题目一:找出影片类型为2种的视频数据
- 题目描述:长视频类型维度表:Tencent_video_cid_cate
- 包含字段:品类category(电视剧、电影等);影片名称cid_nm;影片类型cate(存储形式为:青春;武侠;悬疑等)
![$$L]{68ZNIUL5(O~K@@~HQL.png](/uploads/projects/u2200239@ng1c58/a6582acbe4142c9b38068815c550b75c.png)
- 需求:找出影片类型为2种的视频数据。
- 数据准备:
DROP TABLE IF EXISTS `Tencent_video_cid_cate`;CREATE TABLE IF NOT EXISTS `Tencent_video_cid_cate` (mdate DATE,category VARCHAR(10),cid_nm VARCHAR(20),cate VARCHAR(50));INSERT INTO `Tencent_video_cid_cate` VALUES('20210301', '电视剧', '陈情令', '玄幻;古装'),('20210302', '电影', '长歌行', '爱情;历史古装;武侠');SELECT * FROM `Tencent_video_cid_cate`;
- 数据准备:
- 解决思路:
- 首先,我们可以发现一条记录中,类型字段中不同类型的数据是通过分号
;分割的。 - 那么通过分析关系可以发现,
 ,那么类型为两种的话,就会有一个分号。
,那么类型为两种的话,就会有一个分号。 - 此时,若将类型数据中的所有分号都替换成空字符串
'',那么 。
。 - 即只要找到
 的行,那么该行视频数据中,类型的种类就是两种。
的行,那么该行视频数据中,类型的种类就是两种。
- 首先,我们可以发现一条记录中,类型字段中不同类型的数据是通过分号
- SQL实现: ```sql — 查询出电影名称、电影类型以及去除分号后的电影类型(去除分号即将分号替换成空字符串)。 SELECT cid_nm, cate, REPLACE(cate, ‘;’, ‘’) AS fin_cate FROM tencent_video_cid_cate;
— 过滤出只有一个分号的影片名称。 SELECT cid_nm FROM ( SELECT cid_nm, cate, REPLACE(cate, ‘;’, ‘’) AS fin_cate FROM tencent_video_cid_cate ) AS tmp_mov WHERE CHAR_LENGTH(cate) - CHAR_LENGTH(fin_cate) = 1;
— 根据影片名称,查询影片数据。 SELECT * FROM tencent_video_cid_cate WHERE cid_nm IN ( SELECT cid_nm FROM ( SELECT cid_nm, cate, REPLACE(cate, ‘;’, ‘’) AS fin_cate FROM tencent_video_cid_cate ) AS tmp_mov WHERE CHAR_LENGTH(cate) - CHAR_LENGTH(fin_cate) = 1 );
<a name="yRMps"></a>#### 题目二:客户单量分布情况- 题目描述:现有数据库中揽收表字段如下:- 要求计算创建日期在0501~0531期间的客户的单量分布情况。- 最终得出数据如下: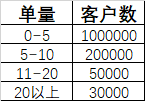- 数据准备:```sqlDROP TABLE IF EXISTS `express_tb`;CREATE TABLE IF NOT EXISTS `express_tb` (`order_id` VARCHAR(255) PRIMARY KEY COMMENT '运单号',`client_id` VARCHAR(255) COMMENT '客户ID',`create_date` DATE COMMENT '创建日期');INSERT INTO `express_tb` VALUES('pno0001', 'cc001', '2022-05-01'),('pno0002', 'cc001', '2022-05-01'),('pno0003', 'cc002', '2022-05-02'),('pno0004', 'cc002', '2022-05-03'),('pno0005', 'cc002', '2022-05-04'),('pno0006', 'cc002', '2022-05-05'),('pno0007', 'cc002', '2022-05-06'),('pno0008', 'cc002', '2022-05-06'),('pno0009', 'cc003', '2022-05-01'),('pno0010', 'cc003', '2022-05-01'),('pno0011', 'cc003', '2022-05-01'),('pno0012', 'cc003', '2022-05-01'),('pno0013', 'cc003', '2022-05-01'),('pno0014', 'cc003', '2022-05-01'),('pno0015', 'cc003', '2022-05-01'),('pno0016', 'cc003', '2022-05-01'),('pno0017', 'cc003', '2022-05-01'),('pno0018', 'cc004', '2022-05-01'),('pno0019', 'cc004', '2022-05-01'),('pno0020', 'cc004', '2022-05-01'),('pno0021', 'cc004', '2022-05-01'),('pno0022', 'cc004', '2022-05-01'),('pno0023', 'cc004', '2022-05-01'),('pno0024', 'cc005', '2022-05-01'),('pno0025', 'cc005', '2022-05-01');SELECT * FROM express_tb;
- 解决思路:
- 首先需要统计出所要求的时间范围内每个用户的下单量。
- 然后,用
IF或者CASE-WHEN结构给下单量进行一个等级划分。 - 最后,按照等级进行分组,然后进行一个客户数量统计即可。
- SQL实现: ```sql — 统计在0501~0531期间每个用户的下单量。 SELECT client_id, COUNT(order_id) AS order_num FROM express_tb WHERE create_date BETWEEN ‘2022-05-01’ AND ‘2022-05-31’ GROUP BY client_id;
