- 01. 文件操作基础
- 可以看出这个file是一个迭代器类型的数据
- 读取第一行
- 读取第二行
- 1.4 数据写入操作
- 准备数据。因为写操作只能写入字符,因此需要先将数值型数据转换成整型数据。
- 接着,因为要求每行只能写入一个数字,所以要在数字字符串的后面拼上换行符。
- 对Hello.txt文件的操作。
- 此时文件使用完成后,并没有关闭通道,尝试直接删除文件,会报错。
- 复制文件
- 删除原文件
- 创建学生表.xlsx
- 创建家长表.xlsx
- 3.4 单元格数据插入
- 定位工作簿和单元表
- 插入数据
- 保存修改
- 定位工作簿和单元表
- 插入数据
- 保存修改
- 写入标题
- 写入公式数据
- 设置字体
- 3.6 数据查询
- 定位工作簿和单元表
- 定位单元格并查询数据
- 定位工作簿和单元表
- 按行查询数据
- 定位工作簿和单元表
- 按列查询数据
- 运行前先打开Excel,然后按Ctrl + S保存一次再关闭。
- 定位工作簿和单元表
- 按行查询数据
- 定位工作簿和单元表
- 读取指定列的数据
- 定位工作簿和单元表
- 读取指定列的数据
01. 文件操作基础
1.1 Python文件操作概述
- Python文件操作就是指通过Python程序对文件进行读写行为。
Python文件操作的大致步骤:
Python操作文件的一种方式是使用open()函数建立文件与程序之间的通道。
open()函数格式:
open(文件路径, 文件的操作模式, encoding=文件的编码方式)1.2.2 文件操作模式
Python通过文件的操作模式来决定对文件执行读操作还是写操作,还可以决定是交互文件的字符串内容还是字节串内容。
- 交互字符串内容的操作模式:
- r:只读,即只对文件进行内容读取操作。
- 当文件联系通道建立完成后,文件中的数据就会以行为单位加载到一个迭代器中。
- 因此对这个迭代器进行操作,实际上就是程序在读取文件。
- r模式要求路径对应的文件必须存在。
- w:只写【清空写】。
- 如果路径对应的文件不存在,则会自动创建文件并写入内容;
- 如果路径对应的文件存在,则会先清空文件内原有的所有内容,然后再将数据写入到文件内。
- a:只写【追加写】。
- 如果路径对应的文件不存在,则会自动创建文件并写入内容;
- 如果路径对应的文件存在,则会在文件原有内容的末尾,追加写入新的内容。
- r:只读,即只对文件进行内容读取操作。
交互字节串内容的操作模式:在字符串交互操作模式后面加个b即可,如:rb、wb、ab。
设置编码集主要是针对于字符串交互操作的。因为字符串需要进行编码解码操作,字节串不需要。
只有给字符串指明用哪种编码集进行编解码操作,计算机在对数据进行处理时,才不容易出现乱码。
1.3 文件读取操作
1.3.1 实现准备
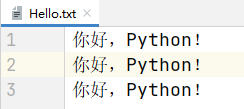
实验文件:在Python源码文件同目录下创建一个Hello.txt文件,在里面写入三行
你好,Python!。
1.3.2 遍历迭代器方式读取数据
- 要对文件进行操作,首先要用open()函数与文件建立通道:
- 路径:./Hello.txt,即当前路径下的Hello.txt文件。
- 软件工程建议使用相对路径,这样整个项目就具有较好的可移植性。
- 操作模式:字符串交互下的只读。
- 编码集:UTF-8 ```python file = open(“./Hello.txt”, ‘r’, encoding=”utf-8”) print(file) # <_io.TextIOWrapper name='./Hello.txt' mode='r' encoding='utf-8'>
- 路径:./Hello.txt,即当前路径下的Hello.txt文件。
可以看出这个file是一个迭代器类型的数据
from collections.abc import Iterator print(isinstance(file, Iterator)) # True
- 连接建立后,由于是用r只读的模式与文件建立连接的,故此时文件的内容已经被读到迭代器变量file中了,对其遍历打印输出即可。- 在完成操作后,记得调用close()函数关闭文件资源。```python# 建立文件通道并读取数据,得到的file是个迭代器。file = open("./Hello.txt", 'r', encoding="utf-8")# 遍历迭代器,输出文件内容for data in file:print(data)# 关闭文件资源file.close()
- 输出内容: ```python 你好,Python!
你好,Python!
你好,Python!
- 可以发现,输出的内容与原Hello.txt中的内容略有差异。这是因为文件中每行文件的末尾都自带了一个换行符,而`print()`函数也自带有换行符,因此每行之间就会多出一个空行来。- 此时,要解决这个问题,只需要取消print()自带的换行即可。```pythonfile = open("./Hello.txt", 'r', encoding="utf-8")for data in file:print(data, end="") # 指定end参数的值为空字符串,取消其换行。file.close()
除了用1.3.2中的迭代器方式读取数据外,还可以调用file的read()函数将文件内的内容一次性读出。
file = open("./Hello.txt", 'r', encoding="utf-8")print(file.read())file.close()
- 运行结果:
你好,Python!你好,Python!你好,Python!
