01. 列表的基本概念
1.1 容器介绍
- 在Python中可以使用容器类型的数据结构来保存和操作多个数据。
容器在Python中有列表(List)、元组(Tuple)、字典(Dict)、集合(Set)四大类。
1.2 列表的概念与定义
1.2.1 列表的基本概念
列表是有一系列元素按照特定顺序构成的数据序列,可以用来保存多个数据。
- 列表中的元素可以重复(不可重复的在Python称为集合)。
Python与Java等语言不同,Python的列表中可以存储不同类型的数据。
1.2.2 列表与字符串的异同
和字符串一样,列表也是一个有序序列,因此也可以使用索引。
和字符串不同的是列表是一个可变序列,因此索引不仅可以用来获取元素,还可以用来修改元素。
1.2.3 列表的定义
可以使用
[]字面量表示法定义列表,列表中可以有多个元素,每个元素间用逗号隔开。 ```python nums = [] # 空列表 nums = [17] # 一个元素的列表 nums = [17, 34, 56, 78, 91] # 多个元素的列表,元素间用逗号隔开
jack_info = [“Jack”, 27, True] # 一个列表中可以存放不同类型的数据
- 可以使用`list(序列型数据)`函数来构造列表。```pythonlst0 = list() # 生成空列表print(lst0) # []lst1 = list(range(5)) # 将range(5)生成的序列构造成列表print(lst1) # [0, 1, 2, 3, 4]lst2 = list("Hello") # 字符串的本质是字符序列,因此用字符串也可以构造列表print(lst2) # ['H', 'e', 'l', 'l', 'o']
可以使用列表推导式生成列表。
lst = [x for x in range(10)]print(lst) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
02. 列表的相关操作
2.1 列表的索引与切片
列表是一个有序序列,因此也可以使用索引和切片。
列表的索引与切片和字符串十分类似,唯一区别是列表是可变序列,可以用索引修改元素。
2.1.1 列表的索引
与字符串相同的是,列表也是有序序列,因此每个元素按照添加的先后顺序拥有下标(即索引值),故列表可以用元素的下标定位并获取元素。
lst = [39, 46, 72, 81, 55, 67]print(lst[2]) # 72,正向索引print(lst[-3]) # 81,负向索引
与字符串不同的是,列表是可变序列,因此列表还可以用索引来定位并修改元素。
lst = [39, 46, 72, 81, 55, 67]lst[1] = 77lst[-2] = 93print(lst) # [39, 77, 72, 81, 93, 67]
2.1.2 列表的切片
列表的切片与字符串基本一致,不过是字符串切到的是子字符串,列表切到的是子列表的区别。
lst = [39, 46, 72, 81, 55, 67, 122, 30, 12, 98]print(lst[1:6]) # [46, 72, 81, 55, 67]print(lst[2:-3]) # [72, 81, 55, 67, 122]print(lst[3:9:2]) # [81, 67, 30]print(lst[::-1]) # [67, 55, 81, 72, 46, 39]
列表的切片还可以给多个元素同时修改值。
- 注意,哪怕多个元素全部要改为同一个数据,也不能写
list[startIndex:endIndex:step] = value这样的形式。这是因为value不具有迭代能力,它就是一个值。 - 如
lst[3:9:2] = 2和lst[3:9] = 2都会报错:TypeError: can only assign an iterable。 - 只有当value是容器类型的数据,并且当长度与切片的长度相等时,才能修改成功。
故上述例子必须写成
lst[3:9:2] = [2, 2, 2]和lst[3:9] = [2, 2, 2, 2, 2, 2]。lst = [39, 46, 72, 81, 55, 67, 122, 30, 12, 98]lst[3:6] = [3, 4, 5]print(lst) # [39, 46, 72, 3, 4, 5, 122, 30, 12, 98]
但是列表的切片支持将一段连续的元素合并成一个或多个元素,也可以将少数数据扩展成多个数据。
- 但若定位到的元素不是连续的,即是跳跃的元素,则定位到的元素和要赋值的列表中元素的个数必须保持一致。
- 即连续元素可以扩大或缩小,但不连续的元素不支持扩大或缩小。 ```python lst = [39, 46, 72, 81, 55, 67, 122, 30, 12, 98]