— 按照下单量进行分级 SELECT *, CASE WHEN order_num > 20 THEN ‘20以上’ WHEN order_num > 10 THEN ‘11-20’ WHEN order_num > 5 THEN ‘5-10’ ELSE ‘0-5’ END AS order_level FROM ( SELECT client_id, COUNT(order_id) AS order_num FROM express_tb WHERE create_date BETWEEN ‘2022-05-01’ AND ‘2022-05-31’ GROUP BY client_id ) AS tmp;
— 按照下单量等级进行分组,统计每组用户的数量。 SELECT order_level AS 单量, COUNT(client_id) AS 客户数 FROM ( SELECT *, CASE WHEN order_num > 20 THEN ‘20以上’ WHEN order_num > 10 THEN ‘11-20’ WHEN order_num > 5 THEN ‘5-10’ ELSE ‘0-5’ END AS order_level FROM ( SELECT client_id, COUNT(order_id) AS order_num FROM express_tb WHERE create_date BETWEEN ‘2022-05-01’ AND ‘2022-05-31’ GROUP BY client_id ) AS tmp ) AS tmp GROUP BY order_level;
- 进一步完善结果:- 问题描述:根据现有的数据,能够查询出来的就只有两个分段,因为另外两个分段没有相对应的数据。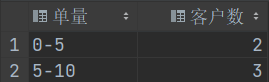- 需求:此时想要把另外两个分段也显示出来,然后客户数显示为0即可。- 实现:```sql-- 首先,可以先制作一张分段表。SELECT '20以上' AS 单量UNIONSELECT '11-20' AS 单量UNIONSELECT '5-10' AS 单量UNIONSELECT '0-5' AS 单量;-- 然后让这张分段表与之前的结果进行连接。-- 需要显示分段表中的所有数据,因此要使用外连接。-- 最后,用IFNULL函数对空的客户数进行一下简单的处理,就可以得到最后的结果。SELECT t2.单量, IFNULL(t1.客户数, 0) AS 客户数 FROM (SELECTorder_level AS 单量,COUNT(client_id) AS 客户数FROM (SELECT *,CASEWHEN order_num > 20 THEN '20以上'WHEN order_num > 10 THEN '11-20'WHEN order_num > 5 THEN '5-10'ELSE '0-5'END AS order_levelFROM (SELECT client_id, COUNT(order_id) AS order_num FROM express_tbWHERE create_date BETWEEN '2022-05-01' AND '2022-05-31'GROUP BY client_id) AS tmp) AS tmpGROUP BY order_level) AS t1 RIGHT OUTER JOIN (SELECT '20以上' AS 单量 UNION SELECT '11-20' AS 单量 UNION SELECT '5-10' AS 单量 UNION SELECT '0-5' AS 单量) AS t2 ON t1.单量 = t2.单量;
题目三:昨天、本周、本月创建的用户
- 业务场景描述:现在有用户表user:
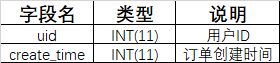
- 数据准备: ```sql — 创建user表 DROP TABLE IF EXISTS user; CREATE TABLE IF NOT EXISTS user ( uid INT(11) PRIMARY KEY AUTO_INCREMENT COMMENT ‘用户ID’, create_time INT(11) COMMENT ‘用户创建时间’ );
— 插入数据(这个数据具有一定的实时性,因此需要手动改一下) INSERT INTO user(create_time) VALUES — 当天的时间:SELECT UNIX_TIMESTAMP(); — 1668434630 (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), (1668434630), — 一天前的时间:SELECT UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 DAY)); — 1668348276 (1668348276), (1668348276), (1668348276), (1668348276), (1668348276), (1668348276), (1668348276), — 上周的时间:SELECT UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 1 WEEK)); — 1667829891 (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), (1667829891), — 10天前的时间:SELECT UNIX_TIMESTAMP(DATE_SUB(NOW(), INTERVAL 10 DAY)); — 1667570721 — 注意:笔记的当前时间是2022/11/13,这些数据为的是创建当月的数据。 — 若阅读笔记时的日期小于10号,请不要使用10天前的时间。 (1667570721), (1667570721), (1667570721), (1667570721), (1667570721);
— 验证插入 SELECT * FROM user;
- 需求1:写SQL取出昨天、本周、本月创建的用户数,输出如下结果:```sql-- 为了方便阅读,将时间戳数据转换成正常的时间格式数据。SELECT *, FROM_UNIXTIME(create_time) AS date_time FROM user;-- 标记数据的时间范围SELECT*,IF(DATEDIFF(NOW(), date_time) = 1, 1, 0) AS yesterday_tag, -- 判断数据是否是昨天,若是则标记为1,否则标记为0IF(WEEK(date_time, 1) = WEEK(NOW(), 1), 1, 0) AS week_tag, -- 判断数据是否是本周IF(MONTH(date_time) = MONTH(NOW()), 1, 0) AS month_tag -- 判断数据是否是本月FROM (SELECT *, FROM_UNIXTIME(create_time) AS date_time FROM user) AS tmp;-- 对每个时间段的tag进行求和,得到最后的结果SELECTSUM(IF(DATEDIFF(NOW(), date_time) = 1, 1, 0)) AS '昨天',SUM(IF(WEEK(date_time, 1) = WEEK(NOW(), 1), 1, 0)) AS '本周',SUM(IF(MONTH(date_time) = MONTH(NOW()), 1, 1)) AS '本月'FROM (SELECT *, FROM_UNIXTIME(create_time) AS date_time FROM user) AS tmp;
