp4raVIZc8BSisAje+50wBxuPFFFKyLc5NWb0K8euaFrTjR74RR3k33tK1FAkrlfmOI24kUFT86bkJU4Y4zV218P6LY3KXNppGn286Z2yxWyIy5GDggZHBIooqlJpWJNGs/U9Ht9U8qR3nt7qDPkXVtKY5IycZ5HDLkKSjBkYqu5TgUUUgM/7H4w/wCg7of/AIJpv/kqiiigD//Z'base64_data = data.split(",", maxsplit=1)[-1]img_data = base64.b64decode(base64_data)# 数据写入文件file = open("./code.jpg", "wb")file.write(img_data)file.close()
此时,在当前Python文件同目录下就可以看见验证码图片了。
5.2.2 b64encode()编码
使用base64模块中的
b64encode(字节数据)可以将字节数据编码成Base64编码数据。 ```python import base64
imgdata = b’\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x02\x00\x00\x01\x00\x01\x00\x00\xff\xdb\x00C\x00\x08\x06\x06\x07\x06\x05\x08\x07\x07\x07\t\t\x08\n\x0c\x14\r\x0c\x0b\x0b\x0c\x19\x12\x13\x0f\x14\x1d\x1a\x1f\x1e\x1d\x1a\x1c\x1c $.\’ “,#\x1c\x1c(7),01444\x1f\’9=82<.342\xff\xdb\x00C\x01\t\t\t\x0c\x0b\x0c\x18\r\r\x182!\x1c!22222222222222222222222222222222222222222222222222\xff\xc0\x00\x11\x08\x00(\x00\x81\x03\x01”\x00\x02\x11\x01\x03\x11\x01\xff\xc4\x00\x1f\x00\x00\x01\x05\x01\x01\x01\x01\x01\x01\x00\x00\x00\x00\x00\x00\x00\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\xff\xc4\x00\xb5\x10\x00\x02\x01\x03\x03\x02\x04\x03\x05\x05\x04\x04\x00\x00\x01}\x01\x02\x03\x00\x04\x11\x05\x12!1A\x06\x13Qa\x07”q\x142\x81\x91\xa1\x08#B\xb1\xc1\x15R\xd1\xf0$3br\x82\t\n\x16\x17\x18\x19\x1a%&\’()456789:CDEFGHIJSTUVWXYZcdefghijstuvwxyz\x83\x84\x85\x86\x87\x88\x89\x8a\x92\x93\x94\x95\x96\x97\x98\x99\x9a\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xff\xc4\x00\x1f\x01\x00\x03\x01\x01\x01\x01\x01\x01\x01\x01\x01\x00\x00\x00\x00\x00\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\xff\xc4\x00\xb5\x11\x00\x02\x01\x02\x04\x04\x03\x04\x07\x05\x04\x04\x00\x01\x02w\x00\x01\x02\x03\x11\x04\x05!1\x06\x12AQ\x07aq\x13”2\x81\x08\x14B\x91\xa1\xb1\xc1\t#3R\xf0\x15br\xd1\n\x16$4\xe1%\xf1\x17\x18\x19\x1a&\’()56789:CDEFGHIJSTUVWXYZcdefghijstuvwxyz\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x92\x93\x94\x95\x96\x97\x98\x99\x9a\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xff\xda\x00\x0c\x03\x01\x00\x02\x11\x03\x11\x00?\x00\xf7\xfa\xc7\xbe\xd1\xaf\xee\xef$\x9e\x1f\x13j\xb6Q\xb61\x04\x11\xda\x94L\x008/\x0b7=y\’\xaf\xa7\x15\xa1}5\xc5\xbd\x9c\x92\xda\xda\xfd\xaad\xc1\x10\x89\x02\x17\x19\x1b\x82\x93\xc6\xecg\x00\x90\t\xc0%A\xdc<\xfc\xeb\xfa\xde\x89\xa6\x0f\x13C\xa7\xe8i\xa0\xf92\xb2\x1dZUEy\xe4@\xb3\x82\xd6\xcb\xe5\xa9\xf37H\x08\xe7\xef6\xfd\xe0\x1e\x89\x04m\r\xbcQ<\xd2N\xe8\x81ZY\x02\x86r\x07\xde;@\x19=x\x00z\x01L\x9a\xf6\xd6\xd9\xc2Os\x0cLFB\xbc\x81N=y\xac\x9b\xbb\xddZ\x1f\x0e]\xcf\x7fkiit\x0e\xd4[[\xa7\x9dv\x92\x06\xed\xc5#!\xb9<c\xb09\xed\\\xce\x8f\xa3\xc9\xaeMp\xcds\xb3f\x0b;\r\xcc\xc4\xe7\xdf\xd8\xf3\x9a\xf3\xf1X\xc9\xd3\xab\x1a4\xe3y=\x7f\xaf\xb8\xd20M]\xb3\xbd\x82\xea\xde\xe7w\xd9\xe7\x8a]\xbf{\xcbp\xd8\xfa\xe2\x9d=\xc46\xb0\xb4\xd7\x13G\x0cK\x8d\xcf#\x05Q\xdb\x92k\xcf5;\t\xb4-Ec\x8e\xe4\x96\xd8\x1d$L\xa9\xc1\xc8\xfc:\x1e\xf5\x99?\x85\xbcA\xae\xcdw\xab\x18\x01\x12HdUy0\xf2\xa6O\x11\x82q\x90\xa3\xe5\x0cT\x1f\x97\xe6\x03\x91\x8c3\x1a\xb2\x93\xa7\xec\xfd\xf5\xe7\xa7\xf5\xfd\\\xc7\x10\xe5M\'\x05{\x9e\x9d\x06\xaf\xa6]L\xb0\xdb\xea6\x93J\xd9\xda\x91\xce\xac\xc7\xbf\x00\x1a\xb9^=\xa9\xf8P[xz\xdb]\xd3\xef\xd6\xfa\xc2x\xd2P\xfeQ\x88\x84p\n6\t\xcf9\x1cpFG\x1dq\xd0\xf8\x17\xc5v\xb1\xda\r+T\xd4\xad\xa1\x9b\xccX\xec\x96\xe2\xe1U\xe5\r\xc0\x8d\x01\xc1l\x1ct\xcf\xde\x03\xd2\xb6\xa3\x8c\x9b\xab\xeckF\xcd\x9c\xd4\xf1\x12u=\x9dH\xd9\x9d\xd5\xcd\xdd\xb5\x9cbK\xab\x88\xa0Bv\x86\x95\xc2\x82}2~\x95\x1d\xb6\xa5ay!\x8e\xd6\xf6\xdaw\x03qX\xa5V z\xe0\x1fz\xf3O\x10j\x13\xf8\xb3V\x9cY\x156V0I*\x16\x1b~@\x01f\xf59 \x00>\x9c\x0ej?