- 注意,哪怕多个元素全部要改为同一个数据,也不能写
合并(减少元素)
lst[2:6] = [9] print(lst) # [39, 46, 9, 122, 30, 12, 98] lst[1:6] = [1, 2, 3] print(lst) # [39, 1, 2, 3, 98]
扩展(增加元素)
lst[1] = [4, 2, 5, 3, 1] print(lst) # [39, [4, 2, 5, 3, 1], 2, 3, 98],将一个int型元素换成一个列表型数据,这不会增加列表元素的个数。 lst[1:2] = [4, 2, 5, 3, 1] print(lst) # [39, 4, 2, 5, 3, 1, 2, 3, 98],实现1个元素扩展成多个元素。 lst[1:3] = [43, 56, 74, 23, 45, 67] print(lst) # [39, 43, 56, 74, 23, 45, 67, 5, 3, 1, 2, 3, 98],多个元素的扩展。
<a name="VZTfK"></a>### 2.2 列表的运算- 列表支持的运算符有:+、*、in、not in、+=、*=、比较运算符。<a name="QHNVZ"></a>#### 2.2.1 +连接列表- `l1 + l2`会生成一个新的列表,将两个列表的元素合并到新列表中。```pythonlst1 = [1, 2, 3, 4, 5]lst2 = [6, 7, 8, 9, 10]lst3 = lst1 + lst2print(lst3) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
2.2.2 *重复列表
lst * num会生成一个新的列表,将列表lst中的元素重复n次,然后放到新的列表中。lst1 = [1, 2, 3]lst2 = lst1 * 3print(lst2) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
2.2.3 in判断列表是否拥有某元素
ele in lst用于判断一个元素ele是否存在于列表lst中。lst = [1, 3, 5, 7, 9]print(1 in lst) # Trueprint(2 in lst) # False
2.2.4 not in判断列表是否不拥有某元素
ele not in lst用于判断一个元素ele是否不存在于列表lst中。lst = [1, 3, 5, 7, 9]print(1 not in lst) # Falseprint(2 not in lst) # True
2.2.5 +=合并列表
lst += seq用于将序列seq中的元素合并到列表lst中,不会生成新的列表。lst = [1, 2, 3]lst += [4, 5] # 合并列表print(lst) # [1, 2, 3, 4, 5]lst += (6, 7) # 合并元组print(lst) # [1, 2, 3, 4, 5, 6, 7]lst += "Hello" # 合并字符串print(lst) # [1, 2, 3, 4, 5, 6, 7, 'H', 'e', 'l', 'l', 'o']lst += range(9, 20, 2) # 合并range序列print(lst) # [1, 2, 3, 9, 11, 13, 15, 17, 19]
2.2.6 *=重复n次
lst *= n用于将列表lst中的元素重复n次,不会生成新的列表。lst = [1, 2, 3]lst *= 3print(lst) # [1, 2, 3, 1, 2, 3, 1, 2, 3]
2.2.7 比较运算符
列表支持的比较运算符有:
>、>=、<、<=、==、!=。列表的比较运算类似于字符串,会从左到右对相同位置的元素进行比较,一旦比较出结果则马上结束。
lst1 = [1, 2, 3, 4, 5]lst2 = [1, 2, 5, 4, 5]print(lst1 > lst2) # False,最终得出结论的是3 > 5为False。得出结论后,后续的元素不在比较。print(lst1 < lst2) # True
相等则是要所有元素完全相同才为True,不相等则是一个元素不等就为True。
lst1 = [1, 2, 3, 4, 5]lst2 = [1, 2, 3, 4, 5]lst3 = [1, 2, 5, 4, 5]print(lst1 == lst2) # Trueprint(lst1 == lst3) # Falseprint(lst1 != lst3) # True
2.3 列表的遍历
2.3.1 直接遍历列表
可以通过for-in循环直接遍历列表,会从左到右依次获取列表中的所有元素。
nums = [18, 23, 45, 61, 29, 35]for ele in nums:print(ele)