- 需求2:写SQL取出昨天、本周、本月创建的用户数,输出如下结果:
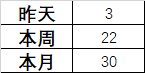
-- 这道题需要多次用到需求1的SQL语句,因此可以先将需求1的SQL保存成一个视图。-- 视图在07. MySQL高级操作中有介绍CREATE VIEW v_date AS (SELECTSUM(IF(DATEDIFF(NOW(), date_time) = 1, 1, 0)) AS '昨天',SUM(IF(WEEK(date_time, 1) = WEEK(NOW(), 1), 1, 0)) AS '本周',SUM(IF(MONTH(date_time) = MONTH(NOW()), 1, 1)) AS '本月'FROM (SELECT *, FROM_UNIXTIME(create_time) AS date_time FROM user) AS tmp);SELECT * FROM v_date;-- 接着,将昨天、本周、本月的数据分别查询出来。-- 然后用UNION连接到一起,就可以实现纵向的效果。SELECT '昨天' AS date, 昨天 AS num FROM v_dateUNIONSELECT '本周' AS date, 本周 AS num FROM v_dateUNIONSELECT '本月' AS date, 本月 AS num FROM v_date;
- 需求3:写SQL取出最近3天创建的用户数量,输出如下结果:
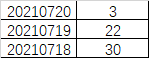
-- 最近三天指:前天、昨天、今天-- 三天之内指:今天、明天、后天-- 将时间戳数据转换成正常的时间格式数据,并保存视图。CREATE VIEW v_user AS SELECT *, FROM_UNIXTIME(create_time) AS date_time FROM user;SELECT * FROM v_user;-- 筛选出三天内的用户数据,把三天之前的数据过滤掉。-- 并把时间格式化成表中的格式。-- 为了方便后续的操作,可以将这一步的结果保存视图。CREATE VIEW v_three_day AS (SELECT*,DATE_FORMAT(date_time, '%Y%m%d') AS timeFROM v_user WHERE DATEDIFF(NOW(), date_time) <= 2);SELECT * FROM v_three_day;-- 统计每一段用户数量,即可得到结果SELECTtime,COUNT(*) AS numFROM v_three_dayGROUP BY time;-- 最后,简单处理一下显示的数据即可。SELECTt1.time,IFNULL(t2.num, 0) AS numFROM (SELECT DATE_FORMAT(NOW(), '%Y%m%d') AS timeUNIONSELECT DATE_FORMAT(DATE(DATE_SUB(NOW(), INTERVAL 1 DAY)), '%Y%m%d') AS timeUNIONSELECT DATE_FORMAT(DATE(DATE_SUB(NOW(), INTERVAL 2 DAY)), '%Y%m%d') AS time) AS t1 LEFT OUTER JOIN (SELECT time, COUNT(*) AS numFROM v_three_day GROUP BY time) AS t2 ON t1.time = t2.time;
题目四:购买平台人数分布
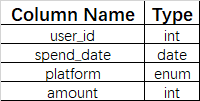
- 题目描述:现有支出表:
- 表描述:
- 这张表记录了用户在一个在线购物网站的支出历史。
- 该在线购物平台同时拥有桌面端(‘desktop’)和手机端(‘mobile’)的应用程序。
- 这张表的主键是(‘user_id’, ‘spend_date’, ‘plotform’)。
- 平台列platform是一种ENUM,类型为(‘desktop’, ‘mobile’)。
- 需求:写一段SQL来查找每天仅使用手机端用户、仅使用桌面端用户、同时使用桌面端和手机端的用户人数。
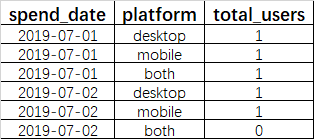
- 结果:
- 在2019-07-01,用户1同时使用桌面端和手机端购买;用户2仅使用了手机端购买;用户3仅使用了桌面端购买。
- 在2019-07-02,用户2仅使用了手机端购买;用户3仅使用了桌面端购买;且没有用户同时使用桌面端和手机端购买。
- 数据准备: ```sql — 创建spending表 DROP TABLE IF EXISTS spending; CREATE TABLE IF NOT EXISTS spending ( user_id INT COMMENT ‘用户ID’, spend_date DATE COMMENT ‘消费时间’, platform ENUM(‘desktop’, ‘mobile’) COMMENT ‘使用平台’, amount INT COMMENT ‘支出金额’, PRIMARY KEY(user_id, spend_date, platform) );
— 插入数据 INSERT INTO spending VALUES (1, ‘2019-07-01’, ‘mobile’, 100), (1, ‘2019-07-01’, ‘desktop’, 100), (2, ‘2019-07-01’, ‘mobile’, 100), (2, ‘2019-07-02’, ‘mobile’, 100), (3, ‘2019-07-01’, ‘desktop’, 100), (3, ‘2019-07-02’, ‘desktop’, 100);
— 验证查询 SELECT * FROM spending;