\x05[=\xe5\xee\xa7k\x19P\xf3i\xd2\xc6\xa5\xba\x02J\x81\x9f\xce\xbb\xaeg\x0cg=uM/u\xbb\\\xf4MG\xc4\xba6\x95o4\xd7Z\x84X\x84\xedx\xe2\xcc\xb2\x03\x9ccb\x02\xc7\x9e\xb8\x1cs\x9e\x95gN\xd5,uku\x9e\xc6\xe5&FE|\x0e\x19C\x0c\x8d\xcayS\xec@<\x1a\xf3\xc9\xfc\x12\xf6W\xb6\xd1__\xacV\xf7\x01Q.V-\xc8\xb3\x93\x8f-\xb9\x1bwd\x04n\x8cr\xa7k\x14\x0f\x95\xab\xe9\x97~\x18\xd5\x96%\xba\xc4\xbb<\xc8\xe5\x85\x8a\x9d\xa4\x95\xfc\x0f\x07\x8ez\xf5\xac\xddIGV\x8f\xa3\xa7\x83\xc3\xd5|\xb4\xea]\xfa\x1e\xc3,\xb1\xc1\x0b\xcd4\x89\x1cQ\xa9gw\x15TrI\’\xa0\xack\x8dc\xc3\x1a\xcc?\xd9\xf2j\xfam\xc0\x9d\x95V8\xef\x13y|\x82\xa5\n\xb6\xe0\xe1\x80W\x90@#\x04\n\xf1O\x17\xf8\xa3S\xf1\xa6\xb7m\xa6C\x91\n\xbaC\r\xb2\xe1\x03\xce@Vc\x92\x7f\x88\x90\t</\xa1\’:z\xe7\xc2;\xfd\x1f\xc3\xd2\xeaQj1]Mo\x1f\x9b<\x02=\x81T\x0c\xb9V\’\xe6\xc7\xb8\x19\x19\xef\xc1\xf4\xa3\x86\x82\x8a\xe7\x95\x9b<\xb9&\x9bG\xaa}\xba\xf7\xc3\xdf&\xab$\xf7\xfao\xde:\xab,j\xd6\xe3\xbf\xda\x15v\x8d\xa0\xe3\x12”\xe0.w\x85\x08]\xb7&\x9e\x1bd\x0f<\xb1\xc4\x85\xd5\x03;\x05\x05\x99\x82\xa8\xe7\xb9b\x00\x1d\xc9\x02\xbc\xa7\xe1\’\x8c.\xae\xa6>\x1c\xbf\x95$\x8e8K\xdaI#\xe1\xc0\~\xec\x7fx`\x92;\x80\xa7\xb61\xea\xd3\xc1\r\xd5\xbc\xb6\xf7\x11G4\x12\xa1I#\x91C+\xa9\x18 \x83\xc1\x04q\x8a\xe7\xabI\xd3\x97+\x02J+\x9f\xff\x00\x847K\xff\x00\x9f\xads\xff\x00\x07\xb7\xbf\xfcz\x8a\xcc\x0e\x82\xb1\xf5;\x1d\x1a\xc7\xc3\xda\xc8\xbe\x8f\xcb\xd2\xa6\x8ay\xaf\x943\xed\xd8\xc8|\xd2\x02\xf2\xb9\x1b\x98\xec\xc6X\xb3}\xe6$\xecQ@\x1c\x7f\x86\xe6\x83K\xf0I\xb6\xd4e\x96I-\x98\xd9\xdd[\xfc\xab\xe5\xca\x00WX\x94m+\x1bs\x03\x8cG”\xed\n\xbbUr,m/\xeegy4\x98\xaec\cp\x97\x1e\x99\x05\xb8\x07\xb1\xc5o\xdd\xf8b\r?\xc2pi\xbadd\xfd\x91”\x19\xda<\xc9\xfc\xb8\xc4@\xb1\x00e\xb6\xf3\x8f\xe1\x00\x0e\x95\x8f\xa3x\x86M”\x17\x87\xec\xeb,L\xc5\xfe\xf6\xd6\xcf\x03\xaf<q\xe9^\x16c(\xbcLcY\xf2\xc6\xdb\xad\xcd\xe9\xfc:nA,\x12\xdaj\xda\xd5\xbd\xcc\x81\x88\xc9\xf39lc\xf8\xb9\xdd\xc7\x18\x04}Ewqj\x96RC\x14\x86\xe6$\xf3ai\xd5^E\r\xb1q\xbc\xe3=\x14\xb2\x82z\x02Fz\xd7\x0f\xabj\xf3ks\xc2\xa2\x00\x81\t\x11\xa2\xe5\x98\x93\x8e=\xf9\x1e\x95\xcak\xb7\xf7w\x0f\x1e\x99r\x15b\xd3\xe5p\x91\x8eq&X\x16\’\xd7\x96\x19\xec\t\xf59\xe7\xc3b\xe1\x86\x9c\xf9=\xe8\xbd\x9f[\xf9\xbf\xbc\xc3\x19YQ\x82\x94\xb7.k\x9a\xeb\x06\xd4t\xbd.\xea9t[\x9b\x8f\xb5”\x9br\xae\x8e\xe7|\x8b\xb8\x92YL\x84\xbf \x10X\x81\xf2\x80;{\xe1\xa5xv{HfSw\xa8\x11\xf6\x85W;\xa1\x88\x0c\xa0#\x1c\x17\x0cOS\xf2\x158\xf9\xb3Y\x96W\x16\xd6\xe2S42\xbc\xac\x00\x8aH\xda?\xdd\xf3\xc9\xdb$n\xad\x91\xc7 \xe3\’\xbe\x08\xe9a\x91|w\xaa@/\xae\xa3\xb0\xbc[t\x85vB\xcc\x93\xb8\xdc\xcd\xb7\’\nq\x92\x10\x92p\xacFB\xb1\x1d\x18:\x8a\xb5\x7fiR^\xf7E\xa9\xe29N\xb5\xe4\x9f\xbc\xf4K\xc8\xdf\xb5M\x1bF\xf0u\xf5\xa4z\x96\x9f-\xe4\xb6\xd2y\xaf\x1c\xcaL\x8eT\xe0\x0erq\x9c\x0f\xcf\x1c\x9a\xc0\xf0\r\xdd\xb5\x9e\xbb<\x97W\x11@\x86\xd9\x944\xae\x14\x13\xb9x\xc9\xfaU\xeb\xff\x00\x87\x9fb\xd3\xaen\xff\x00\xb57\xf9\x114\x9b~\xcf\x8d\xdbA8\xce\xefj\xe4\xac\xac^\xf2;\xb6M\xc4\xdb\xc1\xe7\x15U\xce\xe1\xb9T\xfd0\x18\x9c\xfbW\xb4\xdd\xb5)F\xb3\xafJ\x9fOe\xa9\xdfx\xbfL\xd6\xb5\x9b\x85\x1af\xf9\xf4\xd9\xedBH\x89p\xa29C\x16\xc8[\x0c\n\x91\xecEq\xb2\xc5u\xa3kh\xfa\xb5\x9f\x9d\xb8\x96H\xa7l\x89A\xe7;\x81\xe7\xeb\xc8\xc8\xe7<\x8a\xe8t\xdf\x88\x0fc\xa6\xdbZ>\x9a\xb2\x98#\x11\x87Y\xb6\xe4\x01\x81\xc6\xd3\xdb\x1d\xeb#[\xd6\xef|S\x7f\n\xc7j\xc0 “\x1bx\x81v\xe9\x969\x03\’\xa7\xe0\x07\xd4\x9c&\xe2\xf5OS\xee\xb0p\xc4ArU\x82Q\xb6\xfd\x7f?\xf29\x0f\x18\xc6\xdaO\x8b\xe3\xd74\xe9\E}!\xd4-$\x91rV@\xf9u \x8c\x12\xaf\xdb\x91\x82\xb9\’5\xb9\xab\xfcW\xd4\xf5\xfd\x10\xe8\xf6\x9aRCwv\xa2\td\x8d\xcc\x86@\xc3\x0c\xa8\x9bx-\x9c\x0eI\x00\xfa\xe0\x8dO\x10\xeb\xd7\xbe\x0b\x1af\x8d\xa8\xe9V\xda\x9e\x93=\x9a\xc95\xbd\xccCo\x9c$v![\x90J\x93\x1er\x1b\xee\x821\x9c\xd7\x11?\x8b\x96\xdbW\xd4\xb5\x1d\x03L\x8bI\x96\xfe\x01\x0b4r\xb3\x18W\n\x18D\x06\xd4Pv)\xce\xc2\xc0\x96;\xb9\x01}\xea\\xd5!\x178]\xf7\xb9\xe0UQS\x92\x83\xd2\xfa\x16>\x18\x7f\xc9E\xd2\xbf\xed\xb7\xfe\x8az\xfa2\xbc\xab\xe1\’\x85u\x1d.