2.3.2 通过下标遍历
range(0, len(lst))可以生成由数组lst中的每一个索引组成的序列,由此可以遍历数组中的每一个元素。
lst = [18, 23, 45, 61, 29, 35]for i in range(0, len(lst)):print(lst[i])
2.3.3 enumerate遍历
枚举操作:
enumerate(有序序列)可以生成一个二维元组序列。- 序列中的元素又是序列的序列称为二维序列,如
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]就是一个二维数组序列。 enumerate(有序序列)生成的序列中的每个元素都是一个二元组,其值的格式为:(索引值, 元素)lst = [18, 23, 45, 61, 29, 35]for i in enumerate(lst):print(i)
运行结果:
(0, 18)(1, 23)(2, 45)(3, 61)(4, 29)(5, 35)
- 序列中的元素又是序列的序列称为二维序列,如
注意:任何的有序序列(列表、元组、字符串)都可以通过enumerate()生成(索引, 元素)的二维序列。
虽然用for循环也可以实现(index, element)这也的二维序列,但相比之下用enumerate()函数效率会高很多。
2.3.4 拆包(解包)
所谓的拆包(也成为解包)是指将一个序列中的元素赋值给多个变量。
如现有
nums = [19, 22],那么拆包就是a, b = nums。- 这个操作会把列表nums中第一个元素赋值给变量a,第二个元素赋值给变量b。
lst = [19, 22]a, b = lstprint(a, b) # 19 22
- 这个操作会把列表nums中第一个元素赋值给变量a,第二个元素赋值给变量b。
因此可以对enumerate(序列)获取到的内容进行拆包操作。
lst = [18, 23, 45, 61, 29, 35]for index, element in enumerate(lst):print(f"{index}位上的元素是{element}")
lst.append(obj):用于将元素obj添加到列表lst的末尾。
示例:将81添加到列表
lst = [27, 71, 33, 45, 27, 19, 66, 54]lst = [27, 71, 33, 45, 27, 19, 66, 54]lst.append(81)print(lst) # [27, 71, 33, 45, 27, 19, 66, 54, 81]
2.4.2 insert()插入元素
lst.insert(index, obj):用于将元素obj插入到列表lst中的index索引位中。
示例:在列表
lst = [21, 43, 51, 23, 45, 63]中的3索引位上插入77。lst = [21, 43, 51, 23, 45, 63]lst.insert(3, 77)print(lst) # [21, 43, 51, 77, 23, 45, 63]
2.4.3 extend()合并列表
lst1.extend(lst2):用于将列表lst2追加到列表lst1的末尾。
示例:将列表
new_lst = [12, 45, 56, 22]追加到列表lst = [61, 23, 54]的末尾。lst = [61, 23, 54]new_lst = [12, 45, 56, 22]lst.extend(new_lst)print(lst) # [61, 23, 54, 12, 45, 56, 22]
2.5 列表元素的删除
2.5.1 del list[index]/del list删除指定位置的元素或删除列表
del lst[index]:用于删除列表lst中index索引位的元素。
示例1:删除列表
lst = [12, 43, 32, 32, 43]中索引为2的元素。lst = [12, 43, 32, 32, 43]del lst[2]print(lst) # [12, 43, 32, 43]
del lst:用于将列表lst从内存中删除,此时在访问列表lst会报错。
示例2:将列表
lst = [12, 43, 32, 32, 43]从内存中删除。lst = [12, 43, 32, 32, 43]del lstprint(lst) # 报错:NameError: name 'lst' is not defined
2.5.2 pop()删除指定位置的元素
lst.pop(index):用于删除列表lst中index索引位的元素,并将删除的数据返回。
示例:删除列表
lst = [12, 43, 32, 32, 43]中索引为2的元素。lst = [12, 43, 32, 32, 43]remover_ele = lst.pop(2)print(lst) # [12, 43, 32, 43]print(remover_ele) # 32,pop()会将删除的元素返回。