- 解决思路:- 步骤一:- 总的来说该需求需要的是每天平台的消费用户,并且平台需要区分的出仅desktop、仅mobile、both三类。- 要得到这些,首先就需要得到每天每个用户的消费平台(即根据日期和用户ID进行分类,然后用GROUP_CONCAT()函数聚合当天该用户的所有消费平台)。- 步骤二:- 接着,若最终结果是both的,那么聚合的结果是`desktop,mobile`。- 换言之,就是聚合的结果中若存在逗号`,`,那么就有个将聚合的结果替换成`both`- 步骤三:- 可能有些天里有些平台没有用户使用,但是在结果中,这部分数据是显示出来的,只不过显示为0而已。- 此时就需要去造表以显示完整的表结构。- 步骤四:将步骤三与步骤二的结果进行连接,然后再做数据聚合即可统计完成total_user的数据。- SQL实现:```sql-- 聚合每天每个用户的消费平台。CREATE VIEW v_spend AS (SELECTspend_date,user_id,GROUP_CONCAT(platform) AS platformFROM spendingGROUP BY spend_date, user_id);SELECT * FROM v_spend;-- 将有两个平台的聚合结果替换成bothSELECTspend_date,user_id,IF(INSTR(platform, ','), 'both', platform) AS platformFROM v_spend;-- 造表显示完整的结构CREATE VIEW v_platform AS (SELECT DISTINCT spend_date, 'both' AS platform FROM spendingUNIONSELECT DISTINCT spend_date, 'mobile' AS platform FROM spendingUNIONSELECT DISTINCT spend_date, 'desktop' AS platform FROM spendingORDER BY spend_date, platform DESC);SELECT * FROM v_platform;-- 接着将结构表与步骤二进行连接。-- 然后再聚合数据即可统计完成total_user的数据。SELECTp.spend_date,p.platform,COUNT(user_id) AS total_usersFROM v_platform AS pLEFT OUTER JOIN (SELECT spend_date, user_id,IF(INSTR(platform, ','), 'both', platform) AS platformFROM v_spend) AS tON p.spend_date = t.spend_date AND p.platform = t.platformGROUP BY p.spend_date, p.platform;
题目五:用户订单
- 表描述(两张):
- 订单明细表ord,字段包括:dt-日期、dept-部门、pin-用户ID、ord_id-订单ID、sku_id-商品ID、qtty-销量、amout-金额。
- 全量用户画像表npl,字段包括:dt-日期、pin-用户ID、gender-性别(男/女)、age-年龄(0-18/19-25/26-30/31-35/36-45/46以上)、city_lvl-城市级别(L1/L2/L3/L4/L5/L6)、profession-职业。
- 数据准备: ```sql — 创建订单明细表ord DROP TABLE IF EXISTS ord; CREATE TABLE IF NOT EXISTS ord ( ord_id INT PRIMARY KEY AUTO_INCREMENT COMMENT ‘订单ID’, sku_id INT COMMENT ‘商品ID’, pin INT COMMENT ‘用户ID’, qtty INT COMMENT ‘销量’, amount INT COMMENT ‘销售额’, dept VARCHAR(255) COMMENT ‘部门’, dt DATE COMMENT ‘订单日期’ );
— 创建用户画像表npl DROP TABLE IF EXISTS npl; CREATE TABLE IF NOT EXISTS npl ( pin INT PRIMARY KEY COMMENT ‘用户id’, gender VARCHAR(10) COMMENT ‘性别’, age VARCHAR(255) COMMENT ‘年龄0-18/19-25/26-30/31-35/36-45/46以上’, city_lvl VARCHAR(255) COMMENT ‘城市级别 L1/L2…/L6’, profession VARCHAR(255) COMMENT ‘职业’, dt DATE COMMENT ‘创建日期’ );
— 插入数据 INSERT INTO npl VALUES (10001, ‘男’, ‘19-25’, ‘L2’, ‘医务人员’, ‘2021-06-01’), (10002, ‘男’, ‘0-18’, ‘L1’, ‘学生’, ‘2021-06-10’), (10003, ‘女’, ‘0-18’, ‘L2’, ‘学生’, ‘2021-06-05’), (10004, ‘女’, ‘19-25’, ‘L3’, ‘行政人员’, ‘2021-06-09’), (10005, ‘男’, ‘31-35’, ‘L2’, ‘教师’, ‘2021-06-01’), (10006, ‘女’, ‘36-45’, ‘L1’, ‘演员’, ‘2021-06-09’), (10007, ‘男’, ‘26-30’, ‘L4’, ‘医务人员’, ‘2020-06-10’), (10008, ‘男’, ‘26-30’, ‘L4’, ‘医务人员’, ‘2020-07-01’), (10009, ‘女’, ‘36-45’, ‘L6’, ‘演员’, ‘2020-07-01’), (10010, ‘女’, ‘26-30’, ‘L6’, ‘医务人员’, ‘2020-07-05’), (10011, ‘女’, ‘36-45’, ‘L6’, ‘演员’, ‘2020-07-07’), (10012, ‘女’, ‘26-30’, ‘L1’, ‘医务人员’, ‘2021-06-15’), (10013, ‘男’, ‘46以上’, ‘L1’, ‘演员’, ‘2019-06-22’), (10014, ‘男’, ‘46以上’, ‘L1’, ‘医务人员’, ‘2019-06-21’), (10015, ‘男’, ‘31-35’, ‘L5’, ‘演员’, ‘2019-06-11’), (10016, ‘女’, ‘46以上’, ‘L5’, ‘医务人员’, ‘2019-07-03’), (10017, ‘男’, ‘19-25’, ‘L2’, ‘医务人员’, ‘2019-07-09’), (10018, ‘女’, ‘46以上’, ‘L3’, ‘教师’, ‘2019-06-14’), (10019, ‘女’, ‘31-35’, ‘L5’, ‘教师’, ‘2019-06-22’), (10020, ‘男’, ‘31-35’, ‘L4’, ‘医务人员’, ‘2020-06-17’);