\xf2\xfbT\xd4\xecnm\x0b\xc0\xb1[\x89p\xbb\xc1b)\xf7\x81\x05\x13\x19\x03\x86\xe3=\xbd\x17X\xb5\xbc\xba\xb3F\xd3\xee<\x9b\xc8%I\xa2\xdc\xe5RM\xa7\xe6\x8d\xf1\x9f\x95\xd4\xb2\xe4\x86\xdb\xb80\x05\x94W.2jU4\xe8B4(\xae\x7f\xfe\x12\x1dS\xfe\x84\xcds\xfe\xff\x00Y\x7f\xf2E\x15\xca3\xa0\xaaz\x9e\xa5\x0e\x95j\x97\x13\xac\x8c\x8fq\x05\xb8\x08\x01;\xa5\x95bS\xc9\x1cnpO\xb6z\xf4\xa2\x8a\x00\xb9PMekr\xe1\xe7\xb6\x86V\x03\x01\x9e0\xc7\x1e\x9c\xd1E\’\x15%f\x80X-m\xed\xb7}\x9e\x08\xa2\xdd\xf7\xbc\xb4\x0b\x9f\xae+/Z\xf0\xc6\x9f\xabiZ\x8d\xb4v\xf6\xd6\xd7WpI\x1a\xde-\xba\x97\x89\xddH\x12\x03\xc1$\x13\x9e\xa0\xe4u\xa2\x8a\\x91\xb5\xac&\x93\xdcX|-\xa3Cysp,-\xd9g\xdaL/\n2#\x01\x82W#+\x91\xb7 \x1d\xbf.@\x04\xb1l\x8f\x13\xe8zu\x9f\xd8u4\xb6\xfb-\xa5\xbc\xbe]\xf3Y;Z\xc8\xb0I\x81\xbf\xcc\x88\xab\x05G\x08\xcd\x96\t\xb0;\x10YP\x82\x8aJ\x9cS\xbaBQ\x8a\xd5#Z\r\x12]>;\x91m\x7fy{\x03@\xc9\x16\x9f\xa8N$\x8bq\xe7\x99Y\x1ac\x93\x91\xf33\x80\x18\xe1p\x00\x18zc[xz\xda\xc6+\xdf\rj\xf6\xafe\x1a\xc3\xf6\xf8#\x17\x7fhp\x9bN\xef\xb3\x93$\x81\xb9l\xc9\x1a\x8c\x80HV\xda(\xa2\xacm&\xeeo\xda\x7f\xc2?\xe2\x04\x92\xf6\xde\x1b\x1b\xc6\x0f\xe5\xcc\xcd\n\x99#p\x06R@F\xe4p\x08\xca\xb0\x04t R\xdd\x9b\x8d\x1e8\xff\x00\xb2t8\xaem\x89f\x9e+iR\x19s\xc0R\x8a\xc0#{\xeet\xc0\x1cn<QE+”\xdc\xe4\xd5\x9b\xd0\xaf\x1e\xb9\xa1kN4{\xe1\x14w\x93}\xed+Q@\x92\xb9\x98\xe26\xe2E\x05O\xce\x9b\x90\x958c\x8c\xd5\xdb_\x0f\xe8\xb67)si\xa4i\xf6\xf3\xa6v\xcb\x15\xb2#.F\x0e\x08\x19\x1c\x12(\xa2\xa9I\xa5bM\x1a\xcf\xd4\xf4{}S\xca\x91\xde{{\xa83\xe4][Jc\x922q\x9eG\x0c\xb9\nJ0db\xab\xb9N\x05\x14R\x03?\xec~0\xff\x00\xa0\xee\x87\xff\x00\x82i\xbf\xf9*\x8a(\xa0\x0f\xff\xd9’
base64_data = base64.b64encode(img_data)
print(base64_data) # b’/9j/4AAQSkZJRgABAgAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjL/wAARCAAoAIEDASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD3+se+0a/u7ySeHxNqtlG2MQQR2pRMADgvCzc9eSevpxWhfTXFvZyS2tr9qmTBEIkCFxkbgpPG7GcAkAnAJUHcPPzr+t6Jpg8TQ6foaaBf+TKyHVpVRXnkQLOC1svlqfM3SAjn72A2/eAeiQRtDbxRPNJO6IFaWQKGcgfeO0AZPXgAegFMmvbW2cJPcwxMRkK8gU49eaybu91aHw5dz39raWl0DtRbW6eddpIG7cUjIbk8Y7A57VzOj6PJrk1wzXOzZgs7DczE59/Y85rz8VjJ06saNON5PX+vuNIwTV2zvYLq3ud32eeKXb97y3DY+uKdPcQ2sLTXE0cMS43PIwVR25JrzzU7CbQtRWOO5JbYHSRMqcHI/Doe9Zk/hbxBrs13qxgBEkhkVXkw8qZPEYJxkKPlDFQfl+YDkYwzGrKTp+z99een9f1cxxDlTScFe56dBq+mXUyw2+o2k0rZ2pHOrMe/ABq5Xj2p+FBbeHrbXdPv1vrCeNJQ/lGIhHAKNgnPORxwRkcdcdD4F8V2sdoNK1TUraGbzFjsluLhVeUNwI0BwWwcdM/eA9K2o4ybq+xrRs2c1PESdT2dSNmd1c3dtZxiS6uIoEJ2hpXCgn0yfpUdtqVheSGO1vbadwNxWKVWIHrgH3rzTxBqE/izVpxZFTZWMEkqFht+QAFm9TkgAD6cDmo/BVs95e6naxlQ82nSxqW6AkqBn867rmcMZz11TS91u1z0TUfEujaVbzTXWoRYhO144syyA5xjYgLHnrgcc56VZ07VLHVrdZ7G5SZGRXwOGUMMjcp5U+xAPBrzyfwS9le20V9frFb3AVEuVi3Is5OPLbkbd2QEboxyp2sUD5Wr6Zd+GNWWJbrEuzzI5YWKnaSV/A8Hjnr1rN1JR1aPo6eDw9V8tOpd+h7DLLHBC800iRxRqWd3YBVUckknoKxrjWPDGsw/2fJq+m3AnZVWOO8TeXyCpQq24OGAKleQQCMECvFPF/ijU/Gmt22mQ5EKukMNsuEDzkBWY5J/iJAJPC+hJzp658I7/R/D0upRajFdTW8fmzwCPYFUDLlWJ+bHuBkZ78H0o4aCiueVmzy5JptHqn2698PfJqsk9/pv3jqrLGrW47/aFXaNoOMSIuAud4UIXbcmnhtkDzyxxIXVAzsFBZmCqOe5YgAdyQK8p+EnjC6upj4cv5UkjjhL2kkj4cBcfux/eGCSO4CntjHq08EN1by29xFHNBKhSSORQyupGCCDwQRxiuerSdOXKwJKK5//AIQ3S/8An61z/wAHt7/8eorMDoKx9TsdGsfD2si+j8vSpop5r5Qz7djIfNIC8rkbmOzGWLN95iTsUUAcf4bmg0vwSbbUZZZJLZjZ3Vv8q+XKAFdYlG0rG3MqA4xHIu0Ku1VyLG0v7md5NJiuY1xjcJcemQW4B7HFb934Yg0/wnBpumRk/ZEiGdo8yfy4xECxAGW2KvOP4QAOlY+jeIZNIheH7OssTMX+9tbPA688celeFmMovExjWfLG263N6fw6bkEsEtpqKtrVvcyBiMnzOWxj+LndxxgEfUV3cWqWUkMUhuYk82Fp1V5FDbFxvOM9FLKCegJGetcPq2rza3PCogCBCRGi5ZiTjj35HpXKa7f3dw8emXIVYtPlcJGOcSZYFifXlhnsCfU558Ni4Yac+T3ovZ9b+b+8wxlZUYKUty5rmusG1HS9Luo5dFubj7Uim3Kujud8i7iSWUyEvyAQWIHygCo7e+GleHZ7SGZTd6gR9oVXO6GIDKAjHBcMT1PyFTj5s1mWVxbW4lM0MrysAIpI2j/d88nbJG6tkccg4ye+COlhkXx3qkAvrqOwvFt0hXZCzJO43M23JwpxkhCScKxGQrEdGDqKtX9pUl73RaniOU615J+89EvI37VNG0bwdfWkepafLeS20nmvHMpMjlTgDnJxnA/PHJrA8A3dtZ67PJdXEUCG2ZQ0rhQTuXjJ+lXr/wCHn2LTrm7/ALU3+RE0m37PjdtBOM7vauSsrF7yO7ZNxNvB5xVVzuG5VP0wGJz7V7TdtSlGs69KnypPZanfeL9M1rWbhRpm+fTZ7UJIiXCiOUMWyCpbDAqR7EVxssV1o2to+rWfnSq4lkinbIlB5zuB5+vIyOc8iuh034gPY6bbWj6aspgjEYdZtuQBgcbT2x3rI1vW73xTfwrHasAgIht4gXbpljkDJ6fgB9ScJuL1T1PusHDEQXJVglG2/X8/8jkPGMbaT4vj1zTpXEV9IdQtJJFyVkD5dSCMEq/bkYK5JzW5q/xX1PX9EOj2mlJDd3aiCWSNzIZAwwyom3gtnA5JAPrgjU8Q69e+CxpmjajpVtqekz2ayTW9zENvnCR2IVuQSpMechvugjGc1xE/i5bbV9S1HQNMi0mW/gELNHKzGFcKGEQG1FB2Kc7CwJY7uQF96lzVIRc4Xfe54FVRU5KD0voWPhh/yUXSv+23/op6+jK8q+EnhXUdLvL7VNTsbm0LwLFbiXC7wWJfKfeBBRMZA4bjPb0XWLW8urNG0+48m8glSaLc5VJNp+aN8Z+V1LLkhtu4MAWUVy4yalU06EI0KK5//hIdU/6EzXP+/wBZf/JFFcozoKp6nqUOlWqXE6yMj3EFuAgBO6WVYlPJHG5wT7Z69KKKALlQTWVrcuHntoZWAwGeMMcenNFFJxUlZoBYLW3tt32eCKLd97y0C5+uKy9a8Mafq2lajbR29tbXV3BJGt4tupeJ3UgSA8EkE56g5HWiilyRtawmk9xYfC2jQ3lzcCwt2WfaTC8KMiMBglcjK5G3IB2/LkAEsWyPE+h6dZ/YdTS2+y2lvL5d81k7WsiwSYG/zIirBUcIzZYJsDsQWVCCikqcU7pCUYrVI1oNEl0+O5Ftf3l7A0DJFp+oTiSLceeZWRpjk5HzM4AY4XAAGHpjW3h62sYr3w1q9q9lGsP2+CMXf2hwm07vs5MkgblsyRqMgEhW2iiirG0m7m/af8I/4gSS9t4bG8YP5czNCpkjcAZSQEbkcAjKsAR0IFLdm40eOP8AsnQ4rm2JZp4raVIZc8BSisAje+50wBxuPFFFKyLc5NWb0K8euaFrTjR74RR3k33tK1FAkrlfmOI24kUFT86bkJU4Y4zV218P6LY3KXNppGn286Z2yxWyIy5GDggZHBIooqlJpWJNGs/U9Ht9U8qR3nt7qDPkXVtKY5IycZ5HDLkKSjBkYqu5TgUUUgM/7H4w/wCg7of/AIJpv/kqiiigD//Z’
<a name="KSOU9"></a>## 06. hashlib加密模块<a name="apZ0B"></a>### 6.1 hashlib与加密介绍<a name="zgJDO"></a>#### 6.1.1 hashlib模块介绍- hashlib是Python提供的一个加密模块,这个模块中封装着许多不同的加密算法,其中常用的加密算法有:MD5、SHA1、SHA2、SHA256。- hashlib模块可以根据加密算法获取加密之后的摘要(所谓摘要即加密的结果,是16进制数据)。<a name="nzGLe"></a>#### 6.1.2 加密的应用场景- 当用户在一个平台上进行注册后,用户的信息就会存储在该平台的服务器中。- 为了防止黑客的攻击造成客户信息的泄露,所以平台方一般会对用户信息进行加密。- 大多数平台都会要求用户输入的密码具有一定的复杂度,这是因为密码格式越复杂,破解难度就越大。<a name="aYiuE"></a>#### 6.1.3 非对称加密- 开头提到的MD5、SHA1、SHA2、SHA256这些加密算法都是非对称加密,是不可逆的。- 非对称加密一般只能使用碰撞破解的方式进行破解。所谓碰撞破解就是按照密码的格式要求生成所有满足要求的密码,然后按照对应的加密方式一条一条进行比对,若某一条密码加密后与数据库中的数据匹配,则说明找到密码了。- 在这种情况,若用户设置的密码复杂度越高,则碰撞破解成功的可能性越低。<a name="t9MEG"></a>### 6.2 使用hashlib加密数据<a name="UspDW"></a>#### 6.2.1 使用md5算法加密数据- 加密流程:- 使用`hashlib.md5()`创建MD5加密对象。- 使用`MD5加密对象.update(字节数据)`加密数据。(原始文本数据需要编码成字节数据)- 最后使用`MD5加密对象.hexdigest()`获取加密后的16进制摘要。- 代码实现:使用MD5算法加密文本数据`12345@AbznfmdMk````pythonimport hashlibdata = "12345@AbznfmdMk"md5 = hashlib.md5() # 创建MD5加密对象md5.update(data.encode("utf-8")) # 加密数据,原始文本数据需要编码成字节print(md5.hexdigest()) # bd55c1c0a11406e00f718de029f2e136,获取16进制摘要
- 分多次传递:
- MD5可以一次性加密所有文本,也可以分批次加密一段文本。
- 但是只要多次加密的文本拼接后是相同的,那么加密后的16进制摘要就是相同的。
- 因为它的运算是先将所有的分批次数据整合在一起,然后再一次性
update(),所以分批次和一次性update()的结果是一样的。 ```python import hashlib
md5 = hashlib.md5() # 创建MD5加密对象
分批次加密data
md5.update(“12345”.encode(“utf-8”)) md5.update(“@Abzn”.encode(“utf-8”)) md5.update(“fmdMk”.encode(“utf-8”))
print(md5.hexdigest()) # bd55c1c0a11406e00f718de029f2e136,与一次性全部加密的效果相同。
<a name="NlEEE"></a>#### 6.2.2 使用sha算法加密数据- 其实hashlib中大多数的加密算法的使用操作都是和6.2.1中一致的。- 示例:使用sha1算法加密数据`data = "12345@AbznfmdMk"````pythonimport hashlibdata = "12345@AbznfmdMk"sha1 = hashlib.sha1()sha1.update(data.encode("utf-8"))print(sha1.hexdigest()) # 182f9072073ece6ef327fffb07f1b1af9300b802
- 示例:使用sha256算法加密数据
data = "12345@AbznfmdMk"```python import hashlib
data = “12345@AbznfmdMk” sha256 = hashlib.sha256() sha256.update(data.encode(“utf-8”)) print(sha256.hexdigest()) # dcf14a457938119ecf88fdbc3286f13b1adb6e11d7f38e6f5757ea06e52ff91f
<a name="wzCm0"></a>## 07. uuid唯一标识模块<a name="tsUvo"></a>### 7.1 uuid模块介绍- uuid模块可以用于生成一个全局的唯一标识。- 比如订单号用于定位唯一的一笔订单,是绝对不允许重复的,此时就可以用uuid生成订单号。<a name="g8Pny"></a>### 7.2 uuid中的常见操作<a name="nDjyo"></a>#### 7.2.1 uuid1()全球唯一标识- `uuid.uuid1()`可以结合当前时间戳、当前设备的Mac地址、一个随机数生成一个全球唯一的标识。- MAC地址是每台设备唯一的,时间戳是每个时间点唯一的。- 再结合一个随机数,就可以做到全球唯一。```pythonimport uuidid = uuid.uuid1()print(id) # 4274165d-3afa-11ed-a1cb-d8f2cacbb589
7.2.2 uuid3()命名空间MD5唯一标识
uuid.uuid3(namespace, name)用于生成同一命名空间中不同名字的唯一标识,以及不同命名空间种任意名字的唯一标识。- uuid3的唯一算法:将命名空间与名称进行MD5加密。
- 因此uuid3()生成的标识可能会有重复。
- namespace和name都一样,那么MD5加密的结果也就一样,因此uuid3生成的结果就是一样的。
- 只有namespace和name中有一个不一样,那么uuid3的结果就不一样。
- 命名空间有
NAMESPACE_DNS、NAMESPACE_URL、NAMESPACE_OID、NAMESPACE_X500这四个可选值。
- 示例:生成OID中名称为Python的标识。 ```python import uuid