除此之外,还可以传入一个数值类型的参数n,指定读入内容的多少。
file对象.readline()可以逐行从迭代器中读取数据,即按行读取(读取时包含换行符\n)。 ```python file = open(‘./Hello.txt’, ‘r’, encoding=’utf-8’)
读取第一行
l1 = file.readline() print(l1)
读取第二行
l2 = file.readline() print(l2)
file.close()
- 运行结果:```python你好,Python!你好,Python!# 因为readline()读取一行时会带上行尾的换行符,而print()默认也是换行的。# 所以运行时会多一个空行。# 要正常打印只需要指定end参数为空字符""即可。
1.3.5 readlines()按行读取全文
file对象.readlines()是readline()函数的一个扩展,它会按行读取文件中的所有行,然后将所有行数据放到一个列表中。file = open('./Hello.txt', 'r', encoding='utf-8')all_lines = file.readlines()print(all_lines) # ['你好,Python!\n', '你好,Python!\n', '你好,Python!']file.close()
1.4 数据写入操作
1.4.1 数据写入文件的基本流程
首先用
open()函数与文件建立通道,注意写操作的open()与读操作的open()有两个显著的区别:- 写操作的操作模式有两个:清空写入要用w,追加写入要用a。
- 路径指向的文件可以不存在,若文件存在则直接对已经存在的目标文件进行写入操作,若文件不存在则会创建一个空文件进行写入操作。
- 接着调用通道中的一些写入函数,将需要写入的数据写入到指定的文件中。
-
1.4.2 write()写入单个数据
file对象.write(data)函数可以将指定的单个数据内容写入到指定的文件中。代码实现示例1:编写Python程序,在当前目录下创建一个HelloLinux.txt文件,并写入一行数据
你好,Linux!。file = open("./HelloLinux.txt", 'w', encoding="utf-8")file.write("你好,Linux!")file.close()
代码实现示例2:编写Python程序,在Hello.txt内追加写入三行
Hello, Python!。file = open("./Hello.txt", 'a', encoding="utf-8")file.write("\nHello, Python!\nHello, Python!\nHello, Python!")file.close()
1.4.3 writelines()写入多个数据
file对象.writelines(序列)函数可以将一个序列中的所有数据一次性全部写入到指定的文件中。(writelines()写入时不会给每个元素加上换行符\n)- 示例:将0~100中所有的偶数写入到偶数.txt文件中,并且一行只写入一个数字。 ```python file = open(‘./偶数.txt’, ‘w’, encoding=’utf-8’)
准备数据。因为写操作只能写入字符,因此需要先将数值型数据转换成整型数据。
接着,因为要求每行只能写入一个数字,所以要在数字字符串的后面拼上换行符。
even = [str(i) + “\n” for i in range(100) if i % 2 == 0] print(even)
file.writelines(even) file.close()
<a name="ObyUn"></a>### 1.5 文件I/O的其他知识点<a name="ZTKtI"></a>#### 1.5.1 字节模式操作文件- 字符操作常用于输入输出文本数据,而字节操作则常针对于文件、音频、视频等的读写。- 读取操作:- 读取流程:- 建立文件通道(此时只需要指定文件路径和操作模式,不需要指定编码)。- 调用`read()`函数,读取文件中的内容。- 关闭文件通道。- 代码实现:用字节模式读取Hello.txt文件中的内容。```python# 建立文件通道file = open("./Hello.txt", "rb")# 调用read()函数,读取文件中的内容。data = file.read()print(data) # b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8cPython\xef\xbc\x81\r\n\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8cPython\xef\xbc\x81\r\n\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8cPython\xef\xbc\x81\r\nHello, Python!\r\nHello, Python!\r\nHello, Python!'# 关闭文件通道。file.close()
写入操作:
- 写入流程:
- 建立文件通道(此时只需要指定文件路径和操作模式,不需要指定编码)。
- 调用
write()函数,将数据写道到文件中。若这里写入的是字符数据,需要调用数据字符串的encode()函数进行编码。 - 关闭文件通道。
代码实现:用字节模式写入你好到当前目录的打招呼.txt文件中。
file = open("./打招呼.txt", "wb")file.write("你好".encode("utf-8"))file.close()
注意:在字节模式下用
writelines()写入多个数据,且多个数据中有字符类型数据时,所有的字符类型数据都需要进行编码。 ```python file = open(‘./偶数.txt’, ‘wb’)
- 写入流程:
even = [str(i) + “\n” for i in range(100) if i % 2 == 0] even_enc = [i.encode(‘utf-8’) for i in even] # 因为列表中所有的数据都是字符数据,因此所有的数据元素都要编码 print(even_enc)
file.writelines(even_enc) file.close()
<a name="LhATQ"></a>#### 1.5.2 文件复制- 文件复制的本质:在操作系统中复制一份文件分为复制和粘贴两步:- 复制:将文件中的数据及其文件名复制一份。- 粘贴:先在目标文件夹中创建一个相同文件名的文件,然后再将数据写入。- 示例:将D:\Test\1\video.mp4文件复制到D:\Test\2\new_video.mp4。(路径可以自己换成计算机中已有的文件)```pythonimport os # os是系统模块# 定义原路径和目标路径src_path = "D:/Test/1/video.mp4"filename = os.path.basename(src_path) # 获取完整路径中的文件名print(filename) # video.mp4dest_path = f"D:/Test/2/{filename}"# 建立文件通道sfile = open(src_path, "rb")dfile = open(dest_path, "wb")# 实现文件复制data = sfile.read()dfile.write(data)# 关闭文件通道dfile.close()sfile.close()
1.5.3 切断联系的原因
- 在文件处理完成后,若不调用close()关闭文件通道,则在整个程序运行结束前,这个文件的访问都将一直被占用,程序中其他代码将无法对该文件进行访问与操作。
- 示例:读取当前目录下Hello.txt文件的内容,读取完成后不关闭,并尝试直接删除它。 ```python import os
file = open(“./Hello.txt”, “r”, encoding=”utf-8”)
对Hello.txt文件的操作。
data = file.read() print(data)
此时文件使用完成后,并没有关闭通道,尝试直接删除文件,会报错。
os.remove(“./Hello.txt”) # os模块中的remove()函数用于删除指定路径的文件
- 运行结果:```pythonTraceback (most recent call last):File "D:\Project\Python\BaseProject\HelloWorld.py", line 10, in <module>os.remove("./Hello.txt") # os模块中的remove()函数用于删除指定路径的文件PermissionError: [WinError 32] 另一个程序正在使用此文件,进程无法访问。: './Hello.txt'你好,Python!你好,Python!你好,Python!Hello, Python!Hello, Python!Hello, Python!