INSERT INTO ord(sku_id, pin, qtty, amount, dept, dt) VALUES (10, 10003, 10, 100, ‘01’, ‘2020-11-15’), (20, 10003, 10, 300, ‘02’, ‘2020-12-15’), (30, 10003, 10, 500, ‘03’, ‘2021-01-15’), (30, 10005, 10, 500, ‘01’, ‘2021-01-15’), (20, 10008, 10, 300, ‘03’, ‘2021-05-15’), (10, 10007, 10, 100, ‘03’, ‘2021-05-19’), (10, 10010, 10, 100, ‘02’, ‘2021-06-15’), (20, 10015, 10, 300, ‘02’, ‘2021-08-15’), (20, 10012, 10, 300, ‘01’, ‘2021-08-15’), (20, 10017, 10, 300, ‘02’, ‘2021-11-15’), (30, 10010, 10, 500, ‘02’, ‘2022-01-15’), (30, 10005, 10, 500, ‘01’, ‘2022-03-15’), (30, 10004, 10, 500, ‘03’, ‘2022-03-19’), (20, 10008, 10, 300, ‘03’, ‘2022-05-15’), (20, 10005, 10, 300, ‘03’, ‘2022-05-17’), (10, 10011, 10, 100, ‘03’, ‘2022-05-19’), (30, 10015, 10, 500, ‘02’, ‘2022-06-15’), (30, 10019, 10, 500, ‘01’, ‘2022-06-18’), (10, 10011, 10, 100, ‘03’, ‘2022-06-16’);
— 以下数据要根据时间动态修改,为上周数据(年份就今年和去年) INSERT INTO ord(sku_id, pin, qtty, amount, dept, dt) VALUES (20, 10012, 10, 300, ‘01’, ‘2021-11-14’), (20, 10017, 10, 300, ‘02’, ‘2021-11-15’), (30, 10010, 10, 500, ‘02’, ‘2021-11-15’), (30, 10005, 10, 500, ‘01’, ‘2021-11-14’), (30, 10004, 10, 500, ‘03’, ‘2022-11-20’), (20, 10008, 10, 300, ‘03’, ‘2022-11-17’), (20, 10005, 10, 300, ‘03’, ‘2022-11-14’), (10, 10011, 10, 100, ‘03’, ‘2022-11-17’), (30, 10015, 10, 500, ‘02’, ‘2022-11-15’), (30, 10019, 10, 500, ‘01’, ‘2022-11-14’);
- 需求一:提取上周各部门下单用户数、销量、金额、订单量、人均金额,以及下单用户数同比。- 注意:上周时间为2021年11月14日-2021年11月20日,下同;- 同比就是对比去年同期。```sql-- 提取上周各部门下单用户数、销量、金额、订单量、人均金额。-- 筛选出上周的数据SELECT * FROM ordWHERE YEAR(dt) = YEAR(NOW())AND WEEK(dt) + 1 = WEEK(NOW());-- 根据部门归类,统计指标SELECTdept,COUNT(DISTINCT pin) AS 用户数, -- 同一个用户可能下单多次,统计前要先去重SUM(qtty) AS 销量,SUM(amount) AS 金额,COUNT(ord_id) AS 订单量,ROUND(SUM(amount) / COUNT(DISTINCT pin), 2) AS 人均金额 -- 人均金额 = 总金额 ÷ 用户数。FROM ordWHERE YEAR(dt) = YEAR(NOW())AND WEEK(dt) + 1 = WEEK(NOW())GROUP BY dept;-- 要求同比,就要找到去年这个时候下单的用户数。SELECTdept,COUNT(DISTINCT pin) AS 用户数 -- 同一个用户可能下单多次,统计前要先去重FROM ordWHERE YEAR(dt) + 1 = YEAR(NOW())AND WEEK(CONCAT_WS('-', YEAR(NOW()), SUBSTR(dt, 6))) + 1 = WEEK(NOW()) -- 去年一个日期的周数和今年可能不一样,所以要先同一年份。GROUP BY dept;-- 结合同比(今年的 ÷ 去年的)SELECTdept,COUNT(DISTINCT pin) AS 用户数, -- 同一个用户可能下单多次,统计前要先去重SUM(qtty) AS 销量,SUM(amount) AS 金额,COUNT(ord_id) AS 订单量,ROUND(SUM(amount) / COUNT(DISTINCT pin), 2) AS 人均金额, -- 人均金额 = 总金额 ÷ 用户数。IFNULL(COUNT(DISTINCT pin) / (SELECT 用户数 FROM (SELECTdept,COUNT(DISTINCT pin) AS 用户数 -- 同一个用户可能下单多次,统计前要先去重FROM ordWHERE YEAR(dt) + 1 = YEAR(NOW())AND WEEK(CONCAT_WS('-', YEAR(NOW()), SUBSTR(dt, 6))) + 1 = WEEK(NOW()) -- 去年一个日期的周数和今年可能不一样,所以要先同一年份。GROUP BY dept) AS tmp WHERE tmp.dept = ord.dept), 0) AS 同比FROM ordWHERE YEAR(dt) = YEAR(NOW())AND WEEK(dt) + 1 = WEEK(NOW())GROUP BY dept;
- 需求二:提取上周各部门销量Top 100的商品。 ```sql — 先统计出上周各个部门中每种产品的销量值。 SELECT dept, sku_id, SUM(qtty) AS total_qtty FROM ord WHERE YEAR(dt) = YEAR(NOW()) AND WEEK(dt) + 1 = WEEK(NOW()) GROUP BY dept, sku_id;
— 然后对第一步的数据进行排名 SELECT *, ROW_NUMBER() OVER( PARTITION BY dept ORDER BY total_qtty DESC ) AS ranking FROM ( SELECT dept, sku_id, SUM(qtty) AS total_qtty FROM ord WHERE YEAR(dt) = YEAR(NOW()) AND WEEK(dt) + 1 = WEEK(NOW()) GROUP BY dept, sku_id ) AS tmp;