oid_python = uuid.uuid3( namespace=uuid.NAMESPACE_OID, name=”Python” ) print(oid_python.int) # 332315913667175389958021633677999540973,实践中标识 print(oid_python.hex) # fa01b78798ed334fb44ba14ca4b10aed,十六进制标识
<a name="IFCrf"></a>#### 7.2.3 uuid4()随即唯一标识- `uuid.uuid4()`不需要传入任何参数,会更具内部的一个随机数生成一个唯一标识。- 内部的随机数范围是,若随机数一样,则生成的唯一标识就一样。- 因此`uuid4()`存在较大的重复概率,因为这个原因`uuid4()`用的没有另外三个多。```pythonimport uuiduuid4_id = uuid.uuid4()print(uuid4_id.hex) # 904dcc63db6a492c9e195e33d082b430
7.2.4 uuid5()命名空间SHA1唯一标识
uuid.uuid5()与uuid.uuid3()相当类似,差别在于uuid5()用SHA-1加密算法加密。 ```python import uuid
oid_python = uuid.uuid5( namespace=uuid.NAMESPACE_OID, name=”Python” ) print(oid_python.int) # 272431580526339936645692919498369232791 print(oid_python.hex) # ccf469f398c75abd8a3a961769316f97
<a name="zLPKq"></a>## 08. collections容器数据类型模块<a name="Wurmz"></a>### 8.1 deque双端队列<a name="STRwN"></a>#### 8.1.1 deque简介- deque双端队列可以看作是列表的一个替代实现。- 列表的底层是基于数组实现的,而deque底层是基于双向列表实现的。- deque双端队列可以在头尾两端增删数据,并且在性能上要优于列表。<a name="WtbEc"></a>#### 8.1.2 deque()构建双端列表- 使用`deque()`可以构建一个空的双端队列。```pythonfrom collections import dequeque = deque()print(que) # deque([])
deque(序列)还可以将一个序列转换成一个双端队列。 ```python from collections import deque
que = deque([12, 34, 56]) print(que) # deque([12, 34, 56])
<a name="uWIcb"></a>#### 8.1.3 appendleft()/append()在头/尾添加数据- `deque对象.append(数据)`可以在双端队列对象的末尾添加数据。```pythonfrom collections import dequeque = deque([12, 34, 56])que.append(78)que.append(90)print(que) # deque([12, 34, 56, 78, 90])
deque对象.appendleft(数据)可以在双端队列对象的头部添加数据。 ```python from collections import deque
que = deque([12, 34, 56]) que.appendleft(78) que.appendleft(90) print(que) # deque([90, 78, 12, 34, 56])
<a name="UZq2R"></a>#### 8.1.4 popleft()/pop()移除头/尾的数据- `deque对象.pop()`可以移除尾部的最后一个数据。```pythonfrom collections import dequeque = deque([12, 34, 56])que.pop()print(que) # deque([12, 34])
deque对象.popleft()可以移除头部的第一个数据。 ```python from collections import deque
que = deque([12, 34, 56]) que.popleft() print(que) # deque([34, 56])
<a name="jxs7A"></a>#### 8.1.5 extendleft()/extend()在头/尾部合并序列- `deque对象.extend(序列)`可以将序列中的每个元素依次合并到deque对象的末尾。```pythonfrom collections import dequeque = deque([12, 34, 56])que.extend([78, 90])print(que) # deque([12, 34, 56, 78, 90])
deque对象.extendleft(序列)可以将序列中的每个元素依次合并到deque对象的开头。 ```python from collections import deque
que = deque([56, 78, 90]) que.extendleft([12, 34]) print(que) # deque([34, 12, 56, 78, 90])
因为先将12合并到开头,得到deque([12, 56, 78, 90])
然后再将34合并到开头,得到deque([34, 12, 56, 78, 90])
正确方式
from collections import deque
que = deque([56, 78, 90]) que.extendleft(reversed([12, 34])) # 先倒置列表中的元素再添加 print(que) # deque([12, 34, 56, 78, 90])
<a name="IOpGs"></a>#### 8.1.6 insert()/remove()插入/移除元素- `deque对象.insert(index, ele)`可以向双端队列的指定索引处插入指定的元素。```pythonfrom collections import dequeque = deque([12, 34, 78, 90])que.insert(2, 56)print(que) # deque([12, 34, 56, 78, 90])
deque对象.remove(ele)可以删除双端队列中的指定元素中的第一个。 ```python from collections import deque
que = deque([12, 34, 12, 78, 12, 90]) que.remove(12) print(que) # deque([34, 12, 78, 12, 90])
<a name="IiZhG"></a>### 8.2 Counter类<a name="D8Um2"></a>#### 8.2.1 Counter类的介绍与基本使用- Counter类是字典的子类(因此字典的相关操作Counter类都能用),适用于词频统计等应用程序。- 比如这样的一个词频统计程序:```pythons = 'ab123ac121123abc'dic = {}for ch in s:if ch in dic:dic[ch] += 1else:dic[ch] = 1print(dic) # {'a': 3, 'b': 2, '1': 4, '2': 3, '3': 2, 'c': 2}
- 用Counter可以直接实现:(并且还完成了排序) ```python from collections import Counter
s = ‘ab123ac121123abc’ result = Counter(s) print(result) # Counter({‘1’: 4, ‘a’: 3, ‘2’: 3, ‘b’: 2, ‘3’: 2, ‘c’: 2})
<a name="Z5kgw"></a>#### 8.2.2 most_common()获取排名前几的数据- `Counter对象.most_common(n)`可以获取一个完成词频统计的Counter对象中排名前n的数据。- 示例:获取计算机专业中学生选择排在前三的专业。```pythonfrom collections import Counterbasic_data = ["计算机科学与技术", "软件工程", "物联网工程", "数据科学与大数据技术", "软件工程", "计算机科学与技术", "软件工程", "物联网工程", "软件工程", "计算机科学与技术", "网络工程"]wc = Counter(basic_data)top3 = wc.most_common(3)print(top3) # [('软件工程', 4), ('计算机科学与技术', 3), ('物联网工程', 2)]