可以不手动指定index,在缺省情况下,pop()会删除列表中的最后一个元素。
lst = [12, 43, 32, 32, 43]lst.pop()print(lst) # [12, 43, 32, 32]
2.5.3 remove()删除指定元素
lst.remove(obj):在列表lst中从左往右删除第一个obj元素。
- 从左到右是指若列表中存在多个相同的重复元素,则remove()函数只会删除最左边的那个元素。
- 如果元素obj在列表lst中不存在,则remove()函数的运行会报错。
示例1:删除列表
lst = [56, 23, 12, 32, 12, 43, 12, 43]中第一个12。再删除一个不存在的元素41。lst = [56, 23, 12, 32, 12, 43, 12, 43]lst.remove(12)print(lst) # [56, 23, 32, 12, 43, 12, 43]lst.remove(41) # 报错:ValueError: list.remove(x): x not in list
2.5.4 clear()清空列表
lst.clear():用于删除列表lst中所有的元素,将列表lst变成一个空列表。
示例:删除列表
lst = [56, 23, 12, 32, 12, 43, 12, 43]中的所有元素。lst = [56, 23, 12, 32, 12, 43, 12, 43]lst.clear()print(lst) # []
2.5.5 移除元素存在的漏洞以及解决方案
现有一个列表
values = [18, 27, 33, 56, 18, 29, 18, 18, 24, 18, 18],需求是将其中所有18删除。- 基本思路:
- 用for循环遍历列表中每一个元素。
- 若遍历到的元素是18,则用remove()函数删除;若遍历到的元素不是18,就继续遍历下一个元素。
编码实现:
values = [18, 27, 33, 56, 18, 29, 18, 18, 24, 18, 18]for e in values:if e == 18:values.remove(e)print(values) # [27, 33, 56, 29, 24, 18, 18]
存在的问题:从运行结果来看,18并没有被删干净。
- 问题原因分析:
- for循环会先进入到容器内,判断是否有下一个元素,如果有下一个元素,则遍历下一个元素。
- 比如
[18, 18, 27],首次遍历得到元素18,则if为True,首个18被删除,此时列表为[18, 27]。 - 接着for循环发现列表中还有下一个元素,就会遍历下一个元素,即索引为1的元素,但此时索引1对应的元素为27,而非18。
- 由于27 != 18,因此if为False,此时for发现已经没有下一个元素了,故循环结束。
- 在此过程中,可以发现原列表
[18, 18, 27]中索引0的18被删除了,但索引1的18并没有遍历到。 - 上述程序也是因为这种原因,所以漏了两个18没有被删掉,具体程序的运行图解如下表:
- 注意第七次遍历,虽然遍历到了倒数第二个18,但是remove(18)删除的是列表中最左边的18。
- 由此而来,24前面的18被删除了,而第七次遍历到的18并没有被删除,和未遍历的最后一个18一起留下了。
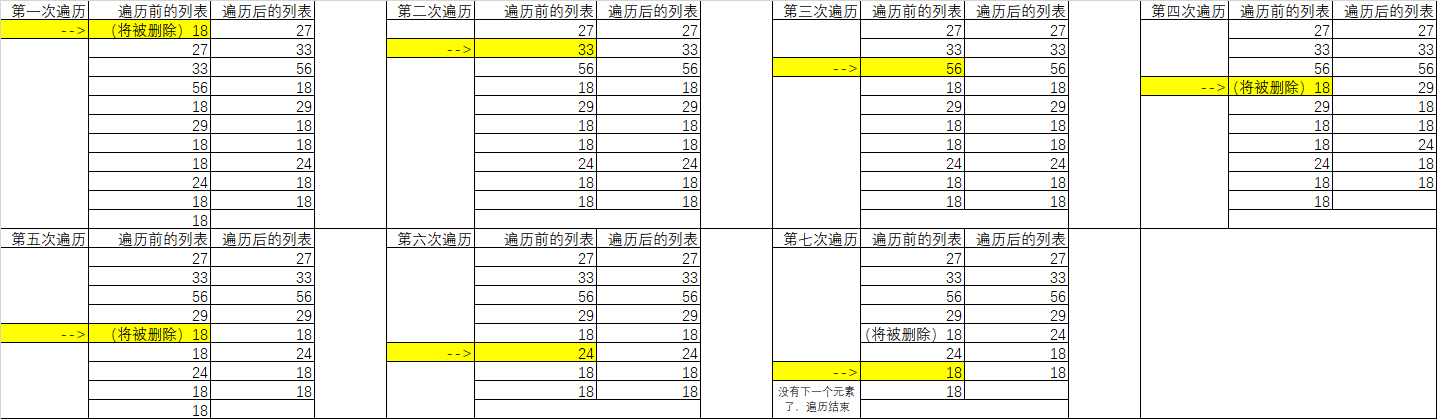
解决方式一:添加代替删除。
- 除了values数据,再定义一个临时数组tmp。
- 遍历values中每个元素,若遍历到的元素不等于18,则将这个元素添加到tmp中。
- 将tmp赋值给values。
values = [18, 27, 33, 56, 18, 29, 18, 18, 24, 18, 18]tmp = [i for i in values if i != 18]values = [i for i in tmp]print(values) # [27, 33, 56, 29, 24]
解决方式二:遍历新列表,删除老列表。
- 定义一个新列表new_lst,将values中所有的元素复制一份到new_lst中。
- 遍历new_lst中的元素,若遍历到18,则删除values中的18。(这也就可以遍历到一份数据中的所有18) ```python values = [18, 27, 33, 56, 18, 29, 18, 18, 24, 18, 18] new_lst = [i for i in values]
遍历新列表,删除老列表
for i in new_lst: if i == 18: values.remove(18) print(values) # [27, 33, 56, 29, 24]