— 最后筛选出Top 100即可。 SELECT FROM ( SELECT , ROW_NUMBER() OVER( PARTITION BY dept ORDER BY total_qtty DESC ) AS ranking FROM ( SELECT dept, sku_id, SUM(qtty) AS total_qtty FROM ord WHERE YEAR(dt) = YEAR(NOW()) AND WEEK(dt) + 1 = WEEK(NOW()) GROUP BY dept, sku_id ) AS tmp ) AS tmp WHERE ranking <= 100;
- 需求三:提取上周各部门下单用户的性别、年龄、城市级别、职业人数分布(即用户画像)。```sqlSELECTdept,gender,age,city_lvl,profession,COUNT(*) AS 人数FROM ordJOIN npl ON ord.pin = npl.pinWHERE YEAR(ord.dt) = YEAR(NOW())AND WEEK(ord.dt) + 1 = WEEK(NOW())GROUP BY dept, gender, age, city_lvl, profession;
- 需求四:统计上周总体的新老用户数,其中新用户定义为该时间段之前从未下过单(假设从2020年1月1日开始有数)。 ```sql — 先去找上周的最后一天。 SELECT DATE_SUB(CURDATE(), INTERVAL DAYOFWEEK(CURDATE()) DAY);
— 若用户的创建时间小于上周的最后一天,就可以获取上周的所有新老用户数据。 SELECT npl.*, ord.dt AS ord_dt FROM npl LEFT OUTER JOIN ord ON npl.pin = ord.pin WHERE npl.dt < DATE_SUB(CURDATE(), INTERVAL DAYOFWEEK(CURDATE()) DAY);
— 老用户就是在2020-01-01之后有下单记录(即订单创建时间不为空)的用户。 SELECT COUNT(DISTINCT pin) AS 老用户数 FROM ( SELECT npl.*, ord.dt AS ord_dt FROM npl LEFT OUTER JOIN ord ON npl.pin = ord.pin WHERE npl.dt < DATE_SUB(CURDATE(), INTERVAL DAYOFWEEK(CURDATE()) DAY) ) AS tmp WHERE ord_dt IS NOT NULL AND ord_dt > ‘2020-01-01’;
— 新用户就是订单为空或者2020年1月1日之后没有订单的用户。 — 2020年1月1日之后没有订单的用户就是不在2020-01-01之后有下单记录的用户中的用户。 SELECT COUNT(DISTINCT pin) AS 新用户数 FROM ( SELECT npl.*, ord.dt AS ord_dt FROM npl LEFT OUTER JOIN ord ON npl.pin = ord.pin WHERE npl.dt < DATE_SUB(CURDATE(), INTERVAL DAYOFWEEK(CURDATE()) DAY) ) AS tmp WHERE ord_dt IS NULL OR pin NOT IN ( SELECT DISTINCT pin FROM ord WHERE dt > ‘2020-01-01’ );
- 需求五:计算今年5月总体下单用户的次月留存率(次月留存率的定义为:本月下单用户中在下个月仍有购买的人所占的比例)```sql-- 先查找5月份下单的用户。SELECT DISTINCTpinFROM ordWHERE YEAR(dt) = YEAR(NOW())AND MONTH(dt) = 5;-- 接着查找6月份下单的用户。SELECT DISTINCT pin FROM ordWHERE YEAR(dt) = YEAR(NOW()) AND MONTH(dt) = 6;-- 从6月份的数据中,找出5月份也有的用户。SELECT * FROM (SELECT DISTINCT pin FROM ordWHERE YEAR(dt) = YEAR(NOW()) AND MONTH(dt) = 6) AS tmpWHERE pin IN (SELECT DISTINCT pin FROM ordWHERE YEAR(dt) = YEAR(NOW()) AND MONTH(dt) = 5);-- 根据留存率的定义,可以得出6月的留存率 = 5月6月都下单的用户用户数 / 5月的总用户数。SELECT (SELECT COUNT(*) FROM (SELECT DISTINCT pin FROM ordWHERE YEAR(dt) = YEAR(NOW()) AND MONTH(dt) = 6) AS tmpWHERE pin IN (SELECT DISTINCT pin FROM ordWHERE YEAR(dt) = YEAR(NOW()) AND MONTH(dt) = 5)) / (SELECTCOUNT(DISTINCT pin)FROM ordWHERE YEAR(dt) = YEAR(NOW())AND MONTH(dt) = 5) AS result;
题目六:连续登录问题
- 题目描述:从日志表中取6月有过连续7天登录的用户。
- 表样式:user_id、login_datetime(登录时间,格式:yyyy-mm-dd hh:mm:ss)。
- 数据准备: ```sql — 创建表 DROP TABLE IF EXISTS login_tb; CREATE TABLE IF NOT EXISTS login_tb ( user_id INT, login_datetime DATETIME );