1.6 with语句
1.6.1 with语句介绍
- 在前面的介绍中,用
open()函数建立的文件通道需要手动调用close()函数进行关闭。 - 在Python中,可以使用
with语句建立文件通道,此时不需要手动调用close()关闭文件通道。 with语句语法格式:(一个with语句后面可以跟上多个open()文件通道)with open(文件路径, 操作模式, 文件编码) as file:对文件的操作
1.6.2 with语句使用实例—文件剪切
文件剪切操作就是在完成文件复制后,将原文件删除。
- 实例:将当前路径下的picture.jpg文件(随便放一张图片即可)剪切到当前目录下的image目录中。 ```python import os
复制文件
src_path = “./picture.jpg” filename = os.path.basename(src_path) dest_path = f”./image/{filename}” with open(src_path, “rb”) as sfile, open(dest_path, “wb”) as dfile: img_data = sfile.read() dfile.write(img_data) dfile.flush() # 刷新加速写入
删除原文件
os.remove(src_path)
<a name="BRlEz"></a>## 02. 对象序列化<a name="tJhYA"></a>### 2.1 序列化介绍- 序列化与反序列化的概念:- 序列化:是指把对象存储到文件中的过程。- 反序列化:是指把对象从文件中读取出来的过程,即序列化的逆过程。- 1.3、1.4中介绍的读写函数无法读写字典、列表、对象等这种序列数据,因此这种读写场景就需要使用序列化与反序列化。- Python序列化工具:- Python中提供了pickle和json两个工具用于序列化列表、字典等这些序列数据。- pickle和json两个都是Python自带的工具库,无需下载,直接导入即可。<a name="amj2i"></a>### 2.2 pickle存储与读取<a name="b9EAA"></a>#### 2.2.1 pickle介绍- pickle是按照字节格式处理数据的,因此在涉及文件I/O时,与文件建立的联系通道应该是字节模式的。- pickle有4个常用函数,主要分为两大类:- 与内存交互:`dumps()`用于把数据存储到内存中、`loads()`用于把数据从内存中读出来。- 与文件交互:`dump()`用于把数据存储到文件中、`load()`用于把数据从文件中读出来。<a name="kwQuL"></a>#### 2.2.2 dumps/loads内存中的读写(用的不多)- `pickle.dumps(序列)`可以用于将序列数据存储到内存中。```pythonimport pickledata = pickle.dumps([10, 20, 30, 40])print(data) # b'\x80\x04\x95\r\x00\x00\x00\x00\x00\x00\x00]\x94(K\nK\x14K\x1eK(e.'# 在内存中以字节形式存储序列
pickle.loads(内存变量)可以用于将内存中的字节序列数据读出来,并反序列化成正常的数据形式。 ```python import pickle
data = pickle.dumps([10, 20, 30, 40]) print(pickle.loads(data)) # [10, 20, 30, 40]
<a name="UdFvJ"></a>#### 2.2.3 dump/load文件中的读写(最常用)- 两个前缀小知识:- pickle操作的是字节格式的数据,因此在建立文件联系通道时使用的是字节模式。- 存放pickle数据的文件后缀一般是`.pkl`。- `pickle.dump(序列, 文件)`可以用于将序列数据存储到指定的`.pkl`文件中。```pythonimport pickledata1 = [12, 34, 56, 78]data2 = {'a': 97, 'b': 98, 'c': 99}with open('./data.pkl', 'wb') as file:pickle.dump(data1, file)pickle.dump(data2, file)
pickle.load(文件)可以用于从指定的.pkl文件中读出字节序列数据,并反序列化成正常的数据形式。 ```python import pickle
with open(‘./data.pkl’, ‘rb’) as file: print(pickle.load(file))
- 运行结果:可以发现就打印了首先写入的data1,后写入的data2并没有被读出来。```python[12, 34, 56, 78]
- 原因分析:
pickle.load(文件)在物理上是写入到磁盘的文件中,但从逻辑上它更像是将数据存储到一个队列中。- 跟据数据结构的知识,队列的特点是先进先出。因此data1是先写入的,故读也是先读data1;data2是后写入的,理所应当的后读data2。
- 当队列中的内容都被读完时,队列就变成了一个空队列,此时若再进行读操作,那就会报错。 ```python import pickle
with open(‘./data.pkl’, ‘rb’) as file: print(pickle.load(file)) # [12, 34, 56, 78] print(pickle.load(file)) # {‘a’: 97, ‘b’: 98, ‘c’: 99} print(pickle.load(file)) # 队列已空,报错:EOFError: Ran out of input
- 补充:- 由于pickle文件读写的这种特点,因此建议在写入多个数据前,先将所有的数据封装到一个大容器中。- 这样在读取时只用固定的读一次,即可避免因为少读造成的数据不完整以及多读的报错问题。```pythonimport pickle# 封装多个数据data = [[12, 34, 56, 78],{'a': 97, 'b': 98, 'c': 99}]# 写入with open('./data.pkl', 'wb') as file:pickle.dump(data, file)# 读取with open('./data.pkl', 'rb') as file:print(pickle.load(file)) # [[12, 34, 56, 78], {'a': 97, 'b': 98, 'c': 99}]
2.3 JSON存储与读取
2.3.1 JSON介绍
- JSON是JavaScript Object Notation — JS对象简谱的缩写,但是JSON中没有涉及到JS的语法,它只是采用了JS中数据的格式而已。
- JSON支持的数据格式:
- JSONArray:即JSON数组,格式为:
[元素1, 元素2, …, 元素N],对应Python的列表。 - JSONObject:即JSON对象,格式为:
{Key1: Value1, Key2, Value2, …, KeyN: ValueN},对应Python的字典。 - string:即字符串,格式为:
'0个或多个字符',对应Python的字符串。 - number:即数值类型,包含整数或者小数。对应Python的int和float。
- boolean:即布尔类型,有true和false两个值,对应Python中的bool。
- null:即空对象,只有一个唯一的值
null,对应Python中的None。
- JSONArray:即JSON数组,格式为:
- JSON是一种轻量级的数据类型,并且从它的数据类型可以看出,它几乎可以兼容所有的编程语言,因此十分适合用于网络数据传输。
Python中的json模块就是用于操作JSON数据的,和pickle一样,josn也有4个常用函数:
json.dumps(obj)可以用于将对象数据obj存储到内存中。- JSON的数据是字符串格式的数据。
- 在将数据转换成JSON数据时,默认对中文数据会进行Unicode编码。 ```python import json
students = [ {‘sid’: 10001, ‘name’: ‘乐乐’}, {‘sid’: 10002, ‘name’: ‘美美’} ]
json_data = json.dumps(students) print(json_data) # [{“sid”: 10001, “name”: “\u4e50\u4e50”}, {“sid”: 10002, “name”: “\u7f8e\u7f8e”}]