- 解决方式三:从后往前通过索引删除元素。- 首先定义一个索引列表index_list,然后遍历values,若元素为18,则将其索引添加到index_list中。- 将index_list反转,得到一个索引值为从右往左的索引列表。(删除后面的18不会影响前面18的索引位置)- 根据index_list中的索引数据,用pop(index)函数删除元素。```pythonvalues = [18, 27, 33, 56, 18, 29, 18, 18, 24, 18, 18]index_list = []# 填充元素18的所有索引值,并倒置。for index, value in enumerate(values):if value == 18:index_list.append(index)index_list = index_list[::-1]print(index_list) # [10, 9, 7, 6, 4, 0]# 通过元素删除所有元素18。for i in index_list:values.pop(i)print(values) # [27, 33, 56, 29, 24]
2.6 列表的其他操作
2.6.1 reverse()逆置列表元素
list.reverse():直接操作列表本身,将列表中的元素进行逆置。
lst3 = [213, 643, True, "ABC", 132]lst3.reverse()print(lst3) # [132, 'ABC', True, 643, 213]
当然,也可以通过切片的方式逆置元素,只不过这种方式不操作列表本身,会产生返回值。
lst = [213, 643, True, "ABC", 132]new_lst = lst[::-1]print(new_lst) # [132, 'ABC', True, 643, 213]
2.6.2 sort()/sorted()列表排序
list.sort():直接操作列表本身,进行升序排序;同时,将参数reverse设置为如True可以实现降序排序。 ```python lst1 = [5, 1, 7, 3, 2, 6] lst1.sort() print(lst1) # [1, 2, 3, 5, 6, 7]
lst2 = [3, 7, 1, 4, 5, 8] lst2.sort(reverse=True) print(lst2) # [8, 7, 5, 4, 3, 1]
- sorted(list, reverse):不会直接操作列表本身,将排序的结果返回。- 这种方式可以直接切片。- 前面两种方式不能直接切片,因为sort()和reverse()操作的都是列表本身,没有返回值。```python# 取前三名的成绩# 方式一:records = [89, 78, 98, 56, 91, 75]print(sorted(records, reverse=True)[:3]) # [98, 91, 89]# 方式二:records = [89, 78, 98, 56, 91, 75]# 必须分开写records.sort(reverse=True)print(records[0:3]) # [98, 91, 89]
2.6.3 len()列表长度
len(lst):返回元素的个数(即列表的长度)。
lst = [132, 'ABC', True, 643, 213]print(len(lst)) # 5
2.6.4 count()元素出现次数
lst.count(obj):给定元素出现的次数。
lst = [5, 5, 1, 3, 2, 5]print(lst.count(5)) # 3
2.6.5 index()查找元素位置
列表可以通过下标来获取列表中的元素,同样的还可以用下标对列表进行切片。
l1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]print(l1[3]) # 3print(l1[1:9:2]) # [1, 3, 5, 7]
反过来,列表还可以通过
index(obj)返回元素obj第一次出现的位置的下标。若列表中没有元素obj则报错。l2 = [0, 6, 1, 3, 5, 7, 1]print(l2.index(1)) # 2print(l2.index(12)) # 报错:ValueError: 12 is not in list
index(obj, start_index)和index(obj, start_i, end_i)(不包含end_i)还可以指定查找的位置。nums = [17, 22, 34, 56, 18, 41, 22, 65, 22]pos = nums.index(22, 3)print(pos) # 6pos = nums.index(22, 7, 9)print(pos) # 8
2.7 深拷贝和浅拷贝
2.7.1 数据拷贝概述