— 插入数据 INSERT INTO login_tb VALUES (1, ‘2022-06-20 11:23:35’), (2, ‘2022-06-20 17:23:35’), (3, ‘2022-06-20 21:23:35’), (4, ‘2022-06-20 12:23:35’), (5, ‘2022-06-20 19:23:35’), (1, ‘2022-06-20 19:23:35’), (1, ‘2022-06-20 21:23:35’), (2, ‘2022-06-21 11:23:35’), (2, ‘2022-06-22 11:23:35’), (2, ‘2022-06-23 11:23:35’), (2, ‘2022-06-24 11:23:35’), (2, ‘2022-06-29 11:23:35’), (2, ‘2022-06-30 11:23:35’), (3, ‘2022-06-23 11:23:35’), (3, ‘2022-06-24 11:23:35’), (3, ‘2022-06-25 11:23:35’), (3, ‘2022-06-27 11:23:35’), (3, ‘2022-06-29 11:23:35’), (3, ‘2022-06-30 11:23:35’), (4, ‘2022-06-21 11:23:35’), (4, ‘2022-06-29 11:23:35’), (5, ‘2022-06-21 11:23:35’), (5, ‘2022-06-22 11:23:35’), (5, ‘2022-06-23 11:23:35’), (5, ‘2022-06-24 11:23:35’), (5, ‘2022-06-25 11:23:35’), (5, ‘2022-06-26 11:23:35’), (5, ‘2022-06-27 11:23:35’), (1, ‘2022-06-25 11:23:35’), (1, ‘2022-06-27 11:23:35’);
- 解决思路:- 可以先处理一下数据,只保留年月日的时间即可。- 此时,若用户一天中登陆了多次,就会出现重复数据,即可以使用DISTINCT去重。- 接着,可以将同一个用户的数据归纳在一起,并且这里不能折叠数据,因此需要使用窗口函数完成。- 使用排名窗口函数完成。- 若时间是连续的,则`日期-排名`就是一个固定值,如: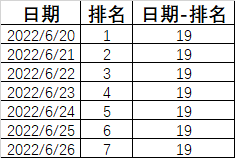- 接着,实现`日期-排名`这个操作。- 最后,根据用户ID和这个差值去分组,统计差值出现的次数。若差值出现的次数大于等于7,就说明该用户连续登录过7天。- SQL实现:```sql-- 处理时间数据并去重。SELECT DISTINCTuser_id AS uid,DATE(login_datetime) AS login_dtFROM login_tb;-- 使用窗户函数归纳数据。SELECT*,ROW_NUMBER() OVER (PARTITION BY uidORDER BY login_dt) AS rankingFROM (SELECT DISTINCT user_id AS uid, DATE(login_datetime) AS login_dt FROM login_tb) AS tmp;-- 实现“日期-排名”这个操作。SELECT*,DAY(login_dt) - ranking AS diffFROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY uid ORDER BY login_dt) AS rankingFROM (SELECT DISTINCT user_id AS uid, DATE(login_datetime) AS login_dt FROM login_tb) AS tmp) AS tmp;-- 归纳数据,找出连续登录7天的用户。SELECTuid,diff,COUNT(uid) AS continue_login_daysFROM (SELECT *, DAY(login_dt) - ranking AS diffFROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY uid ORDER BY login_dt) AS rankingFROM (SELECT DISTINCT user_id AS uid, DATE(login_datetime) AS login_dt FROM login_tb) AS tmp) AS tmp) AS tmpGROUP BY uid, diffHAVING continue_login_days >= 7;
题目七:黑产行为
- 题目描述:
- 现有点击日志表tencent_video_click_online。
- 包括字段:uid-用户ID、click_date-点击日期、click_time-点击时间戳、platform-平台(21移动端,22PC端)。
- 需求:已知同一用户在移动端连续两次点击时间间隔不高于2秒,则可能为黑产行为,请筛选出22年7月所有可能为黑产行为的用户。
- 数据准备: ```sql DROP TABLE IF EXISTS tencent_video_click_online; CREATE TABLE IF NOT EXISTS tencent_video_click_online ( uid INT COMMENT ‘用户ID’, click_date DATE COMMENT ‘点击日期’, click_time INT COMMENT ‘点击时间戳’, platform INT COMMENT ‘平台’ );
INSERT INTO tencent_video_click_online VALUES (1, ‘2022-07-09’, 1657353606, 22), (1, ‘2022-07-09’, 1657353600, 21), (1, ‘2022-07-09’, 1657353601, 21), (1, ‘2022-07-09’, 1657353606, 21), (2, ‘2022-07-09’, 1657353599, 21), (2, ‘2022-07-09’, 1657353606, 21), (3, ‘2022-07-09’, 1657353598, 21), (3, ‘2022-07-09’, 1657353599, 21), (4, ‘2022-07-09’, 1657353601, 21), (4, ‘2022-07-09’, 1657353606, 22), (5, ‘2022-07-09’, 1657353600, 21), (5, ‘2022-07-09’, 1657353606, 21), (7, ‘2022-07-09’, 1657353600, 21), (7, ‘2022-07-09’, 1657353601, 21), (7, ‘2022-07-09’, 1657353603, 21);