09. os文件系统模块
9.1 os文件系统模块介绍
- os文件系统模块中提供了很多方法来处理文件和目录。
os其实包含了os和os.path两个主要的模块,os.path主要是与文件路径相关的一些操作。
9.2 os模块系统相关操作
9.2.1 name查看当前操作系统
os.name可用于查看当前操作系统,其中nt代表着Windows系统,posix代表着Mac或Linux系统。 ```python import os
system = os.name print(system) # nt
<a name="VYRug"></a>#### 9.2.2 environ查看系统环境变量- `os.environ`可用于查看当前操作系统中的环境变量。其值是一个字典,Key代表着环境变量中的变量名,Value是变量名对应的值(多个值之间用分号分割)。```pythonimport osenv = os.environprint(env)
- 因为
os.environ的结果是一个字典,因此要获取具体的某个变量名的值,可以用字典中get(key)或者dict[key]的方式获取。 ```python import os
env = os.environ print(env.get(“PATH”)) print(env[“PATH”])
<a name="TqJ9G"></a>### 9.3 os模块目录相关操作<a name="Dvtwh"></a>#### 9.3.1 getcwd()获取当前目录- `os.getcwd()`可以获取当前工作目录的绝对路径。```pythonimport osprint(os.getcwd()) # D:\Project\Python\BaseProject\Day02
9.3.2 mkdir()创建目录
os.mkdir(目录路径/目录名)可以在指定路径下创建指定名称的目录。 ```python import os
os.mkdir(“./test”)
- 注意1:`mkdir()`只能创建最后一级目录,若之前的目录不存在,会报错。```pythonimport osos.mkdir(r"D:\abc\def") # FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'D:\\abc\\def'
os.mkdir(“./test”) # FileExistsError: [WinError 183] 当文件已存在时,无法创建该文件。: ‘./test’
<a name="jcZsi"></a>#### 9.3.3 makedirs()创建多级目录- 9.3.2中介绍了`mkdir()`只能创建最后一级目录,若之前的目录不存在,会报错。- 若业务中就是需要创建多级目录,则可以使用`os.makedirs(目录路径/目录名)`。```pythonimport osos.makedirs(r"D:\abc\def")
若指定的路径的目录已经存在,则
makedirs()也会报错。9.3.4 rmdir()删除空目录
os.rmdir(路径)可用于删除最后一级空目录。rmdir()的本质是删除空目录。- 因此就要求删除的目录中不可以有任何文件(包括文件、文件夹),因此这就要求被删除的目录是最后一级空目录。 ```python import os
D:\abc中还有def目录,因此不属于最有一级空目录。
os.rmdir(r”D:\abc”) # OSError: [WinError 145] 目录不是空的。: ‘D:\abc’
os.rmdir(r”D:\abc\def”) os.rmdir(r”D:\abc”)
- 若指定的路径的目录不存在,则`rmdir()`也会报错。<a name="cgxuA"></a>#### 9.3.5 removedirs()删除多级空目录- 实验准备:创建`D:\abc\def\ghi`目录。```pythonimport osos.makedirs(r"D:\abc\def\ghi")
os.removedirs(路径)可用于删除多级空目录。- 以D:\abc\def\ghi为例,删除ghi目录后,def就是一个空目录。
- 此时removedirs()会检测到def目录是一个空目录,接着把def目录也给删掉。
- 同理,删除def目录后abc目录也是一个空目录,会被删除。 ```python import os
os.removedirs(r”D:\abc\def\ghi”)
- 当removedirs()删除到某一级目录中有文件时(即不为空目录),就不会再继续执行删除操作了。- 示例:以下程序执行完成后在磁盘中留下的是`D:\abc\jkl`。- 这是因为首先创建了`D:\abc\def\ghi`和`D:\abc\jkl`目录。- 接着从`D:\abc\def\ghi`开始向上删除空目录:- ghi被删除后,def就成了空目录,因此def会被删除。- def被删除后,removedirs()检测到abc不是空目录,因为abc中还有ghi目录。- 因此,在def被删除完后,removedirs()的删除动作就结束了,`D:\abc\jkl`就被保留了下来。```pythonimport osos.makedirs(r"D:\abc\def\ghi")os.mkdir(r"D:\abc\jkl")os.removedirs(r"D:\abc\def\ghi")
9.4 os模块文件相关操作
9.4.1 open()创建文件
- os模块中其实没有特别好的创建文件的函数,因此可以直接使用系统中的
open()函数创建文件。 - 函数格式:
open(文件路径, 操作文件的模式, encoding=文件编码),其中创建文件可以使用写数据模式来实现。 - 写数据模式:这种模式下若文件路径指定的文件不存在时,会自动创建。
- w:清空写;文件不存在则创建文件,文件存在则清空文件原有的内容,然后开始写入操作。
- a:追加写;文件不存在则创建文件,文件存在则不会清空文件原有的内容,然后在文件末尾追加写入数据。
- wb/ab:清空/追加写入字节格式的数据(处理像图片、音视频等字节格式的文件时使用)。
- 注意:字节模式下不需要指定encoding文件编码,因为在写入时就会对文件内容进行编码。 ```python file1 = open(‘./newfile1.txt’, ‘w’, encoding=’utf-8’) file1.write(“你好”) file1.close()
file2 = open(‘./newfile2.txt’, ‘wb’) file2.write(“你好”.encode(“utf-8”)) file2.close()
<a name="GCPwj"></a>#### 9.4.2 remove()删除文件- `os.remove(文件路径)`可以用于删除指定路径下的指定文件。```pythonimport osos.remove("newfile1.txt") # 相对路径删除(省略./就指当前路径)os.remove(r"D:\Project\Python\BaseProject\Day02\newfile2.txt") # 绝对路径删除
若删除前指定的路径的文件本来就已经不存在了,则
remove()会报错。9.4.3 listdir()查看子文件或子目录的名称列表
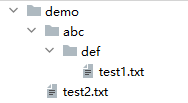
实验准备:
- 运行完成后文件目录树为:
 ```python
import os
```python
import os
- 运行完成后文件目录树为:
os.makedirs(“./demo/abc/def”)
def_test1 = open(“./demo/abc/def/test1.txt”, ‘w’, encoding=’utf-8’) def_test1.write(“abc”) def_test1.close()
demo_test2 = open(“./demo/test2.txt”, ‘w’, encoding=’utf-8’) demo_test2.write(“def”) demo_test2.close()
- `os.listdir(目录路径)`可以查看指定路径下所有的直接目录名或者直接文件名。- 示例:这个列表中只有'abc'和'test2.txt'两个元素,这是因为def目录和test1.txt文件都不是demo的直接子文件或直接目录,因此不会出现在列表中。```pythonimport osdirlist = os.listdir("./demo")print(dirlist) # ['abc', 'test2.txt']