- 若要让中文数据保存原有的样子(即不进行编码),只需要将`dumps()`函数的`ensure_ascii`参数的值设置为False即可。```pythonimport jsonstudents = [{'sid': 10001, 'name': '乐乐'},{'sid': 10002, 'name': '美美'}]json_data = json.dumps(students, ensure_ascii=False)print(json_data) # [{"sid": 10001, "name": "乐乐"}, {"sid": 10002, "name": "美美"}]
json.loads(内存变量)可以用于将内存中的JSON数据读出来,并反序列化成正常的数据形式。- 注意,虽然JSON数据的字面量可能和普通数据是一样的。
- 但是JSON一定是字符串类型的数据,而
loads()出来的可能是其他类型的数据。 ```python import json
students = [ {‘sid’: 10001, ‘name’: ‘乐乐’}, {‘sid’: 10002, ‘name’: ‘美美’} ]
json_data = json.dumps(students, ensure_ascii=False)
print(json_data, type(json_data)) # [{“sid”: 10001, “name”: “乐乐”}, {“sid”: 10002, “name”: “美美”}]
data = json.loads(json_data)
print(data, type(data)) # [{‘sid’: 10001, ‘name’: ‘乐乐’}, {‘sid’: 10002, ‘name’: ‘美美’}]
<a name="UJ9op"></a>#### 2.3.3 dump/load文件中的读写(最常用)- 两个前缀小知识:- json操作的是Unicode编码的字符串格式的数据,因此在建立文件联系通道时使用的是字符模式。- 存放JSON数据的文件后缀一般是`.json`。- `json.dump(JSON数据, 文件)`可以用于将JSON数据存储到指定的`.json`文件中。```pythonimport jsonstudents = [{'sid': 10001, 'name': '乐乐'},{'sid': 10002, 'name': '美美'}]json_data = json.dumps(students, ensure_ascii=False)with open('./data.json', 'w', encoding='utf-8') as file:json.dump(students, file, ensure_ascii=False)
json.load(文件)可以用于从指定的.json文件中读出JSON数据,并反序列化成正常的数据形式。 ```python import json
with open(‘./data.json’, ‘r’, encoding=’utf-8’) as file:
data = json.load(file)
print(data, type(data)) # [{‘sid’: 10001, ‘name’: ‘乐乐’}, {‘sid’: 10002, ‘name’: ‘美美’}]
<a name="ut5wI"></a>## 03. Python操作Excel、CSV<a name="yRFZ4"></a>### 3.1 CSV文件操作<a name="rrfPR"></a>#### 3.1.1 CSV介绍- CSV的文件结构与Excel的文件结构十分类似,都是一行一行来存储信息的。- Excel里一行中不同列的数据之间是以不同的单元格来区分的,而CSV则是用逗号分割的,因此CSV也称为逗号分隔值文件。- CSV是一种纯文本文件,几乎所有的编程语言都是支持与纯文本文件进行交互,所以CSV的支持性比Excel好,但是在其他领域中Excel的占比是比较高的,因此CSV一般作为数据库、Excel表格数据导入导出的数据交换文件存在。- Python官方提供了`csv`模块用于操作CSV文件。<a name="by4bX"></a>#### 3.1.2 CSV基本写入- 前置知识:CSV格式的文件后缀为`.csv`- `csv.writer(file)`可以获取一个文件的handle对象,这个对象中封装了对指定CSV文件的各种操作。```pythonimport csvwith open('./student.csv', 'w', encoding='utf-8') as file:handle = csv.writer(file)
handle.writerow(data)可以用于写入一行数据。(data一般是一个一维序列) ```python import csv
with open(‘./student.csv’, ‘w’, encoding=’utf-8’) as file: handle = csv.writer(file) handle.writerow([‘学号’, ‘姓名’, ‘成绩’])
- student.csv文件的内容: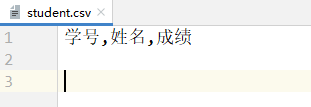- `handle.writerows(data)`可以用于写入一行数据。(data一般是一个二维序列)```pythonimport csvwith open('./student.csv', 'w', encoding='utf-8') as file:handle = csv.writer(file)handle.writerow(['学号', '姓名', '成绩'])handle.writerows([[10001, '乐乐', 80],[10002, '欢欢', 86],[10003, '莱莱', 75]])
- student.csv文件的内容:
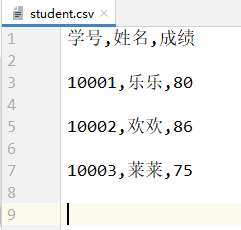
- 可以发现,写入多行数据时每两行数据之间会有一行多余的空行,这是由以下两个原因造成的:
- 因为
open()中有一个newline参数,在操作文件时若没有手动指定这个参数,那么它默认就是\n。 - csv模块在写入数据是自带一个
\n。
- 因为
- 解决方式:
- 这两个原因结合在一起,就会导致一个写入操作完成时,会先进行两次换行,再写入新的数据。
- 因此只需要干掉两个
\n中的其中一个,就不会再有空行了。(一般来说将open()中的newline参数指定为空即可) ```python import csv
with open(‘./student.csv’, ‘w’, encoding=’utf-8’, newline=’’) as file: handle = csv.writer(file) handle.writerow([‘学号’, ‘姓名’, ‘成绩’]) handle.writerows([ [10001, ‘乐乐’, 80], [10002, ‘欢欢’, 86], [10003, ‘莱莱’, 75] ])
- student.csv文件的内容: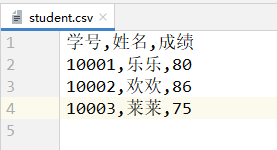<a name="m5E3l"></a>#### 3.1.3 CSV分隔符设置- 在3.1.2中介绍的所有效果中,一行中不同的数据之间使用逗号`,`分割的,这是因为CSV文件默认的分隔符就是逗号。- 可以通过在`writer()`获取handle时指定delimiter参数的值来指定CSV文件的分割符。- 示例:将student.csv文件的分隔符设置为分号`;`。```pythonimport csvwith open('./student.csv', 'w', encoding='utf-8', newline='') as file:handle = csv.writer(file, delimiter=';')handle.writerow(['学号', '姓名', '成绩'])handle.writerows([[10001, '乐乐', 80],[10002, '欢欢', 86],[10003, '莱莱', 75]])
- student.csv文件的内容:
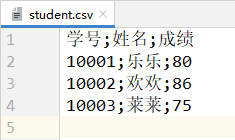
3.1.4 以字典形式写入数据
- 字典类型的handle需要通过
csv.DictWriter()函数获取,需要指定两个参数:- f:写入的CSV文件路径。
- fieldnames:字典数据的键。 ```python import csv
with open(‘./student.csv’, ‘w’, encoding=’utf-8’, newline=’’) as file: dict_handle = csv.DictWriter( f=file, fieldnames=[‘学号’, ‘姓名’, ‘年龄’] )