在Python中对于数据的拷贝可以根据拷贝形式的不同分为深拷贝和浅拷贝。
- 注意:拷贝只是针对于可变数据类型(字典、列表、集合)而言的,不可变数据类型(元组、不可变集合、字符串)没有拷贝一说,因为不可变数据只要数据内容相同,地址就不会发生变化。 ```python import copy
t = (11, 20, 30) # 元组是不可变数据 copy_t = copy.copy(t) deep_copy_t = copy.deepcopy(t) print(f”原数据地址:{id(t)}、浅拷贝地址:{id(copy_t)}、深拷贝地址:{id(deep_copy_t)}”) “”” 运行结果: 原数据地址:2899309161088、浅拷贝地址:2899309161088、深拷贝地址:2899309161088 id全部相同,说明拷贝无效 “””
- 对于一维数据而言,深浅拷贝是没有区别的,深浅拷贝的差别主要体现在多维数据上。<a name="YYSY8"></a>#### 2.7.2 Python中的赋值- Python中的赋值都是地址引用,即将等号右边的地址赋值给等号左边的变量,而非将值本身赋值给左边的变量。- 如下操作是一个列表变量的赋值:```pythonlst1 = [5, 1, [7, 3]]lst2 = lst1
- 在内存中其大致结构如下:
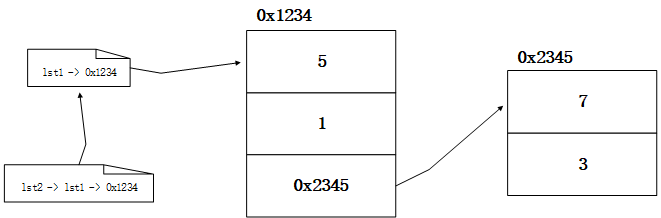
- 可以用id()函数来验证,可以发现id(lst1)和id(lst2)的结果是一样的。
print(id(lst1)) # 2058910520000print(id(lst2)) # 2058910520000
因此在这种情况下,对lst2做修改,实际上就是对0x1234做修改,故lst2的修改结果会影响到lst1。
lst2[1] = 300print(lst1) # [5, 300, [7, 3]]
2.7.3 浅拷贝
浅拷贝即将数据的表面结构进行拷贝,如果数据为嵌套的结构,则嵌套结构里面的元素是对之前数据的引用。修改之前的数据会影响拷贝得到的数据。
- 浅拷贝通过copy模块中的copy(obj)方法实现: ```python import copy
lst1 = [5, 1, [7, 3]] lst2 = copy.copy(lst1)
- 在内存中其大致结构如下:(实际上lst1和lst2中的5、1也是同一个数据对象)- 这种情况下,直接看两个列表变量的id那肯定是不一样的,但是这两个列表中所有的元素引用的还是同一个地址。```pythonprint(id(lst1), id(lst2)) # 1729082378176 1729085617728print(id(lst1[0]), id(lst2[0])) # 2151962929584 2151962929584print(id(lst1[1]), id(lst2[1])) # 2394705848624 2394705848624print(id(lst1[2]), id(lst2[2])) # 1729085600576 1729085600576
- 此时,直接修改列表lst1中的元素,不会对lst2产生影响,但是若修改lst1中嵌套的数据结构,lst2就会被影响。 ```python lst1[1] = 100 print(lst1, lst2) # [5, 100, [7, 3]] [5, 1, [7, 3]]
lst1[2][1] = 400 print(lst1, lst2) # [5, 100, [7, 400]] [5, 1, [7, 400]]
lst1[2] = [300, 500] # 将嵌套结构的地址改掉 print(lst1, lst2) # [5, 100, [300, 500]] [5, 1, [7, 400]]
lst1[2][1] = 800 # 此时修改lst1就不会对lst2产生影响了 print(lst1, lst2) # [5, 100, [300, 800]] [5, 1, [7, 400]]
- 当然,浅拷贝也可以通过`list_obj.copy()`实现。```pythonlst1 = [5, 1, [7, 3]]lst2 = lst1.copy()print(id(lst1), id(lst2)) # 1729082378176 1729085617728print(id(lst1[2]), id(lst2[2])) # 1729085600576 1729085600576
2.7.4 深拷贝
- 深拷贝,解决了嵌套结构中深层结构只是引用的问题,它会对所有的数据进行一次复制,修改之前的数据则不会改变拷贝得到的数据。
- 深拷贝通过copy模块中的deepcopy(obj)方法实现: ```python import copy
lst1 = [5, 1, [7, 3]] lst2 = copy.deepcopy(lst1)