9.5 os.path子模块路径操作
9.5.1 join()路径拼接
- 9.4.3中介绍的
listdir()只用于获取指定路径中内容名(包括文件和目录),无法获取这些内容的完整路径。 ```python import os
pwd = r”D:\Project\Python\BaseProject\Day02\demo” file_list = os.listdir(pwd) for name in file_list: print(name) “”” 运行结果: abc test2.txt “””
- `os.path.join(父路径, 文件名)`可以将父路径与文件名拼接在一起,形成一个完整的绝对路径。```pythonimport ospwd = r"D:\Project\Python\BaseProject\Day02\demo"file_list = os.listdir(pwd)for name in file_list:file_path = os.path.join(pwd, name)print(file_path)"""运行结果:D:\Project\Python\BaseProject\Day02\demo\abcD:\Project\Python\BaseProject\Day02\demo\test2.txt"""
9.5.2 basename()获取文件/目录名
os.path.basename(路径)可以获取指定路径中最后一级的文件名或目录名。- 若路径最后一级是文件,则获取的是文件名。
- 若路径最后一级是目录,则获取的是目录名。 ```python import os
pwd = r”D:\Project\Python\BaseProject\Day02\demo” file_list = os.listdir(pwd) for name in file_list: file_path = os.path.join(pwd, name) print(os.path.basename(file_path)) “”” 运行结果: abc # 是个目录 test2.txt # 是个文件 “””
<a name="yvv76"></a>#### 9.5.3 abspath()获取相对路径的绝对路径- `os.path.abspath(相对路径)`可以获取相对路径对应的文件或目录的绝对路径。```pythonimport osprint(os.path.abspath("./demo/test2.txt")) # D:\Project\Python\BaseProject\Day02\demo\test2.txt
9.6 os.path子模块文件操作
9.6.1 dirname()获取所在路径
os.path.dirname(路径)可以查看指定路径中文件或目录所在的目录的绝对路径。- 若路径最后一级是文件,则获取的是文件所在目录的绝对路径。
- 若路径最后一级是目录,则获取的是该目录上一级目录的绝对路径。 ```python import os
pwd = r”D:\Project\Python\BaseProject\Day02\demo” file_list = os.listdir(pwd) for name in file_list: file_path = os.path.join(pwd, name) print(os.path.dirname(file_path)) “”” 运行结果: D:\Project\Python\BaseProject\Day02\demo D:\Project\Python\BaseProject\Day02\demo “””
<a name="apF6A"></a>#### 9.6.2 获取文件后缀名操作- 获取文件后缀名的本质是根据路径中最后一级的内容中的`.`将原路径字符串切割成两个子字符串,其中第二个子字符串就是文件后缀名。- 如路径:D:\Project\Python\BaseProject\Day02\demo\test2.txt。- 最后一级内容为:test2.txt。- 跟据点切割:`D:\Project\Python\BaseProject\Day02\demo\test2`与`txt`。- 获取第二个元素txt即获取文件名的后缀。- 若路径指向的是一个目录,则目录中最后一级的内容中肯定是没有符号`.`的,因此得到是原路径和一个空字符串。- `os.path.splitext(路径)`就可以将路径跟据符号`.`完成切割。```pythonimport ospwd = r"D:\Project\Python\BaseProject\Day02\demo"file_list = os.listdir(pwd)for name in file_list:file_path = os.path.join(pwd, name)# 获取文件后缀split_path = os.path.splitext(file_path) # 切割原始路径字符串file_extension = split_path[1] # 获取切割后的第二个字符,即文件后缀# 判断是文件还是目录if file_extension == "": # 或文件后缀为空,则说明路径指向的是个目录print(f"{file_path}是一个目录")else: # 否则说明路径指向的是个文件print(f"{file_path}的文件后缀为:{file_extension}")"""运行结果:D:\Project\Python\BaseProject\Day02\demo\abc是一个目录D:\Project\Python\BaseProject\Day02\demo\test2.txt的文件后缀为:.txt"""
9.6.3 getsize()获取文件大小
os.path.getsize(文件路径)可以获取路径指向的文件的大小。- getsize()获取到的文件大小的单位是字节。
- 若路径指向的是个目录,则getsize()的结果为0。 ```python import os
file_path = r”D:\Project\Python\BaseProject\Day02\demo\test2.txt” file_size = os.path.getsize(file_path)
dir_path = r”D:\Project\Python\BaseProject\Day02\demo\abc” dir_size = os.path.getsize(dir_path)
print(file_size, dir_size) # 3 0
<a name="i21qq"></a>#### 9.6.4 getctime()获取文件的创建时间- `os.path.getctime(路径)`可以获取路径指向的文件或目录的创建时间。(时间戳形式)```pythonimport ospwd = r"D:\Project\Python\BaseProject\Day02\demo"file_list = os.listdir(pwd)for name in file_list:file_path = os.path.join(pwd, name)ctime = os.path.getctime(file_path)print(f"{file_path}的创建时间为:{ctime}")"""运行结果:D:\Project\Python\BaseProject\Day02\demo\abc的创建时间为:1664177047.1555665D:\Project\Python\BaseProject\Day02\demo\test2.txt的创建时间为:1664177047.1575594"""
9.6.5 getatime()获取文件的访问时间
os.path.getatime(路径)可以获取路径指向的文件或目录的访问时间。(时间戳形式) ```python import os
pwd = r”D:\Project\Python\BaseProject\Day02\demo” file_list = os.listdir(pwd) for name in file_list: file_path = os.path.join(pwd, name) ctime = os.path.getatime(file_path) print(f”{file_path}的访问时间为:{ctime}”)
“”” 运行结果: D:\Project\Python\BaseProject\Day02\demo\abc的访问时间为:1664259001.741476 D:\Project\Python\BaseProject\Day02\demo\test2.txt的访问时间为:1664177047.8417337 “””