- `handle.writeheader()`可以写入CSV表的表头数据。对于字典形式写入而言,实际上就是将`DictWriter()`函数中设置的fieldnames参数值写入CSV文件。```pythonimport csvwith open('./student.csv', 'w', encoding='utf-8', newline='') as file:dict_handle = csv.DictWriter(f=file, fieldnames=['学号', '姓名', '年龄'])dict_handle.writeheader()
- student.csv文件的内容:
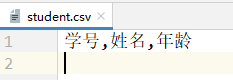
- 两个写入函数:
handle.writerow(data)可以写入一行数据。(data在这里是一个字典数据)handle.writerows(data)可以写入多行数据。(data在这里是一个由多个字典组成的序列)
- 示例: ```python import csv
with open(‘./student.csv’, ‘w’, encoding=’utf-8’, newline=’’) as file: dict_handle = csv.DictWriter(f=file, fieldnames=[‘学号’, ‘姓名’, ‘年龄’]) dict_handle.writeheader()
# 写入一行数据(单个字典)dict_handle.writerow({'学号': 10001, '姓名': '欢欢', '年龄': 20})# 写入多行数据(字典序列)dict_handle.writerows([{'学号': 10002, '姓名': '开开', '年龄': 23},{'学号': 10003, '姓名': '乐乐', '年龄': 18},{'学号': 10004, '姓名': '涛涛', '年龄': 25},{'学号': 10005, '姓名': '美美', '年龄': 19},])
- student.csv文件的内容: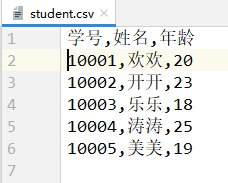<a name="wax4j"></a>#### 3.1.5 CSV文件数据读取- CSV文件读取思路:- 使用`open()`建立程序与CSV文件的联系。- 使用`csv.reader(file)`获取一个迭代器,文件file中的数据就是按行封装成一个列表,存储在这个迭代器中的。- 遍历这个迭代器,获取每一行数据。- 示例:读取student.csv文件中的数据。```pythonimport csvwith open('./student.csv', 'r', encoding='utf-8') as file:# delimiter参数指定的是行中列的分隔符,缺省为逗号","# 分隔符使用缺省值可以不指定delimiter参数,但是若分隔符是其他符号则必须要指定delimiter参数reader = csv.reader(file, delimiter=",")# 遍历得到数据for data in reader:print(data, type(data))"""运行结果:['学号', '姓名', '年龄'] <class 'list'>['10001', '欢欢', '20'] <class 'list'>['10002', '开开', '23'] <class 'list'>['10003', '乐乐', '18'] <class 'list'>['10004', '涛涛', '25'] <class 'list'>['10005', '美美', '19'] <class 'list'>"""
- 使用
csv.DictReader(file)可以获取到一个字典类型的迭代器。- 这个迭代器会将文件中的第一行数据解析为键,同一列的数据解析为键对应的值,然后封装成一个字典。
- 这种类型的迭代器更方便进行数据处理,因此推荐使用
DictReader()读取数据。 ```python import csv
with open(‘./student.csv’, ‘r’, encoding=’utf-8’) as file: reader = csv.DictReader(file) for data in reader: print(data, type(data))
“””
运行结果:
{‘学号’: ‘10001’, ‘姓名’: ‘欢欢’, ‘年龄’: ‘20’}
<a name="sH4zk"></a>### 3.2 Excel的认识与工作簿操作<a name="s7lv1"></a>#### 3.2.1 Excel介绍- Excel是微软开发的一款电子表格办公软件,用二维表(数据采用行和列的形式组织)的形式组织数据。- Excel文件结构:- 一个Excel文件(后缀为".xlsx"的文件)被称为一个工作簿;- 一个工作簿由多个Sheet(工作单元表)组成;- 一个Sheet中有多个行与多个列;- 一个确定的行与一个确定的列组合确定了一个Cell(单元格)。- Excel是数据分析中常用的一款数据工具,因此学习如何用Python程序与Excel交互是一项十分重要的技能。- Python没有提供直接操作Excel的工具,因此需要安装第三库openpyxl。```pythonpip install openpyxl
3.2.2 工作簿的创建
- 工作簿(Excel)创建流程:
- 导入openpyxl模块。
- 调用openpyxl模块中的Workbook()函数创建一个工作簿对象。
- 调用工作簿对象的save(file_path)保存为一个实际的Excel文件,其中file_path表示生成的Excel文件完整的路径名。
- 注意:当file_path对应的Excel文件已经被打开时,save()函数执行会报错。
- 代码实现:在当前目录的excel目录中创建一个名为
学生表.xlsx和名为家长表.xlsx的Excel文件。 ```python import openpyxl
创建学生表.xlsx
student_workbook = openpyxl.Workbook() # 创建工作簿对象 student_workbook.save(“./excel/学生表.xlsx”) #命名保存
创建家长表.xlsx
parent_workbook = openpyxl.Workbook() # 创建工作簿对象 parent_workbook.save(“./excel/家长表.xlsx”) #命名保存
- 运行完成后,在excel目录中会出现学生版.xlsx和家长表.xlsx文件,这两个文件中都带有一个默认的单元表Sheet。<a name="fgk3f"></a>#### 3.2.3 工作簿的删除- 工作簿本质上还是计算机中的一个文件,要删除一个工作簿与删除一个普通的计算机文件没有任何区别。- 示例:删除家长表.xlsx文件。```pythonimport osos.remove("./excel/家长表.xlsx")
3.2.4 读入已存在的工作簿
- 采用openpyxl模块中的load_workbook(file_pach)函数可以读入指定路径下已存在的工作簿。 ```python import openpyxl
workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”)
print(workbook) #
- 注意,后续对单元表、单元格的各种操作,都是针对工作簿对象workbook的,且workbook即可以是创建出来的,也可以是导入进来的,操作上没有任何区别。<a name="pBtHg"></a>### 3.3 单元表的相关操作<a name="guTtt"></a>#### 3.3.1 当前工作簿中所有单元表- 采用`工作簿对象.sheetnames`可以获取到当前工作簿中所有的单元表的表名构成的列表。- 一般情况下,初始只有一个单元表Sheet。```pythonimport openpyxlstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")sheet_names = student_workbook.sheetnamesprint(sheet_names) # ['Sheet']
- 采用
工作簿对象.worksheets可以获取到当前工作簿中所有的单元表对象构成的列表。 ```python import openpyxl
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”)
worksheet_list = student_workbook.worksheets
print(worksheet_list) # [