lst1[1] = 100 lst1[2][1] = 400
print(lst1, lst2) # [5, 100, [7, 400]] [5, 1, [7, 3]]
<a name="q0jzs"></a>### 2.8 列表的常见应用<a name="hRhdK"></a>#### 2.8.1 过滤符合条件的数据- 基本思路:- 定义一个空列表。- 遍历原列表中所有元素,找出符合条件的元素。- 将符合条件的元素添加到空列表中。- 示例:筛选出列表`nums = [18, 24, 33, 61, 35, 27]`中元素为3的倍数的元素。```pythonnums = [18, 24, 33, 61, 35, 27]new_nums = []for ele in nums:if ele % 3 == 0:new_nums.append(ele)print(new_nums) # [18, 24, 33, 27]
2.8.2 转换列表中的数据
- 基本思路:
- 定义一个空列表。
- 遍历原列表中所有元素,将每个元素转换为需要的格式。
- 将转换完成的数据添加到空列表中。
示例:将列表
nums = [19, 81, 27, 33, 65]中所有的数据都转换为字符串,并在前后都添加%,如数据81转换成”%81%”。nums = [19, 81, 27, 33, 65]new_nums = []for ele in nums:str_ele = f"%{str(ele)}%"new_nums.append(str_ele)print(new_nums) # ['%19%', '%81%', '%27%', '%33%', '%65%']
2.9 列表推导式
列表推导式也是定义列表的一种方式,代码简洁,可提升执行效率。
- 基本格式:
[放在列表中的元素 遍历操作[ 筛选操作]]- 注:筛选操作用于筛选遍历中的数据,不是必要的。
示例1:现有列表
nums = [18, 24, 33, 61, 35, 27],定义一个新列表,其元素是nums中所有为三的倍数的元素。nums = [18, 24, 33, 61, 35, 27]new_nums = [ele for ele in nums if ele % 3 == 0]print(new_nums) # [18, 24, 33, 27]
示例2:用列表推导式生成列表,其中的元素是
[2, 4, 6, 8, 10, 12, 14, 16, 18, 20]nums = [i * 2 for i in range(1, 11)]print(nums) # [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
示例三:
所谓二维列表,就是列表中的元素又是一个列表。
lst = [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]print(lst) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
二维列表实际上存储的数据更像是一张表数据,因此二维列表也可以写成行和列的形式。
lst = [[1, 2, 3],[4, 5, 6],[7, 8, 9],[10, 11, 12]]print(lst) # [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]]
如何确定是二维列表:列表定义式开头有几个连续的
[就是几维列表,如[[就是二维列表、[[[[[就是五维列表。3.2 二维列表元素的索引
3.2.1 获取外层元素
获取二维列表的外层元素时,可以将二维列表看成一个普通的一维列表来操作即可。
示例:获取每个学生的成绩。
score = [[76, 87, 88], [68, 76, 55]]print(f"小明的成绩:{score[0]}") # 小明的成绩:[76, 87, 88]print(f"小涛的成绩:{score[1]}") # 小涛的成绩:[68, 76, 55]
3.2.2 获取内层元素
二维列表的内层元素可以通过
列表对象[外层索引][内层索引]的方式获取。- 示例:获取每个学生每门课的成绩。 ```python score = [[76, 87, 88], [68, 76, 55]]
print(“小明的成绩:”) print(f”语文:{score[0][0]}”) print(f”数学:{score[0][1]}”) print(f”英语:{score[0][2]}”)
print(“小涛的成绩:”) print(f”语文:{score[1][0]}”) print(f”数学:{score[1][1]}”) print(f”英语:{score[1][2]}”) ```

若有收获,就点个赞吧
0 人点赞