<a name="jN44V"></a>#### 9.6.6 getmtime()获取文件的修改时间- `os.path.getmtime(路径)`可以获取路径指向的文件或目录最后一次修改的时间。(时间戳形式)```pythonimport ospwd = r"D:\Project\Python\BaseProject\Day02\demo"file_list = os.listdir(pwd)for name in file_list:file_path = os.path.join(pwd, name)ctime = os.path.getmtime(file_path)print(f"{file_path}最后一次修改的时间为:{ctime}")"""运行结果:D:\Project\Python\BaseProject\Day02\demo\abc最后一次修改的时间为:1664177047.1555665D:\Project\Python\BaseProject\Day02\demo\test2.txt最后一次修改的时间为:1664177047.1575594"""
9.7 os.path子模块判断操作
9.7.1 exists()判断文件是否存在
os.path.exists(路径)可以判断路径指向的文件或目录是否存在。 ```python import os
path1 = r”D:\Project\Python\BaseProject\Day02\demo” path2 = r”F:\demo\test2.txt”
print(os.path.exists(path1)) # True,表述该目录存在 print(os.path.exists(path2)) # False,表述该文件不存在
<a name="KWa9t"></a>#### 9.7.2 isfile()判断是否是文件- `os.path.isfile(路径)`可以判断路径指向的是否是一个文件。```pythonimport ospath1 = r"D:\Project\Python\BaseProject\Day02\demo"path2 = r"D:\Project\Python\BaseProject\Day02\demo\test2.txt"print(os.path.isfile(path1)) # False,说明是个目录print(os.path.isfile(path2)) # True,说明是个文件
9.7.3 isdir()判断是否是目录
os.path.isdir(路径)可以判断路径指向的是否是一个目录。 ```python import os
path1 = r”D:\Project\Python\BaseProject\Day02\demo” path2 = r”D:\Project\Python\BaseProject\Day02\demo\test2.txt”
print(os.path.isdir(path1)) # True,说明是个目录 print(os.path.isdir(path2)) # False,说明是个文件
<a name="kHQzg"></a>#### 9.7.4 isabs()判断是否为绝对路径- `os.path.isabs(路径)`可以判断路径是否是一个绝对路径。```pythonimport osprint(os.path.isabs("../abc/def")) # False,说明是相对路径print(os.path.isabs("D:/abc/def")) # True,说明是绝对路径
9.8 os模块中的常用操作
9.8.1 获取指定目录中所有的文件
- 实现思路:
- 首先,这个操作应该是一个整体且可复用的操作,因此可以封装成一个函数,参数应该是指定目录的路径。
- 接着,可以用
listdir()函数获取这个路径下所有的子内容名。 - 然后遍历得到每个子内容名,并且拼接成一个绝对路径。
- 最后,判断这个绝对路径指向的是否是一个文件:
- 若是一个文件,则说明获取到了一个文件,可以对该文件进行需要的操作(这里仅输出他的绝对路径)。
- 若是一个目录,则需要获取这个目录中的所有内容,也就是重复一次上面的步骤(递归实现)。
- 代码实现: ```python import os
def get_all_file(path): filenames = os.listdir(path) for name in filenames: file_path = os.path.join(path, name) if os.path.isfile(file_path): print(f”绝对路径:{os.path.abspath(file_path)}”) else: get_all_file(file_path)
get_all_file(“D:/Project/Python/BaseProject”)
<a name="c0mtF"></a>#### 9.8.2 获取指定后缀的文件- 实现思路一:- 首先,指定后缀的文件它首先应该是个文件,因此需要先用9.8.1中的方法获取一个路径下所有的文件。- 然后在对文件进行操作前,先用9.6.2中介绍的操作获取该文件的文件后缀,若是后缀则操作该文件,否则应该不做任何处理。- 代码实现:获取路径下所有的`.py`文件。```pythonimport osdef get_ext_file(path, file_ext):filenames = os.listdir(path)for name in filenames:file_path = os.path.join(path, name)if os.path.isfile(file_path):# 若是个文件,则获取文件的文件后缀;# 接着若与给定的文件后缀相匹配,则该文件是目标文件。now_file_ext = os.path.splitext(file_path)[-1]if now_file_ext == file_ext:print(f"绝对路径:{os.path.abspath(file_path)}")else:get_ext_file(file_path, file_ext)get_ext_file("D:/Project/Python/BaseProject", ".py")
- 实现思路二:
- 方式二实际上是方式一的另一种实现形式而已。
- 首先我们一定会获取到目录下每个文件的路径,那么路径的本质实际上是一个字符串。
- 若该路径字符串是以指定的后缀字符串结尾的,那么该路径字符串指向的文件就是目标文件。
- 代码实现:获取路径下所有的
.txt文件。 ```python import os
def get_ext_file(path, file_ext): filenames = os.listdir(path) for name in filenames: file_path = os.path.join(path, name) if os.path.isfile(file_path): if os.path.abspath(file_path).endswith(file_ext): print(f”绝对路径:{os.path.abspath(file_path)}”) else: get_ext_file(file_path, file_ext)
get_ext_file(“D:/Project/Python/BaseProject”, “.txt”)
- 实现思路三:可以使用正则表达式,但本质上与思路一、思路二没什么差别,这里就不再过多介绍了。<a name="W8AN6"></a>#### 9.8.3 递归删除文件夹- 实现思路与说明:在9.3.4和9.4.2中分别介绍了删除空目录和删除单个文件的操作,但是没有介绍如何删除一个多级非空目录。- 所谓的多级非空目录,就是指一个目录下还有多个层级的目录,每一级目录下还可能存在0个或多个文件。- 因此要删除最外层的目录是没法直接做到的,需要先进入该目录,将里面所有的文件删除,然后如果遇到子目录,再进到子目录里将里面所有的文件删掉。- 以此类推,层层递进,知道将该文件下所有的内容都删光,即让该目录变成一个空目录,然后就再将这个目录删掉即可。- 代码实现:```pythonimport osdef del_dir(path):# 先对该文件中的子文件或子目录进行操作filenames = os.listdir(path)for name in filenames:file_path = os.path.join(path, name)if os.path.isfile(file_path):# 若是个文件,则删除文件os.remove(file_path)elif os.path.isdir(file_path):# 若是个目录,则继续对该目录进行操作(递归)del_dir(file_path)# 当该目录下所有的子内容都被删除后,删除该目录os.rmdir(path)del_dir("./demo")

若有收获,就点个赞吧
0 人点赞