<a name="oAkTo"></a>#### 3.3.2 定位单元表- 根据索引获取单元表:通过索引`工作簿对象.worksheets`中的元素可以获取指定的单元表对象。```pythonimport openpyxlstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")worksheet_0 = student_workbook.worksheets[0]print(worksheet_0) # <Worksheet "Sheet">
- 根据单元表名获取单元表:使用
工作簿对象[单元表表名]的方式可以获取到指定名称的单元表对象。 ```python import openpyxl
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”)
worksheet_0 = student_workbook[“Sheet”]
print(worksheet_0) #
<a name="Pf4DY"></a>#### 3.3.3 修改单元表表名- 采用`单元表对象.title = 单元表名`的方式可以修改指定单元表的表名。- 注意:对工作簿中任何内容做出任何修改时,都要调用`工作簿对象.save(file_path)`函数进行保存;否则修改不生效。```pythonimport openpyxlstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")worksheet_0 = student_workbook["Sheet"]worksheet_0.title = "学生名单"print(worksheet_0) # <Worksheet "学生名单">student_workbook.save("./excel/学生表.xlsx")
此时打开”./excel/学生表.xlsx”对应的文件,会发现学生表.xlsx底部的Sheet单元表消失了,取而代之的是“学生名单”。
3.3.4 新建单元表
采用
单元表对象变量 = 工作簿对象.create_sheet("单元表表名", 索引)的方式创建新的单元表,并且会返回对应的单元表对象。- 索引就是sheetnames列表中的索引,从0开始(Sheet就是默认索引为0的单元表)。 ```python import openpyxl
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”)
score_table = student_workbook.create_sheet(“考试成绩”, 1)
contact_inf = student_workbook.create_sheet(“学生家庭联系方式”, 2)
print(student_workbook.worksheets) # [
student_workbook.save(“./excel/学生表.xlsx”)
- 此时打开"./excel/学生表.xlsx"对应的文件,会发现学生表.xlsx底部多了考试成绩表和学生家庭联系方式表两张单元表。- 修改工作簿的操作不会影响未操作的数据,因此学生名单单元表依旧存在,且及其中的数据不会发生任何改变(若有数据的话)。<a name="penUB"></a>#### 3.3.5 删除单元表- 采用`工作簿对象.remove(单元表对象)`的方式删除指定的单元表。```pythonimport openpyxlstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")print(student_workbook.sheetnames) # ['学生名单', '考试成绩', '学生家庭联系方式']# 删除考试成绩表和学生家庭联系方式表score_table = student_workbook["考试成绩"]student_workbook.remove(score_table)contact_inf = student_workbook["学生家庭联系方式"]student_workbook.remove(contact_inf)print(student_workbook.sheetnames) # ['学生名单']student_workbook.save("./excel/学生表.xlsx")
此时打开”./excel/学生表.xlsx”对应的文件,会发现学生表.xlsx底部只有学生名单表了,考试成绩表和学生家庭联系方式表被删除了。
3.4 单元格数据插入
3.4.1 插入一个Cell的数据
Cell(单元格)插入数据流程:
- 获取单元表。
- 在单元表的指定单元格内插入数据,有以下两种方式。
- 单元格的行索引和列索引都是从1开始依次递增的,故可以用
单元表对象.cell(行索引, 列索引, 数据)的方式插入数据。 - 列除了用数字索引外,还可以用A、B、C这样的方式表示,故可以用
单元表对象["B1"] = 数据的方式插入数据。
- 单元格的行索引和列索引都是从1开始依次递增的,故可以用
- 实例:在学生名单单元表中,用第一种方式在第1行第1列中插入字符串数据“学号”,然后用第二种方式在下面两行插入两个学号。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
插入数据
student_list.cell(1, 1, “学号”) student_list[“A2”] = 1001 student_list[“A3”] = 1002
保存修改
student_workbook.save(“./excel/学生表.xlsx”)
<a name="hMsst"></a>#### 3.4.2 修改单元格中的数据- 修改单元格的数据实际上就是再向指定的单元格内插入一次数据,依旧调用cell()函数。- 示例:将A2单元格中的数据改为1003```pythonimport openpyxl# 定位工作簿和单元表student_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 修改单元格的数据student_list["A2"] = 1003# 保存修改student_workbook.save("./excel/学生表.xlsx")
3.4.3 插入一整行数据
- 实现思路:
- 可以将一整行中的所有数据封装成一个列表。
- 然后遍历这个列表的enumerate()对象,可以获取到列表中的所有数据以及其对应的索引。
- 用cell()函数插入数据,一般来说一整行数据的行是固定的,每个数据的列也和其索引位置有着直接的关系。
- 代码实现:在Excel的第一行添加数据标题即:学号、姓名、年龄、性别、班级,然后在第二行插入一行数据:1001、Dosbo、20、男、软件工程2022。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
插入数据
titles = [“学号”, “姓名”, “年龄”, “性别”, “班级”] for position, title in enumerate(titles): student_list.cell(1, position + 1, title) # 行固定为1,列为索引值加一。
datas = [1001, “Dosbo”, 20, “男”, “软件工程2022”] for position, data in enumerate(datas): student_list.cell(2, position + 1, data) # 行固定为2,列为索引值加一。
保存修改
student_workbook.save(“./excel/学生表.xlsx”)