- SQL实现:```sql-- 连续两次点击的时间都存在点击表中,因此需要采用自连接。-- 第一个视作第一次点击,第二个视作第二次点击。-- 自连接的条件:平台一样,用户一样。SELECT * FROM tencent_video_click_online AS t1INNER JOIN tencent_video_click_online AS t2ON t1.uid = t2.uidAND t1.platform = t2.platform;-- 题目中需要的移动平台的黑产数据,因此可以过滤出platform=21的数据。-- 并且第一次点击的时间一定是早于第二次点击的时间的。SELECT * FROM tencent_video_click_online AS t1INNER JOIN tencent_video_click_online AS t2ON t1.uid = t2.uidAND t1.platform = t2.platformWHERE t1.platform = 21AND t1.click_time < t2.click_time;-- 最后,黑产行为的标准是两次点击时间间隔不高于两秒(第二次点击时间 - 第一次点击时间 <= 2)-- 以及题目要求的时间为22年7月。SELECT DISTINCT t1.uidFROM tencent_video_click_online AS t1INNER JOIN tencent_video_click_online AS t2ON t1.uid = t2.uidAND t1.platform = t2.platformWHERE t1.platform = 21AND t1.click_time < t2.click_timeAND t2.click_time - t1.click_time <= 2AND YEAR(t1.click_date) = 2022 AND MONTH(t1.click_date) = 7;
题目八:主播平均时长
- 题目描述:
- 现有主播表user_anchor。
- 表结构:id-主播ID、dt-日期(yyyy-mm-dd)、event-事件,有开播和下播两类、time-开播下播发生时间(yyyy-mm-dd hh:MM:ss)。
- 求10月份每个主播平均每次的直播时长。(开播和下播的次数一样,不存在缺失情况)
- 数据准备: ```sql DROP TABLE IF EXISTS user_anchor; CREATE TABLE IF NOT EXISTS user_anchor ( id INT COMMENT ‘主播ID’, dt DATE COMMENT ‘日期’, event INT COMMENT ‘开播为1,下播为2’, time DATETIME COMMENT ‘开播下播发生的时间’ );
INSERT INTO user_anchor VALUES (1, ‘2022-07-01’, 1, ‘2022-07-01 07:00:00’), (1, ‘2022-07-01’, 2, ‘2022-07-01 09:00:00’), (1, ‘2022-07-01’, 1, ‘2022-07-01 19:00:00’), (1, ‘2022-07-01’, 2, ‘2022-07-01 20:30:00’), (1, ‘2022-07-02’, 1, ‘2022-07-02 07:00:00’), (1, ‘2022-07-02’, 2, ‘2022-07-02 21:00:00’), (1, ‘2022-07-03’, 1, ‘2022-07-03 19:00:00’), (1, ‘2022-07-04’, 2, ‘2022-07-04 07:00:00’), (2, ‘2022-07-01’, 1, ‘2022-07-01 09:00:00’), (2, ‘2022-07-01’, 2, ‘2022-07-01 11:00:00’), (2, ‘2022-07-03’, 1, ‘2022-07-03 19:00:00’), (2, ‘2022-07-03’, 2, ‘2022-07-03 22:00:00’);
- SQL实现:```sql-- 要知道7月份每个主播的平均直播时长,就要知道总直播时长和直播次数。-- 首先:每次的直播时间,即求上播时间和下播时间的时间差。-- (抽象出上播表和下播表,使用自连接查询)SELECT * FROM user_anchor AS onlineINNER JOIN user_anchor AS offlineON online.id = offline.id -- 相同主播进行关联AND online.event = 1 -- 上播表仅处理上播事件AND offline.event = 2 -- 下播表仅处理下播事件WHERE online.time < offline.time; -- 按照现实逻辑,上播时间一定是小于下播时间的。-- 步骤一完成后,发现上播时间重复的在和下播时间进行匹配。-- 那按照常理来说,每一个下播时间,对应的是和它最近的上播时间。-- 因此可以按照用户和下播时间进行归类,找出上播时间的最大值即可。SELECTonline.id,MAX(online.time) AS online_time,offline.time AS offline_timeFROM user_anchor AS onlineINNER JOIN user_anchor AS offlineON online.id = offline.idAND online.event = 1AND offline.event = 2WHERE online.time < offline.timeGROUP BY id, offline.time;-- 接着,在步骤二的基础上,求每次的直播时长(直播时长 = 下播时间 - 上播时间)SELECT*,TIMESTAMPDIFF(MINUTE, online_time, offline_time) AS minute_diffFROM (SELECT online.id, MAX(online.time) AS online_time, offline.time AS offline_timeFROM user_anchor AS onlineINNER JOIN user_anchor AS offline ON online.id = offline.id AND online.event = 1 AND offline.event = 2WHERE online.time < offline.timeGROUP BY id, offline.time) AS tmp;-- 最后,按照主播ID分组求时间平均值即可。SELECTid,AVG(minute_diff) AS avg_minuteFROM (SELECT *, TIMESTAMPDIFF(MINUTE, online_time, offline_time) AS minute_diffFROM (SELECT online.id, MAX(online.time) AS online_time, offline.time AS offline_timeFROM user_anchor AS onlineINNER JOIN user_anchor AS offline ON online.id = offline.id AND online.event = 1 AND offline.event = 2WHERE online.time < offline.timeGROUP BY id, offline.time) AS tmp) AS tmpGROUP BY id;

若有收获,就点个赞吧
0 人点赞