<a name="h4ojm"></a>#### 3.4.4 插入多行数据- 实现思路:- 一行数据采用一个一维列表封装,那么多行数据固然采用二维列表进行封装(表头标题也可以封装进来)。- 首先遍历外层的enumerate(),会得到内层列表的索引值以及一整行数据。- 接着再遍历内层的enumerate(),就可以获取具体的数据值以及其在内层列表中的索引。- 外层列表的索引往往对应着行,内层列表的索引则往往对应着列。既然行、列、数据都拿到了,那么直接用cell()函数插入数据即可。- 实例:向Excel中插入如下数据:}2SZXH5IJ]K@Q.png](https://cdn.nlark.com/yuque/0/2022/png/2692415/1665469123385-ab134c7e-9b2b-475d-88be-ee0f07d8238e.png#averageHue=%23d7d7d7&clientId=ucb1218c4-c699-4&from=paste&height=86&id=u2c236bab&originHeight=91&originWidth=637&originalType=binary&ratio=1&rotation=0&showTitle=false&size=7275&status=done&style=none&taskId=uc999bbf5-caa3-4f3c-8233-811616a626d&title=&width=600)- 代码实现:```pythonimport openpyxl# 定位工作簿和单元表student_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 封装数据datas = [["学号", "姓名", "年龄", "性别", "班级", "计算机科学导论", "软件工程导论", "大数据导论"],[1001, "Dosbo", 20, "男", "软件工程2022", 89, 72, 61],[1002, "Adam", 21, "男", "计科2022", 82, 89, 51],[1003, "Mark", 23, "男", "软件工程2019", 91, 75, 60],[1004, "Mary", 20, "女", "大数据2022", 95, 82, 71]]# 插入数据for line, line_data in enumerate(datas):for column, data in enumerate(line_data):student_list.cell(line + 1, column + 1, data)# 保存修改student_workbook.save("./excel/学生表.xlsx")
3.4.5 插入公式数据
- 目标效果:

- 实现思路:
- 以表中I2单元格为例,其公式为:
=SUM(F2:H2)。 - 因此可以推断出,I2~I5单元格的公式为
=SUM(F{line}:H{line})。 - 因此只需要定位到目标单元格,然后将公式写进去即可。
- 以表中I2单元格为例,其公式为:
- 实现思路:(这里仅仅插入I列,A~H列的基本数据写入在3.4.4中已经实现) ```python import openpyxl
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
写入标题
student_list[“I1”] = “总成绩”
写入公式数据
for line in range(2, 6): student_list[f”I{line}”] = f”=SUM(F{line}:H{line})”
student_workbook.save(“./excel/学生表.xlsx”)
<a name="BXogA"></a>### 3.5 单元表样式设计<a name="U44Is"></a>#### 3.5.1 行高与列宽设置- `单元表对象.row_dimensions[line].height = h`可以将单元表中第line行的行高设置为h。- `单元表对象.column_dimensions[col].width = w`可以将单元表中第col列的列宽设置为w。- 示例:将学生表.xlsx文件中的学生名单表的第3行的行高设置为30,第B列的列宽设置为20。```pythonimport openpyxlstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]student_list.row_dimensions[3].height = 30student_list.column_dimensions['B'].width = 20student_workbook.save("./excel/学生表.xlsx")
3.5.2 字体设置
- 单元格字体的设置思路:
- 字体首先要构造
openpyxl.styles.Font对象,这个对象常用的构造参数有:- name:字体名称
- size(或sz):字号大小
- bold(或b):是否加粗
- italic(或i):是否斜体
- charset:编码集
- color:颜色(一般用的十六进制颜色数据)
- 接着就是要定位单元格,依旧使用
cell()函数,只不过此时只需要指定单元格的行标和列表,不需要设置内容。 - 最后,只要将单元格的
font属性指定为构造的Font对象即可。
- 字体首先要构造
- 示例:将第4行第3列的单元格设置为楷体、18号字、颜色为ad4e2f、加粗、斜体。 ```python import openpyxl from openpyxl.styles import Font
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
设置字体
student_list.cell(4, 3).font = Font(name=”楷体”, size=18, color=”ad4e2f”, bold=True, italic=True)
student_workbook.save(“./excel/学生表.xlsx”)
<a name="uOoNZ"></a>#### 3.5.3 对其模式设置- 单元格对其模式的设置思路:- 对其模式首先要构造`openpyxl.styles.Alignment`对象,这个对象常用的构造参数有:- horizontal:横向对其模式,常用的值有:left左对齐、center居中对齐、right右对齐。- vertical:纵向对其模式,常用的值有:top顶部对齐、center居中对齐、bottom底部对齐。- 接着就是使用`cell()`函数定位单元格。- 最后,将单元格的`alignment`属性指定为构造的`Alignment`对象即可。- 示例:将第4行第3列的单元格设置为横向居中对齐,纵向顶部对齐。```pythonimport openpyxlfrom openpyxl.styles import Alignmentstudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 设置对其模式student_list.cell(4, 3).alignment = Alignment(horizontal="center", vertical="top")student_workbook.save("./excel/学生表.xlsx")
3.5.4 边框设置
设置边框首先要设置边对象(
openpyxl.styles.Side对象),Side对象有以下两个属性:style:边样式,其值包括:
style = NoneSet(values=('dashDot','dashDotDot', 'dashed','dotted','double','hair', 'medium', 'mediumDashDot', 'mediumDashDotDot','mediumDashed', 'slantDashDot', 'thick', 'thin'))
color:边颜色,一般用的十六进制颜色数据。
- 示例:构造一条样式为mediumDashDot的黑边。 ```python from openpyxl.styles import Border, Side
side = Side(style=’mediumDashDot’, color=’000000’)
- 单元格边框设置思路:- 对其模式首先要构造`openpyxl.styles.Border`对象,这个对象有以下四个基本属性:- left:边框左边。- right:边框右边。- top:边框底边。- bottom:边框顶边。- 这四个边参数都可以指定为`openpyxl.styles.Side`的对象。- 接着就是使用`cell()`函数定位单元格,并将其`border`属性指定为构造的`Border`对象即可。- 示例:为第4行第3列的单元格设置边框,样式为:顶边与底边为dashDotDot的红边,左边与右边为mediumDashDot的黑边。```pythonimport openpyxlfrom openpyxl.styles import Border, Sidestudent_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 定义边red_side = Side(style='dashDotDot', color='ff0000')black_side = Side(style='mediumDashDot', color='000000')# 设置边框student_list.cell(4, 3).border = Border(top=red_side, bottom=red_side,left=black_side, right=black_side)student_workbook.save("./excel/学生表.xlsx")
3.6 数据查询
3.6.1 读取指定单元格的数据
- 查询指定单元格的数据很简单,只需要先定位到具体的单元格对象,然后调用
单元格对象.value属性即可。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
定位单元格并查询数据
cell_d4 = student_list[“D4”] print(cell_d4.value) # 男
cell_2_2 = student_list.cell(2, 2) print(cell_2_2.value) # Dosbo
<a name="crRyt"></a>#### 3.6.2 查询单元表中数据的规模- 调用`单元表对象.max_row`可以获取单元表中数据的总行数(数据间的空行也算)。- 调用`单元表对象.max_column`可以获取单元表中数据的总列数(数据间的空行也算)。```pythonimport openpyxl# 定位工作簿和单元表student_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 定位单元表的数据规模print(f"学生名单表的数据总行数为:{student_list.max_row}") # 学生名单表的数据总行数为:5print(f"学生名单表的数据总列数为:{student_list.max_column}") # 学生名单表的数据总列数为:9
3.6.3 按行查询工作簿中的数据
实现思路:
采用
单元表对象.rows可以以行为单位获取到工作簿中的所有数据。- 每一行数据被封装成一个元组。
- 元组中的每个元组都是一个Cell对象,格式为:
<Cell 单元表表名.单元格位置>。(<Cell '学生名单'.A1>, <Cell '学生名单'.B1>, <Cell '学生名单'.C1>, <Cell '学生名单'.D1>, <Cell '学生名单'.E1>)
遍历行元组中的每一个Cell,再调用Cell对象中的value属性,就可以获取到单元格的实际数据。
- 代码实现:按行查询学生表.xlsx文件中学生名单表中的数据。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
按行查询数据
for row_data in student_list.rows: for cell in row_data: print(cell.value, end=’\t’) print()
- 运行结果:```python学号 姓名 年龄 性别 班级 计算机科学导论 软件工程导论 大数据导论 总成绩1001 Dosbo 20 男 软件工程2022 89 72 61 =SUM(F2:H2)1002 Adam 21 男 计科2022 82 89 51 =SUM(F3:H3)1003 Mark 23 男 软件工程2019 91 75 60 =SUM(F4:H4)1004 Mary 20 女 大数据2022 95 82 71 =SUM(F5:H5)
3.6.4 按列查询工作簿中的数据
实现思路:采用
单元表对象.columns可以以列为单位获取到工作簿中的所有数据,其他与按行查询一样。(<Cell '学生名单'.A1>, <Cell '学生名单'.A2>, <Cell '学生名单'.A3>, <Cell '学生名单'.A4>, <Cell '学生名单'.A5>)
代码实现:按列查询学生表.xlsx文件中学生名单表中的数据。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
按列查询数据
for column_data in student_list.columns: for cell in column_data: print(cell.value, end=’\t’) print()
- 运行结果:```python学号 1001 1002 1003 1004姓名 Dosbo Adam Mark Mary年龄 20 21 23 20性别 男 男 男 女班级 软件工程2022 计科2022 软件工程2019 大数据2022计算机科学导论 89 82 91 95软件工程导论 72 89 75 82大数据导论 61 51 60 71总成绩 =SUM(F2:H2) =SUM(F3:H3) =SUM(F4:H4) =SUM(F5:H5)
3.6.5 读取公式单元格的数据
- 不管在3.6.3还是3.6.4中,读取到I列总成绩时,显示都是单元格中的公式,而不是公式计算得到的结果。
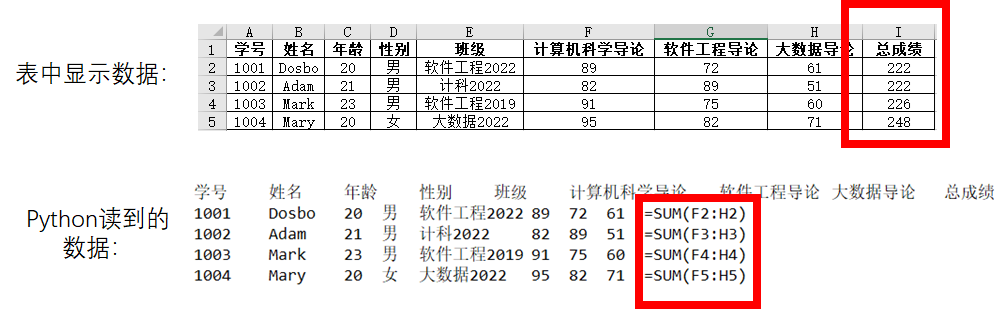
- 读取实际数据的操作:
- 打开需要读取的目标Excel文件,然后按Ctrl + S保存。(必须做,是一个BUG)
- 然后将
load_workbook()函数中的data_only参数值设置为True。 - 接着即可正常读取出公式计算得到的值了。
- 代码实现:
```python
运行前先打开Excel,然后按Ctrl + S保存一次再关闭。
import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”, data_only=True) student_list = student_workbook[“学生名单”]
按行查询数据
for row_data in student_list.rows: for cell in row_data: print(cell.value, end=’\t’) print()
- 运行结果:```python学号 姓名 年龄 性别 班级 计算机科学导论 软件工程导论 大数据导论 总成绩1001 Dosbo 20 男 软件工程2022 89 72 61 2221002 Adam 21 男 计科2022 82 89 51 2221003 Mark 23 男 软件工程2019 91 75 60 2261004 Mary 20 女 大数据2022 95 82 71 248
3.6.6 读取指定列的数据
通过类似于
单元表对象["A1:A5"]的形式可以获取到一列数据,这个数据是一个由多个单元组构成的元组。((<Cell '学生名单'.A1>,), (<Cell '学生名单'.A2>,), (<Cell '学生名单'.A3>,), (<Cell '学生名单'.A4>,), (<Cell '学生名单'.A5>,))
处理思路:
- 遍历外层元组中所有的内层单元组。
- 然后获取每个单元组中0索引位上的元素即可得到这列上的每个Cell对象。
- 再调用value就可得到值。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
读取指定列的数据
for tup_cell in student_list[“A1:A5”]: print(tup_cell[0].value)
<a name="tSxeS"></a>#### 3.6.7 读取指定行的数据- 通过类似于`单元表对象["A1:E1"]`的形式可以获取到一行数据,这个数据是一个单元组。- 这个单元组中的唯一的一个元素就是这一行中所有Cell对象构成的元组。```python((<Cell '学生名单'.A1>, <Cell '学生名单'.B1>, <Cell '学生名单'.C1>, <Cell '学生名单'.D1>, <Cell '学生名单'.E1>),)
- 处理思路:
- 先获取外层元组0索引位的元素,即这一行中所有Cell构成的元组。
- 遍历这个元组中所有的Cell,并调用每个Cell的value就可得到值。 ```python import openpyxl
定位工作簿和单元表
student_workbook = openpyxl.load_workbook(“./excel/学生表.xlsx”) student_list = student_workbook[“学生名单”]
读取指定列的数据
for cell in student_list[“A1:E1”][0]: print(cell.value, end=”\t”)
<a name="MLEJ2"></a>#### 3.6.8 读取指定范围的数据- 通过类似于`单元表对象["A1:E5"]`的形式可以获取到一个连续的范围内的数据。- 这个数据是一个由多个行元组构成的元组,数据格式与处理方式都与2.5.3类似。```pythonimport openpyxl# 定位工作簿和单元表student_workbook = openpyxl.load_workbook("./excel/学生表.xlsx")student_list = student_workbook["学生名单"]# 读取指定范围的数据for row_data in student_list["A1:E5"]:for cell in row_data:print(cell.value, end="\t")print()

若有收获,就点个赞吧
0 人点赞
